Как искать свободные домены с ТИЦ и добывать уникальные статьи из Вебархива —
В позапрошлые выходные несколько часов посвятил углублению в тему брошенных доменов. По результатам этого небольшого исследования даже написал в блог статью о вариантах заработка на брошенных доменах с ТИЦ. Но, так как тема достаточно обширная, при практическом соприкосновении с этой темой нюансы продолжают выявляться. О них я и хотел поговорить сегодня.
Просматривая недавно освобожденные на определенную дату домены, в очередной раз убедился, что доменных имен с ненулевым показателем ТИЦ каждый день появляются сотни. Домены с ТИЦ от 50, как правило, перехватываются, в момент освобождения. Многие регистраторы проводят с этой целью аукционы доменов, зачастую продавая их по сильно завышенным ценам.
Но есть и другой путь. Без участия в аукционах тоже можно легко и просто перехватить домен с небольшим ТИЦ. В свободном доступе практически всегда имеются «десятки» и «двадцатки», порой даже с красивыми именами. По горячим следам решил написать простую мини-инструкцию для тех, кто хочет получить общее представление о том, где и как искать свободные домены с ТИЦ и как добывать уникальные статьи из Вебархива. Постараюсь дать повторяемый общий алгоритм с живыми примерами. Возможно, кому-то это пригодится – в настоящем или будущем.
По горячим следам решил написать простую мини-инструкцию для тех, кто хочет получить общее представление о том, где и как искать свободные домены с ТИЦ и как добывать уникальные статьи из Вебархива. Постараюсь дать повторяемый общий алгоритм с живыми примерами. Возможно, кому-то это пригодится – в настоящем или будущем.
Свободные домены с ТИЦ
Список освобожденных и свободных доменов с ТИЦ на любую конкретную дату всегда открыт и общедоступен. Нужно лишь знать, где его можно посмотреть. Онлайн-сервисов для этого в сети предостаточно. Здесь приведу лишь один сервис с большим количеством различных настроек, позволяющий быстро, в несколько кликов, получить нужный результат по тому или иному запросу.
Этот сервис от РегРу удобен и интуитивно понятен. Нам остается лишь задать параметры:- ключи, встречающиеся в имени домена;
- необходимую доменную зону;
- период, в который освобождены домены;
- желаемое минимальное значение ТИЦ.


В этом же окне настроек можно скрыть уже зарегистрированные домены. Нажатие зеленой кнопки «Применить» выводит ниже список освобожденных доменов с заданными параметрами.
На скриншоте видны выбранные мной параметры. Из этого списка для эксперимента возьмем домен с ключевиками в имени avtomotoblogger.ru и будем работать с ним дальше.
Проверка домена на клей
Освобожденный домен, как ни странно, может иметь высокий ТИЦ, но при этом быть «склеенным» с другим доменом, считающимся поисковыми системами главным зеркалом. Т.е., при жизни такой домен служил лишь для перенаправления на другой адрес. В этом случае имеющийся показатель ТИЦ после перерегистрации обнулится, сохранившись за основным доменом.
Для быстрой массовой проверки на клей доменных имен я пользуюсь инструментом форума WebmastersRu. Тут все предельно просто: ввели список доменов для проверки (по одному на строку), нажали кнопочку. В случае, если клей будет обнаружен, система покажет, к какому именно домену приклеено проверяемое имя.
В нашем случае склейки доменов нет, переходим к следующему шагу.
Проверка качества ссылочной массы домена
Есть для этой цели замечательный инструмент Ahrefs.com — Site Explorer, с помощью которого можно проанализировать ссылочную массу любого ресурса. Причем качество ссылочной массы сайта позволяет оценить даже бесплатная версия онлайн-анализатора. Нас, в первую очередь, интересует количество входящих ссылок и анкоры на сайт.
По нашему пациенту анализ ссылок показывает, что хоть количество доноров и ссылок на сайт не велико, анкоры в ссылках вполне адекватные. Это дает основания надеяться на то, что имеющийся у домена ТИЦ продержится еще несколько апдейтов.
Проверка наличия сайта в Вебархиве
Важный момент для тех, кому нужен не только домен с халявным ТИЦ, но и тексты с сайта, бывшего на этом домене. Для того чтобы понять, можно ли будет восстановить на этот домен статьи, нужно убедиться в наличии снимков сайта в Вебархиве. Для этого переходим по адресу web.archive.org и в строку поиска вводим интересующее нас доменное имя. Результат проверки показывает, что снимки сайта сохранились.
Для этого переходим по адресу web.archive.org и в строку поиска вводим интересующее нас доменное имя. Результат проверки показывает, что снимки сайта сохранились.
Если Вебархив вам не доступен, воспользуйтесь простым и удобным расширением к вашему браузеру, о котором я писал в этой статье.
Проверка статей из Вебархива на уникальность
Для бесплатной проверки текстов на уникальность рекомендую воспользоваться сервисом TextRu, одним из самых строгих и адекватных в своей нише на данный момент.
На скриншотах видно, что выбранная нами статья размером в 4500 символов является 100% уникальной. Не факт, что подобный результат TextRu выдаст для каждой имеющейся в архивах статьи. Скорее всего, часть текстов окажется уже опубликованной на других сайтах, и чем дольше времени прошло с момента освобождения домена – тем меньше уникальных статей на нем остается, т. к. желающих использовать в своих корыстных целях бесплатный уникальный контент весьма велико.
к. желающих использовать в своих корыстных целях бесплатный уникальный контент весьма велико.
Дальнейшие шаги
После того, как мы определились с тем, что в проверенном в разных онлайн-сервисах домене нас все устраивает, остается лишь зарегистрировать его у любого из регистраторов, прописать DNS в соответствии с используемым вами хостингом, установить на хостинг WordPress, восстановить сохранившиеся в Вебархиве статьи на вновь созданный сайт, добавить новых тематических статей, дождаться полного индексирования всех статей и минимальной посещаемости, начать зарабатывать на сайте. Все просто, не правда ли?
Кстати, информацию как искать свободные домены с ТИЦ, уникальные тексты в Вебархиве и как на этом зарабатывать, подобную изложенной в этой статье, можно встретить под разными названиями в различных дорогих инфокурсах о заработке в интернет. Делюсь ею с вами безвозмездно, т.к. абсолютно уверен в том, что проверит этот алгоритм в деле лишь небольшая часть читателей, а зарабатывать на этой теме захочет и сможет — и того меньше. Такова бесстрастная и беспощадная статистика )
Такова бесстрастная и беспощадная статистика )
В заключение скажу, что приведенный выше алгоритм – лишь один из возможных. Разумеется, профессиональные охотники за доменами и уникальным контентом пользуются более продвинутым набором инструментов. В одной из следующих статей постараюсь рассказать о том, как можно легко и просто скачивать из Вебархива целые сайты, уже недоступные в обычном поиске Яндекса и Гугла.
Расскажите об этой статье в соцсетях:
«РГ» представляет восемь легендарных сайтов российского интернета — Российская газета
30 сентября в России отмечается День интернета. «РГ» вспоминает отечественные сайты, популярные десять или пятнадцать лет назад, а теперь незаслуженно забытые или уступающие новым ресурсам.
1. Mail.ru
Мало кто помнит, что в конце девяностых сайт, открывавшийся по адресу www.mail.ru, выглядел совсем не так, как сейчас. Вместо заглавной страницы с новостями, строкой поиска, телепрограммой, киноафишей и прогнозом погоды пользователя встречал весьма лаконичный ресурс, не содержавший на первых порах ни рекламы, ни гороскопа на следующую неделю. Вместо «гладкого» логотипа Mail.ru, к которому сегодня все привыкли, в левом верхнем углу заглавной странице был изображен осьминог с почтальонской сумкой. К сожалению, отыскать оригинальную страницу Mail.ru не удалось даже с помощью интернет-архива web.archive.org.
Вместо «гладкого» логотипа Mail.ru, к которому сегодня все привыкли, в левом верхнем углу заглавной странице был изображен осьминог с почтальонской сумкой. К сожалению, отыскать оригинальную страницу Mail.ru не удалось даже с помощью интернет-архива web.archive.org.
2. Чат «Кроватка»
«Кроватка» (krovatka.ru) — один из самых популярных чатов на стыке конца девяностых и начала двухтысячных годов. По своей посещаемости и уровняю народной любви он, пожалуй, опережал даже Chat.ru, который считается пионером чатопроходческого движения в Рунете.
Сейчас групповые чаты вообще малопопулярны, только если речь не идет об общении нескольких друзей в какой-нибудь социальной сети. В «Кроватке» к разговору мог присоединиться любой пользователь, прошедший несложный процесс регистрации. Простейший интерфейс, легко загружавшийся через медленное модемное соединение, возможность раскрашивать тексты сообщений в разные цвета и многочасовые ночные (ночью интернет стоил дешевле) разговоры «за жизнь» — все это постепенно сошло на нет с появлением блогов и социальных сетей.
3. Mult.ru и Масяня
Серия комедийных флешовых мультфильмов с питерской девчонкой Масяней в главной роли, выпущенных Олегом Куваевым в 2001 году, быстро завоевала популярность. Во многом этому способствовали оптимизм, философичность и легкий налет черного юмора, присутствовавшие практически в каждом мультфильме.
Всего было выпущено почти 130 серий мультиков про Масяню и ее друзей — Хрюнделя, Лохматого и других. Выпуск «Масяни» неоднократно прекращался и возобновлялся, однако популярность его была настолько велика, что рисованные человечки и их «папа» Куваев даже появились в передаче «Намедни». Всего на телевидении было показано около двадцати мультов.
Несмотря на спад популярности, в 2013 году интернет-пользователи приступили к сбору средств на продолжение выпуска сериала.
4. Паравозов-News и «Вечерний интернет»
«Паравозов-News», созданный Александром Гагиным, который писал под псевдонимом Иван Паравозов, можно считать первым блогом Рунета. Начиная с конца 1996 года публиковались обзоры интернета и событий, так или иначе с ним связанных. Это могли быть как пространные «рассуждения на тему», так и ссылки на новые и интересные сайты. Примерно тогда же появился «Вечерний интернет», который вел популярный и поныне блогер Антон Носик.
Начиная с конца 1996 года публиковались обзоры интернета и событий, так или иначе с ним связанных. Это могли быть как пространные «рассуждения на тему», так и ссылки на новые и интересные сайты. Примерно тогда же появился «Вечерний интернет», который вел популярный и поныне блогер Антон Носик.
В настоящее время и тот, и другой (сайты, а не их создатели) существуют лишь в виде архивов. Однако, несмотря на то, что все события, в них описываемые, давно уже неактуальны, читать «Паравозов-News» и «Вечерний интернет» все равно интересно. Отметим также, что Александр Гагин является создателем нынешней версии сайта «РГ».
5. Анекдоты из России, составитель Дима Вернер
Anekdot.ru — один из «старожилов интернета», выходящий, согласно надписи на логотипе, с 8 ноября 1995 года. Его создателем стал Дмитрий Вернер — профессор астрофизики, родившийся в 1959 году в Ленинграде.
Уже почти восемнадцать лет его любимый ресурс обновляется ежедневно, однако уже довольно длительное время Anekdot.
Тем не менее Anekdot.ru, где каждый день публикуются новые анекдоты, истории, афоризмы, стихи и карикатуры, уступает «юнцу» по имени bash.im, специализирующемуся на малых прозаических формах — выдержках из чатов, как настоящих, так и полностью выдуманных.
