Что такое Web Archive и как им пользоваться
Что такое Web Archive
В 1996 году американский предприниматель и активист Брюстер Кейл основал некоммерческую организацию Internet Archive («Архив интернета»). С тех пор она создаёт и хранит копии сайтов, а также книг, изображений и другого контента, который публикуется на открытых ресурсах Сети. Таким образом учредитель намерен сберечь международное культурное наследие.
Архив пополняют боты, сканирующие веб. Им помогают сотрудники и партнёры организации, среди которых множество библиотек и университетов. Кроме того, любой пользователь может загружать контент на серверы через официальный сайт организации. Содержимое архива доступно здесь же — бесплатно и для всех желающих.
Web Archive, также известный как Wayback Machine («Машина времени»), — это один из разделов на сайте Internet Archive. Здесь можно добавить новые или просмотреть уже загруженные копии веб-страниц.
Боты периодически обновляют данные. Но каждая очередная копия страницы не перезаписывает предыдущую, а сохраняется отдельно с указанием даты добавления. Поэтому с помощью Internet Archive можно посмотреть, как со временем менялись дизайн и наполнение выбранного сайта.
 Копия сайта Google, созданная 3 декабря 2000 года
Копия сайта Google, созданная 3 декабря 2000 годаБолее того, сохранённые копии остаются доступными, даже если оригинал исчезает из Сети. По этой причине Web Archive часто используют, чтобы просмотреть опубликованную информацию, которую пытаются стереть, или получить доступ к старым и уже неработающим сайтам.
С сервисом можно работать через сайт и официальное приложение Wayback Machine для iOS и Android.
Сейчас читают 🔥
Как посмотреть архивные копии страницы в Web Archive
Откройте сайт Web Archive или приложение сервиса. Если используете последнее, сразу после запуска создайте аккаунт.
Вставьте ссылку на нужную страницу и нажмите Enter (на сайте) или Overview of All Archives (в приложении).

Пролистайте календарь, чтобы найти подходящие копии. Дни, в которые бот создавал дубликаты страницы, отмечены кружками.

Нажмите на подходящую дату, чтобы просмотреть архивную копию.

Сайт также позволяет сравнивать две копии. Для этого на странице с календарём нажмите Changes, отметьте две даты и кликните Compare.

В результате Web Archive отобразит копии рядом и выделит несовпадения.

Как удалить копии ваших страниц из Web Archive или запретить их добавление
Если вы не желаете, чтобы копии вашего ресурса были в архиве, сообщите об этом администрации Internet Archive. Согласно официальной справке, для этого нужно отправить письмо на ящик [email protected], указав ссылку на свой сайт.
Скорее всего, вас попросят доказать факт владения ресурсом и объяснить причину удаления или запрета на добавление в архив. И да, писать лучше на английском.
Как добавить копию страницы в Web Archive
Чтобы не дожидаться, пока бот найдёт и сохранит нужную вам страницу, можете добавить её вручную.
Если используете сайт, перейдите в специальный подраздел. Вставьте ссылку на сохраняемую страницу и нажмите Save Page. Отметьте пункт Save error pages, если хотите, чтобы система архивировала в том числе страницы, которые не открываются из-за ошибок.

Если используете приложение, вставьте ссылку на нужную страницу и нажмите Archive Page Now.
Для быстрого добавления страниц можно также использовать расширения для десктопных браузеров. После установки достаточно открыть в браузере нужную ссылку, нажать на кнопку плагина и выбрать Save Page Now.

