Удаление подсказок при поиске в Яндексе
Как удалить историю запросов в поисковой строке Яндекс
Когда вы совершаете поиск в той или иной поисковой системе, она сохраняет ваши запросы. Разработчики осведомлены, что пользователям свойственно искать ту же информацию через некоторое время. Поэтому мы при вводе повторяющихся слов видим в подсказках уже знакомые, веденные нами ранее фразы. Такая помощь не всегда полезна. Темой этой статьи станет удаление истории запросов в поисковой строке Яндекс.
Как избавиться от собственных запросов в Яндекс
Вне зависимости от того, авторизованы ли вы в системе Яндекс, поисковик вместе с браузером запоминают историю веденных вами фраз. Если вы ведете уже знакомое слово, то все ваши прошлые запросы будут выделены фиолетовым. Чтобы быстро удалить один или несколько из них, вы можете здесь же в строке навести курсор на нужный и нажать на крестик. Таким образом, он навсегда исчезнет из подсказок не только в текущей сессии, но и после перезагрузки браузера или даже компьютера.
Удаление подсказок в поисковой строке Яндекс
Не стоит забывать, что все манипуляции в браузере запоминаются в его истории. Поэтому, если вы хотите стереть свои следы пребывания на каком-нибудь ресурсе, вам необходимо очистить и свой обозреватель. Если вы ни разу не делали этого, поступите следующим образом:
- Откройте свой браузер, не зависимо от его названия;
- Найдите вверху на панели кнопку меню. Она может выглядеть как 3 горизонтальные линии (Firefox), 3 точки (Chrome) или первая буква названия, например, Opera;
- В меню найдите пункт «Настройки» и выберите его;
- А теперь найдите вверху окна настроек строку поиска. Она специально предназначена для быстрого перехода к тем или иным настройкам браузера;
- Введите в ней «Истор…». Не вводите свой запрос полностью, так как неверное его окончание может запутать систему, и вы ничего не найдете. Выберите пункт «Удалить историю».
Удаление истории в браузере
Найдите пункт «Удалить за все время» чтобы удалить всю историю посещений сайтов.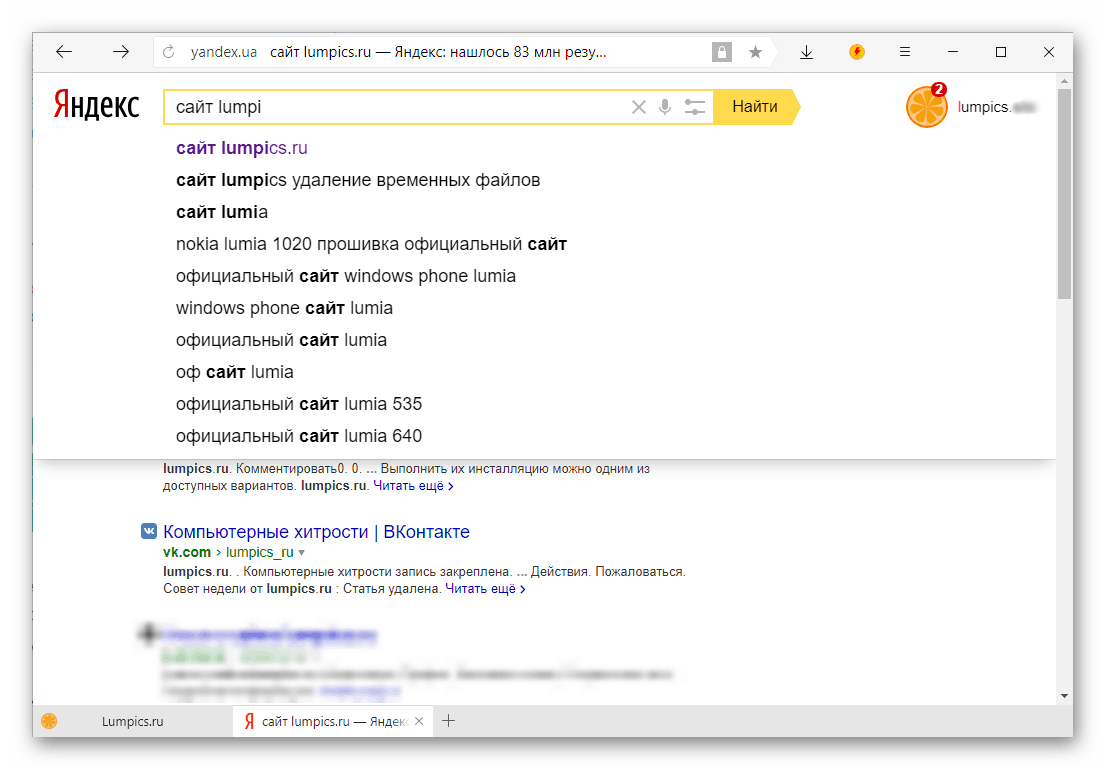 Если вас интересует какой-то отдельный сайт, в этом разделе также будет поиск. Воспользуйтесь им и найдите нужный ресурс.
Если вас интересует какой-то отдельный сайт, в этом разделе также будет поиск. Воспользуйтесь им и найдите нужный ресурс.
Очистить запросы в настройках аккаунта Yandex
- Вверху справа выберите свой аватар или имя аккаунта;
- В выпадающем меню нажмите пункт «Настройки»;
Настройки профиля в Яндекс
Разделы настроек в профиле Яндекс
Удаление истории поисковых запросов в профиле Яндекс
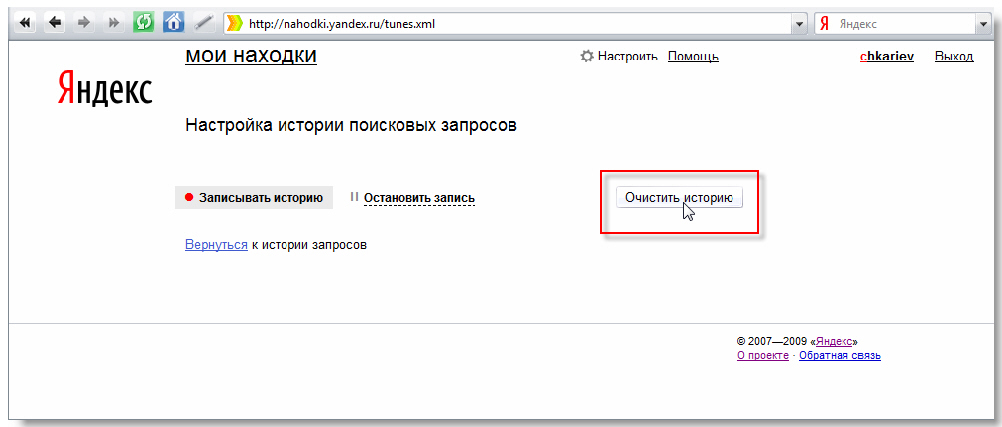
Прежде всего вам нужно нажать на кнопку «Очистить историю запросов», чтобы удалить ранее сохраненные данные. Остальные настройки выбирайте на свое усмотрение.
Очистить историю посещений в Яндекс Браузере
Отдельно необходимо поговорить о Яндекс Браузере. В нем удаление истории поисковых запросов Яндекс совершается немного иначе, чем в других браузерах. Тем не менее этот процесс не сложен.
В нем удаление истории поисковых запросов Яндекс совершается немного иначе, чем в других браузерах. Тем не менее этот процесс не сложен.
- Запустите браузер и нажмите на панели вверху «Настройки»;
- Выберите среди прочих пунктов — «История». Вы также можете открыть их при помощи горячих клавиш CTRL+N;
Очистка истории в Яндекс Браузере
Как почистить историю поиска Яндекс в мобильном устройстве
Очистить поисковые запросы Яндекс можно также через мобильное устройство — смартфон или планшет. Ведь и здесь вы будете видеть фразы, которые уже использовали для поиска. Эти строки, как и в веб-версии, выделены фиолетовым цветом. Удалить единичный запрос можно, нажав на крестик в подсказке. Если вы хотите избавиться от пару собственных запросов, вы можете удалить их на месте. Но если вам нужно настроить поиск, чтобы он не запоминал ваши запросы, тогда необходимо авторизоваться в системе Яндекс. Это можно сделать в мобильном приложении.
- В запущенном приложении необходимо выбрать кнопку меню;
- Выберите пункт «Настройки»;
- Найдите пункт «Сохранять историю…» и уберите ползунок в положение влево для её отключения;
Очистка истории в мобильном приложении Яндекс
Теперь все введенные вами фразы поисковая система Яндекс запоминать не будет. Если у вас установлен Яндекс Браузер для мобильных устройств, в нем тоже можно почистить историю.
Если у вас установлен Яндекс Браузер для мобильных устройств, в нем тоже можно почистить историю.
- Откройте браузер и выберите на панели значок в виде часов;
- Укажите на вкладку «История»;
- Выберите один из посещенных сайтов и нажмите кнопку «Удалить»;
- Если необходимо очистить все сайты сразу, выберите «Очистить историю.
Таким образом можно удалить историю ваших запросов не только в поисковой строке Яндекс, но и из браузеров на других устройствах.
Поисковые подсказки Яндекс: особенности формирования, использования и удаления
Когда мы вводим поисковый запрос в адресной или поисковой строке Яндекса, Google или в любом другом поисковике, то видим подсказки – это всплывающие окна с наиболее популярными запросами, которые совпадают с первыми словами, введенными юзером. По сути, поисковая система помогает пользователю максимально корректно сформулировать вопрос, чтобы затем показать наиболее релевантный ответ. Такая помощь ресурса очень полезна, ведь поисковики фильтруют контент и отображают максимально полезный, который соответствует запросу, а не просто в нем присутствуют ключевые слова.
В 2012 году специалисты компании Yandex посчитали, что если бы в начале 2000-х годов в поисковики не началось внедрение такой функции, как поисковые подсказки, то юзер потерял бы 60 лет на ручное формирование своих запросов и их корректирование. Поэтому поисковые подсказки нужны как для экономии времени, так и для следующих целей:
- Максимально корректного формирования поискового запроса и ответа;
- Для правильного формирования семантического ядра сайта специалистами SEO;
- Для отбора контента, который не соответствует запросу пользователя на 100% по теме, местоположению и дате добавления в сеть.
- Для формирования эффективной рекламы.
- Если говорить о подсказках для YouTube, то они нужны для оптимизации видео, которое в свою очередь даст трафик из поиска и рекомендаций. Также подсказки на видео-сервисе могут пригодиться блогерам при поиске идей для новых сюжетов.
Также нужно понимать, что сейчас количество поисковых запросов возросло в десятки раз, по сравнению с 2006-2007 годами, когда поисковые подсказки только были внедрены в поисковики. Поэтому среди разнообразия запросов выбрать нужный достаточно сложно, а вышеупомянутая функция упрощает использование сети.
Поэтому среди разнообразия запросов выбрать нужный достаточно сложно, а вышеупомянутая функция упрощает использование сети.
Формирование поисковых подсказок в таких поисковиках, как Яндекс и Гугл, осуществляется путем работы сложных алгоритмов. К ним относятся:
- Регион запроса. Как правило, если юзер ищет «avto в Москве», то сервис исключить из подсказок другие города, сократив, таким образом, количество результатов выдачи.
- Частота фраз в поисковом запросе. Поисковые сервисы предлагают юзеру наиболее популярные хвосты к введенному запросу.
- Фильтр. Из запроса исключаются нецензурные слова, фразы с ошибками и опечатками, низкопопулярные предложения.
- Ориентация на пользователя. Поисковые сервисы при обработке запроса ориентируются на часто запрашиваемые слова, на историю поиска конкретным пользователем и другую персональную информацию, о которой сервису известно.
- Обновление. Относится к новостным вопросам, поэтому окно с подсказками обновляется постоянно.


Это только основы для формирования поисковых подсказок. Есть сервисы, к примеру, avtodreem, которые занимаются глубоким анализом ключевых запросов, а поэтому для их корректного составления они используют другие алгоритмы.
Для того, чтобы понять, как работает поиск в Яндексе и его подсказки, рассмотрим несколько простых примеров.
Для начала отметим, что Яндекс подсказки значительно экономят время для пользователя. Если тот пишет с ошибками, то сервис их исключает. Если юзер постоянно или часто ищет одно и то же, то сервис запоминает запрос и выдает его до того, как пользователь его полностью введет.
Вот пример. На ПК часто просматривается информация о евробляхах. Соответственно, система выдает еще до начала введения хотя-бы одной буквы подсказки.
Естественно, поисковые подсказки не могут появиться ниоткуда. Список фраз, которые пользователь видит при введении запроса, формируется исходя из всех запросов от всех пользователей Яндекса. Далее они оправляются в фильтр, где исключаются запросы с нецензурной лексикой, персональными данными, а также фразы, которые относятся к порнографии и призывают к насилию.
ВАЖНО! Есть вирусные запросы. В данном случае подсказки по теме попадают в список «быстрых» и статистика обновляется каждые полчаса
Для того, чтобы увидеть чистое формирование поисковых подсказок, включим режим Инкогнито, который исключает любую вероятность использования данных пользователя. Ищем тему о решении BSOD ошибок.
Как видим, это пример использования ключевого запроса в Яндекс подсказках. Как показано на скриншоте, есть несколько категорий, по которым ищет сервис: общая информация, ошибки для конкретной сборки системы, конкретные ошибки. Далее, введя еще одно слово, поисковая подсказка будет уточнена.
Так работают подсказки.
Для того, чтобы не очищать каждый раз поисковые запросы, можно рассмотреть способ, как удалить подсказки в поисковике Яндекс в браузере на ПК и Android.
Как удалить историю поисковых запросов в Яндекс?
Было бы неправильно говорить, что всё, что пользователь вводил в поисковую строку, не оставило следов в истории посещений. Поэтому первым делом рекомендуем избавиться от истории просмотров сайтов, а далее переходить к запросам и подсказкам.
Поэтому первым делом рекомендуем избавиться от истории просмотров сайтов, а далее переходить к запросам и подсказкам.
Чтобы удалить историю просмотров в Яндексе, стоит нажать на кнопку «Меню», «История».
Далее справа нажимаем на кнопку «Очистить историю».
Появится небольшое окно. Выбираем время, за которое нужно очистить историю. Также указываем элементы для очистки. Кликаем «Очистить».
Теперь нужно очистить сами подсказки. Их достаточно просто убрать в Настройках обозревателя. Для этого нужно открыть «Настройки» и найти раздел «Поиск». Убираем все отметки, которые касаются подсказок.
Если не убирать эти отметки, то подсказки будут появляться дальше. Идентичные настройки применяются в случае, если вы используете смартфон с операционной системой Android.
Если вы хотите, чтобы ваш телефон при наборе в поисковике в мобильной версии Яндекса определенного запроса не выдавал подсказки, то проще всего выполнить удаление истории просмотров. Это самый простой способ, как удаляют подсказки в поисковике Яндекс Браузер с мобильного гаджета.
Это самый простой способ, как удаляют подсказки в поисковике Яндекс Браузер с мобильного гаджета.
Для того, чтобы удалять историю просмотров, стоит перейти в «Настройки» приложения и найти раздел «Конфиденциальность».
Далее нажимаем на кнопку «Очистить данные». Проставляем галочки возле тех пунктов, которые нужно очистить.
Кликаем «Очистить данные». Информация о сайтах, в том числе и поисковые полсказки, удаляться и браузер будет работать «как с чистого листа». Однако нужно отметить один момент, что после очистки истории старые сайты первое время будут грузиться долго, так как программа будет заново собирать данные.
Как удалить подсказку в Яндексе?
Подсказки вызывают больше доверия. Что отображается в них, то и популярнокрутополезнохорошоправдиво – так думают юзеры. Но бывает так, что в подсказках отображается нежелательный, оскорбительный, порочащий репутацию запрос. Digital Sharks расскажет, как удалить подсказку в Яндексе.
Подсказки – что это?
Наверняка есть те, кто не в курсе, что собой представляют подсказки в Яндексе. И для простоты восприятия следующих советов объясним.
В Яндекс-подсказках отображаются те запросы, которые наиболее популярны и соответствуют вашему запросу по словамбуквам. Подсказки не статичны – если вы введете больше букв, чем ранее, то и список подсказок изменится. Так же и с контекстом – если поменяется он, то и подсказки тоже.
В подсказках может быть всё что угодно (что не нарушает правила), ведь список формируется исходя из запросов пользователей. Проще говоря, если бы вы ввели «как пок» и при этом запрос «как покушать вверх ногами» был бы популярнее остальных, то вы бы могли узнать о новом варианте приема пищи. И это даже если бы вы искали совершенно другое.
Отметим, что в Яндекс-подсказках содержатся не только популярные и соответствующие запросы. Могут отображаться готовые ответы, если вы задаете вопрос. Или ссылка на сайт, который вы ищете.
Яндекс отметил, что при формировании и ранжировании списка подсказок может учитываться местоположение. Еще могут браться во внимане интересы пользователя, который что-то ищет. Да, по их словам, эти факторы лишь могут учитываться. Это важный момент для тех, кто хочет продвигать свой бренд через подсказки.
Яндекс-подсказки в мобильном браузере
Прежде чем перейти к советам, как удалить подсказку в Яндексе, расскажем и о мобильном поисковике. Здесь они отображаются по другому принципу. Если, например, установить виджет поисковой строки Яндекса, то в поле ввода отобразится запрос, который волнует юзеров больше всего. Если такого нет, включите функцию показа актуального запроса в настройках.
Важный момент – актуальный запрос в мобильном браузере обновляется каждый час. Поэтому если вы решите продвигать бренд через подсказки, вам нужно либо вируситься каждый час, либо генерировать что-то бесподобное и востребованное, тоже – каждый час. Повторим, так только в телефонах. Теперь к более волнующему.
Теперь к более волнующему.
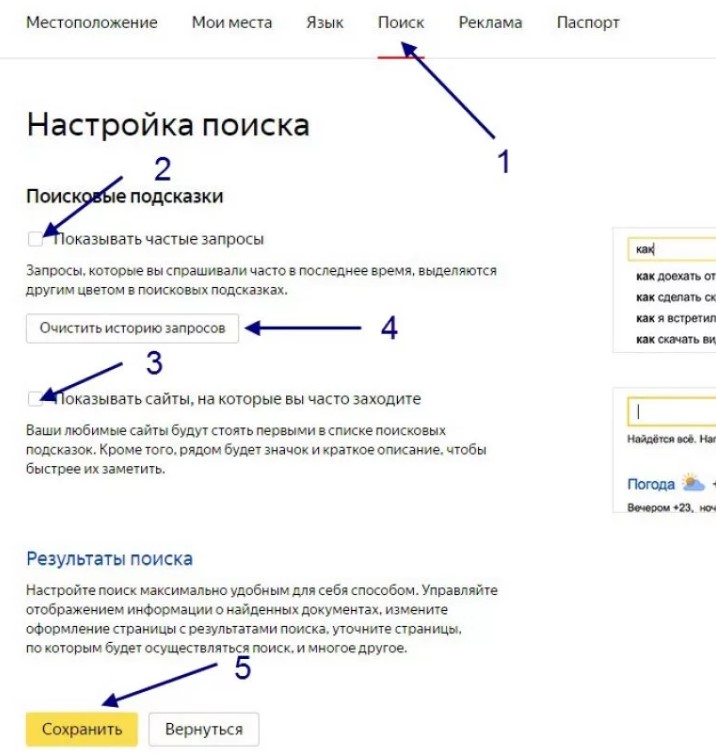
Как удалить подсказку в Яндексе
Если вы обычный юзер, которого просто раздражает какая-то подсказка, то:
- На сайте Яндекса вверху кликайте на «настройки», там выберите графу «поиск».
- Будет предложено 2 варианта: «отображать частые запросы» и «показывать сайты, которые вы посещаете». Первый пункт подразумевает запросы, по которым вы часто переходите. Второй – и так понятно. Выберите в зависимости от того, что вам нужно.
Если вы представитель какой-то фирмы либо медийная личность, а подсказка в Яндексе подрывает репутацию, то может помочь:
Накрутка. Если при вводе соответствующих букв будет отображаться что-то хорошее о вашей компании, то это пойдет вам на благо. Люди воспринимают подсказки как советы от друга, который пытается угадать, что вам нужно. Про продвижение в выдаче знают не все, а про продвижение в подсказках – тем более. Поэтому и доверяют им больше.
В теории, это один из методов, как удалить подсказку в Яндексе. На деле всё сложнее.
На деле всё сложнее.
- Создать страницу на сайте, которая заточена под низкочастотный запрос.
- Вывести ее в топ поисковой выдачи.
- Имитировать интерес, вбивая соответствующий запрос и переходя по нему.
- Вбивать запрос с одного аккаунта – не вариант. Так система с легкостью определит, что это накрутка.
- Даже если вы всё сделаете правильно, со временем алгоритмы поисковой системы определят, что запрос накручен. И исключат его из выдачи.
- Чтобы выполнить все пункты, одного дня не хватит. На это уйдет много времени. Столько, за сколько пользователи увидят нежелательную для вас подсказку.
Рекламная кампания. Случаев, когда через кампанию удавалось продвигать бренд в подсказках, реально мало. Например, кампания МТС «что это» с яйцом – эталон. Люди настолько не понимали и хотели узнать, что это, что такой запрос до сих пор отображается в Яндекс-подсказках:
Минус очевиден: такой интерес стимулировала рекламная кампания. Кампания, на которую нужно много денег и времени.
Кампания, на которую нужно много денег и времени.
Суд. Как удалить подсказку в Яндексе через суд? Наверное, этот метод сложнее остальных. Ведь:
- Вы не сможете просто удалить то, что вам не нравится. Вспомните право на забвение (рассказывали ранее) – здесь примерно такие же условия. Если подсказка портит репутацию, то можете обращаться в суд.
- «Военная коллегия адвокатов» (далее – ВКА) была буквально облита негативом в подсказках. Они обратились в суд, ведь основания были серьезные. Но суд отказал им. Решение суда.
Чтобы вы понимали масштаб проблемы ВКА, вот выдача по их запросу:
Даже не имея нужды обращаться к военным адвокатам, с ВКА даже знакомиться не хочется. А всё из-за выдачи. Фирма наверняка интересовалась, как удалить подсказку в Яндексе, да вот даже судебный орган не помог.
Мы. Наши специалисты помогут:
- Вывести нужные страницы с запросами в топ.
- Вывести запросы в топ подсказок.
- Удалить подсказки в Яндексе, которые портят вам репутацию.

Выше мы отмечали минусы всех способов. Будет честно отметить и наши минусы:
- Сразу, по щелчку убрать ничего не получится. Можете даже не искать, как удалить подсказку в Яндексе за час, день. Учитывая, что подсказки – показатель заинтересованности юзеров, то на удаление может уйти полгода. Нам на удаление требуется от 3 месяцев.
- Эта услуга не бесплатна. Но вы можете бесплатно узнать уDigital Sharks, что о вас думают. Зато теперь вы так же бесплатно узнали, как удалить подсказки в Яндексе.
Как удалить запросы в поисковой Строке Яндекс
Мы рассмотрим как быть при использовании поисковой строки в браузере и для поиска в Яндекс на панели задач Windows.
Чтобы подсказки не всплывали в браузере
Как очистить историю браузера вы можете посмотреть на картинках. Или подробнее найти в интернете, если ваш браузер ниже не представлен.
| Очистка истории посещений в Mozilla FireFox |
| Очистка истории посещений в Google Chrome |
| Очистка истории посещений в Opera |
Можно, также, очищать куки после каждого пользования поиском. В таком случае информация о поисковой истории более не будет связанная с вашим браузером. После очищения кук, подсказки поиска не будут нести никакой информации о вас.
По удалению запросов в Яндекс Строке
Откуда Яндекс.Строка берёт поисковые подсказки?
| Настройки строки поиска |
Есть ещё один вариант. Ждать обновлений и новых доработок.
Ждать обновлений и новых доработок.
Был ли материал полезен вам?
Вопросы, замечания, возражения оставляйте в комментариях.
Как удалить историю запросов в яндексе браузере
Когда ищем какую-нибудь информацию в поисковой системе, мы вводим так называемые запросы и они сохраняются в системе.
Так, при повторном поиске, введя повторяющиеся слова мы видим подсказки, уже знакомые введенные ранее выражения. Однако, такой функционал не всегда нужен и может мешать пользователю. Как его отключить, рассмотрим ниже.
Возможно два варианта:
- История сохраняется в самом браузере, поэтому первый пункт будет — удаление из браузера.
- Удаление из аккаунта yandex.
Удаление из браузера yandex
Поисковая система Yandex, вместе с браузером запоминает историю запросов. При этом совершенно неважно зашел ли пользователь в свой аккаунт в яндексе. Это можно наблюдать введя в поисковой строке ранее знакомое слово или фразу.
Как видно из скриншота выше, прошлые запросы показываются в фиолетовым цвете.
Чтобы быстро убрать один или несколько вариантов, достаточно нажать на крестик рядом с фразой.
Данная манипуляция позволяет избавится от собственных запросов. Стоит отметить, что вся активность в веб-обозревателе сохраняется. Если нужно стереть следы пребывания на сайте, необходимо очистить историю.
Рассмотрим на примере Я.Браузера:
- Нажимаем на кнопку меню три полоски, затем выбираем «Настройки».
- В разделе Системные, кликнуть на «Очистить историю».
- В дополнительном окне выбираем за какой промежуток времени требуется удалить активность.
- Ставим галочки просмотры, загрузки, данные автозаполнения форм, файлы сохраненные в кэше, файлы cookie.
- Нажимаем на кнопку очистить.
Удаляем через аккаунт яндекса
Если имеется учетная запись в Яндексе, можно перейти в профиль и очистит данные, которые отображаются в поисковой строке в виде подсказки. Кроме того, систему можно настроить таким образом, чтобы новые запросы из поисковой строке больше не сохранялись.
Кроме того, систему можно настроить таким образом, чтобы новые запросы из поисковой строке больше не сохранялись.
Выполним удаление через аккаунт:
- Заходим на главную страницу yandex, затем нажимаем справа «войти в почту.»
- Кликаем войти.
- Далее вводим логин и пароль от учетной записи в системе Яндекс.
- После входа в учетную запись, наверху справа кликаем по названию аккаунта, затем выбираем «Управление аккаунтом».
- Еще раз наверху нажимаем на название учетной записи, выбираем настройки.
- Выбираем раздел «Поиск». Как раз в этом разделе самое интересное.
- Первом делом необходимо нажать на кнопку «Очистить историю запросов». Дальше уже по желаю можно снять птичку «Показывать историю поисков».
Как удалить подсказку в Яндексе?
Подсказки вызывают больше доверия. Что отображается в них, то и популярно\круто\полезно\хорошо\правдиво – так думают юзеры. Но бывает так, что в подсказках отображается нежелательный, оскорбительный, порочащий репутацию запрос. Digital Sharks расскажет, как удалить подсказку в Яндексе.
Digital Sharks расскажет, как удалить подсказку в Яндексе.
Подсказки – что это?
Наверняка есть те, кто не в курсе, что собой представляют подсказки в Яндексе. И для простоты восприятия следующих советов объясним.
В Яндекс-подсказках отображаются те запросы, которые наиболее популярны и соответствуют вашему запросу по словам\буквам. Подсказки не статичны – если вы введете больше букв, чем ранее, то и список подсказок изменится. Так же и с контекстом – если поменяется он, то и подсказки тоже.
В подсказках может быть всё что угодно (что не нарушает правила), ведь список формируется исходя из запросов пользователей. Проще говоря, если бы вы ввели «как пок» и при этом запрос «как покушать вверх ногами» был бы популярнее остальных, то вы бы могли узнать о новом варианте приема пищи. И это даже если бы вы искали совершенно другое.
Отметим, что в Яндекс-подсказках содержатся не только популярные и соответствующие запросы. Могут отображаться готовые ответы, если вы задаете вопрос. Или ссылка на сайт, который вы ищете.
Или ссылка на сайт, который вы ищете.
Яндекс отметил, что при формировании и ранжировании списка подсказок может учитываться местоположение. Еще могут браться во внимане интересы пользователя, который что-то ищет. Да, по их словам, эти факторы лишь могут учитываться. Это важный момент для тех, кто хочет продвигать свой бренд через подсказки.
Яндекс-подсказки в мобильном браузере
Прежде чем перейти к советам, как удалить подсказку в Яндексе, расскажем и о мобильном поисковике. Здесь они отображаются по другому принципу. Если, например, установить виджет поисковой строки Яндекса, то в поле ввода отобразится запрос, который волнует юзеров больше всего. Если такого нет, включите функцию показа актуального запроса в настройках.
Важный момент – актуальный запрос в мобильном браузере обновляется каждый час. Поэтому если вы решите продвигать бренд через подсказки, вам нужно либо вируситься каждый час, либо генерировать что-то бесподобное и востребованное, тоже – каждый час. Повторим, так только в телефонах.Теперь к более волнующему.
Повторим, так только в телефонах.Теперь к более волнующему.
Как удалить подсказку в Яндексе
Если вы обычный юзер, которого просто раздражает какая-то подсказка, то:
- На сайте Яндекса вверху кликайте на «настройки», там выберите графу «поиск».
- Будет предложено 2 варианта: «отображать частые запросы» и «показывать сайты, которые вы посещаете». Первый пункт подразумевает запросы, по которым вы часто переходите. Второй – и так понятно. Выберите в зависимости от того, что вам нужно.
Если вы представитель какой-то фирмы либо медийная личность, а подсказка в Яндексе подрывает репутацию, то может помочь:
- накрутка;
- рекламная кампания;
- суд;
- мы.
Накрутка. Если при вводе соответствующих букв будет отображаться что-то хорошее о вашей компании, то это пойдет вам на благо. Люди воспринимают подсказки как советы от друга, который пытается угадать, что вам нужно. Про продвижение в выдаче знают не все, а про продвижение в подсказках – тем более. Поэтому и доверяют им больше.
Поэтому и доверяют им больше.
В теории, это один из методов, как удалить подсказку в Яндексе. На деле всё сложнее.
Вам нужно:
- Создать страницу на сайте, которая заточена под низкочастотный запрос.
- Вывести ее в топ поисковой выдачи.
- Имитировать интерес, вбивая соответствующий запрос и переходя по нему.
Минусов много:
- Вбивать запрос с одного аккаунта – не вариант. Так система с легкостью определит, что это накрутка.
- Даже если вы всё сделаете правильно, со временем алгоритмы поисковой системы определят, что запрос накручен. И исключат его из выдачи.
- Чтобы выполнить все пункты, одного дня не хватит. На это уйдет много времени. Столько, за сколько пользователи увидят нежелательную для вас подсказку.
Рекламная кампания. Случаев, когда через кампанию удавалось продвигать бренд в подсказках, реально мало. Например, кампания МТС «что это» с яйцом – эталон. Люди настолько не понимали и хотели узнать, что это, что такой запрос до сих пор отображается в Яндекс-подсказках:
Минус очевиден: такой интерес стимулировала рекламная кампания. Кампания, на которую нужно много денег и времени.
Кампания, на которую нужно много денег и времени.
Суд. Как удалить подсказку в Яндексе через суд? Наверное, этот метод сложнее остальных. Ведь:
- Вы не сможете просто удалить то, что вам не нравится. Вспомните право на забвение (рассказывали ранее) – здесь примерно такие же условия. Если подсказка портит репутацию, то можете обращаться в суд.
- «Военная коллегия адвокатов» (далее – ВКА) была буквально облита негативом в подсказках. Они обратились в суд, ведь основания были серьезные. Но суд отказал им. Решение суда.
Чтобы вы понимали масштаб проблемы ВКА, вот выдача по их запросу:
Даже не имея нужды обращаться к военным адвокатам, с ВКА даже знакомиться не хочется. А всё из-за выдачи. Фирма наверняка интересовалась, как удалить подсказку в Яндексе, да вот даже судебный орган не помог.
Мы. Наши специалисты помогут:
- Вывести нужные страницы с запросами в топ.
- Вывести запросы в топ подсказок.
- Удалить подсказки в Яндексе, которые портят вам репутацию.

Выше мы отмечали минусы всех способов. Будет честно отметить и наши минусы:
- Сразу, по щелчку убрать ничего не получится. Можете даже не искать, как удалить подсказку в Яндексе за час, день. Учитывая, что подсказки – показатель заинтересованности юзеров, то на удаление может уйти полгода. Нам на удаление требуется от 3 месяцев.
- Эта услуга не бесплатна. Но вы можете бесплатно узнать уDigital Sharks, что о вас думают. Зато теперь вы так же бесплатно узнали, как удалить подсказки в Яндексе.
С минусами, зато честно.
Сделайте Google основной поисковой системой – Google
Your shiny new Windows 8 operating system has tiles and apps on a Start Screen, and
it has the original desktop that looks like the Windows you’re used to.
To make Google your default search engine, you just need to switch from apps to the desktop.
Here two options to help you switch to the desktop:
- The quick way: If you see a black bar at the bottom of the screen saying “The site www.google.com uses add-ons that require Internet Explorer on the desktop”, click the blue Open button to switch to desktop mode.
- You can also get to the desktop manually. First, make the URL bar show by hovering at the bottom of the page, or by swiping from the bottom on a touch screen. Then click on the white wrench icon and select “View on Desktop.”
Now the button to make Google your search provider should work. Aww yeah.
Выберите первый вариант
Нажмите «Добавить»
Выберите первый вариант
Нажмите «Да»
Готово?
Войдите в аккаунт и пользуйтесь поиском.
Войти в Google
Выберите первый вариант
Нажмите «Добавить»
Готово?
Войдите в аккаунт и пользуйтесь поиском.
Войти в Google
Google Поиск установлен, но не сделан поиском по умолчанию. Чтобы сделать Google поиском по умолчанию, выполните следующие действия:
- Нажмите на значок инструментов в правой верхней части окна
браузера.
- Выберите пункт Свойства обозревателя.
- В разделе Поиск вкладки Общие нажмите Параметры.
- Выберите Google.
- Нажмите По умолчанию и Закрыть.

Шаг 1. Откройте «Свойства обозревателя»
Выберите Сервис в меню в верхней части окна браузера.
Затем выберите Свойства обозревателя.
Шаг 2. Сделайте Google стартовой страницей
В верхнем разделе Домашняя страница удалите текст в поле Адрес. Затем
введите в этом поле www.google.ru.
Затем
введите в этом поле www.google.ru.
Шаг 3. Сохраните изменения
Нажмите ОК, чтобы сохранить изменения.
Шаг 1. Откройте настройки браузера
Нажмите на значок настроек в правом верхнем углу и выберите Настройки.
Откроется новая вкладка.
Шаг 2. Сделайте Google поиском по умолчанию
В разделе «Поиск» в раскрывающемся меню выберите Google.
Шаг 3.
 Сделайте Google стартовой страницей
Сделайте Google стартовой страницей В разделе «Внешний вид» установите флажок Показывать кнопку «Главная
страница».
Чтобы настроить стартовую страницу, нажмите Изменить.
Выберите Следующая страница:, затем введите в поле www.google.ru.
Нажмите ОК.
Закройте вкладку настроек. Изменения будут сохранены автоматически.
Подробнее…
Шаг 1. Откройте настройки браузера
Нажмите на значок настроек в правом верхнем углу и выберите Настройки.
Откроется новая вкладка.
Шаг 2.
 Сделайте Google поиском по умолчанию
Сделайте Google поиском по умолчаниюВ разделе «Поиск» в раскрывающемся меню выберите Google.
Шаг 3. Сделайте Google стартовой страницей
В разделе «Внешний вид» установите флажок Показывать кнопку «Главная
страница».
Чтобы настроить стартовую страницу, нажмите Изменить.
Выберите Следующая страница:, затем введите в поле www.google.ru.
Нажмите ОК.
Закройте вкладку настроек. Изменения будут сохранены автоматически.
Подробнее…
Сделайте Google поиском по умолчанию
Нажмите стрелку вниз в левой части окна поиска.
Выберите Google в раскрывающемся меню.
Ещё: сделайте Google стартовой страницей
С помощью мыши перетащите значок Google синего цвета, показанный ниже, на значок домашней страницы, расположенный в правом верхнем углу вашего браузера.
Затем во всплывающем окне нажмите Да.
…или измените стартовую страницу вручную
В левом верхнем углу нажмите Firefox, выберите Настройки и нажмите Настройки в меню справа.
В верхнем меню нажмите кнопку Основные со значком выключателя.
В раскрывающемся меню При запуске Firefox выберите Показать домашнюю
страницу.
В поле Домашняя страница введите www.google.ru и нажмите ОК, чтобы сохранить изменения.
Подробнее…
Шаг 1. Сделайте Google поиском по умолчанию
Нажмите стрелку вниз в левой части окна поиска.
Выберите Google в раскрывающемся меню.
Ещё: сделайте Google стартовой страницей
С помощью мыши перетащите значок Google синего цвета, показанный ниже, на значок домашней страницы, расположенный в правом верхнем углу вашего браузера.
Затем во всплывающем окне нажмите Да.
…или измените стартовую страницу вручную
Выберите Firefox в меню, а затем нажмите Настройки.
Введите www.google.ru в поле Домашняя страница и закройте окно
настроек, чтобы сохранить изменения.
Подробнее…
Шаг 1. Откройте настройки браузера
Нажмите Safari в меню Apple и выберите Настройки.
Шаг 2. Сделайте Google поиском по умолчанию
В раскрывающемся меню Основная поисковая машина выберите Google.
Шаг 3. Сделайте Google стартовой страницей
В раскрывающемся меню В новых окнах открывать выберите вариант Домашнюю
страницу. Откройте следующее раскрывающееся меню и выберите вариант Домашнюю
страницу, чтобы ваша стартовая страница открывалась в новых вкладках.
