Как вытащить картинку из PDF документа
Инструкция как достать картинки из PDF файла
Редактор позволяет вносить изменения в PDF-документы, а также извлечь изображение. Чтобы достать картинку из пдф, нет необходимости обладать специальными навыками. Вы сделаете все за считанные минуты! Следуйте инструкции ниже и получите качественный результат.
Шаг 1. Установите приложение
Чтобы сохранить картинку из PDF, скачайте программу с нашего сайта. После окончания загрузки дважды кликните на установочный файл. Во время инсталляции необходимо ознакомиться с пользовательским соглашением PDF Commander и принять его, указать папку или оставить ее по умолчанию, создать ярлык для быстрого доступа к программному обеспечению.
Скачать бесплатноШаг 2. Импортируйте документ
Запустите приложение и откройте необходимый документ. Вы можете выбрать соответствующее действие в стартовом меню софта или перетащить файл в программу.
Вы можете выбрать соответствующее действие в стартовом меню софта или перетащить файл в программу.
Вы сможете создать пустой ПДФ, конвертировать его в другие форматы или объединять файлы
Шаг 3. Извлеките изображение
Чтобы разобрать PDF на картинки, нажмите «Файл» — «Инструменты» — «Извлечь изображения». С помощью этой функции вы можете сразу извлечь все картинки из документа, открытого в данный момент. Выберите папку для фото, введите название файла и нажмите сохранить. Они будут экспортированы в формате BMP.
Вы можете выбрать функции для вырезания текста, сохранения страниц по отдельности, конвертации
Как вырезать картинку из пдф файла, если нужно извлечь только одно изображение? Перейдите на лист с нужным вам фото: используйте кнопки внизу страницы или в левой панели инструментов выберите «Миниатюры страниц».
Если вы знаете номер страницы, введите его внизу страницы
Чтобы извлечь картинку, кликните в верхнем меню на раздел «Редактор» и выберите действие «Кадрировать». Выделите фрагмент и обрежьте все лишнее. В меню «Миниатюры страниц» нажмите правой кнопкой мыши на лист с фото. Если необходимо, поверните фото. Нажмите «Экспорт страницы», укажите папку и введите название файла. Сохранение возможно в большинстве форматов: JPEG, PNG, BMP, GIF, TIFF.
Также изображение можно сохранить в PDF
Заключение
В этой статье мы рассказали, как из PDF вытащить картинку. Скачайте программу PDF Commander прямо сейчас. Она позволит редактировать любые пдф-файлы, конвертировать их в другие форматы, настраивать текст и изображения. Размещайте электронные подписи, готовые штампы, устанавливливайте защитный пароль, изменяйте метаданные и замазывайте текст! Также можно добавлять новые или удалять лишние страницы, делать заметки и закладки.
Как извлечь фотографии из PDF на iPhone, Android, Windows, Mac • Оки Доки
Есть множество причин, по которым PDF остается предпочтительным форматом документов. Будь то универсальная совместимость или повышенная безопасность за счет защиты паролем или возможность поддерживать исходный заданный макет файла, переносимый формат документа имеет явное преимущество перед другими форматами. Поскольку большинству из нас приходится иметь дело с PDF-файлами регулярно, мы часто сталкиваемся с ситуациями, когда приходится извлекать фотографии из PDF-документов. Зная, что этот процесс требует небольшого обходного пути, я подумал, что было бы здорово поделиться некоторыми полезными советами по легкому извлечению изображений из PDF-файлов на таких платформах, как macOS, Windows, Интернет, iOS и Android.
Извлечение фотографий из PDF-документов на macOS, Windows, iOS и Android
Возможно, вы хотите сохранить изображение в формате PDF на память.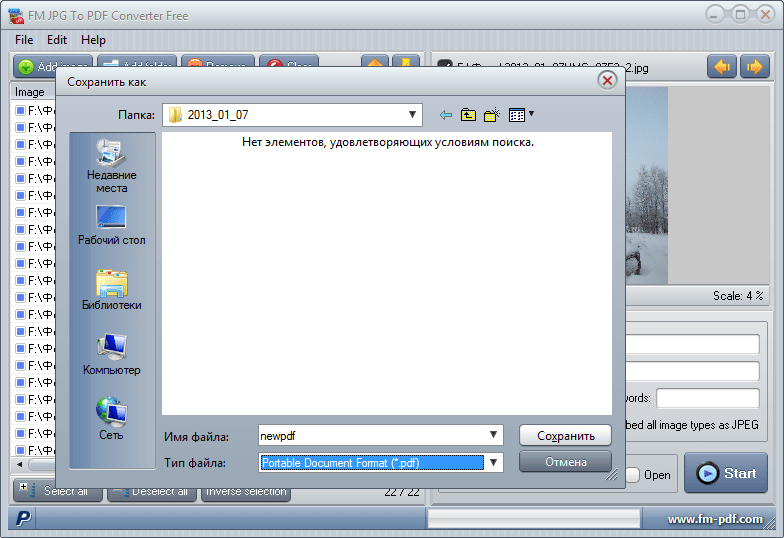 Возможно, вы хотите извлечь фотографию в формате PDF и сохранить ее в своей личной библиотеке, чтобы вы могли использовать ее в какой-то момент. Какой бы ни была ваша цель, есть несколько полезных инструментов, которые помогут выполнить вашу работу без каких-либо сбоев. С учетом сказанного, давайте начнем с руководства!
Возможно, вы хотите извлечь фотографию в формате PDF и сохранить ее в своей личной библиотеке, чтобы вы могли использовать ее в какой-то момент. Какой бы ни была ваша цель, есть несколько полезных инструментов, которые помогут выполнить вашу работу без каких-либо сбоев. С учетом сказанного, давайте начнем с руководства!
Извлечение фотографий из PDF-документов на Mac и ПК с Windows
Хотя существует несколько экстракторов изображений PDF, Adobe Acrobat Reader остается моим любимым инструментом для извлечения изображений из документов PDF на компьютере. Это доступно бесплатно и работает как положено.
Adobe Acrobat Reader поддерживает macOS и Windows. Что касается процесса, он одинаков для обеих операционных систем. Я собираюсь продемонстрировать шаги на моем Mac.
- Запустите Adobe Acrobat Reader на вашем компьютере. Затем нажмите «Мой компьютер» на боковой панели.
2. После этого нажмите Обзор.
3. Теперь перейдите к документу и откройте его в Adobe Acrobat Reader.
4. Затем щелкните фотографию и выберите опцию «Копировать изображение» в контекстном меню, которое появляется прямо над изображением.
5. Скопировав изображение, откройте другое приложение и вставьте его. В этом тесте я собираюсь вставить изображение в приложение Pages для Mac. Вот и все!
Получение фотографий из PDF-документов с помощью онлайн-инструмента
Что делать, если вы не хотите загружать приложение только для извлечения изображений из документов PDF, поскольку вам нужно делать это только время от времени? Что ж, существует довольно много надежных онлайн-инструментов, таких как iLovePDF, PDFКэнди, и PDF24 который может позволить вам легко извлекать фотографии из PDF-файлов.
Процесс извлечения фотографий из PDF-файлов в Интернете довольно прост и идентичен. Просто зайдите на свой любимый сайт и загрузите PDF-документ.
Затем найдите вариант для извлечения изображений, и все готово.
Извлечение изображений из PDF-документов на Android
Благодаря простому, но эффективному приложению «Smart Image Extractor» (свободный) получить изображение из PDF-документа довольно просто.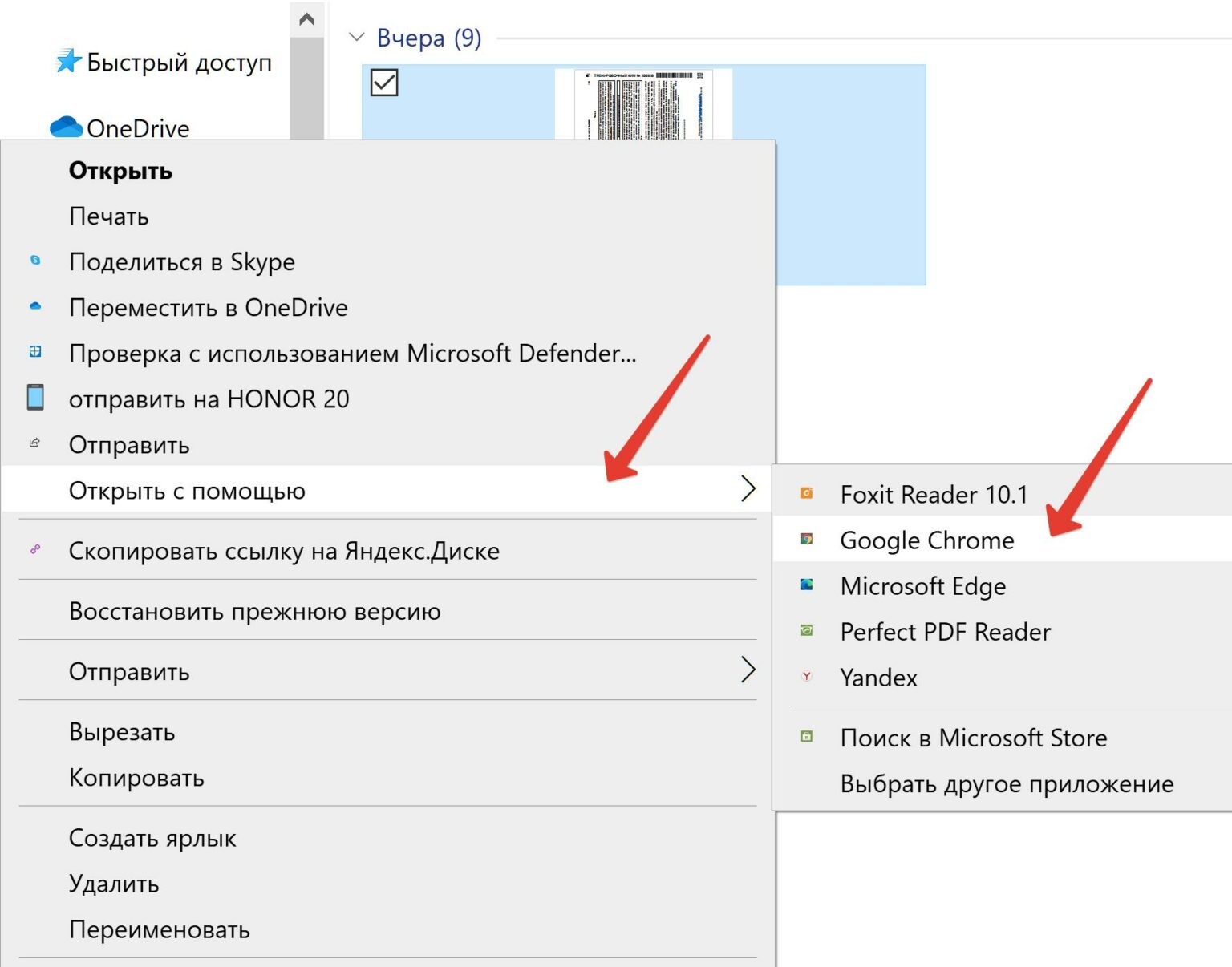 Приложение доступно бесплатно и поддерживает Android 4.4 и новее.
Приложение доступно бесплатно и поддерживает Android 4.4 и новее.
После того, как вы скачали приложение, запустите его. После этого выберите PDF-документ, изображение которого вы хотите извлечь, и нажмите на опцию «Извлечь изображения». Приложение мгновенно извлечет изображения и позволит вам сохранить их в нужном месте.
Извлечение изображений из PDF-документов на iOS и iPadOS
На iPhone и iPad лучше всего сделать снимок экрана с изображением, которое вы хотите сохранить, а затем использовать собственный инструмент обрезки фотографий, чтобы избавиться от ненужных частей.
Просто откройте PDF-файл на своем устройстве, а затем сделайте снимок экрана с расширением. Как только снимок экрана будет сделан, откройте его. После этого нажмите на опцию Edit.
Затем нажмите на инструмент обрезки. Затем используйте ручки, чтобы обрезать ненужные части изображения. Обязательно нажмите Готово, чтобы закончить. Поскольку весь процесс занимает не больше минуты, я не думаю, что он может показаться вам утомительным.
Извлечение изображений из PDF-документов с легкостью
Таким образом, вы можете сохранять изображения из PDF-документов на своем устройстве. Теперь, когда вы знаете, как работает этот трюк, максимально используйте его, чтобы легко извлекать фотографии всякий раз, когда в этом возникает необходимость. Также ознакомьтесь с нашими любимыми приложениями для редактирования фотографий, чтобы улучшить извлеченные изображения. Есть ли у вас отзывы, которыми вы можете поделиться с нами? Если да, не забудьте изложить это, поскольку мы всегда рады полезным предложениям.
Вставка содержимого PDF-файла в презентацию PowerPoint
Содержимое PDF-файла может понадобиться для вашей презентации, но извлечь его из PDF-файла может быть не так просто, как из других типов документов. Для этого существует два способа в зависимости от того, как вы хотите использовать содержимое PDF-файла:
-
Показ содержимого из PDF-файла на слайде Сфотографировать часть PDF-файла, которую вы хотите, и в документе.