Цена: Бесплатно


Разработчик: Разработчик
Цена: Бесплатно
Читайте также 🌐🖥🌐
Вероятно, на Хабре не так много пользователей, кто никогда не слышал об «Архиве Интернета» (Internet Archive), сервисе, который занимается поиском и сохранением важных для всего человечества цифровых данных, будь то интернет-странички, книги, видео или информация иного типа.
Кто управляет Интернет-архивом, когда он появился и какова его миссия? Об этом читайте в сегодняшней «Справочной».
Зачем вообще нужен «Архив»?
Это далеко не только развлечение. Миссия организации — всеобщий доступ ко всей информации. «Интернет-архив» стремится бороться с монополией на предоставление информации со стороны как телекоммуникационных компаний (Google, Facebook и т.п.), так и государств.
При этом «Архив» является законопослушной организацией. Если по закону США какую-то информацию необходимо удалить, организация это делает.
«Архив Интернета» также служит инструментом работы ученых, спецслужб, историков (например, археографов) и представителей многих других сфер, не говоря уже об отдельных пользователях.
Когда появился «Интернет-архив»?
Создатель «Архива» — американец Брюстер Кейл, который создал компанию Alexa Internet. Оба его сервиса стали чрезвычайно популярными, оба они процветают и сейчас.
«Интернет-архив» начал архивировать информацию с сайтов и хранить копии веб-страниц, начиная с 1996 года. Штаб-квартира этой некоммерческой организации располагается в Сан-Франциско, США.
Правда, в течение пяти лет данные были недоступны для общего доступа — данные хранились на серверах «Архива», и это все, просмотреть старые копии сайтов могла лишь администрация сервиса. С 2001 года администрация сервиса решила предоставить доступ к сохраненным данным всем желающим.
В самом начале «Интернет-архив» был лишь веб-архивом, но затем организация начала сохранять книги, аудио, движущиеся изображения, ПО. Сейчас «Интернет-архив» выступает хранилищем для фотографий и других изображений НАСА, текстов Open Library и т.п.
На что существует организация?
«Архив» существует на добровольные пожертвования — как организаций, так и частных лиц. Можно предоставить поддержку и в биткоинах, кошелек 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. Этот кошелек, кстати, за все время существования получил 357.47245492 BTC, это примерно $2,25 миллиона по текущему курсу.
Как работает «Архив»?
Большинство сотрудников заняты в центрах по сканированию книг, выполняя рутинную, но достаточно трудоемкую работу. У организации три дата-центра, расположенных в Калифорнии, США. Один — в Сан-Франциско, второй — Редвуд Сити, третий — Ричмонде. Для того, чтобы избежать опасности потери данных в случае природной катастрофы или других катаклизмов, у «Архива» есть запасные мощности в Египте и Амстердаме.
Насколько велик сейчас “Архив”?
У «Интернет-архива» есть несколько подразделений, и у того, которое занимается сбором информации с сайтов, есть собственное название — Wayback Machine. На момент написания «Справочной» в архиве хранилось 339 миллиардов сохраненных веб-страниц. В 2017 году в «Архиве» хранилось 30 петабайт информации, это примерно 300 млрд веб-страниц, 12 млн книг, 4 млн аудиозаписей, 3,3 млн видеороликов, 1,5 млн фотографий и 170 тыс. различных дистрибутивов ПО. Всего за год сервис заметно «прибавил в весе», теперь «Архив» хранит 339 млрд веб-страниц, 19 млн книг, 4,5 млн видеофайлов, 4,7 млн аудиофайлов, 3,2 млн изображений разного рода, 381 тыс. дистрибутивов ПО.
Как организовано хранение данных?
Информация хранится на жестких дисках в так называемых «дата-нодах». Это серверы, каждый из которых содержит 36 жестких дисков (плюс два диска с операционными системами). Дата-ноды группируются в массивы по 10 машин и представляют собой кластерное хранилище. В 2016 году «Архив» использовал 8-терабайтными HDD, сейчас ситуация примерно такая же. Получается, что одна нода вмещает около 288 терабайт данных. В целом, еще используются жесткие диски и других размеров: 2, 3 и 4 ТБ.
В 2016 году жестких дисков было около 20 000. Дата-центры «Архива» оснащены климатическими установками для поддержания микроклимата с постоянными характеристиками. Одно кластерное хранилище из 10 нод потребляет около 5 кВт энергии.
Структура Internet Archive представляет собой виртуальную «библиотеку», которая поделена на такие секции, как книги, фильмы, музыка и т.п. Для каждого элемента есть описание, внесенное в каталог — обычно это название, имя автора и дополнительная информация. С технической точки зрения элементы структурированы и находятся в Linux-директориях.
Общий объем данных, хранимых «Архивом» составляет 22 ПБ, при этом сейчас есть место еще для 22 ПБ. «Потому, что мы параноики», — говорят представители сервиса.
Посмотрите на скриншот содержимого директории — там есть файл с названием, оканчивающимся на «_files.xml». Это каталог с информацией обо всех файлах директории.
Что будет с данными, если выйдет из строя один или несколько серверов?
Ничего страшного не произойдет — данные дублируются. Как только в библиотеке «Архива» появляется новый элемент, он тут же реплицируется и размещается на различных жестких дисках на разных серверах. Процесс «зеркалирования» контента помогает справиться с проблемами вроде отключения электричества и сбоях в файловой системе.
Если выходит из строя жесткий диск, его заменяют на новый. Благодаря зеркалируемой и редуплицируемой структуре данных новичок сразу же заполняется данными, которые находились на старом HDD, вышедшем из строя.
У «Архива» есть специализированная система, которая отслеживает состояние HDD. В день приходится заменять 6-7 вышедших из строя накопителей.
Что такое Wayback Machine?
Это лишь один из сервисов «Интернет-архива», который специализируется на сохранении веб-страниц. У сервиса есть собственный «паук», который регулярно обследует все доступные в сети сайты и сохраняет их на специализированных серверах. Чем популярнее веб-сайт, тем чаще робот копирует его содержимое. Если администратор ресурса не желает, чтобы информация сайта копировалась ботом, достаточно прописать запрет в файле robots.txt.
Популярные ресурсы копируются часто — практически ежедневно. Wayback Machine индексирует даже социальные сети, включая Twitter, Facebook
В 2017 году «Архив» запустил обновленный сервис Wayback Machine, пообещав более удобный доступ к сохраненным веб-страницам. Сервис был написан если не с нуля, то здорово переработан. Теперь он поддерживает ряд форматов файлов, которые ранее просто не сохранялись В том же 2017 году организация заявила, что каждую неделю ее сервера сохраняют около 1 млрд веб-страниц.
Так выглядел Twitter в 2007 году
Что еще можно найти в базе «Интернет-архива»?
Книги. Коллекция организации огромна, она включает оцифрованные книги, как распространенные, так и очень редкие издания. Книги сохраняются не только англоязычные, но и на многих других языках. У «Архива» есть специализированные центры по сканированию книг, всего таких центров 33, расположены они в пяти странах по всему миру.
