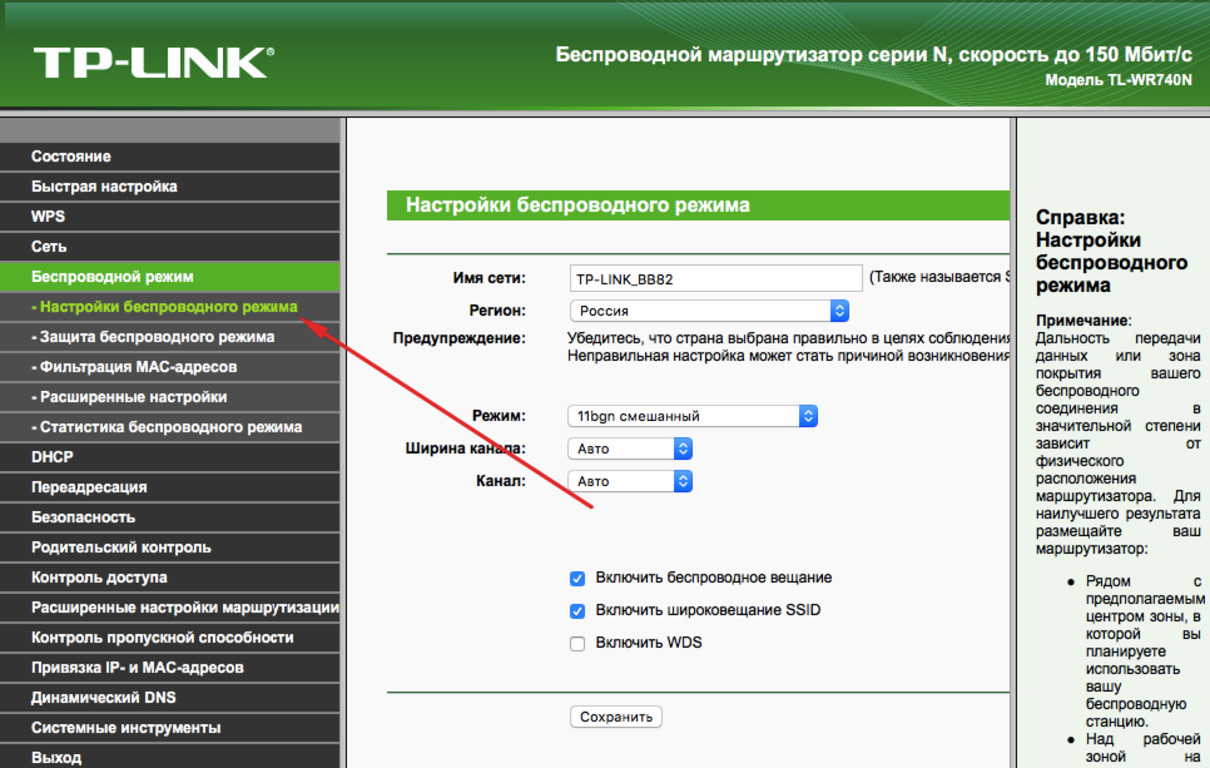
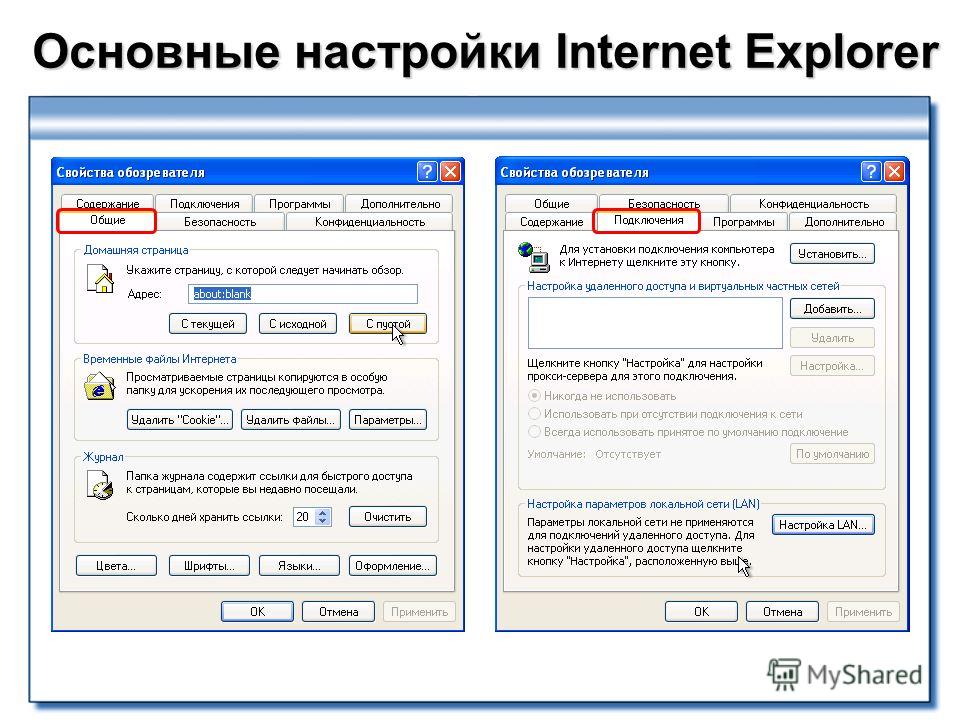
Настройка с использованием SES/WPS или AOSS™ из меню панели управления (автоматической беспроводной режим)
При успешном подключении аппарата к точке доступа/маршрутизатору на ЖКД отобразится Подключена. Теперь аппарат можно использовать в беспроводной сети.
Если было обнаружено перекрытие сеансов, на ЖКД отобразится Ошиб. Соединения. Аппарат обнаружил в сети несколько точек доступа/маршрутизаторов с включенным режимом SecureEasySetup™, Wi-Fi Protected Setup или AOSS™. Убедитесь, что режим SecureEasySetup™, Wi-Fi Protected Setup или AOSS™ включен только для одной точки доступа/маршрутизатора и попробуйте повторить операцию с шага 9.Если аппарат не обнаружил точку доступа/маршрутизатор в используемой сети с включенным режимом SecureEasySetup™, Wi-Fi Protected Setup или AOSS™, на ЖКД отобразится Нет точки дост.. Переместите аппарат ближе к точке доступа/маршрутизатору и попробуйте повторить операцию с шага 9.При неуспешном подключении аппарата к точке доступа/маршрутизатору на ЖКД отобразится Сбой соединения. Попробуйте повторить операцию с пункта 9. Если снова отображается это же сообщение, восстановите в устройстве заводские настройки по умолчанию и повторите операцию. (Для получения информации о сбросе см. раздел Восстановление заводских настроек сети.)
Попробуйте повторить операцию с пункта 9. Если снова отображается это же сообщение, восстановите в устройстве заводские настройки по умолчанию и повторите операцию. (Для получения информации о сбросе см. раздел Восстановление заводских настроек сети.)Сообщения на ЖК-дисплее при использовании SES/WPS/AOSS™ из меню панели управления
Сообщение на ЖК-дисплее | Состояние соединения | Действия | |
Настройка WLAN | Поиск или обращение к точке доступа и загрузка настроек из точки доступа. | — | |
Подключение SES Подключение WPS Подключение AOSS | Подключение к точке доступа. | — | |
Подключена | Успешное подключение. | — | |
Ошиб. Соединения | Обнаружено перекрытие сеансов. | Убедитесь, что режим SecureEasySetup™, Wi-Fi Protected Setup или AOSS™ включен только для одного маршрутизатора или точки доступа, затем повторите операцию с шага 9. | |
Нет точки дост. | Не удалось обнаружить точку доступа. | Переместите аппарат ближе к точке доступа/маршрутизатору и попробуйте повторить операцию с шага 9. | |
Сбой соединения | Сбой подключения. | 1 Попробуйте повторить операцию с шага 9. 2 Если снова отображается это сообщение, восстановите в аппарате заводские настройки и повторите операцию. | |
Настройка с Qt Kits—ArcGIS AppStudio
Этот инструмент расширенной настройки используется для настройки существующей инсталляции Qt Creator для работы с AppStudio. Эта настройка не является обязательной для написания и построения приложений AppStudio и должна использоваться только, если вам требуется любая из следующих функций:
- Другая версия Qt Creator, чем та, которая распространяется с AppStudio.
- QML Scene – утилита для тестирования приложений, которые могут помочь в отладке JavaScript другим способом для AppStudio
- Local Make – применяется для генерирования установочных файлов на вашей машине без подключения к организации ArcGIS
Использование инструмента расширенной конфигурации
Следующие шаги описывают, как использовать расширенный инструмент конфигурации:
- Перед запуском этого инструмента установите желаемую версию Qt Creator.

- В ArcGIS AppStudio нажмите кнопку Edit на боковой панели, чтобы открыть Qt Creator.
- В Qt Creator выберите Инструменты > Внешние > AppStudio > Расширенная настройка, чтобы открыть инструмент расширенной настройки.
- В расширенном инструменте конфигурации щелкните Настроить AppStudio с помощью Qt Kits.
- Установите отметки у всех платформ, на которых будет работать ваше приложение.
Примите во внимание, что список доступных платформ определяется вашей настольной операционной системой. Инструменты для создания приложений iOS и macOS доступны только для macOS. Аналогично, приложения Windows можно создавать только на компьютерах Windows. Инструменты для Android доступны на macOS, Windows и Ubuntu.
- Для каждой платформы укажите путь к исполняемому файлу qmake соответствующей платформы. Местоположение этого файла qmake будет зависеть от пользователя и целевой платформы. В Windows этот путь будет выглядеть так: C:/Qt/5.15.2/5.15.2/android/bin/qmake.exe.
- Когда вы укажете все необходимые файлы qmake, щелкните Продолжить.

 Местоположение этого файла qmake будет зависеть от пользователя и целевой платформы. В Windows этот путь будет выглядеть так: C:/Qt/5.15.2/5.15.2/android/bin/qmake.exe.
Местоположение этого файла qmake будет зависеть от пользователя и целевой платформы. В Windows этот путь будет выглядеть так: C:/Qt/5.15.2/5.15.2/android/bin/qmake.exe.Теперь AppStudio связан с установленной отдельно версией Qt Creator. Чтобы отменить эту связь, выберите Удалить конфигурацию AppStudio из Qt.
Отзыв по этому разделу?
Настройка SQL Azure для пограничных вычислений
- Чтение занимает 7 мин
В этой статье
SQL Azure для пограничных вычислений поддерживает настройку одним из следующих двух способов:
- Переменные среды
- Файл mssql. conf, помещенный в папку /var/opt/mssql
 conf, помещенный в папку /var/opt/mssql
conf, помещенный в папку /var/opt/mssqlПримечание
Задание переменных среды переопределяет параметры, указанные в файле mssql.conf.
Настройка с использованием переменных среды
SQL Azure для пограничных вычислений предоставляет несколько различных переменных среды, которые можно использовать для настройки контейнера SQL Azure для пограничных вычислений. Эти переменные среды являются подмножеством переменных среды, доступных для SQL Server на Linux. Дополнительные сведения о переменных среды SQL Server на Linux см. в разделе Переменные среды.
В SQL Azure для пограничных вычислений были добавлены следующие новые переменные среды.
| Переменная среды | Описание | Значения |
|---|---|---|
| PlanId | Указывает номер SKU SQL Azure для пограничных вычислений, который будет использоваться во время инициализации. Эта переменная среды требуется только при развертывании SQL Azure для пограничных вычислений с помощью Azure IoT Edge. | asde-developer-on-iot-edge или asde-premium-on-iot-edge |
| MSSQL_TELEMETRY_ENABLED | TRUE или FALSE | |
| MSSQL_TELEMETRY_DIR | Задает целевой каталог для файлов аудита сбора данных об использовании и диагностике. | Расположение папки в контейнере SQL для пограничных вычислений. Эту папку можно сопоставить с томом узла с помощью точек подключения или томов данных. |
| MSSQL_PACKAGE | Указывает расположение развертываемого пакета dacpac или bacpac. | Папка, файл или URL-адрес SAS, содержащий пакеты dacpac или bacpac. Дополнительные сведения см. в статье Развертывание пакетов dacpac и bacpac Базы данных SQL в SQL для пограничных вычислений. |
Следующие переменные среды SQL Server на Linux не поддерживаются для SQL Azure для пограничных вычислений. Эта переменная среды будет игнорироваться во время инициализации контейнера, если их определить.
Эта переменная среды будет игнорироваться во время инициализации контейнера, если их определить.
| Переменная среды | Описание |
|---|---|
| MSSQL_ENABLE_HADR | Включите группы доступности. Например, значение 1 включает группу, а 0 отключает. |
Важно!
Переменная среды MSSQL_PID для SQL Azure для пограничных вычислений допускает в качестве допустимых значений только
Установка переменных среды
Укажите переменные среды для SQL для пограничных вычислений при развертывании службы с помощью портала Azure. Их можно добавить либо в разделе Переменные среды в развертывании модуля, либо в составе параметров создания контейнера.
Добавьте значения в Переменные среды.
Добавьте значения в Параметры создания контейнера
Примечание
В режиме отключенного развертывания переменные среды можно указать с помощью параметров -e, --env или --env-file команды docker run.
Настройка с использованием файла mssql.conf
SQL Azure для пограничных вычислений содержит программу настройки mssql-conf, например SQL Server на Linux. Необходимо вручную настроить файл mssql.conf и поместить его на постоянный диск хранилища, сопоставленный с папкой /var/opt/mssql/ в модуле SQL Azure для пограничных вычислений. При развертывании SQL для пограничных вычислений из Azure Marketplace это сопоставление указывается в качестве параметра Mounts (Подключить) в параметре
{
"Mounts": [
{
"Type": "volume",
"Source": "sqlvolume",
"Target": "/var/opt/mssql"
}
]
}
}
Следующие новые параметры mssql. conf были добавлены для SQL Azure для пограничных вычислений.
conf были добавлены для SQL Azure для пограничных вычислений.
Следующие параметры mssql.conf неприменимы к SQL Azure для пограничных вычислений.
| Параметр | Описание |
|---|---|
| Отзывы пользователей | Выберите, нужно ли, чтобы SQL Server отправлял отзыв в корпорацию Майкрософт. |
| Профиль компонента Database Mail | Настройка профиля Database Mail по умолчанию для SQL Server на Linux. |
| Высокая доступность | Включение групп доступности. |
| Координатор распределенных транзакций Майкрософт | Настройка координатора распределенных транзакций Майкрософт на платформе Linux. Дополнительные параметры конфигурации, связанные с распределенными транзакциями, не поддерживаются для SQL Azure для пограничных вычислений. Дополнительные сведения об этих дополнительных параметрах конфигурации см. в статье Настройка координатора распределенных транзакций. |
| Лицензионные соглашения служб ML | Примите лицензионные соглашения для R и Python для пакетов службы «Машинное обучение Azure». Применимо только к SQL Server 2019. |
| outboundnetworkaccess | Включение исходящего сетевого доступа для расширений R, Python и Java Службы машинного обучения. |
Пример файла mssql.conf предназначен для SQL Azure для пограничных вычислений. Дополнительные сведения о формате файла mssql.conf см. в разделе Формат mssql.conf.
[EULA] accepteula = Y [coredump] captureminiandfull = true coredumptype = full [filelocation] defaultbackupdir = /var/opt/mssql/backup/ defaultdatadir = /var/opt/mssql/data/ defaultdumpdir = /var/opt/mssql/data/ defaultlogdir = /var/opt/mssql/log/ [language] lcid = 1033 [memory] memorylimitmb = 6144 [sqlagent] errorlogfile = /var/opt/mssql/log/sqlagentlog.log errorlogginglevel = 7 [traceflag] traceflag0 = 3604 traceflag1 = 3605 traceflag2 = 1204
Запуск SQL Azure для пограничных вычислений от имени пользователя без прав root
По умолчанию контейнеры SQL Azure для пограничных вычислений работают с пользователем или группой без разрешений root. При развертывании с помощью Azure Marketplace (или с помощью docker), если не указан другой пользователь или группа, контейнеры SQL для пограничных вычислений будут запускаться от имени пользователя mssql (без прав root). Чтобы указать другого пользователя, не имеющего прав root, во время развертывания добавьте пару «ключ-значение»
При развертывании с помощью Azure Marketplace (или с помощью docker), если не указан другой пользователь или группа, контейнеры SQL для пограничных вычислений будут запускаться от имени пользователя mssql (без прав root). Чтобы указать другого пользователя, не имеющего прав root, во время развертывания добавьте пару «ключ-значение» *"User": "<name|uid>[:<group|gid>]"* в параметрах создания контейнера. В приведенном ниже примере SQL Azure для пограничных вычислений настроен для запуска от имени пользователя *IoTAdmin*.
{
..
..
..
"User": "IoTAdmin",
"Env": [
"MSSQL_AGENT_ENABLED=TRUE",
"ClientTransportType=AMQP_TCP_Only",
"MSSQL_PID=Premium"
]
}
Чтобы разрешить непривилегированному пользователю доступ к файлам базы данных в подключенных томах, пользователь или группа, от имени которых выполняется контейнер, должны иметь доступ на чтение и запись для постоянного хранилища файлов. В приведенном ниже примере для пользователя, не имеющего прав root, в качестве владельца файлов устанавливается user_id 10001.
В приведенном ниже примере для пользователя, не имеющего прав root, в качестве владельца файлов устанавливается user_id 10001.
chown -R 10001:0 <database file dir>
Обновление с предыдущих версий CTP
Предыдущие выпуски CTP для SQL Azure для пограничных вычислений настроены для запуска от имени пользователей с правами root. При обновлении с предыдущей версии CTP доступны следующие параметры.
- Продолжайте использовать пользователя с правами root. Чтобы использовать этого пользователя дальше, добавьте пару «ключ-значение»
*"User": "0:0"*в параметрах создания контейнера. - Использование пользователя mssql по умолчанию. Для использования пользователя mssql по умолчанию выполните следующие действия.
- Добавьте пользователя с именем mssql на узле docker. В приведенном ниже примере мы добавим пользователя mssql с идентификатором 10001. Этот пользователь также добавляется в группу root.
sudo useradd -M -s /bin/bash -u 10001 -g 0 mssql - Изменение разрешения на том каталога или подключения, где находится файл базы данных
sudo chgrp -R 0 /var/lib/docker/volumes/kafka_sqldata/ sudo chmod -R g=u /var/lib/docker/volumes/kafka_sqldata/
- Добавьте пользователя с именем mssql на узле docker. В приведенном ниже примере мы добавим пользователя mssql с идентификатором 10001. Этот пользователь также добавляется в группу root.
- Использование другой учетной записи пользователя, не имеющей прав root. Для использования другой учетной записи пользователя, без прав root, выполните следующие действия.
- Обновите параметры создания контейнера, чтобы указать пару «ключ-значение»
*"User": "user_name | user_id*в параметрах создания контейнера. Замените user_name или user_id на фактические значения user_name или user_id узла docker. - Измените разрешения для тома каталога или подключения.
- Обновите параметры создания контейнера, чтобы указать пару «ключ-значение»
 Для использования другой учетной записи пользователя, без прав root, выполните следующие действия.
Для использования другой учетной записи пользователя, без прав root, выполните следующие действия.Сохранение данных
Изменения в конфигурации SQL Azure для пограничных вычислений и файлы базы данных сохраняются в контейнере даже в том случае, если он был перезапущен с использованием команд docker stop и docker start. Тем не менее, если удалить контейнер с помощью команды docker rm, будет удалено все его содержимое, включая SQL Azure для пограничных вычислений и ваши базы данных. В следующем разделе описывается, как можно использовать тома данных для сохранения файлов базы данных даже в случае удаления связанных контейнеров.
Важно!
При работе с SQL Azure для пограничных вычислений крайне важно понимать принципы обеспечения сохраняемости данных в Docker. Помимо этого раздела, мы также рекомендуем вам ознакомиться с информацией об управлении данными в контейнерах Docker в документации по Docker.
Подключение каталога узла в качестве тома данных
Первый способ состоит в подключении каталога на вашем узле в качестве тома данных для контейнера. Для этого используйте команду docker run с флагом -v <host directory>:/var/opt/mssql. Такой подход позволяет восстанавливать данные в перерывах между выполнениями контейнера.
docker run -e 'ACCEPT_EULA=Y' -e 'MSSQL_SA_PASSWORD=<YourStrong!Passw0rd>' -p 1433:1433 -v <host directory>/data:/var/opt/mssql/data -v <host directory>/log:/var/opt/mssql/log -v <host directory>/secrets:/var/opt/mssql/secrets -d mcr.microsoft.com/azure-sql-edge
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<YourStrong!Passw0rd>" -p 1433:1433 -v <host directory>/data:/var/opt/mssql/data -v <host directory>/log:/var/opt/mssql/log -v <host directory>/secrets:/var/opt/mssql/secrets -d mcr. microsoft.com/azure-sql-edge
 microsoft.com/azure-sql-edge
microsoft.com/azure-sql-edge
Кроме того, этот способ позволяет предоставлять общий доступ к файлам на узле и просматривать их за пределами Docker.
Важно!
Сопоставление томов узла для Docker в Windows в настоящее время не поддерживает сопоставление полного каталога /var/opt/mssql. Однако можно сопоставить подкаталог, например /var/opt/mssql/data, с хост-компьютером.
Важно!
На данный момент не поддерживается сопоставление томов узла для Docker на Mac с образом SQL Azure для пограничных вычислений. Вместо этого следует использовать контейнеры томов данных. Это ограничение относится только к каталогу /var/opt/mssql. Операции чтения из подключенного каталога осуществляются в нормальном режиме. Например, вы можете подключить каталог узла с помощью команды -v на Mac и восстановить резервную копию из файла с расширением BAK, который находится на узле.
Использование контейнеров томов данных
Второй способ подразумевает использование контейнеров томов данных. Чтобы создать контейнер тома данных, укажите имя тома вместо каталога узла с параметром
Чтобы создать контейнер тома данных, укажите имя тома вместо каталога узла с параметром -v. В следующем примере создается общий том данных с именем sqlvolume.
docker run -e 'ACCEPT_EULA=Y' -e 'MSSQL_SA_PASSWORD=<YourStrong!Passw0rd>' -p 1433:1433 -v sqlvolume:/var/opt/mssql -d mcr.microsoft.com/azure-sql-edge
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<YourStrong!Passw0rd>" -p 1433:1433 -v sqlvolume:/var/opt/mssql -d mcr.microsoft.com/azure-sql-edge
Примечание
Этот способ неявного создания тома данных в рамках команды выполнения не работает в старых версиях Docker. В таком случае следует явно выполнить действия, которые описываются в разделе Создание и подключение контейнера тома данных документации по Docker.
Даже если вы остановите и удалите этот контейнер, том данных будет сохранен. Вы сможете просмотреть его с помощью команды docker volume ls.
docker volume ls
Если затем создать другой контейнер с тем же именем тома, в новом контейнере будут использоваться данные SQL Azure для пограничных вычислений, располагающиеся на этом томе.
Чтобы удалить контейнер тома данных, воспользуйтесь командой docker volume rm.
Предупреждение
Если вы удалите контейнер тома данных, все содержащиеся в нем данные SQL Azure для пограничных вычислений будут удалены без возможности восстановления.
Дальнейшие действия
Настройка IP-АТС на линию сети Телфин на примере программного продукта Asterisk
Мы предлагаем два варианта настройки с возможностью резервирования входящей и исходящей связи и самостоятельной передачи АОНа
1. Вариант — статическое взаимодействие (рекомендуемый)
2. Вариант — динамическое взаимодействие
В обоих вариантах во входящем вызове от серверов Телфин на АТС вызываемый номер будет передаваться в формате E.164, например 78123364242.
Оба варианта подключения подразумевают наличие в личном кабинете Телфин(переход на работу через) только одной(у) линии(ю) вида 000ААААА с подключением(переносом) на неё всех ваших номеров. Для того, чтобы наш сервер начал доверят указываемому вашей АТС АОН-у, необходимо написать соответствующий запрос в нашу тех. поддержку [email protected] с указанием ваших доверенных статисческих IP-адресов и номера линии, на которую нужно поместить все ваши номера.
поддержку [email protected] с указанием ваших доверенных статисческих IP-адресов и номера линии, на которую нужно поместить все ваши номера.
Вариант 1 — статическое взаимодействие (рекомендуемый)
Статическое взаимодействие подразумевает создание статического SIP транка, используя в качестве транспорта сеть Интернет, между:
а) Серверами Телфин — общий адрес sip.telphin.com. В данном домене доступны SIP SRV записи: vip1.sip.telphin.com (213.170.92.166) и vip2.sip.telphin.com (46.229.221.86) для обеспечения резервирования.
SRV в Телфин — справкаДля обеспечения резервирования домену sip. telphin. com присвоена SRV запись:
_sip._udp.sip.telphin.com has SRV record 10 50 5060 vip1.sip.telphin.com. _sip._udp.sip.telphin.com has SRV record 20 50 5060 vip2.sip.telphin.com.
где:
- vip1.sip.telphin.com — адрес основного сервера телефонии
- vip2.sip.telphin.com — адрес резервного сервера телефонии
НО!, в случае с Asterisk, даже при включении параметра «srvlookup», он неправильно обрабатывает приоритеты SRV записей, что приводит к ситуации не правильного использования адресов серверов телефонии.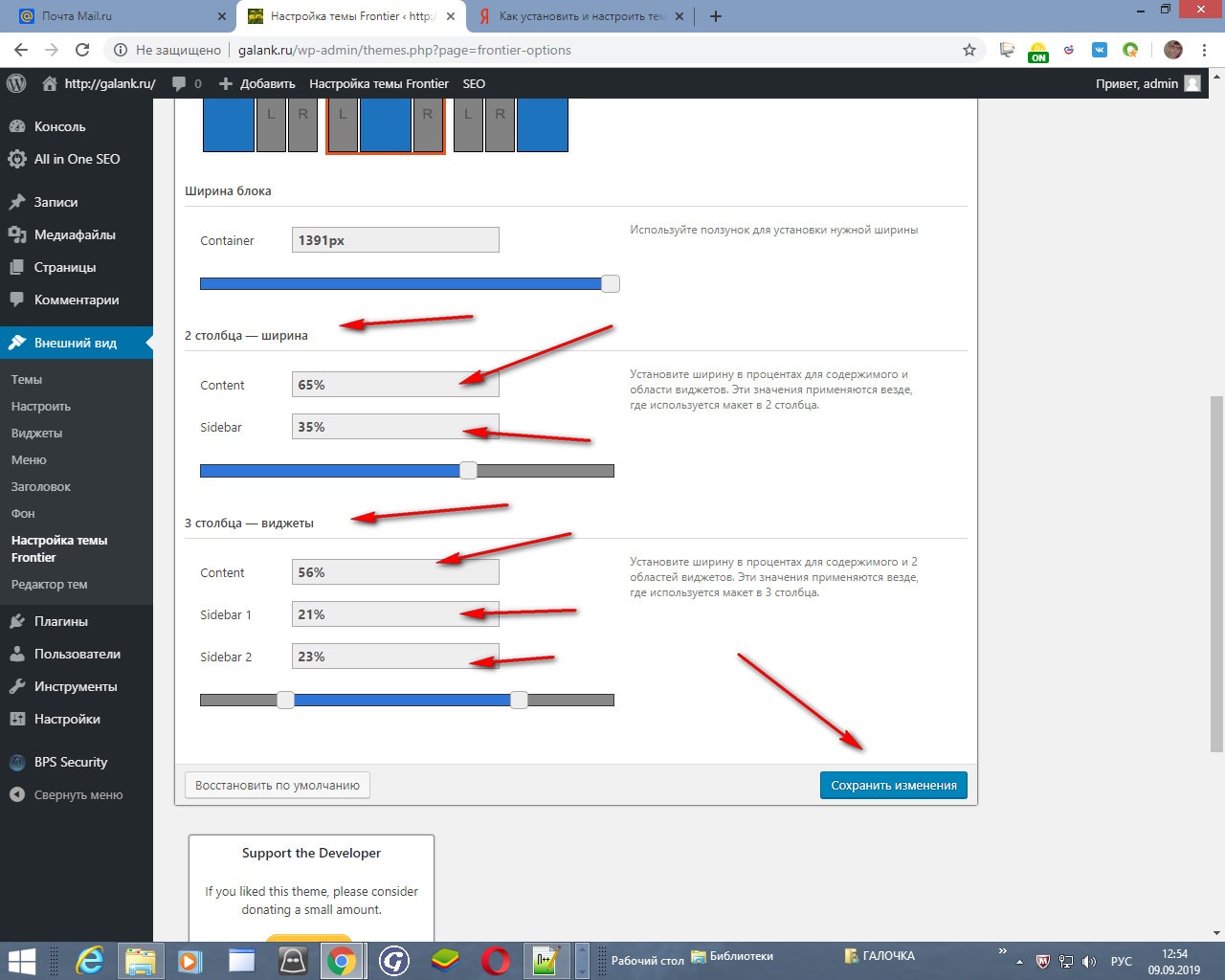 Поэтому, если оборудовании не поддерживает / не корректно поддерживает работу с SRV, необходимо отключить её(SRV) поддержку и, при настройке транков, использовать доменные адреса: vip1.sip.telphin.com и vip2.sip.telphin.com, как это описано ниже.