-
Сохранение PDF-файла как поддерживающего документа для презентации. Вставьте весь PDF-файл в презентацию как объект, который можно открывать и просматривать во время проведения презентации.

Примечание: К сожалению, вставить содержимое PDF-файла при редактировании презентации в PowerPoint в Интернете. Для этого PowerPoint 2013 или более новой версии.
Вставка содержимого PDF-файла как рисунка
-
Откройте PDF-файл, изображение из который вы хотите вставить, а затем переключиться в PowerPoint.
Советы:
-
Не свертывайте окно PDF-файла и перед переходом к следующему этапу убедитесь, что это последнее открытое вами окно.
-
Убедитесь, что все, что вы хотите сделать в качестве изображения, отображается в окне PDF.
Для этого, возможно, потребуется уменьшить масштаб в этом окне.
-
-
В PowerPoint выберите слайд, на который вы хотите добавить содержимое, а затем на вкладке «Вставка» в группе «Изображения» нажмите кнопку «Снимок».
Примечание: В зависимости от размера окна кнопка Снимок может выглядеть по-разному.
Ваш PDF-файл должен быть представлен первым эскизом в списке Доступные окна.
-
Под эскизами выберите элемент Вырезка экрана. PowerPoint окно с PDF-файлом будет свернуто.
-
Когда ваш экран будет иметь белый «замятый» вид, а указатель перекрестья , перетащите указатель, чтобы нарисовать квадратик вокруг содержимого, которое вы хотите скрепить.
(Нажмите клавишу ESC, чтобы отменить вырезку экрана.)Когда вы прекратите перетаскивание, выбранная область появится на PowerPoint как рисунок. Вы можете изменять его размер, обрезать и форматировать, как вам необходимо: выберите рисунок и воспользуйтесь вкладкой Работа с рисунками > Формат.
 Для этого, возможно, потребуется уменьшить масштаб в этом окне.
Для этого, возможно, потребуется уменьшить масштаб в этом окне. (Нажмите клавишу ESC, чтобы отменить вырезку экрана.)
(Нажмите клавишу ESC, чтобы отменить вырезку экрана.)Вставка PDF-файла как объекта
-
Убедитесь, что PDF-файл, который вам нужно вставить, не открыт на компьютере.
-
В PowerPoint выберите слайд, на который вы хотите добавить файл, а затем выберите «Вставить > объект».
-
В окне Вставка объекта выберите команду Создать из файла, а затем укажите путь к PDF-файлу или нажмите кнопку Обзор, найдите PDF-файл и нажмите кнопку ОК.
В результате PDF-файл добавляется в файл презентации. При таком способе вставки качество PDF-файла снижается, но при просмотре или редактировании в обычном режиме вы можете открыть полный PDF-файл, дважды щелкнув изображение.
Примечание: Если при попытке вставить PDF-файл как объект появляется сообщение об ошибке, убедитесь, что PDF-файл не открыт.
Открытие PDF-файла из слайд-шоу
Чтобы открыть вставленный PDF-файл во время слайд-шоу, свяжите с ним действие.
-
В обычном режиме на слайде, содержащем PDF-файл, щелкните значок или изображение PDF-файла, а затем на вкладке Вставка в группе Ссылки нажмите кнопку Действие.
-
В поле Настройка действия выберите вкладку По щелчку мыши, если вы хотите открывать PDF-файл щелчком мыши, или вкладку По наведении указателя мыши, если вы хотите открывать его при наведении указателя на значок PDF-файла.
-
Выберите Действия объекта, а затем в списке — Открыть.
К началу страницы
Вставка векторного рисунка
Microsoft 365 подписчики могут вставлять в PowerPoint изображения в масштабируемой векторной графике (SVG#x1. Подробные сведения см. в видео «Изменение изображений в SVG-изображении в Office».
См. также
Сохранение презентаций PowerPoint в формате PDF
Вставка снимка или вырезки экрана
Извлечение изображений из PDF без передискретизации, в python? Ru Python
Как можно извлечь все изображения из PDF-документа, в собственном разрешении и в формате? (Значение extract tiff как tiff, jpeg как jpeg и т. Д. И без повторной выборки). Макет неважен, мне все равно, что исходное изображение находится на странице.
Д. И без повторной выборки). Макет неважен, мне все равно, что исходное изображение находится на странице.
Я использую python 2.7, но при необходимости могу использовать 3.x.
Часто в формате PDF изображение просто сохраняется как есть. Например, PDF с вставленным jpg будет иметь диапазон байтов где-то посередине, который при извлечении является допустимым файлом jpg. Вы можете использовать это, чтобы очень просто извлекать диапазоны байтов из PDF. Я писал об этом некоторое время назад, с примером кода: Извлечение JPG из PDF-файлов .
В Python с библиотеками PyPDF2 и Pillow это просто:
import PyPDF2 from PIL import Image if __name__ == '__main__': input1 = PyPDF2.PdfFileReader(open("input.pdf", "rb")) page0 = input1.getPage(0) xObject = page0['/Resources']['/XObject'].getObject() for obj in xObject: if xObject[obj]['/Subtype'] == '/Image': size = (xObject[obj]['/Width'], xObject[obj]['/Height']) data = xObject[obj]. getData() if xObject[obj]['/ColorSpace'] == '/DeviceRGB': mode = "RGB" else: mode = "P" if xObject[obj]['/Filter'] == '/FlateDecode': img = Image.frombytes(mode, size, data) img.save(obj[1:] + ".png") elif xObject[obj]['/Filter'] == '/DCTDecode': img = open(obj[1:] + ".jpg", "wb") img.write(data) img.close() elif xObject[obj]['/Filter'] == '/JPXDecode': img = open(obj[1:] + ".jp2", "wb") img.write(data) img.close()  getData() if xObject[obj]['/ColorSpace'] == '/DeviceRGB': mode = "RGB" else: mode = "P" if xObject[obj]['/Filter'] == '/FlateDecode': img = Image.frombytes(mode, size, data) img.save(obj[1:] + ".png") elif xObject[obj]['/Filter'] == '/DCTDecode': img = open(obj[1:] + ".jpg", "wb") img.write(data) img.close() elif xObject[obj]['/Filter'] == '/JPXDecode': img = open(obj[1:] + ".jp2", "wb") img.write(data) img.close()
getData() if xObject[obj]['/ColorSpace'] == '/DeviceRGB': mode = "RGB" else: mode = "P" if xObject[obj]['/Filter'] == '/FlateDecode': img = Image.frombytes(mode, size, data) img.save(obj[1:] + ".png") elif xObject[obj]['/Filter'] == '/DCTDecode': img = open(obj[1:] + ".jpg", "wb") img.write(data) img.close() elif xObject[obj]['/Filter'] == '/JPXDecode': img = open(obj[1:] + ".jp2", "wb") img.write(data) img.close()В Python с PyPDF2 для фильтра CCITTFaxDecode:
import PyPDF2 import struct """ Links: PDF format: http://www.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/pdf_reference_1-7.pdf CCITT Group 4: https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-T.6-198811-I!!PDF-E&type=items Extract images from pdf: http://stackoverflow.com/questions/2693820/extract-images-from-pdf-without-resampling-in-python Extract images coded with CCITTFaxDecode in .net: http://stackoverflow.com/questions/2641770/extracting-image-from-pdf-with-ccittfaxdecode-filter TIFF format and tags: http://www. awaresystems.be/imaging/tiff/faq.html """ def tiff_header_for_CCITT(width, height, img_size, CCITT_group=4): tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h' return struct.pack(tiff_header_struct, b'II', # Byte order indication: Little indian 42, # Version number (always 42) 8, # Offset to first IFD 8, # Number of tags in IFD 256, 4, 1, width, # ImageWidth, LONG, 1, width 257, 4, 1, height, # ImageLength, LONG, 1, lenght 258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1 259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding 262, 3, 1, 0, # Threshholding, SHORT, 1, 0 = WhiteIsZero 273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header 278, 4, 1, height, # RowsPerStrip, LONG, 1, lenght 279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image 0 # last IFD ) pdf_filename = 'scan.pdf' pdf_file = open(pdf_filename, 'rb') cond_scan_reader = PyPDF2.PdfFileReader(pdf_file) for i in range(0, cond_scan_reader.getNumPages()): page = cond_scan_reader. getPage(i) xObject = page['/Resources']['/XObject'].getObject() for obj in xObject: if xObject[obj]['/Subtype'] == '/Image': """ The CCITTFaxDecode filter decodes image data that has been encoded using either Group 3 or Group 4 CCITT facsimile (fax) encoding. CCITT encoding is designed to achieve efficient compression of monochrome (1 bit per pixel) image data at relatively low resolutions, and so is useful only for bitmap image data, not for color images, grayscale images, or general data. K < 0 --- Pure two-dimensional encoding (Group 4) K = 0 --- Pure one-dimensional encoding (Group 3, 1-D) K > 0 --- Mixed one- and two-dimensional encoding (Group 3, 2-D) """ if xObject[obj]['/Filter'] == '/CCITTFaxDecode': if xObject[obj]['/DecodeParms']['/K'] == -1: CCITT_group = 4 else: CCITT_group = 3 width = xObject[obj]['/Width'] height = xObject[obj]['/Height'] data = xObject[obj]._data # sorry, getData() does not work for CCITTFaxDecode img_size = len(data) tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group) img_name = obj[1:] + '. tiff' with open(img_name, 'wb') as img_file: img_file.write(tiff_header + data) # # import io # from PIL import Image # im = Image.open(io.BytesIO(tiff_header + data)) pdf_file.close() 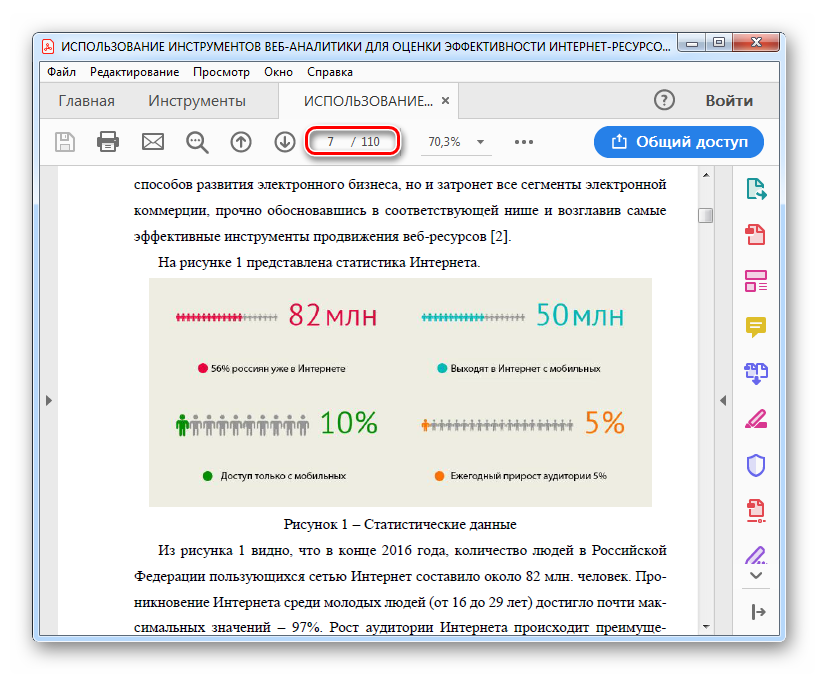 awaresystems.be/imaging/tiff/faq.html """ def tiff_header_for_CCITT(width, height, img_size, CCITT_group=4): tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h' return struct.pack(tiff_header_struct, b'II', # Byte order indication: Little indian 42, # Version number (always 42) 8, # Offset to first IFD 8, # Number of tags in IFD 256, 4, 1, width, # ImageWidth, LONG, 1, width 257, 4, 1, height, # ImageLength, LONG, 1, lenght 258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1 259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding 262, 3, 1, 0, # Threshholding, SHORT, 1, 0 = WhiteIsZero 273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header 278, 4, 1, height, # RowsPerStrip, LONG, 1, lenght 279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image 0 # last IFD ) pdf_filename = 'scan.pdf' pdf_file = open(pdf_filename, 'rb') cond_scan_reader = PyPDF2.PdfFileReader(pdf_file) for i in range(0, cond_scan_reader.getNumPages()): page = cond_scan_reader.
awaresystems.be/imaging/tiff/faq.html """ def tiff_header_for_CCITT(width, height, img_size, CCITT_group=4): tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h' return struct.pack(tiff_header_struct, b'II', # Byte order indication: Little indian 42, # Version number (always 42) 8, # Offset to first IFD 8, # Number of tags in IFD 256, 4, 1, width, # ImageWidth, LONG, 1, width 257, 4, 1, height, # ImageLength, LONG, 1, lenght 258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1 259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding 262, 3, 1, 0, # Threshholding, SHORT, 1, 0 = WhiteIsZero 273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header 278, 4, 1, height, # RowsPerStrip, LONG, 1, lenght 279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image 0 # last IFD ) pdf_filename = 'scan.pdf' pdf_file = open(pdf_filename, 'rb') cond_scan_reader = PyPDF2.PdfFileReader(pdf_file) for i in range(0, cond_scan_reader.getNumPages()): page = cond_scan_reader. getPage(i) xObject = page['/Resources']['/XObject'].getObject() for obj in xObject: if xObject[obj]['/Subtype'] == '/Image': """ The CCITTFaxDecode filter decodes image data that has been encoded using either Group 3 or Group 4 CCITT facsimile (fax) encoding. CCITT encoding is designed to achieve efficient compression of monochrome (1 bit per pixel) image data at relatively low resolutions, and so is useful only for bitmap image data, not for color images, grayscale images, or general data. K < 0 --- Pure two-dimensional encoding (Group 4) K = 0 --- Pure one-dimensional encoding (Group 3, 1-D) K > 0 --- Mixed one- and two-dimensional encoding (Group 3, 2-D) """ if xObject[obj]['/Filter'] == '/CCITTFaxDecode': if xObject[obj]['/DecodeParms']['/K'] == -1: CCITT_group = 4 else: CCITT_group = 3 width = xObject[obj]['/Width'] height = xObject[obj]['/Height'] data = xObject[obj]._data # sorry, getData() does not work for CCITTFaxDecode img_size = len(data) tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group) img_name = obj[1:] + '.