Откройте следующее раскрывающееся меню и выберите вариант Домашнюю
страницу, чтобы ваша стартовая страница открывалась в новых вкладках.
Затем в поле Домашняя страница введите www.google.ru.
Изменения будут сохранены автоматически.
Подробнее…
Шаг 1. Откройте настройки браузера
Нажмите Opera в верхнем меню и выберите пункт Настройки, а затем Общие настройки.
Шаг 2. Измените настройки поиска
Нажмите кнопку Поиск в верхней части окна «Настройки».
Выберите из списка Google, а затем нажмите кнопку Изменить. .. справа.
.. справа.
Шаг 3. Сделайте Google поиском по умолчанию
Нажмите кнопку Подробнее и установите флажки Использовать как службу
поиска по умолчанию и Использовать как поиск Экспресс-панели.
Нажмите кнопку ОК, а затем нажмите кнопку ОК в окне настроек, чтобы
сохранить изменения.
Видите значок Google в правом верхнем углу? Получилось!
Измените настройки или параметры, чтобы сделать Google поиском по умолчанию
К сожалению, мы не можем определить браузер, чтобы показать нужные инструкции.
Попробуйте нажать название вашего браузера в главном меню, а затем выбрать Предпочтения, Настройки или Параметры. Если в главном меню есть
пункт Сервис, нажмите на него и выберите Свойства обозревателя.
Если в главном меню есть
пункт Сервис, нажмите на него и выберите Свойства обозревателя.
Наш совет: загрузите Google Chrome, быстрый и бесплатный браузер. Google Chrome молниеносно открывает веб-страницы и приложения.
Теперь вы можете искать в Google, находясь на любом сайте.
Удобный доступ к Google Поиску
Удобный доступ к Google Поиску с любого сайта. Просто введите запрос в адресной строке.
Персональные подсказки
Войдите в аккаунт Google и получайте персональные подсказки на любых устройствах.
Нажмите Открыть, перейдите в режим рабочего стола и добавьте Google в
настройках браузера.
как попасть в поисковую строку
Как работают поисковые подсказки в поисковых системах, знает любой из нас. Масса вариантов ещё не законченной фразы мгновенно появляется ниже строки поиска на Яндексе или Google. Пользователю остаётся лишь выбрать подходящий вариант.
Пример подсказки в Яндексе
Подсказка в ЯндексеПлюсы системы подсказок для обывателя:
- экономия времени;
- автоматическое исправление ошибок в случае неточного набора;
- умение подстраиваться под вкусы потребителя: показ названий сайтов, которыми чаще всего пользуются с устройства. При этом в настройках браузера очень легко удалить те, которые больше не хочется видеть.
Впрочем, положительные моменты системы подсказок активно используют не только простые пользователи ПК, но и веб-мастера. Они стали использовать алгоритм для продвижения сайтов.
Плюсы для SEO-оптимизаторов:
- попадание названия продвигаемой услуги, товара в поисковые запросы резко увеличивает трафик сайта;
- к бренду, вылетающему под вводом, у потребителей повышается лояльность. Будущие покупатели уверены, что видят самые популярные запросы, а следовательно, фирма является лучшей на рынке.
 Будущие покупатели уверены, что видят самые популярные запросы, а следовательно, фирма является лучшей на рынке.
Будущие покупатели уверены, что видят самые популярные запросы, а следовательно, фирма является лучшей на рынке.Что нужно сделать, чтобы попасть в поисковые подсказки Яндекса или Google? Поверьте, это не так просто, но при большом желании и определённых стараниях очень даже возможно. А для начала ознакомимся со структурой этого сервиса.
Правила создания подсказок
При создании подсказки в Яндексе основное значение имеют такие аспекты: данные о регионе и языке, персонализация, фильтры.
Язык и регион
Очевидно, что подсказки в различных языковых регионах будут отличаться. Язык, указанный в настройках поисковика, определяет семантику запросов. Кроме того, оба поисковика, Google и Яндекс, находят наиболее востребованные запросы для каждой местности и выводят их под строку ввода. Поэтому при наборе запроса «купить» в Москве или Астрахани продолжение будет разным.
Пример подсказки в Google
Подсказка в GoogleПерсонализация
Существенным влиянием на формирование пользовательского алгоритма подсказок обладает использование функций Web History (Google) и «Мои находки» (Яндекс). Наиболее частые запросы с устройства выделяются в подсказках другим цветом, сигнализируя о предпочтениях владельца устройства.
Наиболее частые запросы с устройства выделяются в подсказках другим цветом, сигнализируя о предпочтениях владельца устройства.
Фильтры
Все запросы пользователей автоматически отфильтровываются системой, удаляется нецензурная брань, исправляются неточности, отсеиваются редкие запросы. Пользователю предоставляется выборка из более 20 миллионов запросов, которые делятся на группы по семантике (значению) слов, объединяясь в схожие по смыслу выражения, например «печать», «печать на футболках», «печать на кружках».
Поисковые подсказки по слову «печать»
Подсказки по запросу «печать»Автоматический алгоритм сортировки подсказок учитывает общие свойства контента сайтов, соцсетей, пользовательский выбор и «свежесть» запроса.
Свойства контента
В сети широко известна история индийского блогера-экспериментатора Риши Сакхани, который сформировал два похожих запроса в Twitter и попросил своих фолловеров их запостить. В результате фраза «Rishi Sakhani ROFL» попала в подсказки Google, а вторая — «Rishi Sakhani ha ha ha» — оказалась в группе связанных запросов, но в подсказки не попала. Отсюда вывод, что поисковик учитывает не только количество прямых запросов в поисковой строке, но и насколько часто подобное сочетание встречается внутри контента определённого сайта.
Отсюда вывод, что поисковик учитывает не только количество прямых запросов в поисковой строке, но и насколько часто подобное сочетание встречается внутри контента определённого сайта.
Релевантность, или степень соответствия нуждам пользователя
Персонализация запросов происходит благодаря умению браузера сохранять данные о посещаемых сайтах. Поисковики определяют ценность подсказки для каждого владельца устройства, исходя из личной истории запросов.
Популярность
«Свежесть» запроса учитывается Google, она предлагает пользователю обратить внимание на подсказки, имеющие высокую востребованность в поисковике на данный момент. При падении интереса популярное сочетание удаляется.
В Яндексе обновление подсказок производится раз в сутки, теряющие ценность автоматически убираются системой. Кроме того, в поисковике существуют так называемые «быстрые подсказки», которые формируются на основании многочисленных запросов пользователей каждые полчаса по материалам новых статей, конверсии постов в соцсетях и т. д.
д.
Какие подсказки удаляются
Политика поисковиков в этом случае едина, из общего потока с помощью фильтров удаляются материалы, если они:
- содержат порнографические видео и фото;
- призывают к насилию и ненависти;
- по решению суда должны быть изъяты.
Способы накрутки подсказок
Как уже говорилось выше, включить название бренда в подсказки достаточно сложно. Google и Яндекс борются с сеошниками, формируют всё новые алгоритмы ранжирования, чтобы как можно меньше названий фирм, продвигаемых услуг попадало в выдачу поисковиков.
Существует два «чёрных» метода формирования подсказок:
- ручной;
- автоматизированный.
Ручной создаётся с помощью большого числа пользователей, привлечённых к популяризации запроса. Вспомним, как создал подсказку Риши Сакхани. Обычно такой способ применяется, если требуется попасть в подсказки на короткое время. Для веб-мастера при наличии средств актуальным является обращение на биржи, типа eTXT, «Адвего», где с помощью нанятых копирайтеров он сможет вводить в строку поиска нужный запрос. Способ достаточно дорогой, требующий постоянного внимания, потому что:
Способ достаточно дорогой, требующий постоянного внимания, потому что:
- при обнаружении запросов с одинаковых IP подсказки удаляются;
- требуется постоянный подбор всё новых исполнителей, что дороговато;
- при спаде активности популярность подсказки упадёт, и она будет удалена.
Автоматизированная атака на поисковики ведётся с помощью наборов IP-адресов, программных скриптов, прокси-сервера, которые позволят создать имитацию большого количества уникальных пользователей. Способ дёшев, но в рамках продвижения единичного бренда неактуален. Требуется разработка программного обеспечения, специальное оборудование, присутствует возможность разоблачения пиратского ПО специалистами службы поисковика.
Вышеперечисленными методами можно добиться определённых результатов, но и не исключено, что подобная оптимизация интернет-ресурса приведёт к неприятности. Если сайтом займутся сотрудники службы борьбы со спамом, то он потеряет не только подсказки, но и позиции в выдаче, упав в хвост.
Легальные, «белые» методы формирования подсказок
Грамотная реклама товара или услуги помогает достичь популяризации запроса традиционным, безопасным методом. Цепляя обывателя, она вызывает интерес к бренду, название которого пользователь вводит в строку поиска, движимый эмоциональным порывом. Чем чаще запрос появляется в поиске, тем быстрее появляется подсказка с нужным сочетанием слов.
Способы, повышающие частоту пользовательского запроса:
- тизерная реклама, которая красиво представляет проблему (загадку), за ответом к которой обыватель пойдёт на сайт, создавая запрос;
- активная медийная позиция: участие фирмы в выставках, конференциях, спонсорство. Понятный и заметный логотип непременно привлечёт новых людей, которые захотят узнать больше о компании, обращаясь в поиск;
- использование потенциала известных интернет-блогеров, которые могут активно явно или неявно продвигать товар или услугу.
Теги
Вам также будет интересно
Почему результаты поиска в яндексе сворачиваются.
 Как удалить запросы в поисковой строке яндекс. Причины проблем с непроизвольным открыванием Яндекс.Браузера
Как удалить запросы в поисковой строке яндекс. Причины проблем с непроизвольным открыванием Яндекс.БраузераЭто крайне актуальная тема. Многие пользуются Яндекс.Строкой в Windows или формой поиска Яндекс в браузере . По традиции, ответы на популярные запросы и поисковые подсказки отображаются в самом поле ввода в виде живого поиска. Это очень удобно, но… поисковые системы, в том числе Яндекс, собирают информацию о ваших интересах в интернете, затем стараются угадать ваши предпочтения с учётом этих интересов. Т.е. стоит один раз поискать рецепт плюшек в яндексе, и в следующий раз как только вы введёте букву «П», выскочит куча подсказок со словом «плюшка». Это косвенно указывает на вашу прошлую поисковую историю и интересы в сети. Иногда компьютер используется несколькими людьми, и не всегда хочется, чтобы другой человек видел вашу историю поиска. Как удалить запросы в поисковой строке Яндекс, если не желаешь делиться своими интересами с другими людьми читай далее.
Мы рассмотрим как быть при использовании поисковой строки в браузере и для поиска в Яндекс на панели задач Windows .
Чтобы подсказки не всплывали в браузере
Первым делом . Удаляем историю поиска в самом браузере. Это не относится к Яндекс поиску, но, какой смысл скрывать свои прошлые запросы, если в браузере можно легко найти список всех посещённых сайтов.Как очистить историю браузера вы можете посмотреть на картинках. Или подробнее найти в интернете, если ваш браузер ниже не представлен.
| Очистка истории посещений в Mozilla FireFox |
| Очистка истории посещений в Google Chrome |
| Очистка истории посещений в Opera |
Можно, также, очищать куки после каждого пользования поиском .
 В таком случае информация о поисковой истории более не будет связанная с вашим браузером. После очищения кук, подсказки поиска не будут нести никакой информации о вас.
В таком случае информация о поисковой истории более не будет связанная с вашим браузером. После очищения кук, подсказки поиска не будут нести никакой информации о вас.Однако, проще всего настроить «Персональный поиск » таким образом, чтобы подсказки не несли информации о вашей истории поиска.
Алгоритм таков:
По удалению запросов в Яндекс Строке
В Windows 10 Яндекс.Строка располагается на панели задач , по умолчанию. Яндекс.Строка даёт возможность осуществить поисковый запрос в интернет прямо с панели задач без непосредственного запуска браузера. Ещё строка проводит поиск по папкам на вашем компьютере. И может реагировать на голосовые команды. Довольно удобно, и безопасно, если компьютером пользуетесь только вы.
Откуда Яндекс.Строка берёт поисковые подсказки?
Строка черпает информацию из нескольких источников- перечень ссылок по запросу из поиска Яндекс
- ссылки на разделы выбранного сайта
- ответы на популярные запросы Яндекс
- результаты индексации носителей компьютера (HDD, SSD, и т. д.)
 д.)
д.)Если вы ищите сайт, то могли заметить, что в одном браузере сайт на первом месте, во втором — на третьем, где-то его вообще нет в ТОП10.
В этой статье мы расскажем, почему это происходит.
Причин на самом деле несколько, но они делятся на две группы: персональная выдача и не персональная (другими словами, даже в «чистом» браузере анонимного посетителя выдача тоже может быть разной).
Рассмотрим их по очереди.
1. Персональная выдача
Пользуясь поисковой системой, будь то Яндекс или Google? вы можете быть авторизованы в Яндекс.почте или Gmail. Таким образом, система однозначно знакома с посетителем, его историей поиска и предпочтениями. Причём логин пользователя это дополнительная помощь системе, принцип работает даже если вы не авторизованы в сервисе поисковой системы — о вас итак уже известны какие-то данные, если вы не очищали COOKIE и не удаляли свой браузер.
Если какой-либо сайт посещался вами чаще остальных, поисковая система может выдавать его выше остальных результатов. Похожая система есть в «Вконтакте» — в списке друзей по запросу «Александр» выйдет тот Александр, страницу которого вы недавно просматривали. У другого пользователя будет абсолютно другой Александр.
Похожая система есть в «Вконтакте» — в списке друзей по запросу «Александр» выйдет тот Александр, страницу которого вы недавно просматривали. У другого пользователя будет абсолютно другой Александр.
Ниже более подробно описана поисковая платформа от Яндекса — Калининград.
2. Настройки выдачи и регионы
Помимо классических предпочтений, поисковые системы учитывают ряд других факторов:
- Регион поиска, который определился по вашему IP-адресу
Если в Нижнем Новгороде вы на первом месте, то по Москве вас может быть вообще невозможно найти. - Безопасный поиск
Если безопасный поиск включен, то некоторые из сайтов могут исчезнуть из выдачи — а это тоже влияет на результаты - Количество результатов на страницу.
Некоторые настраивают Яндекс так, чтобы просматривать не 10 результатов на странице, а 50. Это также влияет на результаты выдачи.
Всё это сильно влияет на результаты поиска. Однако даже на чистых системах с настройками по умолчанию выдача также может быть разной. Вот причины этого:
Вот причины этого:
3. Эксперименты Яндекса
Есть информация о том, что Яндекс регулярно проводит эксперименты с целью улучшить качество поиска и сделать Директ (контекстная реклама Яндекса) более выгодным. Регулярно в один и тот же момент времени проводится 5-10 экспериментов, каждый из которых затрагивает примерно 4% аудитории. Пользователи для экспериментов выбираются либо регионально (допустим, Москва), либо в случайном порядке.
На одном компьютере сайт на 5-м месте, а на втором можно случайно нарваться на эксперимент.
Эксперименты могут быть следующими, например:
- Понизить в позициях интересный сайт для того, чтобы повысить кликабельность рекламы
- Активировать новый алгоритм
- Активировать новый дизайн (например, прямо сейчас ряд людей видят новый дизайн Яндекса — острова).
- Показать или скрыть информационные результаты (например, Википедия)
Экспериментировать на небольших фрагментах аудитории ради улучшения качества поиска — благое дело. Однако результаты выдачи — разные.
Однако результаты выдачи — разные.
4. Конкуренты из контекстной рекламы
Все поисковые системы существуют за счёт заработка с контекстной рекламы. Это — их основной хлеб. Понятное дело, что чем больше этого хлеба — тем лучше.
Поисковые системы могут понизить в позициях сайт, который конкурирует с контекстной рекламой. Допустим, на одном компьютере вы на 5-й позиции.
Открываете второй компьютер — бац, кто-то подал объявление в рекламу (или настала очередь показать объявление). Всё, сайт занижен в позициях. Или наоборот, занижены позиции одного из ваших конкурентов по выдаче, или наоборот, объявление пропало — позиции выросли.
Как результат — даже на чистой системе и чистом анонимном браузере выдача может отличаться.
5. Внутренняя архитектура поисковой системы
Яндекс использует систему Apache Hadoop. Поиск требует множество ресурсов, и один-два сервера (родительские) хранят информацию, которая растекается по сотням остальных компьютеров. Таким образом, все пользователи поиска подключаются к машинам которые и осуществляют поиск. Все обновления индекса постоянно «заливаются» на эти машины. Если кто-то зашёл на машину, в которой устаревшие данные, или слишком новые, то результаты поиска будут устаревшие или новые. Другой посетитель, который волей случая был подключён к другой машине — получит другие данные. И опять даже на чистой системе и чистом анонимном браузере выдача может отличаться.
Все обновления индекса постоянно «заливаются» на эти машины. Если кто-то зашёл на машину, в которой устаревшие данные, или слишком новые, то результаты поиска будут устаревшие или новые. Другой посетитель, который волей случая был подключён к другой машине — получит другие данные. И опять даже на чистой системе и чистом анонимном браузере выдача может отличаться.
6. Быстрый индекс и новости
Поисковые системы используют несколько индексов. Первый, большой и неповоротливых, содержит данные по подавляющему числу страницы сети. Быстрый индекс в свою очередь содержит последние новости (часы, минуты, секунды). Это сообщения из блогов, твиттера, горячие новости. Такая новость может появиться в любой момент, и при просмотре во втором браузере она может сдвинуть результаты поиска, либо исчезнуть как устаревшая.
Немного информации про Калининград (поисковая платформа Яндекса)
Ее предназначение − персонализировать поисковые подсказки и результаты выдачи.
Главная цель, которую поставили перед собой специалисты Yandex, − предоставить пользователям правильные, построенные под них ответы по неоднозначным запросам. Если человек впервые прибегает к услугам поисковой системы, ему будет показана неоптимальная выдача. Зато людям, которые уже несколько раз воспользовались поиском, Яндекс предложит персонализированный результат, который будет составлен с учетом его истории поведения.
Если человек впервые прибегает к услугам поисковой системы, ему будет показана неоптимальная выдача. Зато людям, которые уже несколько раз воспользовались поиском, Яндекс предложит персонализированный результат, который будет составлен с учетом его истории поведения.
Поисковая платформа Калининград работает для всех пользователей, про которых удается собрать информацию. Адаптивный механизм включается, как только становится достаточно данных. Информация проверяется раз в сутки. Чтобы начать получать персональную выдачу, достаточно 20 кликов и около десятка запросов.
Чтобы измерить персонализацию ранжирования, используют пользовательские метрики. В расчет берется кликабельность первых позиций, количество ответов, по которым не было переходов. Андрей Стрелковский, ответственный за разработку системы ранжирования Яндекса, говорит, что результаты персонализируются более чем в половине случаев. В среднем по 75 % запросов пользователей ТОП-10 сайтов изменяется благодаря данному алгоритму. В день их количество составляет 114 млн запросов.
В день их количество составляет 114 млн запросов.
В прошлом году список поисковых подсказок мало чем отличался для разных пользователей. Фактически, учитывались только страна и город проживания. Первым шагом в персонализации подсказок стало добавление в список запросов тех, которые были недавно заданы пользователем (они выделяются фиолетовым цветом). Теперь пользователям будут демонстрироваться индивидуальные поисковые подсказки в соответствии с интересами каждого человека.
Персональный поиск подключается по умолчанию для всех пользователей, которые достаточно часто обращаются к Яндексу. Очевидно, что чем больше вопросов задает человек, тем лучше поисковая система будет его понимать. Если переходов по найденным ответам немного, то персональный поиск отключается. Как только пользователь снова начинает задавать большое количество вопросов, система включается вновь. Конечно же, персональный поиск можно в любой момент отключить через настройки.
Что представляет собой Калининград?Поисковая платформа Калининград включает ряд продуктов, которые являются частью персонального поиска. Итак, сюда входят:
Итак, сюда входят:
- Персональная выборка. Yandex предложит пользователю только те ответы, которые ему подходят. С этой целью применяется формула ранжирования. Она учитывает язык общения − пока что только русский или английский (поисковая платформа Рейкьявик), а также историю поиска.
- Персональные подсказки. В поисковой строке пользователь увидит среди подсказок те запросы, которые вводили люди со схожими интересами. По словам разработчиков, выделено 400 тысяч групп пользователей, которых интересуют одни и те же темы.
- Сиреневые подсказки. Как свидетельствует статистика, пользователи повторяют около 24 % своих запросов. Именно поэтому Яндекс добавляет в подсказки те фразы, которые пользователь вводил в последнее время. Такие подсказки подсвечиваются сиреневым цветом. С их помощью пользователь может мгновенно повторить запрос, введенный ранее.
- Любимые сайты в подсказках. Очень часто пользователи при помощи поисковиков ищут ресурсы, URL которых не могут вспомнить. Теперь Яндекс запоминает сайты, на которые пользователи переходят из результатов поиска, и включает их в подсказки. Как утверждают представители поисковика, ежедневно пользователи 3,3 млн раз кликают на персональные навигационные подсказки. Каждую неделю эту функцию использует 18 млн человек.
- Мгновенные подсказки. Яндекс не только учитывает поисковую историю, но и анализирует запросы, которые характерны для определенной поисковой сессии. После введения очередного вопроса поисковая система определяет, что еще может интересовать пользователя по данной теме, и добавляет подходящие варианты в набор подсказок. Каждый день Yandex предлагает подобные учитывающие предыдущий запрос подсказки 53 млн раз.
 Теперь Яндекс запоминает сайты, на которые пользователи переходят из результатов поиска, и включает их в подсказки. Как утверждают представители поисковика, ежедневно пользователи 3,3 млн раз кликают на персональные навигационные подсказки. Каждую неделю эту функцию использует 18 млн человек.
Теперь Яндекс запоминает сайты, на которые пользователи переходят из результатов поиска, и включает их в подсказки. Как утверждают представители поисковика, ежедневно пользователи 3,3 млн раз кликают на персональные навигационные подсказки. Каждую неделю эту функцию использует 18 млн человек.Персональный поиск позволит пользователю сэкономить до 14 % времени. В неделю это составит около 8 минут. Вполне достаточно, чтобы выпить чашечку чая или позвонить друзьям.
15.03.2017
Не всегда использование интернета может быть безопасным. Скачав или открыв сомнительные файлы, можно получить различные вирусы и массу рекламы, что может не только мешать корректной работе компьютера, но и способно украсть ваши данные. Реклама, небезопасные поисковики и сайты — одна из самых распространенных проблем, с которой сталкиваются пользователи.
Реклама, небезопасные поисковики и сайты — одна из самых распространенных проблем, с которой сталкиваются пользователи.
Причины проблем с непроизвольным открыванием Яндекс.Браузера
Чаще всего браузер не открывается с пустыми вкладками, это могут быть различные стартовые страницы и сайты с рекламой. Также можно заметить подмену рекламы от того же Google на различных сайтах. «Подцепить» такого рода вирусы пользователи могут несколькими способами:
Устранение проблемы
Действие 1: Проверка и исправление файла
«Hosts»Получить доступ к этому файлу, можно только обладая правами администратора. Его можно очень просто исправить и проверить с помощью блокнота. Для этого необходимо:
Действие 2: Уборка лишнего с планировщика заданий
Как раз причиной того, что Яндекс.Браузер открывает окна с рекламой через определенное время, есть планировщик заданий. Чтобы вкладки не открывались, их необходимо отключить в планировщике. Сделать это можно так:
Действие 3: Очистка лишнего с автозагрузки
Провести очистку лишних и вредоносных задач с автозагрузки можно довольно простым способом. Для этого понадобится только программа CCleaner , о которой мы уже писали:
Для этого понадобится только программа CCleaner , о которой мы уже писали:
Действие 4: Удаление вредоносного ПО
В диспетчере задач могут находится активные процессы, которые мешают нормальной работе компьютера и являются вредоносными. Их название может меняться каждый раз и демонстрировать их нет смысла, однако их обнаружение и удаление должно быть обязательным. Сделать все действия можно и без помощи софта, но это будет сложнее и дольше по времени, поэтому лучше воспользоваться удобными бесплатными программами.
Скачайте бесплатную программу Adwcleaner и совершите простую установку. Запустите программу и начните сканирование. После того, как сканирование завершится, просто нажмите кнопку «Очистить» .
Также вы можете воспользоваться еще одной бесплатной программой, чтобы очистить компьютер от вирусов. Скачайте программу Malwarebytes и следуйте простой установке. Бесплатной версии программы сроком на 14 дней вам хватит, чтобы полностью очистить ваш компьютер от вредоносного ПО. Совершите сканирование и после нажмите на «Поместить выбранные объекты в карантин» .
Совершите сканирование и после нажмите на «Поместить выбранные объекты в карантин» .
Действие 5: удаление расширений и изменение домашней страницы
Если на вашем компьютере присутствовали вирусы, которые связаны с браузером, то, скорее всего, у вас поменялась домашняя страница, и установились ненужные расширения. Вернуть все на свои места можно довольно просто:
После этого перезагрузите браузер и пользуйтесь им безопасно, быстро и удобно.
Все пять действий, приведенных в статье, помогут вам досконально очистить компьютер от вредоносных программ, которые заставляют открываться Яндекс.Браузер с различной рекламой. Также своевременное обнаружение вредоносного ПО поможет вам сохранить свои личные данные.
Расскажи друзьям в социальных сетях
комментариев 13
Kait.15
Правильно ли я понимаю, что при открытом браузере, веб-обозреватель начинает автоматически открывать последние посещенные вами веб-страницы? Естественно, в голову сразу приходит вирусная активность, но учитывая, что вы переустанавливали ОС, трудно сказать в чем проблема.
Могу лишь посоветовать выполнить сброс настроек браузера, а затем удалить его с компьютера с помощью программы Revo Uninstaller, а затем выполнить новую установку (обязательно загрузив свежий дистрибутив с официального сайта разработчика). Дополнительно все же проверьте компьютер на наличие вирусов с помощью вашего антивируса или лечащей утилиты Dr.Web CureIt.
 Могу лишь посоветовать выполнить сброс настроек браузера, а затем удалить его с компьютера с помощью программы Revo Uninstaller, а затем выполнить новую установку (обязательно загрузив свежий дистрибутив с официального сайта разработчика). Дополнительно все же проверьте компьютер на наличие вирусов с помощью вашего антивируса или лечащей утилиты Dr.Web CureIt.
Могу лишь посоветовать выполнить сброс настроек браузера, а затем удалить его с компьютера с помощью программы Revo Uninstaller, а затем выполнить новую установку (обязательно загрузив свежий дистрибутив с официального сайта разработчика). Дополнительно все же проверьте компьютер на наличие вирусов с помощью вашего антивируса или лечащей утилиты Dr.Web CureIt.Как быстро вывести новую страницу в ТОП Яндекса и Google — SEO на vc.ru
Чтобы новая страница быстро вошла в топ поисковых систем и надолго там «закрепилась», ее нужно правильно оформить (для пользователя) оптимизировать (для поисковых систем). Это не новость для многих SEO-специалистов и руководителей, но некоторые пренебрегают либо первым, либо вторым пунктом.
{«id»:135313,»url»:»https:\/\/vc. ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»title»:»\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google&title=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.
ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»title»:»\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google&title=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter. com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google&text=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google&text=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.
com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google&text=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google&text=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st. shareUrl=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google&body=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
shareUrl=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0431\u044b\u0441\u0442\u0440\u043e \u0432\u044b\u0432\u0435\u0441\u0442\u0438 \u043d\u043e\u0432\u0443\u044e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432 \u0422\u041e\u041f \u042f\u043d\u0434\u0435\u043a\u0441\u0430 \u0438 Google&body=https:\/\/vc.ru\/seo\/135313-kak-bystro-vyvesti-novuyu-stranicu-v-top-yandeksa-i-google»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
39 039 просмотров
Эта статья как раз разбирает для новых или еще не совсем опытных специалистов, почему так важна связка SEO + usability.
При этом работа должна быть поэтапная:
- Индексация. Поисковые роботы должны увидеть, что страница релевантная и полезная, поэтому нужно оптимизировать страницу под ключевые запросы и поработать над качественными ссылками.
- Поведенческие. Если пользователи зайдут на страницу и тут же закроют, то поисковые роботы отследят это и опустят страницу из-за плохих поведенческих факторов. После этого снова придется работать над страницей и ждать, пока роботы до нее доберутся.
Есть два важных правила:
- Хорошее SEO + плохое юзабилити = трафик без конверсии.
- Плохое SEO + хорошее юзабилити = отсутствие трафика.

Поэтому подходите к оптимизации страницы ответственно! А сейчас пошагово рассмотрим продвижение новой страницы.
Пример: нам нужно было продвинуть услугу срочного фото на документы. Это новая категория, и страницы на сайте не было.
Подбираем запросы правильно
Здесь нам помогут сайты конкурентов и «Яндекс.Вордстат».
1. Конкуренты. Вбиваем в поиск «фото на документы» и открываем 3–5 конкурентов. Смотрим, какие ключи у них прописаны в Title, Description, h2 и в самом тексте.
Конкуренты. Вбиваем в поиск «фото на документы» и открываем 3–5 конкурентов. Смотрим, какие ключи у них прописаны в Title, Description, h2 и в самом тексте.
Ключи конкурентов
Делаем выводы, но не спешим. Возможно, конкуренты не учли другие высокочастотные ключи.
2. «Вордстат». Теперь заходим в «Яндекс.Вордстат», ставим нужный (продвигаемый) регион. В нашем случае — Уфа.
Вводим ключ «фото на документы» и выписываем подходящие запросы:
Ключи в «Яндекс. Вордстат»
Вордстат»
Снимаем частотность
Теперь нужно посмотреть точную частоту. Это можно сделать в Key Collector или в «Яндекс.Вордстат».
В Key Collector забиваем запросы списком и смотрим точную частоту:
Точная частота в Key Collector
Если Key Collector отсутствует, то пользуемся Яндекс.Вордстатом. С помощью знаков кавычек и восклицательного знака смотрим количество показов каждого запроса:
Точная частота в «Яндекс. Вордстате»
Вордстате»
Оставляем только высокочастотные и среднечастотные запросы.
Определяем коммерческость
Посмотреть коммерциализацию запросов можно в Tools Pixel Plus и в выдаче:
{«url»:»https:\/\/booster.osnova.io\/a\/relevant?site=vc»,»place»:»between_entry_blocks»,»site»:»vc»,»settings»:{«modes»:{«externalLink»:{«buttonLabels»:[«\u0423\u0437\u043d\u0430\u0442\u044c»,»\u0427\u0438\u0442\u0430\u0442\u044c»,»\u041d\u0430\u0447\u0430\u0442\u044c»,»\u0417\u0430\u043a\u0430\u0437\u0430\u0442\u044c»,»\u041a\u0443\u043f\u0438\u0442\u044c»,»\u041f\u043e\u043b\u0443\u0447\u0438\u0442\u044c»,»\u0421\u043a\u0430\u0447\u0430\u0442\u044c»,»\u041f\u0435\u0440\u0435\u0439\u0442\u0438″]}},»deviceList»:{«desktop»:»\u0414\u0435\u0441\u043a\u0442\u043e\u043f»,»smartphone»:»\u0421\u043c\u0430\u0440\u0442\u0444\u043e\u043d\u044b»,»tablet»:»\u041f\u043b\u0430\u043d\u0448\u0435\u0442\u044b»}},»isModerator»:false}
В Tools Pixel Plus отправляем все запросы и смотрим на проценты. Если коммерциализации меньше 30%, то запрос информационный — не берем его в семантику. В нашем случае все запросы коммерческие.
Если коммерциализации меньше 30%, то запрос информационный — не берем его в семантику. В нашем случае все запросы коммерческие.
Коммерческость по инструменту от «Пиксель Тулс»
Если доступа к инструментам Pixel Tools нет, то воспользуемся поисковой выдачей. Смотрим каждый запрос отдельно. Если по запросу в поиске выходят коммерческие страницы, то запрос подходит. Если информационные — то нет.
Запрос коммерческий, так как в топе только агрегаторы и коммерческие страницы (пример выдачи «Яндекса»):
Определение коммерциализации выдачи
Также нужно сравнить выдачу в Google, потому что поисковые системы могут выдавать разный результат. Ориентируйтесь на нужную вам ПС.
Ориентируйтесь на нужную вам ПС.
Для продвижения оставляем только высокочастотные и среднечастотные коммерческие запросы. Низкочастотные запросы (или нулевые) не принесут трафика, а информационные не подойдут для продвижения, так как услуга коммерческая.
Но есть исключение. Если вы точно знаете, что сейчас по этому запросу нет показов или частотности, например, только вводится новая услуга или в Россию завозится новый товар — то можете оставить НЧ запросы в семантике.
Готовим контент для страницы
Подумайте сами, что важно увидеть пользователям по продвигаемому запросу и обязательно проанализируйте конкурентов. Просто текст с ключами давно не работает — только если вы умеете перемещаться во времени.
Просто текст с ключами давно не работает — только если вы умеете перемещаться во времени.
Анализируем конкурентов. Вводим в поиске запрос «фото на документы» и анализируем 3–5 конкурентов. Смотрим на содержание самой страницы. Анализируем не только структуру страницы, но и содержание текста.
Что указывают конкуренты на странице? Цены, заявку. А о чем пишут в тексте? О видах фотографий, про преимущества копицентра.
Также можно проанализировать этот запрос среди конкурентов из других городов, чтобы добавить для своей страницы «фишки», которых нет у сайтов конкурентов в вашем регионе.
На основе анализа составляем ТЗ для копирайтера. В ТЗ указываем ключи, дополнительные ключи (LSI-текст) и структуру текста.
Если в структуре страницы есть что-то, что невозможно реализовать базовыми знаниями верстки, то ставим задачу для программиста — например, по внедрению формы заявки или калькулятора расчета стиомсти.
ООО — оптимизируем, оформляем, оцениваем
Не оставляйте ЧПУ и оптимизацию и метатегов на «потом». Оптимизируйте сразу правильно, чтобы не ждать, когда же страница начнет продвигаться.
1. Оптимизируем. Создаем станицу, прописываем ЧПУ — «srochnoe-foto-na-dokumenti». На основе анализа конкурентов прописываем Title и Description, h2-h4, alt у картинок. Везде указываем ключи. Как прописывать Title, мы писали в этой статье.
2. Оформляем. Размещаем текст и остальной контент (фотографии, заявку, цены и т.д.). Обязательно проверьте текст перед размещением! Прочтите его, исправьте грамматические ошибки. Прогоните по сервису «Главред» или «Тургенев», выжмите воду.
3. Оцениваем. Оптимизировать страницу технически правильно — только половина дела. Кроме этого страница должна быть логичной и удобной для пользователя.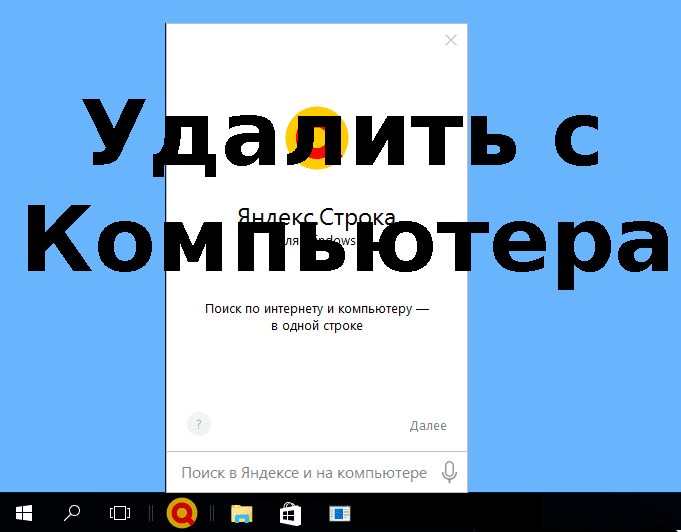 После того, как вы создали и оформили страницу, оцените глазами пользователя.
После того, как вы создали и оформили страницу, оцените глазами пользователя.
Удобно, полезно и все понятно? — Супер!
Или нужно что-то доработать, чего-то не хватает? — Вперед!
А теперь удобно, полезно и все понятно?
Ускоряем индексацию страницы
Итак, вы наконец-то хорошо оптимизировали и оформили страницу. Пора показать страницу поисковикам, пусть тоже заценят.
Пора показать страницу поисковикам, пусть тоже заценят.
Обновляем карту сайта sitemap.xml, чтобы включить в нее новую страницу (если это не делается автоматически).
Показываем страницу Яндексу – в Вебмастере «Индексирование» –> «Переобход страниц». «Индексирование» –> «Проверка статуса URL». И последнее «Информация о сайте» –> «Оригинальные тексты».
индексация в Яндексе
Показываем страницу GoogleBot – в Search Console это «Проверка URL».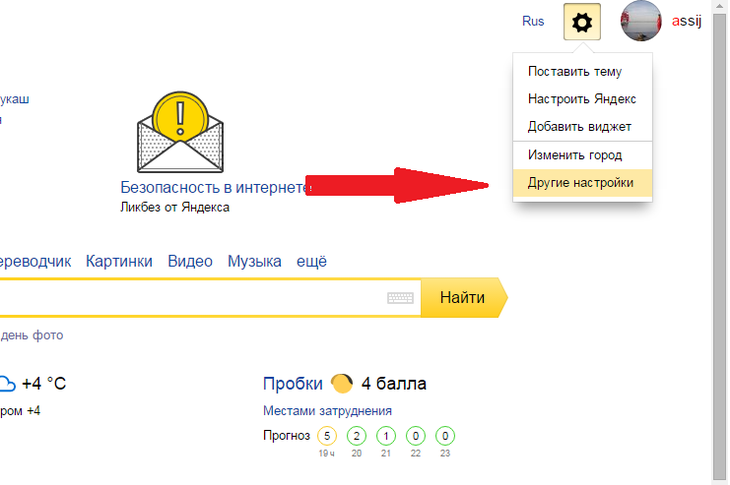 Тут все просто.