Поэтому, если оборудовании не поддерживает / не корректно поддерживает работу с SRV, необходимо отключить её(SRV) поддержку и, при настройке транков, использовать доменные адреса: vip1.sip.telphin.com и vip2.sip.telphin.com, как это описано ниже.
б) Клиентской IP-ATC — IP адрес должен быть публичным (внешним), доступным из сети Интернет. Это либо на АТС должен использоваться публичный IP-адрес, либо, если АТС находится в локальный сети / за NAT, внешний IP-адрес вашего маршрутизатора. НО, для корректности работы необходимо настроить проброс портов на маршрутизаторе в сторону АТС.
Варианты настройки конфигурации Asterisk с использованием модулей SIP и PJSIP
Справка к указаному ниже:- А.А.А.А — внешний статический IP-адрес сервера Asterisk, с которого должны уходить и приниматься вызовы Телфин
- TELPHIN_LINE — линия сети Телфин вида 000АААААА
- TELPHIN_PASSWORD — пароль от линии Телфин
- 7ABCXXXXXXX и 7DEFXXXXXXX — выделенные номера, которые привязаны к линии Телфин TELPHIN_LINE
 1″>Настройка с использованием модуля SIP Пример файла sip.conf
1″>Настройка с использованием модуля SIP Пример файла sip.conf[general] ;externip="внешний IP адрес вашего роутера" ;раскомментировать и заполнить актуальными данными, если Asterisk находится за NAT-ом ;localnet="внутренний ip адрес asterisk/маска" ;раскомментировать и заполнить актуальными данными, если Asterisk находится за NAT-ом ;nat=force_rport,comedia ;раскомментировать, если Asterisk находится за NAT-ом alwaysauthreject = yes srvlookup=no dtmfmode=rfc2833 bindport=5090 ;в целях безопасности настоятельно рекомендуется изменить стандартный порт Asterisk-а 5060 на любой другой, например, 5090 directmedia=no disallow=all allow=ulaw:20 ; согласно https://wiki.asterisk.org/wiki/display/AST/RTP+Packetization allow=alaw:20 ; согласно https://wiki.asterisk.org/wiki/display/AST/RTP+Packetization allow=g729:20 ; согласно https://wiki.SIP Пример файла extensions.conf
 asterisk.org/wiki/display/AST/RTP+Packetization
;;транки(основной и резервный) линии с номерами 78120001122 и 74950001133
[telphin_TELPHIN_LINE_a] ;основной транк линии TELPHIN_LINE
context=telphin_in
type=peer
username=TELPHIN_LINE
fromuser=TELPHIN_LINE
secret=пароль от линии
host=vip1.sip.telphin.com
insecure=invite,port
qualify=no
port=5060
[telphin_TELPHIN_LINE_b] ;резервный транк линии TELPHIN_LINE
context=telphin_in
type=peer
username=TELPHIN_LINE
fromuser=TELPHIN_LINE
secret=пароль от линии
host=vip2.sip.telphin.com
insecure=invite,port
qualify=no
port=5060
asterisk.org/wiki/display/AST/RTP+Packetization
;;транки(основной и резервный) линии с номерами 78120001122 и 74950001133
[telphin_TELPHIN_LINE_a] ;основной транк линии TELPHIN_LINE
context=telphin_in
type=peer
username=TELPHIN_LINE
fromuser=TELPHIN_LINE
secret=пароль от линии
host=vip1.sip.telphin.com
insecure=invite,port
qualify=no
port=5060
[telphin_TELPHIN_LINE_b] ;резервный транк линии TELPHIN_LINE
context=telphin_in
type=peer
username=TELPHIN_LINE
fromuser=TELPHIN_LINE
secret=пароль от линии
host=vip2.sip.telphin.com
insecure=invite,port
qualify=no
port=5060[telphin_out] ;исходящая связь через линию TELPHIN_LINE с возможностью использования резервного маршрута до сервера Телфин и подстановкой нужного АОН-а exten=> _X.,1,SIPAddHeader(P-Asserted-Identity: ДлявходящихвызововотТелфин7abcxxxxxxx>
Настройкас использованиеммодуля
ПримерфайлаААААААААААААПримерфайла
исходящаясвязьчерезсвозможностьюиспользованиярезервногомаршрутадосервераТелфиниподстановкойнужногоАОНаДлявходящихвызововотТелфин7abcxxxxxxx>
Даннаясхемаужепротестированаи являетсяабсолютнорабочимвариантом
Дляпереходана статическоевзаимодействиевашей АТСс серверомТелфиннеобходимонаправитьзапросна адреснашейтехподдержкипо форме- Кудана адреснашейтехподдержки
- ОткогоОБЯЗАТЕЛЬНОс контактного эладресауказанногов вашемличномкабинете
- ТелозапросаПрошудлялинииХХХХХХзадатьстатическиймаршрутвходящихвызововс резервированиемвходящейсвязина адресамоейАТСвыберитеодиниз вариантов
- вашейАТСпорт —основнойи вашейАТСпорт —резервныйеслиу вашейАТСтолькоодинвнешнийадрес
- вашейАТСпорт —основнойи вашейАТСпорт —резервныйеслиу вашейАТСнескольковнешнихадресов
Вариант —динамическоевзаимодействие
Динамическоевзаимодействиеподразумеваетсозданиединамическоготранкаиспользуяв качестветранспортасетьИнтернетмежду
аСерверамиТелфин —общийадресВ данномдоменедоступнызаписии дляобеспечениярезервирования
в Телфин —справкаДляобеспечениярезервированиядоменуприсвоеназапись
где
- —адресосновногосерверателефонии
- —адресрезервногосерверателефонии
НОв случаес дажепривключениипараметра«»он неправильнообрабатываетприоритетызаписейчтоприводитк ситуациине правильногоиспользованияадресовсерверовтелефонииПоэтомуеслиоборудованиине поддерживает не корректноподдерживаетработус необходимоотключитьеёподдержку ипринастройкетранковиспользоватьдоменныеадресаи какэтоописанониже
бКлиентской —на АТСнеобходимонастроитьотправкуна сервераТелфинзапросовна регистрациювыданнойвамлиниигдепараметрамиАТСзадаётсянужноезначениезаголовка
- длярегистрациина заголовокдолжениметьзначение
- длярегистрациина заголовокдолжениметьзначение
Вариантынастройкиконфигурациис использованиеммодулейи
Справкак указаномуниже- АААА —внешнийстатическийадрессерверас которогодолжныуходитьи приниматьсявызовыТелфин
- —линиясетиТелфинвидаАААААА
- —парольот линииТелфин
- и —выделенныеномеракоторыепривязанык линииТелфин
Настройкас использованиеммодуля
ПримерфайлавнешнийадресвашегороутерараскомментироватьизаполнитьактуальнымиданнымиеслинаходитсязаомвнутреннийадресмаскараскомментироватьизаполнитьактуальнымиданнымиеслинаходитсязаомраскомментироватьеслинаходитсязаомвцеляхбезопасностинастоятельнорекомендуетсяизменитьстандартныйпортаналюбойдругойнапримерсогласносогласносогласнораскомментироватькомандынижепринеобходимостипрохождениядинамическойрегистрациинасервереТелфинуказавактуальныйномерлиниипарольрегистрациянаосновномвызовычерезкоторыйбудутнаправлятьсявпервуюочередьпарольрегистрациянарезервномвызовычерезкоторыйбудутнаправлятьсявслучаенеответапоосновномумаршрутутранклиниисномерамииосновнойтранклиниипарольотлиниирезервныйтранклиниипарольотлинииПримерфайла
исходящаясвязьчерезлиниюсвозможностьюиспользованиярезервногомаршрутадосервераТелфиниподстановкойнужногоАОНаДлявходящихвызововотТелфин7abcxxxxxxx>
Настройкас использованиеммодуля
ПримерфайлаААААААААААААПримерфайла
исходящаясвязьчерезсвозможностьюиспользованиярезервногомаршрутадосервераТелфиниподстановкойнужногоАОНаДлявходящихвызововотТелфин7abcxxxxxxx>
Обязательнонужнопроверить
- Установлено лив вашемеразрешающееправилодляприемавходящихвызововс серверателефонии
долженразрешатьвесьтраффикдляи и не блокироватьегопо портамуказаннымв настройкахвашеготкобменголосовымтрафикомосуществляетсянапрямуюс терминирующимиузламивышестоящихоператоров
В целяхбезопасностинастоятельнорекомендуетсяиспользоватьголосовыепортыуказанныев ИСКЛЮЧИТЕЛЬНОдляобменаголосовымтрафикомВ этомслучаедлянихможнобезущербабезопасностиразрешитьвесьтрафик
- Включена лив настройкахвашегороутерамаршрутизатораи роутерамаршрутизаторавашегоинтернетпровайдерафункциясборкипропускафрагментированныхпакетовтквходящиезапросына соединениепо номерамнекоторыхпоставщиковмогутпоступатьв фрагментированномвиде
Рекомендации
Используйтепараметрзначениясекундыеслимодульи параметр«»еслииспользуететолькопринахожденииза оми толькодляподдержанияоткрытымсоединенияеслиэтогоне удаетсядостигнутькорректнойработойпробросапортовна роутеремаршрутизаторе
ИспользованиеэтихпараметрадлятестированиядоступностисервераТелфинпакетамиможетпривестик полномурасходованиюограниченногоколичествадоступныхсообщенийс одногоадресаи какследствиеко временнойблокировкевашегоадресаза флуд
На случайнедоступностимаршрутаот Астерискадо серверав этомруководствеописанокакнастроитьработус серверомиспользуярезервированиекаквходящейтаки исходящейсвязи
- Входящиезвонкибудутприходитьв контекстАстерискана экстеншнравный номерачерезкоторыйпоступилвходящийвызов
- В случаеблокировоксо стороныроутерапровайдераможноиспользоватьпортдляработыс адресамии
В этомслучаене забудьтеуказатьегов томчислеи в файлев описаниивходящихканалови в параметре«»еслииспользуйтеилив файлезаписии в параметре«»еслииспользуетемодуль
Защитаот взломови мошенничества
Обращайтевниманиена настройкибезопасностивашейАТС
СистемафродмониторингаТелфинработаетнадвыявлениемслучаеввзломаи производитблокировкуиспользуемыхмошенникамиаккаунтовабонентоводнакодляповышениязащитыот злоумышленниковмы настоятельнорекомендуемВамв томчислеи САМОСТОЯТЕЛЬНОснижатьрискиобращаявниманиена настройкибезопасностивашейАТС
Прииспользованиибесплатногопрограммногопродуктаответственностьпо поискуи устранениюлюбыхошибокв работеи защитеалежитна егоадминистратореткданныевопросыотносятсяисключительнок настройкеаа не к настройкамна серверетелефонии
Есливы сразупонимаетечтосовершатьвызовына МНнаправлениявы не будететоДлялюбогоклиентасетиТелфинсуществуетвозможностьзапретитьвсевызовыза пределы РФчтолишаетзлоумышленникавозможностисовершатьвызовычерезвашаккаунтна МНнаправлениедажев томслучаекогдаон смогполучитьвашиконфиденциальныеданныеДляэтогонеобходимонаписатьсоответствующийзапросна адрес с вашегоконтактного эладресауказанногов данныхличногокабинета
Еслиза безопасноеиспользованиевиртуальнойАТС«ТелфинОфис»отвечаютнашитехническиеспециалистыто позаботитьсяо защищенномиспользованиителефоннойстанциидругихрешенийвампридетсясамостоятельноПоэтомурекомендуемознакомитьсяс тем
Какобезопаситьтелефоннуюсетькотораяработаетна базебесплатногорешенияот взломаи несанкционированногоиспользованияМинимальныйсписокдействийпо предотвращениювзломарекомендацииприведенына примерепрограммнойАТСкаксамойраспространенной
- Обязательноизменитеномерпортана которомпроисходитвзаимодействиес оборудованиемТелфини вашимивнутреннимителефонамиОборудованиеТелфинподдерживаетлюбойномерпортасо стороныабонентаТакжеизменитепортыи
- Настройкапортапроизводитсяв файлев секциинапримердлятогочтобынастроитьпортнеобходимоуказать
- Новыйпортне долженконфликтоватьс ужеоткрытымив системепортамиИзменитьегоможнов файлеУкажитеновыйномерпортав настройкеи раскомментируйтестрокупутемудалениязнакарешеткаЗатемперезапитекомандой
- Настройкапортапроизводитсяв файлеИзменитепортна любойсвободныйи перезапуститекомандой
- Настройтевашна пропусксигнальноготрафикатолькодляобменас адресомоборудованияТелфинпристандартномподключенииэтоадрес
Длятогочтобыпосленастроекане возниклопроблемс прохождениемголосовоготрафикаввидутогочтона вашуАТСприработечерезсерверон поступаетнапрямуюс терминирующихузловспискакоторогонетввидутогочтоонимогутменятьсянеобходимов еразрешитьвесьтрафикпо всемголосовымпортамиспользуемымсерверомАТСдляобменаголосовымтрафикомПриэтомважнопомнитьчтоэтипортыдолжныбытьдоступныисключительнодляобменаголосовымтрафикомПоэтомурекомендуемзаранееопределитьсячтоэтобудутза портыпо умолчаниюв еэтопортытыстыси отрытьтолько их - Запретитеправиламиаподключениек вашемусерверуАТСлюбымспособомпо рабочимпортамслужащимдляуправленияданнымсерверомс произвольныхадресовсетиинтернетРазрешитепо нимдоступтолькос авторизованныхвамиадресов
- ЗапретитеправиламиаподключениеспроизвольныхадресовсетиинтернетквашейлокальнойсетивкоторойнаходятсятелефоныработающиекаксвашейАТСтакинапрямуюссерверомТелфинРазрешитекнейдоступтолькосавторизованныхвамиадресов
- Ограничьтеправиламивашегосписокадресови сетейс которыхподключаютсявашителефоныи адаптерыДляданнойнастройкив используйтепараметрыНапример
где
и —адресасерверарегистрации
—примердиапазона адресоввашейлокальнойсетииз которойбудетпроисходитьподключениетелефонов
- Создайтепользователяс правамидоступатолькопо Напримерсоздайтепользователянастоятельнорекомендуемпридуматьсвойуникальныйлогини задатьемусвойуникальныйпарольПарольдолженсодержатьспецсимволыцифрыи буквыв разномрегистре
Отредактируйтедобавиввнегоследующуюстрочку- Запретитепользователюподключатьсяк серверупо
- Изменитевсестандартныепаролидоступак вашимресурсам
В частностиэтопароли- доступав настройкиустройствкакна их вебинтерфейстаки черезкоманднуюстроку
- абонентовв АТС
- администраторови менеджеровАТС
Использованиесильныхпаролей —этошагвозможнонаиболееважныйв организациизащитылюбойсетиЕсли бывы виделина сколькосложныи интеллектуальнысредстваподборапаролейвы быпонялина скольколегкообходяттривиальноезапутываниесовременныепроцессорыПоэтому
- не создавайтепаролейкоторыесостоятиз двухслов
- не добавляйтек словуиз словаряцифру
- используйтесимволычислаи буквыверхнегои нижнегорегистра
- длинупароляделайтене менее символов
- Ограничьтеколичествоодновременныхисходящихвызововпоступающихс вашихвнутреннихтелефоновВ настройкахза этоотвечаетстрокапрописаннаяв настройкахвашихвнутреннихабонентовТакВы ограничитедействиямошенниковкоторыеужеподобралиправильноеимяпользователяи парольСледитеза темчтобылегитимныепользователихранилисвоипаролив тайнеа не записывалипарольпрямона корпусетелефонаБываети такое
- БлокируйтепортинтерфейсауправленияАстериском
В файлеконфигурациииспользуйтестроки«»и «»чтобысузитьвходящиесоединенияс интерфейсомуправлениятолькодлядоверительныххостовКаки на этапе«Сильныйпароль»создавайтесложныепаролидлинойне менее символов - Отключитеответо неверномпаролесо стороныПо умолчаниювыдаетоднуошибкуо неверномпароледлясуществующегоаккаунтаи другуюдлянесуществующегоаккаунтаСуществуетмножествопрограммдляподборапаролейпоэтомузлоумышленникуне составиттрудапроверитьвсекороткиеномераи собиратьпаролилишьк существующимаккаунтамкоторыеответили«неверныйпароль»Чтобыпомешатьэтомупоменяйтестрочкув файле на и перезапуститеПослетакойнастройкибудетотвечатьодинаководлялюбыхневерныхавторизации« »и не сообщатьподробностей
- Ограничьтесписокдоступныхдлянаборателефонныхкодовстрани направленийкоторыеиспользуютсявашимисотрудниками
- Не рекомендуетсяиспользоватьдефолтныемаршрутытипа
- Рекомендуетсяуказыватьмаршрутыпо точнымс кодамгородовоператоровмобильнойсвязии МНкодовеслионивообщенужнынапримерХХХХи тд
На обычныхлинияхсетиТелфинестьвозможностьавторизовыватьвызовыпо адресус которогоониприходятвслучаеналичияу АТСстатическоговнешнегоадресаи полю«»соответствующемуномерулинииклиентаЭтодаетвозможностьвообщене указыватьпарольустройствав настройкахАТСитогдаегоневозможнобудетвыкрастьТакжеможнопопроситьтехподдержкуТефлинсменитьтекущийпарольлиниидляработыоборудованияи не сообщатьвамновыйТоименноТелфинбудетнестиответственностьза сохранностьтекущегопаролявашихлиний —до техпорпокавы не попроситесообщитьвамсновапарольвашейлинииДляэтогонеобходимонаписатьсоответствующийзапросна адресс вашегоконтактногоэладресауказанногов данныхличногокабинета
В виртуальнойАТСТелфинОфисестьвозможностьжесткоопределитьадресас которыхразрешенарегистрацияна добавочныхНастройкавыполняетсяиндивидуальнодлякаждогодобавочногоДаннаянастройкабудетполезнав томчислеи принастройкедругихАТСна добавочные«ТелфинОфиса»В случаенеобходимостивыполненияданнойнастройкинеобходимонаписатьсоответствующийзапросна адресс вашегоконтактногоэладресауказанногов данныхличногокабинета
ОБРАЩАЕМВАШЕВНИМАНИЕчтоописанноевышене являетсяпанацеейиилиполнымописаниемвсехвозможныхмербезопасностипо защитевашейАТСНо их соблюдениеточносведетк минимумувозможностьпозвонитьчерезвашаккаунту операторателефониии темсамымсохранитьвашиденьги
Есливы желаетеполучитьещебольшуюзащитувы можетевоспользоватьсянашимрешениемТелфин
Есливы нашлиошибкув даннойстатьенапишитепожалуйстанамо нейна адреснашейтехническойподдержки
%d0%bd%d0%b0%d1%81%d1%82%d1%80%d0%be%d0%b9%d0%ba%d0%b0 — со всех языков на все языки
Все языкиАбхазскийАдыгейскийАфрикаансАйнский языкАканАлтайскийАрагонскийАрабскийАстурийскийАймараАзербайджанскийБашкирскийБагобоБелорусскийБолгарскийТибетскийБурятскийКаталанскийЧеченскийШорскийЧерокиШайенскогоКриЧешскийКрымскотатарскийЦерковнославянский (Старославянский)ЧувашскийВаллийскийДатскийНемецкийДолганскийГреческийАнглийскийЭсперантоИспанскийЭстонскийБаскскийЭвенкийскийПерсидскийФинскийФарерскийФранцузскийИрландскийГэльскийГуараниКлингонскийЭльзасскийИвритХиндиХорватскийВерхнелужицкийГаитянскийВенгерскийАрмянскийИндонезийскийИнупиакИнгушскийИсландскийИтальянскийЯпонскийГрузинскийКарачаевскийЧеркесскийКазахскийКхмерскийКорейскийКумыкскийКурдскийКомиКиргизскийЛатинскийЛюксембургскийСефардскийЛингалаЛитовскийЛатышскийМаньчжурскийМикенскийМокшанскийМаориМарийскийМакедонскийКомиМонгольскийМалайскийМайяЭрзянскийНидерландскийНорвежскийНауатльОрокскийНогайскийОсетинскийОсманскийПенджабскийПалиПольскийПапьяментоДревнерусский языкПортугальскийКечуаКвеньяРумынский, МолдавскийАрумынскийРусскийСанскритСеверносаамскийЯкутскийСловацкийСловенскийАлбанскийСербскийШведскийСуахилиШумерскийСилезскийТофаларскийТаджикскийТайскийТуркменскийТагальскийТурецкийТатарскийТувинскийТвиУдмурдскийУйгурскийУкраинскийУрдуУрумскийУзбекскийВьетнамскийВепсскийВарайскийЮпийскийИдишЙорубаКитайский
Все языкиАбхазскийАдыгейскийАфрикаансАйнский языкАлтайскийАрабскийАварскийАймараАзербайджанскийБашкирскийБелорусскийБолгарскийКаталанскийЧеченскийЧаморроШорскийЧерокиЧешскийКрымскотатарскийЦерковнославянский (Старославянский)ЧувашскийДатскийНемецкийГреческийАнглийскийЭсперантоИспанскийЭстонскийБаскскийЭвенкийскийПерсидскийФинскийФарерскийФранцузскийИрландскийГалисийскийКлингонскийЭльзасскийИвритХиндиХорватскийГаитянскийВенгерскийАрмянскийИндонезийскийИнгушскийИсландскийИтальянскийИжорскийЯпонскийЛожбанГрузинскийКарачаевскийКазахскийКхмерскийКорейскийКумыкскийКурдскийЛатинскийЛингалаЛитовскийЛатышскийМокшанскийМаориМарийскийМакедонскийМонгольскийМалайскийМальтийскийМайяЭрзянскийНидерландскийНорвежскийОсетинскийПенджабскийПалиПольскийПапьяментоДревнерусский языкПуштуПортугальскийКечуаКвеньяРумынский, МолдавскийРусскийЯкутскийСловацкийСловенскийАлбанскийСербскийШведскийСуахилиТамильскийТаджикскийТайскийТуркменскийТагальскийТурецкийТатарскийУдмурдскийУйгурскийУкраинскийУрдуУрумскийУзбекскийВодскийВьетнамскийВепсскийИдишЙорубаКитайский
Динамический ремаркетинг в AdWords – настройка с помощью Google Tag Manager
Представьте ситуацию: вы, бородатый айтишник, забыв сменить аккаунт Google, искали дома определенный товар, ходили по сайтам, читали описания, приценивались. Пришли на работу, открыли YouTube, чтобы показать коллегам прикольный ролик, а там баннер со стрингами в блестках (ну или что вы там искали). С одной стороны, неудобно получилось, а с другой, скидка 30% — надо брать. Примерно так работает динамический ремаркетинг в Google AdWords. Его основное отличие от обычного ремаркетинга в том, что человек, посетивший онлайн-магазин, на других сайтах видит не общую рекламу этого магазина, а объявления с конкретными товарами, которые он просматривал.
В этой статье вы узнаете:
Кроме индивидуальных предложений, к преимуществам динамического ремаркетинга относятся автоматическое обновление рекламы и широкие возможности для сегментации аудитории. Например, можно создать список пользователей, которые положили товар в корзину, но не оплатили, или тех, кто интересовался покупками дороже $100 и т.д.
Вот несколько сценариев, в которых можно «дожать» клиентов с помощью динамического ремаркетинга:
- Человек зашел на сайт и прочитал описание и характеристики определенного товара или услуги.
- Посетитель сайта положил товар в корзину или оформил заказ, но не оплатил покупку.
- Человек искал товары, которые вы продаете, в поисковике.
- Клиент что-то купил на вашем сайте — ему можно предложить вдогонку аксессуары к обновке или сопутствующие товары.
- Клиент купил товар, которому через время понадобится обновление или дополнительный сервис. Например, чистка бойлеров.
Как выглядят динамические баннеры Google AdWords
Google AdWords предлагает объявление адаптивного формата. Это шаблон, в который вы добавляете картинку, название своей компании, сайт, заголовок и текст. В результате получается объявление шести разных типов. Система, подстраиваясь под каждый сайт или устройство, показывает баннер подходящего размера:
Изменить формат адаптивного объявления в Google AdWords нельзя.
Когда нужен динамический ремаркетинг
Ответить на вопрос, нужен ли вам динамический ремаркетинг, поможет отчет «Длина последовательности» (Path Length) в Google Analytics. Найти его можно в меню «Конверсии» → «Многоканальные».
Посмотрите на количество конверсий, которые совершаются пользователями при первом посещении. Если эта цифра меньше 30%, ваш сайт критически нуждается в динамическом ремаркетинге, меньше 50% — настоятельно рекомендуем использовать, меньше 65% — все равно попробуйте, продажи лишними не будут. Если у вас 95-100% конверсий совершается с первого визита, ущипните себя за руку. Это не сон? Тогда проверьте настройки отслеживания в GA, потому что так не бывает.
В любом случае правильно настроенный динамический ремаркетинг имеет самую высокую конверсию среди всех видов рекламы в контекстно-медийной сети. Например, компания Netshoes с помощью динамического ремаркетинга увеличила на 30% доход и на 20% ROI.
Как настроить динамический ремаркетинг в Google AdWords
Перед настройкой динамического ремаркетинга убедитесь, что у вас в Google Analytics включены ремаркетинг и функции отчетов по рекламе. Также нужно связать аккаунты GA и AdWords. После этого можно приступать к настройке. Она состоит из 4 основных этапов:
- Создание фида и его загрузка в Google AdWords.
- Установка на сайт кода динамического ремаркетинга.
- Настройка аудиторий ремаркетинга.
- Создание объявлений и запуск кампаний.
Ритейлеры при настройке динамического ремаркетинга могут использовать Google Merchant Center. Эта платформа позволяет загружать данные о товарах в AdWords и другие сервисы Google. Технически оба варианта настройки (через Merchant Center и без него) очень похожи. Разница заключается лишь в ключе, который отправляется в коде, и в том, куда загружать фид — напрямую в AdWords или в Merchant Center. При этом использование Merchant Center дает свои преимущества:
- В объявлении на одну строку больше.
- Скорость одобрения товаров значительно выше.
- Специальные шаблоны для каждого бизнеса: Образование, Авиабилеты, Отели и аренда жилья, Трудоустройство, Местные предложения, Недвижимость, Розничная торговля, Туризм.
- Возможность показывать поисковую товарную рекламу.
Если ваша страна пока не входит в список стран, в которых работает Merchant Center, не расстраивайтесь — сейчас мы расскажем, как настроить динамический ремаркетинг без него.
Шаг 1. Создайте фид данных с необходимыми атрибутами
Фид — это табличный файл формата CSV, TSV, XLS или XLSX с данными о ваших товарах и услугах. Из него Google AdWords будет подтягивать в объявления актуальную информацию о товарах, которыми интересовались посетители вашего сайта.
Фид должен содержать обязательные атрибуты: ID товара, URL страницы товара и URL фотографии товара. Также в таблицу можно добавить другие параметры: название, категорию, цену товара, цену со скидкой и т.д. Обратите внимание, в фиде можно использовать не только 7 стандартных атрибутов, но и 12 дополнительных в том числе похожие идентификаторы для кросс-сейла. Подробнее о том, как создать фид, вы можете почитать в справке AdWords. Ваша таблица с данными должна выглядеть примерно так:
Допустим, у вашего магазина широкий ассортимент, и в нем есть товары повседневного спроса. Если вы четко знаете, когда покупателю снова понадобится конкретный товар, мы рекомендуем создать несколько фидов данных, разделив товары по параметру скорость потребления. Это позволит настроить динамический ремаркетинг на покупателей этого списка товаров в необходимый промежуток времени (но не более 540 дней).
Когда файл готов, остается загрузить его в Google AdWords. Для этого заходим в меню «Настройка» → «Коммерческие данные» → «Фиды данных» и нажимаем на плюсик, чтобы добавить фид. В выпадающем списке выбираем «Фид динамических медийных объявлений» и вид деятельности вашей компании:
Затем нужно придумать название для фида и загрузить его с вашего компьютера. После этого появится оповещение, сколько товаров добавлено или обновлено. Если в файле есть ошибки, система также напишет об этом — отчет по ошибкам можно скачать.
К основным ошибкам при работе с фидом данных в Google AdWords относятся:
- Недопустимый URL.
- Недействительны или отсутствуют атрибуты фида.
- Повторяющийся ключ элемента фида.
Так выглядят в интерфейсе ошибки при загрузке фида данных:
Если ошибок немного, вы можете исправить их в интерфейсе вручную. В противном случае нужно перезагрузить фид с верными данными.
После загрузки фида система должна его рассмотреть. Пока элементы фида не будут одобрены, показов по ним не будет. Согласно справке AdWords, этот процесс занимает до 3 рабочих дней. Если вы ожидаете одобрения больше 7 дней, советуем позвонить на горячую линию Google AdWords.
Шаг 2. Установите на сайт код динамического ремаркетинга
Чтобы узнать, какие товары просматривал пользователь, их цену и тип страниц, нужно добавить тег динамического ремаркетинга на каждую страницу сайта, которую вы хотите отслеживать. Сделать это можно 4 способами:
- С помощью стандартного тега AdWords — подробно описано в cправке Google AdWords.
- С помощью стандартного тега AdWords и Google Tag Manager — этот способ мы рассмотрим в статье.
- С помощью тега Google Analytics и «Пользовательских параметров». Детали можно узнать в справке Google Analytics.