getPage(i) xObject = page['/Resources']['/XObject'].getObject() for obj in xObject: if xObject[obj]['/Subtype'] == '/Image': """ The CCITTFaxDecode filter decodes image data that has been encoded using either Group 3 or Group 4 CCITT facsimile (fax) encoding. CCITT encoding is designed to achieve efficient compression of monochrome (1 bit per pixel) image data at relatively low resolutions, and so is useful only for bitmap image data, not for color images, grayscale images, or general data. K < 0 --- Pure two-dimensional encoding (Group 4) K = 0 --- Pure one-dimensional encoding (Group 3, 1-D) K > 0 --- Mixed one- and two-dimensional encoding (Group 3, 2-D) """ if xObject[obj]['/Filter'] == '/CCITTFaxDecode': if xObject[obj]['/DecodeParms']['/K'] == -1: CCITT_group = 4 else: CCITT_group = 3 width = xObject[obj]['/Width'] height = xObject[obj]['/Height'] data = xObject[obj]._data # sorry, getData() does not work for CCITTFaxDecode img_size = len(data) tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group) img_name = obj[1:] + '. tiff' with open(img_name, 'wb') as img_file: img_file.write(tiff_header + data) # # import io # from PIL import Image # im = Image.open(io.BytesIO(tiff_header + data)) pdf_file.close()
tiff' with open(img_name, 'wb') as img_file: img_file.write(tiff_header + data) # # import io # from PIL import Image # im = Image.open(io.BytesIO(tiff_header + data)) pdf_file.close() Я начал с кода @sylvain. Были некоторые недостатки, такие как исключение NotImplementedError: unsupported filter /DCTDecode или факт, что код не смог найти изображения на некоторых страницах, потому что они находились на более глубоком уровне, чем страница.
Есть мой код:
import PyPDF2 from PIL import Image import sys from os import path import warnings warnings.filterwarnings("ignore") number = 0 def recurse(page, xObject): global number xObject = xObject['/Resources']['/XObject'].getObject() for obj in xObject: if xObject[obj]['/Subtype'] == '/Image': size = (xObject[obj]['/Width'], xObject[obj]['/Height']) data = xObject[obj]._data if xObject[obj]['/ColorSpace'] == '/DeviceRGB': mode = "RGB" else: mode = "P" imagename = "%s - p. %s - %s"%(abspath[:-4], p, obj[1:]) if xObject[obj]['/Filter'] == '/FlateDecode': img = Image. frombytes(mode, size, data) img.save(imagename + ".png") number += 1 elif xObject[obj]['/Filter'] == '/DCTDecode': img = open(imagename + ".jpg", "wb") img.write(data) img.close() number += 1 elif xObject[obj]['/Filter'] == '/JPXDecode': img = open(imagename + ".jp2", "wb") img.write(data) img.close() number += 1 else: recurse(page, xObject[obj]) try: _, filename, *pages = sys.argv *pages, = map(int, pages) abspath = path.abspath(filename) except BaseException: print('Usage :\nPDF_extract_images file.pdf page1 page2 page3 …') sys.exit() file = PyPDF2.PdfFileReader(open(filename, "rb")) for p in pages: page0 = file.getPage(p-1) recurse(p, page0) print('%s extracted images'% number)  frombytes(mode, size, data) img.save(imagename + ".png") number += 1 elif xObject[obj]['/Filter'] == '/DCTDecode': img = open(imagename + ".jpg", "wb") img.write(data) img.close() number += 1 elif xObject[obj]['/Filter'] == '/JPXDecode': img = open(imagename + ".jp2", "wb") img.write(data) img.close() number += 1 else: recurse(page, xObject[obj]) try: _, filename, *pages = sys.argv *pages, = map(int, pages) abspath = path.abspath(filename) except BaseException: print('Usage :\nPDF_extract_images file.pdf page1 page2 page3 …') sys.exit() file = PyPDF2.PdfFileReader(open(filename, "rb")) for p in pages: page0 = file.getPage(p-1) recurse(p, page0) print('%s extracted images'% number)
frombytes(mode, size, data) img.save(imagename + ".png") number += 1 elif xObject[obj]['/Filter'] == '/DCTDecode': img = open(imagename + ".jpg", "wb") img.write(data) img.close() number += 1 elif xObject[obj]['/Filter'] == '/JPXDecode': img = open(imagename + ".jp2", "wb") img.write(data) img.close() number += 1 else: recurse(page, xObject[obj]) try: _, filename, *pages = sys.argv *pages, = map(int, pages) abspath = path.abspath(filename) except BaseException: print('Usage :\nPDF_extract_images file.pdf page1 page2 page3 …') sys.exit() file = PyPDF2.PdfFileReader(open(filename, "rb")) for p in pages: page0 = file.getPage(p-1) recurse(p, page0) print('%s extracted images'% number) Я установил ImageMagick на свой сервер, а затем запустил вызовы командной строки через Popen :
#!/usr/bin/python import sys import os import subprocess import settings IMAGE_PATH = os.path.join(settings.MEDIA_ROOT , 'pdf_input' ) def extract_images(pdf): output = 'temp. png' cmd = 'convert ' + os.path.join(IMAGE_PATH, pdf) + ' ' + os.path.join(IMAGE_PATH, output) subprocess.Popen(cmd.split(), stderr=subprocess.STDOUT, stdout=subprocess.PIPE) 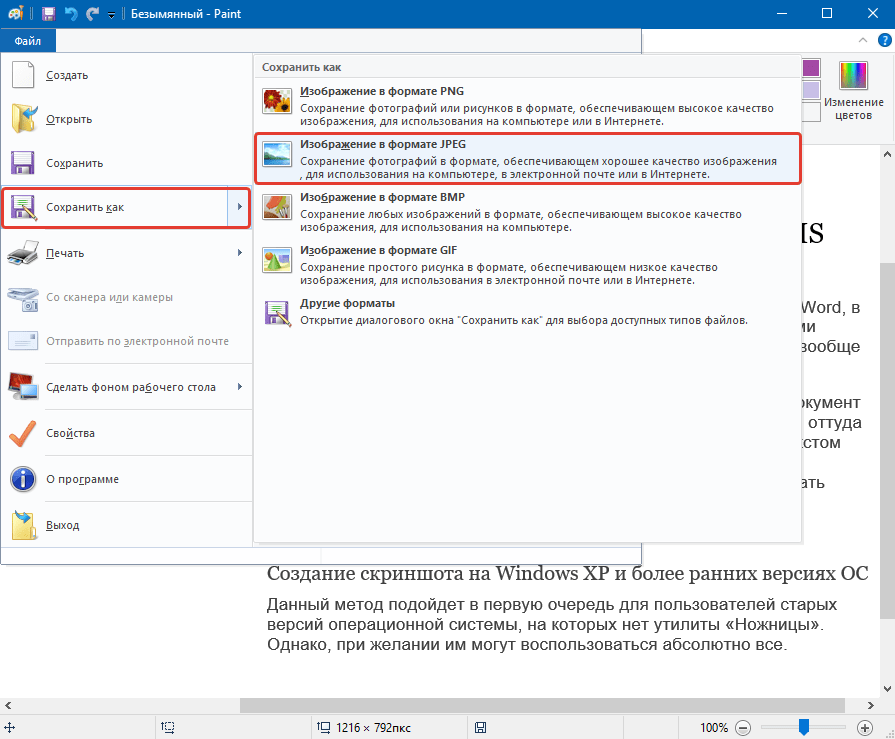 png' cmd = 'convert ' + os.path.join(IMAGE_PATH, pdf) + ' ' + os.path.join(IMAGE_PATH, output) subprocess.Popen(cmd.split(), stderr=subprocess.STDOUT, stdout=subprocess.PIPE)
png' cmd = 'convert ' + os.path.join(IMAGE_PATH, pdf) + ' ' + os.path.join(IMAGE_PATH, output) subprocess.Popen(cmd.split(), stderr=subprocess.STDOUT, stdout=subprocess.PIPE)Это создаст образ для каждой страницы и сохранит их как temp-0.png, temp-1.png …. Это только «извлечение», если вы получили pdf-файл с изображениями и без текста.
Здесь я добавил все вместе в PyPDFTK.
Мой собственный вклад – обработка /Indexed файлы как таковые:
for obj in xObject: if xObject[obj]['/Subtype'] == '/Image': size = (xObject[obj]['/Width'], xObject[obj]['/Height']) color_space = xObject[obj]['/ColorSpace'] if isinstance(color_space, pdf.generic.ArrayObject) and color_space[0] == '/Indexed': color_space, base, hival, lookup = [v.getObject() for v in color_space] # pg 262 mode = img_modes[color_space] if xObject[obj]['/Filter'] == '/FlateDecode': data = xObject[obj].getData() img = Image.frombytes(mode, size, data) if color_space == '/Indexed': img. putpalette(lookup.getData()) img = img.convert('RGB') img.save("{}{:04}.png".format(filename_prefix, i))  putpalette(lookup.getData()) img = img.convert('RGB') img.save("{}{:04}.png".format(filename_prefix, i))
putpalette(lookup.getData()) img = img.convert('RGB') img.save("{}{:04}.png".format(filename_prefix, i)) Обратите внимание, что когда /Indexed файлы найдены, вы не можете просто сравнить /ColorSpace с строкой, потому что она поставляется как объект ArrayObject . Итак, мы должны проверить массив и получить индексированную палитру ( lookup в коде) и установить ее в объекте PIL Image, иначе он останется неинициализированным (ноль), и все изображение станет черным.
Мой первый инстинкт состоял в том, чтобы сохранить их как GIF (индексированный формат), но мои тесты показали, что PNG меньше и выглядят одинаково.
Я нашел эти типы изображений при печати в PDF с помощью PDF-принтера Foxit Reader.
После некоторых поисков я нашел следующий скрипт, который отлично работает с моими PDF-файлами. Он работает только с JPG, но отлично работает с моими незащищенными файлами. Также не требуется никаких внешних библиотек.
Не брать кредит, сценарий происходит от Неда Батчелдера, а не меня. Код Python3: извлечь jpg из pdf. Быстро и грязно
import sys with open(sys.argv[1],"rb") as file: file.seek(0) pdf = file.read() startmark = b"\xff\xd8" startfix = 0 endmark = b"\xff\xd9" endfix = 2 i = 0 njpg = 0 while True: istream = pdf.find(b"stream", i) if istream < 0: break istart = pdf.find(startmark, istream, istream + 20) if istart < 0: i = istream + 20 continue iend = pdf.find(b"endstream", istart) if iend < 0: raise Exception("Didn't find end of stream!") iend = pdf.find(endmark, iend - 20) if iend < 0: raise Exception("Didn't find end of JPG!") istart += startfix iend += endfix print("JPG %d from %d to %d" % (njpg, istart, iend)) jpg = pdf[istart:iend] with open("jpg%d.jpg" % njpg, "wb") as jpgfile: jpgfile.write(jpg) njpg += 1 i = iend Гораздо проще:
Используйте пакет poppler-utils. Чтобы установить его, используйте доморощенный. Первая строка кода, установленная ниже, устанавливает poppler-utils. После установки вторая строка (запускается из командной строки) извлекает изображения из файла PDF и называет их image *. Для запуска этой программы из Python используйте модуль os или subprocess. Третья строка – это код с использованием os-модуля, ниже – пример с подпроцессом (функция python 3.5 или более поздняя для функции run ()). Подробнее здесь: https://www.cyberciti.biz/faq/easily-extract-images-from-pdf-file/
Первая строка кода, установленная ниже, устанавливает poppler-utils. После установки вторая строка (запускается из командной строки) извлекает изображения из файла PDF и называет их image *. Для запуска этой программы из Python используйте модуль os или subprocess. Третья строка – это код с использованием os-модуля, ниже – пример с подпроцессом (функция python 3.5 или более поздняя для функции run ()). Подробнее здесь: https://www.cyberciti.biz/faq/easily-extract-images-from-pdf-file/
brew install poppler
pdfimages file.pdf image
import os os.system('pdfimages file.pdf image') или
import subprocess subprocess.run('pdfimages file.pdf image', shell=True) Как из pdf-документа вырезать страницу и сохранить в виде картинки — Мои статьи — Компьютер и интернет
Будем использовать программу Foxit Reader. Она более удобна и менее тяжеловесна, чем Adobe Reader. Скачать программу можно с сайта разработчика http://www. foxitsoftware.com/downloads/
foxitsoftware.com/downloads/
Существует версия для Linux.