6. «Ау!» и «Апорт»
Когда-то Рунет жил не только «Яндексом» и Google — были в нем и другие поисковики. «Апорт» представлял собой обычный, без претензий, поисковый сайт и каталог, а «Ау!» отличался тем, что при каждом заходе на него через подключенные к компьютеру колонки раздавался громкий и душераздирающий крик: «Ау-у-у!»
Те, кого не хватил сердечный приступ после такого знакомства, до сих пор вспоминают «Ау!» добрым словом. Сейчас оба сайта по-прежнему открываются, однако «Апорт» превратился в поиск по товарам, а «Ау» сменил название на Au — в честь золота, которое по-латински называется aurum. Au представляет собой «поисковик по поисковикам» и другим тематическим сайтам.
Au представляет собой «поисковик по поисковикам» и другим тематическим сайтам.
На YouTube в России больше ходить нельзя. Реплика Максима Кононенко
Одним из важнейших аспектов модернизации является, как известно, повышение производительности труда. Именно от производительности труда напрямую зависит эффективность в любой области деятельности, включая даже такие специфические области деятельности, как судопроизводство. Уж сколько мы слышали жалоб о том, что суды завалены заявлениями, что очереди на рассмотрение дел растягиваются на месяцы, что люди просто не хотят обращаться в суды, потому что это бесперспективно и долго. И вот ситуация начинает меняться.
Центральный районный суд города Комсомольск-на-Амуре по иску прокурора от имени «неопределенного круга лиц» постановил ограничить доступ к пяти интернет-сайтам, содержащим экстремистские материалы. И среди этих пяти — www.youtube.com. Теперь местный провайдер с важным названием ООО РА РТС «Роснет» обязан фильтровать все пользовательские запросы к одному из самых больших интернет-сайтов в мире.
Честно говоря, я воодушевлен. Запрещать доступ к существенной части глобальной сети вместо того, чтобы нажать на YouTube кнопку «пожаловаться модератору» — это новый, революционный подход! Рискну предложить российским судьям несколько рационализаторских предложений по расширению и углублению долгожданного модернизационного порыва. Во-первых, надо запретить использование поисковых систем. Потому что текстов Гитлера в кешах поисковых систем — гигабайты. Причем на всех языках, что при наличии встроенной функции перевода, например, в Google более не является препятствием для изучения экстремистских идей.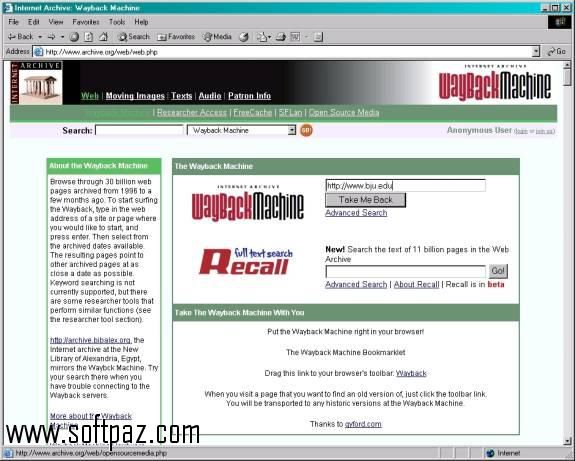
Реплика Максима Кононенко на радио «Вести ФМ»
Читайте также на сайте радио «Вести ФМ»: Жара бьет по психике Агент Солт, вы провалились. В Россию плывёт ядовитый «подарок» из Китая Реплика Антона Долина
Реплика Антона Долина
Веб на заре Рунета. Как создавали и где хостили сайты в 90-е / Хабр
Хоумпейдж мой, домашняя страница готова. Сайт я свой доделал, бабуля!
Удивительно, но я совершенно не помню день своего знакомства с интернетом. Это определенно был 1996 или 97-й год, но сам момент отчего-то не отложился в памяти: интернет вошел в жизнь нашего поколения исподволь, вытеснив из нее и BBS, и эхоконференции Фидонета. Поначалу мы отчаянно потребляли контент: серфинг по сети в середине 90-х напоминал путешествия Колумба в поисках неизведанного, и ежедневно приносил новые увлекательные открытия. Затем у многих тяга к творчеству брала верх, и они начинали робкие эксперименты по созданию собственных «кошмарных домашних страничек». Меня тоже не минула чаша сия — воспоминания о том, как это было, сейчас вызывают лишь ностальгическую улыбку.
Толковых книг на русском языке по синтаксису HTML и тем более по веб-дизайну в середине 90-х еще не издавали. По крайней мере, мои воспоминания о подобной литературе относятся скорее к началу нулевых — тогда на волне популярности темы таких изданий вдруг стало неожиданно много. Приходилось действовать экспериментальным путем: веб-страница сохранялась на диске, открывалась в Notepad.exe, после чего в коде менялись значения атрибутов html-тегов, удалялись и добавлялись строчки, а изменения тут же отслеживались в окне браузера. Собственно, мои первые веб-страницы были по большому счету локализованными копиями зарубежных «хоумпейджей», делать что-то по-настоящему свое я научился немного позже путем натурных экспериментов.
Типичный сайт середины 90-х. От такого дизайна в наши дни и вправду может стошнить
Отличительной особенностью сайтов того времени было повсеместное использование вырвиглазных фоновых картинок, которыми следовало обязательно замостить все пространство страницы сверху донизу. Поэтому крайне важно было добиться, чтобы небольшое изображение правильно стыковалось само с собой по горизонтали и вертикали. Кто-то использовал для этого Photoshop, позже появились и специальные утилиты для работы с фоновыми картинками вроде Harm’s Tile 99, посредством которых удавалось соорудить почти идеальные фоны для сайта, потратив на это минимум усилий. Некоторые «Web-мастера» (именно так их тогда и называли — латиницей и с заглавной буквы «W») очень любили прикрутить к какой-нибудь странице MIDI-файл, который без объявления войны начинал воспроизводиться сразу в момент открытия сайта. Лично я за такое готов был пристукнуть их чем-нибудь тяжелым, поскольку в целях экономии пользовался преимущественно ночным dial-up’ом, и временами забывал выключить колонки.
Поэтому крайне важно было добиться, чтобы небольшое изображение правильно стыковалось само с собой по горизонтали и вертикали. Кто-то использовал для этого Photoshop, позже появились и специальные утилиты для работы с фоновыми картинками вроде Harm’s Tile 99, посредством которых удавалось соорудить почти идеальные фоны для сайта, потратив на это минимум усилий. Некоторые «Web-мастера» (именно так их тогда и называли — латиницей и с заглавной буквы «W») очень любили прикрутить к какой-нибудь странице MIDI-файл, который без объявления войны начинал воспроизводиться сразу в момент открытия сайта. Лично я за такое готов был пристукнуть их чем-нибудь тяжелым, поскольку в целях экономии пользовался преимущественно ночным dial-up’ом, и временами забывал выключить колонки.
Интернет тогда поступал населению преимущественно по модему, поэтому для ускорения загрузки страниц (и благодаря ограничениям хостинга того времени) картинки приходилось сжимать. Формат PNG тогда еще не был широко распространен (поначалу для его поддержки вроде бы даже требовались дополнительные браузерные плагины). Картинки на сайтах были представлены файлами GIF — для кнопок, надписей, «шапок», и, конечно же, анимации, и JPEG — для всего остального. JPEG мы сжимали с помощью Jpeg Optimizator и Jpeg Cleaner for DOS, для второго формата широко использовался GifClean 32 под винду. Позже, уже ближе к нулевым, широкое распространение получила универсальная программа WebGraphics Optimizer: ты загружал в нее картинку, и тулза выдавала несколько вариантов сжатого изображения с различной степенью компрессии: оставалось только выбрать компромисс между подходящим размером файла и количеством грязи и артефактов. Опции «Save for Web» в Фотошопе (по крайней мере, в той версии, которой пользовался я) тогда еще не существовало, мы выживали, как могли. Не существовало и удобной функции нарезки картинки на куски-слайсы, с помощью которой можно было собрать целую мозаику из фрагментов изображения с разными гиперссылками. Картинки резали на части в программе Picture Dicer, пока браузеры не научились наконец нормально поддерживать html-тег <map>.
Картинки на сайтах были представлены файлами GIF — для кнопок, надписей, «шапок», и, конечно же, анимации, и JPEG — для всего остального. JPEG мы сжимали с помощью Jpeg Optimizator и Jpeg Cleaner for DOS, для второго формата широко использовался GifClean 32 под винду. Позже, уже ближе к нулевым, широкое распространение получила универсальная программа WebGraphics Optimizer: ты загружал в нее картинку, и тулза выдавала несколько вариантов сжатого изображения с различной степенью компрессии: оставалось только выбрать компромисс между подходящим размером файла и количеством грязи и артефактов. Опции «Save for Web» в Фотошопе (по крайней мере, в той версии, которой пользовался я) тогда еще не существовало, мы выживали, как могли. Не существовало и удобной функции нарезки картинки на куски-слайсы, с помощью которой можно было собрать целую мозаику из фрагментов изображения с разными гиперссылками. Картинки резали на части в программе Picture Dicer, пока браузеры не научились наконец нормально поддерживать html-тег <map>. После чего об этом извращении с огромным облегчением забыли.
После чего об этом извращении с огромным облегчением забыли.
WebGraphics Optimizer – тулза для сжатия картинок
Самым громким писком моды 90-х были, конечно, анимированные GIF’ы, которые собирались в программах вроде Gif Movie Gear и Ulead GIF Animator. На веб-страницах бегало, скакало и крутилось буквально все. Считалось очень правильным и важным распихать на сайте как можно больше анимированных кнопок, картинок, значков и иконок, так, чтобы у посетителя через пару минут начало рябить в глазах и возникали рвотные позывы. В 1997 году GIF-анимация обрела еще и практическое значение: в Рунете появилась первая баннерообменная сеть Reklama.ru, использовавшаяся для взаимного продвижения сайтов, но при этом забиравшая определенную часть показов под собственную монетизацию. Сеть накладывала очень жесткие ограничения не столько на содержание баннеров, сколько на объем файлов, поэтому отдельные кадры в формате GIF порой приходилось сначала сжимать сторонними компрессорами, а потом еще и оптимизировать в самом GIF Animator’e, сокращая количество цветов в палитре, добавляя туда прозрачность и убирая лишние слои. Иногда на это уходило даже больше времени, чем на рисование самой рекламы.
Иногда на это уходило даже больше времени, чем на рисование самой рекламы.
В Ulead GIF Animator создавалась практически вся эта назойливая анимированная графика
Создатели веб-страниц конца 90-х сталкивались в основном с тремя серьезными проблемами. Первая — кодировки кириллицы. Браузеры не всегда умели корректно распознавать ее в автоматическом режиме, потому порой приходилось готовить несколько версий сайта — сначала в Windows-1251, после чего копии веб-страниц перегонялись в KOI-8, ISO-8859-5 и CP866 с помощью утилит вроде ConvertHTML или Coder. Затем варианты сайта в разных кодировках связывались гиперссылками. Обновление всего этого зоопарка веб-страниц выливалось потом в отдельную эпопею. Крупные конторы, имевшие возможность подкрутить конфигурацию сервера, могли настроить выдачу сайта в разных кодировках через разные http-порты, но у обычной массы веб-мастеров не было доступа даже к папке /cgi-bin/, не говоря уж о более сложных вещах. Потому проблема решалась такими вот кустарными методами и всевозможными подпорками из костылей.