- С помощью тега Google Analytics и Google Tag Manager. Инструкции вы найдете в справке Google Tag Manager.
Если у вас в GA уже есть необходимые параметры: ID товара, его цена и количество, ID похожих товаров, а на этапе «Корзина» и «Оформление заказа» есть все идентификаторы товаров и общая сумма, то быстрее будет внедрить их с помощью способа 3. Однако для использования поискового ремаркетинга он не подходит. В этой статье мы рассмотрим подробнее второй способ настройки — через Google AdWords и Google Tag Manager. Это самый универсальный способ, который позволяет использовать аудитории не только в контекстно-медийной сети, но и для поискового ремаркетинга.
Сначала нужно внести изменения и добавить необходимые параметры в тег AdWords. Для этого заходим в меню «Общая библиотека» → «Менеджер аудиторий» → «Источники аудиторий» и выбираем «Тег AdWords»:
Заходим в настройки тега, нажимаем «Собирать специальные атрибуты или параметры для персонализации рекламы», выбираем свой вид деятельности, ставим галочки напротив нужных параметров и сохраняем тег. В результате в вашем теге появятся 4 дополнительные переменные: тип страницы, ID товара, цена и дополнительный параметр. Для некоторых видов деятельности, зависящих от дат, например для авиабилетов, добавляется еще 2 переменные: дата начала и дата конца рейса.
Теперь нужно установить обновленный тег AdWords на сайт. Это можно сделать вручную либо с помощью Google Tag Manager. Если вы используете DataLayer в GTM, у вас уже есть необходимые данные, осталось найти их и создать тег. Если есть не все данные, допустим, не хватает типа страницы, можно создать несколько тегов, вручную прописать тип страницы и настроить правило активации. Мы подробно описали, как настроить динамический ремаркетинг с помощью GTM, в отдельном файле. Оставьте свой e-mail — и мы пришлем вам ссылку на этот гайд.
Шаг 3. Создайте аудитории для динамического ремаркетинга
Перед тем, как запускать рекламную кампанию, нужно создать списки ремаркетинга — определить аудиторию, которой вы будете показывать динамические баннеры. Сделать это можно в меню «Общая библиотека» → «Менеджер аудиторий» → «Списки аудиторий».
AdWords по умолчанию создает стандартный список из всех пользователей, которые посещали страницы с тегами ремаркетинга:
Вы можете добавить собственные списки, нажав на плюс. Расширить возможности динамических баннеров можно, сегментируя аудиторию по параметрам. Например, параметр стоимость просмотренных товаров позволит выделить тех, кто интересовался дорогими товарами. В свою очередь из этих людей можно выбрать только тех, кто бросил корзину за последние 14 дней. Можно настроить практически любую аудиторию:
Высший пилотаж в создании аудиторий — это использовать дополнительно OWOX BI и Google BigQuery. Благодаря этим инструментам вы легко сможете разделить покупателей на когорты и для каждой настроить отдельную кампанию, установить ставки и частоту показов. А после запуска — оценить реальный вклад канала с помощью OWOX BI Attribution и оптимизировать расходы.
Шаг 4. Запустить динамический ремаркетинг в Google AdWords
Сначала создайте кампанию. Для этого в меню «Кампании» нажмите на плюсик, затем «Новая кампания» и выберите пункт «Контекстно-медийная сеть». Выберите тип «Стандартная медийная кампания» и нажмите «Продолжить»:
Настройте необходимые параметры кампании. В пункте «Динамические объявления» выберите фид данных:
Затем выберите из списка аудиторию для показа объявлений — стандартную или созданную вами:
После этого создайте группу объявлений и объявление. Доступно 4 формата объявления: самые популярные, графические, текстовые и нативные объявления. Все они адаптивные и содержат одно или несколько объявлений с общим текстом и изображением:
Поздравляем, настройки завершены!
Что делать, если вы все настроили, но динамический ремаркетинг не работает
Проверьте сбор данных в тегах, меню «Менеджер аудиторий» → «Источники аудиторий». Возможно, они перестали собираться или не уходит самый важный параметр — идентификатор товара.
Ошибка в теге AdWords:
Ошибка в теге Google Analytics:
Проверьте, одобрены ли товары в фиде:
Проверьте, включена ли кампания и группа:
Если это не помогло, позвоните в поддержку AdWords.
Ну вот, теперь вы знаете, как настроить динамический ремаркетинг, и отложить это дело на потом уже не получится. А если что-то непонятно, напишите свой вопрос в комментарии — охотно поможем.
Использованные инструменты
Настройка с нуля принтсервера CUPS с доменной авторизацией и без нее в сети с разными ОС
Настройка с нуля принтсервера CUPS с доменной авторизацией и без нее в сети с разными ОС
Вступление
Итак. Предположительно, сервис печати CUPS — это мощное решение, позволяющее организовать централизованное управление принтерами в компании. Так оно и есть, но в процессе настройки потребуется провести некоторое время в поисках решения в Google множества мелких неочевидных проблем, особенно, если ваша необходимость выходит за рамки стандартных мануалов по настройке.
В статье будет описана установка принтсервера CUPS на Ubuntu Server в сети с работающим доменом Active Directory, хотя его наличие совершенно не обязательно и инструкции по настройке взаимодействию с ним можно будет смело пропустить, его настройка, а также настройка клиентских машин Linux и Windows для взаимодействия с данным принт-сервером.
В инструкции домен будет именоваться example.com, сам принтсервер — cupsserver (cupsserver.example.com) с IP адресом 10.10.100.50, а клиентские машины linux1, linux2, linux3 и т.д для клиентских машин Linux и windows1, windows2, windows3 и т.д. для клиентских машин Windows соответственно.
Настройка принтсервера
В первую очередь мы настроим принтсервер, а точнее, настроим административный доступ на него, затем настроим печать на него, а затем опишем настройку клиентских машин.
Заходим на принтсервер любым удобным способом и обновим на нем пакеты:
root@cupsserver:~# apt update && apt upgrade -y Далее проверим, установлен ли CUPS на сервере:
root@cupsserver:~# which cupsd Если вывод выглядит как то так:
/usr/bin/cupsd то CUPS установлен, если вывода нет — устанавливаем CUPS:
root@cupsserver:~# apt install cups -y Теперь настроим административный доступ к веб-интерфейсу CUPS. Все файлы конфигурации находятся по пути /etc/cups/. Для начала, на всякий случай сделаем резервные копии основных файлов конфигурации CUPS:
root@cupsserver:~# cp /etc/cups/cupsd.conf /etc/cups/cupsd.conf.original
root@cupsserver:~# cp /etc/cups/cups-files.conf /etc/cups/cups-files.conf.original
root@cupsserver:~# cp /etc/cups/cups-browsed.conf /etc/cups/cups-browsed.conf.originalВпрочем, если вы этого не сделали — не беда, образцы данных файлов по умолчанию лежат по пути /usr/share/cups. Также нужно упомянуть, что вы можете проверить любые добавленные опции в файлы конфигурации CUPS с помощью команды:
root@cupsserver:~# cupsd -t Если вы что-то напутали, опечатались или использовали опцию, которая уже не поддерживается CUPS’ом, то вывод команды отразит данные ошибки.
Но приступим наконец к настройке. После любых изменений файлов в папке /etc/cups/ для получения эффекта необходимо перезапускать сервис CUPS:
root@cupsserver:~# service cups restart
или
root@cupsserver:~# systemctl restart cups
или
root@cupsserver:~# /etc/init.d/cups restartА если вы отредактировали файл /etc/cups/cups-browsed.conf, то за него отвечает отдельный сервис cups-browsed, который тоже нужно перезапустить:
root@cupsserver:~# service cups-browsed restart
или
root@cupsserver:~# systemctl restart cups-browsed
или
root@cupsserver:~# /etc/init.d/cups-browsed restartВыполним команду
root@cupsserver:~# nano /etc/cups/cupsd.conf Первой незакомментированной опцией является
LogLevel warn Она определяет минимальную информативность логов CUPS. Лог-файлы CUPS находятся по пути /var/log/cups/. На время установки, настройки и отладки принтсервера будет разумным перевести логгирование в debug-режим. Для этого изменим warn на debug2:
LogLevel debug2 По умолчанию CUPS слушает входящие подключения только от localhost, то бишь на loopback интерфейсе. Чтобы убедится в этом, можете выполнить команду
root@cupsserver:~# netstat -plutn Одна из строк будет выглядеть приблизительно так:
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 737/cupsd Дальнейшие действия зависят от степени вашей паранойи. Вы можете добавить в блоке, который условно начинается с комментария #Only listen for connections from the local machine несколько строк с указанием IP адресов или подсетей, откуда CUPS’у будет позволено слушать подключения.
# Only listen for connections from the local machine.
Listen localhost:631
Listen /run/cups/cups.sock
#Слушать подключения с определенного IP адреса
Listen 10.10.100.67:631
#Слушать подключения с подсети бухгалтерии
Listen 172.16.0.0:631Либо же вы можете разрешить CUPS’у слушать подключения со всех адресов
# Only listen for connections from the local machine.
Listen /run/cups/cups.sock
Port 631Следующий момент настройки — это обнаружение сетевых и расшаренных принтеров.
# Show shared printers on the local network.
Browsing Off
BrowseLocalProtocols dnssdНа мой взгляд эта опция так и должна остаться выключенной, так как она определяет, будет ли рассылаться широковещательная информация по сети о подключенных к принтсерверу принтерах. А они ведь будут подключены к ней все. И соответственно у всех клиентских машин будут отображаться сразу все принтера. Наш принтсервер должен искать и обнаруживать все принтера в сети, но не рассылать их бездумно по всей сети.
Далее идут настройки аутентификации:
# Default authentication type, when authentication is required...
DefaultAuthType BasicОпределяет права доступа к веб-интерфейсу CUPS, а также к его административной части. Чтобы пользователь user имел право на администрирование CUPS, его нужно добавить в системную группу lpadmin:
root@cupsserver:~# usermod -a -G lpadmin userВообще, группы, которым позволен административный доступ к CUPS, определяются в файле конфигурации cups-files.conf в блоке
# Administrator user group, used to match @SYSTEM in cupsd.conf policy rules...
# This cannot contain the Group value for security reasons...
SystemGroup lpadminЕсли вы хотите добавить некой группе пользователей Linux права на администрирование принтсервера, например printadmins, то просто добавьте их через пробел к lpadmin. Если группа доменная, то это немного сложнее и будет описано позже.
Теперь перейдем к блоку <Location />:
# Restrict access to the server...
<Location />
Order allow,deny
</Location>Order allow,deny означает, что запрещены подключения отовсюду, если специально не указано разрешение. То есть нужно добавлять IP-адреса, подсети, хосты или хосты по маске (.example.com) в виде «Allow from [разрешенный адрес]*»:
# Restrict access to the server...
<Location />
Order allow,deny
Allow from cupsserver # разрешение подключатся к самому себе по имени хоста
Allow from cupsserver.example.com # разрешение подключатся к самому себе по FQDN
Allow from localhost # разрешение подключатся к самому себе через loopback интерфейс
Allow from 10.10.100.* # Если хотите разрешить
Allow from linux4.example.com # доступ на печать с
Allow from 172.168.5.125 # определенных подсетей, IP или хостов
</Location>Для полной уверености и отладки, можно оставить, пока не настроите все остальное, такую констукцию, которая позволит печать отовсюду:
# Restrict access to the server...
<Location />
Order allow,deny
Allow from all
</Location>Приступим к настройке административного доступа к CUPS на принтсервере. Определитесь, с какого/каких IP и/или подсетей вы собираетесь подключаться к CUPS, и добавить их по аналогии с блоком <Location />:
# Restrict access to the admin pages...
<Location /admin>
Order allow,deny
Allow from localhost
Allow from 10.10.100.*
Allow from admin.example.com
</Location>
# Restrict access to configuration files...
<Location /admin/conf>
Order allow,deny
Allow from localhost
Allow from 10.10.100.*
Allow from admin.example.com
</Location>
# Restrict access to log files...
<Location /admin/log>
Order allow,deny
Allow from localhost
Allow from 10.10.100.*
Allow from admin.example.com
</Location>Еще, по желанию, можно добавить язык интерфейса по умолчанию. Список доступных языков можно посмотреть с помощью команды:
root@cupsserver:~# ls /usr/share/cups/localeЕсли нужная вам локализация, например ru, есть, то добавьте строчку в /etc/cups/cupsd.conf:
DefaultLanguage ruЧтобы к вашему принтсерверу cupsserver.example.com можно было обращатся по его хосту (hostname), необходимо создать в папке /etc/cups/ файл client.conf с таким содержимым:
ServerName имя_хостаСамым простым способом это можно сделать так:
root@cupsserver:/etc/cups# echo "ServerName $(cat /etc/hostname)" > /etc/cups/client.confПоскольку мы предполагаем, что в сети есть DNS сервер, то будет предпочтительным, чтобы можно было обращатся к принтсерверу по его доменному имени (cupsserver.example.com). Также серверу может быть присвоен CNAME псевдоним на DNS сервере, например print или cups. Чтобы принтсервер принимал подключения по таким обращениям, необходимо добавить такую строчку в файл /etc/cups/cupsd.conf:
ServerAlias cupsserver.example.com print cupsЕсли вы хотите, чтобы принтсервер примимал любые обращения, или не хотите заморачиваться, то можно добавить это:
ServerAlias *Еще нужно взглянуть внутрь файла /etc/cups/cups-browsed.conf. Этот файл управляет тем, как принтсервер будет искать принтеры в сети и проводить широковещательную рассылку своих принтеров. Я предлагаю совершенно отключить опцию рассылки. Принтсервер будет искать принтера в сети, но с него принтеры на клиентские машины будут подключатся вручную. Ниже будет описано, почему. Пока же мы находим строку BrowseRemoteProtocols dnssd cups:
# Which protocols will we use to discover printers on the network?
# Can use DNSSD and/or CUPS and/or LDAP, or 'none' for neither.
BrowseRemoteProtocols dnssd cupsБлагодаря этой опции принтсервер ищет расшаренные принтера в сети. Ее мы оставляем включенной, так как в наших интересах, чтобы принтсервер искал принтера в сети. Но нам совершенно не нужно, чтобы принтсервер рассылал вообще все подключенные к нему принтеры, иначе возникнет большая путаница. Для предотвращения такого сценария находим следующую опцию #BrowseLocalProtocols none и раскомментируем ее:
# Which protocols will we use to broadcast shared local printers to the network?
# Can use DNSSD and/or CUPS, or 'none' for neither.
# Only CUPS is actually supported, as DNSSD is done by CUPS itself (we ignore DNSSD in this directive).
BrowseLocalProtocols noneНа этом настройку принтсервера приостанавливаем и переходим к настройке клиентких машин Windows и Linux. Требования к ним такие — позволять посылать на себя задания печати принтсерверу, и посылать задания на печать именно (и только) на принтсервер в случае необходимости печати на сетевой принтер.
В качестве примера настроим печать сквозь принтсервер между двумя клиентскими машинами с Linux (имя хоста linux1) и Windows 8 соотвественно (имя хоста windows1). Начнем с настройки windows1 в качестве приемника печати от принтсервера. У меня к нему подключен и штатно работает принтер Canon i-SENSYS MF4410. Имя принтера — Canon-MF4400. Самый простой способ, на самом деле, обеспечить печать с принтсервера на windows1 — перейти в Панель управления > Программы > Программы и компоненты > Включение или отключение компонентов Windows. Там мы включаем компонент Службы печати и документов > Служба печати LPD. Это позволит подключить данный принтер к принтсерверу с помощью адреса lpd://windows1/Canon-MF4400. Разумеется, назревает вопрос, почему бы не подключить с помощью SMB? Никто не запрещает. Если у вас отлажен данный метод, вы можете расшарить принтер таким образом, и подключить к принтсерверу по протоколу SMB. Инстукции по данному подключению, на мой взгляд, выходят за рамки данной статьи, которая и так выходит довольно объемной. Пока же считаем, что читатель успешно зашел по адресу http://cupsserver:631/admin нажал на кнопку «Добавить новый принтер» и следуя интуиции, логике и прочитатанным ранее мануалам успешно подключил принтер с windows1 по протоколу LPD к принтсерверу cupsserver[example.com] и страница принтера доступна по адресу http://cupsserver:631/printers/Canon-MF4400.
Теперь выполним аналогичную операцию на клиентской машине Linux c именем хоста linux1. Вообще, данная часть будет куда объемнее, так как у клиентской машины есть свой сервис CUPS и его тоже нужно настроить во многом так же, как и принтсервер, за исключением его подчиненной роли в организации печати.
Исправление ошибки обращения к CUPS через loopback по имени хоста
Есть неприятный момент. Если вы введете linux1 в домен, настроите на нем CUPS по этим инструкциям, то можете заметить абсурдную ситуацию, когда на WEB-интерфейс linux1 можно зайти снаружи, но на самом хосте этого сделать нельзя! И графические приложения для локальной настройки принтеров, вроде приложения system-config-printer в Linux Mint, отказываются работать. При попытке подключения на свой же CUPS по по адресу http://linux1:631/ будет сообщение «Запрещено» или «Bad Request». Это известная и толком не решенная на множестве форумов интернета проблема.
В большинстве инструкций по введению Linux в домен одним из пунктов является приведение файла /etc/hosts приблизительно к такому виду:
127.0.0.1 localhost
127.0.1.1 linux1.example.com linux1
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe02::2 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allroutersПочему то CUPS не в силах ассоциировать обращение через 127.0.1.1, то есть через Loopback интерфейс, с именем хоста.
Исправляется эта ошибка двумя способами. Если в вашей сети IP адреса статичные, то в файле /etc/hosts исправьте 127.0.1.1 на IP адрес внешнего сетевого интерфейса клиентской машины, например:
127.0.0.1 localhost
192.168.1.50 linux1.example.com linux1Либо же, раз уж вы вводите Linux в домен, то это предполагает, что в вашей сети работает DHCP и DNS сервер Active Directory. В таком случае просто закомментируйте данную строчку:
127.0.0.1 localhost
# 127.0.1.1 linux1.example.com linux1Разницы в работоспособности или проблем от данного действия пока обнаружено не было.
Настройка адресов прослушивания подключений к CUPS у клиентских машин Linux
Заходим на linux1 любым удобным способом. Редактируем файл /etc/cups/cupsd.conf:
user@linux1:~$ sudo nano /etc/cups/cupsd.confНаходим, добавляем или изменяем в нем строки:
DefaultLanguage ru # Если язык присутствует в папке /usr/share/cups/locale
ServerAlias linux1.example.com linux1 [CNAME псевдоним присвоенный на DNS сервере]
или
ServerAlias * # Если неохота вникать в особенности
Listen /run/cups/cups.sock
Listen localhost:631 # Слушать localhost
Listen 10.10.100.50:631 # IP адрес нашего принтсервера.
Listen cupsserver:631 # Доменное имя принтсервера. Рекомендую чтобы его IP тоже был, на всякий случай
Listen linux1:631 #
или
Port 631 # Будет слушать подключения со всех адресов
Listen /run/cups/cups.sock
Browsing off # Выключено. Машина будет посылать информацию только принтсерверу
DefaultAuthType Basic # Без изменений. Есть вариант с авторизацией Kerberos, но там много подводных камнейНастройка адресов прослушивания подключений к CUPS
В предыдущем блоке мы настроили возможность подключения к CUPS. Теперь перейдем к настройке разрешений на доступ к печати, а также к административным страницам сервиса CUPS на хосте linux1. Вновь открываем, если закрыли, файл /etc/cups/cupsd.conf и переходим к редактированию блоков <Location />, <Location /admin>, <Location /admin/conf>, <Location /admin/log>:
# Restrict access to the server...
<Location />
Order allow,deny # Определяет политику доступа "Что не разрешено, то запрещено"
Allow from localhost # Позволяет печатать самой linux1
Allow from linux1 # Печать на свое имя хоста. Проблемы этого действия описаны выше
Allow from cupsserver # Если CUPS нормально взаимодействует с DNS, то сработает. Увы, не всегда это так
Allow from cupsserver.example.com # FQDN принтсервера
Allow from 10.10.100.50 # Разрешение на печать с IP принтсервера **cupsserver**
</Location>
# Restrict access to the admin pages...
<Location /admin>
Order allow,deny # Аналогично предыдущему
Allow from localhost # Необходимо для возможности добавлять принтеры
Allow from linux1 # Аналогично предыдущему
Allow from 10.10.101.71 # Предположим, это IP админа
Allow from 10.20.50.* # Предположим, это подсеть вашего IT отдела
AuthType Default # То есть CUPS спросит логин и пароль. Подробнее ниже
Require user @SYSTEM # Определение группы доступа к CUPS
</Location>
# Restrict access to configuration files...
<Location /admin/conf>
#Блок идентичен предыдущему
Order allow,deny # Аналогично предыдущему
Allow from localhost # Необходимо для возможности добавлять принтеры
Allow from linux1 # Аналогично предыдущему
Allow from 10.10.101.71 # Предположим, это IP админа
Allow from 10.20.50.* # Предположим, это подсеть вашего IT отдела
AuthType Default # То есть CUPS спросит логин и пароль. Подробнее ниже
Require user @SYSTEM # Определение группы доступа к CUPS
</Location>
# Restrict access to log files...
<Location /admin/log>
#Блок идентичен предыдущему
Order allow,deny # Аналогично предыдущему
Allow from localhost # Необходимо для возможности добавлять принтеры
Allow from linux1 # Аналогично предыдущему
Allow from 10.10.101.71 # Предположим, это IP админа
Allow from 10.20.50.* # Предположим, это подсеть вашего IT отдела
AuthType Default # То есть CUPS спросит логин и пароль. Подробнее ниже
Require user @SYSTEM # Определение группы доступа к CUPS
</Location>Настройка раздачи и получения широковещательной рассылки сетевых принтеров
Еще у клиетской машины Linux, в данном случае linux1, необходимо отредактировать файл /etc/cups/cups-browsed.conf:
user@linux1:~$ sudo nano /etc/cups/cups-browsed.conf
BrowseRemoteProtocols none # Пишем none чтобы не получить кучу принтеров автоматически.
BrowseLocalProtocols cups # Показывать подключеные принтеры в сеть. DNSSD указывать не надо, его директива в cupsd.conf
BrowseOrder Allow,Deny # Аналогично директиве Order в cupsd.conf - необходимо явно указать, куда МОЖНО посылать информацию о подключенных принтерах
BrowseAllow 10.10.100.50 # IP принтсервера
BrowseAllow cupsserver # Имя хоста принтсервера
BrowseAllow cupsserver.example.com # Полное доменное имя принтсервераНастройка административного доступа
Еще пару слов по поводу административного доступа, как на WEB-интерфейс CUPS на принтсервере, так и на любой клиентской машине Linux. Даже при условии наличия 30-50 компьютеров нужно унифицировать авторизацию на CUPS, а не держать в голове или еще где пароли каждой машины. И это важно на всех Linux машинах, ведь чтобы добавить принтер на сервер, его сперва нужно установить локально. Я вижу несколько путей.
Первый — на каждой системе Linux создать пользователя printeradmin (например) и добавить в группу lpadmin:
user@linux1:~$ sudo usermod -a -G lpamin printeradmin и авторизовываться на http://имя_хоста:631/admin c помощью его учетных данных.
Второй вариант практически идентичен и предлагает создать группу в системе, например, printersadmins, добавить туда требуемого администратора CUPS (printeradmin, user):
user@linux1:~$ sudo groupadd printersadmins
user@linux1:~$ sudo usermod -a -G printersadmins printeradmin
user@linux1:~$ sudo usermod -a -G printersadmins userЗатем нужно найти в файле /etc/cups/cups-files.conf строку
# Administrator user group, used to match @SYSTEM in cupsd.conf policy rules...
# This cannot contain the Group value for security reasons...
SystemGroup lpadminи добавить через пробел одну или несколько групп пользователей с правом администрировать CUPS.
# Administrator user group, used to match @SYSTEM in cupsd.conf policy rules...
# This cannot contain the Group value for security reasons...
SystemGroup lpadmin printersadmins somegroupИ наконец, третий вариант. Сделать администраторами принтсервера и CUPS’ов клиентских машин доменную группу пользователей. Для этого принтсервер и клиентские машины Linux должны быть присоединены к домену AD. Есть несколько методов подключения Linux к домену Windows, но, насколько я знаю, основные это подключение с помощью winbind и с помощью SSSD(realmd). Описание данных методов не входит в статью, поэтому остановлюсь только на моментах которые касаются конкретно CUPS’а.
Настройка использования доменных групп пользователей для администрирования CUPS
Каждый метод присоединения к системе централизованной авторизации в Linux создает специальный файл-«трубу» (pipe), сквозь который приложения могут посмотреть список пользователей домена. Чтобы так мог сделать CUPS, нужно разрешить ему использовать pipe в AppArmor’е для аутентификации пользователей. AppArmor — модуль безопасности Linux по управлению доступом. Ограничивает определенные программы набором перечисленных в его политиках файлов. Чтобы добавить CUPS’у право использовать пользователей и группы домена через winbindd, нужно добавить в файл /etc/apparmod.d/local/usr.sbin.cupsd такую строку:
/var/lib/samba/winbindd_privileged/pipe rwЕсли Linux введен в домен через SSSD, то необходимо указать расположение его pipe в /etc/apparmod.d/local/usr.sbin.cupsd, добавив туда строку:
/var/lib/sss/pipes/private/pam rwК тому же, в случае с SSSD это позволяет пройти аутентификацию (узнать кто заходит), но чтобы пройти авторизацию (узнать есть ли право у пользователя управлять CUPS) необходимо также добавить в файл конфигурации SSSD /etc/sssd/sssd.conf строку:
ad_gpo_map_interactive = +cupsЭто, условно выражаюсь, дает CUPS’у право «заглядывать» в SSSD.
К тому же, в силу того, что CUPS теперь зависит от сервиса SSSD, нужно указать CUPS’у что он должен запускаться после SSSD, иначе он будет отваливаться при включении и его будет необходимо каждый раз включать вручную.
Добавим CUPS’у указание грузиться после SSSD. Отредактируем файл сервиса cups.service по пути /lib/systemd/system/, добавив инструкцию After в секцию [Unit]:
[Unit]
Description=CUPS Scheduler
Documentation=man:cupsd(8)
After=sssd.serviceТаким образом CUPS настроен на Basic авторизацию через домен, то есть авторизацию с помощью ввода логина и пароля доменного пользователя с правом администрирования CUPS.
Авторизация может быть настроена и иначе, но принцип (pipe-файл) в целом универсален и есть шанс настроить и для LDAP, FreeIPA и прочих служб каталогов по аналогии.
Установка принтера в Linux
Установить принтер на Linux это часто специфическая задача, разная для разных марок и даже моделей. Поэтому не вижу смысла описывать установку принтера и примем за факт, что на хосте linux1 установлен принтер Kyocera-1024FP с именем Kyocera-1024FP, и страница принтера доступна по ссылке http://linux1:631/printers/Kyocera-1024FP.
Теперь, когда сервер и клиенские машины Linux настроены, к некоторым из них присоединены принтеры, а также есть машины на Windows, которым и с которых нужно печатать, и вся эта система должна быть стабильной и в случае, если на одном из ПК необходимо заменить принтер, то это не должно повлечь за собой перенастройку доброй половины всех ПК, если не всех. К тому же нужно как можно меньше проблем с драйверами. И это вполне возможно.
Группы принтеров (Classes)
Выше мы описывали подключение Canon-MF4400 c хоста windows1 через протокол LPD. Принтер все еще подключен и его статус можно посмотреть на странице http://cupsserver:631/printers/Canon-MF4400. А теперь обратим пристальное внимание на главную страницу администрирования cupsserver http://cupsserver:631/admin. На этой странице есть кнопка «Добавить группу» [Add Class]. Нажмем на нее. В ней вы увидите поля «Название», «Описание», «Расположение», аналогичные таким же при настройке обычного принтера. В нижнем же блоке вы увидите список всех подключенных к принтсерверу принтеров. Выберите Canon-MF4400 или любой который хотите, затем в поле «Название» впишите, например printer-windows1, «Описание» и «Расположение» на ваше усмотрение, и нажмите «Добавить группу».
Теперь у нас есть группа printer-windows1 с принтером Canon-MF4400 в ней. Страница этой группы доступна так же как и страница принтера Canon-MF4400 с оговоркой на немного другой путь — http://cupsserver:631/classes/printer-windows1.
Еще у нас все еще есть подключенный к linux1 принтер Kyocera-1024FP. Подключим его к принтсерверу по HTTP. Выбираем метод подключения «Протокол интернет печати (http)» [Internet Printing Protocol (http)], из списка драйверов выбираем марку «Generic», модель «IPP Everywhere». Называем его как угодно, мы назовем так же как на хосте linux1 — Kyocera-1024FP. Теперь принтер доступен на принтсервере по ссылке http://cupsserver:631/printers/Kyocera-1024FP. Аналогично настройке группы printer-windows1 создаем группу printer-linux1 c принтером Kyocera-1024FP в ней. Ее ссылка соответственно http://cupsserver:631/classes/printer-linux1.
