Обзор дедупликации данных | Microsoft Docs
- Чтение занимает 2 мин
В этой статье
Область применения: Windows Server 2022, Windows Server 2019, Windows Server 2016
Что такое дедупликация данных
Дедупликация данных, часто называемая дедупликацией, — это функция, которая помогает снизить влияние избыточных данных на затраты на хранение. Если дедупликация данных включена, она оптимизирует свободное место в томе за счет проверки данных тома на наличие дублирующихся частей. Дублирующиеся части набора данных тома сохраняются один раз и (при необходимости) сжимаются для дополнительной экономии. Дедупликация оптимизирует избыточные данные, не нарушая достоверность или целостность данных.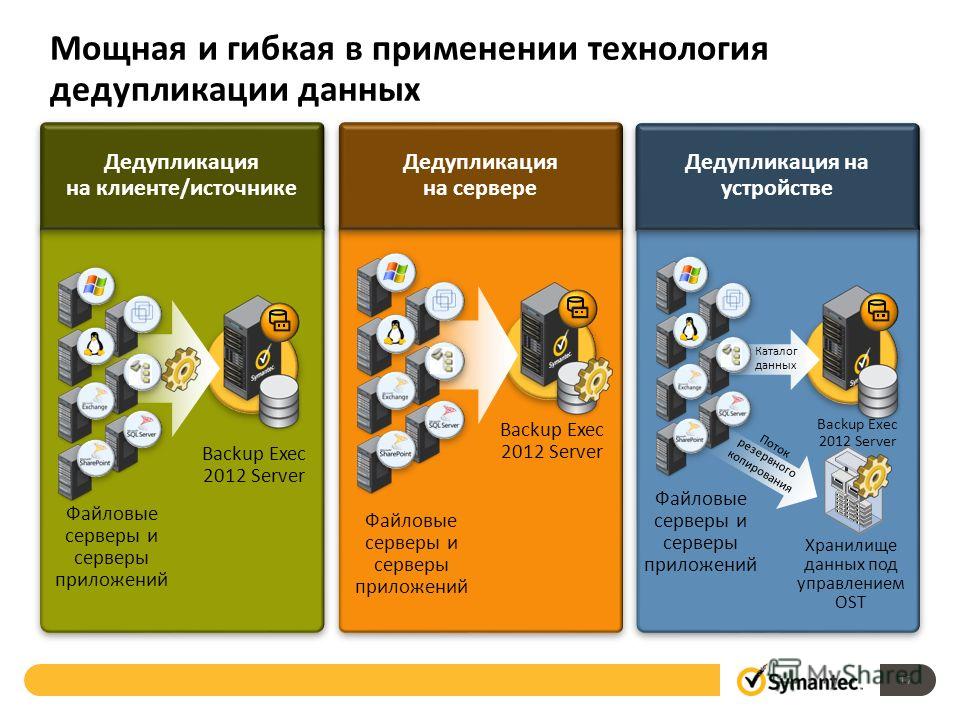
Важно!
KB4025334 содержит сведение исправлений для дедупликации данных, включая важные исправления надежности, и настоятельно рекомендуется устанавливать его при использовании дедупликации данных с Windows Server 2016 и Windows Server 2019.
Преимущества дедупликации данных
Дедупликация данных помогает администраторам хранилища снизить затраты, связанные с дублирующимися данными. Большие наборы данных часто имеют массу дублирования, что увеличивает затраты на хранение данных. Пример:
- Файловые ресурсы пользователей могут содержать множество копий одних и тех же или похожих файлов.
- Гостевые службы виртуализации могут практически не отличаться от служб на виртуальных машинах.
- Моментальные снимки резервных копий могут иметь минимальные отличия от ежедневных.

Экономия места, которую может обеспечить дедупликация данных, зависит от набора данных или рабочей нагрузки в томе. В наборах данных с высоким уровнем дупликации скорость оптимизации достигает 95 %, а объем использования службы хранилища может уменьшаться в 20 раз. В следующей таблице представлены типичные значения экономии за счет дедупликации для разных типов содержимого.
| Сценарий | Содержимое | Обычная экономия пространства |
|---|---|---|
| Документы пользователя | Документы Office, фотографии, музыка, видео и т. д. | 30-50 % |
| Общие ресурсы развертывания | Двоичные файлы программного обеспечения, CAB-файлы, символы и т. д. | 70–80 % |
| Библиотеки виртуализации | Образы ISO, файлы виртуальных жестких дисков и т. д. | 80–95 % |
| Файловый ресурс общего доступа | Все вышеперечисленное | 50–60 % |
Примечание
Если вы просто хотите освободить место на томе, рассмотрите возможность использования Синхронизация файлов Azure с включенным распределением по уровням облака. Благодаря этому вы сможете кэшировать часто используемые файлы локально и распределять редко используемые файлы по уровням облака, сохраняя пространство в локальном хранилище и поддерживая производительность. Дополнительные сведения см. в статье Планирование развертывания Синхронизации файлов Azure.