Второй геморрой — поддержка экранных разрешений. Чтобы ничего не разъезжалось и не расползалось на разных компьютерах, сайты того времени заверстывались в невидимую таблицу, ширина которой определялась наиболее распространенными значениями экранного разрешения. Свои первые сайты я верстал под 640х480, но вскоре самым популярным стандартом стал 800х600, реже встречались веб-страницы, оптимизированные под 1024х768. Сделаешь таблицу слишком узкой — по краям экрана появятся неопрятные пустые поля, слишком широкой — у страдальцев со старыми дисплеями вылезут в браузере полосы прокрутки. Споры о том, какое разрешение считать основным и какую ширину таблиц выбирать в качестве «стандарта», не утихали очень долго и порой превращались в настоящие холивары. По крайней мере, до тех пор, пока наука не придумала «резиновый» адаптивный дизайн.
Типичный сайт с табличной версткой. Такая компоновка сайтов была популярна до начала 00-х.
Но самой большой головной болью были, пожалуй, попытки добиться одинакового отображения веб-страницы в Internet Explorer и Netscape Navigator. В ходе «браузерных войн» разработчики придумывали html-теги, которые нормально поддерживала только их программа, кроме того, Microsoft, по слухам, активно подкармливала консорциум W3C, чтобы легализовать собственные нововведения в стандарт HTML. Дабы не заморачиваться, многие веб-мастера вешали на свои страницы дисклаймер из серии «Этот сайт лучше просматривать в Microsoft Internet Explorer», и со спокойной совестью отправлялись пить пиво. Другие вроде меня стремились к совершенству, и долгими ночами, матюгаясь сквозь зубы, копались в HTML-коде: только наладишь выравнивание объектов в IE, как в «Нетшкафе» съезжает ширина боковых колонок навигации, починишь колонки — пропадают горизонтальные линии, вернешь на место линии — вокруг картинок откуда-то вылезли отвратные рамки. Еще, помнится, существовал национальный браузер «Ариадна», которым даже пользовались… примерно никто. К началу нулевых понемногу стала набирать популярность Opera, добавив веб-мастерам еще немного попоболи: теперь оптимизировать страницы приходилось аж под три разных браузера.
В ходе «браузерных войн» разработчики придумывали html-теги, которые нормально поддерживала только их программа, кроме того, Microsoft, по слухам, активно подкармливала консорциум W3C, чтобы легализовать собственные нововведения в стандарт HTML. Дабы не заморачиваться, многие веб-мастера вешали на свои страницы дисклаймер из серии «Этот сайт лучше просматривать в Microsoft Internet Explorer», и со спокойной совестью отправлялись пить пиво. Другие вроде меня стремились к совершенству, и долгими ночами, матюгаясь сквозь зубы, копались в HTML-коде: только наладишь выравнивание объектов в IE, как в «Нетшкафе» съезжает ширина боковых колонок навигации, починишь колонки — пропадают горизонтальные линии, вернешь на место линии — вокруг картинок откуда-то вылезли отвратные рамки. Еще, помнится, существовал национальный браузер «Ариадна», которым даже пользовались… примерно никто. К началу нулевых понемногу стала набирать популярность Opera, добавив веб-мастерам еще немного попоболи: теперь оптимизировать страницы приходилось аж под три разных браузера.
Мало создать кошмарную домашнюю страничку, ее еще нужно было где-то разместить. Профессиональный хостинг стоил дорого и не каждому был по карману, но многие провайдеры при покупке у них интернета бесплатно предоставляли юзеру до мегабайта дискового пространства. Подобные личные сайты обычно имели URL вида www.cityline.ru/~username. Такой вариант хостинга имел несколько серьезных недостатков. Во-первых, провайдеры обычно накладывали ограничения на содержание сайтов, допуская к размещению только персональные страницы и не разрешая публиковать коммерческие. Во-вторых, через пару дней после того, как ты переставал платить за интернет, страничка попросту уничтожалась — и если на твоем компе не осталось резервной копии, восстановить ее было уже невозможно. В-третьих, ты оказывался фактически привязанным к этой конторе: перенести статический сайт на другой хост при смене провайдера не составляло особого труда, а вот адрес, зарегистрированный во всех интернет-каталогах, терялся навсегда вместе с рейтингом Rambler’s Top 100 и прочими честно заработанными ачивками.
Интернет-провайдер всея Руси Cityline. Дизайн сайта – студии Артемия Лебедева
Второй вариант — бесплатный хостинг. В Рунете с 1996 года действовал портал Halyava.ru, где можно было без-воз-мез-дно, то есть даром, разместить домашнюю страничку общим объемом не более 512 килобайт. На вопрос, чем продиктовано столь жесткое ограничение, в FAQ хостера был опубликован исчерпывающий ответ:
А зачем Вам больше? Если Ваша страничка начинает весить больше 512 килобайт, возникает вопрос: зачем делать такую «тяжелую» графику?
От щедрот душевных компания предлагала для каждой такой странички адрес вида
www.halyava.ru/ваше-имя(для серьезных людей в малиновых пиджаках, которым не нравится слово «Халява», были доступны URL формата
www.homepage.techno.ru/ваше-имя), а также обвешивала ее рекламой. Фактически, сайт пользователя отображался во встроенном фрейме, в верхней части которого хостер откручивал баннеры и размещал ссылку на собственный сервис. Примечательно, что у Halyava.ru поначалу отсутствовала возможность загрузки веб-страниц по FTP: вместо этого данные на сервер передавались по электронной почте, по ней же пользователю отправлялись инструкции. Помнится, у какого-то из хостеров использовался другой извращенный метод: нужно было скопировать HTML-код через буфер обмена в специальную форму, из которой по нажатию кнопки Submit генерировалась в папке на сервере веб-страница с заданным именем. Попутно HTML-код проверялся на предмет «запрещенных» тегов. Страница жила на «Халяве» два месяца с момента получения сервером последней команды от юзера, а затем бесследно исчезала. Естественно, такой бесплатный хостинг не подразумевал использования каких-либо скриптов: только статические веб-страницы, только хардкор! Но даже столь спартанские условия для 90-х считались более чем приемлемыми. Халява, сэр!
Халявный хостинг в 90-е предлагали не так уж и много провайдеров, один из самых известных — GeoCities
Для тех, кто знал английский и не боялся общаться с техподдержкой на иностранном языке, был открыт весь мир: например, на сервере GeoCities бесплатно давали целых 2 мегабайта, а лично я пользовался услугами халявного хостинга на портале Tripod.com. Там тоже лепили на размещаемые сайты собственную рекламу, тоже допускали к публикации только статические веб-страницы, а адрес сайта имел вид www.tripod.com/~username. GeoCities предлагал в добавок к сайту еще и бесплатный почтовый ящик. Кроме того, для загрузки веб-страниц на сервер там предоставлялся нормальный FTP-доступ. Правда, регистрация нового сайта представляла собой не самый простой квест: сначала нужно было выбрать подходящую тематическую рубрику в каталоге, затем найти незанятое имя, и только потом тебя допускали в святая святых — к заполнению анкеты для получения membership. Возможно, именно такая нетривиальная система и отпугивала наших соотечественников. Зато американцы, в отличие от местных хостеров, никак не ограничивали размещение на пользовательских веб-страничках сторонней рекламы. Благодаря участию в партнерских программах я, помнится, даже заработал целых 15 баксов, а потом долго бегал по российским банкам с присланным мне по почте бумажным чеком, пытаясь его обналичить.
Еще один рай для любителей халявы из 90-х — Tripod
Вскоре в Рунете стали возникать и другие площадки для бесплатного размещения сайтов, у разработчиков появилась возможность регистрировать для них домены третьего уровня или создавать алиасы вроде site.da.ru. Но, тем не менее, запуск скриптов по-прежнему оставался недоступным большинству пользователей бесплатных тарифов. Самыми популярными веб-сервисами в то время были гостевые книги и чаты, а самым распространенным языком, на котором писались CGI-сценарии — Perl. Конечно, можно было прикрутить к своему сайту и стороннюю гостевую книгу с чужой рекламой — таких предложений в Рунете было навалом, — но каждому, конечно, хотелось иметь собственный чатик вроде легендарной «Кроватки», или уютную «гостевушку», аккуратно вписанную в существующий дизайн.
Поскольку Perl в случае неправильной настройки сервера (а правильно его настраивать было дано далеко не всем) технически позволял выполнять команды операционной системы и получить доступ к файлам за пределами домашней папки пользователя, а скрипты создавали нагрузку на сервер, доступ к /cgi-bin/ простым смертным открывали далеко не всегда. Чаще всего «бесплатному» юзеру предлагалось написать админу хостинга, что за скрипт он желает запустить на сервере и на кой ему это понадобилось. Затем следовало отправить скрипт на рассмотрение, и только в случае одобрения админ выкладывал его на сайт и давал ему права на выполнение. Отладка сценариев на Perl превращалась при этом в сущую пытку, а задача поправить где-нибудь неправильно указанный путь или ошибку в имени переменной — в mission impossible. Доступ к СУБД на бесплатных тарифах тоже, понятно, отсутствовал как явление, данные писали в текстовые файлы, которые использовались вместо базы данных. Архаика, но чатик на Perl и .TXT благополучно просуществовал на моем сайте, кажется, до 2002 года, когда был упразднен за ненадобностью. Скрипты мы писали сами, но можно было обойтись и готовыми вариантами — огромный выбор самых разных сценариев на все случаи жизни можно было добыть в коллекциях вроде freeware.ru — там имелся ну просто кладезь скриптов и полезного софта на все случаи жизни. Бесплатный хостинг с полноценным доступом к CGI стал широко доступен только в самом начале «нулевых», коммерческие пользователи подобных проблем по понятным причинам не испытывали и до этого.
Freeware.ru — месторождение софта и полезных скриптов
Настоящим откровением в конце 90-х для меня стал стандарт CSS, о котором я узнал от коллег. Оказывается, совершенно необязательно прописывать в каждом html-теге кучу атрибутов, а вместо этого можно собрать все стили в одном внешнем текстовом файле. Вторым грандиозным открытием стала технология Server Side Includes, позволившая экономить кучу времени на обновлении контента. С помощью SSI впервые сделалось возможным отделить дизайн от собственно содержимого сайта: веб-мастер мог распихать «шапку», «подвал», навигацию и контент по разным файлам, а потом динамически собирать их воедино прямо на сервере. Захотел отредактировать меню на всех страницах проекта — достаточно внести правки только в один файлик. «У» — удобство. До появления полноценных CMS оставался ровно один шаг.
Вместо них в начале «нулевых» жизнь веб-мастера заметно облегчали редакторы вроде HomeSite, Hot Metal Pro, Adobe Page Mill, Hotdog, Macromedia DreamWeaver, и конечно же, Microsoft FrontPage, который генерировал адские объемы мусорного кода, но очень уж полюбился мне за наглядность и простоту. Да, код веб-страниц после FrontPage приходилось чистить в «Блокноте», но это было неотъемлемой частью рабочего процесса.