Выберите язык Russian, вашу операционную систему (OS) и нажмите кнопку Download.
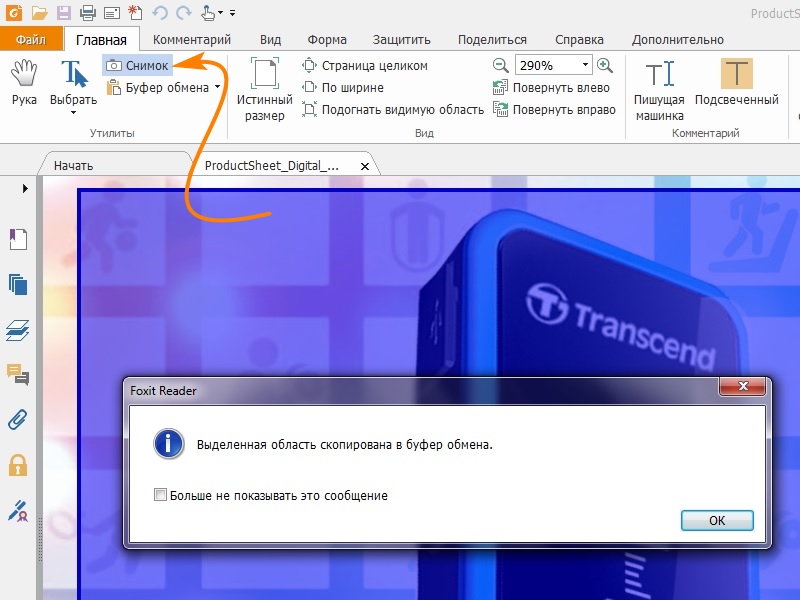
Откройте в Foxit Reader pdf — файл и выберите страницу, которую хотите сохранить как картинку. Страница должна отобразиться на экране монитора. Для сохранения картинки удобно использовать функцию Снимок.
Сначала щелкните по кнопке Истинный размер, чтобы страница предстала в максимальном размере. В меню выберите вкладку Главная и затем щелкните по значку Снимок (значок с изображением фотоаппарата). Подведите курсор мыши к левому верхнему углу страницы. Нажмите левую кнопку мыши (ЛКМ) и, не отпуская кнопку, перемещайте курсор по диагонали к нижнему правому углу страницы. Картинка выделится контуром из тонких пунктирных линий. Отпустите кнопку. Или просто щелкните по странице ЛКМ. Страница выделится синим цветом. Появится окно с сообщением о том, что выделенная область скопирована в буфер обмена. Нажимаем кнопку Ok. Можно выделить только часть страницы.
Если вы используете англоязычную версию, то для получения снимка пройдите в меню по пути Tools -> Snapshot.
Закройте Foxit Reader. Далее можно использовать любую программу, которая поддерживает работу с буфером обмена. Я использовал Paint. Запустите Paint. В меню будет доступна функция Вставить.
Щелкнем по значку Вставить. Картинка из буфера обмена будет вставлена в окно Paint’а. Внизу в строке состояния Paint’а проверьте размеры картинки в пикселях. Обычно требуется изменить размеры картинки, например, для вставки на сайт. В меню выберем вкладку Главная и щелкнем Изменить размер. По умолчанию стоит флажок Проценты. Это не очень удобно, установите флажок на пиксели. Отобразятся размеры картинки в пикселях. Введите желаемый размер по горизонтали или вертикали. Второй размер корректируется автоматически, если стоит галка Сохранить пропорции. Щелкаем Ok для сохранения изменений. Осталось самое простое — сохранить картинку в нужном формате. В меню выбираем Файл — Сохранить как. В правой части окна выбираем нужный формат. Я выбираю Изображение в формате JPEG.
В меню выбираем Файл — Сохранить как. В правой части окна выбираем нужный формат. Я выбираю Изображение в формате JPEG.
В окне Сохранить как изменяем имя файла Безымянный на более осмысленное и нажимаем кнопку Сохранить.
Если вы вырезали только часть картинки, то в Paint’е большая часть листа может оказаться незанятой, чисто белой. Это легко исправить. После кнопки Вставить становится доступной кнопка Обрезать. Щелкните по ней и незаполненная часть листа автоматически обрежется до краев изображения. Или подведите курсор к правому нижнему углу незаполненной части листа. Как только появится двунаправленная стрелка, нажмите ЛКМ и, не отпуская кнопки, перемещайте границу листа по диагонали до края изображения. Отпустите кнопку. Теперь откадрированное изображение можно сохранить.
Также и в самом Paint’е есть возможность обрезать картинку. Нажмите ЛКМ и, не отпуская, выделите нужную часть картинки. Станет доступна кнопка Обрезать. Нажмите ее и картинка обрежется до нужных размеров. Останется сохранить ее, как описано выше.
Останется сохранить ее, как описано выше.
Также есть возможность Вырезать, Копировать и Повернуть и переместить картинку.
Установка Foxit Reader в Linux
С официального сайта скачайте версию для Linux, например FoxitReader.enu.setup.2.4.4.0911.x64.run.tar.gz. Распакуйте скачанный архив. Для этого щелкните ПКМ по значку архива и в меню выберите Распаковать.
Полученный файл FoxitReader.enu.setup.2.4.4.0911(r057d814).x64.run — это установщик программы Foxit Reader, щелкните по значку и запустится установка Foxit Reader. Затем надо принять лицензию и установка завершится. После установки на рабочем столе появится ярлык программы. Щелкнув по ярлыку, можно запустить программу.
Отредактировал статью 16.06.2019
Форматы изображений: какой из них выбрать?
Предположим, вы только что завершили дизайн-проект, собираетесь сохранить файл, и в этот момент нужно выбрать правильное расширение для файла. Если вы не понимаете разницы между этими форматами, то будет достаточно сложно выбрать из них подходящий, но сегодня мы решили помочь вам, и объяснить одну простую вещь:
Существует одно главное правило – для каждой задачи предусмотрены свои форматы изображений.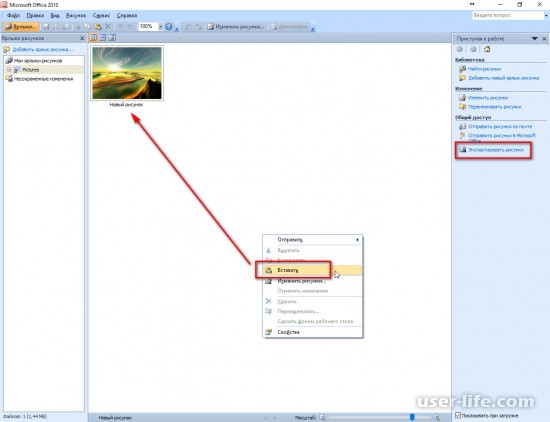 Существует множество различных форматов, с которыми вы никогда даже не столкнетесь, особенно если занимаетесь дизайном печатной продукции.
Существует множество различных форматов, с которыми вы никогда даже не столкнетесь, особенно если занимаетесь дизайном печатной продукции.
Постараемся выяснить, какие форматы изображений нам могут пригодиться.
Чтобы действительно понять разницу между типами изображений, для начала нужно выяснить, чем отличаются растровые изображения от векторных.
Растровые изображения состоят из пикселей, и могут быть выражены в чем угодно: от простых иллюстраций до комплексных изображений вроде цветных фотоснимков.
Так как растровые изображения состоят из фиксированного набора пикселей, при их масштабировании не избежать потери качества, особенно если их увеличивать. Они зачастую используются в качестве финального продукта, готового к отправке в печать или к публикации на сайте.
Векторные изображения на самом деле являются не совсем изображениями, – это нечто вроде математических формул, напрямую взаимодействующих с компьютером, сообщая ему координаты фигур, которые нужно отобразить. Благодаря этому, векторные изображения можно масштабировать без потери качества, так как формула просто-напросто подстраивается под необходимые размеры конечного рисунка.
Благодаря этому, векторные изображения можно масштабировать без потери качества, так как формула просто-напросто подстраивается под необходимые размеры конечного рисунка.
Векторные изображения используются для создания текстов и логотипов, и они не способны отобразить комплексные графические продукты вроде фотографий. Обычно они используются как рабочие файлы, которые позже конвертируют в растровые изображения для сайтов. Но с их помощью также можно разрабатывать графику для последующей печати:
Классификация основных типов файлов, используемых в печати и веб-дизайне, подразумевает нечто большее, чем простое разделение на вектор и растр. Как растр, так и вектор – это лишь два крупных семейства, которые насчитывают множество различных форматов изображений с разными преимуществами, недостатками и предназначением.
Многие недолюбливают JPEG, но стоит отметить, что он просто не совсем подходит для печати. В JPG-формате используется сильное сжатие. Это хорошо, если требуется максимально уменьшить размеры файла, но это не совсем подходит с точки зрения качества картинки, которую вы собираетесь распечатывать. Поэтому этот формат нельзя использовать при создании, скажем, логотипов.
Поэтому этот формат нельзя использовать при создании, скажем, логотипов.
Именно благодаря маленькому размеру файлов, JPEG часто используется в веб-дизайне, так как это положительно влияет на скорость загрузки страниц. JPG-формат также широко используется для цифровых фотографий, так как потери в качестве незаметны, а благодаря меньшему размеру на флешке или жестком диске умещается гораздо больше снимков.
Учитывая все эти преимущества, JPG зарекомендовал себя в качестве «стандартного» формата для всего, что находится за пределами области дизайна. На практике вам наверняка придется столкнуться с клиентами, которые предоставят собственные логотипы в ужасном качестве или с теми, кто предпочитает работать исключительно с этим форматом, потому что знают только его. Сделайте все возможное, чтобы привлечь их внимание к другим, более подходящим, форматам.
Кажется, никто и никогда так и не произнес название этого формата правильно. Дизайнеры часто четко произносят первую букву G или диктуют все три буквы по очереди, однако его создатель, Стив Уилхайт, утверждает, что правильно произносить название как «джив». Хотя его аббревиатура расшифровывается как Graphics Interchange Format («формат для обмена изображениями»), а сам он главным образом используется в веб-дизайне.
Хотя его аббревиатура расшифровывается как Graphics Interchange Format («формат для обмена изображениями»), а сам он главным образом используется в веб-дизайне.
Преимущество GIF (которое также отличает его от остальных веб-форматов для изображений) в том, что эти картинки можно анимировать.
Кроме того, GIF поддерживает прозрачность, что иногда позволяет существенно снизить вес файлов. Однако понятие маленького веса относительно, так как чем больше цветов используется, тем больше будет весить файл. Также важно учитывать количество кадров, так как каждый кадр также влияет на вес файла и увеличивает время загрузки веб-страницы.
Формат PNG совмещает в себе преимущества JPG и GIF, однако, у него есть четкие рекомендации к использованию. Как и JPG, PNG-формат идеально подходит для фотографий, и при этом позволяет сохранить даже лучшее качество снимков, чем JPG. PNG также поддерживает прозрачность, поэтому это почти идеальный вариант для дизайнеров, которым нужны прозрачные элементы, но при этом они не могут пожертвовать качеством графики.
Основной недостаток PNG — большой размер файла, а это отрицательно сказывается на скорости загрузки сайта. Этот формат лучше всего использовать выборочно для элементов, где требуется высокое качество, которое JPG и GIF не способны предложить (например, высококачественные логотипы). PNG также относится к растровым форматам изображений, поэтому при масштабировании таких файлов вы рискуете потерять качество.
TIFF (иногда TIF) – формат файла без сжатия, а это значит, что при сохранении он вообще не подвергается компрессии. TIFF также поддерживает послойную структуру.
Этот формат зачастую называют «готовым к печати» хотя большинство принтеров лучше работают с родными типами файлов вроде AI и PSD.
Кроме того, TIFF слишком тяжелый формат для веб-дизайна. А размеры файлов могут отпугнуть неопытных клиентов, так что постарайтесь подготовить проекты в более распространенных форматах.
PSD представляет собой родной формат программы Adobe Photoshop. Это значит, что беспрепятственно редактировать эти файлы можно только в Photoshop.
PSD нельзя использовать на страницах сайта, и мы настоятельно не рекомендуем вам высылать клиентам превью дизайнов в этом формате. Однако он отлично подходит для последующей печати или для обмена файлами проектами с другими дизайнерами.
EPS – стандартный векторный формат файлов, состоящий из многочисленных формул и чисел, за счет которых генерируется векторная иллюстрация. Это идеальный формат для тех элементов дизайна, которые обычно нужно масштабировать (например, логотипы).
Файлы в EPS-формате готовы к печати, однако, это не тот формат, который нужно использовать в веб-дизайне. Зачастую после утверждения дизайна страницы его составные элементы конвертируются в PNG, JPG и GIF.
Элементы дизайна, сохраненные в формате EPS, можно открыть в любом редакторе с поддержкой векторной графики. Следовательно, EPS больше подходит для обмена файлами с клиентами, печати на принтере или для совместной работы над проектом с другими дизайнерами.