Теперь подключим принтер Kyocera-1024FP с хоста linux1 через принтсервер cupsserver к хосту windows1 с системой Windows 8 на борту без какой либо дополнительной(!) установки драйверов. Для этого мы при подключении принтера выбираем «Выбрать общий принтер по имени». В общем случае мы пишем http://имя_принтcервера:631/classes/название_группы. В нашем конкретном случае — http://cupsserver:631/classes/printer-linux1. При запросе на выбор драйвера указываем марку «Generic», модель — «MS Publisher Imagesetter». Все подтверждаем далее, и имеем подключенный принтер с название вроде printer-linux1 на http://cupsserver:631. Если до сих пор никаких ошибок и подводных камней при настойке не возникло, то попытка пробной печати приведет к успешной печати на Kyocera-1024FP.
Теперь подключим принтер Canon-MF4400 с хоста windows1 через принтсервер cupsserver к хосту linux1 с системой Linux на борту без какой либо дополнительной(!) установки драйверов. Для этого мы при подключении принтера действуем аналогично тому, как подключали Kyocera-1024FP к принтсерверу cupsserver. То есть при добавлении принтера на linux1 выбираем метод подключения «Протокол интернет печати (http)», в качестве расположения принтера (Canon-MF4400) ссылку на его группу на принтсервере — http://cupsserver:631/classes/printer-windows1. При запросе на выбор драйвера указываем марку «Generic», модель — «IPP Everywhere». Называем его как угодно, можно назвать так же как группу — printer-windows1. Теперь принтер доступен на linux1 по ссылке http://linux1:631/printers/printer-windows1, и мы уже можем отправлять на печать документы.
Главная прелесть данного метода в том, что если на любом из ПК заменяется принтер, заменяется сам компьютер, или то и другое сразу, то это никак не влияет на тех, кто был к ним подключен через группу на принтсервере. Единственная настройка производится на принтсервере — к принтсерверу подключается новый принтер, затем из группы, в которой состоял старый принтер, он удаляется, и добавляется новый принтер на замену старому. И никаких дополнительных настроек на любом количестве ПК, только на принтсервере и собственно ПК на котором меняли принтер. Драйвера «IPP Everywhere» и «MS Publisher Imagesetter» содержат большое количество настроек бумаги, печати и т.д., так что нет проблем настроить нужный вид печати через них.
Заключение
Тема слишком обширна, чтобы изложить сколько-нибудь подробно, и даже так статья вышла крайне объемной. Любые уточнения, указания на ошибки, нераскрытые вопросы и советы, данные в комментариях к данной статье, будут приняты во внимание и в случае необходимости включены в статью.
«Камень на камне» с Майклом Бойдом Скачать видео | Ювелирные изделия, видео загрузки
Описание
Вам понравится, если:
- Вы хотите открыть для себя другую технику установки камня : установка камней или металла поверх камней.
- Вы хотите узнать, как добавить дополнительного цвета, размера и текстуры к вашим каменным декорациям с помощью этой техники наслоения.
- Вы хотите раскрыть важные особенности изготовления ювелирных изделий для оправы камня и дизайна ювелирных изделий.
Присоединяйтесь к опытному мастеру по металлу и художнику по драгоценным камням Майклу Бойду и изучите одну из его фирменных техник: камень на каменной оправе. Поднимите фундаментальные навыки на новый уровень с помощью этого обучающего видео-семинара, когда вы откроете для себя важные советы по созданию индивидуальных лицевых панелей, успешному сверлению отверстий в камнях и установке драгоценных камней на более крупные . Это незаменимое техническое руководство с бесконечными возможностями для создания ювелирных украшений.
Закажите копию этого семинара сегодня по номеру:
- Ознакомьтесь с основными советами по изготовлению безеля , чтобы подобрать идеальную оправу, независимо от того, работаете ли вы с непрозрачными, прозрачными, полупрозрачными или полупрозрачными камнями.
- Откройте для себя важные шаги для успешного сверления отверстий в камнях.
- Откройте для себя способы создания плотного крепления с использованием трубок, полировки и эпоксидной смолы.
- Узнайте, как применить этот метод наслоения к металлу , чтобы добиться красивого и контрастного вида металла на камне.
- И многое другое!
Майкл Бойд — прогрессивный и новаторский ювелир, использующий в своей работе необычные, редкие и традиционные материалы. Его опыт художника и колориста сочетается с его способностью резчика по камню определять как форму, так и структуру в своих работах. Используя камень в качестве материала, Майкл сочетает эти материалы с драгоценным металлом в ярком фирменном стиле.Он является членом редакционной коллегии и частым автором журнала Lapidary Journal Jewelry Artist, а также двукратным лауреатом премии Saul Bell Design Award. Его работы представлены на всемирно известных выставках ремесел, а также в частных и музейных коллекциях; чтобы увидеть это, посетите www.michaelboyd.com. Изучите дополнительные советы по обработке металлов и огранке камня от Майкла в его первом видео-семинаре « Основы огранки кабошонов для ювелиров ».
Только вошедшие в систему клиенты, которые приобрели этот продукт, могут оставлять отзывы.
Совместная постановка целей с пожилыми пациентами с хроническими или мультиморбидными заболеваниями: систематический обзор | BMC Geriatrics
Блок-схема процедуры отбора представлена на рис. 1. Первоначальный поиск выявил 3589 ссылок. На основании полнотекстовой оценки 120 статей было включено пять статей. Полнотекстовая оценка статей по 17 протоколам исследований не привела к дополнительным включениям. Проверка ссылок на 12 релевантных обзоров при первичном поиске по базе данных с дополнительной полнотекстовой оценкой 24 статей не привела к дополнительным включениям.Три статьи были включены на основе обратной и прямой проверки ссылок на все включенные статьи. Причинами исключения полнотекстовых статей в соответствии с нашими критериями отбора были дизайн исследования (36), вмешательство (27), поставщик услуг (13), мультиморбидность или хроническое состояние (2), возраст (7), исход (49) или сочетание критериев (45). В итоге в обзор вошло восемь статей.
Рис. 1Блок-схема процедуры выбора. Эта блок-схема основана на блок-схеме PRISMA 2009.Он содержит сводку различных этапов выбора и указывает источник, тип выбора и количество включений и исключений
Риск предвзятости
Все статьи в той или иной степени выражали методологические проблемы. Единственный критерий риска систематической ошибки, по которому все исследования получили оценку «низкий риск», — это сокрытие распределения. В четырех статьях сообщалось о различиях в исходных характеристиках исследуемой и контрольной популяции, а в двух статьях была дана оценка «неясного риска» по этому критерию.Пять статей получили оценку «неясный риск» по защите от загрязнения. Все статьи включали «другие риски предвзятости» в оценке при обсуждении; эти риски (включенные в Дополнительный файл 3) были оценены как «неясные», поскольку их последствия неизвестны. Все риски обобщены на Рис. 2. Подробные результаты оценки рисков, подтверждающие Рис. 2, доступны по запросу.
Рис. 2Риск смещения включенных исследований. * Оценка неполных данных о результатах. † Осведомленность о предотвращении целенаправленных вмешательств.Этот рисунок суммирует риск систематической ошибки при оценке статей, включенных в этот обзор. Оценка риска была основана на критериях обзоров EPOC [16]. Распределение было адекватно скрыто (низкий риск), если единицей распределения было учреждение, команда или профессионал, и распределение было выполнено по всем единицам в начале исследования или если единицей распределения был пациент или эпизод лечения и централизованная Использовалась схема рандомизации. Последовательность распределения генерируется адекватно (низкий риск), если описан случайный компонент в процессе генерации последовательности.Если нет данных о выборочном сообщении результатов, этот критерий оценивается как низкий риск. Измерения исходных результатов не должны показывать существенных различий между исследуемыми группами до вмешательства (низкий риск). Исходные характеристики оцениваются как низкий риск, если сообщаются и аналогичные. Отсутствие критериев исхода вряд ли повлияет на результаты (низкий риск). Знание назначенного вмешательства специалистами по оценке первичных переменных результата должно быть адекватно предотвращено или результаты должны быть объективными (низкий риск).Исследование было надлежащим образом защищено от заражения, если распределение проводилось сообществом, учреждением или практикой, и маловероятно, что контрольная группа получила вмешательство. Девятый критерий — «другие риски предвзятости»
Вмешательства в поддержку совместной постановки целей или установления приоритетов здравоохранения
В восьми статьях, включенных в этот обзор, сообщалось о пяти уникальных вмешательствах. Основываясь на этих вмешательствах, можно было бы провести различие между двумя статьями, описывающими одно и то же базовое исследование, посвященное одному вмешательству, касающемуся установления приоритетов здоровья, PrefCheck [20, 21], и четырем многофакторным вмешательствам, в которых постановка целей и / или установление приоритетов часть более широкого вмешательства.Три из четырех многофакторных вмешательств описали одно и то же исследование, посвященное влиянию управляемой помощи (GC) [22,23,24]. Все остальные статьи касались различных вмешательств, а именно «Помощь пожилым людям в достижении успеха» (HOPES), Модель совместного ухода и Комплексный систематический уход за пожилыми людьми (ISCOPE) ([25–27] соответственно).
Подробная информация о вмешательствах представлена в таблице 1. PrefCheck (т.е. предпочтения в планировании лечения для пожилых пациентов) — единственное включенное исследование, в котором особое внимание уделяется установлению общих приоритетов между терапевтом и пациентом.В рамках программы PrefCheck обученный терапевт проводит консультацию на основе специально разработанного руководства PrefCheck. После того, как пациент оценивает важность каждой существующей проблемы со здоровьем, пациент и терапевт обмениваются информацией и документируют приоритеты в отношении здоровья и лечения [20, 21].
Таблица 1 Вмешательства в отдельные исследованияНесмотря на то, что включенные многофакторные вмешательства не были задуманы как вмешательство с единственным акцентом на постановку целей или установление приоритетов в отношении здоровья, они демонстрируют важные сходства.Во всех этих многофакторных вмешательствах делается явный акцент на постановке целей или установлении приоритетов, а цели или приоритеты определяются конкретно. Важное сходство заключается в том, что все они проводились в основном медсестрой или смежным медицинским работником (за исключением вмешательства ISCOPE, которое проводилось терапевтом или медсестрой под наблюдением терапевта). Во-вторых, участие опекунов было общим компонентом в GC [22,23,24] и вмешательстве ISCOPE [27]. Одно из исследований GC было сосредоточено, в частности, на лицах, осуществляющих уход [22].Кроме того, обучение специалиста, обеспечивающего вмешательство, было прямо упомянуто в GC [22,23,24], ISCOPE [27] и Модели совместного ухода [26]. Кроме того, образовательная программа для вовлеченного пациента была общим компонентом в GC [22,23,24], вмешательстве HOPES [25] и Модели совместного ухода [26]. Наконец, четкое планирование ухода было общим элементом всех многофакторных вмешательств. Несмотря на то, что были общие компоненты, как проанализировано выше, эти многофакторные вмешательства также показали значительные различия из-за изменчивости базовой модели и направленности исследования.
Характеристики исследования и участников
В одном исследовании использовался рандомизированный контролируемый дизайн [25], а в остальных четырех исследованиях были кластерные рандомизированные. Во всех включенных исследованиях группа вмешательства сравнивалась с обычным уходом или стандартной практикой. Количество участников исследования колебалось от 42 до 1921 пациента. Одно исследование было сосредоточено на пациентах с хроническим заболеванием, а именно с серьезным психическим заболеванием [25]. В одно исследование были включены пациенты с диабетом и / или ишемической болезнью сердца, которые также страдали депрессивными симптомами в течение как минимум 2 недель [26].В остальных исследованиях для определения мультиморбидности использовалась гериатрическая оценка [20, 21, 27] или шкала иерархической категории состояния (HCC) [22,23,24]. Хотя все включенные исследования удовлетворяли нашему возрастному критерию, два из них изначально не применяли критерий включения «возраст 65 лет и старше» для основного исследования, а были сосредоточены на более широких возрастных категориях [25, 26]. Большинство исследований проводилось в рамках общей практики / практики первичной медико-санитарной помощи; одно было проведено в общественном центре психического здоровья [25].Исследования проводились в США [22,23,24,25], Великобритании [26], Германии [20, 21] и Нидерландах [27]. Подробная информация об исследовании и характеристиках участников приведены в таблице 2.
Таблица 2 Исследование и характеристики участниковВлияние на показатели результатов
В двух статьях об одном и том же исследовании, в котором применялось вмешательство PrefCheck, сообщалось о частоте установленных приоритетов [20, 21]. В одной статье [20] сообщалось только об определении и планировании приоритетов для интервенционной группы.Приоритеты терапевтов определили вместе с 70% пациентов. Было запланировано лечение 84% приоритетных проблем и 37% неприоритетных проблем. Вмешательство PrefCheck не привело к улучшению договоренности между врачом и пациентом о важности проблем со здоровьем [20].
Вторая статья [21], основанная на 43 записанных консультациях между 28 врачами общей практики и их пациентами, исследовала эффекты вмешательства PrefCheck, чтобы определить степень, в которой общие приоритеты здоровья были установлены и поддерживаются за счет поведения, ориентированного на пациента.В интервенционной группе было проведено 24 консультации; остальные 19 консультаций относились к контрольной группе. Общие заявления об установлении приоритетов были сделаны для разъяснения цели приоритезации в 27,9% всех консультаций (т. Е. 12/43). Четко не указано, являются ли это интервенционными или контрольными консультациями. Шесть консультаций, проведенных с контрольной группой ( N = 19), и девять консультаций, проведенных с группой вмешательства ( N = 24), касались важности по крайней мере одной проблемы со здоровьем.Статистической значимости этого результата не сообщалось [21]. На уровне проблем со здоровьем ( N = 216 проблем со здоровьем) согласие о приоритетном лечении было достигнуто только в ходе семи консультаций (т.е. 3,2%). Не было достигнуто никаких договоренностей об установлении приоритетов для повседневных проблем ( N = 65) [21].
Количество выполненных предварительных распоряжений считалось показателем результатов для определенных приоритетов и целей. Вмешательство НАДЕЖДА увеличило количество выполненных предварительных указаний в группе вмешательства по сравнению с контрольной группой (61% против 33%, размер эффекта.59) [25].
Количество целей в рамках плана ухода также считалось важным результатом нашего обзора. В исследовании ISCOPE 288 участников были случайным образом отобраны для получения плана ухода, в который можно интегрировать проблемы, цели и действия. Для 15% ( N = 43) из них план лечения не был подготовлен терапевтом. В планах интервенционной помощи среднее количество проблем, целей и действий было следующим: 3 (межквартильный размах (IQR) 2–4), 4 (IQR 2–5) и 3 (IQR 2–5), соответственно [27 ].Мы связались с автором, чтобы проверить, доступны ли также номера для контрольной группы. Автор сообщил нам, что четыре пациента, которые не были частью выбранной группы из 288 участников, также получили план лечения.
Шкала оценки пациентом помощи при хронических заболеваниях (PACIC) собирает отчеты пациентов о предпринятых действиях и полученной помощи в соответствии с моделью хронической помощи и предназначена для оценки полученной помощи, ориентированной на пациента, с акцентом на совместную постановку целей, решение проблем и последующие действия как ключевые элементы поддержки самоуправления [28].В дополнение к совокупному измерению качества шкала PACIC состоит из пяти подшкал, т. Е. Постановки целей, координации помощи, поддержки принятия решений, решения проблем и активации пациента [24]. Подшкала «постановки целей» PACIC является важным показателем результатов для нашего обзора.
При оценке эффектов модели GC постановка целей считалась «высококачественной», когда она выполнялась «большую часть времени» или «всегда» [24]. В исследованиях, в которых применялись модели GC и Collaborative Care Model, использовалась шкала PACIC.В модели GC процент пациентов, оценивающих постановку цели как «высокое качество» после получения лечения в течение 6 месяцев, был значительно выше для пациентов GC, чем для пациентов, которые получали обычную помощь (т.е. 24,6% против 11,6%, скорректированное отношение шансов (OR ) 2.37, р. <.001) [24]. Хотя уровень p <0,05 уже не является значимым, процент пациентов, оценивающих постановку целей как «высокое качество» после получения помощи в течение 18 месяцев, был все же выше для пациентов с GC, чем для пациентов, которые получали обычную помощь (т.е. 23,1% против 15,3%, скорректированный OR 1,53 ( p = 0,005) [23].
В модели совместной медицинской помощи баллы пациентов по подшкале постановки целей были выше в совместной группе, чем в «обычной группе лечения» (среднее значение 2,18 (стандартное отклонение 1,2) по сравнению со средним значением 1,77 (стандартное отклонение 1,0)) с величиной эффекта 0,37. Это указывает на то, что данная модель оказания помощи была умеренно эффективной в стимулировании постановки целей в качестве элемента лечения хронических заболеваний [26].
Одна статья, посвященная Программе управляемой помощи для семьи и друзей (GCPFF) [22], включала отчеты опекунов, в которых оценивалось совокупное качество помощи при хронических заболеваниях, предоставляемой получателям помощи, с помощью модифицированной версии шкалы PACIC.По подшкале постановки целей качественные оценки лиц, осуществляющих уход, в GCPFF были значительно выше (среднее значение 3,1 (стандартная ошибка (SE) 0,13) по сравнению со средним значением 2,7 (SE 0,13)), с размером эффекта (ES) 0,47 (95% доверительный интервал). (ES) от 0,15 до 0,79)).
Совместная постановка целей с поддержкой или без поддержки местных медицинских работников для пациентов с множественными хроническими состояниями
Профессиональное резюме
Цель
Сравнить эффективность постановки целей с поддержкой или без поддержки со стороны местных медицинских работников (CHW) для пациентов с множественными хроническими заболеваниями, проживающих в районах с ограниченными ресурсами
Дизайн исследования
| Элемент дизайна | Описание |
|---|---|
| Конструкция | Рандомизированное контролируемое исследование |
| Население | 592 пациента с множественными хроническими заболеваниями, проживающими в районах с ограниченными ресурсами |
| Вмешательства / Компараторы |
|
| Результаты | Первичная: физическое здоровье по самооценке Вторичная: борьба с хроническими заболеваниями, самооценка психического здоровья, качество первичной медико-санитарной помощи, активация пациентов и частота госпитализаций |
| Таймфрейм | 9-месячное наблюдение по поводу первичного исхода |
В этом рандомизированном контролируемом исследовании проверялась эффективность программы постановки целей, которая включала поддержку CHW, под названием Индивидуальное управление для целей, ориентированных на пациента (IMPaCT), по сравнению с постановкой целей без поддержки улучшения физического здоровья пациентов с самооценкой. множественные хронические состояния.МСР — это обученные члены сообщества, которые проводят инструктаж по здоровью пациентов и лиц, осуществляющих уход.
Исследователи рандомизировали пациентов, которые получали программу IMPaCT или не получали программу. В обеих группах исследователи показали пациентам наглядные пособия с низким уровнем грамотности, описывающие поведение в отношении здоровья, которые могут помочь им справиться с хроническими состояниями, такими как гипертония или диабет. Затем пациенты вместе с поставщиками услуг выбирали долгосрочную цель в отношении здоровья.
После определения долгосрочной цели пациенты программы IMPaCT встретились с медработником, чтобы установить краткосрочные цели и разработать планы действий.CHW связывает пациентов с еженедельной группой поддержки и беседует с пациентами еженедельно в течение шести месяцев у них дома, в общинах, клиниках или по телефону. Во время этих бесед медперсонал помогал пациентам ориентироваться в системе здравоохранения, предлагал наставления по постановке целей и давал пациентам обратную связь об их успехах. Пациенты, не участвовавшие в программе, продолжали работать над своими целями без поддержки CHW.
В исследование были включены 592 пациента, проживающих в районах Филадельфии с ограниченными ресурсами.Из них 94% были афроамериканцами, а 2% — латиноамериканцами. Средний возраст составлял 53 года, 62% составляли женщины. Пациенты имели государственную страховку или не имели страховки и имели по крайней мере два из следующих хронических состояний: гипертонию, диабет, ожирение или табачную зависимость. Все получали лечение в академической практике, в федеральном медицинском центре или в медицинском центре по делам ветеранов.
Пациенты прошли опрос для оценки исходов исследования на исходном уровне и снова через шесть и девять месяцев.
Пациенты, лица, осуществляющие уход, и врачи помогли разработать исследование, адаптировать вмешательство и выбрать результаты.
Результаты
Через девять месяцев пациенты двух групп не различались по самооценке физического здоровья; обе группы оценили свое физическое здоровье выше в конце исследования, чем на исходном уровне.
По сравнению с пациентами, не участвовавшими в программе, с пациентами программы IMPaCT
- Сообщил о более высоком качестве первичной медико-санитарной помощи ( p <0,001)
- реже имели несколько госпитализаций во время исследования ( p <0.05) и повторная госпитализация в течение 30 дней после первичной госпитализации ( p <0,05)
Эти две группы не различались по контролю хронических заболеваний, психическому здоровью, активности пациентов или продолжительности пребывания в больнице.
Ограничения
Исследование проходило в Филадельфии; результаты могут отличаться в других регионах. Для пациентов, которые получали лечение в медицинском центре по делам ветеранов, анализ частоты госпитализаций и повторной госпитализации включал данные только из сети Департамента по делам ветеранов и никаких других клинических параметров.
Выводы и актуальность
По сравнению с пациентами, которые не участвовали в программе, пациенты, участвовавшие в программе IMPaCT, не показали улучшения физического здоровья, но оценили качество своей первичной медико-санитарной помощи выше и имели меньшее количество повторных госпитализаций.
Потребности в будущих исследованиях
В будущих исследованиях можно было бы протестировать программу IMPaCT в различных географических регионах или оценить долгосрочные эффекты использования медицинских работников для достижения целей в области здравоохранения.
5 типов границ, которые нужно устанавливать вместе с вашей командой
Вы, наверное, уже знаете, насколько важно иметь здоровые границы.Границы дают вам контроль над своей жизнью, отношениями и тем, как вы проводите время. Это способ сосредоточить вашу энергию на важных вещах и не увлекаться вещами, которые менее важны или не доставляют вам удовольствия.
Однако большая часть рассуждений о границах сосредоточена на их роли в вашей личной жизни, особенно в создании здоровых отношений с семьей, друзьями и партнером. Но отношения на работе тоже имеют значение — в конце концов, что такое команда, как не группа отношений, которые имеют общую цель?
Как и в личной жизни, четкие границы рабочего места на работе имеют решающее значение не только для вашего собственного здравомыслия, но и для здоровья ваших товарищей по команде, а также для качества работы, которую вы можете выполнять вместе.
Продолжайте читать, чтобы узнать, почему границы важны для команд, наиболее важные типы границ, которые необходимо установить на работе, и как вы можете применить их на практике.
Почему важны границы?
Границы так же важны на рабочем месте, как и в остальной части вашей жизни. Без четких границ на работе вы в конечном итоге сгоритесь, обидитесь и будете неудовлетворены своей работой. Профессиональные границы могут быть особенно сложными в небольших командах, в стартапах или в других сплоченных средах, где люди, как правило, носят много шляп.В таких ситуациях границы между разными ролями и обязанностями могут стираться, поэтому особенно важно иметь четкие и здоровые границы для всех.
Если вы боретесь с границами, особенно на работе, вы не одиноки. Многие люди беспокоятся о том, чтобы показаться грубыми, эгоистичными или будто они не работают в команде, если они отстаивают границы. Если вам неудобно или беспокоит установление границ, помните, что границы касаются не только вас. Они также помогают вашей команде, гарантируя, что вы сможете работать как можно лучше и будете здоровым, спокойным и счастливым человеком, с которым можно сотрудничать!
Границы для работы
Есть много типов границ.Здесь мы рассмотрим некоторые из них, которые особенно важны для работы. Затем мы поговорим о том, как их создать и поддерживать.
Физические границы
Физические границы — одни из самых основных и важных, которые необходимо установить. Физические границы связаны с вашим телом и пространством, а также с тем, что вам нужно или с чем вам комфортно физически. Надеюсь, вы обнаружите, что ваши физические границы соблюдаются на работе, но иногда вам все равно придется их отстаивать.
Не каждое нарушение этих границ является драматическим или пугающим, как физическая агрессия, — и коллеги вполне могут столкнуться с физическими границами непреднамеренно, без причинения вреда.
Вот несколько способов напомнить людям о ваших физических границах на работе.
- «Я не могу больше ждать, чтобы сделать перерыв. Мне нужно поесть и подышать свежим воздухом ».
- «Я не смогу сегодня задержаться допоздна. Мне нужно отдохнуть, чтобы я мог сосредоточиться завтра ».
- «Я собираюсь переехать в конференц-зал, чтобы на несколько часов сосредоточиться на работе в одиночестве, я могу ответить на вопросы, когда закончу».
Эмоциональные и интеллектуальные границы
Когда у вас есть здоровые интеллектуальные и эмоциональные границы, вы уделяете приоритетное внимание своим чувствам, мыслям и идеям и относитесь к другим людям с таким же уважением.Сильные эмоциональные границы также означают сохранение сильного самоощущения и отказ от принятия чужих мыслей, мнений или проблем больше, чем вам удобно. На работе это может проявляться в сохранении здорового разделения между профессиональной и личной жизнью.
Вот несколько примеров эмоционального и интеллектуального установления границ на рабочем месте.
- «Я предпочитаю не говорить о своих романтических отношениях на работе. Мне нравится держать некоторые вещи в секрете.”
- «Сьюзен расстроена итогами этой встречи, но я не обязан заставлять ее чувствовать себя лучше».
- «Возможно, я не согласен с вами в этом вопросе, но это не значит, что я невежественен или плохо справляюсь со своей работой».
Приоритет и границы рабочей нагрузки
Чтобы работать с максимальной эффективностью, вам необходимо защитить свою рабочую нагрузку строгими и здоровыми границами. Каждый день или неделю многие члены команды будут просить вас о помощи. Это замечательно — они думают, что вы опытны, и ценят ваш вклад! Но если вы удовлетворяете каждый запрос, вы останетесь измотанным и непродуктивным.Помните, у вас есть только определенное количество часов в неделю. Взяться за все просто невозможно.
Вот несколько способов установить строгие границы, защищающие ваши приоритеты.
- «Мне жаль, что вам нужно срочно разобраться с этим, это звучит нервно! Но у меня сейчас тоже полная тарелка, поэтому я не смогу позаботиться о ней в нужные вам сроки. Я буду рад помочь в следующем месяце, когда у меня будет больше трафика! »
- «Безусловно, я могу взяться за этот проект.Какую еще ответственность вы бы хотели, чтобы я приостановил? »
- «Я могу помочь с этой задачей, но, поскольку я решаю ее впервые, мне понадобится дополнительное время, чтобы ее выполнить».
Границы времени
Очень часто приходится бороться с установлением границ своего рабочего времени. Управление временем — сложная задача для лучших из нас, поэтому даже коллеги с благими намерениями могут время от времени нарушать ваши временные рамки. Без жестких границ вы обнаружите, что все свободное время ускользает от вас — как на работе, так и даже в ваше личное время.
Вот несколько хороших способов установить границы своего времени.
- «Извините, но я не могу посещать встречи до 13:00. Мне нужно непрерывное утреннее рабочее время, чтобы быть продуктивным ».
- «Я выделила нам полчаса на нашу предстоящую встречу. Вот повестка дня — давайте сначала разберемся с важными вещами, чтобы убедиться, что мы не разбегаемся со временем ».
- «Спасибо за ваше сообщение. Я отвечу в понедельник утром, когда вернусь в офис ».
Границы связи
Установите четкие границы того, когда и как вы общаетесь по рабочим вопросам.Если каждый сможет связаться с вами по своему усмотрению, будет еще сложнее обеспечить соблюдение других ваших границ, таких как время и приоритеты.
Вот несколько способов установить границы общения.
- «Я бы предпочел не писать текстовые сообщения по рабочим вопросам. Не могли бы вы вместо этого отправить мне письмо по электронной почте? »
- «Если вы согласитесь звонить мне только в нерабочее время в экстренных случаях, я обещаю забрать трубку, когда вы позвоните, и сделаю все возможное, чтобы помочь.”
- «Если мой статус Slack установлен на« Не беспокоить », это означает, что у меня есть непрерывное рабочее время. Я отвечу на ваше сообщение позже ».
Как установить границы рабочего места?
Итак, теперь мы знаем, почему границы имеют значение, и некоторые важные типы границ, которые необходимо установить. Но как применить их на практике? Вот несколько простых стратегий.
Обсудить границы впереди времени
Это может показаться очевидным, но люди могут уважать ваши границы, только если они знают, что они существуют.Это может показаться пугающим, особенно если вы хотите, чтобы вас считали преданным и надежным, но правда в том, что в установлении границ нет ничего грубого или даже необычного.
Вот несколько способов уточнить границы заранее.
- Когда вы присоединяетесь к новой команде, спросите всех остальных о их границах общения — тогда это идеальное время, чтобы поделиться своими!
- Собираетесь в отпуск на следующей неделе? Сообщите всем, что вы полностью перейдете в автономный режим и вообще не будете проверять рабочее общение.
Настройка структур, поддерживающих ваши границы
После того, как вы договорились о границах со своими коллегами и руководителями, установите процедуры и структуры, которые укрепят их. Это может помочь всем стать частью обычного образа действий вашей команды, а не тем, о чем людям нужно постоянно напоминать.
Вот пара идей:
- Если длительные встречи отнимают ваше независимое рабочее время, начинайте каждую встречу с четкой повестки дня и назначьте одного человека «хранителем протокола» — того, кто поддерживает вопросы повестки дня и следит за соблюдением временных рамок.