Благодаря этому вы сможете кэшировать часто используемые файлы локально и распределять редко используемые файлы по уровням облака, сохраняя пространство в локальном хранилище и поддерживая производительность. Дополнительные сведения см. в статье Планирование развертывания Синхронизации файлов Azure.
Когда можно использовать дедупликацию данных
| Файловые серверы общего назначения Файловые серверы общего назначения представляют собой файловые серверы для общего использования, которые могут содержать общие папки любого типа из перечисленных далее:
 От дедупликации данных выигрывают общие ресурсы для разработки программного обеспечения, так как многие двоичные файлы остаются по сути неизменными от сборки к сборке. От дедупликации данных выигрывают общие ресурсы для разработки программного обеспечения, так как многие двоичные файлы остаются по сути неизменными от сборки к сборке. | |
| развертывания инфраструктура виртуальных рабочих столов (VDI) Благодаря серверам VDI, таким как службы удаленных рабочих столов, организации получают упрощенный способ подготовки настольных компьютеров для пользователей. Эта технология подходит для организаций по многим причинам.
 | |
| Целевые объекты резервного копирования, такие как виртуализированные приложения резервного копирования приложения резервного копирования, такие как Microsoft Data Protection Manager (DPM), являются отличным кандидатом к дедупликации данных из-за значительного дублирования моментальных снимков резервных копий. | |
| Другие рабочие нагрузки К другим рабочим нагрузкам также можно применять дедупликацию данных. |

Дедупликация данных — это… Что такое Дедупликация данных?
Дедупликация данных — это технология, при помощи которой обнаруживаются и исключаются избыточные данные в дисковом хранилище. Например, путем замены повторных копий данных ссылками на первую копию. Это позволяет сократить объёмы физических носителей для хранения тех же объёмов данных.
Простой пример: при использовании централизованной корпоративной почтовой системы когда сотрудник отправляет письмо с вложенным файлом размером 1 МБ двум своим коллегам, это письмо сохраняется 1) в папке «Исходящие» отправителя, 2) в папке «Входящие» двух получателей, 3) все это дублируется в резервной копии базы данных (как минимум в одной).
Использование дедупликации данных активно развивается в области хранения данных резервного копирования, как среди аппаратных устройств (NetApp VTL и Nearstore, EMC Data Domain), так и для программных решений (Symantec Backup Exec 2010, и др.), так как, зачастую, в результате сохранения резервных копий, на устройствах хранения оказываются практически идентичные по содержимому файлы с минимальными изменениями в них. Использование дедупликации позволяет не только экономить пространство хранения, но и увеличивать скорость сохранения и восстановления данных, за счет меньшего объема считывания-записи данных резервных копий.
Другим активно развивающимся направлением, получающим большие выгоды от использования дедупликации, являются системы серверной виртуализации, так как содержимое множества образов виртуальных машин зачастую идентично на 80-90 и более процентов (одна и та же версия OS, с идентичным набором системных файлов, service packs и patch level). На сегодня пока только системы хранения компании NetApp, использующие внутреннюю файловую систему WAFL имеют возможность реализовать дедупликацию на оперативных, primary хранилищах данных, без значительного негативного эффекта на их производительность. Использование дедупликации NetApp для хранилищ данных и образов виртуальных машин зачастую позволяет снизить хранимые объемы на 80-90 %, без заметного снижения производительности, а, в ряде случаев, и повышает ее, так как дедуплицированный набор данных занимает меньше пространства в кэш-памяти системы хранения, и позволяет поместить в кэш значительно большие, чем без дедупликации, объемы данных.
На сегодня пока только системы хранения компании NetApp, использующие внутреннюю файловую систему WAFL имеют возможность реализовать дедупликацию на оперативных, primary хранилищах данных, без значительного негативного эффекта на их производительность. Использование дедупликации NetApp для хранилищ данных и образов виртуальных машин зачастую позволяет снизить хранимые объемы на 80-90 %, без заметного снижения производительности, а, в ряде случаев, и повышает ее, так как дедуплицированный набор данных занимает меньше пространства в кэш-памяти системы хранения, и позволяет поместить в кэш значительно большие, чем без дедупликации, объемы данных.
Ссылки
8 мифов о дедупликации / Хабр
Пришло время рассмотреть все мифы и узнать где правда в вопросах дедупликации для массивов данных.
Несмотря на то, что технология дедупликации известна уже достаточно давно, но только сейчас технологии, применяемые в современных массивах данных, позволили ей пережить второе рождение. Во всех современных массивах данных на текущий момент используется дедупликация, но наличие этой функции в массиве еще не значит, что это даст весомые преимущества именно под ваши данные.