В день сотрудники центров сканируют около 1000 книг. В базе сервиса содержатся миллионы изданий, работа по их оцифровке финансируется как обычными людьми, так и различными организациями, включая библиотеки и фонды.
С 2007 года «Интернет-архив» сохраняет в своей базе общедоступные книги из Google Book Search. После запуска, база книг быстро разрослась — в 2013 году насчитывалось уже более 900 тысяч книг, сохраненных из сервиса Google.
Один из сервисов «Архива» также предоставляет доступ к книгам, которые полностью открыты, таковых насчитывается уже более миллиона. Называется этот сервис Open Library.
Видео. Сервис хранит 4,5 млн роликов. Они разбиты по тематикам и имеют самую разную направленность. На серверах «Архива» хранятся фильмы, документальные фильмы, записи спортивных соревнований, ТВ-шоу и многие другие материалы.
В 2015 году «Архив» дал начало масштабному проекту — оцифровке видеокассет. Сначала речь шла о 40 тысячах кассет из архива Мэрион Стоукс, женщины, которая в течение многих десятилетий записывала на кассеты новости. Затем добавились и другие видеокассеты, которые присылали «Архиву» поклонники идеи оцифровки данных, важных для человечества.
Аудио. Аналогично видео, «Архив» хранит и аудиофайлы, которые также разбиты по тематикам. В прошлом году «Архив» начал реализовывать свой новый проект — расшифровку шеллачных пластинок, старейшего формата аудиозаписей. Звук сохранялся на пластинках из шеллака — природной смолы, которую выделяют самками червецов. Всего в архиве Great 78 Project несколько сотен тысяч пластинок.
Программное обеспечение. Конечно, хранить все созданное человечеством ПО просто невозможно, даже для «Архива». На серверах хранится винтаж — например, программы для Macintosh, ПО под DOS и прочий софт. В 2016 году сотрудники «Архива» выложили 1500+ программ под Windows 3.1, работать можно прямо в браузере. В 2017 Internet Archive выпустил архив софта для первых Macintosh.
Игры. Да, «Архив» предоставляет доступ к огромному количеству игр. В некоторые из них можно поиграть в среде браузерного эмулятора. Игры хранятся самые разные, в том числе, и с портативных аналогово-цифровых приставок. Есть игры под MS-DOS и консольные игры для Atari и ColecoVision.
Впервые архив старых игр организация выложила еще в 2013 году. Речь идет о тайтлах 30–40 летней давности, в которые можно было играть прямо в браузере. Это игры для приставок Atari 2600 (1977 года выпуска), Atari 7800 (1986 г.), ColecoVision (1982 г.), Philips Videopac G7000 (1978 г.) и Astrocade (1983 г.). Самое интересное, что Internet Archive добился того, что играть можно вполне легально. Сейчас коллекция насчитывает уже более 3400 игр и продолжает пополняться.
Веб-архив: импортозамещение / Хабр
Понадобилось найти старую версию одного сайта. В Wayback Machine (https://archive.org/web/) версии от нужной даты не оказалось, и я решил поискать альтернативные архивы интернетов. В основном находились сервисы, реализующие идею «вы нам дайте URL, а мы его заархивируем» (типа уважаемого мной http://archive.md), то есть совсем не то, что было нужно в данный момент.И тут вдруг находится искомое — http://web-arhive.ru/ Сначала порадовался за соотечественников, сделавших полезный сервис, но через несколько минут меня начали терзать смутные сомнения…
При внимательном рассмотрении даты создания снимков на archive.org и на web-arhive.ru оказались полностью совпадающими. Поковырявшись ещё, я сделал вывод, что web-arhive.ru представляет собой прокси: получает запрос, пересылает его на archive.org, парсит ответ, вычищает из него интерфейсные куски и все упоминания о Wayback Machine, меняет URL ссылок внутри на свои, заворачивает в собственный интерфейс и отдаёт ничего не подозревающему пользователю.
Интересно, как к этому отнесётся archive.org, когда узнает? Во втором абзаце правил использования сказано: «Access to the Archive’s Collections is provided at no cost to you and is granted for scholarship and research purposes only.»
Сайт выглядит так (с отключённым блокировщиком рекламы):
Смысл его существования, видимо, сводится к ссылке «Заверить сайт у нотариуса».
Также в глаза бросается нажористый шильдик «Зарегистрировано в Роспатент, рег №2016616556».
Стало любопытно почитать, что же там зарегистрировано, и…
РОССИЙСКАЯ ФЕДЕРАЦИЯ
ФЕДЕРАЛЬНАЯ СЛУЖБА ПО ИНТЕЛЛЕКТУАЛЬНОЙ СОБСТВЕННОСТИ
ГОСУДАРСТВЕННАЯ РЕГИСТРАЦИЯ ПРОГРАММЫ ДЛЯ ЭВМНомер регистрации (свидетельства): 2016616556
Дата регистрации: 15.06.2016
Номер и дата поступления заявки: 2016612809 29.03.2016
Дата публикации: 20.07.2016
Контактные реквизиты:
(8-473)222-67-48, [email protected]Авторы:
Седых Евгений Николаевич,
Дубинин Сергей ВикторовичПравообладатель:
Седых Евгений НиколаевичНазвание программы для ЭВМ:
Программный комплекс по доступу к архивным копиям сайтов в сети Интернет «Веб-архив.ру» версия 1.0Реферат:
Программный комплекс предназначен для доступа к архивным копиям страниц (сайтов) в сети Интернет, хранящимся в архиве Интернет, в том числе текста, фотоизображений, графических изображений, размещенных на страницах сайтов. Программный комплекс обеспечивает выполнение следующих функций: направление запроса к архиву Интернет в отношении архивной копии страницы, адрес которой задается пользователем в интерфейсе программного комплекса; получение ответа от архива Интернет о количестве, дате и времени архивных копий страницы, адрес которой задан пользователем; отображение архивной копии страницы в сети Интернет в интерфейсе браузера в том виде, в котором данная страница существовала на дату, выбранную пользователем из доступных дат; инициирование процедуры автоматической фиксации информации, отображаемой на архивной копии заданной страницы в виде графического образа (скриншота) заданной страницы.Тип реализующей ЭВМ: Сервер
Язык программирования: РНР
Вид и версия операционной системы: FreeBSD 8.3-STABLE
Объем программы для ЭВМ: 355 Мб
В принципе, всё честно написано про это чудо-ПО (вернее даже, целый программный комплекс, это вам не хрен собачий!) Ах, да, они ещё и скриншотик умеют делать. Ладно, хоть что-то новое от себя привнесли.
Можно было бы и не докапываться особо до них, но:
— они на первых местах в Гугле и Яндексе по запросам типа «веб архив», «архив сайтов», «архив интернета» (где-то сразу под archive.org, а где-то и вообще на первом месте),
— люди воспринимают web-arhive.ru как самостоятельный сервис (например, https://qna.habr.com/q/440257) и публикуют ссылки на архивные страницы на нём,
— разные SEO-информационные сайты говорят про от 600 до 2300 уникальных посетителей в день.
То есть, это не маргинальная фиговина в дальнем углу интернета, а что-то, путающееся у людей под ногами.
Так-то!
UPD
В комментариях жалуются на слово «импортозамещение» в заголовке.
Не воспринимайте его как «по заказу государства». Оно имелось в виду в ироничном смысле. Как по мне, один в один тот случай, когда на мониторах логотипы переклеивали.
как пользоваться, чем полезен [Инструкция]