- Настройте автоответчик электронной почты в нерабочее время, который позволит любому, кто пытается связаться с вами, узнать о вашей границе — и, возможно, предложит альтернативный способ связаться с вами в настоящих экстренных случаях.
Что мне делать, если моя граница пересечена?
Если кто-то переступит границу, не паникуйте! Время от времени ситуации неизбежно выходят за рамки ваших границ. Подумайте об этом — если вам никогда не приходилось укреплять свои границы, зачем они вам вообще нужны?
Вот несколько советов, как действовать, когда одна из ваших границ находится под угрозой пересечения.
Не переусердствуйтеВам не нужно приводить миллион причин для существования вашей границы; просто заявить об этом достаточно.
Вместо того, чтобы сказать: «Я не могу задержаться допоздна сегодня вечером, я очень устала и у меня есть планы поужинать с моим мужем», попробуйте просто сказать «Извините, я не работаю после пяти, и я не иметь возможность работать сверхурочно прямо сейчас ».
Когда вы делаете исключение, переформулируйте границы
Это нормально — быть гибким в рамках своих границ, когда это необходимо.Но, повторяя, что граница сохранится и в будущем, вы сообщаете, что это всего лишь исключение.
Вместо того, чтобы говорить: «Нет проблем, я справлюсь с этим в эти выходные», попробуйте сказать: «Обычно я не работаю в выходные, но на этот раз я могу помочь, так как это срочно».
Не принимайте это лично
Почти всегда ваши товарищи по команде или коллеги не пытаются заставить вас чувствовать себя плохо или давить на вас, выходя за ваши границы — они просто напряжены и заняты, а их мысли заняты другими делами!
Не сопротивляйтесь конфронтационным способом — если вам нужно, выделите несколько минут, чтобы успокоиться, прежде чем отвечать.Границы не имеют большого значения, поэтому просто вежливо назовите свои и двигайтесь дальше.
Вместо того, чтобы говорить: «Как я уже неоднократно заявлял, я не беру на себя дополнительную работу по выходным», попробуйте сказать: «Мне очень жаль слышать, что у вас такой сжатый срок, но я не работаю над этим. выходные.»
Альтернативы предложения
Придумывание альтернативных решений может быть хорошим способом смягчить удар, когда вы устанавливаете границы. Хотя можно сказать «нет», попытка найти беспроигрышное решение показывает другому человеку, что вы заботитесь о его проблеме — вы просто не хотите попирать свои собственные границы, чтобы помочь ему с ней.Это может сработать особенно хорошо, если вы очень близки с человеком, который задает вопрос, или если очевидно, что ему действительно нужна ваша помощь.
Вместо того, чтобы говорить: «Извините, у меня нет пропускной способности, чтобы помочь вам с этим», попробуйте что-нибудь вроде «На этой неделе много людей, но на следующей неделе все немного расслабится. Могу ли я чем-нибудь вам помочь?
Лучшие границы = Лучшая работа
Установка границ на работе может показаться вам немного пугающей, если вы к этому не привыкли. Но строгие границы не эгоистичны — они на самом деле помогут вам проявить себя наилучшим образом.Это приносит пользу всем, потому что вы можете явиться вместе с остальной частью своей команды и работать над достижением общих целей!
Если вы будете следовать этим советам, чтобы понять свои собственные границы, а затем установить и поддерживать их в дружеской манере, вы будете на пути к более спокойной, продуктивной и не изматывающей работе. Попробуйте — возможно, вам нравится иметь некоторый порядок и самоопределение в своей рабочей жизни!
Сервировка стола в морской тематике с патриотическими флюидами
Добро пожаловать на 668th Tablescape Thursday, вечеринку в блоге, где делятся красивой сервировкой стола на все случаи жизни!
Вчера был очень загружен, поэтому, когда я смогла накрыть стол на этой неделе, был уже поздний вечер.Когда я начал фотографировать, я был счастлив, увидев, что наступил Голубой час. Вы видите, как он смотрит сквозь верхушки деревьев? (Подробнее о Синем часе читайте в предыдущем посте: Секрет синего часа.)
Я показываю эту таблицу в обратном порядке, начиная с фотографий, сделанных вчера поздно вечером, и заканчивая фотографиями, сделанными сегодня рано утром. Для этой картины я выключил весь свет на крыльце. Еще я забыл зажечь одну из маленьких звездных свечей на столе. Драт! lol Я всегда замечаю эти вещи после того, как начинаю фотографировать.Этот маленький огонек в конце концов загорелся.
Включил пару лампочек для этой картины.
Вид сверху…
Я знаю, что 4 июля прошло, но я все еще чувствую патриотизм в эти дни, поэтому я решил смешать этот пляжный стол с патриотической атмосферой.
Вы не можете увидеть это на этой картинке, но на тарелках с салатом гордо развевается красивый американский флаг, который помогает красиво прикрепить их к тарелкам с флагами.Он будет виден на дневных фотографиях, так что следите за ним там.
Несколько фото с сегодняшнего утра…
Без зажженных свечей…
При зажженных свечах…
Кажется, однажды летом я нашел этот фонарь в Маршаллсе… он был таким длинным, трудно вспомнить. Это всегда заставляет меня думать о маяке, поэтому он отлично сочетается с салатными тарелками на этом патриотическом, оформленном в морской тематике настольном пейзаже.
Салатные тарелки от Уоррена Кимбла 1998 года, узор — Coastal Breeze . Обожаю это имя! Это была находка на eBay много лет назад. Синие фужеры были привезены из Dollar Tree несколько лет назад.
Теперь вы можете видеть наш усыпанный звездами флаг, величественно развевающийся над домом хранителя света. Люби это!
Загрузочные устройства для плавников были с пирса 1 несколько лет назад.Однажды летом я купил набор для своего сына и дилера во время визита, и они мне так понравились, что я купил набор для себя, когда вернулся домой. Обеденная тарелка — это еще один дизайн Уоррена Кимбла из 1997 года, узор называется Colonial .
Я хотел, чтобы этот стол выглядел очень непринужденно, поэтому выбрал свои кольца для салфеток из денима, сделанные из переработанных джинсов. (Найдите этот урок без шитья, здесь: Сделайте кольца для салфеток из старых джинсов). Салфетки, покрытые звездочкой, были от Pottery Barn несколько лет назад.Не могу вспомнить, где я нашел красную и белую салфетки — вероятно, пирс 1.
У некоторых джинсов был декоративный пояс (у вас были такие джинсы в свое время?), Который немного усиливал кольца для салфеток. Столовые приборы цвета кобальта / королевского синего цвета — это столовые приборы Cambridge Silversmith Neapolitan. Я не мог найти его в Интернете — кажется, его нет в наличии в большинстве мест.
Рано утром при свечах … и я действительно не забыл зажечь все свечи на этот раз.лол
Надеюсь, вам понравился этот патриотичный стол в пляжной тематике! С нетерпением ждем всех замечательных настроек стола, связанных с Tablescape в четверг на этой неделе!
Знаете ли вы, что «Между дремотой на крыльце» есть в Instagram? Вы найдете меня в Instagram здесь: Между дремотой на крыльце.
Хотите знать, когда появится новый пост в блоге и его можно будет прочитать? Подпишитесь на рассылку обновлений по электронной почте, это бесплатно, и ваша электронная почта никогда не будет передана другим пользователям. Подпишитесь на бесплатную публикацию обновлений по электронной почте здесь: Подпишитесь на публикацию обновлений.
Tablescape Четверг
Если вы участвуете в Tablescape Thursday, пожалуйста, не забудьте добавить ниже свою постоянную ссылку, а не общий адрес блога. Чтобы получить постоянную ссылку, нажмите на название своего сообщения, затем скопируйте и вставьте адрес, отображаемый в адресной строке, в поле «url» при установке ссылки.
Вам нужно будет добавить в свой пост ссылку на вечеринку, чтобы подключиться и принять участие. Таким образом, посетители вашего блога смогут найти вечеринку и других участников Tablescape Thursday.Пожалуйста, не добавляйте название вашего сообщения / блога ВСЕ ЗАГЛАВНЫМИ БУКВАМИ … это имеет тенденцию создавать большие пробелы между рядами ссылок.
* Если сообщение спонсируется или продукт был предоставлен бесплатно, это будет указано в сообщении. Некоторые ссылки могут быть партнерскими ссылками, и как партнер Amazon я могу зарабатывать на соответствующих покупках. *
Индексирование и выбор данных — документация pandas 1.3.3
Информация о маркировке осей в объектах pandas служит многим целям:
Идентифицирует данные (т.е. предоставляет метаданные () с использованием известных индикаторов, важно для анализа, визуализации и отображения интерактивной консоли.
Включает автоматическое и явное выравнивание данных.
Позволяет интуитивно получать и настраивать подмножества набора данных.
В этом разделе мы сосредоточимся на последнем пункте: а именно, как нарезать, нарезать кубиками, и обычно получают и устанавливают подмножества объектов pandas. Основное внимание будет уделяться на Series и DataFrame, поскольку они получили больше внимания разработчиков в эта зона.
Примечание
Операторы индексирования Python и NumPy [] и оператор атрибута . обеспечить быстрый и легкий доступ к структурам данных pandas в широком диапазоне
вариантов использования. Это делает интерактивную работу интуитивно понятной, так как мало нового
чтобы узнать, знаете ли вы, как работать со словарями Python и NumPy
массивы. Однако, поскольку тип данных, к которым нужно получить доступ, неизвестен в
заранее, прямое использование стандартных операторов имеет некоторые ограничения оптимизации.Для
производственного кода, мы рекомендуем вам воспользоваться оптимизированным
методы доступа к данным pandas, представленные в этой главе.
Предупреждение
Будет ли возвращена копия или ссылка для операции настройки, может
зависят от контекста. Иногда это называется присвоением цепочки и
необходимо избегать. См. Раздел «Возврат просмотра или копии».
См. MultiIndex / Advanced Indexing для MultiIndex и дополнительную документацию по индексированию.
См. Поваренную книгу для ознакомления с некоторыми расширенными стратегиями.
Различные варианты индексации
При выборе объекта был внесен ряд дополнений, запрошенных пользователем, чтобы поддерживать более явную индексацию на основе местоположения. pandas теперь поддерживает три типа многоосевой индексации.
.locв основном основан на метках, но также может использоваться с логическим массивом..locвызоветKeyError, если элементы не найдены. Допустимые вводы:Одинарная этикетка, e.грамм.
5или'a'(обратите внимание, что5интерпретируется как метка индекса. Это использование , а не целочисленной позиции вдоль показатель.).Список или массив меток
['a', 'b', 'c'].Объект-фрагмент с метками
'a': 'f'(Обратите внимание, что в отличие от обычного Python срезов, и включаются начало и конец, если они присутствуют в показатель! См. Раздел «Нарезка с помощью этикеток» и конечные точки включены.)Логический массив (любые значения
NAбудут обрабатываться какFalse).Вызываемая функция с одним аргументом (вызывающая серия или DataFrame) и который возвращает допустимый результат для индексации (один из вышеперечисленных).
Подробнее см. Выбор по этикетке.
.ilocв основном основан на целочисленных позициях (от0доlength-1оси), но также может использоваться с логическим значением множество..ilocвызовет ошибкуIndexErrorпри запросе индексатор находится за пределами диапазона, кроме индексаторов среза , которые позволяют индексирование вне пределов. (это соответствует Python / NumPy slice семантика). Допустимые вводы:Целое число, например
5.Список или массив целых чисел
[4, 3, 0].Объект среза с целыми числами
1: 7.Логический массив (любые значения
NAбудут обрабатываться какFalse).Вызываемая функция с одним аргументом (вызывающая серия или DataFrame) и который возвращает допустимый результат для индексации (один из вышеперечисленных).
Подробнее см. Выбор по позиции, Расширенное индексирование и расширенное Иерархический.
.loc,.iloc, а также[] индексированиеможет приниматьвызываемыйв качестве индексатора. Дополнительные сведения см. В разделе «Выбор по вызываемому».
Для получения значений от объекта с многоосевым выделением используются следующие
обозначение (с использованием .loc в качестве примера, но следующее относится к .iloc как
хорошо). Любой из аксессоров осей может быть нулевым срезом : . Топоры остались вне
предполагается, что спецификация составляет : , например p.loc ['a'] эквивалентно p.loc ['a',:,:] .
Тип объекта | Индексаторы |
|---|---|
Серия | |
DataFrame | |
Основы
Как упоминалось при представлении структур данных в последнем разделе, основная функция индексации с помощью [] (также известного как __getitem__ для тех, кто знаком с реализацией поведения классов в Python) выбирает
низкоразмерные срезы. В следующей таблице показаны значения возвращаемого типа, когда
индексирование объектов pandas с помощью [] :
Тип объекта | Выбор | Тип возвращаемого значения |
|---|---|---|
Серия | | скалярное значение |
DataFrame | | |
Здесь мы создаем простой набор данных временного ряда, чтобы использовать его для иллюстрации функциональность индексации:
В [1]: date = pd.диапазон_даты ('1/1/2000', периодов = 8)
В [2]: df = pd.DataFrame (np.random.randn (8, 4),
...: индекс = даты, столбцы = ['A', 'B', 'C', 'D'])
...:
В [3]: df
Из [3]:
А Б В Г
2000-01-01 0,469112 -0,282863 -1,509059 -1,135632
2000-01-02 1,212112 -0,173215 0,119209 -1,044236
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
2000-01-04 0,721555 -0,706771 -1,039575 0,271860
2000-01-05 -0,424972 0,567020 0,276232 -1,087401
2000-01-06 -0.673690 0,113648 -1,478427 0,524988
2000-01-07 0,404705 0,577046 -1,715002 -1,039268
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885
Примечание
Ни одна из функций индексирования не зависит от временных рядов, если только конкретно указано.
Таким образом, как указано выше, у нас есть самая простая индексация с использованием [] :
В [4]: s = df ['A'] В [5]: s [даты [5]] Выход [5]: -0.6736897080883706
Вы можете передать список столбцов на [] , чтобы выбрать столбцы в указанном порядке.Если столбец не содержится в DataFrame, исключение будет
поднятый. Также можно задать несколько столбцов:
В [6]: df
Из [6]:
А Б В Г
2000-01-01 0,469112 -0,282863 -1,509059 -1,135632
2000-01-02 1,212112 -0,173215 0,119209 -1,044236
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
2000-01-04 0,721555 -0,706771 -1,039575 0,271860
2000-01-05 -0,424972 0,567020 0,276232 -1,087401
2000-01-06 -0,673690 0,113648 -1,478427 0.524988
2000-01-07 0,404705 0,577046 -1,715002 -1,039268
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885
В [7]: df [['B', 'A']] = df [['A', 'B']]
В [8]: df
Из [8]:
А Б В Г
2000-01-01 -0,282863 0,469112 -1,509059 -1,135632
2000-01-02 -0,173215 1,212112 0,119209 -1,044236
2000-01-03 -2,104569 -0,861849 -0,494929 1,071804
2000-01-04 -0,706771 0,721555 -1,039575 0,271860
2000-01-05 0,567020 -0,424972 0,276232 -1,087401
2000-01-06 0,113648 -0.673690 -1,478427 0,524988
2000-01-07 0,577046 0,404705 -1,715002 -1,039268
2000-01-08 -1,157892 -0,370647 -1,344312 0,844885
Вы можете найти это полезным для применения преобразования (на месте) к подмножеству столбцы.
Предупреждение
pandas выравнивает все ОСИ при установке Series и DataFrame из .loc и .iloc .
Это приведет к тому, что , а не , изменит df , потому что выравнивание столбца выполняется до присвоения значения.
В [9]: df [['A', 'B']]
Из [9]:
А Б
2000-01-01 -0,282863 0,469112
2000-01-02 -0,173215 1,212112
2000-01-03 -2,104569 -0,861849
2000-01-04 -0,706771 0,721555
2000-01-05 0,567020 -0,424972
2000-01-06 0,113648 -0,673690
2000-01-07 0,577046 0,404705
2000-01-08 -1,157892 -0,370647
В [10]: df.loc [:, ['B', 'A']] = df [['A', 'B']]
В [11]: df [['A', 'B']]
Из [11]:
А Б
2000-01-01 -0,282863 0,469112
2000-01-02 -0,173215 1,212112
2000-01-03 -2.104569 -0,861849
2000-01-04 -0,706771 0,721555
2000-01-05 0,567020 -0,424972
2000-01-06 0,113648 -0,673690
2000-01-07 0,577046 0,404705
2000-01-08 -1,157892 -0,370647
Правильный способ поменять местами значения столбцов — использовать необработанные значения:
В [12]: df.loc [:, ['B', 'A']] = df [['A', 'B']]. To_numpy ()
В [13]: df [['A', 'B']]
Из [13]:
А Б
2000-01-01 0,469112 -0,282863
2000-01-02 1,212112 -0,173215
2000-01-03 -0,861849 -2,104569
2000-01-04 0,721555 -0.706771
2000-01-05 -0,424972 0,567020
2000-01-06 -0,673690 0,113648
2000-01-07 0,404705 0,577046
2000-01-08 -0,370647 -1,157892
Доступ к атрибутам
Вы можете получить доступ к индексу на Series или столбцу на DataFrame напрямую
в качестве атрибута:
В [14]: sa = pd.Series ([1, 2, 3], index = list ('abc'))
В [15]: dfa = df.copy ()
В [16]: sa.b Вых [16]: 2 В [17]: dfa.A Из [17]: 2000-01-01 0,469112 2000-01-02 1.212112 2000-01-03 -0.861849 2000-01-04 0,721555 2000-01-05 -0,424972 2000-01-06 -0,673690 2000-01-07 0,404705 2000-01-08 -0,370647 Freq: D, имя: A, dtype: float64
В [18]: sa.a = 5
В [19]: sa
Из [19]:
а 5
Би 2
c 3
dtype: int64
В [20]: dfa.A = list (range (len (dfa.index))) # нормально, если A уже существует
В [21]: dfa
Из [21]:
А Б В Г
2000-01-01 0 -0,282863 -1,509059 -1,135632
2000-01-02 1 -0,173215 0,119209 -1,044236
2000-01-03 2 -2.104569 -0.494929 1,071804
2000-01-04 3-0,706771 -1,039575 0,271860
2000-01-05 4 0,567020 0,276232 -1,087401
2000-01-06 5 0,113648 -1,478427 0,524988
2000-01-07 6 0,577046 -1,715002 -1,039268
2000-01-08 7 -1,157892 -1,344312 0,844885
В [22]: dfa ['A'] = list (range (len (dfa.index))) # используйте эту форму для создания нового столбца
В [23]: dfa
Из [23]:
А Б В Г
2000-01-01 0 -0,282863 -1,509059 -1,135632
2000-01-02 1 -0,173215 0,119209 -1,044236
2000-01-03 2 -2.104569 -0.494929 1,071804
2000-01-04 3-0,706771 -1,039575 0,271860
2000-01-05 4 0,567020 0,276232 -1,087401
2000-01-06 5 0,113648 -1,478427 0,524988
2000-01-07 6 0,577046 -1,715002 -1,039268
2000-01-08 7 -1,157892 -1,344312 0,844885
Предупреждение
Вы можете использовать этот доступ, только если элемент индекса является действительным идентификатором Python, например
s.1не допускается. См. Здесь объяснение допустимых идентификаторов.Атрибут будет недоступен, если он конфликтует с существующим именем метода, например.грамм.
с.мин.не допускается, нос ['min']возможно.Аналогично, атрибут будет недоступен, если он конфликтует с любым из следующего списка:
index,major_axis,minor_axis,позиции.В любом из этих случаев стандартное индексирование по-прежнему будет работать, например
с ['1'],с ['min']ис ['index']будет доступ к соответствующему элементу или столбцу.
Если вы используете среду IPython, вы также можете использовать завершение табуляции для увидеть эти доступные атрибуты.
Вы также можете назначить dict строке DataFrame :
В [24]: x = pd.DataFrame ({'x': [1, 2, 3], 'y': [3, 4, 5]})
В [25]: x.iloc [1] = {'x': 9, 'y': 99}
В [26]: x
Из [26]:
х у
0 1 3
1 9 99
2 3 5
Вы можете использовать доступ к атрибутам для изменения существующего элемента Series или столбца DataFrame, но будьте осторожны;
если вы попытаетесь использовать доступ к атрибутам для создания нового столбца, он создаст новый атрибут, а не
новый столбец.В версии 0.21.0 и новее это вызовет UserWarning :
В [1]: df = pd.DataFrame ({'one': [1., 2., 3.]})
В [2]: df.two = [4, 5, 6]
UserWarning: Pandas не позволяет назначать серии несуществующим столбцам - см. Https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute_access
В [3]: df
Из [3]:
один
0 1.0
1 2,0
2 3,0
Диапазоны нарезки
Самый надежный и последовательный способ нарезки диапазонов по произвольным осям — это
описано в разделе «Выбор по позиции»
детализация .iloc метод. А пока мы объясним семантику нарезки с помощью оператора [] .
С Series синтаксис работает точно так же, как с ndarray, возвращая часть значения и соответствующие метки:
В [27]: s [: 5] Из [27]: 2000-01-01 0,469112 2000-01-02 1.212112 2000-01-03 -0,861849 2000-01-04 0,721555 2000-01-05 -0,424972 Freq: D, имя: A, dtype: float64 В [28]: s [:: 2] Из [28]: 2000-01-01 0,469112 2000-01-03 -0,861849 2000-01-05 -0.424972 2000-01-07 0,404705 Freq: 2D, имя: A, dtype: float64 В [29]: s [:: - 1] Из [29]: 2000-01-08 -0,370647 2000-01-07 0,404705 2000-01-06 -0,673690 2000-01-05 -0,424972 2000-01-04 0,721555 2000-01-03 -0,861849 2000-01-02 1.212112 2000-01-01 0,469112 Freq: -1D, имя: A, dtype: float64
Обратите внимание, что настройка также работает:
В [30]: s2 = s.copy () В [31]: s2 [: 5] = 0 В [32]: s2 Из [32]: 2000-01-01 0,000000 2000-01-02 0,000000 2000-01-03 0.000000 2000-01-04 0,000000 2000-01-05 0,000000 2000-01-06 -0,673690 2000-01-07 0,404705 2000-01-08 -0,370647 Freq: D, имя: A, dtype: float64
С DataFrame нарезка внутри [] нарезает строки . Это предусмотрено
в основном для удобства, поскольку это обычная операция.
В [33]: df [: 3]
Из [33]:
А Б В Г
2000-01-01 0,469112 -0,282863 -1,509059 -1,135632
2000-01-02 1,212112 -0,173215 0.119209 -1,044236
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
В [34]: df [:: - 1]
Из [34]:
А Б В Г
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885
2000-01-07 0,404705 0,577046 -1,715002 -1,039268
2000-01-06 -0,673690 0,113648 -1,478427 0,524988
2000-01-05 -0,424972 0,567020 0,276232 -1,087401
2000-01-04 0,721555 -0,706771 -1,039575 0,271860
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
2000-01-02 1,212112 -0,173215 0,119209 -1,044236
2000-01-01 0.469112 -0,282863 -1,509059 -1,135632
Выбор по этикетке
Предупреждение
Будет ли возвращена копия или ссылка для операции настройки, может зависеть от контекста.
Иногда это называется присвоением цепочки , и его следует избегать.
См. Раздел «Возврат просмотра или копии».
Предупреждение
.locявляется строгим, если вы представляете срезы, несовместимые (или конвертируемые) с типом индекса. Например используя целые числа вDatetimeIndex.Это вызовет ошибкуTypeError.
В [35]: dfl = pd.DataFrame (np.random.randn (5, 4),
....: columns = list ('ABCD'),
....: index = pd.date_range ('20130101', периоды = 5))
....:
В [36]: dfl
Из [36]:
А Б В Г
2013-01-01 1.075770 -0.109050 1.643563 -1.469388
2013-01-02 0,357021 -0,674600 -1,776904 -0,968914
2013-01-03 -1.294524 0,413738 0,276662 -0,472035
2013-01-04 -0.013960 -0.362543 -0,006154 -0,1
2013-01-05 0,895717 0,805244 -1,206412 2,565646
В [4]: dfl.loc [2: 3] TypeError: невозможно выполнить индексирование срезов нас этими индексаторами [2]
Строковые типы в нарезке могут быть преобразованы в тип индекса и привести к естественной нарезке.
В [37]: dfl.loc ['20130102': '20130104']
Из [37]:
А Б В Г
2013-01-02 0.357021 -0,674600 -1,776904 -0,968914
2013-01-03 -1.294524 0,413738 0,276662 -0,472035
2013-01-04 -0,013960 -0,362543 -0,006154 -0,1
pandas предоставляет набор методов для индексирования на основе меток . Это протокол, основанный на строгом включении.
Каждая запрошенная метка должна быть в индексе, иначе возникнет ошибка KeyError .
При нарезке как начальная граница , так и граница остановки будут , включая , если они присутствуют в индексе.Целые числа являются допустимыми метками, но они относятся к метке , а не к позиции .
Атрибут .loc является основным методом доступа. Допустимые значения:
Одна этикетка, например
5или'a'(обратите внимание, что5интерпретируется как метка индекса. Это использование , а не как целое число вдоль индекса.).Список или массив меток
['a', 'b', 'c'].Объект-фрагмент с метками
'a': 'f'(Обратите внимание, что в отличие от обычного Python срезов, и включаются начало и конец, если они присутствуют в показатель! См. Раздел «Нарезка с помощью этикеток».Логический массив.
A
, вызываемый, см. Выбор по вызываемому.
В [38]: s1 = pd.Series (np.random.randn (6), index = list ('abcdef'))
В [39]: s1
Из [39]:
а 1.431256
б 1.340309
c -1.170299
d -0,226169
e 0,410835
f 0,813850
dtype: float64
В [40]: s1.loc ['c':]
Из [40]:
с -1.170299
d -0,226169
e 0,410835
f 0,813850
dtype: float64
В [41]: s1.loc ['b']
Из [41]: 1.3403088497993827
Обратите внимание, что настройка также работает:
В [42]: s1.loc ['c':] = 0 В [43]: s1 Из [43]: а 1.431256 б 1.340309 с 0,000000 г 0,000000 е 0,000000 f 0,000000 dtype: float64
с DataFrame:
В [44]: df1 = pd.DataFrame (np.random.randn (6, 4),
....: index = list ('abcdef'),
....: columns = list ('ABCD'))
....:
В [45]: df1
Из [45]:
А Б В Г
а 0,132003 -0,827317 -0,076467 -1,187678
б 1.130127 -1.436737 -1.413681 1.607920
в 1.024180 0.569605 0.875906 -2.211372
г 0,974466 -2,006747 -0,410001 -0,078638
е 0,545952 -1,219217 -1,226825 0,769804
ф -1,281247 -0,727707 -0,121306 -0,097883
В [46]: df1.loc [['a', 'b', 'd'],:]
Из [46]:
А Б В Г
а 0.132003 -0,827317 -0,076467 -1,187678
б 1.130127 -1.436737 -1.413681 1.607920
г 0,974466 -2,006747 -0,410001 -0,078638
Доступ через срезы этикеток:
В [47]: df1.loc ['d' :, 'A': 'C']
Из [47]:
А Б В
д 0,974466 -2,006747 -0,410001
е 0,545952 -1,219217 -1,226825
ф -1,281247 -0,727707 -0,121306
Для получения поперечного сечения с помощью метки (эквивалент df.xs ('a') ):
В [48]: df1.loc ['a'] Из [48]: А 0.132003 В -0,827317 С -0.076467 D -1.187678 Имя: a, dtype: float64
Для получения значений с помощью логического массива:
В [49]: df1.loc ['a']> 0
Из [49]:
Правда
B ложно
C Ложь
D Ложь
Имя: a, dtype: bool
В [50]: df1.loc [:, df1.loc ['a']> 0]
Из [50]:
А
а 0,132003
б 1.130127
в 1.024180
г 0,974466
e 0,545952
f -1,281247
значений NA в логическом массиве распространяются как Ложь :
Изменено в версии 1.0.2.
В [51]: mask = pd.array ([True, False, True, False, pd.NA, False], dtype = "boolean") В [52]: маска Из [52]:[Верно, Ложно, Верно, Ложно, , Ложно] Длина: 6, dtype: boolean В [53]: df1 [маска] Из [53]: А Б В Г а 0,132003 -0,827317 -0,076467 -1,187678 в 1.024180 0.569605 0.875906 -2.211372
Для явного получения значения:
# это также эквивалентно `df1.at ['a', 'A']` ` В [54]: df1.loc ['a', 'A'] Аут [54]: 0.13200317033032932
Нарезка с этикетками
При использовании .loc со срезами, если метки начала и конца
присутствуют в индексе, то элементы , расположенные на между ними (включая их)
возвращаются:
В [55]: s = pd.Series (list ('abcde'), index = [0, 3, 2, 5, 4])
В [56]: s.loc [3: 5]
Из [56]:
3 б
2 с
5 дней
dtype: объект
Если хотя бы один из двух отсутствует, но индекс отсортирован и может быть по сравнению с метками начала и остановки, то нарезка будет по-прежнему работать как ожидается, выбрав метки, которые ранжируют между двумя:
В [57]: с.sort_index () Из [57]: 0 а 2 с 3 б 4 е 5 дней dtype: объект В [58]: s.sort_index (). Loc [1: 6] Из [58]: 2 с 3 б 4 е 5 дней dtype: объект
Однако, если хотя бы один из двух отсутствует и , индекс не сортируется,
возникнет ошибка (поскольку в противном случае это было бы дорогостоящим с точки зрения вычислений,
а также потенциально неоднозначный для индексов смешанного типа). Например, в
Пример выше, s.loc [1: 6] вызовет KeyError .