Тут все просто.
Индексация в Google
Добавляем запросы в сервис для отслеживания позиций. Мы пользуемся line.pr-cy.ru
После проделанных действий, Яндекс почти проиндексировал страницу. А через 10 дней один запрос уже вошел в ТОП-10.
Позиции в «Яндексе»
В Google запросы поднимались не так быстро. Это доказывает, что для Google важен возраст документа и, разумеется, ссылки, ссылки и ещё раз ссылки.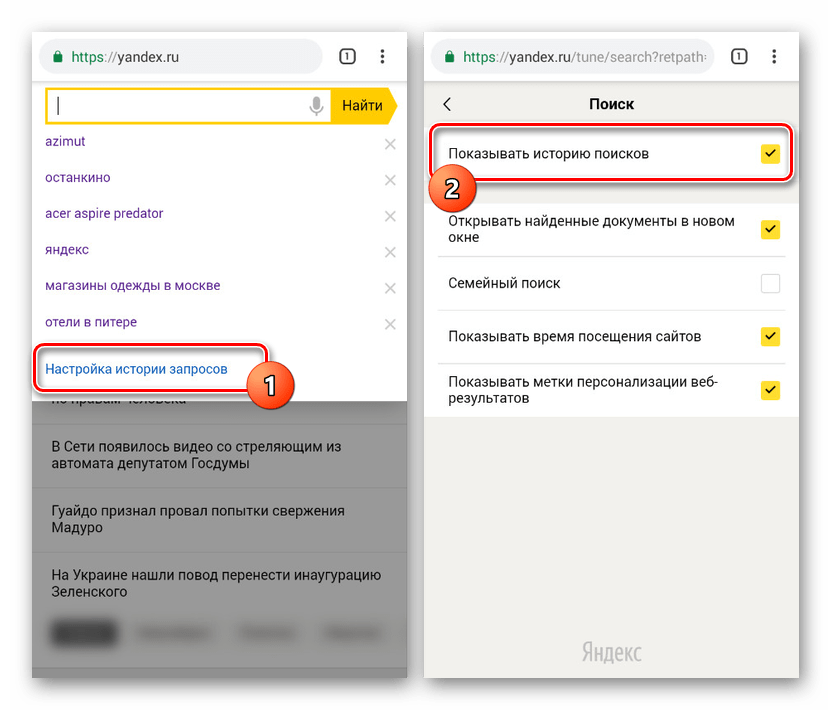
Позиции в Google
Работаем с внутренними ссылками
Так как страница новая, для начала укажем ссылки на нее внутри сайта. Добавляем страницу в меню сайта, в подвал и в дополнительные блоки на страницах для перелинковки.
Внутренние ссылки
Если на сайте ведется блог, то закажите информационную статью и пропишите ссылку на коммерческую страницу.
Работаем с внешними ссылками
Теперь приступаем к анализу ссылочной массы конкурентов с помощью сервисов Ahrefs или MegaIndex. По конкурентам выбираем анкоры, виды и количество ссылок. Если на страницы конкурентов ссылается много ресурсов, то не закупайте массово такое же количество ссылок. Работайте с ссылками постепенно.
Если же у конкурентов 0 ссылок, то все равно сделайте 1-3 ссылки для «затравки» GoogleBot, потому что без этого робот будет долго доходить до вашей страницы. Подробнее про наращивание ссылочной массы читайте в нашей инструкции.
И вот спустя 2 месяца мы добились результатов и в Google! А сейчас занимаем лидирующие позиции в выдаче по Уфе:
Результаты в Google
Помните! Позиции не будут вечно находиться в ТОП-10, ведь алгоритмы меняются, а конкуренты не дремлют.
 Продолжайте отслеживать позиции, анализировать и улучшать страницу.
Продолжайте отслеживать позиции, анализировать и улучшать страницу.Елизавета Григорьева
Ведущий SEO-специалист. Автор статьи
Пример: настройка Tracker для службы поддержки | Яндекс.Облако
Давайте посмотрим, как с помощью Трекера организовать рабочий процесс для службы поддержки.
Tracker — отличный инструмент для управления запросами пользователей, поскольку он позволяет службе поддержки легко общаться с другими отделами, использующими Tracker. Например, вы можете использовать Tracker, чтобы приглашать разработчиков комментировать и вместе решать сложные проблемы, связывать проблемы с другими проблемами, относящимися к запросу пользователя, и так далее.
Давайте создадим специальную очередь Tracker для службы поддержки, чтобы хранить проблемы, созданные на основе запросов пользователей.Теперь давайте настроим дополнительные функции очереди, которые помогут нам более эффективно обрабатывать запросы пользователей:
Создать очередь в службу поддержки
Если в вашей организации еще нет Tracker , активируйте услугу.
Убедитесь, что весь персонал службы поддержки добавлен в вашу организацию и предоставьте им полный доступ к Tracker.
Создайте очередь, используя шаблон Basic support или
Многоуровневой поддержки
.Эти шаблоны уже включают предустановленные типы задач и статусы, которые могут быть полезны для управления запросами пользователей. Шаблон многоуровневой поддержки
включает в себя статусы проблем, такие какЛиния поддержки 1
иЛиния поддержки 2
.Добавьте свой обслуживающий персонал в команду очереди.
При необходимости вы также можете настроить права доступа к задачам в очереди. Например, вы можете разрешить определенным группам пользователей создавать или просматривать проблемы в очереди или запретить им это делать.
Прием заявок по почте и через формы
Пользовательские запросы перед обработкой преобразуются в задачи трекера. Большинство пользователей, как правило, отправляют свои запросы по электронной почте или через веб-сайт. В любом случае пользователи вне вашей организации не имеют доступа к Tracker.
Вот почему мы рекомендуем настроить конвейер обработки запросов таким образом, чтобы вы могли получать запросы по электронной почте или через формы, созданные в Яндекс.Формах.
Прием запросов через формы — лучший выбор, если вы хотите, чтобы пользователи предоставляли определенные данные.Ваши формы могут включать в себя список обязательных и дополнительных вопросов, а ответы могут быть сохранены в параметрах задачи в Tracker.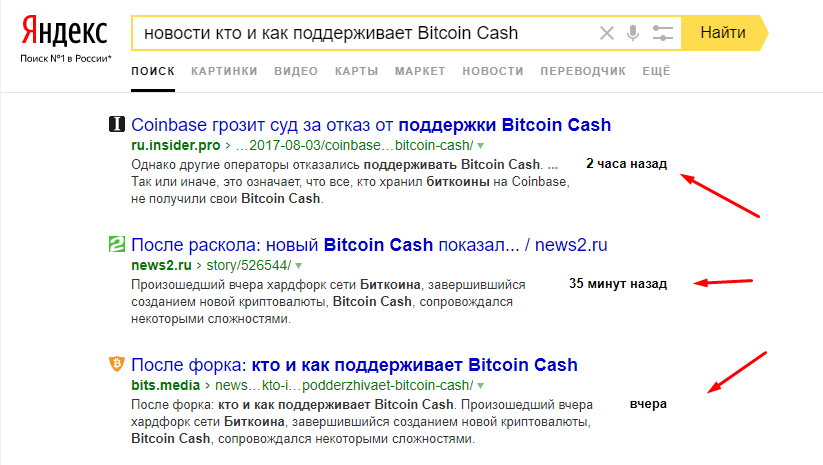
Зайдите в Яндекс.Формы и создайте новую форму.
Добавьте вопросы, которые позволят пользователям предоставить релевантную информацию, необходимую для регистрации своего запроса.
Настроить интеграцию Трекера для форм:
Укажите вашу очередь и другие параметры задачи.
Используйте поле Описание проблемы , чтобы добавить ответы на вопросы, включенные в вашу форму.
Если вы хотите сохранить конкретный ответ в параметрах задачи, добавьте поле задачи, щелкните Переменные → Ответ и выберите соответствующий вопрос.
Сохраните настройки интеграции.
Опубликуйте форму: вставьте ее на веб-сайт или предоставьте ссылку.
Настроить многоуровневую поддержку
Службы поддержки часто используют многоуровневую организацию:
Первая линия поддержки принимает запросы пользователей, собирает соответствующую информацию и решает относительно простые проблемы.
Вторая линия поддержки решает более сложные вопросы.Вторая линия поддержки состоит из квалифицированных специалистов, которые решают сложные технические проблемы.
Иногда может быть организована третья линия поддержки для решения самых сложных вопросов.
 Вторая линия поддержки решает более сложные вопросы.
Вторая линия поддержки решает более сложные вопросы.Вы можете использовать статусы задач Tracker, чтобы распределить проблемы между линиями поддержки и определить, какой линии они назначены. Вы также можете использовать поля проблемы, чтобы указать линии поддержки для каждой проблемы.
Использовать статусы
Каждой линии поддержки можно присвоить отдельный статус проблемы. Например, шаблон многоуровневой поддержки
включает в себя статусы проблем, такие как Линия поддержки 1
и Линия поддержки 2
. Если вам нужно настроить третью линию поддержки, настройте дополнительный статус.
Использовать поля задач
Иногда может быть удобнее создать новое поле проблемы. Допустим, вы получаете запросы пользователей через формы и хотите, чтобы они автоматически распределялись между вашими двумя линиями поддержки в зависимости от темы запроса. Когда вы создаете проблему на основе формы, вы не можете назначить статус проблемы, соответствующий какой-либо из линий поддержки, потому что все новые проблемы автоматически имеют статус
Когда вы создаете проблему на основе формы, вы не можете назначить статус проблемы, соответствующий какой-либо из линий поддержки, потому что все новые проблемы автоматически имеют статус Open
. Однако вы все равно можете присваивать значения полям задач, если у запроса есть конкретная тема. Затем вы можете автоматически изменять статусы задач в зависимости от значения в этом поле проблемы.
Для этого в Трекере:
Шаг 1. Создайте новое поле проблемы
Перейдите в настройки Трекера и создайте новое поле со следующими параметрами:
Тип поля: Раскрывающийся список .
Категория: Система .
Имя:
Строка
. Вы можете указать любое английское имя или ключ проблемы, например Line.Выбор позиции: Отдельная позиция .
Позиции списка: 1, 2 (для двухуровневой поддержки).
Шаг 2.
 Создайте форму запроса
Создайте форму запросаЗайдите в Яндекс.Формы и создайте новую форму.
Добавьте вопросы, которые позволят пользователям предоставить релевантную информацию, необходимую для регистрации своего запроса.
Для распределения запросов между линиями поддержки добавьте раскрывающийся список в форму
Тема запроса
и укажите некоторые общие проблемы.Настроить создание задачи в Tracker Tracker для первой линии поддержки в настройках интеграции:
Настройте [условия уведомления] https://yandex.com/support/connect-forms/common/notifications.html). В списке
Тема запроса
отображаются темы, которые должны обрабатываться первой линией поддержки.Добавьте поле выдачи
Line
и установите значение 1.Если вы хотите назначить проблему сотруднику, ответственному за указанную линию поддержки, укажите его имя пользователя в поле Assignee .
Сохраните настройки интеграции.
Добавьте новую группу уведомлений и аналогичным образом настройте условие создания задачи и параметры задачи для второй линии поддержки.
Сохраните настройки интеграции.
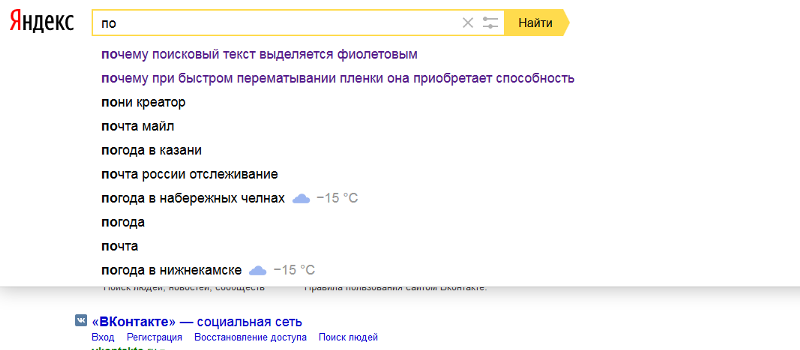
Шаг 3. Настройте условие, запускающее изменение статуса
В очереди службы поддержки создайте два триггера, которые реагируют на изменения в поле Line и обновляют статусы проблем:
Перейдите в настройки очереди, откройте раздел Триггеры и нажмите Создать триггер .
Добавить условие Система → Строка → Значение поля стало равным → 1 .
Добавить действие Изменить статус задачи → Строка поддержки 1 .
Сохраните свой триггер.
Создайте аналогичный триггер для второй линии поддержки.

Проблемы, созданные с помощью формы, теперь будут автоматически распределяться между двумя линиями поддержки в зависимости от их темы.
Группировать запросы по темам
Часто возникает необходимость группировать запросы по определенным параметрам, таким как тип задачи, продукт и т. Д.Это позволяет вам выбирать исполнителей, обладающих необходимыми ноу-хау для каждой конкретной проблемы, а также собирать и анализировать статистику запросов.
Используйте компоненты для группировки проблем по темам:
В очереди группы поддержки создайте компоненты, соответствующие типам запросов.
Вы можете назначить сотрудника ответственным за конкретный компонент и выбрать Назначить для задач по умолчанию , чтобы он автоматически становился уполномоченным по любой проблеме, содержащей компонент, за который они несут ответственность.
Если вы не хотите, чтобы пользователи могли просматривать или редактировать задачи, содержащие определенные компоненты, настройте права доступа для компонентов.
Если вы хотите автоматически выбирать исполнителя после добавления компонента к существующей задаче, настройте триггер, который это сделает.
Использование компонентов в фильтрах позволяет находить проблемы по темам или настраивать дашборды со статистикой.

Отслеживайте время, необходимое для обработки запроса
При оценке эффективности вашей группы поддержки наиболее распространенным методом является отслеживание времени их первого ответа и общего времени, необходимого для обработки запроса.Чем ниже эти показатели, тем быстрее ваша команда решит проблемы пользователей.
Чтобы управлять временем обработки ответа в Tracker, настройте правила SLA для проблем вашей очереди. Правило SLA позволяет вам установить ограничение по времени для обработки запроса и включить таймер, который запускается и останавливается при запуске определенных событий (например, во время создания задачи, изменения статуса, при добавлении правопреемника и т. Д.).
Д.).
Давайте настроим правила SLA, которые будут отслеживать время первого ответа службы поддержки и общее время обработки запроса.
Время первого ответа
Чтобы измерить время первого ответа вашей службы поддержки, настройте таймер, который запускается при создании проблемы и останавливается, когда сотрудник отправляет комментарий или электронное письмо со страницы проблемы.
Зайдите в настройки очереди, откройте раздел SLA и нажмите Create a rule .
Задайте имя правила и выберите График работы, чтобы таймер был активен только в рабочее время.
В таймфреймах для задач установите следующие параметры для всех задач в очереди:
Установите предел времени для первого ответа в Время до истечения .Например, если вы хотите установить время на 2 часа 30 минут, укажите
2h 30m.В поле Время до предупреждения выберите ограничение по времени, которое запускает автоматическое напоминание по электронной почте после истечения срока действия.
Примечание
Если вы хотите, чтобы разные группы задач имели разные временные ограничения, щелкните Создайте новый фильтр и задайте параметры для группировки этих проблем.
Задайте условия запуска и остановки таймера:
В поле Start добавьте условие Проблема создана .
Под Stop добавьте условие Команда очереди ответила .
Если вы хотите автоматически отправлять электронное письмо сотруднику, ответственному за проблему, по истечении первого времени ответа, найдите раздел Уведомление → Истекло и укажите имя этого сотрудника или имя пользователя в Электронное письмо .
Сохраните свое правило.

Теперь таймер будет автоматически включаться после того, как проблема будет создана в очереди службы поддержки. Он будет отсчитывать время до тех пор, пока сотрудник службы поддержки из команды очереди не отправит комментарий или электронное письмо со страницы проблемы.
Он будет отсчитывать время до тех пор, пока сотрудник службы поддержки из команды очереди не отправит комментарий или электронное письмо со страницы проблемы.
Общее время обработки запроса
Если вы хотите измерить общее время обработки запроса, настройте таймер, который срабатывает во время создания проблемы и останавливается после обновления статуса проблемы до Решено
или Закрыто
. Вы можете приостановить таймер, пока проблема имеет статус Требуется информация
, чтобы время ожидания не учитывалось в общем времени обработки.
Зайдите в настройки очереди, откройте раздел SLA и нажмите Create a rule .
Задайте имя правила и выберите График работы, чтобы таймер был активен только в рабочее время.
В таймфреймах для задач установите следующие параметры для всех задач в очереди:
Установите предел времени для решения проблемы в Время до истечения .
Например, установите значение 8h, если вы хотите, чтобы ограничение составляло 8 рабочих часов.В поле Время до предупреждения выберите ограничение по времени, которое запускает автоматическое напоминание по электронной почте после истечения срока действия. Например, установите значение
6 часов, если вы хотите, чтобы ограничение составляло 6 рабочих часов.
Примечание
Если вы хотите, чтобы разные группы задач имели разные временные ограничения, щелкните Создайте новый фильтр и задайте параметры для группировки этих проблем.
Задайте условия запуска и остановки таймера:
В поле Start добавьте условие Проблема создана .
В разделе Пауза добавьте условие Проблема имеет статус → Требуется информация .
В разделе Stop добавьте условие Статус проблемы изменен на и выберите статусы Resolved и Closed .
В разделе Уведомление настройте уведомления, которые запускаются по истечении срока:
Если вы указали предел времени предупреждения в разделе Временные рамки для проблем , выберите Электронная почта в поле Предупреждение и укажите имя или имя пользователя сотрудника, ответственного за проблему. Таким образом, они получат уведомление по истечении установленного срока.
Если вы хотите автоматически отправлять электронное письмо сотруднику, ответственному за проблему, после истечения срока разрешения, в поле Истекло , выберите Электронная почта и укажите имя или имя пользователя этого сотрудника.
Сохраните свое правило.
 Например, установите значение
Например, установите значение 
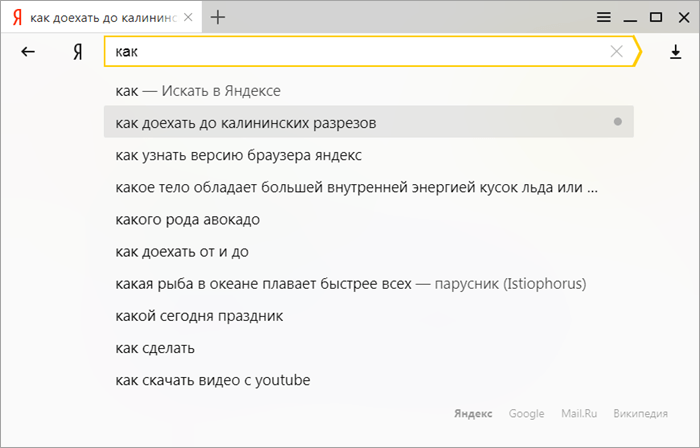
Теперь таймер будет автоматически включаться после того, как проблема будет создана в очереди службы поддержки. Таймер будет активен, пока статус проблемы не обновится до Решено
или Закрыто
. Если специалист службы поддержки запрашивает у запрашивающего дополнительную информацию и обновляет статус проблемы на Требуется информация
, таймер будет приостановлен, и его можно будет возобновить только после следующего изменения статуса.
Сбор статистики запросов
Менеджерам и сотрудникам службы поддержки часто требуется различная информация о текущих проблемах, а также статистика по ранее решенным запросам. В Tracker вы можете просматривать всю необходимую информацию и статистику на панели инструментов. Сначала вам нужно создать информационную панель, а затем добавить виджеты, которые могут включать списки задач, таблицы и диаграммы, которые создаются автоматически на основе фильтров.
Например, менеджер может использовать информационную панель для отображения списка запросов без правопреемников или просмотра данных об открытых и разрешенных запросах за определенный период.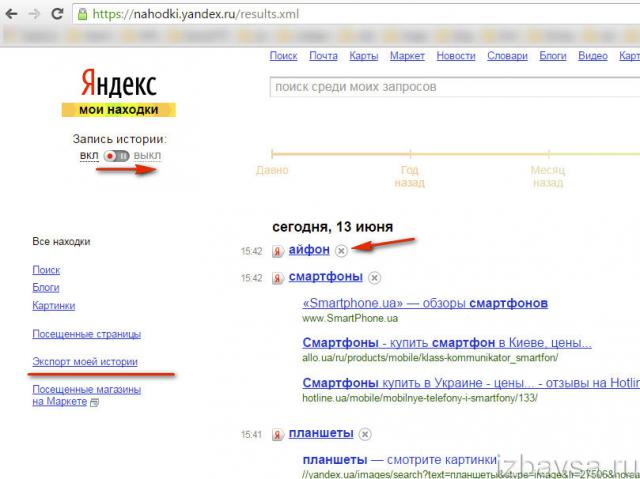 Член группы поддержки может просматривать список задач, которые им назначены, и список проблем, для которых нет исполнителей, которые необходимо решить.
Член группы поддержки может просматривать список задач, которые им назначены, и список проблем, для которых нет исполнителей, которые необходимо решить.
Давайте посмотрим на некоторые виджеты, используемые группами поддержки:
Мои проблемы
Добавьте виджет, который отображает список проблем для ваших сотрудников службы поддержки в их личную панель:
На странице панели управления нажмите → Изменить .
Добавьте виджет с типом Issues .
В поле Фильтр выберите Запрос и введите текст запроса:
Очередь: «<имя очереди>» И Получатель: я () И Разрешение: пусто ()Этот фильтр найдет все нерешенные проблемы, которые вам назначены, в указанной очереди.
Чтобы отобразить таймер правил SLA, в списке задач добавьте параметр SLA в поле Столбцы .
Сохраните виджет.

Список неназначенных выпусков
Чтобы помочь группе поддержки быстро найти и разрешить неназначенные запросы, добавьте этот список проблем на панель управления:
На странице панели управления нажмите → Изменить .
Добавьте виджет с типом Issues .
В поле Фильтр выберите Запрос и введите текст запроса:
Очередь: «<имя очереди>» И Получатель: пусто ()Этот фильтр найдет неназначенные задачи в указанной очереди.
Чтобы отобразить таймер правил SLA, в списке задач добавьте параметр SLA в поле Столбцы .
Сохраните виджет.
Таблица с количеством выпусков на одного правопреемника
Если вы хотите узнать, сколько задач было распределено на одного сотрудника за последние 30 дней, добавьте этот виджет на свою панель управления:
На странице панели управления нажмите → Изменить .
Добавить Сводная таблица виджет.
В поле Фильтр выберите Запрос и введите текст запроса:
Очередь: "<имя очереди>" И Создано:> = сегодня () - 30 дн.Этот фильтр найдет все проблемы в очереди, созданной за последние 30 дней.
Найдите поле Columns и выберите Status , затем найдите Rows и выберите Assignee .Это отображает количество задач, назначенных каждому пользователю, и сортирует их по статусу в ячейках таблицы.
Если вы хотите отображать итоги по столбцам и строкам, выберите Показать итоги .
Сохраните виджет.
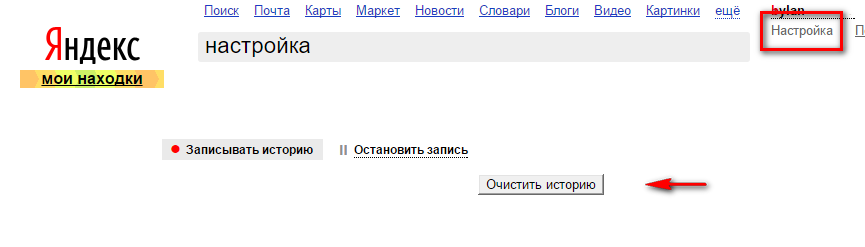
Статистика по открытым и решенным запросам
Добавьте диаграмму на панель мониторинга для отслеживания статистики по созданию и разрешению проблемы:
На странице панели управления нажмите → Изменить .
Добавьте виджет типа «Создано и решено» Диаграмма .
В поле Фильтр выберите Запрос и введите текст запроса:
Этот фильтр найдет все проблемы в указанной очереди.
В поле Группа выберите По дню и укажите количество дней, которые будут отображаться на диаграмме.
Если вы хотите отобразить итоги для созданных и решенных запросов на диаграмме, выберите Показать итого .
Сохраните виджет.

Статистика запросов по темам
Если вы используете компоненты для группировки проблем по темам, вы можете создать диаграмму, которая отображает статистику проблем по компонентам:
На странице панели управления нажмите → Изменить .
Добавьте виджет Статистика проблем .
В поле Фильтр выберите Запрос и введите текст запроса:
Этот фильтр найдет все проблемы в указанной очереди.
В поле Ключевой параметр выберите Компоненты .
Сохраните виджет.
Настроить интеграцию со сторонними платформами
Если вы хотите интегрировать Tracker со сторонним программным обеспечением (таким как CRM-система или программное обеспечение call-центра), используйте Tracker API. Например, вы можете использовать API для создания проблем в Tracker, а затем добавить дополнительную информацию из стороннего программного обеспечения.Подробнее о возможностях Tracker API читайте в документации Яндекс.Трекер API.
Если вы хотите передать информацию, собранную в Tracker, в другую систему (например, отправить уведомления в другой мессенджер), вы можете использовать триггеры. Чтобы просмотреть примеры настройки триггеров, отправляющих уведомления в Slack и Telegram, см. Интеграция с Messenger.
Интеграция с Messenger.
Обратиться в службу поддержки
Удаление файла или папки
Если запрос был обработан без ошибок, API составляет тело ответа в зависимости от типа указанного ресурса.Ответ для пустой папки или файла отличается от ответа для непустой папки. (Если запрос вызвал ошибку, возвращается соответствующий код ответа, в теле ответа которого содержится описание ошибки.)
API отвечает кодом 204 Нет содержимого (ресурс был успешно удален) без тела ответа.
Удаление непустой папки может занять неизвестное время, поэтому API отвечает кодом 202 Принято (процесс удаления начался).
Приложения должны отслеживать статус запрошенных операций. API Яндекс.Диска возвращает ссылку на статус операции, начатой по запросу. Ссылка находится в объекте Link в теле ответа.
Пример ответа:
{"href": "https://cloud-api. yandex.net/v1/disk/operations?id=d80c269ce4eb16c0207f0a15t4a31415313452f9e950cd9576f36b1146ee0" templated ", метод" ложный ":" шаблон "," шаблон ", false" }  yandex.net/v1/disk/operations?id=d80c269ce4eb16c0207f0a15t4a31415313452f9e950cd9576f36b1146ee0" templated ", метод" ложный ":" шаблон "," шаблон ", false" }
yandex.net/v1/disk/operations?id=d80c269ce4eb16c0207f0a15t4a31415313452f9e950cd9576f36b1146ee0" templated ", метод" ложный ":" шаблон "," шаблон ", false" } | Элемент | Описание |
|---|---|
href | URL.Это может быть шаблон URL-адреса; см. шаблонный ключ |
method | HTTP-метод для запроса URL-адреса из ключа |
шаблонный | Указывает шаблон URL-адреса в соответствии с RFC 6570.
|
 Возможные значения:
Возможные значения:| syntax = «proto3»; | |
| пакет yandex.cloud.compute.v1; | |
| import «google / api / annotations.прото «; | |
| import «google / protobuf / field_mask.proto»; | |
import «yandex / cloud / api / operation. proto»; proto»; | |
| импорт «яндекс / облако / вычисления / v1 / disk.proto»; | |
| импорт «яндекс / облако / операция / операция.proto»; | |
| import «yandex / cloud / validation.proto»; | |
| option go_package = «github.com / yandex-cloud / go-genproto / yandex / cloud / compute / v1; вычислить «; | |
| option java_package = «yandex.cloud.api.compute.v1»; | |
| // Набор методов управления дисковыми ресурсами. | |
| сервис DiskService { | |
// Возвращает указанный дисковый ресурс. | |
| // | |
| // Чтобы получить список доступных ресурсов диска, сделайте запрос [List]. | |
| rpc Get (GetDiskRequest) возвращает (Диск) { | |
| option (google.api.http) = {get: «/ compute / v1 / disks / {disk_id}»}; | |
| } | |
| // Извлекает список дисковых ресурсов в указанной папке. | |
| Список rpc (ListDisksRequest) возвращает (ListDisksResponse) { | |
| вариант (гугл.api.http) = {get: «/ compute / v1 / disks»}; | |
| } | |
// Создает диск в указанной папке.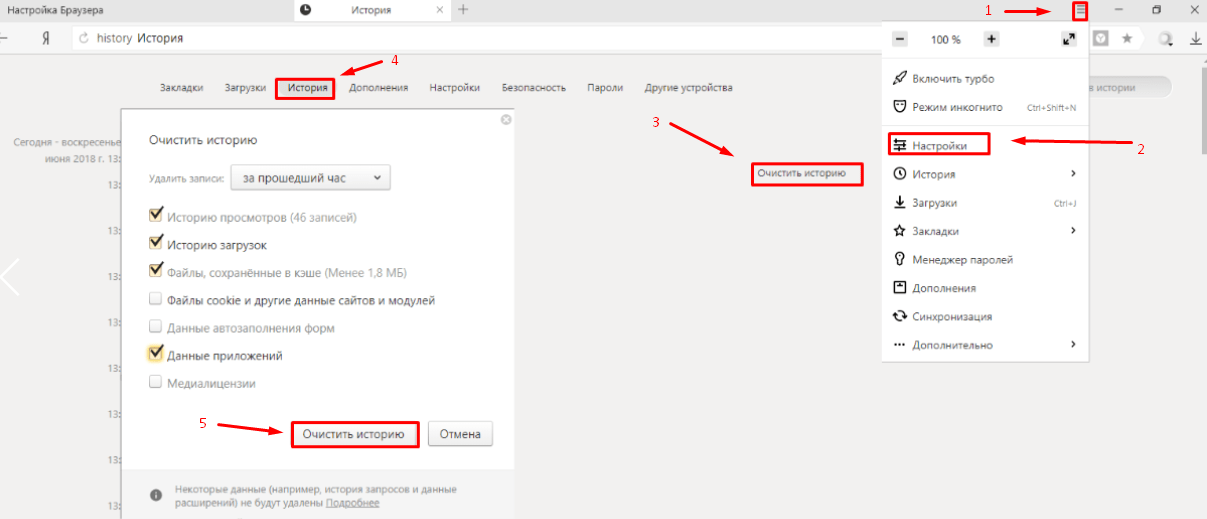 | |
| // | |
| // Вы можете создать пустой диск или восстановить его из снимка или образа. | |
| // Метод запускает асинхронную операцию, которую можно отменить, пока она выполняется. | |
| rpc Create (CreateDiskRequest) возвращает (operation.Operation) { | |
| option (google.api.http) = {post: «/ compute / v1 / disks» body: «*»}; | |
| option (yandex.cloud.api.operation) = { | |
| метаданные: «CreateDiskMetadata» | |
| ответ: «Диск» | |
| }; | |
| } | |
// Обновляет указанный диск. | |
| rpc Update (UpdateDiskRequest) возвращает (operation.Operation) { | |
| option (google.api.http) = {patch: «/ compute / v1 / disks / {disk_id}» body: «*»}; | |
| option (yandex.cloud.api.operation) = { | |
| метаданные: «UpdateDiskMetadata» | |
| ответ: «Диск» | |
| }; | |
| } | |
| // Удаляет указанный диск. | |
| // | |
// Удаление диска навсегда удаляет его данные и необратимо. Однако удаление диска не удаляет Однако удаление диска не удаляет | |
| // любые снимки или изображения, ранее сделанные с диска. Снимки и изображения необходимо удалять отдельно. | |
| // | |
| // Невозможно удалить диск, подключенный к экземпляру. | |
| rpc Delete (DeleteDiskRequest) возвращает (operation.Operation) { | |
| option (google.api.http) = {delete: «/ compute / v1 / disks / {disk_id}»}; | |
| option (yandex.cloud.api.operation) = { | |
| метаданные: «DeleteDiskMetadata» | |
| Ответ | : «google.protobuf.Пусто « |
| }; | |
| } | |
// Список операций для указанного диска.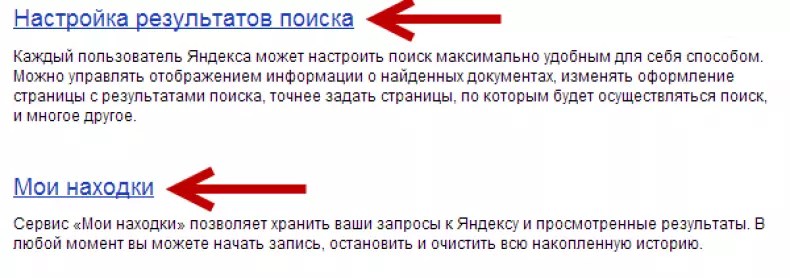 | |
| rpc ListOperations (ListDiskOperationsRequest) возвращает (ListDiskOperationsResponse) { | |
| option (google.api.http) = {get: «/ compute / v1 / disks / {disk_id} / operations»}; | |
| } | |
| } | |
| сообщение GetDiskRequest { | |
| // ID возвращаемого дискового ресурса. | |
| // Чтобы получить идентификатор диска, используйте запрос [DiskService.List]. | |
| строка disk_id = 1 [(обязательно) = true, (length) = «<= 50"]; | |
| } | |
| сообщение ListDisksRequest { | |
// ID папки для перечисления дисков.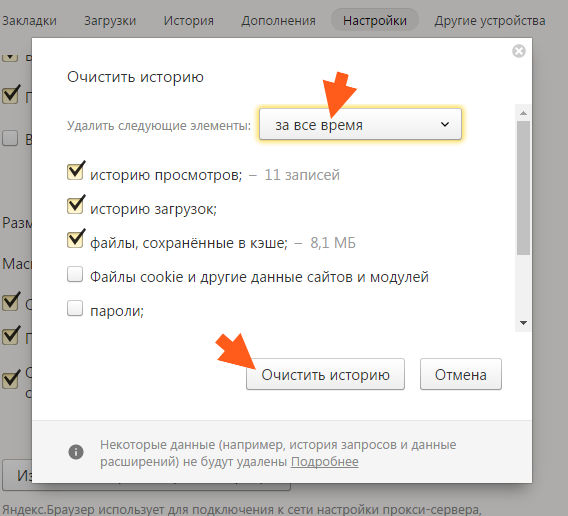 | |
| // Чтобы получить идентификатор папки, используйте [yandex.cloud.resourcemanager.v1.FolderService.List] запрос. | |
| строка folder_id = 1 [(обязательно) = true, (length) = «<= 50"]; | |
| // Максимальное количество возвращаемых результатов на страницу. Если в наличии | |
| // результат больше [page_size], | |
| // служба возвращает [ListDisksResponse.next_page_token] | |
| // который можно использовать для получения следующей страницы результатов в последующих запросах списка. | |
| int64 page_size = 2 [(значение) = «<= 1000"]; | |
| // Токен страницы. Чтобы получить следующую страницу результатов, установите [page_token] на | |
| // [ListDisksResponse.next_page_token], возвращенный предыдущим запросом списка. | |
| строка page_token = 3 [(длина) = «<= 100"]; | |
| // Выражение фильтра, которое фильтрует ресурсы, перечисленные в ответе. | |
| // Выражение должно указывать: | |
| // 1. Имя поля. В настоящее время фильтрацию можно использовать только по полю [Disk.name]. | |
| // 2.[a-z] ([- a-z0-9] {, 61} [a-z0-9])? $ `. | |
| строковый фильтр = 4 [(длина) = «<= 1000"]; | |
| } | |
| сообщение ListDisksResponse { | |
// Список дисковых ресурсов. | |
| повторяющихся Дисковых диска = 1; | |
| // Этот токен позволяет вам получить следующую страницу результатов для запросов списка.Если количество результатов | |
| // больше, чем [ListDisksRequest.page_size], используйте | |
| // [next_page_token] как значение | |
| // для параметра запроса [ListDisksRequest.page_token] | |
| // в следующем запросе списка. Каждый последующий запрос списка будет иметь собственный | |
| // [next_page_token] для продолжения пролистывания результатов. | |
| строка next_page_token = 2; | |
| } | |
| сообщение CreateDiskRequest { | |
// ID папки для создания диска. | |
| // Чтобы получить идентификатор папки, используйте запрос [yandex.cloud.resourcemanager.v1.FolderService.List]. | |
| строка folder_id = 1 [(обязательно) = true, (length) = «<= 50"]; | |
| // Имя диска. | |
| строка name = 2 [(шаблон) = «| [a-z] ([- a-z0-9] {0,61} [a-z0-9])?»]; | |
| // Описание диска. | |
| строковое описание = 3 [(длина) = «<= 256"]; | |
// Ресурсы помечаются как пары `ключ: значение`. | |
| map | |
| // ID типа диска. | |
| // Чтобы получить список доступных типов дисков, используйте запрос [yandex.cloud.compute.v1.DiskTypeService.List]. | |
| string type_id = 5 [(длина) = «<= 50"]; | |
| // ID зоны доступности, в которой находится диск. | |
// Для получения списка доступных зон используйте запрос [yandex.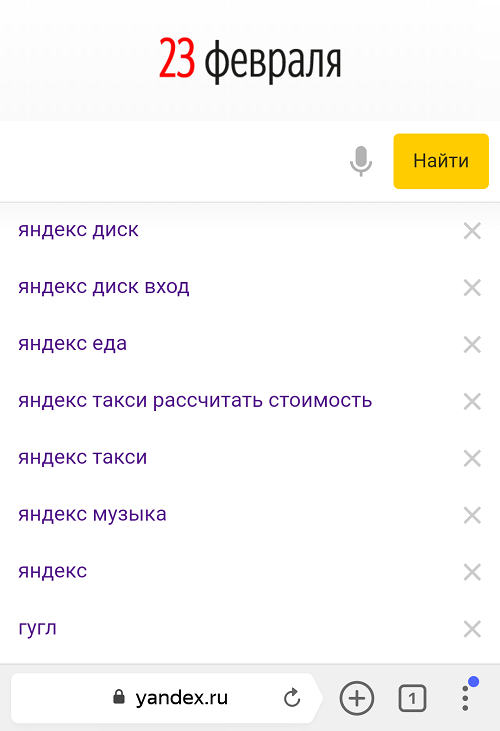 cloud.compute.v1.ZoneService.List]. cloud.compute.v1.ZoneService.List]. | |
| string zone_id = 6 [(обязательно) = true, (length) = «<= 50"]; | |
| // Размер диска, указанный в байтах. | |
| // Если диск был создан из образа, это значение должно быть больше | |
| // [яндекс.cloud.compute.v1.Image.min_disk_size] значение. | |
| int64 size = 7 [(обязательно) = true, (value) = «4194304-28587302322176»]; | |
| один из источников { | |
| // ID образа для создания диска. | |
| строка image_id = 8 [(длина) = «<= 50"]; | |
// ID снимка, из которого нужно восстановить диск. | |
| строка snapshot_id = 9 [(длина) = «<= 50"]; | |
| } | |
| // Размер блока, используемого для диска, указан в байтах. По умолчанию — 4096. | |
| int64 размер_блока = 10; | |
| // Конфигурация политики размещения. | |
| DiskPlacementPolicy disk_placement_policy = 11; | |
| } | |
| сообщение CreateDiskMetadata { | |
// ID создаваемого диска.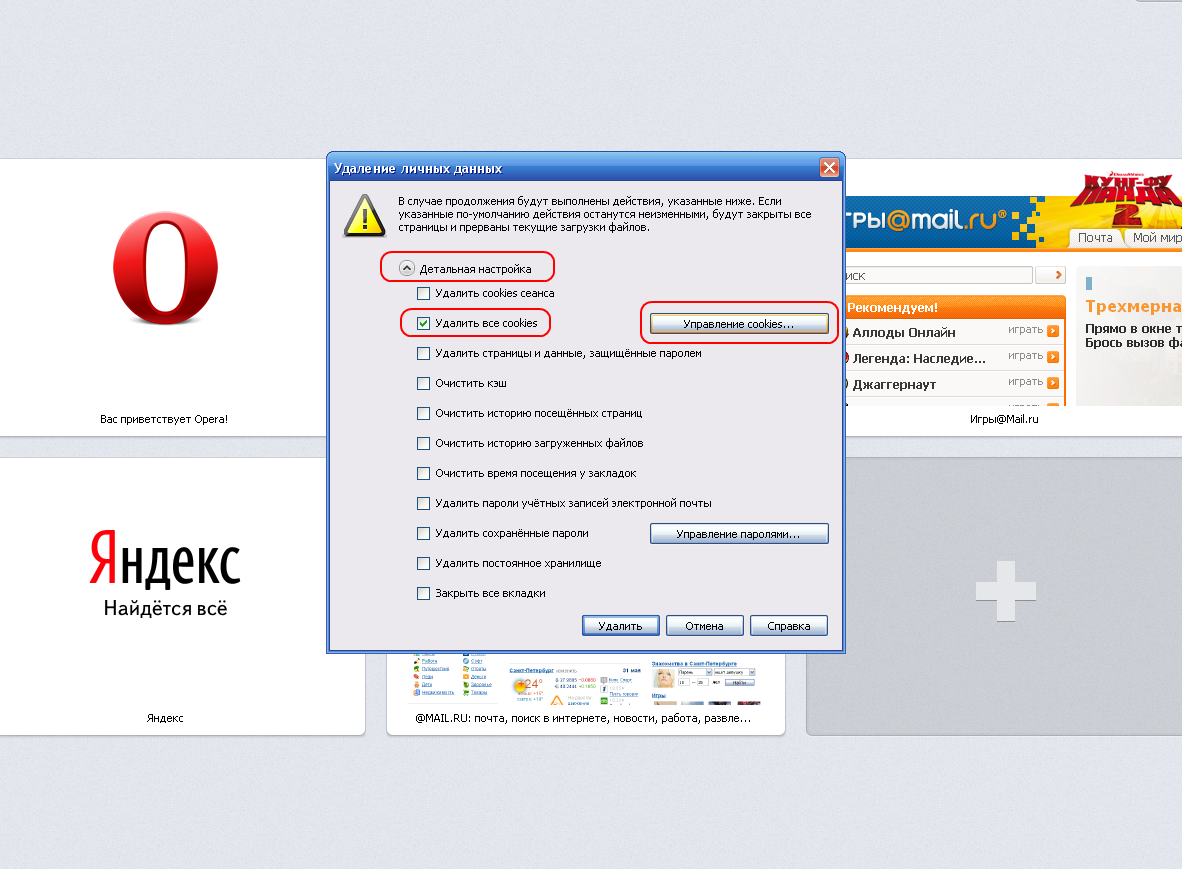 | |
| строка disk_id = 1; | |
| } | |
| сообщение UpdateDiskRequest { | |
| // Идентификатор дискового ресурса для обновления. | |
| // Чтобы получить идентификатор диска, используйте запрос [DiskService.List]. | |
| строка disk_id = 1 [(обязательно) = true, (length) = «<= 50"]; | |
| // Маска поля, указывающая, какие поля дискового ресурса будут обновлены. | |
google.protobuf. FieldMask update_mask = 2; FieldMask update_mask = 2; | |
| // Имя диска. | |
| строка name = 3 [(шаблон) = «| [a-z] ([- a-z0-9] {0,61} [a-z0-9])?»]; | |
| // Описание диска. | |
| описание строки = 4 [(длина) = «<= 256"]; | |
| // Ресурсы помечаются как пары `ключ: значение`. | |
| // | |
| // Существующий набор `label` полностью заменяется предоставленным набором. | |
map <строка, строка> label = 5 [(yandex. cloud.size) = «<= 64", (length) = "<= 63", (pattern) = "[-_./\\@0- 9a-z] * ", (map_key) .length =" 1-63 ", (map_key) .pattern =" [az] [-_./\\@ 0-9a-z] * "]; cloud.size) = «<= 64", (length) = "<= 63", (pattern) = "[-_./\\@0- 9a-z] * ", (map_key) .length =" 1-63 ", (map_key) .pattern =" [az] [-_./\\@ 0-9a-z] * "]; | |
| // Размер диска, указанный в байтах. | |
| int64 size = 6 [(значение) = «4194304-4398046511104»]; | |
| // Конфигурация политики размещения. | |
| DiskPlacementPolicy disk_placement_policy = 7; | |
| } | |
| сообщение UpdateDiskMetadata { | |
| // ID обновляемого дискового ресурса. | |
| строка disk_id = 1; | |
| } | |
| сообщение DeleteDiskRequest { | |
| // ID удаляемого диска. | |
| // Чтобы получить идентификатор диска, используйте запрос [DiskService.List]. | |
| строка disk_id = 1 [(обязательно) = true, (length) = «<= 50"]; | |
| } | |
| сообщение DeleteDiskMetadata { | |
// ID удаляемого диска. | |
| строка disk_id = 1; | |
| } | |
| сообщение ListDiskOperationsRequest { | |
| // ID дискового ресурса для перечисления операций. | |
| строка disk_id = 1 [(обязательно) = true, (length) = «<= 50"]; | |
| // Максимальное количество возвращаемых результатов на страницу. Если в наличии | |
| // результат больше, чем [page_size], служба возвращает [ListDiskOperationsResponse.next_page_token] | |
// который можно использовать для получения следующей страницы результатов в последующих запросах списка.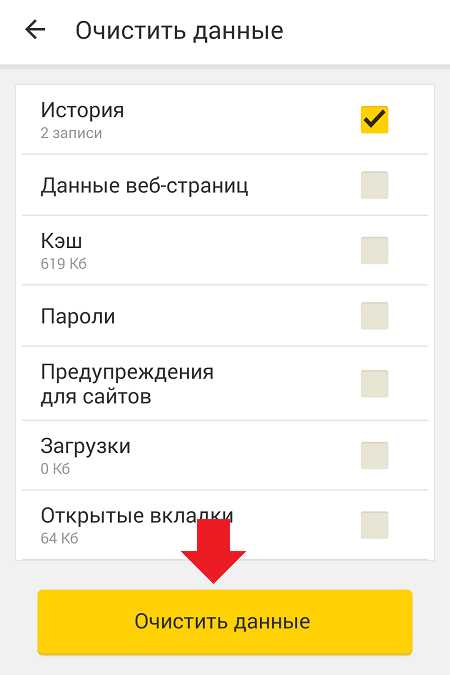 | |
| int64 page_size = 2 [(значение) = «<= 1000"]; | |
| // Токен страницы. Чтобы получить следующую страницу результатов, установите [page_token] на | |
| // [ListDiskOperationsResponse.next_page_token], возвращенный предыдущим запросом списка. | |
| строка page_token = 3 [(длина) = «<= 100"]; | |
| } | |
| сообщение ListDiskOperationsResponse { | |
| // Список операций для указанного диска. | |
повторная операция. Операции операции = 1; Операции операции = 1; | |
| // Этот токен позволяет вам получить следующую страницу результатов для запросов списка. Если количество результатов | |
| // больше, чем [ListDiskOperationsRequest.page_size], используйте [next_page_token] как значение | |
| // для [ListDiskOperationsRequest.page_token] параметр запроса в следующем запросе списка. | |
| // Каждый последующий запрос списка будет иметь свой собственный [next_page_token] для продолжения пролистывания результатов. | |
| строка next_page_token = 2; | |
| } |
RTB — Яндекс
Общие инструкции по настройке RTB см. В разделе «Начало работы с RTB». В этой статье содержится информация по интеграции с Яндекс.