Очень много веб-страниц было сверстано в Microsoft FrontPage
В тот период запад переживал самый пик знаменитого «пузыря доткомов», а в российском сегменте сети начался бурный рост новых проектов, часть которых впоследствии превратилась в крупные интернет-компании с многомиллионной капитализацией. Но это было потом. Тогда же подавляющее большинство русскоязычных сайтов создавалось на голом энтузиазме и поддерживалось за счет финансовых ресурсов и личного времени самих разработчиков. Многим тогда справедливо казалось, что в Рунете денег нет. Я и пара моих приятелей «подхалтуривали» иным способом, а именно, делали сайты для американских заказчиков, в основном, для малого и сверхмалого бизнеса. В Штатах подобные услуги стоили тогда дорого, в России — на порядок дешевле. Помню, как меня ввел в полнейший ступор вопрос от джентльмена из Техаса, сколько долларов стоит в России час работы веб-мастера. Да пёс его знает! В России конца 90-х обычно платили за завершенный проект, да и то не всегда. Некоторые студенты вообще трудились за пиво. Помню, в тот период мы сделали хоумпейдж для какой-то пекарни из Алабамы, для религиозной общины из Пенсильвании, для семейного бизнеса, предлагавшего трансферт туристов на минивене из аэропорта Ла-Гуардия, для небольшого косметического салона и частного мастера по очистке бассейнов из техасской глубинки, для магазина газонокосилок из городка, который я даже не смог отыскать на карте… Совсем не миллионные стартапы, конечно, но какие-то деньги это приносило. Притом наша небольшая банда веб-мастеров не давала никакой рекламы: простого знания английского вполне хватало, чтобы заказы приходили один за другим посредством «сарафанного радио».
Когда PHP окончательно вытеснил Perl с просторов интернета, веб-программист мог считаться настоящим мужчиной, только если он осилил три главных достижения в своей жизни: посадил печень, вырастил патлы и написал собственную CMS. Количество самописных движков с примерно одинаковым функционалом, напоминавших велосипеды с квадратными, треугольными, трапециевидными и даже выполненными в виде ленты мёбиуса колесами, быстро превысило все разумные пределы. Но к тому моменту я уже окончательно завязал с веб-дизайном и вся эта вакханалия благополучно прошла мимо меня. Тем более, к этому моменту интернет в целом обрел свой современный вид, окончательно коммерциализировался, и веб-разработкой стали заниматься профессионалы, освоившие поистине промышленные масштабы производства по промышленным же расценкам. А для меня веб-дизайн никогда не был основной профессией и главным источником дохода. Гораздо больше мне нравилось заниматься текстами.
Однако говорят, что бросить возиться с сайтами иногда даже сложнее, чем бросить курить. Временами я все еще делаю что-то на Joomla и WordPress — для собственного удовольствия. Но всякий раз, открывая свои старые архивы, я с улыбкой вспоминаю те времена, когда мы писали сайты в Notepad.exe, вручную оптимизировали перед выкладкой каждую картинку, а главное — учились методом проб и ошибок, без роликов на YouTube, онлайн-курсов и даже без специальной литературы. В нашем распоряжении не было такого количества общедоступных сервисов, начиная от движков на любой вкус до визуальных конструкторов, с помощью которых можно за пару минут набросать мышкой работоспособный лендинг, попивая кофе и поглядывая одним глазом в ТикТок. Да и Рунет был крошечным, как детская песочница во дворе, а его население — как и население той песочницы — более наивным, добродушным и открытым. Хорошие все-таки были времена.
Кто не идёт вперед, тот идёт назад: сентября 2013
Реализация проектов «открытое правительство» во всем мире строится на максимальном раскрытии государственной информации. При этом государственные органы достаточно часто при любой возможности стараются максимально закрыть государственную информацию, и наши государственные органы — не исключение.
Арбитражный суд города Москвы в сентябре 2012 года при рассмотрении дела № А40-86515/12 признал, что предоставление правовых актов, содержащих засекреченную информацию или персональные данные, противоречит положениям закона о доступе к государственной информации, при этом поверив Правительству Москвы на слово. По мнению арбитражных судов, такая проверка возможна только в том случае, если соответствующим правовым актом были бы непосредственно затронуты права и законные интересы конкретного субъекта предпринимательской деятельности.
Суть спора
ЗАО «Анализ, Консультации и Маркетинг» обратилось в Правительство Москвы о предоставлении в распоряжение общества полных текстов правых актов Мэра и Правительства Москвы по экономической тематике, принятых в период с 1998 – 2009 г.г. (всего было запрошено 300 актов).
В январе 2012 года общетву были предоставлены восемь архивных копий документов за 1998 – 2002 годы, а также сообщено, что часть запрашиваемых правовых актов содержит пометку «ОП», в связи с чем проводится согласование возможности выдачи интересующих документов.
Позже обществу были предоставлены еще 14 правовых актов Правительства города Москвы. В марте 2012 года Правительство Москвы в лице Управления по организации работы с документами Правительства Москвы отказало обществу в предоставлении иных запрошенных правовых актов, поскольку они содержат сведения, предназначенные для служебного пользования, а также персональные данные и другую конфиденциальную информацию.
Полагая, что Правительством Москвы совершены действия по неправомерному ограничению доступа к информации, осуществлявшиеся путем отнесения к числу документов, не являющихся общедоступными, правовых актов Мэра Москвы и Правительства Москвы по экономической тематике, а также не согласившись с действиями Правительства Москвы, выразившимися в отказе в представлении информации общество обратилось в суд с иском.
Позиция ЗАО «Анализ, Консультации и Маркетинг»
Ограничения на доступ к информации о деятельности государственных органов установлены только в отношении сведений, содержащих государственную тайну. Следовательно, Правительство Москвы не могло ограничивать доступ к правовым актам Мэра Москвы и Правительства Москвы, не содержащим сведения, отнесенные к государственной тайне, и не имело правовых оснований относить такие правовые акты к актам, доступ к которым ограничен.
Оспариваемые действия создают существенное препятствие для осуществления экономической деятельности общества.
Неправомерное ограничение доступа к информации и непредставление запрошенной информации создает для общества иные препятствия для осуществления предпринимательской деятельности, не позволяя ему воспользоваться этой информацией в коммерческих целях, в том числе путем ее распространения в целях извлечения прибыли.
Позиция Правительства Москвы
Оспариваемые действия Правительства Москвы не противоречат действующему законодательству, не нарушают прав и законных интересов заявителя в сфере предпринимательской и иной экономической деятельности.
Позиция Арбитражного суда города Москвы
Действия Правительства Москвы в период с 1998 – 2008 годов по ограничению доступа к информации о деятельности Мэра Москвы и Правительства Москвы, а также действия Правительства Москвы, выразившихся в отказе представления информации, содержащейся в запрошенных правовых актах соответствуют закону, поскольку предоставление правовых актов, содержащих засекреченную информацию или персональные данные, противоречило бы положениям федеральных законов.
Суд проанализировал основные виды деятельности общества и пришел к выводу, что общество не специализируется на коммерческой реализации запрашиваемых у Правительства Москвы сведений, содержащихся в правовых актах Мэра и Правительства Москвы и составляющих государственную, коммерческую или иную специально охраняемую законом тайну, в связи с чем, оспариваемые обществом действия не создают каких-либо препятствий обществу в осуществлении полиграфической, образовательной, издательской и другой деятельности.
При этом, запрашиваемые правовые акты не адресованы заявителю и не возлагают на него каких-либо обязанностей.
Суд отказал ЗАО «Анализ, Консультации и Маркетинг» в удовлетворении заявленных к Правительству города Москвы требований в полном объеме.
Позиция Девятого арбитражного апелляционного суда
Девятый арбитражный апелляционный суд в декабре 2012 года рассмотрел апелляцию общества, в котором оно отмечало то ни один из запрошенных правовых актов государственную или служебную тайну не содержит, в связи с чем отказ в предоставлении информации, содержащейся в запрошенных правовых актах является неправомерным, создает препятствия в использовании информации, не являющейся ограниченной в доступе, а также нарушает права и законные интересы заявителя в сфере предпринимательской деятельности.
По мнению суда, из материалов дела следовало, что в рассматриваемом случае заявителю было отказано в предоставлении тех правовых актов, которые были либо засекречены, либо содержали информацию ограниченного доступа или персональные данные, — вопреки доводам автора апелляционной жалобы о том, что ни один из запрошенных заявителем правовых актов государственную или служебную тайну не содержит. При этом следует отметить, что отнесение тех или иных правовых актов к секретным или содержащим служебную тайну относится к компетенции издающего их государственного органа.
По мнению апелляционного суда, суд первой инстанции пришел к правильному выводу об отсутствии нарушений требований законодательства Правительством Москвы.
При этом суд отметил, что проверка наличия в спорных правовых актах сведений, составляющих государственную или служебную тайну, на необходимость чего указывается в апелляционной жалобе, возможна только в том случае, если соответствующим правовым актом были непосредственно затронуты права и законные интересы конкретного субъекта предпринимательской деятельности.
Обществом же не были доказаны обстоятельства, свидетельствующие о нарушении его прав и законных интересов оспариваемыми действиями в сфере предпринимательской и иной экономической деятельности, не было обосновано, каким образом запрашиваемые правовые акты относятся к информации в сфере экономики и финансов, адресованы обществу, либо возлагают на него каких-либо обязанности.
Девятый арбитражный апелляционный суд оставил без изменения решение Арбитражного суда г. Москвы, а апелляционную жалобу — без удовлетворения.
Федеральный арбитражный суд Московского округа в апреле 2013 года оставил без изменения решение Арбитражного суда города Москвы и постановление Девятого арбитражного апелляционного суда, а кассационную жалобуЗАО «Анализ, Консультации и Маркетинг» без удовлетворения.
Коллегия судей Высшего Арбитражного Суда Российской Федерации в июле 2013 года (Определение № ВАС-9185/13) отказала в передаче дела в Президиум Высшего Арбитражного Суда Российской Федерации для пересмотра в порядке надзора.
Мой комментарий: Замечательно, что все суды – в том числе ВАС (позор ему за это!) ухитрились грубо нарушить сразу несколько положений закона! Оставляя в стороне то, что закон не предусматривает возможность нераскрытия информации ввиду отнесения её к служебной тайне (ну нет у нас закона о служебной тайне!), и то, что закон не требует обосновывать причины, по которым информация запрашивается, — но даже если бы все перечисленные документы содержали самую ужаснейшую из государственных тайн, их все равно следовало предоставить после вымарывания секретных сведений (при этом для каждого вымаранного фрагмента указав основания удаления этих сведений). Коллегию судей в полном составе следовало бы срочно отправить на курсы повышения квалификации 🙂
Для сомневающихся приведу цитаты:
Федеральный закон от 09.02.2009 N8-ФЗ (ред. от 07.06.2013) «Об обеспечении доступа к информации о деятельности государственных органов и органов местного самоуправления»Источник: Официальный сайт Высшего Арбитражного Суда Российской Федерации:Статья 5. Информация о деятельности государственных органов и органов местного самоуправления, доступ к которой ограничен
1. Доступ к информации о деятельности государственных органов и органов местного самоуправления ограничивается в случаях, если указанная информация отнесена в установленном федеральным законом порядке к сведениям, составляющим государственную или иную охраняемую законом тайну.
2. Перечень сведений, относящихся к информации ограниченного доступа, а также порядок отнесения указанных сведений к информации ограниченного доступа устанавливается федеральным законом.