Обоснование такого поведения см. Конечные точки включены.
В [59]: s = pd.Series (list ('abcdef'), index = [0, 3, 2, 5, 4, 2])
В [60]: s.loc [3: 5]
Из [60]:
3 б
2 с
5 дней
dtype: объект
Кроме того, если в индексе есть повторяющиеся метки и , дублируется либо начальная, либо конечная метка,
возникнет ошибка. Например, в приведенном выше примере s.loc [2: 5] вызовет KeyError .
Для получения дополнительной информации о повторяющихся этикетках см. Повторяющиеся ярлыки.
Выбор по позиции
Предупреждение
Будет ли возвращена копия или ссылка для операции настройки, может зависеть от контекста.Иногда это называется присвоением цепочки , и его следует избегать.
См. Раздел «Возврат просмотра или копии».
pandas предоставляет набор методов для получения чисто целочисленной индексации . Семантика близко соответствует нарезке Python и NumPy. Это индексирование на основе 0. При нарезке начальная граница - , включая , а верхняя граница - , исключая . Попытка использовать нецелое число, даже допустимая метка вызовет ошибку IndexError .
Атрибут .iloc является основным методом доступа. Допустимые значения:
Целое число, например
5.Список или массив целых чисел
[4, 3, 0].Объект среза с целыми числами
1: 7.Логический массив.
A
, вызываемый, см. Выбор по вызываемому.
В [61]: s1 = pd.Series (np.random.randn (5), индекс = список (диапазон (0, 10, 2))) В [62]: s1 Из [62]: 0 0,695775 2 0,341734 4 0,959726 6 -1,110336 8 -0,619976 dtype: float64 В [63]: s1.iloc [: 3] Из [63]: 0 0,695775 2 0,341734 4 0,959726 dtype: float64 В [64]: s1.iloc [3] Из [64]: -1.1103361028
Обратите внимание, что настройка также работает:
В [65]: s1.iloc [: 3] = 0 В [66]: s1 Из [66]: 0 0,000000 2 0,000000 4 0,000000 6 -1,110336 8 -0,619976 dtype: float64
с DataFrame:
В [67]: df1 = pd.DataFrame (np.random.randn (6, 4),
....: index = list (диапазон (0, 12, 2)),
....: columns = list (диапазон (0, 8, 2)))
....:
В [68]: df1
Из [68]:
0 2 4 6
0 0,149748 -0,732339 0,687738 0,176444
2 0,403310 -0,154951 0,301624 -2,179861
4 -1,369849 -0,954208 1,462696 -1,743161
6 -0,826591 -0,345352 1,314232 0,6
8 0,995761 2,396780 0,014871 3,357427
10 -0,317441 -1,236269 0,896171 -0,487602
Выбор с помощью целочисленного нарезания:
В [69]: df1.iloc [: 3]
Из [69]:
0 2 4 6
0 0,149748 -0,732339 0,687738 0,176444
2 0,403310 -0,154951 0,301624 -2,179861
4 -1,369849 -0,954208 1,462696 -1,743161
В [70]: df1.iloc [1: 5, 2: 4]
Из [70]:
4 6
2 0,301624 -2,179861
4 1,462696 -1,743161
6 1,314232 0,6
8 0,014871 3,357427
Выбрать через целочисленный список:
В [71]: df1.iloc [[1, 3, 5], [1, 3]]
Из [71]:
2 6
2 -0,154951 -2,179861
6 -0,345352 0,6
10 -1.236269 -0,487602
В [72]: df1.iloc [1: 3,:]
Из [72]:
0 2 4 6
2 0,403310 -0,154951 0,301624 -2,179861
4 -1,369849 -0,954208 1,462696 -1,743161
В [73]: df1.iloc [:, 1: 3]
Из [73]:
2 4
0 -0,732339 0,687738
2 -0,154951 0,301624
4 -0,954208 1,462696
6 -0,345352 1,314232
8 2,396780 0,014871
10 -1,236269 0,896171
# это также эквивалентно `df1.iat [1,1]` В [74]: df1.iloc [1, 1] Аут [74]: -0.1549507744249032
Для получения поперечного сечения с использованием целочисленной позиции (эквивалент df.xs (1) ):
В [75]: df1.iloc [1] Из [75]: 0 0,403310 2 -0,154951 4 0,301624 6 -2,179861 Имя: 2, dtype: float64
Индексы срезов вне диапазона обрабатываются изящно, как в Python / NumPy.
# это разрешено в Python / NumPy.
В [76]: x = list ('abcdef')
В [77]: x
Out [77]: ['a', 'b', 'c', 'd', 'e', 'f']
В [78]: x [4:10]
Out [78]: ['e', 'f']
В [79]: x [8:10]
Из [79]: []
В [80]: s = pd.Серия (x)
В [81]: s
Из [81]:
0 а
1 б
2 с
3 дн.
4 е
5 ж
dtype: объект
В [82]: s.iloc [4:10]
Из [82]:
4 е
5 ж
dtype: объект
В [83]: s.iloc [8:10]
Out [83]: Series ([], dtype: object)
Обратите внимание, что использование срезов, выходящих за границы, может привести к пустая ось (например, возвращается пустой DataFrame).
В [84]: dfl = pd.DataFrame (np.random.randn (5, 2), columns = list ('AB'))
В [85]: dfl
Из [85]:
А Б
0 -0,082240 -2,182937
1 0,380396 0.084844
2 0,432390 1,519970
3 -0,493662 0,600178
4 0,274230 0,132885
В [86]: dfl.iloc [:, 2: 3]
Из [86]:
Пустой фрейм данных
Столбцы: []
Индекс: [0, 1, 2, 3, 4]
В [87]: dfl.iloc [:, 1: 3]
Из [87]:
B
0 -2,182937
1 0,084844
2 1,519970
3 0,600178
4 0,132885
В [88]: dfl.iloc [4: 6]
Из [88]:
А Б
4 0,27423 0,132885
Один индексатор, выходящий за границы, вызовет ошибку IndexError .
Список индексаторов, у которых какой-либо элемент находится за пределами, вызовет Ошибка индекса .
>>> dfl.iloc [[4, 5, 6]] IndexError: позиционные индексаторы находятся за пределами >>> dfl.iloc [:, 4] IndexError: одиночный позиционный индексатор находится за пределами
Выбор по телефону
.loc , .iloc , а также [] индексирование может принимать вызываемый в качестве индексатора.
Вызываемая функция должна быть функцией с одним аргументом (вызывающая серия или DataFrame), которая возвращает допустимые выходные данные для индексации.
В [89]: df1 = pd.DataFrame (np.random.randn (6, 4),
....: index = list ('abcdef'),
....: columns = list ('ABCD'))
....:
В [90]: df1
Из [90]:
А Б В Г
а -0,023688 2,410179 1,450520 0,206053
б -0,251905 -2,213588 1,063327 1,266143
в 0,299368 -0,863838 0,408204 -1,048089
г -0,025747 -0,988387 0,094055 1,262731
е 1,289997 0,082423 -0,055758 0,536580
ф -0,489682 0,369374 -0,034571 -2,484478
В [91]: df1.loc [lambda df: df ['A']> 0,:]
Из [91]:
А Б В Г
с 0.299368 -0,863838 0,408204 -1,048089
е 1,289997 0,082423 -0,055758 0,536580
В [92]: df1.loc [:, lambda df: ['A', 'B']]
Из [92]:
А Б
а -0,023688 2,410179
б -0,251905 -2,213588
в 0,299368 -0,863838
г -0,025747 -0,988387
е 1,289997 0,082423
ж -0,489682 0,369374
В [93]: df1.iloc [:, lambda df: [0, 1]]
Из [93]:
А Б
а -0,023688 2,410179
б -0,251905 -2,213588
в 0,299368 -0,863838
г -0,025747 -0,988387
е 1,289997 0,082423
ж -0,489682 0,369374
В [94]: df1 [лямбда df: df.столбцы [0]]
Из [94]:
а -0,023688
б -0,251905
в 0,299368
d -0,025747
e 1.289997
f -0,489682
Имя: A, dtype: float64
Вы можете использовать вызываемую индексацию в Series .
В [95]: df1 ['A']. Loc [лямбда s: s> 0] Из [95]: в 0,299368 e 1.289997 Имя: A, dtype: float64
Используя эти методы / индексаторы, вы можете связать операции выбора данных без использования временной переменной.
В [96]: bb = pd.read_csv ('data / baseball.csv', index_col = 'id')
В [97]: (bb.groupby (['год', 'команда']). sum ()
....: .loc [лямбда df: df ['r']> 100])
....:
Из [97]:
stint g ab r h X2b X3b hr rbi sb cs bb so ibb hbp sh sf gidp
год команда
2007 КИН 6 379 745 101 203 35 2 36 125,0 10,0 1,0 105 127,0 14,0 1,0 1,0 15,0 18,0
ДЕТ 5 301 1062 162 283 54 4 37 144,0 24,0 7.0 97 176,0 3,0 10,0 4,0 8,0 28,0
HOU 4 311 926 109 218 47 6 14 77,0 10,0 4,0 60 212,0 3,0 9,0 16,0 6,0 17,0
LAN 11413 1021 153293 61 3 36 154,0 7,0 5,0 114 141,0 8,0 9,0 3,0 8,0 29,0
NYN 13 622 1854 240 509 101 3 61 243,0 22,0 4,0 174 310,0 24,0 23,0 18,0 15,0 48,0
SFN 5 482 1305 198 337 67 6 40 171,0 26,0 7,0 235 188,0 51,0 8,0 16,0 6,0 41,0
ТЕКСТ 2 198 729 115 200 40 4 28 115.0 21,0 4,0 73140,0 4,0 5,0 2,0 8,0 16,0
ТЗ 4 459 1408 187 378 96 2 58 223,0 4,0 2,0 190 265,0 16,0 12,0 4,0 16,0 38,0
Сочетание позиционной индексации и индексации на основе меток
Если вы хотите получить 0-й и 2-й элементы из индекса в столбце «A», вы можете сделать:
В [98]: dfd = pd.DataFrame ({'A': [1, 2, 3],
....: 'B': [4, 5, 6]},
....: index = список ('abc'))
....:
В [99]: dfd
Из [99]:
А Б
а 1 4
б 2 5
в 3 6
В [100]: dfd.loc [dfd.index [[0, 2]], 'A']
Из [100]:
а 1
c 3
Имя: A, dtype: int64
Это также можно выразить с помощью .iloc , явно получая местоположения в индексаторах и используя позиционная индексация для выбора вещей.
В [101]: dfd.iloc [[0, 2], dfd.columns.get_loc ('A')]
Из [101]:
а 1
c 3
Имя: A, dtype: int64
Для получения нескольких индексаторов , используя .get_indexer :
В [102]: dfd.iloc [[0, 2], dfd.columns.get_indexer (['A', 'B'])] Из [102]: А Б а 1 4 в 3 6
Индексирование со списком с отсутствующими метками устарело
Предупреждение
Изменено в версии 1.0.0.
Использование .loc или [] со списком с одной или несколькими пропущенными метками больше не будет переиндексировать в пользу .reindex .
В предыдущих версиях при использовании .loc [list-of-labels] работал бы до тех пор, пока было найдено не менее 1 ключей (в противном случае
вызовет KeyError ).Это поведение было изменено и теперь будет вызывать ошибку KeyError , если хотя бы одна метка отсутствует.
Рекомендуемая альтернатива - использовать .reindex () .
Например.
В [103]: s = pd.Series ([1, 2, 3]) В [104]: s Из [104]: 0 1 1 2 2 3 dtype: int64
Выбор со всеми найденными ключами не изменился.
В [105]: s.loc [[1, 2]] Из [105]: 1 2 2 3 dtype: int64
Предыдущее поведение
В [4]: s.loc [[1, 2, 3]] Из [4]: 1 2.0 2 3,0 3 NaN dtype: float64
Текущее поведение
В [4]: s.loc [[1, 2, 3]] Передача списков лайков в .loc с любыми несоответствующими элементами вызовет KeyError в будущем вы можете использовать .reindex () в качестве альтернативы. Смотрите документацию здесь: https://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike Из [4]: 1 2,0 2 3,0 3 NaN dtype: float64
Переиндексирование
Идиоматический способ добиться выбора потенциально ненайденных элементов - через .Переплет () . См. Также раздел о переиндексации.
В [106]: s.reindex ([1, 2, 3]) Из [106]: 1 2,0 2 3,0 3 NaN dtype: float64
В качестве альтернативы, если вы хотите выбрать только действительных ключей , следующее будет идиоматическим и эффективным; гарантируется сохранение dtype выделения.
В [107]: label = [1, 2, 3] В [108]: s.loc [s.index.intersection (метки)] Из [108]: 1 2 2 3 dtype: int64
Наличие дублированного индекса повысит до .переиндекс () :
В [109]: s = pd.Series (np.arange (4), index = ['a', 'a', 'b', 'c']) В [110]: label = ['c', 'd']
В [17]: s.reindex (метки) ValueError: невозможно переиндексировать с повторяющейся оси
Как правило, желаемые метки можно пересекать с текущими оси, а затем переиндексировать.
В [111]: s.loc [s.index.intersection (метки)]. Reindex (метки) Из [111]: в 3,0 d NaN dtype: float64
Однако это будет по-прежнему , если ваш результирующий индекс будет продублирован.
В [41]: labels = ['a', 'd'] В [42]: s.loc [s.index.intersection (метки)]. Reindex (метки) ValueError: невозможно переиндексировать с повторяющейся оси
Отбор случайных выборок
Случайный выбор строк или столбцов из Series или DataFrame с помощью метода sample () . По умолчанию метод отбирает строки и принимает определенное количество строк / столбцов для возврата или часть строк.
В [112]: s = pd.Series ([0, 1, 2, 3, 4, 5]) # Если аргументы не переданы, возвращается 1 строка.В [113]: s.sample () Из [113]: 4 4 dtype: int64 # Можно указать количество строк: В [114]: s.sample (n = 3) Из [114]: 0 0 4 4 1 1 dtype: int64 # Или часть строк: В [115]: s.sample (frac = 0,5) Из [115]: 5 5 3 3 1 1 dtype: int64
По умолчанию образец вернет каждую строку не более одного раза, но можно также выполнить выборку с заменой
с помощью опции заменить :
В [116]: s = pd.Series ([0, 1, 2, 3, 4, 5]) # Без замены (по умолчанию): В [117]: с.образец (n = 6, replace = False) Из [117]: 0 0 1 1 5 5 3 3 2 2 4 4 dtype: int64 # С заменой: В [118]: s.sample (n = 6, replace = True) Из [118]: 0 0 4 4 3 3 2 2 4 4 4 4 dtype: int64
По умолчанию каждая строка имеет равную вероятность быть выбранной, но если вы хотите, чтобы строки
чтобы иметь разные вероятности, вы можете передать веса выборки функции выборки как весит . Эти веса могут быть списком, массивом NumPy или серией, но они должны быть той же длины, что и объект, который вы выбираете.Отсутствующие значения будут рассматриваться как нулевой вес, а значения inf не допускаются. Если суммы весов не равны 1, они будут повторно нормализованы путем деления всех весов на сумму весов. Например:
В [119]: s = pd.Series ([0, 1, 2, 3, 4, 5]) В [120]: example_weights = [0, 0, 0,2, 0,2, 0,2, 0,4] В [121]: s.sample (n = 3, weights = example_weights) Из [121]: 5 5 4 4 3 3 dtype: int64 # Вес будет повторно нормализован автоматически В [122]: example_weights2 = [0,5, 0, 0, 0, 0, 0] В [123]: с.образец (n = 1, weights = example_weights2) Из [123]: 0 0 dtype: int64
При применении к DataFrame вы можете использовать столбец DataFrame в качестве весов выборки. (при условии, что вы выбираете строки, а не столбцы), просто передавая имя столбца в виде строки.
В [124]: df2 = pd.DataFrame ({'col1': [9, 8, 7, 6],
.....: 'weight_column': [0.5, 0.4, 0.1, 0]})
.....:
В [125]: df2.sample (n = 3, weights = 'weight_column')
Из [125]:
col1 weight_column
1 8 0.4
0 9 0,5
2 7 0,1
образец также позволяет пользователям выбирать столбцы вместо строк с использованием аргумента оси .
В [126]: df3 = pd.DataFrame ({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
В [127]: df3.sample (n = 1, axis = 1)
Из [127]:
col1
0 1
1 2
2 3
Наконец, можно также установить начальное число для генератора случайных чисел образца образца , используя аргумент random_state , который будет принимать либо целое число (как начальное значение), либо объект NumPy RandomState.
В [128]: df4 = pd.DataFrame ({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
# С заданным семенем образец всегда будет рисовать одни и те же строки.
В [129]: df4.sample (n = 2, random_state = 2)
Из [129]:
col1 col2
2 3 4
1 2 3
В [130]: df4.sample (n = 2, random_state = 2)
Из [130]:
col1 col2
2 3 4
1 2 3
Настройка с увеличением
Операции .loc / [] могут выполнять увеличение при установке несуществующего ключа для этой оси.
В случае Series это фактически операция добавления.
В [131]: se = pd.Series ([1, 2, 3]) В [132]: se Из [132]: 0 1 1 2 2 3 dtype: int64 В [133]: se [5] = 5. В [134]: se Из [134]: 0 1.0 1 2,0 2 3,0 5 5,0 dtype: float64
DataFrame может быть увеличен по любой оси через .loc .
В [135]: dfi = pd.DataFrame (np.arange (6) .reshape (3, 2), .....: columns = ['A', 'B']) .....: В [136]: dfi Из [136]: А Б 0 0 1 1 2 3 2 4 5 В [137]: dfi.loc [:, 'C'] = dfi.loc [:, 'A'] В [138]: dfi Из [138]: А Б В 0 0 1 0 1 2 3 2 2 4 5 4
Это похоже на операцию добавления к DataFrame .
В [139]: dfi.loc [3] = 5 В [140]: dfi Из [140]: А Б В 0 0 1 0 1 2 3 2 2 4 5 4 3 5 5 5
Быстрое получение и установка скалярного значения
Поскольку индексирование с помощью [] должно обрабатывать множество случаев (доступ по одной метке,
нарезка, логическое индексирование и т. д.), у него есть немного накладных расходов, чтобы вычислить
из того, что вы просите. Если вы хотите получить доступ только к скалярному значению,
Самый быстрый способ - использовать методы на и и на , которые реализованы на
все структуры данных.
Аналогично loc , at обеспечивает скалярный поиск на основе метки , а iat обеспечивает поиск на основе целых чисел аналогично iloc
В [141]: s.iat [5] Вых [141]: 5 В [142]: df.в [даты [5], 'A'] Из [142]: -0.6736897080883706 В [143]: df.iat [3, 0] Из [143]: 0,7215551622443669
Можно также установить с помощью этих же индексаторов.
В [144]: df.at [date [5], 'E'] = 7 В [145]: df.iat [3, 0] = 7
на может увеличить объект на месте, как указано выше, если индексатор отсутствует.
В [146]: df.at [даты [-1] + pd.Timedelta ('1 день'), 0] = 7
В [147]: df
Из [147]:
А Б В Г Д Е 0
2000-01-01 0.469112 -0,282863 -1,509059 -1,135632 NaN NaN
2000-01-02 1,212112 -0,173215 0,119209 -1,044236 NaN NaN
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804 NaN NaN
2000-01-04 7,000000 -0,706771 -1,039575 0,271860 NaN NaN
2000-01-05 -0,424972 0,567020 0,276232 -1,087401 NaN NaN
2000-01-06 -0,673690 0,113648 -1,478427 0,524988 7,0 NaN
2000-01-07 0,404705 0,577046 -1,715002 -1,039268 NaN NaN
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885 NaN NaN
9 января 2000 г. NaN NaN NaN NaN NaN 7.0
Булево индексирование
Другой распространенной операцией является использование логических векторов для фильтрации данных.
Операторы: | для или , и для и и ~ для , а не .
Эти должны быть сгруппированы с помощью круглых скобок , поскольку по умолчанию Python будет
оценить такое выражение, как df ['A']> 2 & df ['B'] <3 как df ['A']> (2 & df ['B']) <3 , а желаемый порядок оценки - (df ['A']> 2) и (df ['B'] <3) .
Использование логического вектора для индексации серии работает точно так же, как в NumPy ndarray:
В [148]: s = pd.Series (диапазон (-3, 4)) В [149]: s Из [149]: 0–3 1-2 2-1 3 0 4 1 5 2 6 3 dtype: int64 В [150]: s [s> 0] Из [150]: 4 1 5 2 6 3 dtype: int64 В [151]: s [(s <-1) | (s> 0,5)] Из [151]: 0–3 1-2 4 1 5 2 6 3 dtype: int64 В [152]: s [~ (s <0)] Из [152]: 3 0 4 1 5 2 6 3 dtype: int64
Вы можете выбирать строки из DataFrame, используя логический вектор той же длины, что и индекс DataFrame (например, что-то производное от одного из столбцов DataFrame):
В [153]: df [df ['A']> 0]
Из [153]:
А Б В Г Д Е 0
2000-01-01 0.469112 -0,282863 -1,509059 -1,135632 NaN NaN
2000-01-02 1,212112 -0,173215 0,119209 -1,044236 NaN NaN
2000-01-04 7,000000 -0,706771 -1,039575 0,271860 NaN NaN
2000-01-07 0,404705 0,577046 -1,715002 -1,039268 NaN NaN
Понимание списков и карта Метод серии также можно использовать для создания
более сложные критерии:
В [154]: df2 = pd.DataFrame ({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
.....: 'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
.....: 'c': np.random.randn (7)})
.....:
# нужно только два или три
В [155]: критерий = df2 ['a']. Map (lambda x: x.startswith ('t'))
В [156]: df2 [критерий]
Из [156]:
а б в
2 два года 0,041290
3 три x 0,361719
4 два года -0,238075
# эквивалентно, но медленнее
В [157]: df2 [[x.startswith ('t') для x в df2 ['a']]]
Из [157]:
а б в
2 два года 0,041290
3 три x 0,361719
4 два года -0,238075
# Несколько критериев
В [158]: df2 [критерий & (df2 ['b'] == 'x')]
Из [158]:
а б в
3 три x 0.361719
С методами выбора Выбор по метке, Выбор по позиции, и Advanced Indexing, вы можете выбрать более чем одну ось, используя логические векторы в сочетании с другими выражениями индексации.
В [159]: df2.loc [критерий & (df2 ['b'] == 'x'), 'b': 'c'] Из [159]: до н.э 3 х 0,361719
Предупреждение
iloc поддерживает два вида логического индексирования. Если индексатор является логическим Series ,
возникнет ошибка.Например, в следующем примере df.iloc [s.values, 1] подходит.
Логический индексатор - это массив. Но df.iloc [s, 1] вызовет ValueError .
В [160]: df = pd.DataFrame ([[1, 2], [3, 4], [5, 6]],
.....: index = list ('abc'),
.....: columns = ['A', 'B'])
.....:
В [161]: s = (df ['A']> 2)
В [162]: s
Из [162]:
Ложь
б Верно
c Верно
Имя: A, dtype: bool
В [163]: df.loc [s, 'B']
Из [163]:
б 4
в 6
Имя: B, dtype: int64
В [164]: df.iloc [s.values, 1]
Из [164]:
б 4
в 6
Имя: B, dtype: int64
Индексирование с помощью isin
Рассмотрим метод isin () из серии , который возвращает логическое значение
вектор, который является истинным везде, где в переданном списке присутствуют элементы Series .
Это позволяет вам выбирать строки, в которых один или несколько столбцов имеют нужные вам значения:
В [165]: s = pd.Series (np.arange (5), index = np.arange (5) [:: - 1], dtype = 'int64') В [166]: s Из [166]: 4 0 3 1 2 2 1 3 0 4 dtype: int64 В [167]: с.isin ([2, 4, 6]) Из [167]: 4 ложь 3 ложь 2 Верно 1 ложь 0 Верно dtype: bool В [168]: s [s.isin ([2, 4, 6])] Из [168]: 2 2 0 4 dtype: int64
Тот же метод доступен для объектов Index и полезен для случаев
когда вы не знаете, какой из искомых ярлыков присутствует на самом деле:
В [169]: s [s.index.isin ([2, 4, 6])] Из [169]: 4 0 2 2 dtype: int64 # сравните это со следующим В [170]: s.reindex ([2, 4, 6]) Из [170]: 2 2.0 4 0,0 6 NaN dtype: float64
Кроме того, MultiIndex позволяет выбрать отдельный уровень для использования
в проверке членства:
В [171]: s_mi = pd.Series (np.arange (6), .....: index = pd.MultiIndex.from_product ([[0, 1], ['a', 'b', 'c']])) .....: В [172]: s_mi Из [172]: 0 а 0 б 1 с 2 1 а 3 б 4 в 5 dtype: int64 В [173]: s_mi.iloc [s_mi.index.isin ([(1, 'a'), (2, 'b'), (0, 'c')])] Из [173]: 0 с 2 1 а 3 dtype: int64 В [174]: s_mi.iloc [s_mi.index.isin (['a', 'c', 'e'], level = 1)] Из [174]: 0 а 0 с 2 1 а 3 в 5 dtype: int64
DataFrame также имеет метод isin () . При вызове и передайте набор
значения в виде массива или dict. Если значения являются массивом, isin возвращает
DataFrame логических значений, имеющий ту же форму, что и исходный DataFrame, с True
где бы элемент ни находился в последовательности значений.
В [175]: df = pd.DataFrame ({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
.....: 'ids2': ['a', 'n', 'c', 'n']})
.....:
В [176]: values = ['a', 'b', 1, 3]
В [177]: df.isin (значения)
Из [177]:
vals ids ids2
0 правда правда правда
1 Неверно Верно Неверно
2 Верно Неверно Неверно
3 Ложно Ложно Ложно
Часто бывает необходимо сопоставить определенные значения с определенными столбцами.
Просто сделайте значения dict , где ключом является столбец, а значение
список элементов, которые вы хотите проверить.
В [178]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
В [179]: df.isin (значения)
Из [179]:
vals ids ids2
0 верно верно неверно
1 Неверно Верно Неверно
2 Верно Неверно Неверно
3 Ложно Ложно Ложно
Объедините DataFrame isin с методами any () и all () , чтобы
быстро выбрать подмножества ваших данных, которые соответствуют заданным критериям.
Чтобы выбрать строку, в которой каждый столбец соответствует своему критерию:
В [180]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
В [181]: row_mask = df.isin (значения).все (1)
В [182]: df [row_mask]
Из [182]:
vals ids ids2
0 1 а а
The
where () Метод и маскирование Выбор значений из серии с логическим вектором обычно возвращает
подмножество данных. Чтобы гарантировать, что результат выбора имеет ту же форму, что и
исходные данные, вы можете использовать метод where в Series и DataFrame .
Чтобы вернуть только выбранные строки:
В [183]: s [s> 0] Из [183]: 3 1 2 2 1 3 0 4 dtype: int64
Чтобы вернуть серию той же формы, что и оригинал:
В [184]: с.где (s> 0) Из [184]: 4 NaN 3 1.0 2 2,0 1 3,0 0 4,0 dtype: float64
Выбор значений из DataFrame с логическим критерием теперь также сохраняет
форма входных данных. , где используется под капотом в качестве реализации.
Приведенный ниже код эквивалентен df. где (df <0) .
В [185]: df [df <0]
Из [185]:
А Б В Г
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0,352480 NaN -1.1 NaN
2000-01-03 -0,864883 NaN -0,227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1,169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2,670153 -0,114722 NaN -0,048048
2000-01-08 NaN NaN -0.048788 -0.808838
Кроме того, , где принимает необязательный другой аргумент для замены
значения, где условие - Ложь, в возвращенной копии.
В [186]: df.где (df <0, -df)
Из [186]:
А Б В Г
2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166
2000-01-02 -0,352480 -0,3 -1,1 -1,655824
2000-01-03 -0,864883 -0,299674 -0,227870 -0,281059
2000-01-04 -0,846958 -1,222082 -0,600705 -1,233203
2000-01-05 -0,669692 -0.605656 -1,169184 -0,342416
2000-01-06 -0,868584 -0,948458 -2,297780 -0,684718
2000-01-07 -2,670153 -0,114722 -0,168904 -0,048048
2000-01-08 -0,801196 -1,3 -0,048788 -0,808838
Вы можете установить значения на основе некоторых логических критериев.Интуитивно это можно сделать так:
В [187]: s2 = s.copy ()
В [188]: s2 [s2 <0] = 0
В [189]: s2
Из [189]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
В [190]: df2 = df.copy ()
В [191]: df2 [df2 <0] = 0
В [192]: df2
Из [192]:
А Б В Г
2000-01-01 0,000000 0,000000 0,485855 0,245166
2000-01-02 0,000000 0,3 0,000000 1,655824
2000-01-03 0,000000 0,299674 0,000000 0,281059
2000-01-04 0,846958 0,000000 0.600705 0,000000
2000-01-05 0,669692 0,000000 0,000000 0,342416
2000-01-06 0,868584 0,000000 2,297780 0,000000
2000-01-07 0,000000 0,000000 0,168904 0,000000
2000-01-08 0.801196 1.3 0.000000 0.000000
По умолчанию , где возвращает измененную копию данных. Существует
необязательный параметр вместо , чтобы можно было изменить исходные данные
без создания копии:
В [193]: df_orig = df.copy ()
В [194]: df_orig.where (df> 0, -df, inplace = True)
В [195]: df_orig
Из [195]:
А Б В Г
2000-01-01 2.104139 1,309525 0,485855 0,245166
2000-01-02 0,352480 0,3 1,1 1,655824
2000-01-03 0,864883 0,299674 0,227870 0,281059
2000-01-04 0,846958 1,222082 0,600705 1,233203
2000-01-05 0,669692 0,605656 1,169184 0,342416
2000-01-06 0,868584 0,948458 2,297780 0,684718
2000-01-07 2,670153 0,114722 0,168904 0,048048
2000-01-08 0,801196 1,3 0,048788 0,808838
Примечание
Подпись для DataFrame.where () отличается от numpy.где () .