В разделе «Начало работы с RTB». В этой статье содержится информация по интеграции с Яндекс.
🚧
Требуется разрешение
Яндекс доступен только с согласия партнера. Свяжитесь с менеджером своего аккаунта, чтобы начать процесс утверждения.
Нажмите, чтобы добавить рекламодателя.
Выберите «Яндекс» в качестве партнера в раскрывающемся списке. Если вы не видите такой возможности, обратитесь к менеджеру своего аккаунта.
Введите настройки RTB в разделе «Настройки». Их вам выдаст либо ваш аккаунт-менеджер, либо напрямую Яндекс:
- Конечная точка участника торгов — URL Яндекса, на который Кевел отправляет запрос ставки.
- Publisher ID — Ваш идентификатор издателя на Яндексе (необязательно).
- Страница отправлена партнеру с запросом RTB (необязательно) — Домен вашего сайта.
- BidRequest. source.pchain — TAG идентификатор платежа
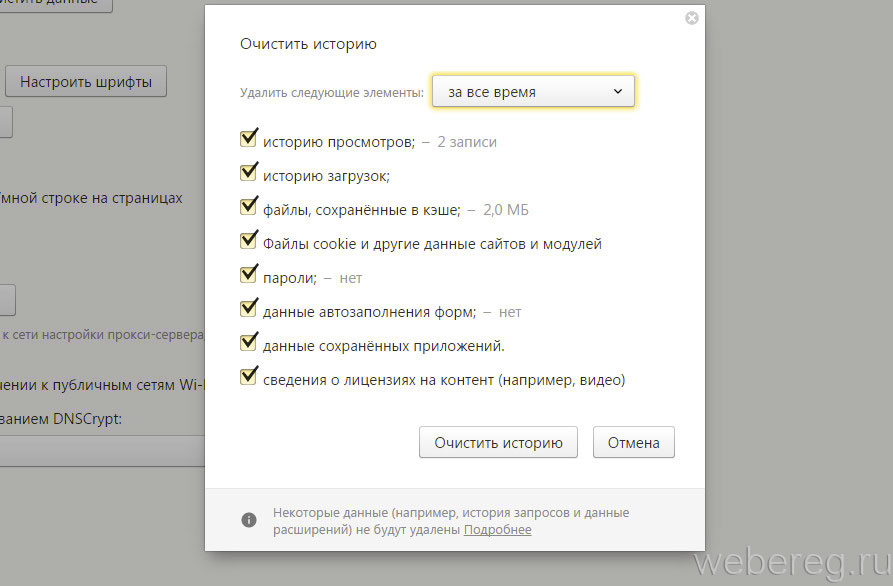 source.pchain — TAG идентификатор платежа
source.pchain — TAG идентификатор платежаСоздайте новую кампанию и период для RTB-рекламодателя так же, как и для не-RTB кампании.
📘
Во время полета для Типа тарифа будет установлено значение «CPM». Вы не можете установить какой-либо другой тип ставки.«Цена» также будет проигнорирована: выручка от полета будет определяться ставками от Яндекс.
В RTB-рейсах поддерживаются все типы приоритета. RTB также поддерживает новый приоритет: лотерея Outbid Lottery . Установите этот приоритет, чтобы заставить рейсы RTB коллективно конкурировать с рейсами не RTB.
Добавьте новый креатив во время полета или прямо со страницы рекламодателя:
- Добавьте креатив в период RTB для каждого размера объявления, которое вы собираетесь показывать через этого провайдера.
- Минимальная цена доступна для объявлений RTB, но не обязательна. Обратите внимание: если вы не введете допустимое значение, по умолчанию будет 0,01 доллара США.
- Если вы переопределяете домен в этом объявлении, введите Переопределить URL-адрес страницы, отправленной партнеру с запросом RTB .
- Если вы активировали частную торговую площадку с Яндексом, введите Deal Id. Это не обязательно.
- Понятное имя и Размер объявления .

Запросить рекламу Яндекса можно с помощью рекламных тегов JavaScript или Decision API.
Если вы вызываете RTB-объявления через Decision API, обязательно укажите в запросе URL-адрес сайта и свой IP-адрес.
Не могу подключиться к аккаунту на Яндексе
Если у вас возникли проблемы с добавлением учетной записи на Яндексе в Spark, выполните следующие действия.
1. Убедитесь, что вы используете IMAP:
- Войдите в свою учетную запись в браузере.
- Щелкните значок настроек вверху.
- Выберите «Все настройки»> «Почтовые клиенты».
- Убедитесь, что установлен флажок С сервера imap.yandex.com через IMAP .

2. Убедитесь, что вы отправили необходимые данные для входа.
Если у вас не включена двухфакторная аутентификация и вы не использовали пароль приложения, вы можете отметить Пароль портала как показан на скриншоте выше, и используйте свой обычный пароль для входа в Spark.
Если у вас включена двухфакторная аутентификация или включена опция безопасности паролей приложений для учетной записи на Яндексе, создайте специальный пароль для Spark и вставьте его в необходимое поле для входа в Spark.
Чтобы проверить, какой метод безопасности вы включили, перейдите по этой ссылке. Здесь на снимке экрана отображается учетная запись, для которой не был выбран ни один из вариантов.
Чтобы создать пароль приложения, выполните следующие действия:
- Перейдите на страницу управления доступом.
- Выберите Пароли приложений> Создать пароль приложения .
- Введите имя приложения, для которого вы создаете пароль. Пароль будет отображаться с этим именем в списке.
- Нажмите кнопку Создать пароль . Пароль приложения появится во всплывающем окне.

Примечание: « Пароль портала» опция недоступна i если вы уже используете пароль приложения.
3. Множественные попытки входа в систему
Если вы несколько раз пытались добавить учетную запись Яндекса в Spark, сервер этой учетной записи мог заблокировать соединение Spark.В этом случае, чтобы разрешить добавление учетной записи в Spark, перейдите по этой ссылке и введите символы, которые вы увидите.
4. Добавьте свой аккаунт на Яндексе в Spark
Проверьте сетевое соединение на вашем устройстве. Если вы используете VPN, мы не можем гарантировать, что Spark будет работать должным образом. Качество работы через VPN зависит исключительно от серверов сети VPN. По этой причине мы рекомендуем вам отключить VPN.
Некоторые организации включают брандмауэр для предотвращения доступа к определенным веб-сайтам из своих сетей.Спросите администратора, разрешен ли доступ к Spark (как к стороннему почтовому приложению). Как вариант, вы можете попробовать подключиться к другой сети.
- Щелкните Spark в левом верхнем углу экрана.
- Выберите Добавить учетную запись> Настроить учетную запись вручную.
- Введите свой адрес электронной почты и пароль.
- В Spark коснитесь значка меню в верхнем левом углу.
- Откройте Настройки> Учетные записи почты> Добавить учетную запись .
- Выберите Настроить учетную запись вручную .
- Введите свой адрес электронной почты и пароль.
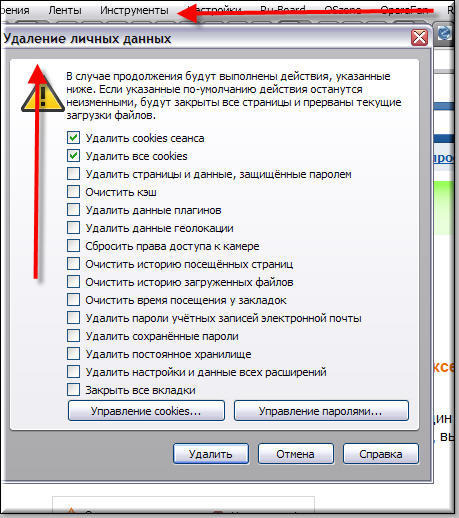
- Коснитесь значка меню в верхнем левом углу.
- Откройте Настройки> Учетные записи почты> Добавить учетную запись .
- Выбрать Другое .
- Введите свой адрес электронной почты и пароль.
5. Свяжитесь с нашей службой поддержки
Если вы все еще испытываете трудности с добавлением учетной записи на Яндексе, мы будем рады помочь вам лично.
- Запустите Spark и щелкните Справка в левом верхнем углу экрана. Выберите Отправить отзыв .
- Появится новое окно электронной почты. В строке Тема: напишите «Невозможно подключиться к аккаунту на Яндексе». Нам нужна эта тема письма, чтобы вы могли быстро и лично ответить.
- В своем сообщении введите адрес электронной почты , который вы пытаетесь войти, и приложите снимок экрана с сообщением об ошибке, которое появляется при попытке добавить учетную запись.
- Отправьте электронное письмо, и наша служба поддержки свяжется с вами, чтобы решить вашу проблему.
Spark автоматически прикрепляет файл .zip с журналами приложений к вашей электронной почте. Нам нужны журналы для нашего расследования. Этот файл может содержать некоторые конфиденциальные личные данные, и мы заверяем вас, что будем рассматривать его как конфиденциальную информацию.
- В Spark коснитесь значка меню в верхнем левом углу.
- Откройте Настройки> Поддержка> Диагностика> Отправить диагностическую информацию .
- Появится новое окно электронной почты. В строке Тема: напишите «Невозможно подключиться к аккаунту на Яндексе». Нам нужна эта тема письма, чтобы вы могли быстро и лично ответить.
- В своем сообщении введите адрес электронной почты , который вы пытаетесь войти, и приложите снимок экрана с сообщением об ошибке, которое появляется при попытке добавить учетную запись.
- Отправьте электронное письмо, и наша служба поддержки свяжется с вами, чтобы решить вашу проблему.
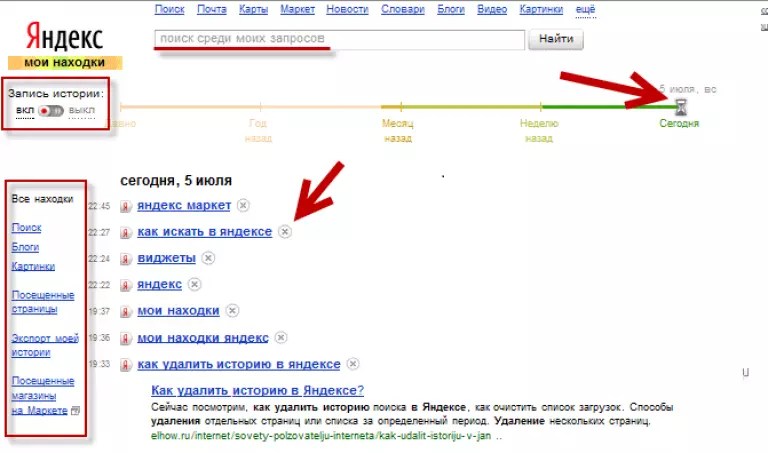
Spark автоматически подключает файл.zip-файл с журналами приложения на вашу электронную почту. Нам нужны журналы для нашего расследования. Этот файл может содержать некоторые конфиденциальные личные данные, и мы заверяем вас, что будем рассматривать его как конфиденциальную информацию.
Обратите внимание: нет возможности получить доступ к Spark и связаться с нами , если учетная запись электронной почты, которую вы не можете подключить к Spark, является первой учетной записью, которую вы пытаетесь добавить.
В этом случае сначала добавьте в Spark любую другую учетную запись электронной почты. Затем попробуйте добавить свою основную учетную запись.Если не удается подключиться, обратитесь в нашу службу поддержки, как описано выше.
- Коснитесь значка меню в верхнем левом углу.
- Откройте Настройки> Поддержка> Диагностика> Отправить диагностическую информацию .
- Появится новое окно электронной почты. В строке Тема: напишите «Невозможно подключиться к аккаунту на Яндексе». Нам нужна эта тема письма, чтобы вы могли быстро и лично ответить.
- В своем сообщении введите адрес электронной почты , с которым вы пытаетесь войти, и приложите снимок экрана с сообщением об ошибке, которое появляется при попытке добавить учетную запись.
- Отправьте электронное письмо, и наша служба поддержки свяжется с вами, чтобы решить вашу проблему.
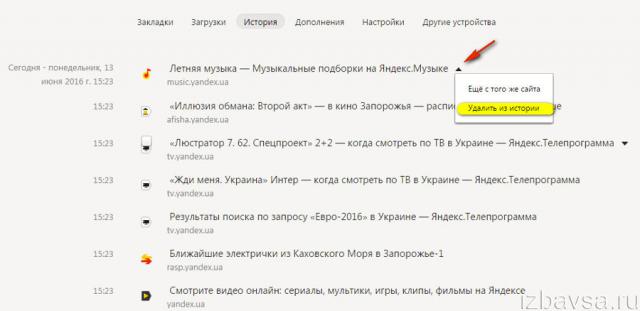
Spark автоматически прикрепляет файл .zip с журналами приложений к вашей электронной почте. Нам нужны журналы для нашего расследования. Этот файл может содержать некоторые конфиденциальные личные данные, и мы заверяем вас, что будем рассматривать его как конфиденциальную информацию.
Обратите внимание: нет возможности получить доступ к Spark и связаться с нами , если учетная запись электронной почты, которую вы не можете подключить к Spark, является первой учетной записью, которую вы пытаетесь добавить.
В этом случае сначала добавьте в Spark любую другую учетную запись электронной почты. Затем попробуйте добавить свою основную учетную запись. Если не удается подключиться, обратитесь в нашу службу поддержки, как описано выше.
Читать далее: Проблемы с отправкой электронных писем из учетных записей Exchange / Office 365Нам очень жаль это слышать.Что вам показалось наиболее бесполезным?
Если вам потребуется дополнительная помощь, свяжитесь с нами.Результаты поиска в Яндексе свернуты. Почему результат поиска в Яндексе отличается в разных браузерах и на разных компьютерах? Для удаления запросов в Яндекс Линии
Это очень горячая тема.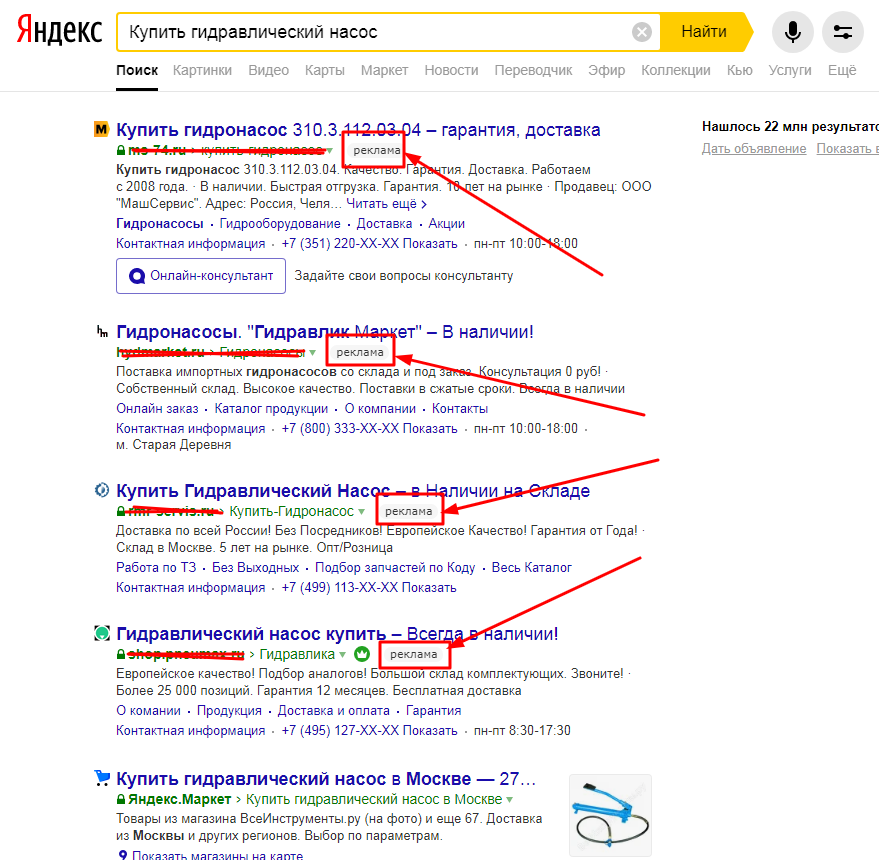 Многие используют Яндекс.Строку в Windows или формируют поиск яндекса в браузере … Традиционно ответы на популярные запросы и поисковые подсказки отображаются в самом поле ввода как живой поиск. Это очень удобно, но … поисковые системы, в том числе Яндекс, собирают информацию о ваших интересах в Интернете, а затем пытаются угадать ваши предпочтения с учетом этих интересов. Те. стоит один раз поискать рецепт булочек в Яндексе, а в следующий раз, как только вы введете букву «П», выскочит куча подсказок со словом «булочка». Это косвенно указывает на вашу прошлую историю поиска и интернет-интересы.Иногда компьютер используют несколько человек, и вы не всегда хотите, чтобы другой человек видел вашу историю поиска. Как удалить запросы в поисковой строке Яндекса, если вы не хотите делиться своими интересами , читайте дальше.
Многие используют Яндекс.Строку в Windows или формируют поиск яндекса в браузере … Традиционно ответы на популярные запросы и поисковые подсказки отображаются в самом поле ввода как живой поиск. Это очень удобно, но … поисковые системы, в том числе Яндекс, собирают информацию о ваших интересах в Интернете, а затем пытаются угадать ваши предпочтения с учетом этих интересов. Те. стоит один раз поискать рецепт булочек в Яндексе, а в следующий раз, как только вы введете букву «П», выскочит куча подсказок со словом «булочка». Это косвенно указывает на вашу прошлую историю поиска и интернет-интересы.Иногда компьютер используют несколько человек, и вы не всегда хотите, чтобы другой человек видел вашу историю поиска. Как удалить запросы в поисковой строке Яндекса, если вы не хотите делиться своими интересами , читайте дальше.
Посмотрим, что делать при использовании строки поиска. в браузере и поиск в Яндекс на панели задач Windows .

Чтобы подсказки не всплывали в браузере
Первым делом … Удаляем историю поиска в самом браузере. Это не относится к поиску Яндекса, но какой смысл скрывать свои прошлые запросы, если вы легко можете найти список всех посещенных сайтов в браузере.Вы можете увидеть, как очистить историю браузера на картинках. Или найдите более подробную информацию в Интернете, если ваш браузер не указан ниже.
| Очистка истории просмотров в Mozilla FireFox |
| Очистка истории просмотров в Google Chrome |
| Очистка истории просмотров в Opera |
Вы также можете очищать файлы cookie после каждого поиска .
 .. В этом случае информация об истории поиска больше не будет связана с вашим браузером. После очистки файлов cookie подсказки по поиску не будут содержать никакой информации о вас.
.. В этом случае информация об истории поиска больше не будет связана с вашим браузером. После очистки файлов cookie подсказки по поиску не будут содержать никакой информации о вас.Однако проще всего настроить « Персональный поиск » так, чтобы подсказки не содержали информацию о вашей истории поиска.
Алгоритм следующий:
Для удаления запросов в Яндекс Лине
В Windows 10 Яндекс.Строка расположена на панели задач , по умолчанию. Яндекс.Строка позволяет выполнять поисковый запрос в Интернете прямо с панели задач, не запуская напрямую браузер. Другая строка ищет папки на вашем компьютере. И может отвечать на голосовые команды. Довольно удобно и безопасно, если только вы пользуетесь компьютером.
Откуда Яндекс.Строка получает поисковые подсказки?
Строка извлекает информацию из нескольких источников- Список ссылок по запросу из поиска Яндекса
- ссылок на разделы выбранного сайта
- ответы на популярные запросы Яндекса
- результатов индексации компьютерных носителей (HDD, SSD и др. ))
 ))
))15.03.2017
Использование Интернета не всегда может быть безопасным. Скачивая или открывая сомнительные файлы, вы можете получить различные вирусы и множество рекламных объявлений, которые могут не только помешать правильной работе вашего компьютера, но и украсть ваши данные. Реклама, небезопасные поисковые системы и веб-сайты — одна из самых распространенных проблем, с которыми сталкиваются пользователи.
Причины проблем с непроизвольным открытием Яндекс.Браузера
Чаще всего браузер открывается не с пустыми вкладками, это могут быть разные стартовые страницы и сайты с рекламой.Также можно заметить подмену рекламы от одного и того же Google на разных сайтах. Пользователи могут поймать этот вид вирусов несколькими способами:
Устранение проблемы
Шаг 1. Проверьте и исправьте файл
«Хосты» Доступ к этому файлу возможен только с правами администратора. Это легко исправить и проверить с помощью блокнота. Для этого требуется:
Для этого требуется:
Шаг 2. Очистите избыточный планировщик задач
Причина, по которой Яндекс.Браузер открывает окна с рекламой через определенное время, — это планировщик задач.Чтобы вкладки не открывались, их нужно отключить в планировщике. Сделать это можно так:
Шаг 3. Удалите лишнее при запуске
Убрать ненужные и вредоносные задачи из автозагрузки вполне возможно. по-простому … Для этого вам понадобится только программа CCleaner, о которой мы уже писали:
Шаг 4. Удаление вредоносного ПО
Диспетчер задач может содержать активные процессы, которые мешают нормальной работе компьютера и являются вредоносными.Их название может каждый раз меняться и демонстрировать их нет смысла, но их обнаружение и удаление должны быть обязательными. Вы можете проделать все действия без помощи программного обеспечения, но это будет сложнее и дольше по времени, поэтому лучше использовать удобные бесплатные программы.
Загрузите бесплатное программное обеспечение Adwcleaner, чтобы упростить установку. Запустите программу и начните сканирование. После завершения сканирования достаточно нажать кнопку «Очистить» .
Запустите программу и начните сканирование. После завершения сканирования достаточно нажать кнопку «Очистить» .
Вы также можете использовать еще одну бесплатную программу для очистки компьютера от вирусов.Загрузите Malwarebytes и выполните простую установку. Бесплатная версия программы сроком на 14 дней достаточно, чтобы вам полностью очистить компьютер от вредоносных программ. Сканировать и затем нажать «Поместить выбранные объекты в карантин» .
Шаг 5: удалите расширения и измените домашнюю страницу
Если на вашем компьютере есть вирусы, связанные с браузером, то, скорее всего, ваша домашняя страница изменилась и были установлены ненужные расширения. Уложить все на свои места довольно просто:
Затем перезапустите браузер и используйте его безопасно, быстро и удобно.
Все пять шагов, описанных в статье, помогут вам тщательно очистить компьютер от вредоносных программ, из-за которых Яндекс.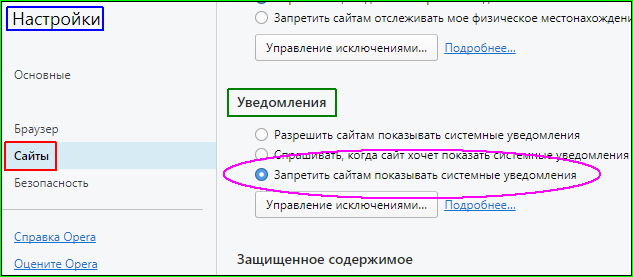 Браузер открывается с различной рекламой. Также своевременное обнаружение вредоносных программ поможет вам сохранить ваши личные данные.
Браузер открывается с различной рекламой. Также своевременное обнаружение вредоносных программ поможет вам сохранить ваши личные данные.
Расскажи друзьям в социальных сетях
Комментарии 13
Kait.15
Правильно ли я понимаю, что при открытии браузера он начинает автоматически открывать последние посещенные вами веб-страницы? Естественно, сразу приходит в голову вирусная активность, но с учетом того, что вы переустановили ОС, сложно сказать, в чем проблема.Могу только посоветовать сбросить настройки браузера, а затем удалить его с компьютера с помощью программы Revo Uninstaller, а затем выполнить новую установку (обязательно скачайте свежий дистрибутив с официального сайта разработчика). Дополнительно проверьте свой компьютер на вирусы с помощью антивируса или утилитой лечения Dr.Web CureIt.
Если вы искали сайт, то наверняка заметили, что в одном браузере сайт находится на первом месте, во втором — в третьем, где-то его вообще нет в ТОП10.
В этой статье мы объясним, почему это происходит.
Причин на самом деле несколько, но они разделены на две группы: личные и неличные (другими словами, даже в «чистом» браузере анонимного посетителя результаты тоже могут быть разными).
Рассмотрим их по очереди.
1. Личный вопрос
Используете поисковую систему, будь то Яндекс или Гугл? вы можете авторизоваться в Яндекс.почте или Gmail. Таким образом, система однозначно знакома с посетителем, его историей поиска и предпочтениями.Более того, имя пользователя является дополнительным подспорьем для системы, принцип работает, даже если вы не авторизованы в сервисе поисковой системы — некоторые данные о вас уже известны, если вы не очищали COOKIE и не удаляли свой браузер.
Если вы посещаете сайт чаще других, поисковая система может выдать его поверх остальных результатов. Аналогичная система есть и во Вконтакте — в списке друзей по запросу «Александр» будет выделяться тот Александр, чью страницу вы недавно просматривали. У другого пользователя будет совсем другой Александр.
У другого пользователя будет совсем другой Александр.
Более подробно поисковая платформа Яндекс — Калининград описана ниже.
2. Настройки доставки и регионы
Помимо классических предпочтений, поисковые системы учитывают ряд других факторов:
- Регион поиска определяется вашим IP-адресом
Если в Нижнем Новгороде вы на первом месте, то в Москве вас может вообще не найти. - Безопасный поиск
Если включен безопасный поиск, некоторые сайты могут исчезнуть из результатов поиска — и это также влияет на результаты. - Количество результатов на странице.
Некоторые настраивают Яндекс так, что смотрят не 10 результатов на странице, а 50. Это тоже влияет на результаты поиска.
Все это очень сильно влияет на результаты поиска. Однако даже в чистых системах с настройками по умолчанию результат также может отличаться. Причины тому:
3. Эксперименты Яндекса
Есть информация, что Яндекс регулярно проводит эксперименты, чтобы улучшить качество поиска и сделать Директ (контекстную рекламу Яндекса) более прибыльным. Регулярно одновременно проводится 5-10 экспериментов, каждый из которых затрагивает около 4% аудитории. Пользователи для экспериментов выбираются либо регионально (скажем, Москва), либо случайным образом.
Регулярно одновременно проводится 5-10 экспериментов, каждый из которых затрагивает около 4% аудитории. Пользователи для экспериментов выбираются либо регионально (скажем, Москва), либо случайным образом.
На одном компьютере сайт находится на 5 месте, а на втором можно случайно нарваться на эксперимент.
Эксперименты могут быть такими, например:
- Понизить интересующий сайт в позициях, чтобы увеличить CTR рекламы
- Активировать новый алгоритм
- Активировать новый дизайн (например, сейчас количество человек видят новый дизайн Яндекса — острова).
- Показать или скрыть информационные результаты (например, Википедия)
Поэкспериментируйте с небольшими фрагментами вашей аудитории, чтобы улучшить качество поиска. Однако результаты выпуска разные.