AI – еще один брендовый векторный формат от Adobe, предназначенный для работы в программе Illustrator.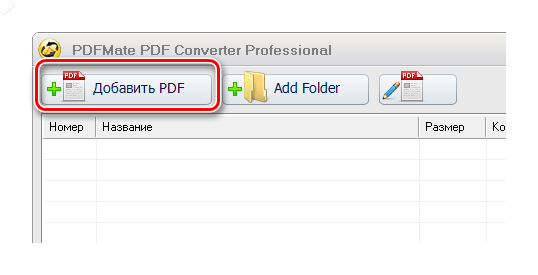 AI-файл нельзя встраивать в веб-страницы, и это не тот формат, который используется для отправки проектов клиенту. Но он хорошо подходит для внутреннего использования и для печати.
AI-файл нельзя встраивать в веб-страницы, и это не тот формат, который используется для отправки проектов клиенту. Но он хорошо подходит для внутреннего использования и для печати.
PDF-формат от Adobe идеально подходит как для печатной продукции, так и для цифрового использования. Это формат, с которым «справится» любой клиент, и который без проблем можно распечатать на принтере. В PDF-документ можно поместить как растровые, так и векторные изображения, или даже комбинировать их в едином документе.
Конечно, придется сильно постараться, чтобы качественно отобразить содержимое PDF-документа на странице сайта, однако можно реализовать его скачивание. Этот формат также идеально подходит для отправки клиентам превью финального результата.
Однако PDF больше подходит для печатных продуктов вроде книг, брошюр или листовок.
В процессе работы над дизайном печатной продукции, вам, возможно, придется прыгать от одного формата к другому. Иногда нужно поместить JPG-фотографии и EPS-логотип в общий проект, работа над которым ведется в PSD-файле в Photoshop.
Хорошо то, что у каждого формата изображений есть сильные стороны, и опытный дизайнер знает, как из них извлечь выгоду. Велика вероятность, что один и тот же элемент дизайна понадобится вам в разных форматах: основной исходник логотипа будет храниться в EPS-формате, его PNG-версия будет использоваться на сайте, а анимированная GIF-версия припасена для особых случаев.
При помощи Photoshop и Illustrator вы можете сохранять и конвертировать изображения практически в любые форматы. Но стоит отметить, что сохранение картинки с низким разрешением в какой-то специфический формат не поможет вам улучшить его качество. А вот сохранение высококачественного изображения в формат с использованием сжатия приведет к потере качества.
Конвертировать векторное изображение в растровое очень просто – нужно указать желаемый растровый формат при сохранении. Однако такое действие сожмет векторы в пиксели, а это значит, что вы больше не сможете «безболезненно» масштабировать сохраненное изображение, поэтому мы рекомендуем на всякий случай оставить копию исходного файла.
Конвертирование растрового изображения в векторное – это целая наука. Нет простого способа конвертировать пиксели растрового изображения в формулы, генерирующие векторы. Самый проверенный способ – это просто перерисовать картинку при помощи векторов.
МГМаксим Галенкоавтор
Извлекать изображения из PDF без передискретизации, в Python?
import PyPDF2
import struct
"""
Links:
PDF format: http://www.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/pdf_reference_1-7.pdf
CCITT Group 4: https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-T.6-198811-I!!PDF-E&type=items
Extract images from pdf: http://stackoverflow.com/questions/2693820/extract-images-from-pdf-without-resampling-in-python
Extract images coded with CCITTFaxDecode in .net: http://stackoverflow.com/questions/2641770/extracting-image-from-pdf-with-ccittfaxdecode-filter
TIFF format and tags: http://www.awaresystems.be/imaging/tiff/faq.html
"""
def tiff_header_for_CCITT(width, height, img_size, CCITT_group=4):
tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h'
return struct. pack(tiff_header_struct,
b'II', # Byte order indication: Little indian
42, # Version number (always 42)
8, # Offset to first IFD
8, # Number of tags in IFD
256, 4, 1, width, # ImageWidth, LONG, 1, width
257, 4, 1, height, # ImageLength, LONG, 1, lenght
258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1
259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding
262, 3, 1, 0, # Threshholding, SHORT, 1, 0 = WhiteIsZero
273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header
278, 4, 1, height, # RowsPerStrip, LONG, 1, lenght
279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image
0 # last IFD
)
pdf_filename = 'scan. pdf'
pdf_file = open(pdf_filename, 'rb')
cond_scan_reader = PyPDF2.PdfFileReader(pdf_file)
for i in range(0, cond_scan_reader.getNumPages()):
page = cond_scan_reader.getPage(i)
xObject = page['/Resources']['/XObject'].getObject()
for obj in xObject:
if xObject[obj]['/Subtype'] == '/Image':
"""
The CCITTFaxDecode filter decodes image data that has been encoded using
either Group 3 or Group 4 CCITT facsimile (fax) encoding. CCITT encoding is
designed to achieve efficient compression of monochrome (1 bit per pixel) image
data at relatively low resolutions, and so is useful only for bitmap image data, not
for color images, grayscale images, or general data.
K < 0 --- Pure two-dimensional encoding (Group 4)
K = 0 --- Pure one-dimensional encoding (Group 3, 1-D)
K > 0 --- Mixed one- and two-dimensional encoding (Group 3, 2-D)
"""
if xObject[obj]['/Filter'] == '/CCITTFaxDecode':
if xObject[obj]['/DecodeParms']['/K'] == -1:
CCITT_group = 4
else:
CCITT_group = 3
width = xObject[obj]['/Width']
height = xObject[obj]['/Height']
data = xObject[obj]. _data # sorry, getData() does not work for CCITTFaxDecode
img_size = len(data)
tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group)
img_name = obj[1:] + '.tiff'
with open(img_name, 'wb') as img_file:
img_file.write(tiff_header + data)
#
# import io
# from PIL import Image
# im = Image.open(io.BytesIO(tiff_header + data))
pdf_file.close()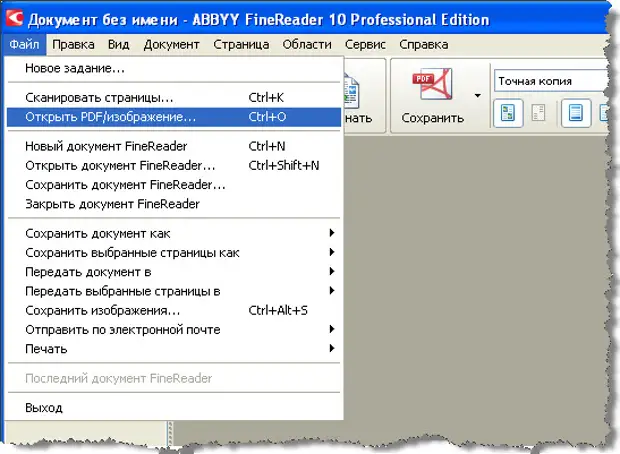 pack(tiff_header_struct,
b'II', # Byte order indication: Little indian
42, # Version number (always 42)
8, # Offset to first IFD
8, # Number of tags in IFD
256, 4, 1, width, # ImageWidth, LONG, 1, width
257, 4, 1, height, # ImageLength, LONG, 1, lenght
258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1
259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding
262, 3, 1, 0, # Threshholding, SHORT, 1, 0 = WhiteIsZero
273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header
278, 4, 1, height, # RowsPerStrip, LONG, 1, lenght
279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image
0 # last IFD
)
pdf_filename = 'scan.
pack(tiff_header_struct,
b'II', # Byte order indication: Little indian
42, # Version number (always 42)
8, # Offset to first IFD
8, # Number of tags in IFD
256, 4, 1, width, # ImageWidth, LONG, 1, width
257, 4, 1, height, # ImageLength, LONG, 1, lenght
258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1
259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding
262, 3, 1, 0, # Threshholding, SHORT, 1, 0 = WhiteIsZero
273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header
278, 4, 1, height, # RowsPerStrip, LONG, 1, lenght
279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image
0 # last IFD
)
pdf_filename = 'scan. pdf'
pdf_file = open(pdf_filename, 'rb')
cond_scan_reader = PyPDF2.PdfFileReader(pdf_file)
for i in range(0, cond_scan_reader.getNumPages()):
page = cond_scan_reader.getPage(i)
xObject = page['/Resources']['/XObject'].getObject()
for obj in xObject:
if xObject[obj]['/Subtype'] == '/Image':
"""
The CCITTFaxDecode filter decodes image data that has been encoded using
either Group 3 or Group 4 CCITT facsimile (fax) encoding. CCITT encoding is
designed to achieve efficient compression of monochrome (1 bit per pixel) image
data at relatively low resolutions, and so is useful only for bitmap image data, not
for color images, grayscale images, or general data.
K < 0 --- Pure two-dimensional encoding (Group 4)
K = 0 --- Pure one-dimensional encoding (Group 3, 1-D)
K > 0 --- Mixed one- and two-dimensional encoding (Group 3, 2-D)
"""
if xObject[obj]['/Filter'] == '/CCITTFaxDecode':
if xObject[obj]['/DecodeParms']['/K'] == -1:
CCITT_group = 4
else:
CCITT_group = 3
width = xObject[obj]['/Width']
height = xObject[obj]['/Height']
data = xObject[obj].
pdf'
pdf_file = open(pdf_filename, 'rb')
cond_scan_reader = PyPDF2.PdfFileReader(pdf_file)
for i in range(0, cond_scan_reader.getNumPages()):
page = cond_scan_reader.getPage(i)
xObject = page['/Resources']['/XObject'].getObject()
for obj in xObject:
if xObject[obj]['/Subtype'] == '/Image':
"""
The CCITTFaxDecode filter decodes image data that has been encoded using
either Group 3 or Group 4 CCITT facsimile (fax) encoding. CCITT encoding is
designed to achieve efficient compression of monochrome (1 bit per pixel) image
data at relatively low resolutions, and so is useful only for bitmap image data, not
for color images, grayscale images, or general data.
K < 0 --- Pure two-dimensional encoding (Group 4)
K = 0 --- Pure one-dimensional encoding (Group 3, 1-D)
K > 0 --- Mixed one- and two-dimensional encoding (Group 3, 2-D)
"""
if xObject[obj]['/Filter'] == '/CCITTFaxDecode':
if xObject[obj]['/DecodeParms']['/K'] == -1:
CCITT_group = 4
else:
CCITT_group = 3
width = xObject[obj]['/Width']
height = xObject[obj]['/Height']
data = xObject[obj]. _data # sorry, getData() does not work for CCITTFaxDecode
img_size = len(data)
tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group)
img_name = obj[1:] + '.tiff'
with open(img_name, 'wb') as img_file:
img_file.write(tiff_header + data)
#
# import io
# from PIL import Image
# im = Image.open(io.BytesIO(tiff_header + data))
pdf_file.close()
_data # sorry, getData() does not work for CCITTFaxDecode
img_size = len(data)
tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group)
img_name = obj[1:] + '.tiff'
with open(img_name, 'wb') as img_file:
img_file.write(tiff_header + data)
#
# import io
# from PIL import Image
# im = Image.open(io.BytesIO(tiff_header + data))
pdf_file.close()Как извлечь все изображения из PDF-файла
Вы можете использовать Nitro Pro для извлечения всех изображений из ваших PDF-документов в отдельные файлы изображений, которые затем можно повторно использовать в других программах. Этот процесс помогает извлекать изображения из ряда страниц, целых файлов PDF или коллекции файлов.
Как извлекать изображения из файлов PDF:
1. На вкладке Home в группе Convert щелкните To Other , затем Extract Images . Появится диалоговое окно Extract Images .
Появится диалоговое окно Extract Images .
2. В диалоговом окне « Extract Images » выполните одно из следующих действий:
- В разделе «Файлы » для извлечения изображений из раздела щелкните Добавить файлы , а затем выберите дополнительные файлы PDF для включения
- Чтобы изменить порядок документов, выберите файл PDF в списке и нажмите Вверх или Вниз . Чтобы удалить выбранный файл PDF из списка, нажмите Удалить.
- Включить все открытые PDF-документы: добавить PDF-файлы, открытые в настоящее время в Nitro Pro, в список и указать все страницы.
- Чтобы извлечь изображения с определенных страниц документа, выберите документ и нажмите Выбрать страницы . В поле Pages укажите страницы, разделенные запятой, или диапазон страниц, разделенных тире. Например, чтобы извлечь изображения со страниц 1, 3, 4 и 5 8-страничного документа, введите 1, 3-5 . Вы можете использовать стрелки навигации по страницам в нижней части диалогового окна для предварительного просмотра страниц для облегчения выбора.
- В разделе Выход выберите параметр Папка , чтобы указать, где хранить извлеченные файлы.
- Чтобы изменить настройки для форматов файлов по умолчанию, щелкните Параметры . Укажите формат файла для цветных и монохромных изображений. Если вы выберете Optimal , Nitro Pro автоматически выберет лучший тип файла изображения на основе информации PDF.
- Открыть папку после создания: автоматически открыть папку назначения после извлечения изображений

3.Щелкните Преобразовать , чтобы завершить извлечение.
Для получения информации о том, как быстро извлечь отдельное изображение из файла PDF, см. Извлечение изображения.