Интернет в привычном для нас виде появился 36 лет назад — за это время он развивался семимильными шагами, а сайты тысячи раз меняли свой дизайн и контент. Web archive представляет собой своеобразную машину времени, которой может воспользоваться каждый пользователь.
Что такое Web Archive?
Это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
- узнать тематику сайта — архив интернета демонстрирует содержимое, благодаря чему легко определить нишу проекта;
- посмотреть, как выглядел сайт раньше — это находка для охотников за б/у доменами;
- определить, регистрировался ли до этого анализируемый домен — полезный инструмент для тех, кому принципиальна «стерильность» домена или для того чтобы избежать санкций поисковиков;
- восстановить свой сайт, если вы почему-то не сделали резервное копирование.
- отыскать уникальный контент — трудоемкая задача, которая может подарить вам десятки бесплатных статей;
- увидеть удаленный текст из закладок — шансы найти нужную страницу достаточно высоки.
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Как пользоваться веб-архивом?
Сервис очень удобный в применении. Пошаговая инструкция такова:
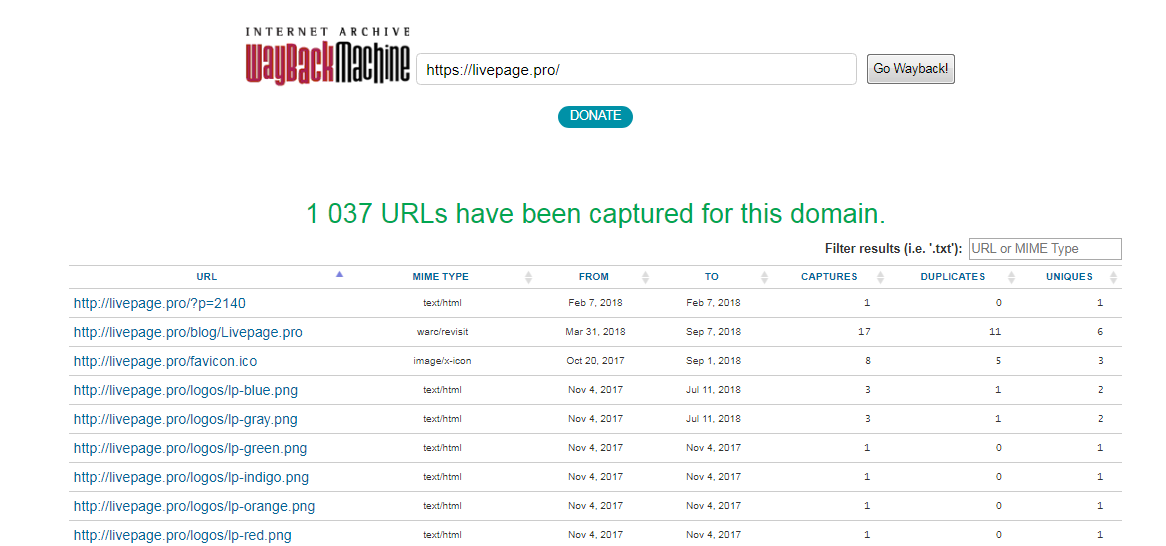
- Зайдите на главную страницу платформы.
- Введите в поле название интересующего вас сайта и нажмите Enter (в нашем случае это https://livepage.pro).