4. Конкуренты из контекстной рекламы
Все поисковые системы существуют за счет заработка на контекстной рекламе. Это их главный хлеб. Понятно, что чем больше этого хлеба, тем лучше.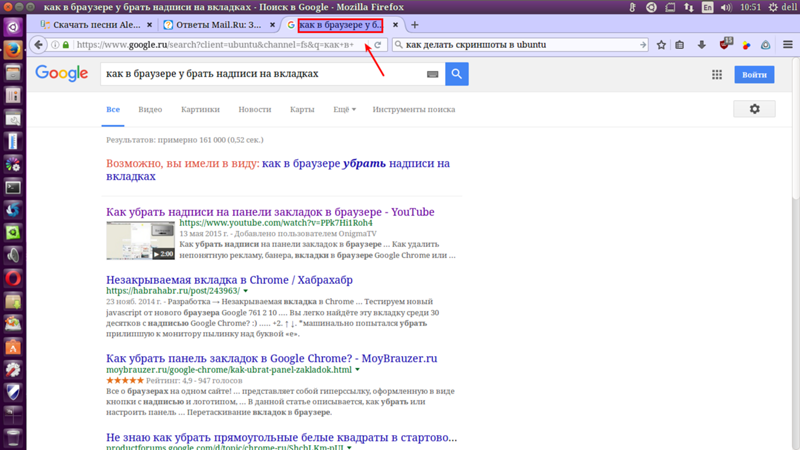
Поисковые системы могут понизить рейтинг сайта, который конкурирует с контекстной рекламой.Допустим, вы на 5-м месте на одном компьютере.
Вы открываете второй компьютер — бац, кто-то разместил рекламу в рекламе (или сейчас очередь показывать рекламу). Все, сайт занижен по позициям. Или наоборот, позиция одного из ваших конкурентов в поисковой выдаче занижена, или наоборот, пропала реклама — позиции выросли.
В результате даже в чистой системе и в чистом анонимном браузере результат может отличаться.
5. Внутренняя архитектура поисковой системы
Яндекс использует систему Apache Hadoop.Для поиска требуется много ресурсов, и один или два сервера (родительские) хранят информацию, которая распространяется на сотни других компьютеров. Таким образом, все пользователи поиска подключаются к машинам, выполняющим поиск. Все обновления индекса постоянно «выгружаются» на эти машины. Если кто-то перейдет к машине с устаревшими или слишком новыми данными, результаты поиска будут устаревшими или новыми. Другой посетитель, случайно подключившийся к другому компьютеру, получит другие данные. Опять же, даже в чистой системе и в чистом анонимном браузере результат может отличаться.
Другой посетитель, случайно подключившийся к другому компьютеру, получит другие данные. Опять же, даже в чистой системе и в чистом анонимном браузере результат может отличаться.
6. Быстрый индекс и новости
Поисковые системы используют несколько индексов. Первый, большой и громоздкий, содержит данные о подавляющем количестве веб-страниц. Быстрый индекс, в свою очередь, содержит последние новости (часы, минуты, секунды). Это сообщения из блогов, твиттера, горячие новости. Такие новости могут появиться в любой момент, а при просмотре во втором браузере они могут сместить результаты поиска или исчезнуть как устаревшие.
Немного информации о Калининграде (поисковая платформа Яндекс)
Его цель — персонализировать поисковые подсказки и результаты поиска.
Основная цель, которую поставили перед собой специалисты Яндекса, — дать пользователям правильные, индивидуальные ответы на неоднозначные запросы. Если человек впервые пользуется услугами поисковой системы, ему будут показаны неоптимальные результаты. Но для людей, которые уже пользовались поиском несколько раз, Яндекс предложит персонализированный результат, который будет составлен с учетом его истории поведения.
Но для людей, которые уже пользовались поиском несколько раз, Яндекс предложит персонализированный результат, который будет составлен с учетом его истории поведения.
Поисковая площадка Калининград работает для всех пользователей, о которых можно собирать информацию.Адаптивный механизм активируется, как только данных будет достаточно. Информация проверяется раз в сутки. Чтобы начать получать персональные результаты, достаточно 20 кликов и около десятка запросов.
Пользовательские метрики используются для измерения персонализации ранжирования. При расчете учитывается кликабельность первых позиций, количество откликов, по которым не было кликов. Андрей Стрелковский, ответственный за разработку рейтинговой системы Яндекса, говорит, что результаты персонализируются более чем в половине случаев.В среднем 75% запросов пользователей ТОП-10 сайтов меняются благодаря этому алгоритму. Их количество составляет 114 миллионов в сутки.
В прошлом году список поисковых подсказок не сильно отличался для разных пользователей.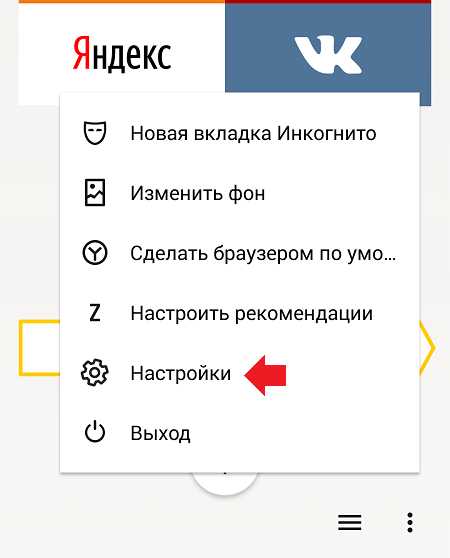 Фактически учитывались только страна и город проживания. Первым шагом в настройке подсказок было добавление в список подсказок тех, которые были недавно введены пользователем (они выделены фиолетовым цветом). Теперь пользователям будут показаны индивидуальные поисковые предложения в соответствии с интересами каждого человека.
Фактически учитывались только страна и город проживания. Первым шагом в настройке подсказок было добавление в список подсказок тех, которые были недавно введены пользователем (они выделены фиолетовым цветом). Теперь пользователям будут показаны индивидуальные поисковые предложения в соответствии с интересами каждого человека.
Персональный поиск по умолчанию включен для всех пользователей, часто использующих Яндекс. Очевидно, что чем больше вопросов задает человек, тем лучше его поймет поисковая система. Если по найденным ответам мало кликов, то персональный поиск отключен. Как только пользователь снова начинает задавать большое количество вопросов, система снова включается. Конечно, личный поиск можно в любой момент отключить через настройки.
Что такое Калининград?Калининградская поисковая платформа включает ряд продуктов, которые являются частью персонального поиска.Таким образом, это включает:
- Персональный выбор. Яндекс предложит пользователю только те ответы, которые ему подходят. Для этого применяется формула ранжирования. Учитывается язык общения — пока только русский или английский (поисковая платформа Рейкьявика), а также историю поиска.
- Индивидуальные подсказки. В строке поиска пользователь увидит среди подсказок те запросы, которые были введены людьми со схожими интересами. По заявлению разработчиков, выделено 400 тысяч групп пользователей, которым интересны одни и те же темы.
- Сиреневые намеки. По статистике, пользователи повторяют около 24% своих запросов. Поэтому Яндекс добавляет в подсказки фразы, которые пользователь недавно вводил. Такие наконечники выделены сиреневым цветом. С их помощью пользователь может мгновенно повторить введенный ранее запрос.
- Любимые сайты в подсказках. Очень часто пользователи используют поисковые системы для поиска ресурсов, URL-адреса которых они не могут запомнить. Теперь Яндекс запоминает сайты, на которые переходят пользователи из результатов поиска, и включает их в подсказки.По словам представителей поисковой системы, пользователи ежедневно нажимают на персональные советы по навигации 3,3 миллиона раз. Этой функцией еженедельно пользуются 18 миллионов человек.
- Мгновенные подсказки. Яндекс не только учитывает историю поиска, но и анализирует запросы, характерные для конкретной поисковой сессии. После ввода следующего вопроса поисковая система определяет, что еще может заинтересовать пользователя по этой теме, и добавляет подходящие варианты в набор подсказок.Каждый день Яндекс предлагает аналогичные подсказки с учетом предыдущего запроса 53 миллиона раз.
 Для этого применяется формула ранжирования. Учитывается язык общения — пока только русский или английский (поисковая платформа Рейкьявика), а также историю поиска.
Для этого применяется формула ранжирования. Учитывается язык общения — пока только русский или английский (поисковая платформа Рейкьявика), а также историю поиска. Этой функцией еженедельно пользуются 18 миллионов человек.
Этой функцией еженедельно пользуются 18 миллионов человек.Персональный поиск сэкономит пользователю до 14% времени. Это будет примерно 8 минут в неделю. Вполне достаточно, чтобы выпить чашку чая или позвонить друзьям.
Глобальные флаги
Здесь описаны глобальные флаги, доступные для каждой команды rclone. разделены на две группы: не-бэкэнд-флаги и бэкэнд-флаги.
Флаги без серверной части
Эти флаги доступны для каждой команды.
--ask-password Разрешить запрос пароля для зашифрованной конфигурации. (по умолчанию true)
--auto-confirm Если включено, не запрашивать подтверждение консоли.
--backup-dir string Создавать резервные копии в иерархии на основе DIR.
--bind string Локальный адрес для привязки исходящих соединений, IPv4, IPv6 или имя.
--buffer-size SizeSuffix Размер буфера памяти при чтении файлов для каждого --transfer.(по умолчанию 16M)
--bwlimit BwTimetable Предел пропускной способности в килобайтах / с, или используйте суффикс b | k | M | G или полное расписание.
--bwlimit-file BwTimetable Ограничение пропускной способности файла в кБайт / с, или используйте суффикс b | k | M | G или полное расписание.
--ca-cert string Сертификат ЦС, используемый для проверки серверов
--cache-dir строка Каталог, который rclone будет использовать для кеширования. (по умолчанию "$ HOME / .cache / rclone")
--check-first Выполнить все проверки перед началом передачи.--checkers int Количество чекеров, запускаемых параллельно. (по умолчанию 8)
-c, --checksum Пропускать на основе контрольной суммы (если есть) и размера, а не времени модификации и размера
--client-cert string Клиентский SSL-сертификат (PEM) для взаимной аутентификации TLS
--client-key string Закрытый ключ SSL клиента (PEM) для взаимной аутентификации TLS
--compare-dest string Включить дополнительный путь на стороне сервера во время сравнения. --config string Файл конфигурации. (по умолчанию "$ HOME / .config / rclone / rclone.conf")
--contimeout duration Тайм-аут подключения (по умолчанию 1 мин. с)
--copy-dest string Подразумевает --compare-dest, но также копирует файлы из пути в место назначения.
--cpuprofile string Записать профиль процессора в файл
--cutoff-mode string Режим остановки передачи при достижении максимального лимита передачи HARD | SOFT | CAUTIOUS (по умолчанию "HARD")
--delete-after При синхронизации удалить файлы в месте назначения после передачи (по умолчанию)
--delete-before При синхронизации удалить файлы в месте назначения перед передачей
--delete-during При синхронизации, удалять файлы во время передачи
--delete-excluded Удалять файлы по назначению, исключенные из синхронизации
--disable string Отключить список функций, разделенных запятыми.Используйте справку, чтобы просмотреть список.
-n, --dry-run Выполнить пробный запуск без постоянных изменений
--dump DumpFlags Список элементов для выгрузки: заголовки, тела, запросы, ответы, аутентификация, фильтры, горутины, открытые файлы
--dump-body Дампить заголовки и тела HTTP - может содержать конфиденциальную информацию
--dump-headers Дампить HTTP-заголовки - могут содержать конфиденциальную информацию
--error-on-no-transfer Устанавливает код выхода 9, если файлы не передаются, полезно в скриптах
--exclude stringArray Исключить файлы, соответствующие шаблону
--exclude-from stringArray Чтение шаблонов исключения из файла (используйте - для чтения из стандартного ввода)
--exclude-if-present string Исключить каталоги, если указано имя файла
--expect-continue-timeout duration Тайм-аут при использовании expect / 100-continue в HTTP (по умолчанию 1 с)
--fast-list Использовать рекурсивный список, если он доступен. Использует больше памяти, но меньше транзакций.
--files-from stringArray Прочитать список имен исходных файлов из файла (используйте - для чтения из stdin)
--files-from-raw stringArray Прочитать список имен исходных файлов из файла без обработки строк (используйте - для чтения из stdin)
-f, --filter stringArray Добавить правило фильтрации файлов
--filter-from stringArray Чтение шаблонов фильтрации из файла (используйте - для чтения из стандартного ввода)
--header stringArray Установить HTTP-заголовок для всех транзакций
--header-download stringArray Установить HTTP-заголовок для транзакций загрузки
--header-upload stringArray Установить HTTP-заголовок для транзакций загрузки
--ignore-case Игнорировать регистр в фильтрах (без учета регистра)
--ignore-case-sync Игнорировать регистр при синхронизации
--ignore-checkum Пропустить проверку контрольных сумм после копирования.--ignore-errors удалить, даже если есть ошибки ввода / вывода
--ignore-existing Пропустить все файлы, существующие в месте назначения
--ignore-size Игнорировать размер при пропуске использования времени модификации или контрольной суммы.
-I, --ignore-times Не пропускать файлы, совпадающие по размеру и времени - передать все файлы
--immutable Не изменять файлы. Ошибка, если существующие файлы были изменены.
--include stringArray Включить файлы, соответствующие шаблону
--include-from stringArray Чтение шаблонов включения из файла (используйте - для чтения из стандартного ввода)
-i, --interactive Включить интерактивный режим
--log-file string Записывать все в этот файл
--log-format string Список параметров формата журнала, разделенных запятыми (по умолчанию «дата, время»)
--log-level строка Уровень журнала ОТЛАДКА | ИНФОРМАЦИЯ | УВЕДОМЛЕНИЕ | ОШИБКА (по умолчанию "УВЕДОМЛЕНИЕ")
--log-systemd Активировать интеграцию systemd для регистратора.--low-level-retries int Число повторных попыток низкого уровня. (по умолчанию 10)
--max-age Продолжительность Передавать только файлы младше этого в s или суффиксе ms | s | m | h | d | w | M | y (по умолчанию выключено)
--max-backlog int Максимальное количество синхронизируемых или проверяемых объектов. (по умолчанию 10000)
--max-delete int При синхронизации ограничить количество удалений (по умолчанию -1)
--max-depth int Если установлено, ограничивает глубину рекурсии этим.(по умолчанию -1)
--max-duration duration Максимальная продолжительность, в течение которой rclone будет передавать данные.
--max-size SizeSuffix Передавать только файлы меньшего размера в k или суффиксе b | k | M | G (по умолчанию выключено)
--max-stats-groups int Максимальное количество групп статистики для хранения в памяти. На максимуме самое старое отбрасывается. (по умолчанию 1000)
--max-transfer SizeSuffix Максимальный размер передаваемых данных. (по умолчанию выключено)
--memprofile string Записать профиль памяти в файл
--min-age Продолжительность Передавать только файлы старше указанного в s или суффиксе ms | s | m | h | d | w | M | y (по умолчанию выключено)
--min-size SizeSuffix Передавать только файлы большего размера в k или суффиксе b | k | M | G (по умолчанию выключено)
--modify-window duration Максимальная разница во времени, которая считается одинаковой (по умолчанию 1 нс)
--multi-thread-cutoff SizeSuffix Использовать многопоточную загрузку для файлов, размер которых превышает этот размер. (по умолчанию 250 МБ)
--multi-thread-streams int Максимальное количество потоков, используемых для многопоточных загрузок. (по умолчанию 4)
--no-check-certificate Не проверять SSL-сертификат сервера. Ненадежный.
--no-check-dest Не проверять место назначения, копировать все равно.
--no-console Скрыть окно консоли. Поддерживается только в Windows.
--no-gzip-encoding Не устанавливать Accept-Encoding: gzip.
--no-traverse Не проходить через целевую файловую систему при копировании.--no-unicode-normalization Не нормализовать символы Unicode в именах файлов.
--no-update-modtime Не обновлять время мода назначения, если файлы идентичны.
--order-by string Инструкции по заказу переводов, например 'размер по убыванию'
--password-command SpaceSepList Команда для ввода пароля для зашифрованной конфигурации.
-P, --progress Показать прогресс во время передачи.
--progress-terminal-title Показать прогресс по заголовку терминала.Требуется -P / - progress.
-q, --quiet Печатать как можно меньше материалов
--rc Включить сервер удаленного управления.
--rc-addr string IPaddress: Порт или: Порт для привязки сервера. (по умолчанию "localhost: 5572")
--rc-allow-origin string Установить разрешенное происхождение для CORS.
--rc-baseurl string Префикс для URL-адресов - оставьте поле пустым для root.
--rc-cert string Ключ SSL PEM (объединение сертификата и сертификата CA)
--rc-client-ca строка Центр сертификации клиентов для проверки клиентов с помощью
--rc-enable-metrics Включить метрики prometheus на / metrics
--rc-files string Путь к локальным файлам для обслуживания на HTTP-сервере.--rc-htpasswd string файл htpasswd - если не указан, аутентификация не выполняется
--rc-job-expire-duration duration expire завершенные асинхронные задания старше этого значения (по умолчанию 1 мес.)
--rc-job-expire-interval интервал продолжительности для проверки истекших асинхронных заданий (по умолчанию 10 с)
--rc-key string SSL PEM Закрытый ключ
--rc-max-header-bytes int Максимальный размер заголовка запроса (по умолчанию 4096)
--rc-no-auth Не требует авторизации для некоторых методов. --rc-pass строка Пароль для аутентификации.
--rc-realm строковая область для аутентификации (по умолчанию "rclone")
--rc-serve Включить обслуживание удаленных объектов.
--rc-server-read-timeout duration Тайм-аут для чтения данных сервером (по умолчанию 1h0m0s)
--rc-server-write-timeout duration Тайм-аут для записи данных сервером (по умолчанию 1h0m0s)
--rc-template строка Пользовательский шаблон.--rc-user строка Имя пользователя для аутентификации.
--rc-web-fetch-url строка URL-адрес для получения выпусков для webgui. (по умолчанию "https://api.github.com/repos/rclone/rclone-webui-react/releases/latest")
--rc-web-gui Запустить WebGUI на локальном хосте
--rc-web-gui-force-update Принудительное обновление до последней версии веб-интерфейса.
--rc-web-gui-no-open-browser Не открывать браузер автоматически
--rc-web-gui-update Проверить и обновить веб-интерфейс до последней версии
--refresh-times Обновить время модификации удаленных файлов. --retries int Повторять операции столько раз, если они терпят неудачу (по умолчанию 3)
--retries-sleep duration Интервал между повторными попытками в случае неудачи, например, 500 мс, 60 с, 5 мин. (0 для отключения)
--size-only Пропускать только по размеру, а не по времени модификации или контрольной сумме
--stats duration Интервал между печатью статистики, например 500 мс, 60 с, 5 мин. (0 для отключения) (по умолчанию 1 мин. С)
--stats-file-name-length int Максимальная длина имени файла в статистике.0 без ограничения (по умолчанию 45)
--stats-log-level string Уровень журнала для отображения --stats output DEBUG | INFO | NOTICE | ERROR (по умолчанию "INFO")
--stats-one-line Уместить статистику в одну строку.
--stats-one-line-date Включает --stats-one-line и добавляет префикс текущей даты / времени.
--stats-one-line-date-format string Включает --stats-one-line-date и использует дату в настраиваемом формате. Заключите строку даты в двойные кавычки ("). См. Https://golang.org/pkg/time/#Time.Формат
--stats-unit string Показывать скорость передачи данных в статистике в виде битов или байтов / с (по умолчанию «байты»)
--streaming-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку, если размер файла неизвестен. Загрузка начинается после достижения отсечки или когда файл заканчивается. (по умолчанию 100 КБ)
--suffix string Суффикс для добавления к измененным файлам.
--suffix-keep-extension Сохранить расширение при использовании --suffix.
--syslog Использовать системный журнал для ведения журнала
--syslog-feature string Средство для системного журнала, e.грамм. KERN, USER, ... (по умолчанию "DAEMON")
--timeout duration IO idle timeout (по умолчанию 5 минут)
--tpslimit float Ограничить это количество HTTP-транзакций в секунду.
--tpslimit-burst int Максимальный пакет транзакций для --tpslimit. (по умолчанию 1)
--track-renames При синхронизации отслеживать переименования файлов и, если возможно, выполнять перемещение на стороне сервера
--track-renames-strategy string Стратегии, используемые при синхронизации с использованием хеша для переименования дорожек | modtime | leaf (по умолчанию "хэш")
--transfers int Количество параллельных передач файлов. (по умолчанию 4)
-u, --update Пропускать более новые файлы в месте назначения.
--use-cookies Включить сессию cookiejar.
--use-json-log Использовать формат журнала json.
--use-mmap Использовать распределитель mmap (см. документацию).
--use-server-modtime Использовать время изменения сервера вместо метаданных объекта
--user-agent string Устанавливает пользовательский агент на указанную строку. По умолчанию это rclone / version (по умолчанию «rclone / v1.54,0 ")
-v, --verbose count Печатать много другого материала (повторить еще раз)
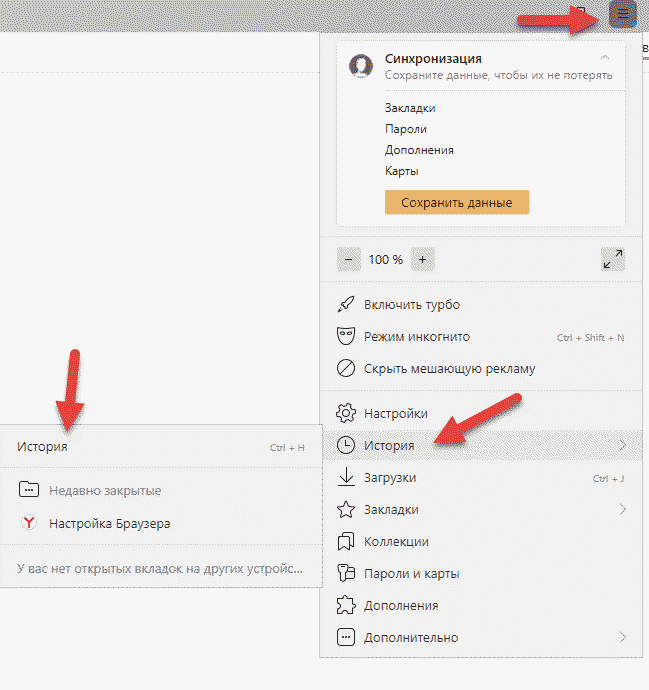 (по умолчанию true)
--auto-confirm Если включено, не запрашивать подтверждение консоли.
--backup-dir string Создавать резервные копии в иерархии на основе DIR.
--bind string Локальный адрес для привязки исходящих соединений, IPv4, IPv6 или имя.
--buffer-size SizeSuffix Размер буфера памяти при чтении файлов для каждого --transfer.(по умолчанию 16M)
--bwlimit BwTimetable Предел пропускной способности в килобайтах / с, или используйте суффикс b | k | M | G или полное расписание.
--bwlimit-file BwTimetable Ограничение пропускной способности файла в кБайт / с, или используйте суффикс b | k | M | G или полное расписание.
--ca-cert string Сертификат ЦС, используемый для проверки серверов
--cache-dir строка Каталог, который rclone будет использовать для кеширования. (по умолчанию "$ HOME / .cache / rclone")
--check-first Выполнить все проверки перед началом передачи.--checkers int Количество чекеров, запускаемых параллельно. (по умолчанию 8)
-c, --checksum Пропускать на основе контрольной суммы (если есть) и размера, а не времени модификации и размера
--client-cert string Клиентский SSL-сертификат (PEM) для взаимной аутентификации TLS
--client-key string Закрытый ключ SSL клиента (PEM) для взаимной аутентификации TLS
--compare-dest string Включить дополнительный путь на стороне сервера во время сравнения.
(по умолчанию true)
--auto-confirm Если включено, не запрашивать подтверждение консоли.
--backup-dir string Создавать резервные копии в иерархии на основе DIR.
--bind string Локальный адрес для привязки исходящих соединений, IPv4, IPv6 или имя.
--buffer-size SizeSuffix Размер буфера памяти при чтении файлов для каждого --transfer.(по умолчанию 16M)
--bwlimit BwTimetable Предел пропускной способности в килобайтах / с, или используйте суффикс b | k | M | G или полное расписание.
--bwlimit-file BwTimetable Ограничение пропускной способности файла в кБайт / с, или используйте суффикс b | k | M | G или полное расписание.
--ca-cert string Сертификат ЦС, используемый для проверки серверов
--cache-dir строка Каталог, который rclone будет использовать для кеширования. (по умолчанию "$ HOME / .cache / rclone")
--check-first Выполнить все проверки перед началом передачи.--checkers int Количество чекеров, запускаемых параллельно. (по умолчанию 8)
-c, --checksum Пропускать на основе контрольной суммы (если есть) и размера, а не времени модификации и размера
--client-cert string Клиентский SSL-сертификат (PEM) для взаимной аутентификации TLS
--client-key string Закрытый ключ SSL клиента (PEM) для взаимной аутентификации TLS
--compare-dest string Включить дополнительный путь на стороне сервера во время сравнения.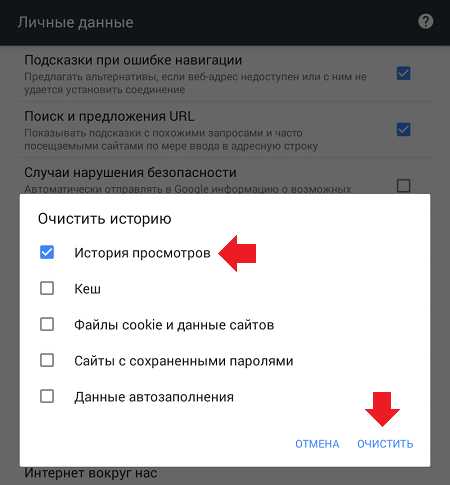 --config string Файл конфигурации. (по умолчанию "$ HOME / .config / rclone / rclone.conf")
--contimeout duration Тайм-аут подключения (по умолчанию 1 мин. с)
--copy-dest string Подразумевает --compare-dest, но также копирует файлы из пути в место назначения.
--cpuprofile string Записать профиль процессора в файл
--cutoff-mode string Режим остановки передачи при достижении максимального лимита передачи HARD | SOFT | CAUTIOUS (по умолчанию "HARD")
--delete-after При синхронизации удалить файлы в месте назначения после передачи (по умолчанию)
--delete-before При синхронизации удалить файлы в месте назначения перед передачей
--delete-during При синхронизации, удалять файлы во время передачи
--delete-excluded Удалять файлы по назначению, исключенные из синхронизации
--disable string Отключить список функций, разделенных запятыми.Используйте справку, чтобы просмотреть список.
-n, --dry-run Выполнить пробный запуск без постоянных изменений
--dump DumpFlags Список элементов для выгрузки: заголовки, тела, запросы, ответы, аутентификация, фильтры, горутины, открытые файлы
--dump-body Дампить заголовки и тела HTTP - может содержать конфиденциальную информацию
--dump-headers Дампить HTTP-заголовки - могут содержать конфиденциальную информацию
--error-on-no-transfer Устанавливает код выхода 9, если файлы не передаются, полезно в скриптах
--exclude stringArray Исключить файлы, соответствующие шаблону
--exclude-from stringArray Чтение шаблонов исключения из файла (используйте - для чтения из стандартного ввода)
--exclude-if-present string Исключить каталоги, если указано имя файла
--expect-continue-timeout duration Тайм-аут при использовании expect / 100-continue в HTTP (по умолчанию 1 с)
--fast-list Использовать рекурсивный список, если он доступен.
--config string Файл конфигурации. (по умолчанию "$ HOME / .config / rclone / rclone.conf")
--contimeout duration Тайм-аут подключения (по умолчанию 1 мин. с)
--copy-dest string Подразумевает --compare-dest, но также копирует файлы из пути в место назначения.
--cpuprofile string Записать профиль процессора в файл
--cutoff-mode string Режим остановки передачи при достижении максимального лимита передачи HARD | SOFT | CAUTIOUS (по умолчанию "HARD")
--delete-after При синхронизации удалить файлы в месте назначения после передачи (по умолчанию)
--delete-before При синхронизации удалить файлы в месте назначения перед передачей
--delete-during При синхронизации, удалять файлы во время передачи
--delete-excluded Удалять файлы по назначению, исключенные из синхронизации
--disable string Отключить список функций, разделенных запятыми.Используйте справку, чтобы просмотреть список.
-n, --dry-run Выполнить пробный запуск без постоянных изменений
--dump DumpFlags Список элементов для выгрузки: заголовки, тела, запросы, ответы, аутентификация, фильтры, горутины, открытые файлы
--dump-body Дампить заголовки и тела HTTP - может содержать конфиденциальную информацию
--dump-headers Дампить HTTP-заголовки - могут содержать конфиденциальную информацию
--error-on-no-transfer Устанавливает код выхода 9, если файлы не передаются, полезно в скриптах
--exclude stringArray Исключить файлы, соответствующие шаблону
--exclude-from stringArray Чтение шаблонов исключения из файла (используйте - для чтения из стандартного ввода)
--exclude-if-present string Исключить каталоги, если указано имя файла
--expect-continue-timeout duration Тайм-аут при использовании expect / 100-continue в HTTP (по умолчанию 1 с)
--fast-list Использовать рекурсивный список, если он доступен. Использует больше памяти, но меньше транзакций.
--files-from stringArray Прочитать список имен исходных файлов из файла (используйте - для чтения из stdin)
--files-from-raw stringArray Прочитать список имен исходных файлов из файла без обработки строк (используйте - для чтения из stdin)
-f, --filter stringArray Добавить правило фильтрации файлов
--filter-from stringArray Чтение шаблонов фильтрации из файла (используйте - для чтения из стандартного ввода)
--header stringArray Установить HTTP-заголовок для всех транзакций
--header-download stringArray Установить HTTP-заголовок для транзакций загрузки
--header-upload stringArray Установить HTTP-заголовок для транзакций загрузки
--ignore-case Игнорировать регистр в фильтрах (без учета регистра)
--ignore-case-sync Игнорировать регистр при синхронизации
--ignore-checkum Пропустить проверку контрольных сумм после копирования.--ignore-errors удалить, даже если есть ошибки ввода / вывода
--ignore-existing Пропустить все файлы, существующие в месте назначения
--ignore-size Игнорировать размер при пропуске использования времени модификации или контрольной суммы.
Использует больше памяти, но меньше транзакций.
--files-from stringArray Прочитать список имен исходных файлов из файла (используйте - для чтения из stdin)
--files-from-raw stringArray Прочитать список имен исходных файлов из файла без обработки строк (используйте - для чтения из stdin)
-f, --filter stringArray Добавить правило фильтрации файлов
--filter-from stringArray Чтение шаблонов фильтрации из файла (используйте - для чтения из стандартного ввода)
--header stringArray Установить HTTP-заголовок для всех транзакций
--header-download stringArray Установить HTTP-заголовок для транзакций загрузки
--header-upload stringArray Установить HTTP-заголовок для транзакций загрузки
--ignore-case Игнорировать регистр в фильтрах (без учета регистра)
--ignore-case-sync Игнорировать регистр при синхронизации
--ignore-checkum Пропустить проверку контрольных сумм после копирования.--ignore-errors удалить, даже если есть ошибки ввода / вывода
--ignore-existing Пропустить все файлы, существующие в месте назначения
--ignore-size Игнорировать размер при пропуске использования времени модификации или контрольной суммы. -I, --ignore-times Не пропускать файлы, совпадающие по размеру и времени - передать все файлы
--immutable Не изменять файлы. Ошибка, если существующие файлы были изменены.
--include stringArray Включить файлы, соответствующие шаблону
--include-from stringArray Чтение шаблонов включения из файла (используйте - для чтения из стандартного ввода)
-i, --interactive Включить интерактивный режим
--log-file string Записывать все в этот файл
--log-format string Список параметров формата журнала, разделенных запятыми (по умолчанию «дата, время»)
--log-level строка Уровень журнала ОТЛАДКА | ИНФОРМАЦИЯ | УВЕДОМЛЕНИЕ | ОШИБКА (по умолчанию "УВЕДОМЛЕНИЕ")
--log-systemd Активировать интеграцию systemd для регистратора.--low-level-retries int Число повторных попыток низкого уровня. (по умолчанию 10)
--max-age Продолжительность Передавать только файлы младше этого в s или суффиксе ms | s | m | h | d | w | M | y (по умолчанию выключено)
--max-backlog int Максимальное количество синхронизируемых или проверяемых объектов.
-I, --ignore-times Не пропускать файлы, совпадающие по размеру и времени - передать все файлы
--immutable Не изменять файлы. Ошибка, если существующие файлы были изменены.
--include stringArray Включить файлы, соответствующие шаблону
--include-from stringArray Чтение шаблонов включения из файла (используйте - для чтения из стандартного ввода)
-i, --interactive Включить интерактивный режим
--log-file string Записывать все в этот файл
--log-format string Список параметров формата журнала, разделенных запятыми (по умолчанию «дата, время»)
--log-level строка Уровень журнала ОТЛАДКА | ИНФОРМАЦИЯ | УВЕДОМЛЕНИЕ | ОШИБКА (по умолчанию "УВЕДОМЛЕНИЕ")
--log-systemd Активировать интеграцию systemd для регистратора.--low-level-retries int Число повторных попыток низкого уровня. (по умолчанию 10)
--max-age Продолжительность Передавать только файлы младше этого в s или суффиксе ms | s | m | h | d | w | M | y (по умолчанию выключено)
--max-backlog int Максимальное количество синхронизируемых или проверяемых объектов. (по умолчанию 10000)
--max-delete int При синхронизации ограничить количество удалений (по умолчанию -1)
--max-depth int Если установлено, ограничивает глубину рекурсии этим.(по умолчанию -1)
--max-duration duration Максимальная продолжительность, в течение которой rclone будет передавать данные.
--max-size SizeSuffix Передавать только файлы меньшего размера в k или суффиксе b | k | M | G (по умолчанию выключено)
--max-stats-groups int Максимальное количество групп статистики для хранения в памяти. На максимуме самое старое отбрасывается. (по умолчанию 1000)
--max-transfer SizeSuffix Максимальный размер передаваемых данных. (по умолчанию выключено)
--memprofile string Записать профиль памяти в файл
--min-age Продолжительность Передавать только файлы старше указанного в s или суффиксе ms | s | m | h | d | w | M | y (по умолчанию выключено)
--min-size SizeSuffix Передавать только файлы большего размера в k или суффиксе b | k | M | G (по умолчанию выключено)
--modify-window duration Максимальная разница во времени, которая считается одинаковой (по умолчанию 1 нс)
--multi-thread-cutoff SizeSuffix Использовать многопоточную загрузку для файлов, размер которых превышает этот размер.
(по умолчанию 10000)
--max-delete int При синхронизации ограничить количество удалений (по умолчанию -1)
--max-depth int Если установлено, ограничивает глубину рекурсии этим.(по умолчанию -1)
--max-duration duration Максимальная продолжительность, в течение которой rclone будет передавать данные.
--max-size SizeSuffix Передавать только файлы меньшего размера в k или суффиксе b | k | M | G (по умолчанию выключено)
--max-stats-groups int Максимальное количество групп статистики для хранения в памяти. На максимуме самое старое отбрасывается. (по умолчанию 1000)
--max-transfer SizeSuffix Максимальный размер передаваемых данных. (по умолчанию выключено)
--memprofile string Записать профиль памяти в файл
--min-age Продолжительность Передавать только файлы старше указанного в s или суффиксе ms | s | m | h | d | w | M | y (по умолчанию выключено)
--min-size SizeSuffix Передавать только файлы большего размера в k или суффиксе b | k | M | G (по умолчанию выключено)
--modify-window duration Максимальная разница во времени, которая считается одинаковой (по умолчанию 1 нс)
--multi-thread-cutoff SizeSuffix Использовать многопоточную загрузку для файлов, размер которых превышает этот размер. (по умолчанию 250 МБ)
--multi-thread-streams int Максимальное количество потоков, используемых для многопоточных загрузок. (по умолчанию 4)
--no-check-certificate Не проверять SSL-сертификат сервера. Ненадежный.
--no-check-dest Не проверять место назначения, копировать все равно.
--no-console Скрыть окно консоли. Поддерживается только в Windows.
--no-gzip-encoding Не устанавливать Accept-Encoding: gzip.
--no-traverse Не проходить через целевую файловую систему при копировании.--no-unicode-normalization Не нормализовать символы Unicode в именах файлов.
--no-update-modtime Не обновлять время мода назначения, если файлы идентичны.
--order-by string Инструкции по заказу переводов, например 'размер по убыванию'
--password-command SpaceSepList Команда для ввода пароля для зашифрованной конфигурации.
-P, --progress Показать прогресс во время передачи.
--progress-terminal-title Показать прогресс по заголовку терминала.Требуется -P / - progress.
(по умолчанию 250 МБ)
--multi-thread-streams int Максимальное количество потоков, используемых для многопоточных загрузок. (по умолчанию 4)
--no-check-certificate Не проверять SSL-сертификат сервера. Ненадежный.
--no-check-dest Не проверять место назначения, копировать все равно.
--no-console Скрыть окно консоли. Поддерживается только в Windows.
--no-gzip-encoding Не устанавливать Accept-Encoding: gzip.
--no-traverse Не проходить через целевую файловую систему при копировании.--no-unicode-normalization Не нормализовать символы Unicode в именах файлов.
--no-update-modtime Не обновлять время мода назначения, если файлы идентичны.
--order-by string Инструкции по заказу переводов, например 'размер по убыванию'
--password-command SpaceSepList Команда для ввода пароля для зашифрованной конфигурации.
-P, --progress Показать прогресс во время передачи.
--progress-terminal-title Показать прогресс по заголовку терминала.Требуется -P / - progress. -q, --quiet Печатать как можно меньше материалов
--rc Включить сервер удаленного управления.
--rc-addr string IPaddress: Порт или: Порт для привязки сервера. (по умолчанию "localhost: 5572")
--rc-allow-origin string Установить разрешенное происхождение для CORS.
--rc-baseurl string Префикс для URL-адресов - оставьте поле пустым для root.
--rc-cert string Ключ SSL PEM (объединение сертификата и сертификата CA)
--rc-client-ca строка Центр сертификации клиентов для проверки клиентов с помощью
--rc-enable-metrics Включить метрики prometheus на / metrics
--rc-files string Путь к локальным файлам для обслуживания на HTTP-сервере.--rc-htpasswd string файл htpasswd - если не указан, аутентификация не выполняется
--rc-job-expire-duration duration expire завершенные асинхронные задания старше этого значения (по умолчанию 1 мес.)