Метод простого извлечения изображений из PDF
2021-08-24 09:16:22 • Отправлено в: Практическое руководство • Проверенные решения
В документе PDF, содержащем текст, таблицы и различные изображения, вы можете легко извлечь текст из файла PDF с помощью инструмента редактирования или ручного инструмента в любом редакторе PDF. Если вы хотите извлечь одно изображение, вы можете просто скопировать его и вставить в программу редактирования изображений, такую как Paint в Windows. Однако, если у вас большой PDF-файл, извлечение изображений станет намного сложнее, так как для этого потребуется вручную перейти на каждую страницу и скопировать все изображения одно за другим. К счастью, PDFelement может извлекать изображения из PDF намного проще.
Если вы хотите извлечь одно изображение, вы можете просто скопировать его и вставить в программу редактирования изображений, такую как Paint в Windows. Однако, если у вас большой PDF-файл, извлечение изображений станет намного сложнее, так как для этого потребуется вручную перейти на каждую страницу и скопировать все изображения одно за другим. К счастью, PDFelement может извлекать изображения из PDF намного проще.
2 шага для извлечения изображения из PDF
Вот пошаговое руководство по извлечению изображений из файлов PDF с помощью PDFelement.
Шаг 1. Загрузите PDF-файл в программу
Запустите PDFelement на своем компьютере и нажмите кнопку «Открыть файл» на вкладке «Главная». Затем выберите файл, из которого вы хотите извлечь изображения. После открытия файла PDF вы можете извлечь одно изображение или все изображения из файла PDF.
Шаг 2. Извлечение изображения из PDF в Windows
Перейдите на вкладку «Преобразовать» и нажмите кнопку «В изображение». Во всплывающем окне выберите желаемый формат вывода.Затем нажмите кнопку «Настройки». Выберите «Извлечь все изображения в PDF». Выбрав соответствующий вариант, нажмите «ОК». Наконец, нажмите «Сохранить», чтобы удалить изображения из файла PDF.
Во всплывающем окне выберите желаемый формат вывода.Затем нажмите кнопку «Настройки». Выберите «Извлечь все изображения в PDF». Выбрав соответствующий вариант, нажмите «ОК». Наконец, нажмите «Сохранить», чтобы удалить изображения из файла PDF.
PDFelement позволяет извлекать все изображения из одного файла PDF всего за пару кликов. Избегайте поиска по всему документу, чтобы вручную скопировать все изображения. Теперь вы можете автоматически сохранять их в отдельные папки на вашем компьютере. Еще одно преимущество использования PDFelement заключается в том, что качество изображений в файле PDF останется прежним.
Видео о том, как извлекать изображения из PDF
PDFelement — это больше, чем просто средство для извлечения изображений PDF. Он также предлагает полный набор инструментов для редактирования PDF. Одной из наиболее полезных функций является распознавание текста, которое извлекает текст из отсканированного или графического PDF-файла и делает его редактируемым. PDFelement также позволяет конвертировать файлы PDF в Word, Excel, PowerPoint или другие форматы файлов.
PDFelement также позволяет конвертировать файлы PDF в Word, Excel, PowerPoint или другие форматы файлов.
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Как извлекать изображения из файла PDF
Как технический писатель, я много работаю с файлами PDF.Иногда я их создаю, иногда редактирую. Полезно иметь возможность извлекать из них изображения и использовать элементы этих файлов любым способом. Если вы хотите извлечь изображения из файлов PDF, вы можете сделать это несколькими способами. Вы можете использовать Adobe Acrobat Pro DC, Photoshop, инструмент для обрезки изображений, сделать снимок экрана или воспользоваться бесплатным веб-сервисом. Я покажу вам, как использовать все пять.
Я покажу вам, как использовать все пять.
Извлечение изображений из файлов PDF с помощью веб-службы
Если используемый файл PDF не является конфиденциальным, и у вас нет доступа или времени для использования любого из предыдущих методов, вы можете использовать веб-службу для извлечения всевозможные данные из файла PDF.Я рекомендую наш собственный бесплатный tools.techjunkie.com, поскольку он быстрый, простой и безопасный.
- Перейдите к инструменту извлечения изображений в формате pdf от TechJunkie Tools.
- Загрузите файл PDF на веб-сайт.
- Загрузите извлеченные изображения из PDF на свой компьютер.
Изображения будут сжаты в Zip-файл, в котором вам понадобится средство для извлечения файлов для доступа к файлам. Windows 10 изначально поддерживает Zip-файлы, в противном случае есть множество бесплатных инструментов, которые помогут.
Извлечение изображений из файлов PDF с помощью Adobe Acrobat Pro
Если вам посчастливилось иметь копию Adobe Acrobat Pro, извлекать изображения очень просто. Как собственное приложение для всех PDF-файлов, Acrobat позволяет управлять PDF-файлами и управлять ими. Жаль, что это так дорого! При цене 14,99 долларов в месяц это не для случайного пользователя, но если вы работаете с большим количеством PDF-файлов, нет ничего лучше.
Как собственное приложение для всех PDF-файлов, Acrobat позволяет управлять PDF-файлами и управлять ими. Жаль, что это так дорого! При цене 14,99 долларов в месяц это не для случайного пользователя, но если вы работаете с большим количеством PDF-файлов, нет ничего лучше.
- Откройте файл PDF в Adobe Acrobat Pro.
- Выберите «Инструменты» и «Экспортируйте PDF».
- Выберите изображение, а затем формат.
- Установите флажок Экспортировать все изображения под параметрами.
- Выберите «Экспорт» и укажите место для их сохранения.
Acrobat Pro, затем извлеките все изображения из PDF и сохраните их в выбранном вами формате в выбранном вами файле.
Извлечение изображений из файлов PDF с помощью Adobe Photoshop
Вы можете сделать что-то подобное с Adobe Photoshop, если он у вас есть, но нет копии Acrobat. В Photoshop есть несколько способов сделать это, но, на мой взгляд, использование Pages — самый быстрый.
- Откройте файл PDF в Photoshop.
- Выберите Страницы в поле Импорт PDF, а затем страницу, содержащую изображение.
- Установите разрешение изображения на какое-нибудь пригодное для использования, минимум 72 для Интернета или 300 для печати.
- Выберите OK
- Выберите «Файл» и «Сохранить как», чтобы сохранить изображение в выбранном вами формате.
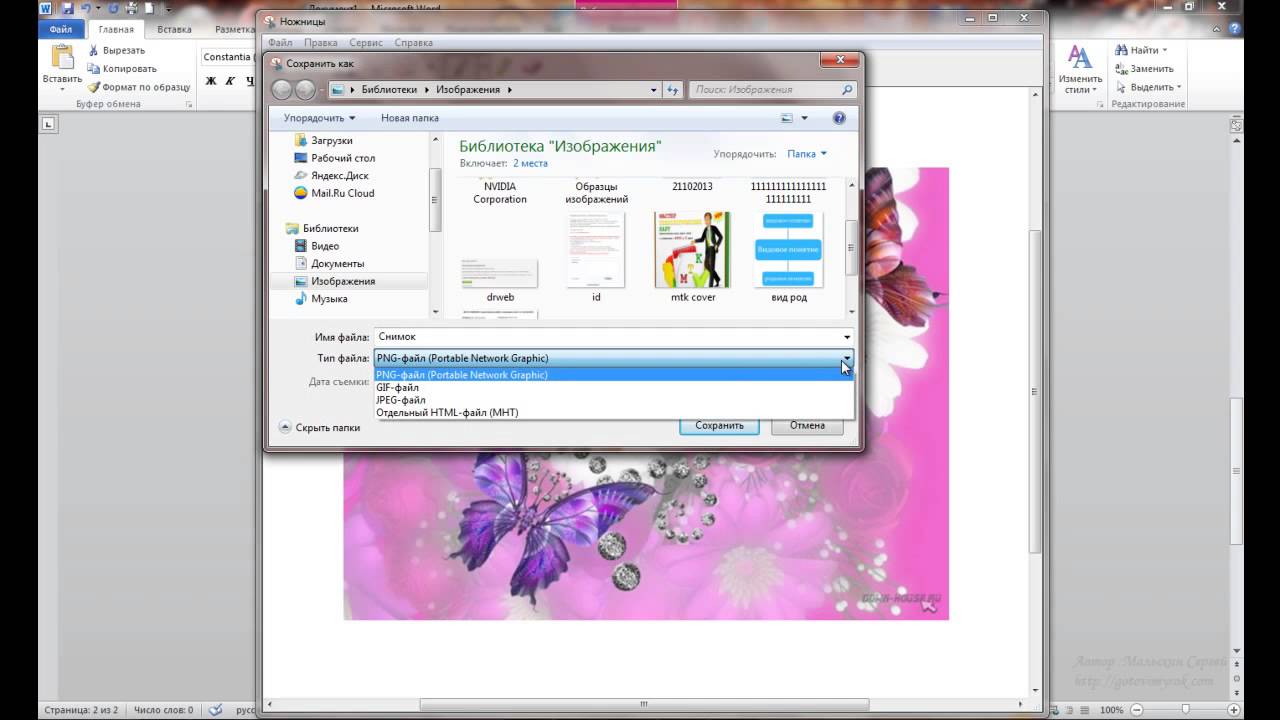
Извлечение изображений из файлов PDF с помощью инструмента Windows snipping.
Встроенный инструмент Windows snipping неоценим для создания снимков экрана или частей экрана.Он скрыт в Windows, но предлагает множество полезностей для всех, кто работает с изображениями.
- Откройте ножницы в Windows.
- Выберите PDF-файл, из которого вы хотите сделать снимок, и убедитесь, что изображение находится в центре экрана.
- Выберите «Новый» в инструменте «Ножницы», и экран исчезнет.
- Перетащите курсор вокруг изображения, удерживая его как можно плотнее.
- Сохраните его в выбранном вами формате и назовите что-нибудь значимое.

Затем вы можете использовать Photoshop или любой другой редактор изображений, чтобы изменить его размер.
Извлечение изображений из файлов PDF с помощью снимков экрана
Если вам не нравится работа с инструментом для обрезки, вы можете просто сделать быстрый снимок экрана Windows.
- Убедитесь, что изображение PDF находится в центре экрана.
- Нажмите клавишу PrtSrn на клавиатуре.
- Откройте редактор изображений и вставьте в него экран.
- Измените размер и формат по размеру.
Хотя это и не так точно, как эти другие методы, если вы в затруднительном положении, создание снимка экрана с помощью PrtScrn — это быстрый и эффективный способ захвата изображения.
Извлечь все изображения из PDF в JPG, PNG, GIF, BMP и т. Д. [Руководство 2020]
Anuraag | Изменено: 2020-01-08T11: 14: 58 + 00: 00 | PDF | Одним из наиболее предпочтительных средств обмена документами через Интернет является файл PDF. Эти файлы содержат текст, изображения, графику и т. Д. Когда кто-то получает какой-либо файл PDF в виде конфиденциальных документов, отчетов по проектам, каталогов, презентаций или заметок об исследованиях, возможно, мы захотим сохранить изображения, присутствующие в этом конкретном файле. .Хотя мы можем открывать или читать эти файлы с помощью Adobe Reader, мы не можем сохранять или извлекать все изображения из файлов PDF с помощью Adobe Reader. Следовательно, необходима полная версия Acrobat Pro или любой другой альтернативный инструмент, который может извлекать изображения из Adobe PDF. В этой статье мы предоставили 3 решения, которые помогут в извлечении изображений PDF, поэтому просматривайте их одно за другим.
Эти файлы содержат текст, изображения, графику и т. Д. Когда кто-то получает какой-либо файл PDF в виде конфиденциальных документов, отчетов по проектам, каталогов, презентаций или заметок об исследованиях, возможно, мы захотим сохранить изображения, присутствующие в этом конкретном файле. .Хотя мы можем открывать или читать эти файлы с помощью Adobe Reader, мы не можем сохранять или извлекать все изображения из файлов PDF с помощью Adobe Reader. Следовательно, необходима полная версия Acrobat Pro или любой другой альтернативный инструмент, который может извлекать изображения из Adobe PDF. В этой статье мы предоставили 3 решения, которые помогут в извлечении изображений PDF, поэтому просматривайте их одно за другим.
Извлечение всех изображений из файлов PDF с помощью PDF Toolb Различные инструменты и программное обеспечение, которые можно использовать для извлечения изображений из PDF и экспорта их в форматы JPG, BMP, PNG. PDF Toolbox может помочь пользователям получать изображения из PDF в JPG, PNG, BMP, GIF, ICO, RAW, PCS, TGA и т.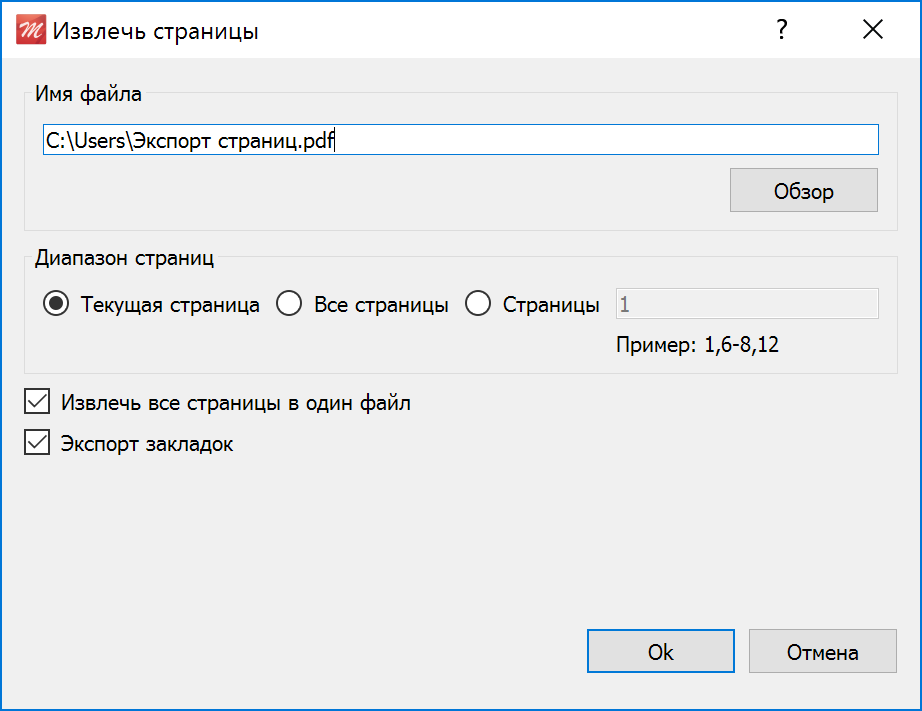 Д. Это программное обеспечение предоставляет возможность добавления файлов или добавления папки для вставки нескольких документов PDF для извлечения изображений. Программное обеспечение совместимо со всеми версиями операционной системы Windows, включая 10.