Статья 8. Права пользователя информациейПользователь информацией имеет право:
3) не обосновывать необходимость получения запрашиваемой информации о деятельности государственных органов и органов местного самоуправления, доступ к которой не ограничен;
Статья 19. Порядок предоставления информации о деятельности государственных органов и органов местного самоуправления по запросу
4. В случае, если запрашиваемая информация относится к информации ограниченного доступа, в ответе на запрос указываются вид, наименование, номер и дата принятия акта, в соответствии с которым доступ к этой информации ограничен. В случае, если часть запрашиваемой информации относится к информации ограниченного доступа, а остальная информация является общедоступной, государственный орган или орган местного самоуправления обязан предоставить запрашиваемую информацию, за исключением информации ограниченного доступа.
http://www.arbitr.ru/
Сайты на narod.ru Печальная история
Реставрация WEB 1.0. сайта narod.ru испорченного UCOZ.Прошло много лет с того момента как открылся сервис бесплатного хостинга narod.ru. На равне с канувшими в лета by.ru, nm.ru, vov.ru, он не побоюсь этого слова, являлся одним из “священных” столпов украинского, белорусского, российского интернета. Ведь с 2000 года, там были зарегистрированы миллионы уникальных HTML сайтов, многие из которых превратились из обычных домашних страничек в настоящие серьезные проекты. За десяток лет, сайты narod.ru перестали быть для многих пользователей частным и обыденным явлением, они превратились не только в свидетельство развития эпохи Web 1.0, но и в культурный и цивилизационный феномен. Можно сказать и больше. Это была последняя постмодернистская священная корова НАШЕГО интернета. Этот сервис содержал не просто какие-то абстрактные сайты, он содержал вехи истории жизни, любви, ненависти, технологий, бизнеса, всего того, что раньше умещали в емкую фразу “домашняя страничка”. Только на narod.ru пока еще можно найти очень старые сканированные фотографии городов конца 90х начала 2000х годов, сайты факультетов, научных кафедр, чатовок, событий, забытых богом уже несуществующих деревень, мемориальных страниц, а так же некоторых программ, коих нигде больше не существует и прочего, прочего, прочего…
Но, к сожалению, к моему глубочайшему сожалению, этих возможностей становится все меньше и меньше. 31 января 2013 года, интернет – общественность узнала шокирующую новость о том, что последний и старейший бесплатный хостинг продается сомнительной с точки зрения нашей морали компании UCOZ. До 25 апреля 2013 года все сайты narod.ru были перенесены на сервера нового владельца. Это событие, вошло в анналы современной истории Internet так же, как и поджог Александрийской библиотеки в мировую копилку дикости и варварства.
Не смотря на заявляния и убеждения UCOZ в том, что они будут бережно относиться к сайтам, такого не случилось. Как написал Антон Благовещенский: “Самой сильной стала претензия относительно эротической рекламы на новом сервере”. Но и это далеко не все. Реклама narod.ru была не только не навязчивой, она не влияла на отображение самих сайтов. Не пропадали фреймы, меню, а сами HTML странички без проблем грузились на компьютерах класса Pentium 1.
Но после переноса сайта на UCOZ, были замечены следующие проблемы. Все архивы не zip формата, были удалены. Миллиарды файлов с уникальной информацией были просто затерты! Все их нет, и уже никогда не будет. Файлы *html & *htm, вместо прописанных в них кодировок Windows-1251 и Koi-8, каким-то чертом начали отображаться в UTF! Из-за чего отдельные браузеры сходят с ума и пользователям приходится вручную указывать кодировку. Но самое неприятное ждало впереди. Некоторые домашние странички исчезли физически. И с каждым днем таких HTML сайтов становится все больше и больше. Эта публикация, попытка рассказать историю о том, как вытащить из UCOZ любимые или важные сайты и при этом вернуть их в первоначальное состояние, то есть отреставрировать.
Шаг 1.
Самое важное, с чем столкнется реставратор сайта narod.ru – это необходимое программное обеспечение. Для простоты и доступности, необходимые утилиты уже собраны в архиве Клуба Web 1.0 Fdd5-25.net (http://club.fdd5-25.net/download.htm). Ниже описан пошаговый алгоритм действий для восстановления сайтов, а так же часто возникающие проблемы.
Итак, неискушенному читателю может показаться, что не существует никаких проблем. Достаточно запустить программу Teleport pro, выкачать нужный сайт и начать им пользоваться.
Признаться, так изначально думал и я, пока не столкнулся с рядом проблем, которые постепенно увеличивали багаж программ и необходимых действий.
Для скачивания сайта, я действительно, пользуюсь старым проверенным Teleport Pro. У которого есть несколько неприятных особенностей. Первая, из которых состоит в том, что нужно вручную дописывать некоторые форматы файлов для скачивания. И это приходится делать в каждом новом проекте, заходя в его свойства и добавляя нужные расширения.
Шаг 2.
Следующая неприятная особенность Teleport pro касается его маниакального желания создавать в html файлах тэг (tppabs=”http://”), содержащий путь к месту, откуда был выкачан сайт, а так же в замене внешних ссылок сообщением типа “tppmsgs/msgs0.htm#19”. Но по сути это не проблема. От первого можно избавиться при помощи утилиты TPPABS Remover.
А от второго, при помощи той же самой программы, которой удаляются скрипты ненавистной рекламы. Но об этом чуть позже.
Стоит предупредить, что TPPABS Remover работает только с файлами с расширением *.html. Поэтому все *.htm файлы придется переименовать в *.html, дабы утилита могла их обработать.
Шаг 3.
После того, как сайт выкачан и удалены все ненужные тэги , вы столкнетесь с проблемой, которую я, признаться, изначально не заметил. Все HTML файлы представлены в кодировке UTF-8. При том, что оригинальная кодировка Windows-1251. Это критически важный момент. Ведь программы, которые нам позволят массово и по шаблону удалить рекламу из файлов, а так же ненужные ссылки не понимают иной кодировки. И после того, как эти утилиты отработают, существует риск того, что исходный HTML файл превратится в набор не подлежащих дешифровке каракуль.
Так же читатель возможно поинтересуется, зачем что-то удалять сторонними программами? Ведь теоретически все можно сделать вручную. Поясняю. Например, сайт компьютерного юмора Старковского содержит 379 уникальных HTML страниц. Поэтому лучше даже не пытаться что-то редактировать вручную.
Для массовой смены кодировки в файлах, существует отдельная утилита Web-Sam Unicode2ansi.
Следует отметить, что эта программа не заменяет тэг , она меняет именно кодировку файла. Обратите внимание на изображение представленное ниже. Не смотря на то, что указанная кодировка HTML страницы Windows-1251, по сути это UTF-8. Еще один привет от бережливого UCOZ!
Хочу предупредить по поводу утилиты Web-Sam Unicode2ansi. У нее существует так же одна нехорошая особенность. Если указать слишком большое количество файлов с перезаписью в самих себя, то она может их повредить. Поэтому настоятельно рекомендую конвертировать не более 50 файлов за один подход.
Шаг 4.
После того, как тэги Teleport pro удалены, а кодировка файлов приведена в соответствие с их изначальным состоянием, начинается самый интересный этап – удаление скриптов рекламы UCOZ и остатков рекламы Яндекса. Да-да. Именно так! Судя по всему, многие домашние страницы не загружаются именно потому, что в них присутствует и старая реклама Яндекс и новая от UCOZ.
Фишка этих скриптов в том, что в каждом файле они имеют новый уникальный код. И если, допустим, неработающие баннеры или какие-то шаблонные выражения типа scriptext можно массово удалить или изменить утилитой HTMLCHANGER.dlk4fEtm;IVNdzn84qfL5F9Ik6Shr8cXL7Mh!4!qEpw3JSZUCneULivs;HakwIQOLvfwafmlM3RmiBN5JR;O664OQdzqs2!s;».
При чем как вам стало известно, в каждом новом файле, содержится новый уникальный код. Что не позволяет удалять его по шаблону. Еще один привет от бережливого UCOZ!
Шаг 5.
Мне пришлось долго повозиться прежде, чем найти нужную утилиту меняющую содержимое файлов не просто по шаблону, но и с допущением на подобие результатов команды dir *.*e в DOS. По иронии судьбы такая утилита нашлась в обзоре одного из скачанных под реставрацию сайтов. Это австралийская утилита 2003 года Text Magican v 1.0. Она позволяет не просто удалить шаблон, она позволяет удалить блок текста находящийся в промежутке ОТ и ДО. Смотрите скриншот.
Казалось бы неприятной особенностью программы является то, что она создана для работы с TXT файлами. Но это не такая уж серьезная проблема. Чтобы выбрать HTML достаточно, в меню “открыть” выбирать вкладку “отобразить все файлы”. И так же, как и в случае с Web-Sam Unicode2ansi, не обрабатывать более 50 файлов за один раз.
Пройдя эти пять простых шагов вы сможете полностью очистить HTML страницы от мусора, которым их забил UCOZ, а так же Narod.ru.
Дальнейшие же действия будут зависеть от вашего императива. Сохранять ли старые баннеры или нет? Нужно ли оставлять нерабочие ссылки на внешние сайты или нет? Стоит ли сохранить несуществующую гостевую книгу или нет? Все это уже будет зависеть исключительно от каждого конкретного человека.
В свою очередь хочу добавить следующее, что данный автоматизированный алгоритм действий, помог излечить некоторые важные для меня сайты от болезни UCOZ. Например, мемориальный сайт Немига 99, посвященный трагедии на Немиге, произошедшей 30 мая 1999 года. Когда, спасаясь от дождя около двух с половиной тысяч человек, хлынули в переход станции метро «Немига». Печальным следствием этого события стали 52 погибших и более 150 раненых.
Из-за того, что часть сайта была написана на Java, а сайт перенесли на хостинг UCOZ, меню разделов оказалось неработоспособным, а часть страниц исчезла. Пришлось создавать новый фрейм и ссылки, а так же искать утраченные страницы через Веб Архив http://archive.org/web/, чтобы полностью восстановить информацию.
Проститутки из Питера на сайте putin2000.ru // Питерские интернет-сутенеры подарили Путину свою аудиторию
Проститутки из Питера на сайте putin2000.ru
Оригинал
этого материала
© «Newsru.com», 20.01.2004,
Скриншот: corsika
Питерские интернет-сутенеры подарили Путину свою аудиторию
Предвыборный сайт кандидата в президенты России putin2000.ru, который был зарегистрирован 25 февраля 2000 года лично на Владимира Путина и использовался его предвыборным штабом, еще сегодня с утра предлагал посетителям из его родного города Санкт-Петербурга услуги «девочек по вызову», перенаправляя посетителей на SPBgirls.ru, сообщает Internet.ru.
Правда, через 40 минут после публикации заметки на NEWSru.com главная страница сайта www.putin2000.ru была заменена на пустую. Однако это было только начало. После 17 часов по московскому времени домен www.putin2000.ru стал переадресовывать посетителей на официальный сайт президента www.president.kremlin.ru. Впрочем, внутренние страницы сайта www.putin2000.ru до сегодняшнего вечера предлагали интимные услуги питерских девушек (через 24 минуты после публикации этой фразы внутренние страницы также были заменены на пустые).
Кроме того, к изумлению постоянных посетителей сайта SPBgirls.ru, предлагающего интимные услуги, при наборе этого домена в строке браузера также стала происходить переадресация на официальный сайт президента России. Так продолжалось вплоть до 18:40. Видимо, системный администратор, обслуживающий сайт SPBgirls.ru, допустил ошибку в процессе настройки веб-сервера. Теперь, после того как ошибка была исправлена, адрес putin2000.ru ведет на официальный сайт президента России, а адрес SPBgirls.ru, как и положено, приводит посетителей к питерским девочкам.
Сайт в версии от 2000 года, когда им управлял предвыборный штаб и.о. президента России, можно увидеть с помощью сервиса WebArchive.org, пройдя по этой ссылке.