--rc-job-expire-interval интервал продолжительности для проверки истекших асинхронных заданий (по умолчанию 10 с)
--rc-key string SSL PEM Закрытый ключ
--rc-max-header-bytes int Максимальный размер заголовка запроса (по умолчанию 4096)
--rc-no-auth Не требует авторизации для некоторых методов.
-q, --quiet Печатать как можно меньше материалов
--rc Включить сервер удаленного управления.
--rc-addr string IPaddress: Порт или: Порт для привязки сервера. (по умолчанию "localhost: 5572")
--rc-allow-origin string Установить разрешенное происхождение для CORS.
--rc-baseurl string Префикс для URL-адресов - оставьте поле пустым для root.
--rc-cert string Ключ SSL PEM (объединение сертификата и сертификата CA)
--rc-client-ca строка Центр сертификации клиентов для проверки клиентов с помощью
--rc-enable-metrics Включить метрики prometheus на / metrics
--rc-files string Путь к локальным файлам для обслуживания на HTTP-сервере.--rc-htpasswd string файл htpasswd - если не указан, аутентификация не выполняется
--rc-job-expire-duration duration expire завершенные асинхронные задания старше этого значения (по умолчанию 1 мес.)
--rc-job-expire-interval интервал продолжительности для проверки истекших асинхронных заданий (по умолчанию 10 с)
--rc-key string SSL PEM Закрытый ключ
--rc-max-header-bytes int Максимальный размер заголовка запроса (по умолчанию 4096)
--rc-no-auth Не требует авторизации для некоторых методов. --retries int Повторять операции столько раз, если они терпят неудачу (по умолчанию 3)
--retries-sleep duration Интервал между повторными попытками в случае неудачи, например, 500 мс, 60 с, 5 мин. (0 для отключения)
--size-only Пропускать только по размеру, а не по времени модификации или контрольной сумме
--stats duration Интервал между печатью статистики, например 500 мс, 60 с, 5 мин. (0 для отключения) (по умолчанию 1 мин. С)
--stats-file-name-length int Максимальная длина имени файла в статистике.0 без ограничения (по умолчанию 45)
--stats-log-level string Уровень журнала для отображения --stats output DEBUG | INFO | NOTICE | ERROR (по умолчанию "INFO")
--stats-one-line Уместить статистику в одну строку.
--stats-one-line-date Включает --stats-one-line и добавляет префикс текущей даты / времени.
--stats-one-line-date-format string Включает --stats-one-line-date и использует дату в настраиваемом формате. Заключите строку даты в двойные кавычки (").
--retries int Повторять операции столько раз, если они терпят неудачу (по умолчанию 3)
--retries-sleep duration Интервал между повторными попытками в случае неудачи, например, 500 мс, 60 с, 5 мин. (0 для отключения)
--size-only Пропускать только по размеру, а не по времени модификации или контрольной сумме
--stats duration Интервал между печатью статистики, например 500 мс, 60 с, 5 мин. (0 для отключения) (по умолчанию 1 мин. С)
--stats-file-name-length int Максимальная длина имени файла в статистике.0 без ограничения (по умолчанию 45)
--stats-log-level string Уровень журнала для отображения --stats output DEBUG | INFO | NOTICE | ERROR (по умолчанию "INFO")
--stats-one-line Уместить статистику в одну строку.
--stats-one-line-date Включает --stats-one-line и добавляет префикс текущей даты / времени.
--stats-one-line-date-format string Включает --stats-one-line-date и использует дату в настраиваемом формате. Заключите строку даты в двойные кавычки ("). См. Https://golang.org/pkg/time/#Time.Формат
--stats-unit string Показывать скорость передачи данных в статистике в виде битов или байтов / с (по умолчанию «байты»)
--streaming-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку, если размер файла неизвестен. Загрузка начинается после достижения отсечки или когда файл заканчивается. (по умолчанию 100 КБ)
--suffix string Суффикс для добавления к измененным файлам.
--suffix-keep-extension Сохранить расширение при использовании --suffix.
--syslog Использовать системный журнал для ведения журнала
--syslog-feature string Средство для системного журнала, e.грамм. KERN, USER, ... (по умолчанию "DAEMON")
--timeout duration IO idle timeout (по умолчанию 5 минут)
--tpslimit float Ограничить это количество HTTP-транзакций в секунду.
--tpslimit-burst int Максимальный пакет транзакций для --tpslimit. (по умолчанию 1)
--track-renames При синхронизации отслеживать переименования файлов и, если возможно, выполнять перемещение на стороне сервера
--track-renames-strategy string Стратегии, используемые при синхронизации с использованием хеша для переименования дорожек | modtime | leaf (по умолчанию "хэш")
--transfers int Количество параллельных передач файлов.
См. Https://golang.org/pkg/time/#Time.Формат
--stats-unit string Показывать скорость передачи данных в статистике в виде битов или байтов / с (по умолчанию «байты»)
--streaming-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку, если размер файла неизвестен. Загрузка начинается после достижения отсечки или когда файл заканчивается. (по умолчанию 100 КБ)
--suffix string Суффикс для добавления к измененным файлам.
--suffix-keep-extension Сохранить расширение при использовании --suffix.
--syslog Использовать системный журнал для ведения журнала
--syslog-feature string Средство для системного журнала, e.грамм. KERN, USER, ... (по умолчанию "DAEMON")
--timeout duration IO idle timeout (по умолчанию 5 минут)
--tpslimit float Ограничить это количество HTTP-транзакций в секунду.
--tpslimit-burst int Максимальный пакет транзакций для --tpslimit. (по умолчанию 1)
--track-renames При синхронизации отслеживать переименования файлов и, если возможно, выполнять перемещение на стороне сервера
--track-renames-strategy string Стратегии, используемые при синхронизации с использованием хеша для переименования дорожек | modtime | leaf (по умолчанию "хэш")
--transfers int Количество параллельных передач файлов. (по умолчанию 4)
-u, --update Пропускать более новые файлы в месте назначения.
--use-cookies Включить сессию cookiejar.
--use-json-log Использовать формат журнала json.
--use-mmap Использовать распределитель mmap (см. документацию).
--use-server-modtime Использовать время изменения сервера вместо метаданных объекта
--user-agent string Устанавливает пользовательский агент на указанную строку. По умолчанию это rclone / version (по умолчанию «rclone / v1.54,0 ")
-v, --verbose count Печатать много другого материала (повторить еще раз)
(по умолчанию 4)
-u, --update Пропускать более новые файлы в месте назначения.
--use-cookies Включить сессию cookiejar.
--use-json-log Использовать формат журнала json.
--use-mmap Использовать распределитель mmap (см. документацию).
--use-server-modtime Использовать время изменения сервера вместо метаданных объекта
--user-agent string Устанавливает пользовательский агент на указанную строку. По умолчанию это rclone / version (по умолчанию «rclone / v1.54,0 ")
-v, --verbose count Печатать много другого материала (повторить еще раз)
Backend Flags
Эти флаги доступны для каждой команды. Они контролируют бэкенды и может быть установлен в файле конфигурации.
--acd-auth-url string URL-адрес сервера аутентификации.
--acd-client-id строка Идентификатор клиента OAuth
--acd-client-secret строка Секрет клиента OAuth
--acd-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, InvalidUtf8, точка)
--acd-templink-threshold SizeSuffix Files> = этот размер будет загружен через их tempLink. (по умолчанию 9G)
--acd-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--acd-token-url строка URL-адрес сервера токена.
--acd-upload-wait-per-gb Продолжительность Дополнительное время ожидания на ГБ после неудачной полной загрузки, чтобы увидеть, появится ли она.(по умолчанию 3 мин.)
--alias-remote строка Remote или путь к псевдониму.
--azureblob-access-tier string Уровень доступа к BLOB-объекту: горячий, холодный или архивный.
--azureblob-account строка Имя учетной записи хранения (оставьте поле пустым, чтобы использовать URL-адрес SAS или эмулятор)
--azureblob-archive-tier-delete Удалять большие двоичные объекты уровня архива перед перезаписью.
--azureblob-chunk-size SizeSuffix Размер загружаемого фрагмента (<= 100 МБ).(по умолчанию 4M)
--azureblob-disable-checkum Не сохранять контрольную сумму MD5 с метаданными объекта.
--azureblob-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, обратная косая черта, Del, Ctl, RightPeriod, InvalidUtf8)
--azureblob-endpoint строка Конечная точка для службы
--azureblob-key строка Ключ учетной записи хранения (оставьте поле пустым, чтобы использовать URL-адрес SAS или эмулятор)
--azureblob-list-chunk int Размер списка больших двоичных объектов. (по умолчанию 5000)
--azureblob-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--azureblob-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.
--azureblob-msi-client-id строка Идентификатор объекта назначенного пользователем MSI для использования, если таковой имеется. Оставьте поле пустым, если указано msi_object_id или msi_mi_res_id.
--azureblob-msi-mi-res-id строка Идентификатор ресурса Azure для назначенного пользователем MSI, если таковой имеется.Оставьте поле пустым, если указано msi_client_id или msi_object_id.
--azureblob-msi-object-id строка Идентификатор объекта назначенного пользователем MSI для использования, если таковой имеется. Оставьте поле пустым, если указано msi_client_id или msi_mi_res_id.
--azureblob-sas-url string URL-адрес SAS только для доступа на уровне контейнера
--azureblob-service-Principal-file string Путь к файлу, содержащему учетные данные для использования с субъектом службы. --azureblob-upload-cutoff string Отсечка для переключения на фрагментированную загрузку (<= 256 МБ).(Не рекомендуется)
--azureblob-use-emulator Использует эмулятор локального хранилища, если задано значение true (оставьте поле пустым, если используется реальная конечная точка хранилища Azure)
--azureblob-use-msi Использовать удостоверение управляемой службы для аутентификации (работает только в Azure)
--b2-account string Идентификатор учетной записи или идентификатор ключа приложения
--b2-chunk-size SizeSuffix Размер загружаемого фрагмента. Должен уместиться в памяти.(по умолчанию 96M)
--b2-copy-cutoff SizeSuffix Cutoff для переключения на многостраничное копирование (по умолчанию 4G)
--b2-disable-checkum Отключить контрольные суммы для больших (> загружаемых обрезанных) файлов.
--b2-download-auth-duration Продолжительность Время до истечения срока действия токена авторизации в секундах или суффиксе ms | s | m | h | d. (по умолчанию 1 нед. )
--b2-download-url string Пользовательская конечная точка для загрузок.
--b2-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--b2-endpoint string Конечная точка для службы.
--b2-hard-delete Безвозвратно удалить файлы при удаленном удалении, в противном случае скрыть файлы.
--b2-key строка Ключ приложения
--b2-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--b2-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.--b2-test-mode string Строка флага для заголовка X-Bz-Test-Mode для отладки.
--b2-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку. (по умолчанию 200M)
--b2-versions Включить старые версии в списки каталогов.
--box-access-token строка Первичный токен доступа приложения Box
--box-auth-url строка URL-адрес сервера аутентификации. --box-box-config-file строка Расположение Box App config.json
--box-box-sub-type строка (по умолчанию "пользователь")
--box-client-id строка Идентификатор клиента OAuth
--box-client-secret строка Секрет клиента OAuth
--box-commit-retries int Максимальное количество попыток фиксации составного файла. (по умолчанию 100)
--box-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, RightSpace, InvalidUtf8, Dot)
--box-root-folder-id строка Заполните для rclone, чтобы использовать некорневую папку в качестве начальной точки.
--box-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--box-token-url строка URL-адрес сервера токена.
--box-upload-cutoff SizeSuffix Cutoff для переключения на многостраничную загрузку (> = 50 МБ). (по умолчанию 50M)
--cache-chunk-clean-interval Продолжительность Как часто кеш должен выполнять очистку хранилища фрагментов.(по умолчанию 1 мин. 0 сек.)
--cache-chunk-no-memory Отключить кеш в памяти для хранения фрагментов во время потоковой передачи.
--cache-chunk-path строка Каталог для кеширования файлов фрагментов. (по умолчанию "$ HOME / .cache / rclone / cache-backend")
--cache-chunk-size SizeSuffix Размер блока (частичные данные файла). (по умолчанию 5M)
--cache-chunk-total-size SizeSuffix Общий размер, который блоки могут занимать на локальном диске.(по умолчанию 10 г)
--cache-db-path строка Каталог для хранения БД метаданных файловой структуры. (по умолчанию "$ HOME / .cache / rclone / cache-backend")
--cache-db-purge Очистить все кэшированные данные для этого пульта дистанционного управления при запуске.
--cache-db-wait-time Продолжительность Как долго ждать, пока БД станет доступной - 0 не ограничено (по умолчанию 1 с)
--cache-info-age Продолжительность Как долго кэшировать информацию о структуре файла (списки каталогов, размер файла, время и т. д.)). (по умолчанию 6h0m0s)
--cache-plex-insecure string Пропустить все проверки сертификатов при подключении к серверу Plex
--cache-plex-password string Пароль пользователя Plex (скрыт)
--cache-plex-url string URL-адрес сервера Plex. --cache-plex-username строка Имя пользователя Plex.
--cache-read-retries int Сколько раз повторять попытку чтения из кеш-хранилища.(по умолчанию 10)
--cache-remote string Удаленное кеширование.
--cache-rps int Ограничивает количество запросов в секунду к исходной FS (-1 для отключения) (по умолчанию -1)
--cache-tmp-upload-path строка Каталог для хранения временных файлов до их загрузки.
--cache-tmp-wait-time Продолжительность Как долго файлы должны храниться в локальном кеше перед загрузкой (по умолчанию 15 с)
--cache-worker int Сколько воркеров должно работать параллельно для загрузки чанков.(по умолчанию 4)
--cache-пишет Кэшировать данные файла при записи через ФС
--chunker-chunk-size SizeSuffix Файлы, размер которых превышает размер блока, будут разделены на блоки. (по умолчанию 2G)
--chunker-fail-hard Выберите, как chunker должен обрабатывать файлы с отсутствующими или недопустимыми фрагментами.
--chunker-hash-type string Выберите, как chunker обрабатывает хеш-суммы. Все режимы, кроме «none», требуют метаданных.(по умолчанию "md5")
--chunker-remote string Удаленное разделение на фрагменты / снятие фрагментов.
--compress-level int уровень сжатия GZIP (от -2 до 9). (по умолчанию -1)
--compress-mode string Режим сжатия. (по умолчанию "gzip")
--compress-ram-cache-limit SizeSuffix Некоторые пульты дистанционного управления не позволяют загружать файлы неизвестного размера. (по умолчанию 20M)
--compress-remote string Удаленное сжатие.-L, --copy-links Переходить по символическим ссылкам и копировать указанный элемент.
--crypt-directory-name-encryption Параметр, позволяющий либо зашифровать имена каталогов, либо оставить их нетронутыми. (по умолчанию true)
--crypt-filename-encryption string Как зашифровать имена файлов. (по умолчанию "стандарт")
--crypt-password string Пароль или контрольная фраза для шифрования. (затемнено)
--crypt-password2 строка Пароль или парольная фраза для соли.Необязательно, но рекомендуется. (затемнено)
--crypt-remote string Удаленное шифрование / дешифрование.
--crypt-server-side-through-configs Разрешить серверным операциям (например, копированию) работать с разными конфигурациями криптографии.
--crypt-show-mapping Для всех перечисленных файлов показать, как их имена шифруются.
--drive -cknowledge-abuse Устанавливает, чтобы разрешить загрузку файлов, которые возвращают cannotDownloadAbusiveFile.--drive-allow-import-name-change Разрешить изменение типа файла при загрузке документов Google (например, file.doc в file.docx). Это будет сбивать с толку синхронизацию и повторную загрузку каждый раз.
--drive-auth-owner-only Учитывать только файлы, принадлежащие аутентифицированному пользователю.
--drive-auth-url строка URL-адрес сервера аутентификации.
--drive-chunk-size SizeSuffix Размер загружаемого фрагмента. Должна быть степень 2> = 256k.(по умолчанию 8M)
--drive-client-id строка Идентификатор клиента приложения Google
--drive-client-secret строка Секрет клиента OAuth
--drive-disable-http2 Отключить диск с использованием http2 (по умолчанию true)
--drive-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию InvalidUtf8)
--drive-export-sizes строка Список разделенных запятыми предпочтительных форматов для загрузки документов Google.(по умолчанию "docx, xlsx, pptx, svg")
--drive-sizes строка Не рекомендуется: см. export_formats
--drive-impersonate string Выдача себя за этого пользователя при использовании учетной записи службы.
--drive-import-sizes строка Список разделенных запятыми предпочтительных форматов для загрузки документов Google.
--drive-keep-revision-forever Сохранять новую головную ревизию каждого файла навсегда.
--drive-list-chunk int Размер листинга 100-1000.0 для отключения. (по умолчанию 1000)
--drive-pacer-burst int Количество вызовов API, разрешенных без сна. (по умолчанию 100)
--drive-pacer-min-sleep Продолжительность Минимальное время ожидания между вызовами API. (по умолчанию 100 мс)
--drive-root-folder-id строка ID корневой папки
--drive-scope string Область, которую rclone должен использовать при запросе доступа с диска. --drive-server-side-through-configs Разрешить серверные операции (например,грамм. copy) для работы с разными конфигурациями дисков.
--drive-service-account-credentials строка Учетные данные учетной записи службы JSON blob
--drive-service-account-file строка Учетные данные учетной записи службы Путь к файлу JSON
--drive-shared-with-me Показывать только те файлы, к которым мне предоставлен доступ.
--drive-size-as-quota Показывать размеры как использование квоты хранилища, а не фактический размер.
--drive-skip-checkum-gphotos Пропускать контрольную сумму MD5 только для фото и видео Google.--drive-skip-gdocs Пропускать документы Google во всех списках.
--drive-skip-shortcuts Если установлено, пропускать файлы ярлыков
--drive-starred-only Показывать только файлы, помеченные звездочкой.
--drive-stop-on-download-limit Сделать ошибки ограничения загрузки фатальными
--drive-stop-on-upload-limit Сделать ошибки ограничения загрузки фатальными
--drive-team-drive строковый идентификатор общего диска
--drive-token string Токен доступа OAuth в виде большого двоичного объекта JSON. --drive-token-url строка URL-адрес сервера токена.
--drive-trashed-only Показывать только файлы, находящиеся в корзине.
--drive-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 8M)
--drive-use-created-date Использовать дату создания файла вместо даты изменения.,
--drive-use-shared-date Использовать дату публикации файла вместо даты изменения.--drive-use-trash Отправлять файлы в корзину вместо окончательного удаления. (по умолчанию true)
--drive-v2-download-min-size SizeSuffix Если Object больше, используйте для загрузки drive v2 API. (по умолчанию выключено)
--dropbox-auth-url строка URL-адрес сервера аутентификации.
--dropbox-chunk-size SizeSuffix Размер загружаемого фрагмента. (<150 млн). (по умолчанию 48M)
--dropbox-client-id строка Идентификатор клиента OAuth
--dropbox-client-secret строка Секрет клиента OAuth
--dropbox-encoding MultiEncoder Устанавливает кодировку для бэкэнда.(по умолчанию Slash, BackSlash, Del, RightSpace, InvalidUtf8, Dot)
--dropbox-impersonate string Выдача себя за этого пользователя при использовании бизнес-аккаунта. --dropbox-shared-files Указывает rclone работать с отдельными общими файлами.
--dropbox-shared-folder Указывает rclone работать с общими папками.
--dropbox-token string Токен доступа OAuth в виде большого двоичного объекта JSON.--dropbox-token-url строка URL-адрес сервера токена.
--fichier-api-key string Ваш ключ API, получите его с https://1fichier.com/console/params.pl
--fichier-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, SingleQuote, BackQuote, Dollar, BackSlash, Del, Ctl, LeftSpace, RightSpace, InvalidUtf8, Dot)
--fichier-shared-folder строка Если вы хотите загрузить общую папку, добавьте этот параметр
--filefabric-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Del, Ctl, InvalidUtf8, Dot)
--filefabric-constant-token строка Постоянный токен аутентификации
--filefabric-root-folder-id строка ID корневой папки
--filefabric-token строка Токен сеанса
--filefabric-token-expiry string Срок действия токена
--filefabric-url string URL-адрес Enterprise File Fabric для подключения
--filefabric-version строка Версия, прочитанная из файловой структуры
--ftp-concurrency int Максимальное количество одновременных FTP-подключений, 0 для неограниченного
--ftp-disable-epsv Отключить использование EPSV, даже если сервер объявляет о поддержке
--ftp-disable-mlsd Отключить использование MLSD, даже если сервер объявляет о поддержке
--ftp-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, Del, Ctl, RightSpace, Dot)
--ftp-explicit-tls Использовать явный FTPS (FTP через TLS)
--ftp-host строка FTP-хост для подключения
--ftp-no-check-certificate Не проверять TLS-сертификат сервера.
--ftp-pass строка Пароль FTP (скрыто)
--ftp-port строка Порт FTP, оставьте поле пустым, чтобы использовать значение по умолчанию (21)
--ftp-tls Использовать неявный FTPS (FTP через TLS)
--ftp-user строка Имя пользователя FTP, оставьте поле пустым для текущего имени пользователя, $ USER
--gcs-anonymous Доступ к публичным корзинам и объектам без учетных данных
--gcs-auth-url строка URL-адрес сервера аутентификации.--gcs-bucket-acl строка Список контроля доступа для новых корзин.
--gcs-bucket-policy-only Проверки доступа должны использовать IAM-политики на уровне корзины.
--gcs-client-id строка Идентификатор клиента OAuth
--gcs-client-secret string Секрет клиента OAuth
--gcs-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, CrLf, InvalidUtf8, точка)
--gcs-location string Расположение вновь созданных сегментов.--gcs-object-acl string Список контроля доступа для новых объектов.
--gcs-project-number строка Номер проекта.
--gcs-service-account-file строка Учетные данные учетной записи службы Путь к файлу JSON
--gcs-storage-class string Класс хранения, используемый при хранении объектов в Google Cloud Storage.
--gcs-token string Токен доступа OAuth в виде большого двоичного объекта JSON.--gcs-token-url string URL-адрес сервера токена.
--gphotos-auth-url строка URL-адрес сервера аутентификации.
--gphotos-client-id строка Идентификатор клиента OAuth
--gphotos-client-secret строка Секрет клиента OAuth
--gphotos-include-archived Также просматривать и скачивать заархивированные медиафайлы.
--gphotos-read-only Сделать серверную часть Google Фото доступной только для чтения.--gphotos-read-size Устанавливает для чтения размера мультимедийных элементов.
--gphotos-start-year int Год ограничивает загружаемые фотографии теми, которые загружаются после указанного года (по умолчанию 2000)
--gphotos-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--gphotos-token-url string URL-адрес сервера токена.
--hdfs-data-transfer-protection string Защита передачи данных Kerberos: аутентификация | целостность | конфиденциальность
--hdfs-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, Colon, Del, Ctl, InvalidUtf8, Dot)
--hdfs-namenode строка имя hasoop имени узла и порта
--hdfs-service-Principal-name строка Имя участника-службы Kerberos для узла имени
--hdfs-username string имя пользователя hadoop
--http-headers CommaSepList Установить заголовки HTTP для всех транзакций
--http-no-head Не использовать запросы HEAD для поиска размеров файлов в списке каталогов
--http-no-slash Установите это, если сайт не заканчивает каталоги с /
--http-url строка URL-адрес http-хоста для подключения
--hubic-auth-url строка URL-адрес сервера аутентификации.--hubic-chunk-size SizeSuffix Файлы, размер которых превышает этот размер, будут помещены в контейнер _segments. (по умолчанию 5G)
--hubic-client-id строка Идентификатор клиента OAuth
--hubic-client-secret строка Секрет клиента OAuth
--hubic-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8)
--hubic-no-chunk Не разбивать файлы во время потоковой загрузки.--hubic-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--hubic-token-url строка URL-адрес сервера токена.
--jottacloud-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, Del, Ctl, InvalidUtf8, Dot)
--jottacloud-hard-delete Удалить файлы навсегда, а не помещать их в корзину.--jottacloud-md5-memory-limit SizeSuffix Файлы большего размера будут кэшироваться на диске для расчета MD5, если это необходимо. (по умолчанию 10M)
--jottacloud-trashed-only Показывать только файлы, находящиеся в корзине.
--jottacloud-upload-resume-limit SizeSuffix Файлы большего размера могут быть возобновлены в случае сбоя загрузки. (по умолчанию 10M)
--koofr-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--koofr-endpoint string Конечная точка API Koofr для использования (по умолчанию «https://app.koofr.net»)
--koofr-mountid string Идентификатор используемого монтирования. Если не указано, используется основное крепление.
--koofr-password string Ваш пароль Koofr для rclone (сгенерируйте его на https://app.koofr.net/app/admin/preferences/password) (скрыто)
--koofr-setmtime Поддерживает ли серверная часть время изменения настроек.Установите значение false, если вы используете идентификатор монтирования, указывающий на серверную часть Dropbox или Amazon Drive. (по умолчанию true)
--koofr-user строка Ваше имя пользователя Koofr
-l, --links Переводить символические ссылки в / из обычных файлов с расширением '.rclonelink'
--local-case-indensitive Заставить файловую систему сообщать о себе как нечувствительность к регистру
--local-case-sensitive Заставить файловую систему сообщать о том, что она чувствительна к регистру.--local-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, точка)
--local-no-check-updated Не проверять, изменяются ли файлы во время загрузки
--local-no-set-modtime Отключить установку времени мода
--local-no-sparse Отключить разреженные файлы для многопоточной загрузки
--local-no-unicode-normalization Не применять нормализацию Unicode к путям и именам файлов (устарело)
--local-nounc string Отключить преобразование UNC (длинные имена путей) в Windows
--local-zero-size-links Предположить, что размер статистики ссылок равен нулю (и вместо этого прочтите их)
--mailru-check-hash Что делать копии, если контрольная сумма файла не соответствует или недействительна (по умолчанию true)
--mailru-encoding MultiEncoder Устанавливает кодировку для бэкэнда.(по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--mailru-pass строка Пароль (скрыто)
--mailru-speedup-enable Пропустить полную загрузку, если есть другой файл с таким же хешем данных. (по умолчанию true)
--mailru-speedup-file-patterns строка Список разделенных запятыми шаблонов имен файлов, которые могут быть ускорены (помещены с помощью хеша). (по умолчанию "* .mkv, *. avi, *. mp4, *. mp3, *.zip, *. gz, *. rar, *. pdf ")
--mailru-speedup-max-disk SizeSuffix Этот параметр позволяет отключить ускорение (ставится по хешу) для больших файлов (по умолчанию 3G)
--mailru-speedup-max-memory SizeSuffix Файлы, размер которых превышает указанный ниже размер, всегда будут хешироваться на диске. (по умолчанию 32M)
--mailru-user строка Имя пользователя (обычно электронная почта)
--mega-debug Вывести дополнительную отладку из Mega.--mega-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8, точка)
--mega-hard-delete Удалять файлы навсегда, а не помещать их в корзину.
--mega-pass строка Пароль. (затемнено)
--mega-user строка Имя пользователя
-x, --one-file-system Не пересекать границы файловой системы (только unix / macOS).--onedrive-auth-url строка URL-адрес сервера аутентификации.
--onedrive-chunk-size SizeSuffix Размер блока для загрузки файлов - должен быть кратен 320 КБ (327 680 байт). (по умолчанию 10M)
--onedrive-client-id строка Идентификатор клиента OAuth
--onedrive-client-secret строка Секрет клиента OAuth
--onedrive-drive-id строка Идентификатор используемого диска.
--onedrive-drive-type строка Тип диска (личный | бизнес | documentLibrary)
--onedrive-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Del, Ctl, LeftSpace, LeftTilde, RightSpace, RightPeriod, InvalidUtf8, Dot)
--onedrive-expose-onenote-files Установить, чтобы файлы OneNote отображались в списках каталогов.
--onedrive-link-password строка Установить пароль для ссылок, созданных командой link.
--onedrive-link-scope строка Установить область ссылок, создаваемых командой ссылки.(по умолчанию "анонимный")
--onedrive-link-type строка Установить тип ссылок, создаваемых командой ссылки. (вид по умолчанию")
--onedrive-no-versions Удалять все версии при изменении операций
--onedrive-region строка Выберите национальный облачный регион для OneDrive. (по умолчанию "глобальный")
--onedrive-server-side-through-configs Разрешить серверным операциям (например, копированию) работать с разными конфигурациями onedrive.--onedrive-token строка Токен доступа OAuth в виде большого двоичного объекта JSON.
--onedrive-token-url строка URL-адрес сервера токена.
--opendrive-chunk-size SizeSuffix Файлы будут загружаться кусками этого размера. (по умолчанию 10M)
--opendrive-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, LeftSpace, LeftCrLfHtVt, RightSpace, RightCrLfHtVt, InvalidUtf8, Dot)
--opendrive-пароль строка Пароль.(затемнено)
--opendrive-username строка Имя пользователя
--pcloud-auth-url строка URL-адрес сервера аутентификации.
--pcloud-client-id строка Идентификатор клиента OAuth
--pcloud-client-secret строка Секрет клиента OAuth
--pcloud-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--pcloud-hostname строка Имя хоста для подключения.(по умолчанию "api.pcloud.com")
--pcloud-root-folder-id строка Заполните rclone, чтобы использовать некорневую папку в качестве начальной точки. (по умолчанию "d0")
--pcloud-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--pcloud-token-url строка URL-адрес сервера токена.
--premiumizeme-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, DoubleQuote, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--putio-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--qingstor-access-key-id строка Идентификатор ключа доступа QingStor
--qingstor-chunk-size SizeSuffix Размер блока для загрузки. (по умолчанию 4M)
--qingstor-connection-retries int Количество попыток подключения. (по умолчанию 3)
--qingstor-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, Ctl, InvalidUtf8)
--qingstor-endpoint string Введите URL-адрес конечной точки для подключения QingStor API.--qingstor-env-auth Получить учетные данные QingStor из среды выполнения. Применяется, только если access_key_id и secret_access_key пустые.
--qingstor-secret-access-key строка Секретный ключ доступа QingStor (пароль)
--qingstor-upload-concurrency int Параллелизм для многокомпонентных загрузок. (по умолчанию 1)
--qingstor-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 200M)
--qingstor-zone string Зона для подключения.--s3-access-key-id строка Идентификатор ключа доступа AWS.
--s3-acl string Постоянный список контроля доступа, используемый при создании сегментов, а также при хранении или копировании объектов.
--s3-bucket-acl string Стандартный список контроля доступа, используемый при создании корзин.
--s3-chunk-size SizeSuffix Размер блока для загрузки. (по умолчанию 5M)
--s3-copy-cutoff SizeSuffix Cutoff для переключения на многостраничное копирование (по умолчанию 4.656G)
--s3-disable-checkum Не сохранять контрольную сумму MD5 с метаданными объекта
--s3-disable-http2 Отключить использование http2 для бэкэндов S3
--s3-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8, точка)
--s3-endpoint string Конечная точка для S3 API.
--s3-env-auth Получить учетные данные AWS из среды выполнения (переменные среды или метаданные EC2 / ECS, если переменных окружения нет).--s3-force-path-style Если true, использовать стиль доступа, если false, использовать виртуальный размещенный стиль. (по умолчанию true)
--s3-leave-parts-on-error Если true, избегать вызова прерывания загрузки в случае сбоя, оставляя все успешно загруженные части на S3 для ручного восстановления.
--s3-list-chunk int Размер блока листинга (список ответов для каждого запроса ListObject S3). (по умолчанию 1000)
--s3-location-constraint string Ограничение местоположения - должно быть установлено, чтобы соответствовать региону.--s3-max-upload-parts int Максимальное количество частей в многокомпонентной загрузке. (по умолчанию 10000)
--s3-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--s3-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.
--s3-no-check-bucket Если установлено, не пытаться проверять, существует ли сегмент, или создавать его.
--s3-no-head Если установлено, не ЗАГЛАВАТЬ загруженные объекты для проверки целостности
--s3-profile string Профиль для использования в файле общих учетных данных
--s3-provider string Выберите своего провайдера S3.--s3-region строка Регион для подключения.
--s3-Requester-pays Включает опцию оплаты запрашивающей стороны при взаимодействии с корзиной S3.
--s3-secret-access-key строка AWS Secret Access Key (пароль)
--s3-server-side-encryption string Алгоритм шифрования на стороне сервера, используемый при сохранении этого объекта в S3.
--s3-session-token string Токен сеанса AWS
--s3-shared-credentials-file string Путь к файлу общих учетных данных
--s3-sse-customer-algorithm строка При использовании SSE-C алгоритм шифрования на стороне сервера, используемый при сохранении этого объекта в S3.--s3-sse-customer-key string При использовании SSE-C вы должны предоставить секретный ключ шифрования, используемый для шифрования / дешифрования ваших данных.
--s3-sse-customer-key-md5 строка При использовании SSE-C вы можете указать контрольную сумму MD5 секретного ключа шифрования (необязательно).
--s3-sse-kms-key-id string При использовании KMS ID необходимо предоставить ARN ключа.
--s3-storage-class строка Класс хранения, используемый при сохранении новых объектов в S3.--s3-upload-concurrency int Параллелизм для многокомпонентных загрузок. (по умолчанию 4)
--s3-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 200M)
--s3-use-accelerate-endpoint Если true, использовать ускоренную конечную точку AWS S3.
--s3-v2-auth Если true, использовать аутентификацию v2.
--seafile-2fa Двухфакторная аутентификация ('true', если в учетной записи включена двухфакторная аутентификация)
--seafile-create-library Должен ли rclone создать библиотеку, если она не существует
--seafile-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, DoubleQuote, BackSlash, Ctl, InvalidUtf8)
--seafile-library string Имя библиотеки. Оставьте поле пустым, чтобы получить доступ ко всем незашифрованным библиотекам.
--seafile-library-key строка Пароль библиотеки (только для зашифрованных библиотек). Оставьте поле пустым, если вы передаете его через командную строку. (затемнено)
--seafile-pass строка Пароль (скрыто)
--seafile-url строка URL-адрес хоста seafile для подключения
--seafile-user строка Имя пользователя (обычно адрес электронной почты)
--sftp-ask-password Разрешить запрашивать пароль SFTP при необходимости.--sftp-disable-hashcheck Отключить выполнение команд SSH, чтобы определить, доступно ли удаленное хеширование файлов.
--sftp-host строка SSH-хост для подключения
--sftp-key-file string Путь к файлу закрытого ключа в кодировке PEM, оставьте поле пустым или установите key-use-agent для использования ssh-agent.
--sftp-key-file-pass строка Кодовая фраза для расшифровки файла закрытого ключа в формате PEM.(затемнено)
--sftp-key-pem string Необработанный закрытый ключ в кодировке PEM, если он указан, переопределит параметр key_file.
--sftp-key-use-agent При установке принудительно использовать ssh-agent.
--sftp-known-hosts-file строка Необязательный путь к файлу known_hosts.
--sftp-md5sum-command string Команда, используемая для чтения хэшей md5. Оставьте поле пустым для автоматического определения.
--sftp-pass строка Пароль SSH, оставьте поле пустым, чтобы использовать ssh-agent.(затемнено)
--sftp-path-override string Переопределить путь, используемый SSH-соединением.
--sftp-port строка Порт SSH, оставьте поле пустым, чтобы использовать значение по умолчанию (22)
--sftp-pubkey-file string Необязательный путь к файлу открытого ключа.
--sftp-server-command строка Задает путь или команду для запуска sftp-сервера на удаленном хосте.
--sftp-set-modtime Установить измененное время на пульте дистанционного управления, если установлено.(по умолчанию true)
--sftp-sha1sum-command string Команда, используемая для чтения хэшей sha1. Оставьте поле пустым для автоматического определения.
--sftp-skip-links Устанавливает пропуск любых символических ссылок и любых других нестандартных файлов.
--sftp-subsystem string Задает подсистему SSh3 на удаленном хосте. (по умолчанию "sftp")
--sftp-use-fstat Если установлено, использовать fstat вместо stat
--sftp-use-insecure-cipher Разрешить использование незащищенных шифров и методов обмена ключами.--sftp-user string Имя пользователя SSH, оставьте поле пустым для текущего имени пользователя, $ USER
--sharefile-chunk-size SizeSuffix Размер загружаемого фрагмента. Должна быть степень 2> = 256k. (по умолчанию 64M)
--sharefile-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Ctl, LeftSpace, LeftPeriod, RightSpace, RightPeriod, InvalidUtf8, Dot)
--sharefile-endpoint string Конечная точка для вызовов API.--sharefile-root-folder-id строка ID корневой папки
--sharefile-upload-cutoff SizeSuffix Cutoff для переключения на многостраничную загрузку. (по умолчанию 128M)
--skip-links Не предупреждать о пропущенных символических ссылках.
--sugarsync-access-key-id строка Sugarsync Access Key ID.
--sugarsync-app-id строка Идентификатор приложения Sugarsync.