Примерно df1., где (m, df2) эквивалентно np., где (m, df1, df2) .
В [196]: df.where (df <0, -df) == np.where (df <0, df, -df)
Из [196]:
А Б В Г
2000-01-01 Правда Правда Правда Правда
2000-01-02 Правда Правда Правда Правда
2000-01-03 Правда Правда Правда Правда
2004-01-04 Правда Правда Правда Правда
05.01.2000 Правда Правда Правда Правда
2000-01-06 Правда Правда Правда Правда
07.01.2000 Правда Правда Правда Правда
2008-01-08 Правда Правда Правда Правда
Центровка
Кроме того, , где выравнивает входное логическое условие (ndarray или DataFrame),
такой, что возможен частичный выбор с настройкой.Это аналогично
частичная установка через .loc (но по содержимому, а не по меткам осей).
В [197]: df2 = df.copy ()
В [198]: df2 [df2 [1: 4]> 0] = 3
В [199]: df2
Из [199]:
А Б В Г
2000-01-01 -2.104139 -1.309525 0.485855 0.245166
2000-01-02 -0.352480 3.000000 -1.1 3.000000
2000-01-03 -0,864883 3,000000 -0,227870 3,000000
2000-01-04 3.000000 -1.222082 3.000000 -1.233203
2000-01-05 0,669692 -0,605656-1.169184 0,342416
2000-01-06 0,868584 -0,948458 2,297780 -0,684718
2000-01-07 -2,670153 -0,114722 0,168904 -0,048048
2000-01-08 0.801196 1.3 -0.048788 -0.808838
Где также может принимать параметры оси и уровня для выравнивания ввода, когда
выполняя , где .
В [200]: df2 = df.copy ()
В [201]: df2.where (df2> 0, df2 ['A'], axis = 'index')
Из [201]:
А Б В Г
2000-01-01 -2.104139 -2.104139 0,485855 0,245166
2000-01-02 -0,352480 0,3 -0,352480 1,655824
2000-01-03 -0,864883 0,299674 -0,864883 0,281059
2000-01-04 0,846958 0,846958 0,600705 0,846958
2000-01-05 0,669692 0,669692 0,669692 0,342416
2000-01-06 0,868584 0,868584 2,297780 0,868584
2000-01-07 -2,670153 -2,670153 0,168904 -2,670153
2000-01-08 0.801196 1.3 0.801196 0.801196
Это эквивалент (но быстрее) следующего.
В [202]: df2 = df.copy ()
В [203]: df.apply (лямбда x, y: x.where (x> 0, y), y = df ['A'])
Из [203]:
А Б В Г
2000-01-01 -2.104139 -2.104139 0,485855 0,245166
2000-01-02 -0,352480 0,3 -0,352480 1,655824
2000-01-03 -0,864883 0,299674 -0,864883 0,281059
2000-01-04 0,846958 0,846958 0,600705 0,846958
2000-01-05 0,669692 0,669692 0,669692 0,342416
2000-01-06 0,868584 0,868584 2,297780 0,868584
2000-01-07 -2,670153 -2,670153 0,168904 -2,670153
2000-01-08 0.801196 1.3 0.801196 0.801196
, где может принимать вызываемый объект как условие и других аргументов. Функция должна
быть с одним аргументом (вызывающая серия или DataFrame), который возвращает действительный вывод
как условие и другой аргумент .
В [204]: df3 = pd.DataFrame ({'A': [1, 2, 3],
.....: 'B': [4, 5, 6],
.....: 'C': [7, 8, 9]})
.....:
В [205]: df3.where (лямбда x: x> 4, лямбда x: x + 10)
Из [205]:
А Б В
0 11 14 7
1 12 5 8
2 13 6 9
Маска
mask () - это обратная логическая операция для , где .
В [206]: s.mask (s> = 0)
Из [206]:
4 NaN
3 NaN
2 NaN
1 NaN
0 NaN
dtype: float64
В [207]: df.mask (df> = 0)
Из [207]:
А Б В Г
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0,352480 NaN -1,1 NaN
2000-01-03 -0,864883 NaN -0,227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1,169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2,670153 -0,114722 NaN -0,048048
2000-01-08 NaN NaN -0.048788 -0.808838
Настройка с условным увеличением с использованием
numpy () Альтернатива where () - использовать numpy.where () .
В сочетании с настройкой нового столбца вы можете использовать его для увеличения DataFrame, в котором
значения определены условно.
Предположим, у вас есть два варианта выбора в следующем фрейме данных. И ты хочешь установите цвет нового столбца на «зеленый», когда второй столбец имеет «Z».Вы можете сделать следующее:
В [208]: df = pd.DataFrame ({'col1': список ('ABBC'), 'col2': список ('ZZXY')})
В [209]: df ['color'] = np.where (df ['col2'] == 'Z', 'green', 'red').
В [210]: df
Из [210]:
col1 col2 цвет
0 A Z зеленый
1 B Z зеленый
2 B X красный
3 C Y красный
Если у вас несколько условий, вы можете использовать numpy.select () для этого. Сказать
соответствует трем условиям, есть три варианта выбора цвета, с четвертым цветом
в качестве запасного варианта вы можете сделать следующее.
В [211]: условия = [ .....: (df ['col2'] == 'Z') & (df ['col1'] == 'A'), .....: (df ['col2'] == 'Z') & (df ['col1'] == 'B'), .....: (df ['col1'] == 'B') .....:] .....: В [212]: choices = ['желтый', 'синий', 'фиолетовый'] В [213]: df ['color'] = np.select (условия, варианты, по умолчанию = 'черный') В [214]: df Из [214]: col1 col2 цвет 0 A Z желтый 1 B Z синий 2 B X фиолетовый 3 C Y черный
Объекты DataFrame имеют запрос () метод, позволяющий выбирать с помощью выражения.
Вы можете получить значение кадра, в котором столбец b имеет значения
между значениями столбцов a и c . Например:
В [215]: n = 10
В [216]: df = pd.DataFrame (np.random.rand (n, 3), columns = list ('abc'))
В [217]: df
Из [217]:
а б в
0 0,438921 0,118680 0,863670
1 0,138138 0,577363 0,686602
2 0,595307 0,564592 0,520630
3 0,2 0,926075 0,616184
4 0,078718 0,854477 0,898725
5 0,076404 0.523211 0,5
6 0,7 0,216974 0,564056
7 0,397890 0,454131 0,6
8 0,074315 0,437913 0,019794
9 0,559209 0,502065 0,026437
# чистый питон
В [218]: df [(df ['a']
7 0,397890 0,454131 0,6
# запрос
В [219]: df.query ('(a
7 0,397890 0,454131 0,6
Сделайте то же самое, но вернитесь к именованному индексу, если нет столбца
с именем .
В [220]: df = pd.DataFrame (np.random.randint (n / 2, size = (n, 2)), columns = list ('bc'))
В [221]: df.index.name = 'a'
В [222]: df
Из [222]:
до н.э
а
0 0 4
1 0 1
2 3 4
3 4 3
4 1 4
5 0 3
6 0 1
7 3 4
8 2 3
9 1 1
В [223]: df.запрос ('a Если вместо этого вы не хотите или не можете давать название своему индексу, вы можете использовать имя индекс в выражении вашего запроса:
В [224]: df = pd.DataFrame (np.random.randint (n, size = (n, 2)), columns = list ('bc'))
В [225]: df
Из [225]:
до н.э
0 3 1
1 3 0
2 5 6
3 5 2
4 7 4
5 0 1
6 2 5
7 0 1
8 6 0
9 7 9
В [226]: df.query ('index Примечание
Если имя вашего индекса перекрывается с именем столбца, имя столбца будет
учитывая приоритет.Например,
В [227]: df = pd.DataFrame ({'a': np.random.randint (5, size = 5)})
В [228]: df.index.name = 'a'
В [229]: df.query ('a> 2') # использует столбец 'a', а не индекс
Из [229]:
а
а
1 3
3 3
Вы по-прежнему можете использовать индекс в выражении запроса, используя специальный
идентификатор "index":
В [230]: df.query ('index> 2')
Из [230]:
а
а
3 3
4 2
Если по какой-то причине у вас есть столбец с именем index , вы можете обратиться к
индекс как ilevel_0 , но на этом этапе вы должны рассмотреть
переименование столбцов в менее неоднозначное.
MultiIndex query () Синтаксис Вы также можете использовать уровни DataFrame с MultiIndex , как если бы они были столбцами в кадре:
В [231]: n = 10
В [232]: colors = np.random.choice (['красный', 'зеленый'], size = n)
В [233]: foods = np.random.choice (['яйца', 'ветчина'], размер = n)
В [234]: цвета
Из [234]:
array (['красный', 'красный', 'красный', 'зеленый', 'зеленый', 'зеленый', 'зеленый', 'зеленый',
'зеленый', 'зеленый'], dtype = '
зеленые яйца -0,748199 1,318931
яйца -2,029766 0,792652
ветчина 0,461007 -0,542749
ветчина -0,305384 -0,479195
яйца 0,095031 -0,270099
яйца -0,707140 -0,773882
яйца 0.229453 0,304418
В [239]: df.query ('color == "red"')
Из [239]:
0 1
цветная еда
красный окорок 0,194889 -0,381994
ветчина 0,318587 2,089075
яйца -0,728293 -0,0
Если уровни MultiIndex не имеют названия, вы можете ссылаться на них, используя
специальные имена:
В [240]: df.index.names = [None, None]
В [241]: df
Из [241]:
0 1
красный окорок 0,194889 -0,381994
ветчина 0,318587 2.089075
яйца -0,728293 -0,0
зеленые яйца -0,748199 1,318931
яйца -2,029766 0,792652
ветчина 0,461007 -0,542749
ветчина -0,305384 -0,479195
яйца 0,095031 -0,270099
яйца -0,707140 -0,773882
яйца 0,229453 0,304418
В [242]: df.query ('ilevel_0 == "красный"')
Из [242]:
0 1
красный окорок 0,194889 -0,381994
ветчина 0,318587 2,089075
яйца -0,728293 -0,0
Условное обозначение - ilevel_0 , что означает «индексный уровень 0» для 0-го уровня.
индекса .
query () Примеры использования Пример использования query () - это когда у вас есть коллекция DataFrame объектов, которые имеют подмножество имен столбцов (или индекс
уровни / имена) вместе. Вы можете передать один и тот же запрос обоим кадрам без необходимо указать, какой фрейм вы хотите запрашивать
В [243]: df = pd.DataFrame (np.random.rand (n, 3), columns = list ('abc'))
В [244]: df
Из [244]:
а б в
0 0.224283 0,736107 0,139168
1 0,302827 0,657803 0,713897
2 0,611185 0,136624 0,984960
3 0,195246 0,123436 0,627712
4 0,618673 0,371660 0,047902
5 0,480088 0,062993 0,185760
6 0,568018 0,483467 0,445289
7 0,309040 0,274580 0,587101
8 0,258993 0,477769 0,370255
9 0,550459 0,840870 0,304611
В [245]: df2 = pd.DataFrame (np.random.rand (n + 2, 3), columns = df.columns)
В [246]: df2
Из [246]:
а б в
0 0,357579 0,229800 0,596001
1 0,309059 0,957923 0.965663
2 0,123102 0,336914 0,318616
3 0,526506 0,323321 0,860813
4 0,518736 0,486514 0,384724
5 0,1 0,505723 0,614533
6 0,8 0,623977 0,676639
7 0,480559 0,378528 0,460858
8 0,420223 0,136404 0,141295
9 0,732206 0,419540 0,604675
10 0,604466 0,848974 0,896165
11 0,589168 0,
6 0,732716
В [247]: expr = '0,0 <= a <= c <= 0,5'
В [248]: карта (лямбда-фрейм: frame.query (expr), [df, df2])
Выход [248]: <карта в 0x7f25d5f73220>
query () Сравнение синтаксиса Python и pandas Полный синтаксис, похожий на numpy:
В [249]: df = pd.DataFrame (np.random.randint (n, размер = (n, 3)), columns = list ('abc'))
В [250]: df
Из [250]:
а б в
0 7 8 9
1 1 0 7
2 2 7 2
3 6 2 2
4 2 6 3
5 3 8 2
6 1 7 2
7 5 1 5
8 9 8 0
9 1 5 0
В [251]: df.query ('(a Немного лучше, если убрать круглые скобки (операторы сравнения связывают жестче
чем , и | ):
В [253]: df.запрос ('a Используйте английский вместо символов:
В [254]: df.query ('a Довольно близко к тому, как это можно было бы написать на бумаге:
В [255]: df.query ('a у и нет у операторов query () также поддерживает специальное использование Python в и отсутствует в операторах сравнения , обеспечивая краткий синтаксис для вызова - это метод из Series или DataFrame .
# получить все строки, в которых столбцы "a" и "b" имеют перекрывающиеся значения
В [256]: df = pd.DataFrame ({'a': list ('aabbccddeeff'), 'b': list ('aaaabbbbcccc'),
.....: 'c': np.random.randint (5, size = 12),
.....: 'd': np.random.randint (9, size = 12)})
.....:
В [257]: df
Из [257]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
6 д б 3 3
7 д б 2 1
8 e c 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
В [258]: df.запрос ('а в б')
Из [258]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
# Как бы вы это сделали на чистом Python
В [259]: df [df ['a']. Isin (df ['b'])]
Из [259]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
В [260]: df.query ('a not in b')
Из [260]:
а б в г
6 д б 3 3
7 д б 2 1
8 e c 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
# чистый Python
В [261]: df [~ df ['a']. Isin (df ['b'])]
Из [261]:
а б в г
6 д б 3 3
7 д б 2 1
8 e c 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
Вы можете комбинировать это с другими выражениями для очень сжатых запросов:
# строки, в которых столбцы a и b имеют перекрывающиеся значения
Значения # и col c меньше, чем значения col d
В [262]: df.запрос ('a in b и c Примечание
Обратите внимание, что в и не в оцениваются в Python, поскольку numexpr не имеет эквивалента этой операции.Однако только в / не в Само выражение вычисляется в ванильном Python. Например, в
выражение
df.query ('a in b + c + d')
(b + c + d) оценивается с помощью numexpr и , затем в операция оценивается на простом Python. В общем, любые операции, которые могут
будет оцениваться с использованием numexpr будет.
Специальное использование оператора
== со списком объектов Сравнение списка значений со столбцом с использованием == /! = работает аналогично
до в / не в .
В [264]: df.query ('b == ["a", "b", "c"]')
Из [264]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
6 д б 3 3
7 д б 2 1
8 e c 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
# чистый Python
В [265]: df [df ['b']. Isin ([«a», «b», «c»])]
Из [265]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
6 д б 3 3
7 д б 2 1
8 e c 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
В [266]: df.запрос ('c == [1, 2]')
Из [266]:
а б в г
0 а а 2 6
2 б а 1 6
3 б а 2 1
7 д б 2 1
9 д в 2 0
11 f c 1 2
В [267]: df.query ('c! = [1, 2]')
Из [267]:
а б в г
1 а а 4 7
4 в б 3 6
5 в б 0 2
6 д б 3 3
8 e c 4 3
10 ж в 0 6
# использование в / не в
В [268]: df.query ('[1, 2] in c')
Из [268]:
а б в г
0 а а 2 6
2 б а 1 6
3 б а 2 1
7 д б 2 1
9 д в 2 0
11 f c 1 2
В [269]: df.query ('[1, 2] не в c')
Из [269]:
а б в г
1 а а 4 7
4 в б 3 6
5 в б 0 2
6 д б 3 3
8 e c 4 3
10 ж в 0 6
# чистый Python
В [270]: df [df ['c'].isin ([1, 2])]
Из [270]:
а б в г
0 а а 2 6
2 б а 1 6
3 б а 2 1
7 д б 2 1
9 д в 2 0
11 f c 1 2
Логические операторы
Вы можете инвертировать логические выражения с помощью слова , а не или оператора ~ .
В [271]: df = pd.DataFrame (np.random.rand (n, 3), columns = list ('abc'))
В [272]: df ['bools'] = np.random.rand (len (df))> 0,5
В [273]: df.query ('~ bools')
Из [273]:
a b c bools
2 0.697753 0,212799 0,329209 Ложь
7 0,275396 0,6 0,826619 Ложь
8 0,1 0,558748 0,262467 Ложь
В [274]: df.query ('not bools')
Из [274]:
a b c bools
2 0,697753 0,212799 0,329209 Ложь
7 0,275396 0,6 0,826619 Ложь
8 0,1 0,558748 0,262467 Ложь
В [275]: df.query ('not bools') == df [~ df ['bools']]
Из [275]:
a b c bools
2 Правда Правда Правда Правда
7 Правда Правда Правда Правда
8 правда правда правда правда
Конечно, выражения могут быть сколь угодно сложными:
# короткий синтаксис запроса
В [276]: shorter = df.query ('a 2')
# эквивалент в чистом Python
В [277]: длиннее = df [(df ['a'] 2)]
.....:
В [278]: короче
Из [278]:
a b c bools
7 0,275396 0,6 0,826619 Ложь
В [279]: длиннее
Из [279]:
a b c bools
7 0,275396 0,6 0,826619 Ложь
В [280]: короче == длиннее
Из [280]:
a b c bools
7 Правда Правда Правда Правда
Выполнение запроса
() DataFrame.query () с использованием numexpr немного быстрее, чем Python для
большие рамки.
Примечание
Вы увидите только преимущества в производительности при использовании двигателя numexpr с DataFrame.query () , если в вашем фрейме больше примерно 200 000
ряды.
Этот график был создан с использованием DataFrame с 3 столбцами, каждый из которых содержит
значения с плавающей запятой, сгенерированные с использованием numpy.random.randn () .
Дубликаты данных
Если вы хотите идентифицировать и удалить повторяющиеся строки в DataFrame, есть
два метода, которые помогут: дублированных и drop_duplicates .Каждый
принимает в качестве аргумента столбцы, используемые для идентификации повторяющихся строк.
duplicated возвращает логический вектор, длина которого равна количеству строк и указывает, дублируется ли строка.
drop_duplicates удаляет повторяющиеся строки.
По умолчанию первая наблюдаемая строка повторяющегося набора считается уникальной, но
у каждого метода есть параметр keep , указывающий целевые объекты, которые необходимо сохранить.
keep = 'first' (по умолчанию): отметить / удалить дубликаты, кроме первого вхождения.
keep = 'last' : отметить / удалить дубликаты, кроме последнего вхождения.
keep = False : отметить / удалить все дубликаты.
В [281]: df2 = pd.DataFrame ({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
.....: 'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'],
.....: 'c': np.random.randn (7)})
.....:
В [282]: df2
Из [282]:
а б в
0 один x -1.067137
1 один год 0,309500
2 два x -0,21 · 1056
3 два года -1.842023
4 два х -0,3
5 три x -1.964475
6 четыре x 1,298329
В [283]: df2.duplicated ('a')
Из [283]:
0 ложь
1 Верно
2 ложно
3 Верно
4 Верно
5 Неверно
6 Ложь
dtype: bool
В [284]: df2.duplicated ('a', keep = 'last')
Из [284]:
0 Верно
1 ложь
2 Верно
3 Верно
4 ложь
5 Неверно
6 ложь
dtype: bool
В [285]: df2.дублированный ('a', keep = False)
Из [285]:
0 Верно
1 Верно
2 Верно
3 Верно
4 Верно
5 Неверно
6 ложь
dtype: bool
В [286]: df2.drop_duplicates ('a')
Из [286]:
а б в
0 один x -1.067137
2 два x -0,21 · 1056
5 три x -1.964475
6 четыре x 1,298329
В [287]: df2.drop_duplicates ('a', keep = 'last')
Из [287]:
а б в
1 один год 0,309500
4 два х -0,3
5 три x -1.964475
6 четыре x 1,298329
В [288]: df2.drop_duplicates ('a', keep = False)
Из [288]:
а б в
5 три х -1.964475
6 четыре x 1,298329
Также вы можете передать список столбцов для выявления дубликатов.
В [289]: df2.duplicated (['a', 'b'])
Из [289]:
0 ложь
1 ложь
2 ложно
3 ложь
4 Верно
5 Неверно
6 ложь
dtype: bool
В [290]: df2.drop_duplicates (['a', 'b'])
Из [290]:
а б в
0 один x -1.067137
1 один год 0,309500
2 два x -0,21 · 1056
3 два года -1.842023
5 три x -1.964475
6 четыре x 1,298329
Чтобы удалить дубликаты по значению индекса, используйте индекс .продублируйте , затем выполните нарезку.
Тот же набор опций доступен для параметра keep .
В [291]: df3 = pd.DataFrame ({'a': np.arange (6),
.....: 'b': np.random.randn (6)},
.....: index = ['a', 'a', 'b', 'c', 'b', 'a'])
.....:
В [292]: df3
Из [292]:
а б
а 0 1,440455
а 1 2.456086
б 2 1.038402
в 3 -0,894409
б 4 0,683536
а 5 3,082764
В [293]: df3.index.duplicated ()
Выход [293]: массив ([Ложь, Истина, Ложь, Ложь, Истина, Истина])
В [294]: df3 [~ df3.index.duplicated ()]
Из [294]:
а б
а 0 1,440455
б 2 1.038402
в 3 -0,894409
В [295]: df3 [~ df3.index.duplicated (keep = 'last')]
Из [295]:
а б
в 3 -0,894409
б 4 0,683536
а 5 3,082764
В [296]: df3 [~ df3.index.duplicated (keep = False)]
Из [296]:
а б
в 3 -0,894409
Словарно-подобный
get () метод Каждый из Series или DataFrame имеет метод get , который может возвращать
значение по умолчанию.
В [297]: s = pd.Серии ([1, 2, 3], index = ['a', 'b', 'c'])
В [298]: s.get ('a') # эквивалентно s ['a']
Из [298]: 1
В [299]: s.get ('x', по умолчанию = -1)
Вых [299]: -1
Поиск значений по индексам / меткам столбцов
Иногда требуется извлечь набор значений из последовательности меток строк.
и метки столбцов, это может быть достигнуто с помощью pandas.factorize и индексации NumPy.
Например:
В [300]: df = pd.DataFrame ({'col': ["A", "A", "B", "B"],
.....: 'A': [80, 23, np.нан, 22],
.....: 'B': [80, 55, 76, 67]})
.....:
В [301]: df
Из [301]:
столбец A B
0 А 80,0 80
1 А 23,0 55
2 Б NaN 76
3 В 22,0 67
В [302]: idx, cols = pd.factorize (df ['col'])
В [303]: df.reindex (cols, axis = 1) .to_numpy () [np.arange (len (df)), idx]
Out [303]: массив ([80., 23., 76., 67.])
Ранее этого можно было достичь с помощью специального метода DataFrame.lookup который устарел в версии 1.2.0.
Объекты индекса
Класс pandas Index и его подклассы можно рассматривать как
реализация упорядоченного мультимножества .Дубликаты разрешены. Однако, если вы попробуете
для преобразования объекта Index с повторяющимися записями в установить , будет возбуждено исключение.
Index также обеспечивает инфраструктуру, необходимую для
поиск, выравнивание данных и переиндексация. Самый простой способ создать Индекс напрямую должен передать список или другую последовательность в Индекс :
В [304]: index = pd.Index (['e', 'd', 'a', 'b'])
В [305]: индекс
Out [305]: индекс (['e', 'd', 'a', 'b'], dtype = 'object')
В [306]: 'd' в индексе
Out [306]: Верно
Вы также можете передать имя , которое будет сохранено в индексе:
В [307]: index = pd.Индекс (['e', 'd', 'a', 'b'], name = 'something')
В [308]: index.name
Out [308]: 'что-то'
Имя, если оно задано, будет отображаться на дисплее консоли:
В [309]: index = pd.Index (list (range (5)), name = 'rows')
В [310]: columns = pd.Index (['A', 'B', 'C'], name = 'cols')
В [311]: df = pd.DataFrame (np.random.randn (5, 3), index = index, columns = columns)
В [312]: df
Из [312]:
столбцы A B C
ряды
0 1,295989 -1,051694 1,340429
1-2.366110 0,428241 0,387275
2 0,433306 0,929548 0,278094
3 2,154730 -0,315628 0,264223
4 1,126818 1,132290 -0,353310
В [313]: df ['A']
Из [313]:
ряды
0 1,295989
1 -2,366110
2 0,433306
3 2,154730
4 1,126818
Имя: A, dtype: float64
Задать операции над индексными объектами
Двумя основными операциями являются объединение и пересечение .
Разница предоставляется с помощью метода .difference () .
В [324]: a = pd.Индекс (['c', 'b', 'a'])
В [325]: b = pd.Index (['c', 'e', 'd'])
В [326]: а. Разница (б)
Out [326]: индекс (['a', 'b'], dtype = 'object')
Также доступна операция symric_difference , которая возвращает элементы
которые появляются либо в idx1 , либо в idx2 , но не в обоих. Это
эквивалентно индексу, созданному idx1.difference (idx2) .union (idx2.difference (idx1)) ,
с дубликатами сброшены.
В [327]: idx1 = pd.Index ([1, 2, 3, 4])
В [328]: idx2 = pd.Указатель ([2, 3, 4, 5])
В [329]: idx1.symmetric_difference (idx2)
Выход [329]: Int64Index ([1, 5], dtype = 'int64')
Примечание
Индекс, полученный в результате операции над множеством, будет отсортирован в порядке возрастания.
При выполнении Index.union () между индексами с разными типами данных индексы
должен быть приведен к общему типу dtype. Обычно, хотя и не всегда, это объект dtype. В
Исключением является объединение целочисленных данных и данных с плавающей запятой. В этом случае
целочисленные значения преобразуются в число с плавающей запятой
В [330]: idx1 = pd.Индекс ([0, 1, 2])
В [331]: idx2 = pd.Index ([0.5, 1.5])
В [332]: idx1.union (idx2)
Выход [332]: Float64Index ([0.0, 0.5, 1.0, 1.5, 2.0], dtype = 'float64')
Отсутствующие значения
Важно
Несмотря на то, что индекс может содержать пропущенные значения ( NaN ), этого следует избегать
если вы не хотите неожиданных результатов. Например, некоторые операции
неявно исключить отсутствующие значения.
Index.fillna заполняет пропущенные значения указанным скалярным значением.
В [333]: idx1 = pd.Index ([1, np.nan, 3, 4])
В [334]: idx1
Выход [334]: Float64Index ([1.0, nan, 3.0, 4.0], dtype = 'float64')
В [335]: idx1.fillna (2)
Выход [335]: Float64Index ([1.0, 2.0, 3.0, 4.0], dtype = 'float64')
В [336]: idx2 = pd.DatetimeIndex ([pd.Timestamp ('2011-01-01'),
.....: pd.NaT,
.....: pd.Timestamp ('2011-01-03')])
.....:
В [337]: idx2
Выход [337]: DatetimeIndex (['2011-01-01', 'NaT', '2011-01-03'], dtype = 'datetime64 [ns]', freq = None)
В [338]: idx2.fillna (pd.Timestamp ('2011-01-02'))
Выход [338]: DatetimeIndex (['2011-01-01', '2011-01-02', '2011-01-03'], dtype = 'datetime64 [ns]', freq = None)
Установить / сбросить индекс
Иногда вы загружаете или создаете набор данных в DataFrame и хотите
добавить индекс после того, как вы это уже сделали. Есть пара разных
способами.
Установить индекс
DataFrame имеет метод set_index () , который принимает имя столбца
(для обычного индекса ) или списка имен столбцов (для MultiIndex ).Чтобы создать новый переиндексированный фрейм данных:
В [339]: данные
Из [339]:
а б в г
0 бар один z 1,0
1 бар два и 2,0
2 фу один x 3,0
3 foo two w 4.0
В [340]: indexed1 = data.set_index ('c')
В [341]: indexed1
Из [341]:
а б г
c
z bar один 1.0
у бар два 2,0
x foo one 3.0
w foo two 4.0
В [342]: indexed2 = data.set_index (['a', 'b'])
В [343]: indexed2
Из [343]:
CD
а б
bar one z 1.0
два года 2,0
foo one x 3.0
два w 4.0
Параметр добавить ключевое слово позволяет сохранить существующий индекс и добавить
данные столбцы в MultiIndex:
В [344]: frame = data.set_index ('c', drop = False)
В [345]: frame = frame.set_index (['a', 'b'], append = True)
В [346]: кадр
Из [346]:
CD
такси
z bar one z 1.0
y бар два y 2,0
х фу один х 3,0
w foo two w 4.0
Другие параметры в set_index позволяют не отбрасывать столбцы индекса или добавлять
индекс на месте (без создания нового объекта):
В [347]: данные.set_index ('c', drop = ложь)
Из [347]:
а б в г
c
z bar one z 1.0
y бар два y 2,0
х фу один х 3,0
w foo two w 4.0
В [348]: data.set_index (['a', 'b'], inplace = True)
В [349]: данные
Из [349]:
CD
а б
bar one z 1.0
два года 2,0
foo one x 3.0
два w 4.0
Сбросить индекс
Для удобства в DataFrame есть новая функция, которая называется reset_index () , который передает значения индекса в
DataFrame и задает простой целочисленный индекс.Это обратная операция для set_index () .