Сайт putin2000.ru никто не взламывал. В 2004 году истек срок регистрации этого домена, а продлить его забыли или не захотели. Теперь предвыборный сайт Путина зарегистрирован на имя некоего Константина Воробьева, а в качестве координат указан питерский номер мобильного телефона.
Корреспондент NEWSru.com позвонил Константину Воробьеву, который выкупил себе права на предвыборный сайт президента. Перед началом разговора, правда, Воробьев предупредил, что «адекватных ответов не обещает». Судя по голосу, господин Воробьев был не совсем трезв.
«Я купил его из-за популярности: у сайта была очень высокая степень цитирования», — заявил Воробьев. На вопрос, обращались ли к нему после покупки домена представители питерской администрации, представители президента или правоохранительных органов, Воробьев ответил отрицательно.
«Все про этот сайт уже давно забыли», - заявил он NEWSru.com.
Воробьев утверждает, что он не в курсе, что за компания занимает домен www.putin2000.ru в настоящее время, а виртуальный бордель, открытый по этому адресу, к нему отношения не имеет. Никаких угрызений совести в связи с использованием имени главы государства в личных целях Воробьев не испытывает.
Напоследок Константин Воробьев поинтересовался, не хочет ли его собеседник перекупить у него домен. Отрицательный ответ Воробьева определенно огорчил.
В пресс-службе президента NEWSru.com сообщили, что официальные комментарии по этому вопросу будут даны позднее.
Так в 2000 году описывала содержание сайта Putin2000.ru немецкая газета Die Welt.
«Владимир Путин изображен на главной странице своего сайта в интернете в скромных черно-белых тонах. На сайте и.о. президента России www.putin2000.ru собрано все, что, по мнению его команды, необходимо для победы на предстоящих выборах.
Наряду с телевидением интернет превратился в поле боя, на котором во всех частях огромной страны ведут активную борьбу кандидаты на пост президента России. «Интернет — наше окно в мир», говорит учительница Люба с полуострова Камчатка, которая может открывать это окно только в школе, потому что дома у нее нет телефона», — писала немецкая Die Welt.
«На сайте Путина имеется англоязычная версия. С первой страницы видно, что основной проблемой кандидат Путин считает Чечню. Это подтверждают и представленные здесь письма его сторонников, которые считают справедливой антитеррористическую операцию на Кавказе. Только после этого размещаются выступления руководителей социологических институтов, предсказывающие Путину победу на выборах.
Полностью разочаровывает рубрика «программа»: ее просто нет. Путин лишь формулирует «нашу общую цель», которая заключается в создании «достойной жизни», которую хотят вести «большинство моих граждан». Гладкую биографию Путина можно найти также еще и на другом сайте по адресу: www.president.kremlin.ru».
Потерянные, но не забытые: поиск страниц в неархивированной сети
В этом разделе мы изучаем RQ4: полезны ли полученные производные представления неархивированных страниц и веб-сайтов на практике? Улавливают ли они достаточно уникального содержимого страницы, чтобы его можно было найти среди миллионов других представлений страниц? Мы фокусируемся на извлечении неархивированных веб-страниц на основе их производных представлений в настройке поиска по известным элементам и сравниваем уровень страницы с представлениями на уровне хоста.Наше открытие состоит в том, что сжатое представление обычно достаточно богато, чтобы идентифицировать страницы в неархивированной сети: в настройке поиска по известным элементам мы извлекаем эти страницы в среднем в первых рядах. Агрегация страниц на уровне хоста приводит к дальнейшему повышению эффективности поиска.
Настройка оценки
Чтобы оценить полезность обнаруженных свидетельств неархивированной сети, мы проиндексировали представления в внешней ауре архива. Следовательно, мы проиндексировали неархивированные страницы, обнаруженные с помощью структуры ссылок архива, родительский домен которой равен , а не в списке поиска.Эти представления состоят из неархивированных URL-адресов, агрегированного текста привязки и слов URL-адресов неархивированных страниц и хостов. Мы проиндексировали эти документы с помощью Terrier 3.5 IR Platform [26], используя базовую фильтрацию по ключевым словам и поиск по Портеру. Мы проиндексировали три набора представлений:
представлений на уровне страниц для всех 5,19 млн неархивированных URL-адресов
представлений на уровне страниц для 324.807 домашних страниц (входные страницы хостов)
агрегированных представлений на уровне сайта для 324,807 неархивированных хостов
Для каждого набора представлений мы создали три индекса. Первый индекс каждой категории использует только агрегированные якорные слова ( anchT ). Второй индекс ( urlW ) использует другое свидетельство: слова, содержащиеся в URL.Неалфавитно-цифровые символы были удалены из URL-адресов, а слова длиной от 2 до 20 символов были проиндексированы. Наконец, третий индекс для каждого набора представлений состоит как из агрегированного текста привязки, так и из слов URL ( anchTUrlW ).
Для создания запросов с известными элементами была взята стратифицированная выборка набора данных, состоящая из 500 случайных URL-адресов не домашних страниц и 500 случайных домашних страниц. Здесь мы определяем URL-адрес не домашней страницы как имеющий косую черту 1 или более, а URL-адрес домашней страницы как имеющий косую черту 0.Эти URL-адреса были проверены в Интернет-архиве (страницы заархивированы в 2012 году). Если моментальный снимок не был доступен в Интернет-архиве (например, из-за исключения robots.txt ), URL-адрес проверялся по действующей сети. Если с доказательствами страницы нельзя было ознакомиться, выбирался следующий URL-адрес в списке, пока не было достигнуто в общей сложности 150 запросов на категорию. Обсуждаемые страницы использовались двумя аннотаторами для создания запросов на известные элементы. В частности, после просмотра целевой страницы вкладка или окно закрываются, и создатель темы записывает запрос, который он или она будет использовать для уточнения целевой страницы с помощью стандартной поисковой системы.Следовательно, запрос был основан на их воспоминании о содержимом страницы, а аннотаторы совершенно не знали о текстовом представлении привязки (полученном из страниц, ссылающихся на цель). Как оказалось, создатели темы использовали запросы из 5–7 слов как для домашних, так и для не домашних страниц. Набор запросов первого аннотатора использовался для оценки (\ (n = 300 \)), а набор запросов второго аннотатора использовался для проверки результатов (\ (n = 100 \)). Мы обнаружили, что разница между аннотаторами была небольшой: средняя разница в результирующих оценках MRR между аннотаторами для 100 запросов на домашнюю страницу по всем индексам составила 8%, а средняя разница в уровне успеха составила 3%.
Для первой части нашей оценки (раздел 7.2) мы выполнили эти 300 запросов к домашней и не домашней страницам для anchT , urlW и индексов уровня страницы anchTUrlW , созданных в Terrier, используя его поиск InL2 по умолчанию. модель на основе DFR и сохранила рейтинг нашего URL в списке результатов. Во второй части нашей оценки (раздел 7.3) 150 запросов к домашней странице были выполнены по индексам хостов на уровне страницы и на уровне сайта во внешней ауре архива.Q {\ frac {1} {\ hbox {rank} _i}} \ end {align} $$
(1)
MRR (1) — это статистическая мера, которая оценивает вероятность получения правильных результатов. Это среднее значение первого правильного результата для каждого запроса (рассчитывается с помощью \ (\ frac {1} {\ mathrm {rank}} \)). Мы также вычисляем коэффициент успеха на 10-м ранге, то есть для какой части тем мы фактически получаем правильный URL-адрес в пределах первых 10 рангов.
Мы использовали неархивированные страницы, обнаруженные в голландском веб-архиве, которые либо доступны в Интернет-архиве, либо все еще доступны в интерактивном режиме, чтобы иметь основную правдивую информацию о содержании страницы.Это потенциально вносит предвзятость — может быть некоторая разница между страницами, которые все еще активны или были заархивированы, и теми, которые не являются таковыми, — но URL-адреса не предполагают резких различий. Из всех обследованных случайно выбранных домашних страниц 79,9% были доступны либо через Интернет-архив, либо через Интернет. Однако это не относилось к не-домашним страницам (случайно выбранным страницам с числом косой черты 1 или более), поскольку только 49,8% можно было получить через Интернет-архив или интерактивную сеть.Основные причины того, что многие URL-адреса не могут быть заархивированы, включают ограничительные политики robots.txt (например, страницы Facebook), содержимое, специально исключенное из архива (например, учетные записи Twitter и твиты), а также ссылки, указывающие на автоматически сгенерированные страницы (например, «поделиться» в LinkedIn ссылки). Недоступность URL-адресов усиливает потенциальную полезность сгенерированных представлений страниц, например, с помощью агрегированного якорного текста, поскольку больше невозможно получить свидетельства страницы.
Страничные представления
В этом разделе содержится первая часть нашей оценки, в которой основное внимание уделяется постраничным представлениям неархивированного содержимого.Мы используем индексы представлений 5,19 млн страниц во внешней ауре архива в сочетании со 150 запросами об известных элементах домашней страницы и 150 запросами не на главной странице.
MRR и вероятность успеха
баллов MRR были рассчитаны для исследованных домашних страниц и не домашних страниц, чтобы проверить, насколько сгенерированных представлений достаточно для получения неархивированных URL. Окончательные результаты оценки на основе MRR приведены в Таблице 20. Мы обнаружили, что оценки MRR для домашних и не домашних страниц очень похожи, хотя можно увидеть некоторые различия.При использовании индекса якорного текста домашние страницы получают более высокий балл, чем другие, возможно, из-за более богатого представления, доступного для этих домашних страниц. Оценка индекса слов URL-адресов, естественно, выше для страниц, не являющихся домашними: у них более длинные URL-адреса и, следовательно, больше слов, которые могут соответствовать словам, используемым в запросе. Наконец, мы можем видеть, что комбинация якоря и URL-слов свидетельствует о значительном повышении эффективности поиска: MRR близко к 0,5, что означает, что в среднем случае правильный результат получается на втором ранге.
Таблица 20 Средний взаимный ранг (MRR) Таблица 21 Показатели успешности (целевая страница в топ-10)Мы также исследовали коэффициент успешности, то есть для какой степени тем мы действительно получаем правильный URL в первых 10 рангах? Таблица 21 показывает, что снова есть некоторое сходство между домашними и не домашними страницами. Домашние страницы получают больше очков при использовании индекса привязки текста, чем другие страницы: 46,7% могут быть извлечены.С другой стороны, не-домашние страницы работают лучше, чем домашние страницы, использующие URL-слова: 46,0% не-домашних страниц включены в первые 10 рангов. Опять же, мы видим, что объединение обоих представлений приводит к значительному увеличению вероятности успеха: мы можем получить 64,0% домашних страниц и 55,3% неосновных страниц в первых 10 рангах.
Оценки MRR показывают, что текст привязки в сочетании с токенизированными словами URL-адреса может быть достаточно разборчивым, чтобы выполнять поиск по известным элементам: правильные результаты обычно могут быть получены в пределах первых рангов.Во-вторых, показатели успешности показывают, что, комбинируя якорный текст и свидетельство URL-слова, можно получить 64% домашних страниц и 55,3% более глубоких страниц. Это дает положительное свидетельство полезности этих представлений.
Производительность производных представлений сопоставима с производительностью обычных представлений веб-страниц [11]. Здесь мы использовали стандартную модель поиска без включения различных априорных факторов, адаптированных к поставленной задаче [20].