--sugarsync-authorization строка Sugarsync авторизация
--sugarsync-authorization-expiry string Срок действия авторизации Sugarsync
--sugarsync-deleted-id строка Идентификатор удаленной папки Sugarsync
--sugarsync-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Ctl, InvalidUtf8, Dot)
--sugarsync-hard-delete Безвозвратно удалить файлы, если true
--sugarsync-private-access-key строка Sugarsync Private Access Key
--sugarsync-refresh-token строка Маркер обновления Sugarsync
--sugarsync-root-id строка Sugarsync root id
--sugarsync-user строка Пользователь Sugarsync
--swift-application-credential-id строка Идентификатор учетных данных приложения (OS_APPLICATION_CREDENTIAL_ID)
--swift-application-credential-name строка Имя учетных данных приложения (OS_APPLICATION_CREDENTIAL_NAME)
--swift-application-credential-secret строка Секрет учетных данных приложения (OS_APPLICATION_CREDENTIAL_SECRET)
--swift-auth string URL аутентификации для сервера (OS_AUTH_URL).--swift-auth-token string Токен аутентификации из альтернативной аутентификации - необязательно (OS_AUTH_TOKEN)
--swift-auth-version int AuthVersion - необязательно - установите значение (1,2,3), если ваш URL-адрес авторизации не имеет версии (ST_AUTH_VERSION)
--swift-chunk-size SizeSuffix Файлы, размер которых превышает этот размер, будут помещены в контейнер _segments. (по умолчанию 5G)
--swift-domain строка Пользовательский домен - необязательно (v3 auth) (OS_USER_DOMAIN_NAME)
--swift-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, InvalidUtf8)
--swift-endpoint-type string Тип конечной точки для выбора из каталога услуг (OS_ENDPOINT_TYPE) (по умолчанию "общедоступный")
--swift-env-auth Получить быстрые учетные данные из переменных среды в стандартной форме OpenStack.
--swift-key string Ключ API или пароль (OS_PASSWORD).
--swift-leave-parts-on-error Если true, избегать вызова прерывания загрузки в случае сбоя.Для возобновления загрузки в разные сеансы необходимо установить значение true.
--swift-no-chunk Не разбивать файлы во время потоковой загрузки.
--swift-region строка Имя региона - необязательно (OS_REGION_NAME)
--swift-storage-policy строка Политика хранения, используемая при создании нового контейнера.
--swift-storage-url строка URL-адрес хранилища - необязательно (OS_STORAGE_URL)
--swift-tenant string Имя клиента - необязательно для аутентификации v1, в противном случае требуется this или tenant_id (OS_TENANT_NAME или OS_PROJECT_NAME)
--swift-tenant-domain строка Домен клиента - необязательно (v3 auth) (OS_PROJECT_DOMAIN_NAME)
--swift-tenant-id строка Tenant ID - необязательно для аутентификации v1, в противном случае требуется этот или тенант (OS_TENANT_ID)
--swift-user строка Имя пользователя для входа (OS_USERNAME).--swift-user-id строка Идентификатор пользователя для входа - необязательно - большинство быстрых систем используют пользователя и оставляют это поле пустым (v3 auth) (OS_USER_ID).
--tardigrade-access-grant строка Разрешение доступа.
--tardigrade-api-key строка API-ключ.
--tardigrade-passphrase строка Кодовая фраза шифрования. Для доступа к существующим объектам введите парольную фразу, используемую для загрузки.
--tardigrade-provider строка Выберите метод аутентификации.(по умолчанию "существующий")
--tardigrade-satellite-address @ : Адрес спутника. Пользовательский спутниковый адрес должен соответствовать формату: @ : . (по умолчанию "us-central-1.tardigrade.io")
--union-action-policy строка Политика выбора восходящего потока в категории ACTION. (по умолчанию "epall")
--union-cache-time int Время использования кеша и свободное место (в секундах). Эта опция полезна только при использовании политики сохранения пути.(по умолчанию 120)
--union-create-policy string Политика выбора восходящего потока в категории CREATE. (по умолчанию "epmfs")
--union-search-policy строка Политика выбора восходящего потока в категории ПОИСК. (по умолчанию "ff")
--union-upstreams строка Список восходящих потоков, разделенных пробелом.
--webdav-bearer-token строка Токен на предъявителя вместо user / pass (например, Macaroon)
--webdav-bearer-token-command string Команда для запуска для получения токена на предъявителя
--webdav-pass строка Пароль.(затемнено)
--webdav-url строка URL-адрес http-хоста для подключения
--webdav-user строка Имя пользователя
--webdav-vendor string Имя сайта / службы / программного обеспечения Webdav, которое вы используете
--yandex-auth-url строка URL-адрес сервера аутентификации.
--yandex-client-id строка Идентификатор клиента OAuth
--yandex-client-secret строка Секрет клиента OAuth
--yandex-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Del, Ctl, InvalidUtf8, Dot)
--yandex-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--yandex-token-url строка URL-адрес сервера токена.  (по умолчанию 9G)
--acd-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--acd-token-url строка URL-адрес сервера токена.
--acd-upload-wait-per-gb Продолжительность Дополнительное время ожидания на ГБ после неудачной полной загрузки, чтобы увидеть, появится ли она.(по умолчанию 3 мин.)
--alias-remote строка Remote или путь к псевдониму.
--azureblob-access-tier string Уровень доступа к BLOB-объекту: горячий, холодный или архивный.
--azureblob-account строка Имя учетной записи хранения (оставьте поле пустым, чтобы использовать URL-адрес SAS или эмулятор)
--azureblob-archive-tier-delete Удалять большие двоичные объекты уровня архива перед перезаписью.
--azureblob-chunk-size SizeSuffix Размер загружаемого фрагмента (<= 100 МБ).(по умолчанию 4M)
--azureblob-disable-checkum Не сохранять контрольную сумму MD5 с метаданными объекта.
--azureblob-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, обратная косая черта, Del, Ctl, RightPeriod, InvalidUtf8)
--azureblob-endpoint строка Конечная точка для службы
--azureblob-key строка Ключ учетной записи хранения (оставьте поле пустым, чтобы использовать URL-адрес SAS или эмулятор)
--azureblob-list-chunk int Размер списка больших двоичных объектов.
(по умолчанию 9G)
--acd-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--acd-token-url строка URL-адрес сервера токена.
--acd-upload-wait-per-gb Продолжительность Дополнительное время ожидания на ГБ после неудачной полной загрузки, чтобы увидеть, появится ли она.(по умолчанию 3 мин.)
--alias-remote строка Remote или путь к псевдониму.
--azureblob-access-tier string Уровень доступа к BLOB-объекту: горячий, холодный или архивный.
--azureblob-account строка Имя учетной записи хранения (оставьте поле пустым, чтобы использовать URL-адрес SAS или эмулятор)
--azureblob-archive-tier-delete Удалять большие двоичные объекты уровня архива перед перезаписью.
--azureblob-chunk-size SizeSuffix Размер загружаемого фрагмента (<= 100 МБ).(по умолчанию 4M)
--azureblob-disable-checkum Не сохранять контрольную сумму MD5 с метаданными объекта.
--azureblob-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, обратная косая черта, Del, Ctl, RightPeriod, InvalidUtf8)
--azureblob-endpoint строка Конечная точка для службы
--azureblob-key строка Ключ учетной записи хранения (оставьте поле пустым, чтобы использовать URL-адрес SAS или эмулятор)
--azureblob-list-chunk int Размер списка больших двоичных объектов. (по умолчанию 5000)
--azureblob-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--azureblob-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.
--azureblob-msi-client-id строка Идентификатор объекта назначенного пользователем MSI для использования, если таковой имеется. Оставьте поле пустым, если указано msi_object_id или msi_mi_res_id.
--azureblob-msi-mi-res-id строка Идентификатор ресурса Azure для назначенного пользователем MSI, если таковой имеется.Оставьте поле пустым, если указано msi_client_id или msi_object_id.
--azureblob-msi-object-id строка Идентификатор объекта назначенного пользователем MSI для использования, если таковой имеется. Оставьте поле пустым, если указано msi_client_id или msi_mi_res_id.
--azureblob-sas-url string URL-адрес SAS только для доступа на уровне контейнера
--azureblob-service-Principal-file string Путь к файлу, содержащему учетные данные для использования с субъектом службы.
(по умолчанию 5000)
--azureblob-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--azureblob-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.
--azureblob-msi-client-id строка Идентификатор объекта назначенного пользователем MSI для использования, если таковой имеется. Оставьте поле пустым, если указано msi_object_id или msi_mi_res_id.
--azureblob-msi-mi-res-id строка Идентификатор ресурса Azure для назначенного пользователем MSI, если таковой имеется.Оставьте поле пустым, если указано msi_client_id или msi_object_id.
--azureblob-msi-object-id строка Идентификатор объекта назначенного пользователем MSI для использования, если таковой имеется. Оставьте поле пустым, если указано msi_client_id или msi_mi_res_id.
--azureblob-sas-url string URL-адрес SAS только для доступа на уровне контейнера
--azureblob-service-Principal-file string Путь к файлу, содержащему учетные данные для использования с субъектом службы. --azureblob-upload-cutoff string Отсечка для переключения на фрагментированную загрузку (<= 256 МБ).(Не рекомендуется)
--azureblob-use-emulator Использует эмулятор локального хранилища, если задано значение true (оставьте поле пустым, если используется реальная конечная точка хранилища Azure)
--azureblob-use-msi Использовать удостоверение управляемой службы для аутентификации (работает только в Azure)
--b2-account string Идентификатор учетной записи или идентификатор ключа приложения
--b2-chunk-size SizeSuffix Размер загружаемого фрагмента. Должен уместиться в памяти.(по умолчанию 96M)
--b2-copy-cutoff SizeSuffix Cutoff для переключения на многостраничное копирование (по умолчанию 4G)
--b2-disable-checkum Отключить контрольные суммы для больших (> загружаемых обрезанных) файлов.
--b2-download-auth-duration Продолжительность Время до истечения срока действия токена авторизации в секундах или суффиксе ms | s | m | h | d. (по умолчанию 1 нед.
--azureblob-upload-cutoff string Отсечка для переключения на фрагментированную загрузку (<= 256 МБ).(Не рекомендуется)
--azureblob-use-emulator Использует эмулятор локального хранилища, если задано значение true (оставьте поле пустым, если используется реальная конечная точка хранилища Azure)
--azureblob-use-msi Использовать удостоверение управляемой службы для аутентификации (работает только в Azure)
--b2-account string Идентификатор учетной записи или идентификатор ключа приложения
--b2-chunk-size SizeSuffix Размер загружаемого фрагмента. Должен уместиться в памяти.(по умолчанию 96M)
--b2-copy-cutoff SizeSuffix Cutoff для переключения на многостраничное копирование (по умолчанию 4G)
--b2-disable-checkum Отключить контрольные суммы для больших (> загружаемых обрезанных) файлов.
--b2-download-auth-duration Продолжительность Время до истечения срока действия токена авторизации в секундах или суффиксе ms | s | m | h | d. (по умолчанию 1 нед.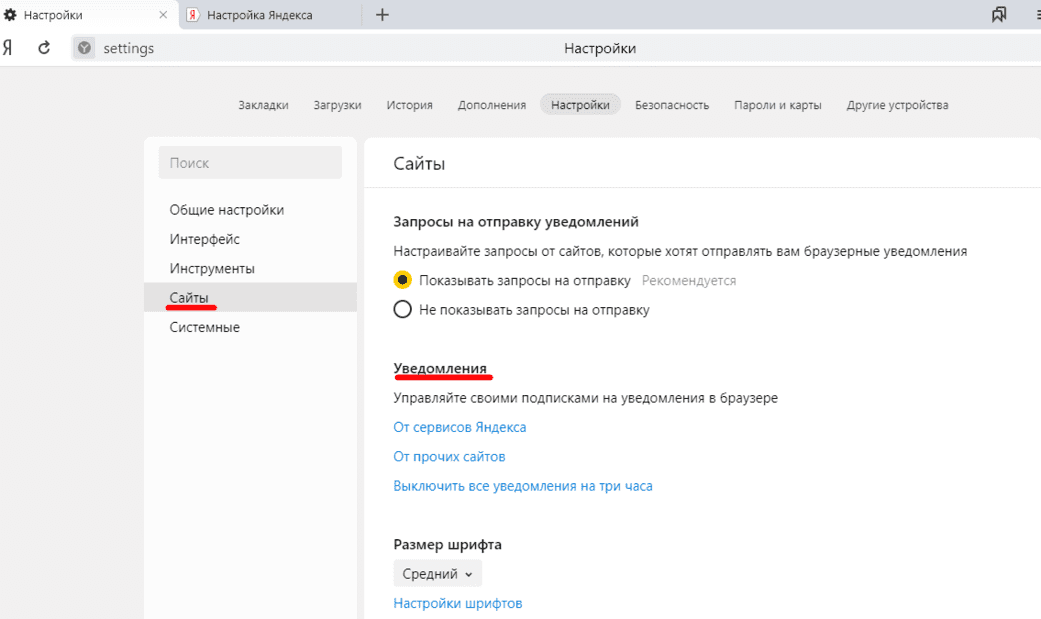 )
--b2-download-url string Пользовательская конечная точка для загрузок.
--b2-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--b2-endpoint string Конечная точка для службы.
--b2-hard-delete Безвозвратно удалить файлы при удаленном удалении, в противном случае скрыть файлы.
--b2-key строка Ключ приложения
--b2-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--b2-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.--b2-test-mode string Строка флага для заголовка X-Bz-Test-Mode для отладки.
--b2-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку. (по умолчанию 200M)
--b2-versions Включить старые версии в списки каталогов.
--box-access-token строка Первичный токен доступа приложения Box
--box-auth-url строка URL-адрес сервера аутентификации.
)
--b2-download-url string Пользовательская конечная точка для загрузок.
--b2-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--b2-endpoint string Конечная точка для службы.
--b2-hard-delete Безвозвратно удалить файлы при удаленном удалении, в противном случае скрыть файлы.
--b2-key строка Ключ приложения
--b2-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--b2-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.--b2-test-mode string Строка флага для заголовка X-Bz-Test-Mode для отладки.
--b2-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку. (по умолчанию 200M)
--b2-versions Включить старые версии в списки каталогов.
--box-access-token строка Первичный токен доступа приложения Box
--box-auth-url строка URL-адрес сервера аутентификации. --box-box-config-file строка Расположение Box App config.json
--box-box-sub-type строка (по умолчанию "пользователь")
--box-client-id строка Идентификатор клиента OAuth
--box-client-secret строка Секрет клиента OAuth
--box-commit-retries int Максимальное количество попыток фиксации составного файла. (по умолчанию 100)
--box-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, RightSpace, InvalidUtf8, Dot)
--box-root-folder-id строка Заполните для rclone, чтобы использовать некорневую папку в качестве начальной точки.
--box-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--box-token-url строка URL-адрес сервера токена.
--box-upload-cutoff SizeSuffix Cutoff для переключения на многостраничную загрузку (> = 50 МБ). (по умолчанию 50M)
--cache-chunk-clean-interval Продолжительность Как часто кеш должен выполнять очистку хранилища фрагментов.(по умолчанию 1 мин.
--box-box-config-file строка Расположение Box App config.json
--box-box-sub-type строка (по умолчанию "пользователь")
--box-client-id строка Идентификатор клиента OAuth
--box-client-secret строка Секрет клиента OAuth
--box-commit-retries int Максимальное количество попыток фиксации составного файла. (по умолчанию 100)
--box-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, RightSpace, InvalidUtf8, Dot)
--box-root-folder-id строка Заполните для rclone, чтобы использовать некорневую папку в качестве начальной точки.
--box-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--box-token-url строка URL-адрес сервера токена.
--box-upload-cutoff SizeSuffix Cutoff для переключения на многостраничную загрузку (> = 50 МБ). (по умолчанию 50M)
--cache-chunk-clean-interval Продолжительность Как часто кеш должен выполнять очистку хранилища фрагментов.(по умолчанию 1 мин. 0 сек.)
--cache-chunk-no-memory Отключить кеш в памяти для хранения фрагментов во время потоковой передачи.
--cache-chunk-path строка Каталог для кеширования файлов фрагментов. (по умолчанию "$ HOME / .cache / rclone / cache-backend")
--cache-chunk-size SizeSuffix Размер блока (частичные данные файла). (по умолчанию 5M)
--cache-chunk-total-size SizeSuffix Общий размер, который блоки могут занимать на локальном диске.(по умолчанию 10 г)
--cache-db-path строка Каталог для хранения БД метаданных файловой структуры. (по умолчанию "$ HOME / .cache / rclone / cache-backend")
--cache-db-purge Очистить все кэшированные данные для этого пульта дистанционного управления при запуске.
--cache-db-wait-time Продолжительность Как долго ждать, пока БД станет доступной - 0 не ограничено (по умолчанию 1 с)
--cache-info-age Продолжительность Как долго кэшировать информацию о структуре файла (списки каталогов, размер файла, время и т. д.)). (по умолчанию 6h0m0s)
--cache-plex-insecure string Пропустить все проверки сертификатов при подключении к серверу Plex
--cache-plex-password string Пароль пользователя Plex (скрыт)
--cache-plex-url string URL-адрес сервера Plex.
0 сек.)
--cache-chunk-no-memory Отключить кеш в памяти для хранения фрагментов во время потоковой передачи.
--cache-chunk-path строка Каталог для кеширования файлов фрагментов. (по умолчанию "$ HOME / .cache / rclone / cache-backend")
--cache-chunk-size SizeSuffix Размер блока (частичные данные файла). (по умолчанию 5M)
--cache-chunk-total-size SizeSuffix Общий размер, который блоки могут занимать на локальном диске.(по умолчанию 10 г)
--cache-db-path строка Каталог для хранения БД метаданных файловой структуры. (по умолчанию "$ HOME / .cache / rclone / cache-backend")
--cache-db-purge Очистить все кэшированные данные для этого пульта дистанционного управления при запуске.
--cache-db-wait-time Продолжительность Как долго ждать, пока БД станет доступной - 0 не ограничено (по умолчанию 1 с)
--cache-info-age Продолжительность Как долго кэшировать информацию о структуре файла (списки каталогов, размер файла, время и т. д.)). (по умолчанию 6h0m0s)
--cache-plex-insecure string Пропустить все проверки сертификатов при подключении к серверу Plex
--cache-plex-password string Пароль пользователя Plex (скрыт)
--cache-plex-url string URL-адрес сервера Plex. --cache-plex-username строка Имя пользователя Plex.
--cache-read-retries int Сколько раз повторять попытку чтения из кеш-хранилища.(по умолчанию 10)
--cache-remote string Удаленное кеширование.
--cache-rps int Ограничивает количество запросов в секунду к исходной FS (-1 для отключения) (по умолчанию -1)
--cache-tmp-upload-path строка Каталог для хранения временных файлов до их загрузки.
--cache-tmp-wait-time Продолжительность Как долго файлы должны храниться в локальном кеше перед загрузкой (по умолчанию 15 с)
--cache-worker int Сколько воркеров должно работать параллельно для загрузки чанков.(по умолчанию 4)
--cache-пишет Кэшировать данные файла при записи через ФС
--chunker-chunk-size SizeSuffix Файлы, размер которых превышает размер блока, будут разделены на блоки. (по умолчанию 2G)
--chunker-fail-hard Выберите, как chunker должен обрабатывать файлы с отсутствующими или недопустимыми фрагментами.
--chunker-hash-type string Выберите, как chunker обрабатывает хеш-суммы.
--cache-plex-username строка Имя пользователя Plex.
--cache-read-retries int Сколько раз повторять попытку чтения из кеш-хранилища.(по умолчанию 10)
--cache-remote string Удаленное кеширование.
--cache-rps int Ограничивает количество запросов в секунду к исходной FS (-1 для отключения) (по умолчанию -1)
--cache-tmp-upload-path строка Каталог для хранения временных файлов до их загрузки.
--cache-tmp-wait-time Продолжительность Как долго файлы должны храниться в локальном кеше перед загрузкой (по умолчанию 15 с)
--cache-worker int Сколько воркеров должно работать параллельно для загрузки чанков.(по умолчанию 4)
--cache-пишет Кэшировать данные файла при записи через ФС
--chunker-chunk-size SizeSuffix Файлы, размер которых превышает размер блока, будут разделены на блоки. (по умолчанию 2G)
--chunker-fail-hard Выберите, как chunker должен обрабатывать файлы с отсутствующими или недопустимыми фрагментами.
--chunker-hash-type string Выберите, как chunker обрабатывает хеш-суммы. Все режимы, кроме «none», требуют метаданных.(по умолчанию "md5")
--chunker-remote string Удаленное разделение на фрагменты / снятие фрагментов.
--compress-level int уровень сжатия GZIP (от -2 до 9). (по умолчанию -1)
--compress-mode string Режим сжатия. (по умолчанию "gzip")
--compress-ram-cache-limit SizeSuffix Некоторые пульты дистанционного управления не позволяют загружать файлы неизвестного размера. (по умолчанию 20M)
--compress-remote string Удаленное сжатие.-L, --copy-links Переходить по символическим ссылкам и копировать указанный элемент.
--crypt-directory-name-encryption Параметр, позволяющий либо зашифровать имена каталогов, либо оставить их нетронутыми. (по умолчанию true)
--crypt-filename-encryption string Как зашифровать имена файлов. (по умолчанию "стандарт")
--crypt-password string Пароль или контрольная фраза для шифрования. (затемнено)
--crypt-password2 строка Пароль или парольная фраза для соли.Необязательно, но рекомендуется.
Все режимы, кроме «none», требуют метаданных.(по умолчанию "md5")
--chunker-remote string Удаленное разделение на фрагменты / снятие фрагментов.
--compress-level int уровень сжатия GZIP (от -2 до 9). (по умолчанию -1)
--compress-mode string Режим сжатия. (по умолчанию "gzip")
--compress-ram-cache-limit SizeSuffix Некоторые пульты дистанционного управления не позволяют загружать файлы неизвестного размера. (по умолчанию 20M)
--compress-remote string Удаленное сжатие.-L, --copy-links Переходить по символическим ссылкам и копировать указанный элемент.
--crypt-directory-name-encryption Параметр, позволяющий либо зашифровать имена каталогов, либо оставить их нетронутыми. (по умолчанию true)
--crypt-filename-encryption string Как зашифровать имена файлов. (по умолчанию "стандарт")
--crypt-password string Пароль или контрольная фраза для шифрования. (затемнено)
--crypt-password2 строка Пароль или парольная фраза для соли.Необязательно, но рекомендуется.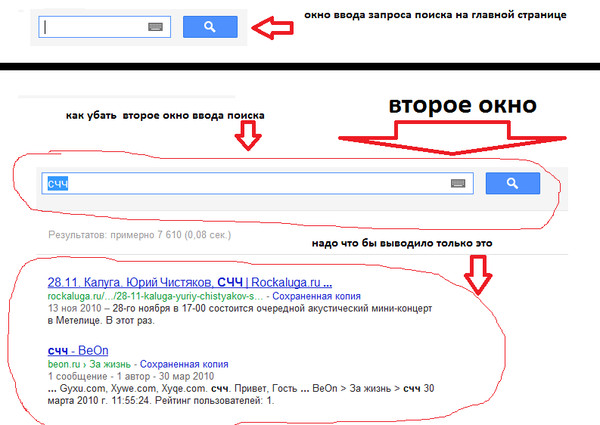 (затемнено)
--crypt-remote string Удаленное шифрование / дешифрование.
--crypt-server-side-through-configs Разрешить серверным операциям (например, копированию) работать с разными конфигурациями криптографии.
--crypt-show-mapping Для всех перечисленных файлов показать, как их имена шифруются.
--drive -cknowledge-abuse Устанавливает, чтобы разрешить загрузку файлов, которые возвращают cannotDownloadAbusiveFile.--drive-allow-import-name-change Разрешить изменение типа файла при загрузке документов Google (например, file.doc в file.docx). Это будет сбивать с толку синхронизацию и повторную загрузку каждый раз.
--drive-auth-owner-only Учитывать только файлы, принадлежащие аутентифицированному пользователю.
--drive-auth-url строка URL-адрес сервера аутентификации.
--drive-chunk-size SizeSuffix Размер загружаемого фрагмента. Должна быть степень 2> = 256k.(по умолчанию 8M)
--drive-client-id строка Идентификатор клиента приложения Google
--drive-client-secret строка Секрет клиента OAuth
--drive-disable-http2 Отключить диск с использованием http2 (по умолчанию true)
--drive-encoding MultiEncoder Устанавливает кодировку для серверной части.
(затемнено)
--crypt-remote string Удаленное шифрование / дешифрование.
--crypt-server-side-through-configs Разрешить серверным операциям (например, копированию) работать с разными конфигурациями криптографии.
--crypt-show-mapping Для всех перечисленных файлов показать, как их имена шифруются.
--drive -cknowledge-abuse Устанавливает, чтобы разрешить загрузку файлов, которые возвращают cannotDownloadAbusiveFile.--drive-allow-import-name-change Разрешить изменение типа файла при загрузке документов Google (например, file.doc в file.docx). Это будет сбивать с толку синхронизацию и повторную загрузку каждый раз.
--drive-auth-owner-only Учитывать только файлы, принадлежащие аутентифицированному пользователю.
--drive-auth-url строка URL-адрес сервера аутентификации.
--drive-chunk-size SizeSuffix Размер загружаемого фрагмента. Должна быть степень 2> = 256k.(по умолчанию 8M)
--drive-client-id строка Идентификатор клиента приложения Google
--drive-client-secret строка Секрет клиента OAuth
--drive-disable-http2 Отключить диск с использованием http2 (по умолчанию true)
--drive-encoding MultiEncoder Устанавливает кодировку для серверной части.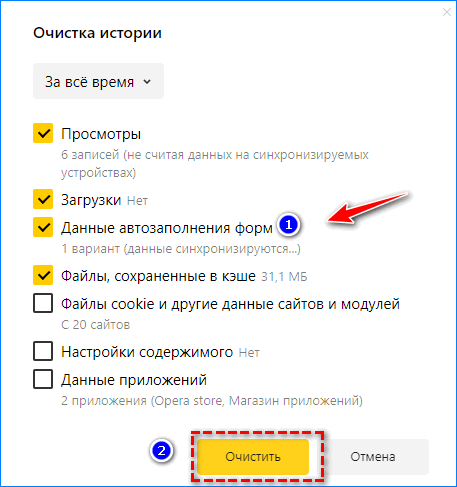 (по умолчанию InvalidUtf8)
--drive-export-sizes строка Список разделенных запятыми предпочтительных форматов для загрузки документов Google.(по умолчанию "docx, xlsx, pptx, svg")
--drive-sizes строка Не рекомендуется: см. export_formats
--drive-impersonate string Выдача себя за этого пользователя при использовании учетной записи службы.
--drive-import-sizes строка Список разделенных запятыми предпочтительных форматов для загрузки документов Google.
--drive-keep-revision-forever Сохранять новую головную ревизию каждого файла навсегда.
--drive-list-chunk int Размер листинга 100-1000.0 для отключения. (по умолчанию 1000)
--drive-pacer-burst int Количество вызовов API, разрешенных без сна. (по умолчанию 100)
--drive-pacer-min-sleep Продолжительность Минимальное время ожидания между вызовами API. (по умолчанию 100 мс)
--drive-root-folder-id строка ID корневой папки
--drive-scope string Область, которую rclone должен использовать при запросе доступа с диска.
(по умолчанию InvalidUtf8)
--drive-export-sizes строка Список разделенных запятыми предпочтительных форматов для загрузки документов Google.(по умолчанию "docx, xlsx, pptx, svg")
--drive-sizes строка Не рекомендуется: см. export_formats
--drive-impersonate string Выдача себя за этого пользователя при использовании учетной записи службы.
--drive-import-sizes строка Список разделенных запятыми предпочтительных форматов для загрузки документов Google.
--drive-keep-revision-forever Сохранять новую головную ревизию каждого файла навсегда.
--drive-list-chunk int Размер листинга 100-1000.0 для отключения. (по умолчанию 1000)
--drive-pacer-burst int Количество вызовов API, разрешенных без сна. (по умолчанию 100)
--drive-pacer-min-sleep Продолжительность Минимальное время ожидания между вызовами API. (по умолчанию 100 мс)
--drive-root-folder-id строка ID корневой папки
--drive-scope string Область, которую rclone должен использовать при запросе доступа с диска. --drive-server-side-through-configs Разрешить серверные операции (например,грамм. copy) для работы с разными конфигурациями дисков.
--drive-service-account-credentials строка Учетные данные учетной записи службы JSON blob
--drive-service-account-file строка Учетные данные учетной записи службы Путь к файлу JSON
--drive-shared-with-me Показывать только те файлы, к которым мне предоставлен доступ.
--drive-size-as-quota Показывать размеры как использование квоты хранилища, а не фактический размер.
--drive-skip-checkum-gphotos Пропускать контрольную сумму MD5 только для фото и видео Google.--drive-skip-gdocs Пропускать документы Google во всех списках.
--drive-skip-shortcuts Если установлено, пропускать файлы ярлыков
--drive-starred-only Показывать только файлы, помеченные звездочкой.
--drive-stop-on-download-limit Сделать ошибки ограничения загрузки фатальными
--drive-stop-on-upload-limit Сделать ошибки ограничения загрузки фатальными
--drive-team-drive строковый идентификатор общего диска
--drive-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--drive-server-side-through-configs Разрешить серверные операции (например,грамм. copy) для работы с разными конфигурациями дисков.
--drive-service-account-credentials строка Учетные данные учетной записи службы JSON blob
--drive-service-account-file строка Учетные данные учетной записи службы Путь к файлу JSON
--drive-shared-with-me Показывать только те файлы, к которым мне предоставлен доступ.
--drive-size-as-quota Показывать размеры как использование квоты хранилища, а не фактический размер.
--drive-skip-checkum-gphotos Пропускать контрольную сумму MD5 только для фото и видео Google.--drive-skip-gdocs Пропускать документы Google во всех списках.
--drive-skip-shortcuts Если установлено, пропускать файлы ярлыков
--drive-starred-only Показывать только файлы, помеченные звездочкой.
--drive-stop-on-download-limit Сделать ошибки ограничения загрузки фатальными
--drive-stop-on-upload-limit Сделать ошибки ограничения загрузки фатальными
--drive-team-drive строковый идентификатор общего диска
--drive-token string Токен доступа OAuth в виде большого двоичного объекта JSON. --drive-token-url строка URL-адрес сервера токена.
--drive-trashed-only Показывать только файлы, находящиеся в корзине.
--drive-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 8M)
--drive-use-created-date Использовать дату создания файла вместо даты изменения.,
--drive-use-shared-date Использовать дату публикации файла вместо даты изменения.--drive-use-trash Отправлять файлы в корзину вместо окончательного удаления. (по умолчанию true)
--drive-v2-download-min-size SizeSuffix Если Object больше, используйте для загрузки drive v2 API. (по умолчанию выключено)
--dropbox-auth-url строка URL-адрес сервера аутентификации.
--dropbox-chunk-size SizeSuffix Размер загружаемого фрагмента. (<150 млн). (по умолчанию 48M)
--dropbox-client-id строка Идентификатор клиента OAuth
--dropbox-client-secret строка Секрет клиента OAuth
--dropbox-encoding MultiEncoder Устанавливает кодировку для бэкэнда.(по умолчанию Slash, BackSlash, Del, RightSpace, InvalidUtf8, Dot)
--dropbox-impersonate string Выдача себя за этого пользователя при использовании бизнес-аккаунта.
--drive-token-url строка URL-адрес сервера токена.
--drive-trashed-only Показывать только файлы, находящиеся в корзине.
--drive-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 8M)
--drive-use-created-date Использовать дату создания файла вместо даты изменения.,
--drive-use-shared-date Использовать дату публикации файла вместо даты изменения.--drive-use-trash Отправлять файлы в корзину вместо окончательного удаления. (по умолчанию true)
--drive-v2-download-min-size SizeSuffix Если Object больше, используйте для загрузки drive v2 API. (по умолчанию выключено)
--dropbox-auth-url строка URL-адрес сервера аутентификации.
--dropbox-chunk-size SizeSuffix Размер загружаемого фрагмента. (<150 млн). (по умолчанию 48M)
--dropbox-client-id строка Идентификатор клиента OAuth
--dropbox-client-secret строка Секрет клиента OAuth
--dropbox-encoding MultiEncoder Устанавливает кодировку для бэкэнда.(по умолчанию Slash, BackSlash, Del, RightSpace, InvalidUtf8, Dot)
--dropbox-impersonate string Выдача себя за этого пользователя при использовании бизнес-аккаунта. --dropbox-shared-files Указывает rclone работать с отдельными общими файлами.
--dropbox-shared-folder Указывает rclone работать с общими папками.
--dropbox-token string Токен доступа OAuth в виде большого двоичного объекта JSON.--dropbox-token-url строка URL-адрес сервера токена.
--fichier-api-key string Ваш ключ API, получите его с https://1fichier.com/console/params.pl
--fichier-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, SingleQuote, BackQuote, Dollar, BackSlash, Del, Ctl, LeftSpace, RightSpace, InvalidUtf8, Dot)
--fichier-shared-folder строка Если вы хотите загрузить общую папку, добавьте этот параметр
--filefabric-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Del, Ctl, InvalidUtf8, Dot)
--filefabric-constant-token строка Постоянный токен аутентификации
--filefabric-root-folder-id строка ID корневой папки
--filefabric-token строка Токен сеанса
--filefabric-token-expiry string Срок действия токена
--filefabric-url string URL-адрес Enterprise File Fabric для подключения
--filefabric-version строка Версия, прочитанная из файловой структуры
--ftp-concurrency int Максимальное количество одновременных FTP-подключений, 0 для неограниченного
--ftp-disable-epsv Отключить использование EPSV, даже если сервер объявляет о поддержке
--ftp-disable-mlsd Отключить использование MLSD, даже если сервер объявляет о поддержке
--ftp-encoding MultiEncoder Устанавливает кодировку для серверной части.
--dropbox-shared-files Указывает rclone работать с отдельными общими файлами.
--dropbox-shared-folder Указывает rclone работать с общими папками.
--dropbox-token string Токен доступа OAuth в виде большого двоичного объекта JSON.--dropbox-token-url строка URL-адрес сервера токена.
--fichier-api-key string Ваш ключ API, получите его с https://1fichier.com/console/params.pl
--fichier-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, SingleQuote, BackQuote, Dollar, BackSlash, Del, Ctl, LeftSpace, RightSpace, InvalidUtf8, Dot)
--fichier-shared-folder строка Если вы хотите загрузить общую папку, добавьте этот параметр
--filefabric-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Del, Ctl, InvalidUtf8, Dot)
--filefabric-constant-token строка Постоянный токен аутентификации
--filefabric-root-folder-id строка ID корневой папки
--filefabric-token строка Токен сеанса
--filefabric-token-expiry string Срок действия токена
--filefabric-url string URL-адрес Enterprise File Fabric для подключения
--filefabric-version строка Версия, прочитанная из файловой структуры
--ftp-concurrency int Максимальное количество одновременных FTP-подключений, 0 для неограниченного
--ftp-disable-epsv Отключить использование EPSV, даже если сервер объявляет о поддержке
--ftp-disable-mlsd Отключить использование MLSD, даже если сервер объявляет о поддержке
--ftp-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, Del, Ctl, RightSpace, Dot)
--ftp-explicit-tls Использовать явный FTPS (FTP через TLS)
--ftp-host строка FTP-хост для подключения
--ftp-no-check-certificate Не проверять TLS-сертификат сервера.
--ftp-pass строка Пароль FTP (скрыто)
--ftp-port строка Порт FTP, оставьте поле пустым, чтобы использовать значение по умолчанию (21)
--ftp-tls Использовать неявный FTPS (FTP через TLS)
--ftp-user строка Имя пользователя FTP, оставьте поле пустым для текущего имени пользователя, $ USER
--gcs-anonymous Доступ к публичным корзинам и объектам без учетных данных
--gcs-auth-url строка URL-адрес сервера аутентификации.--gcs-bucket-acl строка Список контроля доступа для новых корзин.
--gcs-bucket-policy-only Проверки доступа должны использовать IAM-политики на уровне корзины.
--gcs-client-id строка Идентификатор клиента OAuth
--gcs-client-secret string Секрет клиента OAuth
--gcs-encoding MultiEncoder Устанавливает кодировку для серверной части.
(по умолчанию Slash, Del, Ctl, RightSpace, Dot)
--ftp-explicit-tls Использовать явный FTPS (FTP через TLS)
--ftp-host строка FTP-хост для подключения
--ftp-no-check-certificate Не проверять TLS-сертификат сервера.
--ftp-pass строка Пароль FTP (скрыто)
--ftp-port строка Порт FTP, оставьте поле пустым, чтобы использовать значение по умолчанию (21)
--ftp-tls Использовать неявный FTPS (FTP через TLS)
--ftp-user строка Имя пользователя FTP, оставьте поле пустым для текущего имени пользователя, $ USER
--gcs-anonymous Доступ к публичным корзинам и объектам без учетных данных
--gcs-auth-url строка URL-адрес сервера аутентификации.--gcs-bucket-acl строка Список контроля доступа для новых корзин.
--gcs-bucket-policy-only Проверки доступа должны использовать IAM-политики на уровне корзины.
--gcs-client-id строка Идентификатор клиента OAuth
--gcs-client-secret string Секрет клиента OAuth
--gcs-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, CrLf, InvalidUtf8, точка)
--gcs-location string Расположение вновь созданных сегментов.--gcs-object-acl string Список контроля доступа для новых объектов.
--gcs-project-number строка Номер проекта.
--gcs-service-account-file строка Учетные данные учетной записи службы Путь к файлу JSON
--gcs-storage-class string Класс хранения, используемый при хранении объектов в Google Cloud Storage.
--gcs-token string Токен доступа OAuth в виде большого двоичного объекта JSON.--gcs-token-url string URL-адрес сервера токена.
--gphotos-auth-url строка URL-адрес сервера аутентификации.
--gphotos-client-id строка Идентификатор клиента OAuth
--gphotos-client-secret строка Секрет клиента OAuth
--gphotos-include-archived Также просматривать и скачивать заархивированные медиафайлы.