Д. Это программное обеспечение предоставляет возможность добавления файлов или добавления папки для вставки нескольких документов PDF для извлечения изображений. Программное обеспечение совместимо со всеми версиями операционной системы Windows, включая 10.
2 дополнительных параметра для извлечения изображений из PDF
1- Опция извлечения изображения
С помощью этой опции пользователи могут сохранять извлеченные фотографии PDF в различных форматах изображений.Он включает в себя TIFF, JPEG, PNG, BMP, GIF и т. Д.
Дополнительные настройки: С помощью этой опции установите минимальный и максимальный размер изображений, задав их ширину и высоту.
Опции с двумя страницами
Эта опция объединяется с 3 другими опциями. Включает «Все», «Диапазон страниц», «Страницы
»- Всего: Для извлечения изображений со всех страниц файла PDF
- Диапазон страниц: Для извлечения изображений из определенного диапазона страниц
- Страниц: Для извлечения изображений с определенных страниц файла PDF
Действия по сохранению изображений в документе PDF в других форматах изображений
Выполните следующие простые шаги, чтобы извлечь все изображения из файлов PDF:
- Скачать и запустить SysTools PDF Toolbox Software
- Выберите Извлечь изображения из опций меню
- Нажмите Добавить файлы / Добавить папку , чтобы вставить файлы PDF
- Выберите нужный вариант Извлечь изображение и Параметры страницы
- Нажмите кнопку «Пуск» , чтобы начать процесс
Извлечение изображений из PDF с помощью Adobe Acrobat Pro
Adobe Acrobat Pro — это многофункциональная программа, которая может помочь в выполнении нескольких задач. С помощью этой программы пользователи также могут сохранять фотографии из документов PDF.
С помощью этой программы пользователи также могут сохранять фотографии из документов PDF.
Теперь выполните следующие простые шаги:
- Откройте документ PDF в Adobe Acrobat Pro DC
- Нажмите на «Инструменты» и выберите «Экспорт в PDF».
- Щелкните параметр Изображение и выберите желаемый формат извлеченных изображений (например, JPEG 2000, JPEG, PNG, TIFF).
- Теперь установите флажок «Экспортировать все изображения» и нажмите кнопку «Экспорт».
- Выберите место назначения для экспортированного изображения
- Щелкните диалоговое окно «Сохранить как» и укажите имя файла изображения.
Извлечение всех изображений из PDF-документов с помощью Snipping Tool
Еще одно решение для извлечения изображений из PDF-документов — использование Windows Snipping Tool .Чтобы использовать этот инструмент для сохранения изображений из документов PDF, выполните следующие простые шаги:
- Нажмите кнопку «Пуск» и введите Snipping Tool в поле поиска
- Щелкните New Option , чтобы выбрать изображение
- Теперь, перейдите к опции «Файл» и нажмите «Сохранить как».
- Выберите место назначения и нажмите Кнопка «Сохранить»
По умолчанию изображение сохраняется в формате PNG.Но пользователи могут изменить их на формат GIF, JPG и HTML.
Ограничения использования ручных решений
- С Adobe Acrobat Pro пользователи могут сохранять извлеченные изображения только в форматах JPEG, JPEG 2000, PNG и TIFF.
- С помощью инструмента «Ножницы» изображения можно сохранять только в формате GIF, PNG, JPG и HTML.
- Это будет длительный и трудоемкий процесс
- Если извлечение изображения является единственным требованием, необходимо приобрести полную версию Adobe Acrobat, которая слишком дорога
- Невозможно извлечь встроенные изображения из выбранных страниц с помощью ручного метода
- Пользователи не могут экспортировать изображения в другие форматы, такие как BMP, TGA, ICO, RAW
Заключение
Эта статья напоминает нам о важности извлечения изображений из документов PDF. Наряду с этим мы также рассмотрели 3 различных решения для извлечения всех изображений из файлов PDF. В настоящее время, будь то презентация, отчеты или любой другой файл, каждый хочет сохранить важные данные, такие как изображения или текст. В этом блоге мы рассмотрели решение, позволяющее извлекать различные изображения из PDF. Итак, учитывая все плюсы и минусы каждого решения, пользователи могут выбрать наиболее надежное.
Наряду с этим мы также рассмотрели 3 различных решения для извлечения всех изображений из файлов PDF. В настоящее время, будь то презентация, отчеты или любой другой файл, каждый хочет сохранить важные данные, такие как изображения или текст. В этом блоге мы рассмотрели решение, позволяющее извлекать различные изображения из PDF. Итак, учитывая все плюсы и минусы каждого решения, пользователи могут выбрать наиболее надежное.
Об авторе
Анурааг
Предприниматель, технический аналитик, писатель с новаторскими и аутентичными мыслями о технологиях.Предлагает блестящие решения проблем, с которыми пользователи сталкиваются при работе с технологиями. Обладая потрясающими знаниями в технических областях во многих областях.
5 Способ извлечения изображений из файла PDF
Как извлечь изображения из файла PDF: Некоторые файлы PDF содержат много изображений, и вы обнаружили, что эти изображения из файла PDF могут быть вам полезны. Но вопрос здесь в том, как вы можете извлекать изображения из файлов PDF. Для извлечения изображений есть несколько способов, таких как программное обеспечение, инструменты, онлайн-сайты и т. Д.В этой статье мы собираемся обсудить пять различных методов, которые могут помочь вам в извлечении изображений из файла PDF.
Но вопрос здесь в том, как вы можете извлекать изображения из файлов PDF. Для извлечения изображений есть несколько способов, таких как программное обеспечение, инструменты, онлайн-сайты и т. Д.В этой статье мы собираемся обсудить пять различных методов, которые могут помочь вам в извлечении изображений из файла PDF.
Каждый метод имеет свои преимущества, некоторые из них платные, а некоторые бесплатные. Эти методы помогут вам в разных случаях, например, если вы хотите сохранить извлеченные изображения на диске или хотите сохранить в другом формате изображения. Эти методы могут быть полезны во всех смыслах, так что приступим.
Обязательно создайте точку восстановления на случай, если что-то пойдет не так.
Adobe Acrobat Pro — идеальный инструмент для всех операций, связанных с PDF. С этим инструментом очень легко работать, но вы должны заплатить за него, так как это не бесплатный инструмент. Вы можете использовать его бесплатную пробную версию, чтобы использовать его функции в течение некоторого времени, но после этого вам необходимо приобрести подписку.
С помощью этого инструмента вы можете легко экспортировать PDF-файл в любой формат. Просто откройте это приложение и на панели инструментов выберите опцию « TOOLS ». Теперь нажмите на опцию « Экспорт в PDF » и перейдите к файлу PDF, для которого вам нужно извлечь изображения.
Теперь он предоставит вам возможность выбрать, в каком формате вы хотите экспортировать файл PDF. Обязательно выберите « изображений ». Теперь внизу нажмите на « Экспорт всех изображений », и он извлечет все изображения из файла PDF. Вы также можете выбрать формат изображений.
Наконец, нажмите кнопку Export внизу и перейдите в то место, где вы хотите сохранить все извлеченные изображения.
Windows Snipping Tool — это инструмент, созданный Microsoft в виде утилиты для создания снимков экрана, включенный в Windows Vista и более поздние операционные системы. Вы можете делать снимки экрана открытого окна или любого объекта на экране, а затем комментировать, сохранять или публиковать изображение. Этот инструмент может быть очень полезен для извлечения изображений из файла PDF. Таким образом, вы можете легко сделать скриншоты изображений из файла PDF с помощью этого инструмента, а затем сохранить изображения.
Вы можете делать снимки экрана открытого окна или любого объекта на экране, а затем комментировать, сохранять или публиковать изображение. Этот инструмент может быть очень полезен для извлечения изображений из файла PDF. Таким образом, вы можете легко сделать скриншоты изображений из файла PDF с помощью этого инструмента, а затем сохранить изображения.
1. Нажмите Windows Key + S, чтобы открыть Windows Search, затем введите « Snipping Tool ».
2. Выберите режим, используя желаемую опцию, и сделайте снимок экрана с изображениями в PDF-файле.
3. Наконец, сохраняем изображение в папку из буфера обмена.
Есть несколько бесплатных веб-приложений PDF, которые вы можете использовать, если хотите извлечь много изображений из файлов PDF.
PDFAID
Перейдите на сайт pdfaid.com, затем выберите опцию « Извлечь изображения » и выберите « Выбрать файл PDF ». Теперь выберите формат изображения, который вам нужен для извлеченных изображений. Как только все будет сделано, нажмите « Извлечь изображения ».
Теперь выберите формат изображения, который вам нужен для извлеченных изображений. Как только все будет сделано, нажмите « Извлечь изображения ».
PDFcandy
Перейдите на сайт pdfcandy.com, затем выберите «Извлечь изображения», затем добавьте файлы PDF либо с помощью компьютера, либо вы можете добавить их с помощью Google Диска или Dropbox. После выбора файла PDF все изображения будут извлечены из файла PDF, и вы сможете загрузить их в виде zip-файла. Здесь у вас не будет возможности выбрать формат извлеченных изображений, но вы можете легко сохранить изображения на своем компьютере.
PDFdu
Перейдите на сайт pdfdu.com, и вы увидите все шаги по извлечению изображений из файла PDF. Вы также можете выбрать формат извлеченных изображений.
Adobe Photoshop также можно использовать для извлечения изображений из файла PDF. Просто выполните следующие действия, чтобы извлечь изображения:
1. Откройте Adobe Photoshop, затем откройте файл PDF, из которого вы хотите извлечь изображения.
Откройте Adobe Photoshop, затем откройте файл PDF, из которого вы хотите извлечь изображения.
2. Затем в диалоговом окне «Импорт PDF» выберите « изображений» и нажмите «ОК».
3. Теперь выберите изображения из PDF, которые хотите открыть в Photoshop. С помощью клавиши SHIFT вы можете открыть все изображения в Photoshop.
4. Теперь введите желаемое имя для каждого изображения и сохраните их, используя сочетание клавиш Ctrl + S. Вы также можете сохранить изображения в желаемом формате, и вы также можете внести любые изменения в изображение перед их сохранением.
PDFShaper
PDFShaper — это программное обеспечение, которое вы можете установить для выполнения определенных функций в вашем PDF-файле.Имеется как бесплатная, так и платная версия. Функция извлечения изображений доступна в бесплатной версии, поэтому бесплатная версия подойдет вам.
У него очень простой интерфейс, просто вы добавляете файл, и он извлекает все изображения. Вы также можете выбрать формат изображения с опцией, присутствующей в программном обеспечении.
Вы также можете выбрать формат изображения с опцией, присутствующей в программном обеспечении.
Конвертер PkPdf
PkPdfConverter — это бесплатное программное обеспечение, которое вы можете загрузить для работы, связанной с PDF. Он содержит различные опции, кроме извлечения изображения из PDF, например, преобразование PDF в слово и т. Д.
Просто скачайте zip-файл (8 МБ) и запустите его. Это установит это приложение на ваш компьютер. Теперь запустите приложение и добавьте файл для извлечения изображений из файлов PDF.
Рекомендовано:
Я надеюсь, что приведенные выше шаги были полезны, и теперь вы можете легко Извлечь изображения из файла PDF , , но если у вас все еще есть какие-либо вопросы относительно этого руководства, не стесняйтесь задавать их в разделе комментариев.