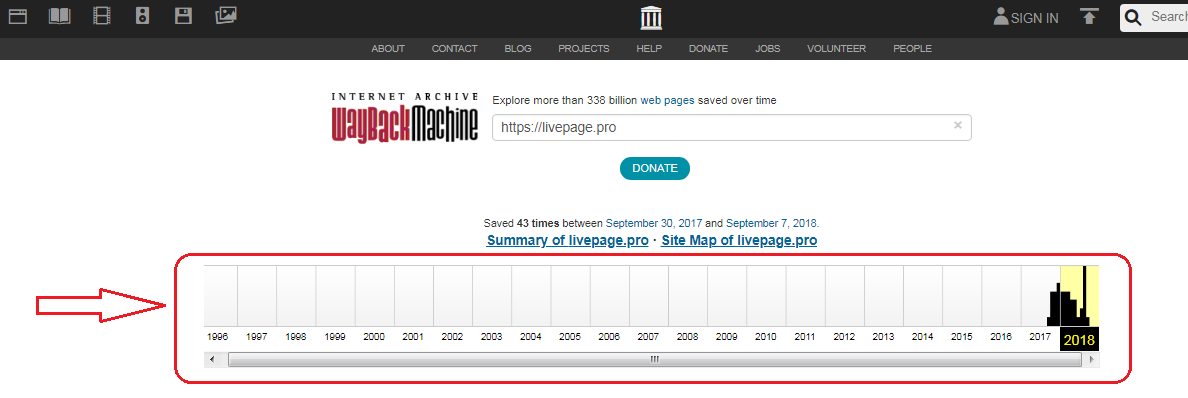
- Под указанным доменным именем демонстрируется основная информация: когда начинается история проекта, сколько слепков имеет сайт. В примере видно, что ресурс был впервые архивирован 30 сентября 2017 года, библиотека хранит его 43 архивные копии.
- Дальше мы обращаем внимание на календарь — голубым цветом в нем отмечены даты создания слепков.Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
- При желании можно получить общие данные о web-проекте — надо нажать на кнопку Summary над хронологической таблицей и календарем или же ознакомиться с картой сайта (кнопка Site Map).

 Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!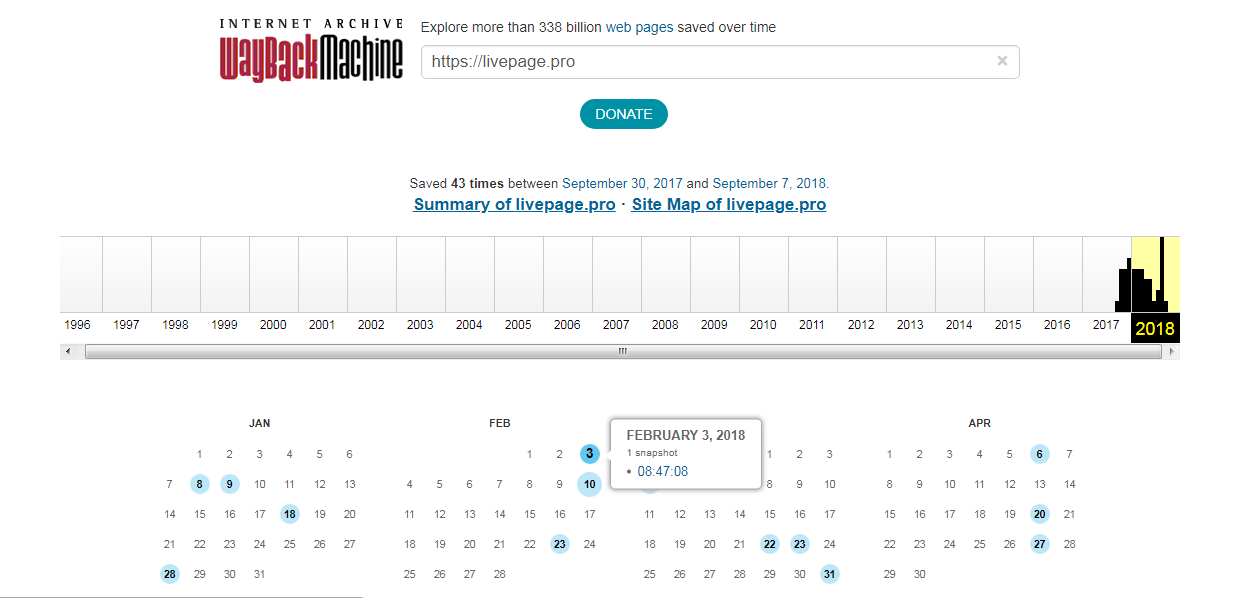


Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера
http://web.archive.org/web/*/http://url.
В нашем случае это
http://web.archive.org/web/*/https://livepage.pro.
Как восстановить сайт из веб-архива?
Плохая новость для тех, кто планирует просто найти архив сайта и скачать его привычным способом: страницы имеют вид статических html-файлов, к тому же их слишком много для того, чтобы заниматься этим вручную. Решить проблему можно при помощи специальных программ, к примеру, приложения на ruby. Необходимо лишь установить все на сервер и запустить восстановление страниц.
- Установите «Руби».
apt-get install ruby

- Добавьте саму программу, необходимую для работы.
gem install wayback_machine_downloader
- Запустите выкачивание сайта из web archive.

wayback_machine_downloader http://www.site.ru -timestamp 20131209110704
Для удобства можно указать отметку снапшота — утилита определит число страниц и выведет выкачиваемые файлы на консоль. После скачивания и сохранения мы получим набор статических данных.
- Разместите файлы в выбранной папке. Подойдет rsync:
rsync -avh./websites/www.site.com/ /var/www/site.com/
- Создайте конфигурацию в nginx и дождитесь обновления dns. На этом все!

Как восстановить сайт без бэкапа?
Вернуть ресурс из небытия можно даже без резервного копирования.
- Как уже говорилось раньше, можно восстановить сайт из веб-архива https://archive.org. Чтобы получить все страницы, введите в специальное поле имя ресурса с добавлением /* (https://livepage.pro/*). Здесь же предусмотрена возможность фильтрации файлов по подстроке в URL. Для скачивания файлов подойдут многие программы, например, Teleport Pro.
- Страницы интернет-проектов часто хранятся в кэше поисковых систем. По причине того что у каждого поисковика свои параметры, для лучшего эффекта промониторьте не только Google и Яндекс, но и Bing, Rambler:
http://www.google.ru/advanced_search
http://yandex.ru/search/advanced
http://www.bing.com/
http://nova.rambler.ru/srch/advanced
Войдите в режим расширенного поиска и укажите имя сайта. Получив результаты, кликайте по ссылкам «cached» или «копия».
- Если вы отдаете полный RSS, тогда стоит проверить еще и ридеры, агрегаторы.
Учтите!
Нужный вам проект может и не входить в архив сайтов интернета. Если вы его не нашли в библиотеке — значит, правообладатель потребовал удаления копий или же ресурс закрыли в соответствии с законом о защите интеллектуальной собственности. Возможен и другой вариант: через файл robots.txt был банально внесен соответствующий запрет.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
- Найдите подходящие вам блоги. Для этого следует зайти на Reg.ru и скачать оттуда список недавно освободившихся доменов.
- Посетите архив интернета с целью поиска сохраненных копий.
- Проверьте понравившиеся тексты через антиплагиат (контент может быть уже скопирован на другие сайты).
- Опубликуйте уникальные статьи на своем ресурсе.
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
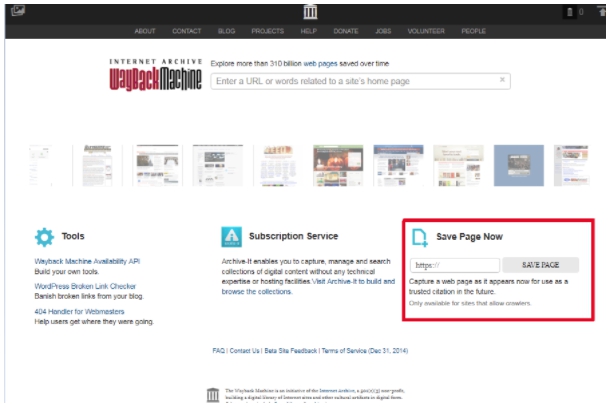
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.
Аналоги Webarchive
Альтернативой рассматриваемой в обзоре электронной библиотеке может стать:
Принцип работы тот же, как и у archive.org.
4.6 B 4.6B
14 декабря 2005 г. 12/05
по Аудио Сообщества
Вам предлагается просмотреть или загрузить аудио в коллекцию сообщества.Эти тысячи записей были предоставлены пользователями Архива и членами сообщества. Пожалуйста, выберите Creative Commons License во время загрузки, чтобы другие знали, что они могут (или не могут) делать с вашим аудио. Нажмите здесь, чтобы добавить свой аудио! Обзор по стилю: блюз, кантри, электронная, экспериментальная, хип-хоп, инди, джаз, рок, разговорное слово.
2,5 B 2,5 млрд
26 февраля 2005 г. 02/05
по Интернет-архив
Вам предлагается просмотреть или загрузить свои видео в коллекцию сообщества.Эти тысячи видео были предоставлены пользователями Архива и членами сообщества. Эти видео доступны для бесплатного скачивания. Пожалуйста, выберите Creative Commons License во время загрузки, чтобы другие знали, что они могут (или не могут) делать с вашим видео. Нажмите здесь, чтобы загрузить свое видео!
Тема: Moving Images
2 B 2.0B
18 января 2005 г. 01/05
по Интернет-архив
Эти книги — книги, предоставленные сообществом.Нажмите здесь, чтобы внести свою книгу! Для получения дополнительной информации и инструкций смотрите help.archive.org/hc/en-us/articles/360002360111-Uploading-A-Basic-Guide Uploaders, пожалуйста, обратите внимание: Archive.org поддерживает метаданные об элементах практически на любом языке, поэтому пока символы закодированы в UTF8 Поиск книг по языку: Afar Books Африкаанс Книги Akan Книги Албанский Книги Арабские Книги Армянские Книги Аймара Книги Азербайджан Книги Балочи Книги Бамбара …
Тема: Тексты
Коллекция американских библиотек включает в себя материалы, представленные со всей территории Соединенных Штатов.Учреждения варьируются от Библиотеки Конгресса до многих местных публичных библиотек. В целом, этот сборник материалов представляет фонды, охватывающие многие аспекты американской жизни и науки, в открытом доступе. Значительные части этой коллекции были щедро спонсированы Microsoft, Yahoo! Фонд Слоана и другие.
Сбор данных и различных средств массовой информации, пожертвованных отдельными лицами в Интернет-архив.
LibriVox — основана в 2005 году — это сообщество добровольцев со всего мира, которые записывают тексты общественного достояния: стихи, рассказы, целые книги, даже драматические произведения на разных языках. Все записи LibriVox находятся в свободном доступе в США и доступны для бесплатной загрузки в Интернете. Если вы не в США, пожалуйста, проверьте закон об авторских правах вашей страны перед загрузкой. Пожалуйста, посетите веб-сайт LibriVox, где вы можете искать книги, которые вас интересуют.Вы можете искать или …
Electric Sheep — это проект распределенных вычислений для анимации и развития фрактального пламени, которые, в свою очередь, распространяются на сетевые компьютеры, которые отображают их в качестве заставки. Процесс Процесс прозрачен для обычного пользователя, который может просто установить программное обеспечение в качестве заставки. Альтернативно, пользователь может стать более вовлеченным в проект, вручную создав файл фрактального пламени для загрузки на сервер, где он отображается в видеофайле анимированного фрактального пламени….
Рубрика: электрические овцы
524 М 524M
16 июня 2005 г. 06/05
по Интернет-архив Канады
Добро пожаловать на страницу канадских библиотек.Сканирующий центр в Торонто был создан в 2004 году на территории кампуса Университета Торонто. Internet Archive Canada с самого начала работала с более чем 250 учреждениями, предоставляя своим уникальным материалам открытый доступ и делясь этими коллекциями по всему миру. От архива сестер службы до Университета Альберты IAC оцифровывает более 600 000 уникальных текстов по состоянию на сентябрь 2019 года. Многие тексты / коллекции …
Тема: Тексты
Обзор: все артисты · этот день в истории · средний рейтинг отзывов · количество обзоров · дата просмотра · количество просмотров Live Music Archive — это сообщество, которое стремится предоставлять живые концерты высочайшего качества в формате без потерь, загружаемые в формате, наряду с удобством Поток по требованию.В 2002 году Интернет-архив объединился с etree.org, чтобы создать Архив живой музыки, чтобы сохранить и заархивировать как можно больше живых концертов для нынешнего и будущих поколений, чтобы …
Тема: Живая музыка
Изображения предоставлены пользователями интернет-архива и членами сообщества. Эти изображения доступны для бесплатного скачивания. Пожалуйста, выберите Creative Commons License во время загрузки, чтобы другие знали, что они могут (или не могут) делать с вашими изображениями.
Тема: картинки