Влияние степени
Теперь мы исследуем влияние количества уникальных входящих ссылок на полноту представления текста привязки на уровне страницы.Например, домашняя страница Центра европейских реформ (cer.org.uk) получает ссылки с 3 уникальных хостов: portill.nl, europa-nu.nl и media.europa-nu.nl, вместе составляя 5 уникальных якорных слов, а на странице actionaid.org/kenya есть 1 внутрисерверная ссылка с actionaid.org, содержащая только 1 якорное слово. Для объединенных 300 тем (доменов и не доменов вместе) мы вычислили среднее количество уникальных слов, MRR и количество домашних страниц в подмножестве.
Таблица 22 Деление по степени уникальных хостовРезультаты в таблице 22 показывают, что увеличение количества входящих ссылок от уникальных хостов приводит к увеличению среднего количества слов.Однако он также иллюстрирует искаженное распределение нашего набора данных: большинство страниц (251 из 300) имеют ссылки только с одного исходного хоста, в то время как гораздо меньший набор (49 из 300) имеет ссылки с 2 или более уникальных исходных хостов. . В таблице также представлены доказательства гипотезы о том, что домашние страницы имеют больше входящих ссылок с уникальных хостов, чем с других: при степени 2 или более домашние страницы занимают более 80% набора страниц. Мы также можем наблюдать из данных, что MRR с использованием индекса текста привязки в нашей выборке является самым высоким при наличии ссылок как минимум с 4 уникальных хостов.
Представления на основе сайтов
Выявленная важность более высокой степени и уникального количества слов для представления неархивированных страниц побудила нас поэкспериментировать с другими подходами для улучшения представлений. Эта вторая часть нашей оценки сравнивает эффективность поиска представлений хостов на странице входа (на уровне страниц) с агрегированными представлениями всех страниц на определенном хосте (на уровне сайта). Мы используем индексы, созданные с использованием этих двух наборов из 324.807 представлений в сочетании со 150 запросами на домашнюю страницу известных элементов.
MRR и процент успеха
В таблице 23 приведены оценки MRR для представлений на уровне страницы и сайта. Оценка индекса уровня сайта, основанного на тексте привязки, на 4% выше, чем индекс текста привязки на уровне страницы. В наших производных представлениях на уровне сайта мы агрегировали до 100 URL-адресов и токенизировали слова URL-адресов. Ценность этого подхода видна в оценке MRR для индекса urlW на уровне сайта : оценка MRR увеличивается на 5%.Наконец, комбинированные представления ( AnchTUrlW ) работают лучше всего с более высоким рейтингом MRR, чем только индексы AnchT и UrlW . Показатель MRR улучшился почти на 6% за счет агрегирования данных якорного текста и URL-слов, что показывает ценность агрегирования доказательств на основе ссылок на уровне сайта.
Таблица 23 Представления сайтов: средний взаимный ранг (MRR) Таблица 24 Сравнение показателей MRR для запросов на домашнюю страницу на уровне сайта ( srAnchTUrlW ) и на уровне страницы ( plAnchTUrlW ) индексы текста привязки Таблица 25 Покрытие URL-адресов по представлениям сайтов и связанным подсчетам, среднему количеству слов и MRRЧтобы лучше понять, какие запросы работают лучше или хуже, мы более подробно рассмотрим различия в производительности для всех 150 запросов домашней страницы по индексам AnchTUrlW на уровне страницы и на уровне сайта (Таблица 24).Для 21 темы лучше работают представления на основе сайтов, а для 14 тем — представления на основе страниц. Следовательно, мы видим некоторые доказательства как улучшения представления сайтов, так и потенциального появления шума (влияющего на темы, которые не работали лучше). Еще одно поразительное наблюдение: оценки по 115 темам остались прежними. Причина может быть связана с неравномерным распределением нашего набора данных: для некоторых хостов у нас может быть несколько захваченных URL-адресов, которые можно использовать в представлении на основе сайта.
Таким образом, теперь мы смотрим на количество URL-адресов, доступных для каждого хоста, поскольку это может повлиять на полноту представлений. Таблица 25 показывает, что для большинства целевых хостов (103 из 150 запросов с известными элементами) в нашем наборе данных есть только один URL. Для 47 хостов доступны 2 или более URL. В таблице мы также видим, что среднее количество уникальных слов увеличивается с увеличением количества охваченных URL-адресов. Для 47 хостов с двумя или более закрытыми URL-адресами значения MRR для представлений на уровне сайта явно выше, чем для представлений на уровне страниц.
Таблица 26 Представления сайтов: показатели успеха (целевая страница в топ-10)Наконец, мы смотрим на показатели успеха (количество тем с правильными URL-адресами в первых 10 результатах). Показатели успешности в таблице 26 показывают другой результат, чем сравнение показателей MRR: оценки представлений на уровне страницы и на уровне сайта очень похожи. Показатель успешности индекса привязки текста на уровне сайта немного ниже, а индекс слов URL — немного улучшен.Подобные оценки могут быть вызваны неравномерным распределением набора данных. Как мы видели в таблице 25, для 103 из 150 хостов в нашем оценочном наборе у нас есть только 1 захваченный URL. В таких случаях агрегирование URL-адресов по хостам не увеличивает вероятность успеха.
Подводя итог, мы исследовали, действительно ли производные представления характеризуют уникальное содержание неархивированных веб-страниц. Мы провели критический тестовый отбор как задачу по поиску известных элементов, требующую найти уникальные страницы среди миллионов других страниц — настоящая задача «иголка в стоге сена».Результат первой части нашей оценки явно положительный: с оценкой MRR около 0,5 мы находим релевантные страницы в среднем на втором ранге, а для большинства страниц соответствующая страница входит в топ-10 результатов. Во второй части нашей оценки представления на уровне страниц сравнивались с представлениями на уровне сайта. Мы обнаружили, что использование представлений на уровне сайта повышает эффективность поиска по запросам домашней страницы на 4–6%, в то время как показатели успеха остаются стабильными. Следовательно, ответ на наш четвертый вопрос исследования снова положительный: мы можем реконструировать представления неархивированных веб-страниц, которые содержательно характеризуют их содержание.
Как извлечь URL-адреса из Archive.org (Wayback Machine)
Бывают случаи, когда клиент может прийти к вам после миграции CMS или домена, что привело к ранжированию или потере трафика. Эту ситуацию сложно исправить, если вы не можете найти какие-либо предыдущие файлы sitemap.xml или более старые обходы Screaming Frog.
Если некоторые страницы имеют высокую посещаемость, продажи или ценность потенциальных клиентов, они могут быть полностью потеряны. Если бы на некоторых страницах было большое количество входящих ссылок, то ценность этих ссылок, измеряемая в PageRank, Link Equity, Trust Flow и т. Д., Также была бы полностью потеряна.
Без полного знания прежней структуры сайта и URL-адресов внутри него, тупиковые страницы 404 могут потерять большую ценность.
Мы сами недавно столкнулись с такой же ситуацией, и нам пришлось разобраться — благодаря большой руке помощи Лиама Делаханти. Спасибо, Лиам! — решение, которое мы хотели бы передать вам.
Использование данных Archive.org
Archive.org, или Wayback Machine , как его чаще называют, — это поисковый робот и система индексации веб-страниц в Интернете для исторического архивирования.Это отличный инструмент, который позволяет нам взглянуть на то, как выглядел Google, например, в 1998 году, когда он все еще находился на стадии бета-тестирования.
Поскольку он сканирует большую часть Интернета, весьма вероятно, что ваш веб-сайт был просканирован их поисковым роботом. Получив эти общедоступные данные, мы можем составить приблизительное представление о возможной структуре сайта на предварительно перенесенном веб-сайте.
Данные находятся в свободном доступе для использования, а на Archive.org краткое описание того, как можно получить доступ и использовать API, доступно здесь.
Я сам не являюсь специалистом по API, поэтому в следующем процессе я вернусь к классическому подходу копирования и вставки, который могут использовать специалисты по оптимизации поисковых систем с любым уровнем квалификации.
Как извлечь старые URL-адреса из Archive.org
1. Найдите на своем веб-сайте файл JSON или TXT
Начните с перехода по следующему URL-адресу, изменив удерживающий корневой домен example.com на собственный корень вашего веб-сайта.
Для файла JSON:
http: // web.archive.org/cdx/search/cdx?url=example.com*&output=json
Для формата TXT:
http://web.archive.org/cdx/search/cdx?url=example.com*&output=txt
Если вам нужно ограничить временные рамки сканирования, вы можете добавить следующие параметры в конец, чтобы сузить диапазон.
ггггMMddhhmmss
Пример:
http://web.archive.org/cdx/search/cdx?url=example.com*&output=txt&from=2010&to=2018
Вы также можете уменьшить или увеличить лимит в соответствии с вашими потребностями.
Пример:
http://web.archive.org/cdx/search/cdx?url=example.com*&output=txt&limit=999999
Вы можете найти полное изложение доступных параметров фильтрации здесь:
https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server#filtering
2. Вставьте в электронную таблицу и разделите на столбцы
Скопируйте весь текст загруженной страницы и вставьте результаты в электронную таблицу. В данном случае мы используем Google Таблицы.
Выберите весь диапазон данных и используйте параметр «Разбить текст на столбцы…» в меню «Данные» на панели инструментов. Поскольку мы используем форматирование TXT, мы используем разделитель «пробел» для разделения данных.
3. Удалите столбцы, оставив только URL-адреса
Удалите все ненужные столбцы, чтобы оставить только URL-адреса. Обычно это столбец C.
4. Используйте команду «Найти и заменить», чтобы удалить: 80 из URL-адресов
Выберите столбец URL-адресов и с помощью функции «Найти и заменить» найдите текст «: 80» и замените его ничем (оставьте текстовое поле замены пустым).Это приведет в порядок все URL-адреса, иногда удаляя десятки тысяч экземпляров «: 80»
5. Используйте формулу = UNIQUE для удаления дубликатов
В отдельном столбце используйте формулу UNIQUE , т. Е. = UNIQUE (A: A) , чтобы удалить дубликаты из первого столбца, оставив только отдельные URL-адреса для проверки кодов состояния 3XX, 4XX и 5XX.
6. Сканируйте URL-адреса с помощью Screaming Frog и извлеките отчет для проверки
Скопируйте окончательный список URL-адресов, откройте Screaming Frog и переключите его в режим списка, затем вставьте собранные URL-адреса.
Экспортируйте завершенное сканирование в формате CSV и скопируйте / вставьте данные в другую вкладку своей электронной таблицы. На этом этапе вы можете либо удалить все столбцы, кроме столбцов URL-адреса и кода состояния, либо выполнить ВПР для заполнения соответствующих статусов для исходного списка.
Теперь вы можете отфильтровать этот полный список URL-адресов, чтобы найти страницы 404 или цепочки переадресации.
Другие преимущества и советы
Этот процесс можно улучшить, собирая URL-адреса с помощью Google Analytics как можно раньше, не забывая проверять все прежние URL-адреса, которые в прошлом могли иметь высокий трафик или страницы с высокой конверсией продаж.
Сделав еще один шаг вперед, вы можете найти больше URL-адресов с помощью других веб-сканеров, таких как Majestic, который также ведет журнал просканированных URL-адресов, которые вы также можете загрузить и добавить в свой общий список, прежде чем удалять все дубликаты и сканировать их.