Как извлечь изображения из PDF
Если для вас открыт вопрос о том, как извлекать изображения из PDF, то эта статья поможет вам в этом.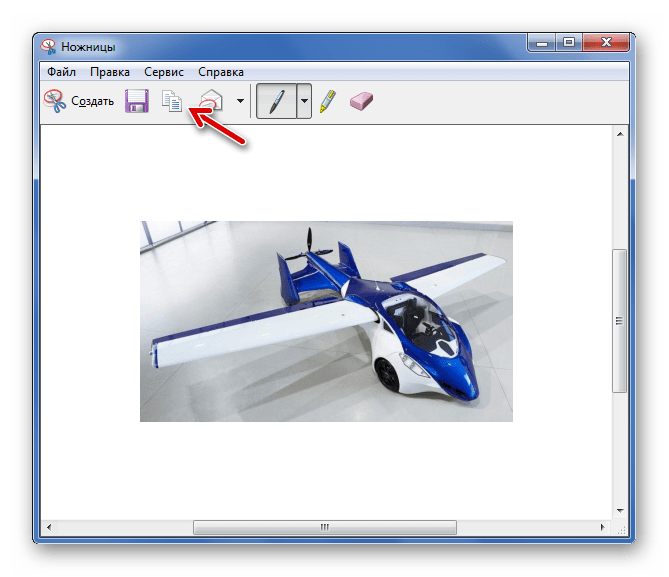 Информация постоянно меняется, будь то листовка сообщества, финансовый отчет компании или буклет с практическими рекомендациями. Наиболее распространенный и удобный способ обмена такой информацией — это формат переносимого документа или PDF. Чистый макет и ограничения на редактирование делают его идеальным для многоцелевого использования.
Информация постоянно меняется, будь то листовка сообщества, финансовый отчет компании или буклет с практическими рекомендациями. Наиболее распространенный и удобный способ обмена такой информацией — это формат переносимого документа или PDF. Чистый макет и ограничения на редактирование делают его идеальным для многоцелевого использования.
Однако бывают случаи, когда нам нужно извлечь изображения из PDF. Возможно, вы хотите сохранить инфографику для использования в будущем или отправить другу коллекцию изображений.Настройка этого формата затрудняет извлечение изображений из PDF.
Хотя некоторые пользователи могут пытаться делать снимки экрана, кадрировать и сохранять по одному изображению за раз, в этом нет необходимости. Инструмент «Извлечь изображения из PDF» от PDF Candy делает сохранение изображений быстрым и простым процессом. Читайте дальше и наслаждайтесь этим простым решением!
Основные возможности PDF Candy
Мы разработали инструмент для извлечения фотографий из PDF, чтобы он был максимально простым, легким и понятным. Нашей основной задачей были доступность и удобство использования, а также возможность извлекать изображения из файла PDF за считанные секунды.Прочтите, чтобы узнать о трех основных функциях инструмента для извлечения PDF-файлов и узнать, сколько времени и стресса вы можете сэкономить!
Нашей основной задачей были доступность и удобство использования, а также возможность извлекать изображения из файла PDF за считанные секунды.Прочтите, чтобы узнать о трех основных функциях инструмента для извлечения PDF-файлов и узнать, сколько времени и стресса вы можете сэкономить!
44 бесплатных онлайн-инструмента
Вы, вероятно, нашли несколько программ, которые могут превратить PDF в изображение во время поиска подходящего инструмента. Доступны похожие варианты, но они редко бывают удобными для пользователя. PDF Candy всегда доступен онлайн для простого и быстрого доступа с любого компьютера.
Допустим, вы работаете из дома в течение дня и оставили рабочий ноутбук в офисе.Вам необходимо извлечь изображения из PDF, чтобы создать PowerPoint. Хотите вернуться в офис, чтобы выполнить эту простую задачу? Мы предполагаем, что ответ на этот вопрос — твердое «нет».
Вместо этого вы можете рассчитывать на наш онлайн-сервис. Он может выполнять ту же работу, что и программное обеспечение, приобретенное вашей компанией, для повышения вашей производительности, но вам не нужно загружать программу или платить за ее использование. Если вы офисный работник, студент колледжа или просто хотите сохранить любимые фотографии, PDF Candy всегда готов вам помочь.
Совместимость с разными платформами и устройствами
Может быть сложно найти службу или приложение для извлечения изображений из PDF, которые подходят для вашего конкретного устройства и операционной системы. Многие программы и веб-сайты работают только с определенными устройствами. Независимо от того, используете ли вы устройства Windows, Mac, iOS или Android, вы, скорее всего, в тот или иной момент столкнулись с проблемами совместимости.
Это не проблема с нашим экстрактором PDF. Разработанный нами онлайн-сервис поддерживает файлы PDF со всех типов устройств и браузеров.Даже если у вас есть старый PDF-файл, который вы держали, PDF Candy может читать файл, быстро извлекать изображения из PDF и помещать их в удобный для сохранения формат.
Он также работает с PDF-файлами, хранящимися на других онлайн-платформах. Вы можете загружать изображения с Google Диска и Dropbox, выполнив быстрый и безопасный вход в свою учетную запись на соответствующей платформе. Будет проще, чем когда-либо, сохранять изображения на разных устройствах, в учетных записях и в общих проектах!
Сохранение изображений в исходном качестве и формате
Обычный обходной путь для сохранения изображений из файлов PDF — это сделать снимок экрана с нужным изображением.Скриншоты и инструменты для обрезки не только отнимают много времени, но и снижают качество изображения и позволяют сохранить его только в одном формате. Это заметный недостаток, особенно если вы повторно используете изображения для презентации, электронной почты или веб-сайта.
В отличие от этих опций, инструмент «Извлечь изображения из PDF» может извлекать исходные изображения из файлов PDF. Это означает, что у вас есть доступ к желаемому качеству, размеру и формату изображения. Это лучший способ обеспечить последовательность и кристально чистую загрузку.
Как извлекать изображения из PDF с помощью PDF Candy
Давайте обсудим, как завершить процесс онлайн с помощью нашего сервиса. Это быстро и легко сделать с помощью понятных инструкций на экране для справки. Чтобы продолжить, откройте инструмент «Извлечь изображения из PDF» на веб-сайте.
Шаг 1. Добавьте файл PDF
Сначала найдите PDF-файл, который вы хотите загрузить в PDF Candy. Его можно сохранить на вашем компьютере, на Google Диске или в Dropbox. Если PDF-файл уже сохранен на вашем устройстве, вы можете нажать зеленую кнопку «Добавить файл» и выбрать документ в браузере файлов.У вас также есть возможность перетащить файл PDF на веб-страницу.
Также доступныфайлов на Google Диске или Dropbox. У инструмента есть значок для каждой программы — щелкните один раз, какую из них вы хотите использовать. Вам будет предложено выполнить безопасный вход на платформу, где хранятся ваши файлы. Выберите файл PDF, и он будет загружен на веб-страницу PDF Candy.
Шаг 2: Извлечение изображений из PDF
После того, как вы загрузили PDF-файл, вам больше ничего не нужно делать.Процесс преобразования PDF в изображение начинается автоматически, и вам на короткое время будет показан экран загрузки, пока изображения будут извлечены. Обычно извлечение изображений из PDF занимает всего несколько секунд.
Шаг 3. Сохраните изображения одним щелчком мыши
Все изображения в PDF будут собраны и сохранены в одном архивном файле. Каждое изображение будет в исходном размере, четкости и формате. Просто нажмите зеленую кнопку «Загрузить файл», чтобы сохранить изображения на свое устройство.Если у вас предустановлен менеджер закачек, то с его помощью можно скачать zip-архив с изображениями. Вы также можете щелкнуть значки Google Диска или Dropbox, чтобы сохранить изображения в соответствующей учетной записи.
Как видите, с помощью PDF Candy легко и быстро извлекать изображения из файла PDF. Его всегда можно использовать бесплатно, и к нему можно получить доступ из любого браузера для максимального удобства и доступности. Вам не нужно загружать программу или беспокоиться о совместимости вашего устройства.
Мы рекомендуем вам попробовать сами и убедиться, насколько прост и удобен этот онлайн-инструмент. Если вы обнаружите, что хотите больше, чем извлекать изображения из PDF, на PDF Candy есть большой выбор других бесплатных инструментов. Мы также предлагаем программное обеспечение Windows для загрузки, когда вам нужно работать в автономном режиме. Мы надеемся, что это руководство было полезным. Независимо от того, извлекаете ли вы изображения для личного использования или для рабочих презентаций, мы знаем, что вы найдете этот инструмент удобным и простым в использовании.Спасибо за чтение — наслаждайтесь новыми картинками!
Как легко извлекать изображения PNG, JPEG, GIF, BMP из защищенного PDF
В большинстве случаев, когда мы читаем PDF-документы, такие как журналы, заметки, книги и т. Д., Мы можем найти интересные изображения и захотим их загрузить. Но иногда файл не дает нам соответствующих разрешений для извлечения изображения PDF. Однако основная причина, по которой пользователи не могут получить все изображения из PDF, связана с безопасностью i.е. файл ограничивает пользователя выполнять извлечение данных либо текста, либо изображений. Следовательно, чтобы сначала загрузить или извлечь изображения из защищенного PDF-файла, необходимо снять защиту файла, а затем использовать приложение для извлечения изображений из PDF-файла. В этом сообщении блога мы описали несколько решений, которые помогают пользователю извлекать изображения .png, .jpeg, .gif, .bmp и т. Д. Из PDF, но перед этим давайте узнаем, как сначала снять защиту с документа.
Надежное решение для снятия защиты PDF-файлов при извлечении изображенийКак известно, к файлам PDF можно применять два типа защиты: i.е. пароль или ограничения. Используя защиту паролем, мы запрещаем кому-либо открывать PDF-файлы, не применяя правильный пароль. С другой стороны, с ограничениями мы ограничиваем доступность файла, то есть человек не может изменять, копировать, распечатывать, извлекать, подписывать PDF. Но с помощью SysTools PDF Document Unlocker Tool можно легко удалить оба типа защиты. Инструмент легко удаляет известный пароль пользователя из PDF-документа и позволяет им сохранять документ в любом желаемом месте. Кроме того, как только инструмент разблокирует ограничения PDF, пользователи могут выполнять несколько задач с PDF.Теперь, после снятия ограничения на извлечение, получите все изображения из PDF-документов.
Решения для извлечения изображений PNG, JPEG, GIF, BMP из защищенных PDF-файловТеперь, после использования вышеупомянутого инструмента, выполните любой из следующих методов для извлечения изображения:
1- SysTools PDF Toolbox
2- Adobe Photoshop
3- Adobe Acrobat Reader DC
БЫСТРОЕ РЕШЕНИЕ
Если вы не хотите использовать два инструмента, один для разблокировки, а другой для извлечения, вы можете использовать SysTools PDF Image Extractor Tool.Он может извлекать изображения из заблокированных файлов (PDF-файлов, защищенных как владельцем, так и пользователем). В случае защищенного владельцем PDF (PDF с ограниченным доступом) пароль доступа не требуется.
Извлечение изображений JPEG, BMP, GIF, PNG из PDF с помощью профессионального инструментаЧтобы извлечь изображения из файлов PDF, выполните следующие действия:
1- Запустите и запустите программу PDF Toolbox
2- Выберите опцию Извлечь изображения из списка
3- Нажмите Добавить файлы / Добавить папку , чтобы вставить файлы PDF
4- Выберите место назначения и нажмите кнопку «Далее»
5- Выберите любой формат изображения для извлеченного изображения
6- Выберите страницы , из которых нужно извлечь изображение
7- Нажмите кнопку «Дополнительные настройки », чтобы управлять размером, шириной и высотой изображения
8- Просмотрите сводный отчет, содержащий все подробности, и нажмите кнопку запуска , чтобы начать процесс
Используйте Adobe Acrobat Pro DC для извлечения изображений из защищенного PDF-файлаAdobe Acrobat Pro DC позволяет пользователям получать все изображения из файлов PDF.Необходимо наличие платной версии инструмента, иначе с обычным Adobe Reader пользователи не смогут выполнить задачу:
1. Запустите Adobe Acrobat Pro DC и откройте файл PDF
.2. Выберите «Инструменты» и затем, , нажмите кнопку «Экспорт PDF». .
.3. Выберите изображение , а затем нужный формат изображения.
4. Установите флажок Экспортировать все изображения под параметрами.
5. Наконец, нажмите кнопку «Экспорт» и выберите место для сохранения изображений
Используйте Adobe Photoshop для получения всех изображений из PDFAdobe Photoshop предоставляет функциональные возможности для извлечения изображений из защищенного PDF-документа.Однако изображения могут иметь любой формат, например .jpeg, .png, .jpg, .bmp, .gif, если можно удалить любой тип изображения. Он включает в себя несколько простых шагов, а именно:
1- Во-первых, откройте документ PDF с помощью Adobe Photoshop
2- Затем появится диалоговое окно Импорт PDF
3- Щелкните опцию «Изображения» , чтобы извлечь изображения из PDF-файла
.4- Выберите изображения , которые вы хотите извлечь
5- Выберите Размер изображения и параметр страницы и нажмите кнопку ОК
6- После этого сохраните извлеченные изображения
ЗаключениеКак извлекать изображения из документов PDF становится наиболее распространенной потребностью среди пользователей, поскольку извлеченные изображения можно использовать в презентациях, создании веб-сайтов или для любых других целей.Более того, наряду с изображениями иногда пользователям также требуется извлечь данные из документа PDF . Но что, если файл защищен и пользователи хотят получить все изображения из файлов PDF. Поэтому, чтобы ответить на этот вопрос, мы обсудили лучшее решение, которое помогает пользователям извлекать изображения из защищенных файлов PDF. С помощью программного обеспечения, поставляемого SysTools , безопасность PDF-файлов может быть легко удалена, и как только файл получит незащищенные изображения, такие как PNG, JPEG, GIF, BMP, можно легко извлечь из него без каких-либо проблем.