Исследовательская библиотека Джона П. Робартса, обычно называемая библиотекой Робартса, является основной библиотекой гуманитарных и социальных наук Университета Торонто и крупнейшей отдельной библиотекой в университете. Открытая в 1973 году и названная в честь Джона Робарта, 17-го премьера Онтарио, библиотека содержит более 4,5 миллионов единиц книжной формы, 4,1 миллиона единиц микроформ и 740 000 других предметов.Здание библиотеки является одним из наиболее значительных примеров бруталистической архитектуры в …
Эти видео о религии и духовности были предоставлены пользователями Архива.
Калифорнийская цифровая библиотека поддерживает сбор и творческое использование мировых стипендий и знаний для библиотек Калифорнийского университета и сообществ, которые они обслуживают.Кроме того, CDL предоставляет инструменты, которые поддерживают создание информационных служб в Интернете для исследований, преподавания и обучения, включая службы, которые позволяют библиотекам UC эффективно обмениваться своими материалами и предоставлять больший доступ к цифровому контенту.
Фольксономия: система классификации, основанная на практике и методе совместного создания и управления тегами для аннотирования и категоризации контента; эта практика также известна как совместная маркировка, социальная классификация, социальная индексация и социальная маркировка.Созданный Томасом Вандером Уоллом, он является портом народного и таксономического искусства. Folksoundomy: коллекция звуков, музыки и речи, полученных в результате усилий добровольцев, чтобы сделать информацию как можно более доступной. Потому что …
Добро пожаловать в коллекцию Netlabels в интернет-архиве. Эта коллекция содержит полные, свободно загружаемые / потоковые, часто лицензированные Creative Commons каталоги «виртуальных лейблов».Эти «сетевые метки» являются некоммерческими организациями, созданными сообществом и предназначенными для предоставления высококачественной, некоммерческой, свободно распространяемой музыки в формате MP3 / OGG для онлайн-загрузки во множестве жанров. Стили включают в себя: мелодическую электронику (например, онлайн-обсерваторию, пожалуйста, сделайте что-нибудь) минимальный дом (…
(1 отзывов)
201 M 201M
26 февраля 2005 г. 02/05
по Интернет-архив
Художественные фильмы, шорты, немые фильмы и трейлеры доступны для просмотра и загрузки.Наслаждайтесь! Просмотр списка всех художественных фильмов, отсортированных по популярности. Вы хотите опубликовать художественный фильм? Во-первых, выясните, является ли это общественным достоянием. Прочтите этот FAQ, чтобы определить, является ли что-то PD Если вы все еще не уверены, опубликуйте вопрос на форуме ниже с как можно большей информацией о фильме. Один из наших пользователей может иметь соответствующую информацию.
Тема: Moving Images
Сканированные книги из разных европейских библиотек.
Смотрите тысячи фильмов из архива Прелингера! Prelinger Archives был основан в 1983 году Риком Прелингером в Нью-Йорке. За следующие двадцать лет он вырос в коллекцию из более чем 60 000 «эфемерных» (рекламных, образовательных, промышленных и любительских) фильмов. В 2002 году коллекция фильмов была приобретена Библиотекой Конгресса, Отделом кинематографии, радиовещания и звукозаписи. Prelinger Archives остается в наличии, храня около 11 000 оцифрованных и…
Программы в & nbsp; Архив новостей ТВ для исследовательских и образовательных целей. Программы позволяют пользователям осуществлять поиск в коллекции телевизионных новостных программ, начиная с 2009 года, в исследовательских и образовательных целях, таких как проверка фактов. Пользователи могут просматривать короткие клипы, делиться ссылками на индивидуальные короткие цитаты, вставлять собственные короткие цитаты или брать копию полной программы.
(1 отзывов)
Документы США по патентам и товарным знакам предоставлены Фондом Think Computer Foundation.
Тема: Патент США
Элементы, включенные в службу поиска телевизионных новостей. Часть ТВ Новости Архив.
Kodi (ранее XBMC) — это бесплатное программное обеспечение с открытым исходным кодом для медиаплеера, разработанное XBMC Foundation, некоммерческим технологическим консорциумом. Kodi доступен для нескольких операционных систем и аппаратных платформ с программным 10-футовым пользовательским интерфейсом для использования с телевизорами и пультами дистанционного управления.Он позволяет пользователям воспроизводить и просматривать большинство потоковых мультимедиа, таких как видео, музыка, подкасты и видео из Интернета, а также все обычные цифровые медиафайлы из локального и сетевого хранилища …
143,3 М 143M
27 марта 2004 г. 03/04
по Благодарный мертвец
Обзор: это только в · потоковое (SBD) шоу · загружаемые (AUD) шоу · этот день в истории · средний рейтинг отзывов · количество обзоров · дата просмотра · количество просмотров · поисковые форумы Созданная в 2004 году, эта коллекция состоит из аудитории и дека записи.Нередко можно найти несколько версий одного шоу. Для получения дополнительной информации смотрите FAQ. Коллекция Grateful Dead в настоящее время не открыта для публичной загрузки. Поиск шоу: Загружаемые шоу — обычно …
Тема: благодарные покойники, джем, рок, Джерри Гарсиа
Вдохновляющие открытия благодаря свободному доступу к знаниям о биоразнообразии. | Библиотека наследия биоразнообразия улучшает методологию исследований, совместно делая литературу по биоразнообразию, открыто доступную миру, как часть глобального сообщества биоразнообразия.БХЛ также служит основополагающим литературным компонентом Энциклопедии Жизни. Библиотека наследия биоразнообразия (BHL) — это консорциум библиотек естествознания и ботаники, которые сотрудничают в целях оцифровки наследия литературы …
Фольксономия: система классификации, основанная на практике и методе совместного создания и управления тегами для аннотирования и категоризации контента; эта практика также известна как совместная маркировка, социальная классификация, социальная индексация и социальная маркировка.Созданный Томасом Вандером Уоллом, он является портом народного и таксономического искусства. Folkscanomy: коллекция книг и текстов, полученных в результате усилий добровольцев, чтобы сделать информацию как можно более доступной. Потому что …
Коллекция Vintage Software объединяет различные усилия групп для классификации, сохранения и предоставления исторического программного обеспечения. Эти старые программы, многие из которых работают на устаревшем и редком оборудовании, предназначены для изучения, обучения и исторической справки.
Коллекция программ APK (Android Package), загруженных различными пользователями.
Internet Arcade — это сетевая библиотека аркадных (монетных) видеоигр с 1970-х по 1990-е годы, эмулированная в JSMAME, являющейся частью программного пакета JSMESS. Аркада, содержащая сотни игр самых разных жанров и стилей, предлагает исследования, сравнение и развлечения в сфере видеоигр.Коллекция игр варьируется от ранних видеоигр «бронзового века» с черно-белыми экранами и простыми звуками до крупномасштабных …
Вы приглашены послушать и скачать радио-шоу Old Time здесь! Просмотр по: количеству просмотров · среднему рейтингу отзывов · количеству отзывов · дате проверки · дате в архиве & middot; тема
Существует два основных способа продвижения ваших сайтов в поисковых системах; хотя PPC (оплата за клик) рекламы или через SEO (поисковая оптимизация). Хотя PPC и SEO совершенно разные, если все сделано правильно, они оба достигают одного и того же результата. В результате люди приходят на ваш сайт и видят, что вы предлагаете. Неважно, если вы что-то продаете, являетесь партнером по маркетингу или просто хотите, чтобы трафик на ваш блог; Все сайты нуждаются в трафике, чтобы быть успешными.