Кроме того, важно запустить этот список URL-адресов с помощью такого инструмента, как Majestic, чтобы увидеть, есть ли какие-либо обратные ссылки на страницы с кодами состояния 3XX, 4XX и 5XX, где ссылочный вес может быть рассредоточен или полностью потерян
Этот процесс также можно использовать для построения ссылок.Следуя той же процедуре для веб-сайтов конкурентов, вы можете найти страницы с кодами статуса 4XX с обратными ссылками на них. Вы можете использовать Wayback Machine, чтобы увидеть, какими были эти страницы, а затем воссоздать и улучшить их старый контент — не копируя ничего из в их оригинале — прежде чем обращаться к связывающим доменам, чтобы предложить ваш новый контент в качестве замены для этого неработающей ссылке.
И все. Простой процесс сбора URL-адресов давно забытого или недавно перенесенного старого веб-сайта.
Еще раз спасибо Liam Delahunty за руководство в этом процессе. Это полностью его детище.
Находите, просматривайте и загружайте старые версии веб-сайтов (которые больше не существуют)
С помощью Wayback Machine вы сможете получить доступ к старым веб-страницам, которые больше не доступны по их предыдущему URL-адресу. Таким образом вы сможете как минимум найти и сохранить текстовое содержимое нужной вам страницы. Но иногда вам нужно больше, чем просто текст старой статьи.Иногда проблема больше. Возможно, страницы больше нет, и резервная копия тоже не помогает. Возможно, вы хотите загрузить весь веб-сайт, чтобы отредактировать или сохранить исходный код, отфильтровать неработающие ссылки или протестировать старую версию своего веб-сайта для оптимизации SEO. Все это возможно с помощью Wayback-Machine-Downloader.
На GitHub есть загрузчик с открытым исходным кодом, а именно Wayback Machine Downloader. Сначала вы должны установить Ruby. Но вам не нужно быть профессионалом Ruby, чтобы использовать программу.Разработчики перечисляют наиболее важные команды кода прямо на странице загрузки. Введите требуемый URL-адрес, и программа загрузит соответствующие файлы на ваш компьютер. Он автоматически создает страницы index.html, совместимые с Apache и NGINX. Опытные пользователи могут более подробно определять параметры временных меток, URL-фильтров и снимков.
Веб-инструмент Archivarix подходит для небольших веб-сайтов или блогов благодаря четко структурированному пользовательскому интерфейсу. Услуга предоставляется бесплатно, если она используется для веб-сайтов с менее чем 200 файлами, в противном случае взимается плата.Вы должны зарегистрироваться, чтобы использовать Archivarix. Затем просто введите желаемый домен и определите параметры оптимизации и структуры ссылок с помощью нескольких щелчков мышью. Затем введите свой адрес электронной почты. Если загрузка из архива Интернет-сайта завершена, Archivarix отправляет zip-файл на этот адрес.
Archive.org сам по себе не предлагает загрузчик веб-сайтов. Однако в качестве члена библиотеки, то есть вошедшего в систему пользователя, для загрузки доступны миллионы текстов, изображений и аудиофайлов. Если у вас есть права на что-либо, вы можете загрузить это для публичного некоммерческого использования, как это делает НАСА с большей частью своих аудио- и визуальных материалов.Например, следующее видео, снятое ISS, заархивировано как обычное произведение по лицензии Creative Commons.
Как просматривать потерянные веб-страницы
Если веб-страница, которую вы хотели открыть, недоступна — причины могут варьироваться от временной сетевой проблемы до полного удаления страницы с веб-сайта — тогда вам не нужно терять надежду . На самом деле можно восстановить резервные копии большинства страниц из Интернета с помощью небольшого ноу-хау. Весь процесс невероятно прост, и вы найдете его очень полезным, если изучите тему и обнаружите, что ссылки, которые вы сохраняли в течение недель или даже месяцев, больше не работают.
Если вы хотите прочитать веб-страницу, которая была удалена или по другим причинам недоступна, это то, что вы можете сделать.
Wayback Machine
Archive.org Wayback, вероятно, лучший инструмент для восстановления любой удаленной веб-страницы. Это часть Интернет-архива, некоммерческой организации, которая пытается дублировать весь контент в Интернете. Он сохранил более 435 миллиардов веб-страниц, что, вероятно, не весь контент в Интернете, но все же впечатляет.Страницы фиксируются несколько раз, поэтому, например, мы использовали Wayback Machine, чтобы просмотреть домашнюю страницу NDTV Gadgets в течение нескольких разных лет, и увидели, что наш дизайн со временем эволюционировал.
Вот как им пользоваться.
Откройте сайт Wayback.
Введите URL-адрес отсутствующего веб-сайта или веб-страницы, которую вы хотите открыть, в поле вверху.
Щелкните Обзор истории .
Вы увидите представление календаря.Выберите год вверху, а затем дату из списка месяцев ниже.
Вот и все! Вам будет показана сохраненная версия страницы с этой даты.
Кэш поисковой системы
Если вы ищете страницу, которая была недавно удалена, то, возможно, будет проще найти ее с помощью поисковой системы, такой как Google, Yahoo или Bing. Пока вы можете найти веб-страницу в поисковой системе, вы также сможете загрузить резервную копию страницы.Вот как это работает:
Откройте понравившуюся поисковую систему. Кеширование Google очень хорошее, поэтому мы рекомендуем вам его использовать.
Вставьте ссылку на отсутствующую веб-страницу в строку поиска, если вы ее знаете, или просто выполните поиск страницы, чтобы найти нужную ссылку.
Под синим текстом ссылки вы увидите строку зеленого текста, которая представляет собой URL-адрес веб-страницы. Щелкните стрелку вниз рядом с зеленым текстом URL-адреса.
Нажмите Кэшировано .Это покажет вам сохраненную версию нужной страницы, а также подробную информацию о том, когда была сделана резервная копия.
Если эта страница не загружается должным образом, вы можете попробовать щелкнуть Текстовая версия в правом верхнем углу. Это приведет к потере всех изображений, которые были на странице, но, если они загружаются неправильно, это все равно позволит вам получить важные данные, которые вам нужны.
Сохранение необходимых веб-страниц
Если вы хотите сохранить веб-страницы для исследовательских целей, лучше сохранить их заранее.Сделать это из браузера очень просто:
Перейдите на веб-сайт, который хотите сохранить.
Нажмите Ctrl + S .
Дайте ему любое имя файла и нажмите Сохранить .
Это сохранит страницу на вашем компьютере, и вы сможете получить к ней доступ в любое время. Если вы не используете свой компьютер, вы всегда можете использовать сторонние службы, такие как Pocket, для сохранения веб-страниц для чтения в автономном режиме — после установки расширения сохранять страницы так же просто, как нажимать кнопку Pocket в браузере, когда вы ‘ повторно прочтите страницу, которую вы хотите сохранить, или щелкните правой кнопкой мыши ссылку и выберите Сохранить в Pocket .
Для получения дополнительных руководств посетите наш раздел «Как сделать».
Как найти старые сайты, которые Google не покажет
Интернет как «место» постоянно растет. Мы создаем все больше и больше веб-страниц каждый день — на самом деле так много, что может казаться, что некоторые его уголки потеряны для времени.
Как оказалось, они могут быть потеряны только для Google. Ранее в этом году веб-разработчики-блоггеры Тим Брей и Марко Фьоретти отметили, что Google, похоже, прекратил полностью индексировать Интернет для поиска Google.В результате некоторые старые веб-сайты, возраст которых превышает 10 лет, не отображаются в поиске Google. Оба автора сетовали на то, что ограничение эффективной памяти Google последним десятилетием, хотя и логично, когда мы сталкиваемся со сложной задачей играть информационным консьержем для каждого нашего причудливого вопроса, заставляет нас считаться с тем фактом, что, когда вы используете Google для исторического поиска, есть возможно больше ответов там.
Согласно сообщению BoingBoing, основанному на замечаниях Брея, DuckDuckGo и Bing по-прежнему предлагают более полные записи об Интернете, в частности, показывая веб-страницы, которые Google прекратил индексировать для поиска.Если вы ищете определенный веб-сайт до 2009 года и не можете его найти, любой из них — хороший первый шаг. Если это не сработает, всегда возможно, что кто-то другой, кому нужна была та же страница, которую вы искали, сохранил ее в виде архива на Wayback Machine.
А как насчет общих вопросов? Вопросы, на которые вы еще не знаете ответа? Историческое исследование из ранней паутины? Для этого есть другие, более специализированные варианты. Сообщение на форуме Hacker News предлагает пару поисковых систем.Million Short, который позволяет запускать поиск и автоматически пропускать самые популярные ответы, чтобы глубже проникнуть в Интернет. Wiby.me — это «поисковая система для классических веб-сайтов», созданная для того, чтобы помогать людям находить страницы для любителей и другие архаичные особенности Интернета.
В новостной ветке Hacker также упоминается Pinboard, минималистичный сервис закладок, подобный Pocket, который имеет ключевую функцию для архивистов: если вы подпишетесь на его премиум-сервис — 11 долларов в год — Pinboard сделает веб-архив каждой страницы вы сэкономили.Если вы просматриваете старые, не проиндексированные материалы, такой инструмент может упростить возврат к определенным частям старого Интернета, которые вы, возможно, захотите или должны будете вспомнить снова.
G / O Media может получить комиссию
Почему так мало осталось от раннего Интернета
«Как только происходит смена правительства или реструктуризация quangos, сайты закрываются», — говорит Джейн Винтерс, профессор цифровых гуманитарных наук в Лондонском университете. «Или посмотрите на сайты предвыборной агитации, которые по своей природе созданы как временные.”
Иногда потерянные участки отражают даже более сильные сейсмические изменения; смерть и рождение самих народов. «Это случилось с Югославией; .yu был доменом верхнего уровня для Югославии, и это закончилось, когда он рухнул. «Есть исследователь, который пытается восстановить то, что было до распада», — говорит она.
«Политическое так часто связано с техническим».
Есть, наверное, легкая серебряная подкладка. «Я вырос в истории, и нам всегда приходилось иметь дело с пробелами в исторических записях, о некоторых из которых мы знаем, а о некоторых просто не имеем представления.
Дама Венди Холл также видит параллели с физическим. Когда ей было 15, в конце 1960-х, она появилась в составе аудитории на записи музыкального шоу BBC Top of the Pops.
Шоу было показано на Рождество. «Телевизор был включен, и моя мама сказала:« Вот ты где! Но я это упустил. И с тех пор я пошел на Би-би-си и попытался получить его копию — они записали это на пленку. Я так и не увидел этого ».
—
Вам понравился этот рассказ? Тогда у нас есть просьба об одолжении.Присоединяйтесь к своим коллегам-читателям и проголосуйте за нас в конкурсе Webby Awards ! Это займет всего минуту и поможет поддержать оригинальную и глубокую журналистику. Спасибо!
Присоединяйтесь к 900 000+ будущих поклонников, поставив нам лайк на Facebook или подписавшись на нас в Twitter или Instagram .
Если вам понравилась эта история, подпишитесь на еженедельник BBC.com предлагает информационный бюллетень под названием «Если вы прочитаете только 6 статей на этой неделе». Тщательно подобранная подборка историй из BBC Future, Culture, Capital и Travel, которые доставляются на ваш почтовый ящик каждую пятницу.
Расширение использования веб-архивов путем рекомендации заархивированных веб-страниц, использующих только URI
% PDF-1.7 % 1 0 объект > эндобдж 2 0 obj > поток 2019-07-01T11: 37: 37-07: 002019-07-01T11: 37: 36-07: 002019-07-01T11: 37: 37-07: 00Appligent AppendPDF Pro 5.5uuid: 5e4fd380-abe2-11b2-0a00- 782dad000000uuid: 5e507ef2-abe2-11b2-0a00-90695b33ff7fapplication / pdf