В [350]: данные
Из [350]:
CD
а б
bar one z 1.0
два года 2,0
foo one x 3.0
два w 4.0
В [351]: data.reset_index ()
Из [351]:
а б в г
0 бар один z 1,0
1 бар два и 2,0
2 фу один x 3,0
3 foo two w 4.0
Вывод больше похож на таблицу SQL или массив записей. Имена для
столбцы, полученные из индекса, хранятся в атрибуте names .
Вы можете использовать ключевое слово level , чтобы удалить только часть индекса:
В [352]: рамка
Из [352]:
CD
такси
z bar one z 1.0
y бар два y 2,0
х фу один х 3,0
w foo two w 4.0
В [353]: frame.reset_index (level = 1)
Из [353]:
а в г
в б
z одна полоса z 1,0
y два бара y 2,0
х один фу х 3,0
ш два фу ш 4.0
reset_index принимает необязательный параметр drop , который, если true, просто
отбрасывает индекс вместо того, чтобы помещать значения индекса в столбцы DataFrame.
Добавление специального индекса
Если вы создаете индекс самостоятельно, вы можете просто назначить его полю index :
Возврат просмотра по сравнению с копией
При установке значений в объекте pandas необходимо соблюдать осторожность, чтобы избежать того, что называется Цепная индексация . Вот пример.
В [354]: dfmi = pd.DataFrame ([список ('abcd'),
.....: list ('efgh'),
.....: список ('ijkl'),
.....: list ('mnop')],
.....: columns = pd.MultiIndex.from_product ([['один', 'два'],
.....: ['первая секунда']]))
.....:
В [355]: dfmi
Из [355]:
один два
первая секунда первая секунда
0 а б в г
1 e f g h
2 я дж к л
3 мес.
Сравните эти два метода доступа:
В [356]: dfmi ['один'] ['второй']
Из [356]:
0 б
1 ж
2 Дж
3 п
Имя: второй, dtype: объект
В [357]: dfmi.loc [:, ('один', 'второй')]
Из [357]:
0 б
1 ж
2 Дж
3 п
Имя: (один, второй), dtype: object
Они оба дают одинаковые результаты, так что вы должны использовать? Поучительно разобраться в порядке
операций над ними и почему метод 2 ( .loc ) намного предпочтительнее, чем метод 1 (связанный [] ).
dfmi ['one'] выбирает первый уровень столбцов и возвращает DataFrame, который имеет одиночный индекс.
Затем другая операция Python dfmi_with_one ['second'] выбирает серию с индексом 'second' .На это указывает переменная dfmi_with_one , потому что pandas видит эти операции как отдельные события.
например отдельные вызовы к __getitem__ , поэтому он должен рассматривать их как линейные операции, они происходят одна за другой.
Сравните это с df.loc [:, ('one', 'second')] , который передает вложенный кортеж (slice (None), ('one', 'second')) в один вызов к __getitem__ . Это позволяет пандам справляться с этим как с единым целым. Кроме того, этот порядок операций может быть значительно
быстрее и позволяет при желании индексировать обе оси .
Почему не удается присвоение при использовании цепной индексации?
Проблема в предыдущем разделе связана только с производительностью. Что с
предупреждение SettingWithCopy ? Мы не используем , как правило, предупреждаем, когда
вы делаете что-то, что может стоить несколько дополнительных миллисекунд!
Но оказывается, что присвоение продукту цепной индексации
по своей сути непредсказуемые результаты. Чтобы убедиться в этом, подумайте о том, как Python
интерпретатор выполняет этот код:
dfmi.loc [:, ('один', 'второй')] = значение
# становится
dfmi.loc .__ setitem __ ((фрагмент (Нет), ('один', 'второй')), значение)
Но этот код обрабатывается иначе:
dfmi ['one'] ['second'] = значение
# становится
dfmi .__ getitem __ ('один') .__ setitem __ ('второй', значение)
Видите, что там __getitem__ ? Вне простых случаев очень сложно
предсказать, вернет ли он представление или копию (это зависит от макета памяти
массива, о котором pandas не дает никаких гарантий), и, следовательно, __setitem__ изменит dfmi или временный объект, который будет брошен
сразу после этого. Это то, что SettingWithCopy предупреждает вас
о!
Примечание
Вам может быть интересно, стоит ли нам беспокоиться о loc недвижимость в первом примере. Но dfmi.loc гарантированно будет dfmi сам с измененным поведением индексации, поэтому dfmi.loc .__ getitem__ / dfmi.loc .__ setitem__ работают с dfmi напрямую. Конечно, dfmi.loc .__ getitem __ (idx) может быть представлением или копией dfmi .
Иногда предупреждение SettingWithCopy появляется в тех случаях, когда нет
происходит очевидное цепное индексирование. Эти - ошибки, которые SettingWithCopy создан для ловли! панды, вероятно, пытается вас предупредить
что вы сделали это:
def do_something (df):
foo = df [['bar', 'baz']] # Является ли foo представлением? Копия? Никто не знает!
# ... здесь много строк ...
# Мы не знаем, изменит ли это df или нет!
foo ['quux'] = значение
return foo
Ура!
Порядок оценки имеет значение
При использовании цепной индексации порядок и тип операции индексации
частично определить, является ли результат срезом исходного объекта, или
копия среза.
pandas имеет SettingWithCopyWarning , потому что назначение копии
срез часто не является преднамеренным, а является ошибкой, вызванной цепным индексированием
возврат копии там, где ожидался фрагмент.
Если вы хотите, чтобы панды более или менее доверяли назначению
связанное выражение индексации, вы можете установить опцию mode.chained_assignment на одно из этих значений:
«предупредить» , значение по умолчанию, означает, что будет напечатано SettingWithCopyWarning .
«поднять» означает, что панды поднимут SettingWithCopyException вы должны иметь дело с.
Нет. полностью подавит предупреждения.
В [358]: dfb = pd.DataFrame ({'a': ['one', 'one', 'two',
.....: «три», «два», «один», «шесть»],
.....: 'c': np.arange (7)})
.....:
# Это покажет SettingWithCopyWarning
# но значения кадра будут установлены
В [359]: dfb ['c'] [dfb ['a'].str.startswith ('o')] = 42
Однако это работает с копией и не будет работать.
>>> pd.set_option ('mode.chained_assignment', 'предупреждать')
>>> dfb [dfb ['a']. str.startswith ('o')] ['c'] = 42
Отслеживание (последний вызов последний)
...
SettingWithCopyWarning:
Значение пытается быть установлено на копии фрагмента из DataFrame.
Попробуйте вместо этого использовать .loc [row_index, col_indexer] = value
Цепное назначение также может возникать в настройке в кадре смешанного типа dtype.
Примечание
Эти правила настройки применяются ко всем файлам .loc / .iloc .
Ниже приведен рекомендуемый метод доступа с использованием .loc для нескольких элементов (с использованием маски ) и одного элемента с использованием фиксированного индекса:
В [360]: dfc = pd.DataFrame ({'a': ['one', 'one', 'two',
.....: «три», «два», «один», «шесть»],
.....: 'c': np.arange (7)})
.....:
В [361]: dfd = dfc.copy ()
# Установка нескольких элементов с помощью маски
В [362]: маска = dfd ['a'].str.startswith ('о')
В [363]: dfd.loc [маска, 'c'] = 42
В [364]: dfd
Из [364]:
а с
0 один 42
1 один 42
2 два 2
3 три 3
4 два 4
5 один 42
6 шесть 6
# Установка одного элемента
В [365]: dfd = dfc.copy ()
В [366]: dfd.loc [2, 'a'] = 11
В [367]: dfd
Из [367]:
а с
0 один 0
1 один 1
2 11 2
3 три 3
4 два 4
5 один 5
6 шесть 6
Следующий может работать время от времени, но это не гарантируется, и поэтому его следует избегать:
В [368]: dfd = dfc.копия ()
В [369]: dfd ['a'] [2] = 111
В [370]: dfd
Из [370]:
а с
0 один 0
1 один 1
2 111 2
3 три 3
4 два 4
5 один 5
6 шесть 6
Наконец, следующий пример не будет работать вообще , поэтому его следует избегать:
>>> pd.set_option ('mode.chained_assignment', 'поднять')
>>> dfd.loc [0] ['a'] = 1111
Отслеживание (последний вызов последний)
...
SettingWithCopyException:
Значение пытается быть установлено на копии фрагмента из DataFrame.Попробуйте вместо этого использовать .loc [row_index, col_indexer] = value
Предупреждение
Предупреждения / исключения связанных назначений нацелены на то, чтобы проинформировать пользователя о возможном недопустимом
назначение. Возможны ложные срабатывания; ситуации, когда связанное назначение непреднамеренно
сообщил.
Целевые практики, поддерживающие культуру обучения
Наиболее эффективно, когда ученики ставят перед собой цели и следят за своими успехами, когда учителя могут создавать культуру, а не следовать предписывающим инструкциям.
Заставить учащихся понять, на каком этапе обучения они находятся, - сложная задача, которая может принести огромную выгоду, когда вы стремитесь создать школьную и классную культуру, в которой процветают совершенствование и рост. Итак, что могут сделать преподаватели, чтобы помочь учащимся заботиться о своем обучении и больше инвестировать в собственный успех? В частности, как учителя могут использовать оценки для мотивации учащихся, не обескураживая их и не создавая стереотипов?
Постановка целей - одна из многих форм использования данных с участием учащихся (Jimerson & Reames, 2015) - вовлекает учащихся в анализ результатов своей оценки, работу со своими учителями над установлением разумных, но амбициозных целей для улучшения и дальнейшее стимулирование их обучения. с частыми ссылками на эти цели.При правильном применении эти методы постановки целей оказывают значительное положительное влияние на результаты учащихся и школьную культуру (Leithwood & Sun, 2018; Moeller, Theiler, & Wu, 2012).
Неудивительно, что учащиеся успевают лучше, когда чувствуют, что контролируют свое обучение. Обзор исследований Роберта Марцано (2009), например, показывает, что постановка целей может дать учащимся успехи в обучении на 18–41 процентильный балл. Эффективные методы постановки целей помогают учащимся сосредоточиться на конкретных результатах, побуждают их искать академические вызовы и проясняют связь между непосредственными задачами и будущими достижениями в различных классах, предметных областях и учебных заведениях (Stronge & Grant, 2014). .Тем не менее, не любая форма постановки целей способствует обучению. Постановка цели должна включать четыре элемента задач, которые мотивируют учащихся: предоставление им возможностей для развития компетентности, предоставление им контроля или автономии, развитие интереса и изменение их восприятия собственных способностей (Usher & Kober, 2012). Без этих элементов положительные эффекты от постановки целей теряются.
Цели могут сильно отличаться от студента к студенту. Любой академический или поведенческий результат - от демонстрации навыков многозначного умножения до определения и правильного использования вопросительных слов до сокращения пропусков занятий и опозданий - может сыграть роль в достижении целей учащегося.Однако процесс постановки, мониторинга и анализа целей является ключом к успешной постановке целей.
Процесс постановки, мониторинга и анализа целей является ключевым в обеспечении успешной постановки целей.
В частности, исследование призывает учителей использовать постановку целей для развития ориентации на мастерство, когда ученики сосредотачиваются на преодолении личных проблем или обучении в максимально возможной степени, а не на подходах, основанных на достижении конкретных целей или избегании неудач (Wolters, 2004).Эти ориентации взаимозаменяемы: даже когда учителя не ставят цели напрямую, они выражают отношение и дают указания о том, как следует ставить и интерпретировать цели (Marsh, Farrell, & Bertrand, 2014). И, как и любой элемент школьной культуры, отношение учителей в значительной степени зависит от того, как остальная часть школьной системы думает об использовании данных и как администраторы ожидают от учителей интерпретации результатов оценки (Schildkamp & Lai, 2013). Таким образом, изолированная постановка целей с гораздо меньшей вероятностью будет успешной, чем когда она является частью культуры, где постановка целей является обычным явлением, цели связаны с обучением, а учащиеся продолжают ставить цели, меняя учителей и оценки.
Как исследователь в NWEA, я учился в тысячах школ и округов в Соединенных Штатах и во всем мире, которые используют нашу оценку роста MAP, чтобы помочь учащимся понять, что они знают, и стремиться узнать больше. История одной из этих систем, которую в этой статье я называю Уолнат-Хиллз, иллюстрирует, как акцент на постановке целей при обеспечении широкой автономии учителя позволяет ориентации на мастерство процветать и оказывает значительное влияние на школьную культуру.
От поручения к владению
В течение нескольких лет Уолнат-Хиллз, пригородный район среднего размера на Среднем Западе США, использовал оценку роста MAP Growth от NWEA для измерения успеваемости учащихся. Кроме того, в классах по всему округу учителя и ученики внедрили основанную на исследованиях модель постановки целей, в которой они предпринимают конкретные шаги для обсуждения целей, постановки новых и определения пути обучения для их достижения; округ связал этот процесс постановки целей со своей более широкой стратегией индивидуального обучения.Преднамеренный характер этого процесса в сочетании с очевидным высоким уровнем поддержки со стороны округа и набором сильных культурных ожиданий в отношении учащихся, учителей и администраторов делают его интересным примером для понимания того, как сделать постановку целей частью организационной работы школы. культура.
Однако работа началась медленно. Сначала округ требовал, чтобы учителя использовали одни и те же рабочие листы для постановки целей в разных классах, что сделало процесс особенно трудным для понимания младшими школьниками.И хотя не было проблем с участием учащихся в процессе постановки целей, большинство школ отводили время для этого процесса только в дни после основных тестов. Между тестами учителя редко использовали формирующие данные, чтобы помочь ученикам определить свои цели, и, что, возможно, наиболее важно, они редко связывались с учениками относительно их целей.
Тем не менее, учителя твердо придерживались фундаментальных ценностей программы: индивидуального обучения, формирующего оценивания и ответственности учащихся за обучение.Со временем они нашли способы адаптировать модель к своим потребностям, создав ряд более гибких, ориентированных на класс практик постановки целей, которые, хотя и несколько различались от учителя к учителю, сохранили дух и исследовательскую ДНК, которая имела стимулировало принятие исходной модели.
Например, когда стало очевидно, что ее ученики детского сада и 1-го класса не понимают предписанных рабочих листов, Лесли (все имена являются псевдонимами) попыталась создать свои собственные рабочие листы.Это было улучшением, но она все еще чувствовала, «как будто некоторые из моих детей проделывали определенные шаги» при постановке целей, не понимая, почему они это делают. Поэтому, чтобы сделать процесс более конкретным, она решила сосредоточиться на объяснении актуальности целей в повседневной жизни, используя понятный студентам язык и разбивая данные оценки на части, которые имели для них смысл. Со временем, вспоминала она, ее ученики постепенно привыкли говорить и ставить цели обучения.
Точно так же Кассандра, учительница средней школы, впервые познакомилась со стратегией постановки целей округа через серию семинаров по профессиональному развитию, и сразу поняла, что ей придется адаптировать модель. По ее словам, подход был «очень сложным», и это происходило только вместе с окнами тестирования. Поэтому она обратилась к передовому опыту исследования постановки целей взрослыми, чтобы понять, как это можно применить к ее ученикам. «Она должна быть очень простой, целевой, краткосрочной и периодической, - заключила она.Применяя эти изменения и ища регулярные данные, относящиеся к жизни студентов, Кассандра создала подходящую для возраста практику постановки целей, направленную на улучшение посещаемости, учебного поведения и успеваемости учащихся.
Подобно Лесли и Кассандре, другие учителя в Уолнат-Хиллз теперь используют обычные студенческие конференции, поощряют участие учеников в постановке целей и контрольных точек и полагаются на различные формы оценочных данных, включая графику и другие визуальные представления, чтобы держать цели учеников в центре внимания. свои классы.Эти учителя увидели преимущества постановки целей через модель и попытались свести ее к основным элементам. Сделав беседы по постановке целей простыми, целенаправленными и краткосрочными, сделало их частью повседневной учебной жизни учителей и учеников, а не просто очередной реформой, предписанной округом.
Выполнение постановки задач
Хотя все учителя, которых я наблюдал в Уолнат-Хиллз, использовали несколько иной подход к постановке целей, их общие практики рисуют картину органичного и динамичного процесса, который поддерживает последовательность для учеников от детского сада до выпуска:
Ранний старт. В Walnut Hills постановка целей начинается еще в детском саду. Поскольку эти ученики могут быть не готовы сначала думать об индивидуальных академических целях, учителя начинают с общеклассных целей в отношении поведения и развития навыков. Затем они переходят к постановке простых индивидуальных целей, таких как выучить набор букв или потратить определенное количество времени на выполнение задачи. В процессе постановки целей для своего класса и для себя маленькие дети учатся понимать, что такое цель и как она способствует обучению.
Однако для учащихся более важным, чем суть целей, является сам процесс. «Мы говорим о том, почему мы ставим цель, какова ее цель, как она направляет ваше обучение и как вы гордитесь, когда достигли этой цели», - говорит Лесли. По ее мнению, цель постановки целей с самыми маленькими детьми - предоставить набор норм и ожиданий, которые подготовят их к постановке конкретных и измеримых целей в более поздних классах. Джоди, учительница младших классов в другой школе, поддержала эту идею: «Мы видим большой успех в том, что начинаем в столь раннем возрасте, а не в старших классах.. . они могут начать делать гораздо больше самостоятельно ».
Делайте это часто. Каждый из учителей, с которыми я разговаривал в Уолнат-Хиллз, вовлекал своих учеников в постановку краткосрочных целей, обычно длятся не более четырех-шести недель. Краткосрочные цели предполагали частые проверки со студентами, по крайней мере, еженедельно, если не ежедневно. В свою очередь, эти проверки позволили часто пересматривать цели в зависимости от успеваемости ученика, не давая ученикам чувствовать себя обескураженными: с несколькими возможностями наблюдать за прогрессом, еще не достигнутая цель становится целью, которая может быть достигнута в будущем с дополнительными усилиями.
Процесс постановки целей часто начинается с конференции, на которой студенты отвечают на вопросы, подобные тем, которые использовала Карен: «Какая цель является подходящей?» и «Почему мы думаем, что это подходящая цель для вас?» Во время регулярных проверок учителя обсуждают со студентами текущую работу, ее связь с их целями и стратегии, которые они используют для улучшения обучения. Конференция по постановке целей в конце процесса способствует размышлениям над обучением, отвечая на такие вопросы Карен: «Что вы замечаете в своей работе с начала до сих пор?» и "Как ты себя чувствуешь, как ты вырос?"
Увеличение частоты проверок для постановки целей может потребовать расслабления более сложных или затяжных процедур в пользу быстрых разговоров, сосредоточенных на нескольких ключевых вопросах.Учителя в Уолнат-Хиллз отмечают, что все, что они потеряли, отойдя от исходной структурированной модели к чему-то более гетерогенному, более чем компенсируется возможностью, которую они теперь имеют, укреплять установку на рост, практиковать академические беседы и поддерживать регулярный индивидуальный контакт с каждый студент.
Сделайте это наглядным.
Учителя по постановке целей полагаются на различные визуальные инструменты и артефакты, которые помогают укрепить свою культуру постановки целей.На уровне всего класса они могут включать в себя диаграммы привязки, указывающие на цели класса, или графики, показывающие прогресс учащегося в достижении определенных целей обучения или целей оценки (без указания имен отдельных учащихся). На индивидуальном уровне это могут быть записные книжки с данными, персонализированные планы обучения (физические или цифровые, которыми можно поделиться с родителями и другими учителями) и рабочие листы для постановки целей.
Рабочие листы, созданные учителем, которые я наблюдал, имеют много общего:
- Во-первых, они сосредотачиваются на определении цели и установлении твердой конечной даты для ее достижения.Если учащиеся имеют опыт работы с целями SMART (конкретными, измеримыми, достижимыми, актуальными и привязанными к срокам), рабочие листы могут ссылаться на эти рекомендации.
- Во-вторых, в рабочих листах учащихся просят описать действенные шаги для достижения своей цели. Сюда может входить определенное количество занятий по математике в неделю, определенное количество страниц, которые нужно читать каждую ночь, или даже набор поведения, например, приходить в школу вовремя. Эти шаги позволяют студентам по-настоящему адаптировать цель к собственному обучению.Как отмечает Карла: «У них есть свое представление, они проводят инвентаризацию стилей обучения, они оценивают свои результаты» и используют другие инструменты, чтобы определить шаги, которые для них достижимы.
- Наконец, артефакты постановки целей просят учащихся описать свидетельства того, что они достигли своей цели. Это может включать размышления, эссе или другие рабочие продукты, а также отзывы учителей или сверстников. Все учителя, с которыми я разговаривал, подчеркивали, что результаты тестов представляют собой лишь часть более широкого набора свидетельств обучения, но они могут поддержать студентов, мотивированных видением их прогресса по шкале, при условии, что эти результаты конкретным образом связаны с целями обучения.Требуя свидетельства об обучении, цель этих преподавателей заключалась в том, чтобы предоставить несколько способов, с помощью которых учащиеся могли бы продемонстрировать свои собственные успехи способами, которые их мотивировали.
Создайте личную значимость. Несколько учителей, например Карла, отметили, что начало разговора о постановке целей вокруг личных целей дает возможность продемонстрировать преимущества постановки целей:
Я заставляю их думать о чем-то, с чем они борются, будь то домашнее задание или работа по дому, или что-то еще.А потом мы начинаем спрашивать: «Хорошо, что мы можем сделать, чтобы это исправить?» Итак, мы поставили цель вокруг этого, а затем это подводит нас к следующему: «А теперь давайте сосредоточимся на школьном аспекте. С какими проблемами вы боретесь в школе? "
Многие учителя ссылались на цели, которые они поставили в своей личной жизни, как на возможность сделать постановку целей более актуальной. Для Нэнси беседа о постановке целей начинается со слов: «Кем вы как человек хотите быть? А в какой области с академической точки зрения вы хотите, чтобы мы вам помогли? "
Потребность в личной значимости также подчеркивает важность построения отношений в обеспечении успеха в постановке целей.По словам Керри, общение со студентами обеспечивает «большую отдачу от вложенных средств», позволяя как налаживать отношения со студентами, так и изучать их конкретные индивидуальные потребности в обучении. Даже когда разговор о постановке целей сосредоточен на улучшении оценки или достижении произвольной вехи, разговоры о постановке целей могут помочь учащимся осознать, как сказала Кассандра, «что у них есть некоторый контроль над своей оценкой». Однако ни один из учителей, с которыми я разговаривал, не использовал результативность как фактор оценки учеников.Вместо этого постановка целей служила инструментом для более четкой иллюстрации взаимосвязи между учебной деятельностью, успеваемостью и итоговой оценкой, поощряя учащегося и учителя к разговору об успеваемости до того, как придут табели успеваемости.
Центр по выбору студентов. Наконец, учащиеся причастны к обучению в максимальной степени, когда учащиеся ощущают свободу выбора и свободу выбора. Учителя, устанавливающие цели, выступают в роли руководителей обучения: разбивая большие цели на области навыков, предлагая цели на основе навыков, которые не хватает учащимся, и намечают шаги, необходимые для достижения конкретной цели, но в конечном итоге оставляя выбор самой цели в руках из студентов.Даже для молодых студентов, которые менее способны к саморефлексии, выбор внешнего вида является ключевым. Лесли сказал: «Я могу поставить им два или три гола. Затем я позволяю им выбирать [даже если] вы по-прежнему обеспечиваете им цель ».
Эти ранние выборы укрепляют культуру выбора учеников, которая окупается, когда ученики становятся более самосознательными, как объяснила Карла: «Я как бы даю им цель, так сказать, но в конце концов они начнут ставить свою собственную. . . вы на самом деле садитесь и слушаете ребенка, у которого есть цель, которую он хочет достичь, и помогаете ему понять, как ее достичь, потому что именно в этом он и застрял.«В подобных беседах по постановке целей учитель по-прежнему играет активную роль, обеспечивая конкретные, измеримые и связанные с обучением цели. Они также играют важную постоянную роль в праздновании достижений, способствуя настойчивости и внушая уверенность. Однако в конечном итоге цель постановки целей как общешкольной культурной практики состоит в том, чтобы обеспечить постепенный переход к самодостаточной постановке целей. Карен сказала: «Я думаю, что лучшие конференции по постановке целей - это те, на которых студенты могут взглянуть на свою работу, взглянуть на метрическую часть и фактически сказать:« Знаете что? Я еще не там », но [также, чтобы признать]« Я могу быть там.Но это то, что мне нужно сделать ».
Собираем все вместе
Установление целей учащимися и для учащихся помогает сформировать клей, который связывает воедино оценочные мероприятия. Посредством постановки целей учащиеся развивают навыки, позволяющие осмыслить свое обучение и превратить понимание своих текущих знаний и навыков в стремление узнать больше. В классах, демонстрирующих владение учащимся процессом обучения: «Учащиеся знают, куда они идут, где они находятся и как сократить разрыв» (Chan et al., 2014, с. 112). Практика постановки целей, которую я наблюдал среди учителей в Уолнат-Хиллз, сосредоточена на выявлении этих трех точек соприкосновения, регулярном возвращении к ним и предоставлении ученикам возможности играть равную роль в определении того, что они будут изучать, и процессов, которые приведут их к этому.
Постановка целей, осуществляемая учащимися посредством разнообразия стилей и подходов обучения, является важной стратегией для любой школы или округа, стремящейся создать культуру обучения на протяжении всей жизни.
Рик Стиггинс (Rick Stiggins, 2002) называет лучшее формирующее оценивание «оценкой для обучения», источником комфортной мотивации студентов для реализации своих амбиций, а не источником беспокойства и страха. В сочетании с такой оценкой эффективная постановка целей вовлекает учащихся в понимание того, как измеряется обучение, мириады способов его проявления, а также прямую взаимосвязь между тем, что изучается в школе, и тем, что учащиеся хотят от своей жизни. Постановка целей, осуществляемая учащимися посредством разнообразия стилей и подходов обучения, является важной стратегией для любой школы или округа, стремящейся создать культуру обучения на протяжении всей жизни.
Наиболее эффективные учителя моделируют поведение, которого они ожидают от своих учеников: они ставят перед собой цели, часто отслеживают прогресс в их достижении и размышляют о том, насколько их ежедневное обучение соответствует их целям. Однако администраторы также должны использовать пример своих учителей, чтобы поощрять более широкие организационные сдвиги, которые гарантируют, что учащиеся будут постоянно устанавливать цели между классами и школами, делая практику частью стандартной операционной процедуры округа.
Список литературы
Чан П.Э., Грэм-Дей К.Дж., Ресса В.А., Питерс М.Т. и Конрад М. (2014). Помимо участия: поощрение участия учащихся в обучении в классах. Вмешательство в школе и поликлинике , 50 (2), 105-113.
Jimerson, J.B. & Reames, E. (2015). Использование данных с участием студентов: создание доказательной базы. Журнал изменений в образовании , 16 (3), 281-304.
Лейтвуд, К.И Солнце, Дж. (2018). Академическая культура: многообещающий посредник влияния школьных руководителей на обучение учащихся. Журнал управления образованием , 56 (3).
Марш, Дж. А., Фаррелл, К. С., Бертран, М. (2014). Подотчетность вниз: как учителя средней школы вовлекают учеников в использование данных. Политика в области образования , 30 (2), 243-280.
Марцано, Р.Дж. (2009). Разработка и преподавание целей и задач обучения: эффективные стратегии в классе .Денвер, Колорадо: Исследовательская лаборатория Марцано.
Мёллер, А.Дж., Тейлер, Дж. М., и Ву, К. (2012). Постановка целей и достижения учащихся: продольное исследование. Журнал современного языка , 96 (2), 153-169.
Шильдкамп, К. и Лай, М.К. (2013). Выводы и структура использования данных. У К. Шильдкампа, М.К. Лай и Л. Эрл (ред.), Принятие решений в образовании на основе данных: проблемы и возможности (стр. 177–191). Нидерланды: Спрингер.
Стиггинс, Р.J. (2002). Кризис оценивания: Отсутствие оценки для обучения . Дельта Фи Каппан , 83 (10), 758-765.
Stronge, J.H. И Грант, Л. (2014). Постановка цели достижений учащихся . Нью-Йорк: Тейлор и Фрэнсис.
Ашер, А. и Кобер, Н. (2012). Мотивация учащихся: недооцененная школьная реформа. Вашингтон, округ Колумбия: Центр образовательной политики.
Wolters, C.A. (2004). Развитие теории целей достижения: использование структур целей и ориентации целей для прогнозирования мотивации, познания и достижений учащихся. Журнал педагогической психологии , 96 (2), 236-250.
ЧЕЙС НОРДЕНГРЕН (chase.