Почему же некоторые интернет-маркетологи не верят, что SEO — это маркетинг? Если владелец веб-сайта использует PPC для привлечения трафика на свой веб-сайт, никто не усомнится в том, что показ рекламы на платформе PPC является формой маркетинга. Почему же тогда люди задаются вопросом, является ли получение сайта в верхней части результатов поисковой системы естественным путем с помощью SEO, является маркетингом или нет? Давайте рассмотрим 6 возможных причин для этого.
1. SEO не мгновенное
Причина номер один, почему SEO не считается маркетингом, заключается в том, что нет мгновенной выгоды.С помощью PPC-маркетинга или других форм онлайн-маркетинга вы можете получить довольно быстрые результаты вскоре после запуска процесса. К сожалению, поисковая оптимизация — это процесс, который требует времени и времени, а не того, что у людей много.
Еще одна проблема, связанная с тем, что SEO не является мгновенной, это деньги. Если у новой компании небольшой бюджет, у нее не будет тонны денег для инвестирования в SEO. Это не обязательно означает, что компания или отдел маркетинга считают, что SEO не является формой маркетинга, но иногда это не вариант, независимо от того, как люди к нему относятся.
2. Нет «рекламы»
Когда маркетолог использует рекламу PPC, Facebook, баннер или даже печатную рекламу, есть физическое доказательство рекламы. В SEO единственным физическим доказательством является результат поиска, который в начале процесса SEO может содержать несколько десятков страниц в результатах поиска. Иногда для того, чтобы маркетолог чувствовал, что он действительно продает, нужна физическая реклама.
3. Интенсивные работы
Как мы упоминали ранее, в SEO нет ничего мгновенного или быстрого, и, кроме того, это требует много работы.Это идет вразрез с быстрыми и мощными решениями, которые большинство интернет-маркетологов либо проповедуют, либо утверждают, что могут достичь их в наши дни.
4. Отслеживание
С SEO вы получите миллион статистики. Маркетологи не хотят тратить большую часть своего времени, просматривая цифры и пытаясь понять, что они все значат. Маркетологи еще раз хотят, чтобы результаты были быстрыми и простыми. Проводить дни, просматривая статистику трафика, ключевые слова и контент, который люди читают больше всего, — это не прогулка в парке.
5. Бахвальство
Похоже, миллионы маркетологов кричат миру, как много они знают и насколько они хороши в маркетинге. Вы не часто слышите, как миллионы людей говорят, что они хороши в SEO. Значит ли это, что SEO не маркетинг? Нет, это означает, что SEO является более сложной задачей и требует больше времени, и поэтому права на хвастовство не одинаковы. И, между прочим, если вы слышите, как кто-то говорит, что он может получить ваш сайт на первой позиции в Google по вашим ключевым словам за 24 часа … вы можете поставить под сомнение это утверждение.
6. Вы не можете научить этому в течение одного часа семинара
Это не значит, что нужно копать в онлайн-маркетингу, это простая истина. Мы любим маркетинг так же, как и любую другую компанию, но SEO — это постоянный процесс, который человек не может освоить за час. Конечно, есть много семинаров и конференций по SEO, но они не предназначены для того, чтобы другие люди узнали, как оптимизировать сайт за час или меньше.
SEO — это интернет-маркетинг; это просто другая форма онлайн-маркетинга.Для некоторых компаний реклама PPC лучше, а для других — SEO. Это действительно зависит от вашей конкретной ситуации, вашего времени и вашего бюджета.
,Интернет-архив: об ИА
Интернет-архив, 501 (с) (3) некоммерческая, строит цифровая библиотека интернет-сайтов и других культурных артефактов в цифровом виде. Как и бумажная библиотека, мы предоставляем бесплатный доступ исследователям, историкам, ученые, печать отключена, и широкая публика. Наша миссия — предоставить Универсальный доступ ко всем Знание.
Мы начали в 1996 году с архивирования самого Интернета, который был просто начинает расти в использовании.Как и газеты, контент, опубликованный в Интернете, был эфемерный — но в отличие от газет, никто не спасал его. Сегодня у нас 20+ лет веб-истории, доступной через Wayback Machine, и мы работаем с библиотекой 625+ и другими партнерами в рамках нашей программы Archive-It span>, чтобы определить важные веб-страницы.
По мере роста нашего веб-архива росло и наше стремление предоставлять цифровые версии других опубликованных работ. Сегодня наш архив содержит:
Любой, у кого есть бесплатный аккаунт, может загрузить медиа в интернет архив.Мы работаем с тысячами партнеров по всему миру, чтобы сохранить копии своих работ в специальные коллекции.
Поскольку мы библиотека, мы уделяем особое внимание книгам. Не у всех есть доступ к публичной или академической библиотеке с хорошей коллекцией, чтобы обеспечить Универсальный доступ нам нужен для предоставления цифровых версий книг. Мы начали программа оцифровки книг в 2005 году, и сегодня мы сканируем 1000 книг в день за 28 места по всему миру. Книги, изданные до 1923 года, доступны для скачать, и сотни тысяч современных книг можно взять на нашем сайте Open Library.Некоторые из наших оцифрованных Книги доступны только для печати отключены.
Как и Интернет, телевидение также является эфемерной средой. Мы начали архивирование телевизионные программы в конце 2000 года, и наш первый публичный телевизионный проект был архив телевизионных новостей, окружающих события 11 сентября 2001 года. В 2009 году мы начали делать избранные США. телевизионные новостные трансляции с возможностью поиска по субтитрам в нашем архиве телевизионных новостей. Эта услуга позволяет исследователи и общественность, чтобы использовать телевидение в качестве цитируемой и разделяемой ссылка.
Интернет-архив обслуживает миллионы людей каждый день и является одним из лучших 300 веб-сайтов в мире. Единственная копия библиотеки Интернет-архива Коллекция занимает более 45 петабайт серверного пространства (и мы храним не менее 2 копии всего). Мы финансируем за счет пожертвований, грантов и предоставления веб услуги по архивированию и оцифровке книг для наших партнеров. Как и в большинстве библиотеки мы ценим конфиденциальность наших клиентов, поэтому мы избегаем сохраняя IP (интернет-протокол) адреса наших читателей и предлагая наш сайт в протоколе https (безопасный).
Вы можете найти информацию о наших проектах в нашем блоге (включая важные объявления), связаться с нами, купить swag в нашем магазине и подписаться на нас в Twitter и Facebook. Добро пожаловать в библиотека!
Недавнее финансирование фонда щедро предоставлено ::
.- Домашняя страница
Тестирование
- Назад
- Agile Тестирование
- BugZilla
- Огурец
- тестируется
- Тестирование JIRA
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Mobile Тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Quality Center (ALM)
- RPA
- SAP Тестирование
- Selenium
- SoapUI
- Test Management
- TestLink
SAP
- Назад
- ABAP
- APO
- Новичок
- Базис
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- HMS
- кристалл
- кристаллов
- 50005 кристаллов кристаллов
- QM
- Расчет заработной платы
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Solution Manager
- Successfactors
- SAP Обучение
веб
- Назад
- Apache
- Android
- AngularJS
- ASP.Чистая
- C
- C #
- C ++
- CodeIgniter
- СУБД
- Назад
- Java
- JavaScript
- JSP
- Kotlin
M000
- Back
- Perl
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL5000
- SQL000
- UML
- VB.Net
- VBScript
- Веб-сервисы
- WPF
Необходимо учиться!
- Назад
- Учет
- Алгоритмы
- Blockchain
- Бизнес-аналитик
- Сложение Сайт
- CCNA
- Cloud Computing
- COBOL
- Compiler Design
- Embedded Systems
- Назад
- Ethical Hacking
- Excel Учебники
- Go Программирование
- IoT
- ITIL
- Дженкинс
- MIS
- Networking
- Операционная система
- Prep
- Назад
- PMP
- Photoshop Управление
- Проект
- Отзывы
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Складирование данных 000000000 HBB