--gphotos-read-only Сделать серверную часть Google Фото доступной только для чтения.--gphotos-read-size Устанавливает для чтения размера мультимедийных элементов.
--gphotos-start-year int Год ограничивает загружаемые фотографии теми, которые загружаются после указанного года (по умолчанию 2000)
--gphotos-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--gphotos-token-url string URL-адрес сервера токена.
--hdfs-data-transfer-protection string Защита передачи данных Kerberos: аутентификация | целостность | конфиденциальность
--hdfs-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, Colon, Del, Ctl, InvalidUtf8, Dot)
--hdfs-namenode строка имя hasoop имени узла и порта
--hdfs-service-Principal-name строка Имя участника-службы Kerberos для узла имени
--hdfs-username string имя пользователя hadoop
--http-headers CommaSepList Установить заголовки HTTP для всех транзакций
--http-no-head Не использовать запросы HEAD для поиска размеров файлов в списке каталогов
--http-no-slash Установите это, если сайт не заканчивает каталоги с /
--http-url строка URL-адрес http-хоста для подключения
--hubic-auth-url строка URL-адрес сервера аутентификации.--hubic-chunk-size SizeSuffix Файлы, размер которых превышает этот размер, будут помещены в контейнер _segments. (по умолчанию 5G)
--hubic-client-id строка Идентификатор клиента OAuth
--hubic-client-secret строка Секрет клиента OAuth
--hubic-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8)
--hubic-no-chunk Не разбивать файлы во время потоковой загрузки.--hubic-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--hubic-token-url строка URL-адрес сервера токена.
--jottacloud-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, Del, Ctl, InvalidUtf8, Dot)
--jottacloud-hard-delete Удалить файлы навсегда, а не помещать их в корзину.--jottacloud-md5-memory-limit SizeSuffix Файлы большего размера будут кэшироваться на диске для расчета MD5, если это необходимо. (по умолчанию 10M)
--jottacloud-trashed-only Показывать только файлы, находящиеся в корзине.
--jottacloud-upload-resume-limit SizeSuffix Файлы большего размера могут быть возобновлены в случае сбоя загрузки. (по умолчанию 10M)
--koofr-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--koofr-endpoint string Конечная точка API Koofr для использования (по умолчанию «https://app.koofr.net»)
--koofr-mountid string Идентификатор используемого монтирования. Если не указано, используется основное крепление.
--koofr-password string Ваш пароль Koofr для rclone (сгенерируйте его на https://app.koofr.net/app/admin/preferences/password) (скрыто)
--koofr-setmtime Поддерживает ли серверная часть время изменения настроек.Установите значение false, если вы используете идентификатор монтирования, указывающий на серверную часть Dropbox или Amazon Drive. (по умолчанию true)
--koofr-user строка Ваше имя пользователя Koofr
-l, --links Переводить символические ссылки в / из обычных файлов с расширением '.rclonelink'
--local-case-indensitive Заставить файловую систему сообщать о себе как нечувствительность к регистру
--local-case-sensitive Заставить файловую систему сообщать о том, что она чувствительна к регистру.--local-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, точка)
--local-no-check-updated Не проверять, изменяются ли файлы во время загрузки
--local-no-set-modtime Отключить установку времени мода
--local-no-sparse Отключить разреженные файлы для многопоточной загрузки
--local-no-unicode-normalization Не применять нормализацию Unicode к путям и именам файлов (устарело)
--local-nounc string Отключить преобразование UNC (длинные имена путей) в Windows
--local-zero-size-links Предположить, что размер статистики ссылок равен нулю (и вместо этого прочтите их)
--mailru-check-hash Что делать копии, если контрольная сумма файла не соответствует или недействительна (по умолчанию true)
--mailru-encoding MultiEncoder Устанавливает кодировку для бэкэнда.(по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--mailru-pass строка Пароль (скрыто)
--mailru-speedup-enable Пропустить полную загрузку, если есть другой файл с таким же хешем данных. (по умолчанию true)
--mailru-speedup-file-patterns строка Список разделенных запятыми шаблонов имен файлов, которые могут быть ускорены (помещены с помощью хеша). (по умолчанию "* .mkv, *. avi, *. mp4, *. mp3, *.zip, *. gz, *. rar, *. pdf ")
--mailru-speedup-max-disk SizeSuffix Этот параметр позволяет отключить ускорение (ставится по хешу) для больших файлов (по умолчанию 3G)
--mailru-speedup-max-memory SizeSuffix Файлы, размер которых превышает указанный ниже размер, всегда будут хешироваться на диске. (по умолчанию 32M)
--mailru-user строка Имя пользователя (обычно электронная почта)
--mega-debug Вывести дополнительную отладку из Mega.--mega-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8, точка)
--mega-hard-delete Удалять файлы навсегда, а не помещать их в корзину.
--mega-pass строка Пароль. (затемнено)
--mega-user строка Имя пользователя
-x, --one-file-system Не пересекать границы файловой системы (только unix / macOS).--onedrive-auth-url строка URL-адрес сервера аутентификации.
--onedrive-chunk-size SizeSuffix Размер блока для загрузки файлов - должен быть кратен 320 КБ (327 680 байт). (по умолчанию 10M)
--onedrive-client-id строка Идентификатор клиента OAuth
--onedrive-client-secret строка Секрет клиента OAuth
--onedrive-drive-id строка Идентификатор используемого диска.
--onedrive-drive-type строка Тип диска (личный | бизнес | documentLibrary)
--onedrive-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Del, Ctl, LeftSpace, LeftTilde, RightSpace, RightPeriod, InvalidUtf8, Dot)
--onedrive-expose-onenote-files Установить, чтобы файлы OneNote отображались в списках каталогов.
--onedrive-link-password строка Установить пароль для ссылок, созданных командой link.
--onedrive-link-scope строка Установить область ссылок, создаваемых командой ссылки.(по умолчанию "анонимный")
--onedrive-link-type строка Установить тип ссылок, создаваемых командой ссылки. (вид по умолчанию")
--onedrive-no-versions Удалять все версии при изменении операций
--onedrive-region строка Выберите национальный облачный регион для OneDrive. (по умолчанию "глобальный")
--onedrive-server-side-through-configs Разрешить серверным операциям (например, копированию) работать с разными конфигурациями onedrive.--onedrive-token строка Токен доступа OAuth в виде большого двоичного объекта JSON.
--onedrive-token-url строка URL-адрес сервера токена.
--opendrive-chunk-size SizeSuffix Файлы будут загружаться кусками этого размера. (по умолчанию 10M)
--opendrive-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, LeftSpace, LeftCrLfHtVt, RightSpace, RightCrLfHtVt, InvalidUtf8, Dot)
--opendrive-пароль строка Пароль.(затемнено)
--opendrive-username строка Имя пользователя
--pcloud-auth-url строка URL-адрес сервера аутентификации.
--pcloud-client-id строка Идентификатор клиента OAuth
--pcloud-client-secret строка Секрет клиента OAuth
--pcloud-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--pcloud-hostname строка Имя хоста для подключения.(по умолчанию "api.pcloud.com")
--pcloud-root-folder-id строка Заполните rclone, чтобы использовать некорневую папку в качестве начальной точки. (по умолчанию "d0")
--pcloud-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--pcloud-token-url строка URL-адрес сервера токена.
--premiumizeme-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, DoubleQuote, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--putio-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--qingstor-access-key-id строка Идентификатор ключа доступа QingStor
--qingstor-chunk-size SizeSuffix Размер блока для загрузки. (по умолчанию 4M)
--qingstor-connection-retries int Количество попыток подключения. (по умолчанию 3)
--qingstor-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, Ctl, InvalidUtf8)
--qingstor-endpoint string Введите URL-адрес конечной точки для подключения QingStor API.--qingstor-env-auth Получить учетные данные QingStor из среды выполнения. Применяется, только если access_key_id и secret_access_key пустые.
--qingstor-secret-access-key строка Секретный ключ доступа QingStor (пароль)
--qingstor-upload-concurrency int Параллелизм для многокомпонентных загрузок. (по умолчанию 1)
--qingstor-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 200M)
--qingstor-zone string Зона для подключения.--s3-access-key-id строка Идентификатор ключа доступа AWS.
--s3-acl string Постоянный список контроля доступа, используемый при создании сегментов, а также при хранении или копировании объектов.
--s3-bucket-acl string Стандартный список контроля доступа, используемый при создании корзин.
--s3-chunk-size SizeSuffix Размер блока для загрузки. (по умолчанию 5M)
--s3-copy-cutoff SizeSuffix Cutoff для переключения на многостраничное копирование (по умолчанию 4.656G)
--s3-disable-checkum Не сохранять контрольную сумму MD5 с метаданными объекта
--s3-disable-http2 Отключить использование http2 для бэкэндов S3
--s3-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8, точка)
--s3-endpoint string Конечная точка для S3 API.
--s3-env-auth Получить учетные данные AWS из среды выполнения (переменные среды или метаданные EC2 / ECS, если переменных окружения нет).--s3-force-path-style Если true, использовать стиль доступа, если false, использовать виртуальный размещенный стиль. (по умолчанию true)
--s3-leave-parts-on-error Если true, избегать вызова прерывания загрузки в случае сбоя, оставляя все успешно загруженные части на S3 для ручного восстановления.
--s3-list-chunk int Размер блока листинга (список ответов для каждого запроса ListObject S3). (по умолчанию 1000)
--s3-location-constraint string Ограничение местоположения - должно быть установлено, чтобы соответствовать региону.--s3-max-upload-parts int Максимальное количество частей в многокомпонентной загрузке. (по умолчанию 10000)
--s3-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--s3-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.
--s3-no-check-bucket Если установлено, не пытаться проверять, существует ли сегмент, или создавать его.
--s3-no-head Если установлено, не ЗАГЛАВАТЬ загруженные объекты для проверки целостности
--s3-profile string Профиль для использования в файле общих учетных данных
--s3-provider string Выберите своего провайдера S3.--s3-region строка Регион для подключения.
--s3-Requester-pays Включает опцию оплаты запрашивающей стороны при взаимодействии с корзиной S3.
--s3-secret-access-key строка AWS Secret Access Key (пароль)
--s3-server-side-encryption string Алгоритм шифрования на стороне сервера, используемый при сохранении этого объекта в S3.
--s3-session-token string Токен сеанса AWS
--s3-shared-credentials-file string Путь к файлу общих учетных данных
--s3-sse-customer-algorithm строка При использовании SSE-C алгоритм шифрования на стороне сервера, используемый при сохранении этого объекта в S3.--s3-sse-customer-key string При использовании SSE-C вы должны предоставить секретный ключ шифрования, используемый для шифрования / дешифрования ваших данных.
--s3-sse-customer-key-md5 строка При использовании SSE-C вы можете указать контрольную сумму MD5 секретного ключа шифрования (необязательно).
--s3-sse-kms-key-id string При использовании KMS ID необходимо предоставить ARN ключа.
--s3-storage-class строка Класс хранения, используемый при сохранении новых объектов в S3.--s3-upload-concurrency int Параллелизм для многокомпонентных загрузок. (по умолчанию 4)
--s3-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 200M)
--s3-use-accelerate-endpoint Если true, использовать ускоренную конечную точку AWS S3.
--s3-v2-auth Если true, использовать аутентификацию v2.
--seafile-2fa Двухфакторная аутентификация ('true', если в учетной записи включена двухфакторная аутентификация)
--seafile-create-library Должен ли rclone создать библиотеку, если она не существует
--seafile-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, DoubleQuote, BackSlash, Ctl, InvalidUtf8)
--seafile-library string Имя библиотеки. Оставьте поле пустым, чтобы получить доступ ко всем незашифрованным библиотекам.
--seafile-library-key строка Пароль библиотеки (только для зашифрованных библиотек). Оставьте поле пустым, если вы передаете его через командную строку. (затемнено)
--seafile-pass строка Пароль (скрыто)
--seafile-url строка URL-адрес хоста seafile для подключения
--seafile-user строка Имя пользователя (обычно адрес электронной почты)
--sftp-ask-password Разрешить запрашивать пароль SFTP при необходимости.--sftp-disable-hashcheck Отключить выполнение команд SSH, чтобы определить, доступно ли удаленное хеширование файлов.
--sftp-host строка SSH-хост для подключения
--sftp-key-file string Путь к файлу закрытого ключа в кодировке PEM, оставьте поле пустым или установите key-use-agent для использования ssh-agent.
--sftp-key-file-pass строка Кодовая фраза для расшифровки файла закрытого ключа в формате PEM.(затемнено)
--sftp-key-pem string Необработанный закрытый ключ в кодировке PEM, если он указан, переопределит параметр key_file.
--sftp-key-use-agent При установке принудительно использовать ssh-agent.
--sftp-known-hosts-file строка Необязательный путь к файлу known_hosts.
--sftp-md5sum-command string Команда, используемая для чтения хэшей md5. Оставьте поле пустым для автоматического определения.
--sftp-pass строка Пароль SSH, оставьте поле пустым, чтобы использовать ssh-agent.(затемнено)
--sftp-path-override string Переопределить путь, используемый SSH-соединением.
--sftp-port строка Порт SSH, оставьте поле пустым, чтобы использовать значение по умолчанию (22)
--sftp-pubkey-file string Необязательный путь к файлу открытого ключа.
--sftp-server-command строка Задает путь или команду для запуска sftp-сервера на удаленном хосте.
--sftp-set-modtime Установить измененное время на пульте дистанционного управления, если установлено.(по умолчанию true)
--sftp-sha1sum-command string Команда, используемая для чтения хэшей sha1. Оставьте поле пустым для автоматического определения.
--sftp-skip-links Устанавливает пропуск любых символических ссылок и любых других нестандартных файлов.
--sftp-subsystem string Задает подсистему SSh3 на удаленном хосте. (по умолчанию "sftp")
--sftp-use-fstat Если установлено, использовать fstat вместо stat
--sftp-use-insecure-cipher Разрешить использование незащищенных шифров и методов обмена ключами.--sftp-user string Имя пользователя SSH, оставьте поле пустым для текущего имени пользователя, $ USER
--sharefile-chunk-size SizeSuffix Размер загружаемого фрагмента. Должна быть степень 2> = 256k. (по умолчанию 64M)
--sharefile-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Ctl, LeftSpace, LeftPeriod, RightSpace, RightPeriod, InvalidUtf8, Dot)
--sharefile-endpoint string Конечная точка для вызовов API.--sharefile-root-folder-id строка ID корневой папки
--sharefile-upload-cutoff SizeSuffix Cutoff для переключения на многостраничную загрузку. (по умолчанию 128M)
--skip-links Не предупреждать о пропущенных символических ссылках.
--sugarsync-access-key-id строка Sugarsync Access Key ID.
--sugarsync-app-id строка Идентификатор приложения Sugarsync.
--sugarsync-authorization строка Sugarsync авторизация
--sugarsync-authorization-expiry string Срок действия авторизации Sugarsync
--sugarsync-deleted-id строка Идентификатор удаленной папки Sugarsync
--sugarsync-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Ctl, InvalidUtf8, Dot)
--sugarsync-hard-delete Безвозвратно удалить файлы, если true
--sugarsync-private-access-key строка Sugarsync Private Access Key
--sugarsync-refresh-token строка Маркер обновления Sugarsync
--sugarsync-root-id строка Sugarsync root id
--sugarsync-user строка Пользователь Sugarsync
--swift-application-credential-id строка Идентификатор учетных данных приложения (OS_APPLICATION_CREDENTIAL_ID)
--swift-application-credential-name строка Имя учетных данных приложения (OS_APPLICATION_CREDENTIAL_NAME)
--swift-application-credential-secret строка Секрет учетных данных приложения (OS_APPLICATION_CREDENTIAL_SECRET)
--swift-auth string URL аутентификации для сервера (OS_AUTH_URL).--swift-auth-token string Токен аутентификации из альтернативной аутентификации - необязательно (OS_AUTH_TOKEN)
--swift-auth-version int AuthVersion - необязательно - установите значение (1,2,3), если ваш URL-адрес авторизации не имеет версии (ST_AUTH_VERSION)
--swift-chunk-size SizeSuffix Файлы, размер которых превышает этот размер, будут помещены в контейнер _segments. (по умолчанию 5G)
--swift-domain строка Пользовательский домен - необязательно (v3 auth) (OS_USER_DOMAIN_NAME)
--swift-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, InvalidUtf8)
--swift-endpoint-type string Тип конечной точки для выбора из каталога услуг (OS_ENDPOINT_TYPE) (по умолчанию "общедоступный")
--swift-env-auth Получить быстрые учетные данные из переменных среды в стандартной форме OpenStack.
--swift-key string Ключ API или пароль (OS_PASSWORD).
--swift-leave-parts-on-error Если true, избегать вызова прерывания загрузки в случае сбоя.Для возобновления загрузки в разные сеансы необходимо установить значение true.
--swift-no-chunk Не разбивать файлы во время потоковой загрузки.
--swift-region строка Имя региона - необязательно (OS_REGION_NAME)
--swift-storage-policy строка Политика хранения, используемая при создании нового контейнера.
--swift-storage-url строка URL-адрес хранилища - необязательно (OS_STORAGE_URL)
--swift-tenant string Имя клиента - необязательно для аутентификации v1, в противном случае требуется this или tenant_id (OS_TENANT_NAME или OS_PROJECT_NAME)
--swift-tenant-domain строка Домен клиента - необязательно (v3 auth) (OS_PROJECT_DOMAIN_NAME)
--swift-tenant-id строка Tenant ID - необязательно для аутентификации v1, в противном случае требуется этот или тенант (OS_TENANT_ID)
--swift-user строка Имя пользователя для входа (OS_USERNAME).--swift-user-id строка Идентификатор пользователя для входа - необязательно - большинство быстрых систем используют пользователя и оставляют это поле пустым (v3 auth) (OS_USER_ID).
--tardigrade-access-grant строка Разрешение доступа.
--tardigrade-api-key строка API-ключ.
--tardigrade-passphrase строка Кодовая фраза шифрования. Для доступа к существующим объектам введите парольную фразу, используемую для загрузки.
--tardigrade-provider строка Выберите метод аутентификации.(по умолчанию "существующий")
--tardigrade-satellite-address
(по умолчанию косая черта, CrLf, InvalidUtf8, точка)
--gcs-location string Расположение вновь созданных сегментов.--gcs-object-acl string Список контроля доступа для новых объектов.
--gcs-project-number строка Номер проекта.
--gcs-service-account-file строка Учетные данные учетной записи службы Путь к файлу JSON
--gcs-storage-class string Класс хранения, используемый при хранении объектов в Google Cloud Storage.
--gcs-token string Токен доступа OAuth в виде большого двоичного объекта JSON.--gcs-token-url string URL-адрес сервера токена.
--gphotos-auth-url строка URL-адрес сервера аутентификации.
--gphotos-client-id строка Идентификатор клиента OAuth
--gphotos-client-secret строка Секрет клиента OAuth
--gphotos-include-archived Также просматривать и скачивать заархивированные медиафайлы.
--gphotos-read-only Сделать серверную часть Google Фото доступной только для чтения.--gphotos-read-size Устанавливает для чтения размера мультимедийных элементов.
--gphotos-start-year int Год ограничивает загружаемые фотографии теми, которые загружаются после указанного года (по умолчанию 2000)
--gphotos-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--gphotos-token-url string URL-адрес сервера токена.
--hdfs-data-transfer-protection string Защита передачи данных Kerberos: аутентификация | целостность | конфиденциальность
--hdfs-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, Colon, Del, Ctl, InvalidUtf8, Dot)
--hdfs-namenode строка имя hasoop имени узла и порта
--hdfs-service-Principal-name строка Имя участника-службы Kerberos для узла имени
--hdfs-username string имя пользователя hadoop
--http-headers CommaSepList Установить заголовки HTTP для всех транзакций
--http-no-head Не использовать запросы HEAD для поиска размеров файлов в списке каталогов
--http-no-slash Установите это, если сайт не заканчивает каталоги с /
--http-url строка URL-адрес http-хоста для подключения
--hubic-auth-url строка URL-адрес сервера аутентификации.--hubic-chunk-size SizeSuffix Файлы, размер которых превышает этот размер, будут помещены в контейнер _segments. (по умолчанию 5G)
--hubic-client-id строка Идентификатор клиента OAuth
--hubic-client-secret строка Секрет клиента OAuth
--hubic-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8)
--hubic-no-chunk Не разбивать файлы во время потоковой загрузки.--hubic-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--hubic-token-url строка URL-адрес сервера токена.
--jottacloud-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, Del, Ctl, InvalidUtf8, Dot)
--jottacloud-hard-delete Удалить файлы навсегда, а не помещать их в корзину.--jottacloud-md5-memory-limit SizeSuffix Файлы большего размера будут кэшироваться на диске для расчета MD5, если это необходимо. (по умолчанию 10M)
--jottacloud-trashed-only Показывать только файлы, находящиеся в корзине.
--jottacloud-upload-resume-limit SizeSuffix Файлы большего размера могут быть возобновлены в случае сбоя загрузки. (по умолчанию 10M)
--koofr-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--koofr-endpoint string Конечная точка API Koofr для использования (по умолчанию «https://app.koofr.net»)
--koofr-mountid string Идентификатор используемого монтирования. Если не указано, используется основное крепление.
--koofr-password string Ваш пароль Koofr для rclone (сгенерируйте его на https://app.koofr.net/app/admin/preferences/password) (скрыто)
--koofr-setmtime Поддерживает ли серверная часть время изменения настроек.Установите значение false, если вы используете идентификатор монтирования, указывающий на серверную часть Dropbox или Amazon Drive. (по умолчанию true)
--koofr-user строка Ваше имя пользователя Koofr
-l, --links Переводить символические ссылки в / из обычных файлов с расширением '.rclonelink'
--local-case-indensitive Заставить файловую систему сообщать о себе как нечувствительность к регистру
--local-case-sensitive Заставить файловую систему сообщать о том, что она чувствительна к регистру.--local-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, точка)
--local-no-check-updated Не проверять, изменяются ли файлы во время загрузки
--local-no-set-modtime Отключить установку времени мода
--local-no-sparse Отключить разреженные файлы для многопоточной загрузки
--local-no-unicode-normalization Не применять нормализацию Unicode к путям и именам файлов (устарело)
--local-nounc string Отключить преобразование UNC (длинные имена путей) в Windows
--local-zero-size-links Предположить, что размер статистики ссылок равен нулю (и вместо этого прочтите их)
--mailru-check-hash Что делать копии, если контрольная сумма файла не соответствует или недействительна (по умолчанию true)
--mailru-encoding MultiEncoder Устанавливает кодировку для бэкэнда.(по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--mailru-pass строка Пароль (скрыто)
--mailru-speedup-enable Пропустить полную загрузку, если есть другой файл с таким же хешем данных. (по умолчанию true)
--mailru-speedup-file-patterns строка Список разделенных запятыми шаблонов имен файлов, которые могут быть ускорены (помещены с помощью хеша). (по умолчанию "* .mkv, *. avi, *. mp4, *. mp3, *.zip, *. gz, *. rar, *. pdf ")
--mailru-speedup-max-disk SizeSuffix Этот параметр позволяет отключить ускорение (ставится по хешу) для больших файлов (по умолчанию 3G)
--mailru-speedup-max-memory SizeSuffix Файлы, размер которых превышает указанный ниже размер, всегда будут хешироваться на диске. (по умолчанию 32M)
--mailru-user строка Имя пользователя (обычно электронная почта)
--mega-debug Вывести дополнительную отладку из Mega.--mega-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8, точка)
--mega-hard-delete Удалять файлы навсегда, а не помещать их в корзину.
--mega-pass строка Пароль. (затемнено)
--mega-user строка Имя пользователя
-x, --one-file-system Не пересекать границы файловой системы (только unix / macOS).--onedrive-auth-url строка URL-адрес сервера аутентификации.
--onedrive-chunk-size SizeSuffix Размер блока для загрузки файлов - должен быть кратен 320 КБ (327 680 байт). (по умолчанию 10M)
--onedrive-client-id строка Идентификатор клиента OAuth
--onedrive-client-secret строка Секрет клиента OAuth
--onedrive-drive-id строка Идентификатор используемого диска.
--onedrive-drive-type строка Тип диска (личный | бизнес | documentLibrary)
--onedrive-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Del, Ctl, LeftSpace, LeftTilde, RightSpace, RightPeriod, InvalidUtf8, Dot)
--onedrive-expose-onenote-files Установить, чтобы файлы OneNote отображались в списках каталогов.
--onedrive-link-password строка Установить пароль для ссылок, созданных командой link.
--onedrive-link-scope строка Установить область ссылок, создаваемых командой ссылки.(по умолчанию "анонимный")
--onedrive-link-type строка Установить тип ссылок, создаваемых командой ссылки. (вид по умолчанию")
--onedrive-no-versions Удалять все версии при изменении операций
--onedrive-region строка Выберите национальный облачный регион для OneDrive. (по умолчанию "глобальный")
--onedrive-server-side-through-configs Разрешить серверным операциям (например, копированию) работать с разными конфигурациями onedrive.--onedrive-token строка Токен доступа OAuth в виде большого двоичного объекта JSON.
--onedrive-token-url строка URL-адрес сервера токена.
--opendrive-chunk-size SizeSuffix Файлы будут загружаться кусками этого размера. (по умолчанию 10M)
--opendrive-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, LeftSpace, LeftCrLfHtVt, RightSpace, RightCrLfHtVt, InvalidUtf8, Dot)
--opendrive-пароль строка Пароль.(затемнено)
--opendrive-username строка Имя пользователя
--pcloud-auth-url строка URL-адрес сервера аутентификации.
--pcloud-client-id строка Идентификатор клиента OAuth
--pcloud-client-secret строка Секрет клиента OAuth
--pcloud-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--pcloud-hostname строка Имя хоста для подключения.(по умолчанию "api.pcloud.com")
--pcloud-root-folder-id строка Заполните rclone, чтобы использовать некорневую папку в качестве начальной точки. (по умолчанию "d0")
--pcloud-token string Токен доступа OAuth в виде большого двоичного объекта JSON.
--pcloud-token-url строка URL-адрес сервера токена.
--premiumizeme-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, DoubleQuote, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--putio-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, BackSlash, Del, Ctl, InvalidUtf8, Dot)
--qingstor-access-key-id строка Идентификатор ключа доступа QingStor
--qingstor-chunk-size SizeSuffix Размер блока для загрузки. (по умолчанию 4M)
--qingstor-connection-retries int Количество попыток подключения. (по умолчанию 3)
--qingstor-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, Ctl, InvalidUtf8)
--qingstor-endpoint string Введите URL-адрес конечной точки для подключения QingStor API.--qingstor-env-auth Получить учетные данные QingStor из среды выполнения. Применяется, только если access_key_id и secret_access_key пустые.
--qingstor-secret-access-key строка Секретный ключ доступа QingStor (пароль)
--qingstor-upload-concurrency int Параллелизм для многокомпонентных загрузок. (по умолчанию 1)
--qingstor-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 200M)
--qingstor-zone string Зона для подключения.--s3-access-key-id строка Идентификатор ключа доступа AWS.
--s3-acl string Постоянный список контроля доступа, используемый при создании сегментов, а также при хранении или копировании объектов.
--s3-bucket-acl string Стандартный список контроля доступа, используемый при создании корзин.
--s3-chunk-size SizeSuffix Размер блока для загрузки. (по умолчанию 5M)
--s3-copy-cutoff SizeSuffix Cutoff для переключения на многостраничное копирование (по умолчанию 4.656G)
--s3-disable-checkum Не сохранять контрольную сумму MD5 с метаданными объекта
--s3-disable-http2 Отключить использование http2 для бэкэндов S3
--s3-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию косая черта, InvalidUtf8, точка)
--s3-endpoint string Конечная точка для S3 API.
--s3-env-auth Получить учетные данные AWS из среды выполнения (переменные среды или метаданные EC2 / ECS, если переменных окружения нет).--s3-force-path-style Если true, использовать стиль доступа, если false, использовать виртуальный размещенный стиль. (по умолчанию true)
--s3-leave-parts-on-error Если true, избегать вызова прерывания загрузки в случае сбоя, оставляя все успешно загруженные части на S3 для ручного восстановления.
--s3-list-chunk int Размер блока листинга (список ответов для каждого запроса ListObject S3). (по умолчанию 1000)
--s3-location-constraint string Ограничение местоположения - должно быть установлено, чтобы соответствовать региону.--s3-max-upload-parts int Максимальное количество частей в многокомпонентной загрузке. (по умолчанию 10000)
--s3-memory-pool-flush-time Продолжительность Как часто будут очищаться пулы буферов внутренней памяти. (по умолчанию 1 мин. 0 сек.)
--s3-memory-pool-use-mmap Следует ли использовать буферы mmap во внутреннем пуле памяти.
--s3-no-check-bucket Если установлено, не пытаться проверять, существует ли сегмент, или создавать его.
--s3-no-head Если установлено, не ЗАГЛАВАТЬ загруженные объекты для проверки целостности
--s3-profile string Профиль для использования в файле общих учетных данных
--s3-provider string Выберите своего провайдера S3.--s3-region строка Регион для подключения.
--s3-Requester-pays Включает опцию оплаты запрашивающей стороны при взаимодействии с корзиной S3.
--s3-secret-access-key строка AWS Secret Access Key (пароль)
--s3-server-side-encryption string Алгоритм шифрования на стороне сервера, используемый при сохранении этого объекта в S3.
--s3-session-token string Токен сеанса AWS
--s3-shared-credentials-file string Путь к файлу общих учетных данных
--s3-sse-customer-algorithm строка При использовании SSE-C алгоритм шифрования на стороне сервера, используемый при сохранении этого объекта в S3.--s3-sse-customer-key string При использовании SSE-C вы должны предоставить секретный ключ шифрования, используемый для шифрования / дешифрования ваших данных.
--s3-sse-customer-key-md5 строка При использовании SSE-C вы можете указать контрольную сумму MD5 секретного ключа шифрования (необязательно).
--s3-sse-kms-key-id string При использовании KMS ID необходимо предоставить ARN ключа.
--s3-storage-class строка Класс хранения, используемый при сохранении новых объектов в S3.--s3-upload-concurrency int Параллелизм для многокомпонентных загрузок. (по умолчанию 4)
--s3-upload-cutoff SizeSuffix Cutoff для переключения на частичную загрузку (по умолчанию 200M)
--s3-use-accelerate-endpoint Если true, использовать ускоренную конечную точку AWS S3.
--s3-v2-auth Если true, использовать аутентификацию v2.
--seafile-2fa Двухфакторная аутентификация ('true', если в учетной записи включена двухфакторная аутентификация)
--seafile-create-library Должен ли rclone создать библиотеку, если она не существует
--seafile-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию Slash, DoubleQuote, BackSlash, Ctl, InvalidUtf8)
--seafile-library string Имя библиотеки. Оставьте поле пустым, чтобы получить доступ ко всем незашифрованным библиотекам.
--seafile-library-key строка Пароль библиотеки (только для зашифрованных библиотек). Оставьте поле пустым, если вы передаете его через командную строку. (затемнено)
--seafile-pass строка Пароль (скрыто)
--seafile-url строка URL-адрес хоста seafile для подключения
--seafile-user строка Имя пользователя (обычно адрес электронной почты)
--sftp-ask-password Разрешить запрашивать пароль SFTP при необходимости.--sftp-disable-hashcheck Отключить выполнение команд SSH, чтобы определить, доступно ли удаленное хеширование файлов.
--sftp-host строка SSH-хост для подключения
--sftp-key-file string Путь к файлу закрытого ключа в кодировке PEM, оставьте поле пустым или установите key-use-agent для использования ssh-agent.
--sftp-key-file-pass строка Кодовая фраза для расшифровки файла закрытого ключа в формате PEM.(затемнено)
--sftp-key-pem string Необработанный закрытый ключ в кодировке PEM, если он указан, переопределит параметр key_file.
--sftp-key-use-agent При установке принудительно использовать ssh-agent.
--sftp-known-hosts-file строка Необязательный путь к файлу known_hosts.
--sftp-md5sum-command string Команда, используемая для чтения хэшей md5. Оставьте поле пустым для автоматического определения.
--sftp-pass строка Пароль SSH, оставьте поле пустым, чтобы использовать ssh-agent.(затемнено)
--sftp-path-override string Переопределить путь, используемый SSH-соединением.
--sftp-port строка Порт SSH, оставьте поле пустым, чтобы использовать значение по умолчанию (22)
--sftp-pubkey-file string Необязательный путь к файлу открытого ключа.
--sftp-server-command строка Задает путь или команду для запуска sftp-сервера на удаленном хосте.
--sftp-set-modtime Установить измененное время на пульте дистанционного управления, если установлено.(по умолчанию true)
--sftp-sha1sum-command string Команда, используемая для чтения хэшей sha1. Оставьте поле пустым для автоматического определения.
--sftp-skip-links Устанавливает пропуск любых символических ссылок и любых других нестандартных файлов.
--sftp-subsystem string Задает подсистему SSh3 на удаленном хосте. (по умолчанию "sftp")
--sftp-use-fstat Если установлено, использовать fstat вместо stat
--sftp-use-insecure-cipher Разрешить использование незащищенных шифров и методов обмена ключами.--sftp-user string Имя пользователя SSH, оставьте поле пустым для текущего имени пользователя, $ USER
--sharefile-chunk-size SizeSuffix Размер загружаемого фрагмента. Должна быть степень 2> = 256k. (по умолчанию 64M)
--sharefile-encoding MultiEncoder Устанавливает кодировку для серверной части. (по умолчанию Slash, LtGt, DoubleQuote, Colon, Question, Asterisk, Pipe, BackSlash, Ctl, LeftSpace, LeftPeriod, RightSpace, RightPeriod, InvalidUtf8, Dot)
--sharefile-endpoint string Конечная точка для вызовов API.--sharefile-root-folder-id строка ID корневой папки
--sharefile-upload-cutoff SizeSuffix Cutoff для переключения на многостраничную загрузку. (по умолчанию 128M)
--skip-links Не предупреждать о пропущенных символических ссылках.
--sugarsync-access-key-id строка Sugarsync Access Key ID.
--sugarsync-app-id строка Идентификатор приложения Sugarsync.
--sugarsync-authorization строка Sugarsync авторизация
--sugarsync-authorization-expiry string Срок действия авторизации Sugarsync
--sugarsync-deleted-id строка Идентификатор удаленной папки Sugarsync
--sugarsync-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, Ctl, InvalidUtf8, Dot)
--sugarsync-hard-delete Безвозвратно удалить файлы, если true
--sugarsync-private-access-key строка Sugarsync Private Access Key
--sugarsync-refresh-token строка Маркер обновления Sugarsync
--sugarsync-root-id строка Sugarsync root id
--sugarsync-user строка Пользователь Sugarsync
--swift-application-credential-id строка Идентификатор учетных данных приложения (OS_APPLICATION_CREDENTIAL_ID)
--swift-application-credential-name строка Имя учетных данных приложения (OS_APPLICATION_CREDENTIAL_NAME)
--swift-application-credential-secret строка Секрет учетных данных приложения (OS_APPLICATION_CREDENTIAL_SECRET)
--swift-auth string URL аутентификации для сервера (OS_AUTH_URL).--swift-auth-token string Токен аутентификации из альтернативной аутентификации - необязательно (OS_AUTH_TOKEN)
--swift-auth-version int AuthVersion - необязательно - установите значение (1,2,3), если ваш URL-адрес авторизации не имеет версии (ST_AUTH_VERSION)
--swift-chunk-size SizeSuffix Файлы, размер которых превышает этот размер, будут помещены в контейнер _segments. (по умолчанию 5G)
--swift-domain строка Пользовательский домен - необязательно (v3 auth) (OS_USER_DOMAIN_NAME)
--swift-encoding MultiEncoder Устанавливает кодировку для серверной части.(по умолчанию косая черта, InvalidUtf8)
--swift-endpoint-type string Тип конечной точки для выбора из каталога услуг (OS_ENDPOINT_TYPE) (по умолчанию "общедоступный")
--swift-env-auth Получить быстрые учетные данные из переменных среды в стандартной форме OpenStack.
--swift-key string Ключ API или пароль (OS_PASSWORD).
--swift-leave-parts-on-error Если true, избегать вызова прерывания загрузки в случае сбоя.Для возобновления загрузки в разные сеансы необходимо установить значение true.
--swift-no-chunk Не разбивать файлы во время потоковой загрузки.
--swift-region строка Имя региона - необязательно (OS_REGION_NAME)
--swift-storage-policy строка Политика хранения, используемая при создании нового контейнера.
--swift-storage-url строка URL-адрес хранилища - необязательно (OS_STORAGE_URL)
--swift-tenant string Имя клиента - необязательно для аутентификации v1, в противном случае требуется this или tenant_id (OS_TENANT_NAME или OS_PROJECT_NAME)
--swift-tenant-domain строка Домен клиента - необязательно (v3 auth) (OS_PROJECT_DOMAIN_NAME)
--swift-tenant-id строка Tenant ID - необязательно для аутентификации v1, в противном случае требуется этот или тенант (OS_TENANT_ID)
--swift-user строка Имя пользователя для входа (OS_USERNAME).--swift-user-id строка Идентификатор пользователя для входа - необязательно - большинство быстрых систем используют пользователя и оставляют это поле пустым (v3 auth) (OS_USER_ID).
--tardigrade-access-grant строка Разрешение доступа.
--tardigrade-api-key строка API-ключ.
--tardigrade-passphrase строка Кодовая фраза шифрования. Для доступа к существующим объектам введите парольную фразу, используемую для загрузки.
--tardigrade-provider строка Выберите метод аутентификации.(по умолчанию "существующий")
--tardigrade-satellite-address