Во всех современных массивах данных на текущий момент используется дедупликация, но наличие этой функции в массиве еще не значит, что это даст весомые преимущества именно под ваши данные.
К сожалению, большое количество администраторов принимают «на веру» и считают, что дедупликация обладает безграничными возможностями.
Не важно, являетесь ли вы администратором системы хранения уровня tier-1, архивного хранилища или all-flash гибридных систем хранения, вам будет интересно пройтись по мифам и легендам дедупликации, чтобы избежать досадных ошибок при проектировании или работе с вашими системами хранения.
Коэффициент сокращения данных: чудес не бывает
В то время как дедупликация стала доступна как для массивов, хранящих ваши продуктивные данные, так и для массивов, хранящих резервные копии данных, коэффициент дедупликации на этих массивах может быть совершенно разным. Архитекторы очень часто полагают, что коэффициент, достигнутый на архивном массиве, можно применить и к продуктивному хранилищу.
Дедупликация — это автоматический процесс, существующий на многих массивах известных производителей, но потенциальный коэффициент, который вы можете получить, отличается у массивов разного типа. В результате, например, если вам будет нужен массив на 100ТБ, а вы будете считать коэффициент 10:1, то и приобретете хранилище под 10ТБ, или, скажем, если вы будете оценивать коэффициент как 2:1, следовательно, приобретете хранилище на 50ТБ – в итоге, эти совершенно разные подходы, приводят к совершенно разной стоимости покупки! Вы должны на практике понять какой коэффициент вы можете получить на ваших продуктивных данных, прежде чем сделать выбор в пользу определенной модели с определенным объемом.
Строя конфигурации массивов данных под различные задачи оперативного хранения и резервного хранения, часто приходится сталкиваться со сложностями в правильном определении коэффициента дедупликации. Если вам интересны тонкости архитектурного дизайна массивов под дедупликацию, эта дискуссия для вас.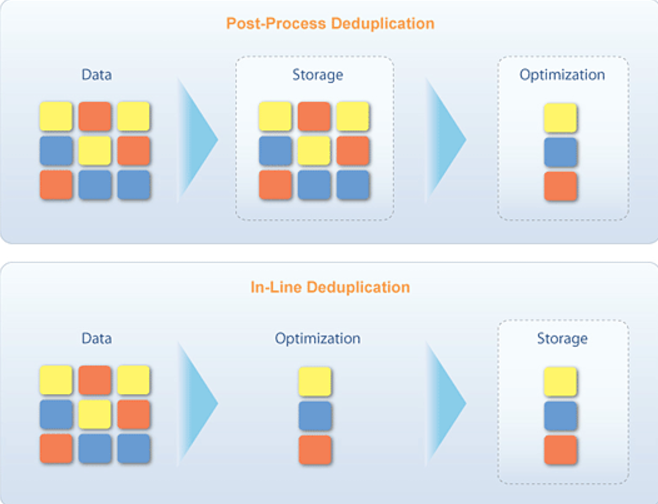
Как минимум, понимание на базовом уровне 8 мифов, приведенных далее, позволит вам осознанно понять дедупликацию и оценить ее коэффициент для ваших данных.
Миф1. Больший коэффициент дедупликации дает больше преимуществ для хранения данных
Верно ли утверждение, что если один вендор предлагает коэффициент дедупликации 50:1 это в пять раз лучше альтернативного предложения 10:1? Нужно проверять и сравнивать совокупную стоимость влдения! Дедупликация позволяет сократить требования к ресурсам, но какова потенциальная экономия объема? 10:1 позволяет уменьшить размер хранимых данных (reduction ratio) на 90%, в то время как коэффициент в 50:1 увеличивает этот показатель на 8% и дает 98% reduction ratio (см. график ниже). Но это только 8% разницы…
В целом, чем выше коэффициент дедупликации, тем меньше преимуществ по уменьшению объема данных, согласно закону убывающей доходности. Объяснение смысла закона убывающей доходности может быть таким: дополнительно применяемые затраты одного фактора (например, коэффициента дедупликации) сочетаются с неизменным количеством другого фактора (например, объема данных). Следовательно, новые дополнительные затраты на текущем объеме дают всё меньшую экономию ресурсов.
Следовательно, новые дополнительные затраты на текущем объеме дают всё меньшую экономию ресурсов.
К примеру, у вас есть офис, в котором работают клерки. Со временем, если увеличивать количество клерков, не увеличивая размер помещения, они будут мешаться под ногами друг у друга и возможно затраты будут превышать доходы.
Рис. 1 Рост коэффициента дедупликации и сокращение объемов хранения
Миф2. Есть четкое определение термина «дедупликация»
Дедупликация позволяет сократить объем хранимых данных, удаляя повторяющиеся последовательности данных из пула. Дедупликация может быть на файловом уровне, блочном уровне или на уровне приложения или контента. Большая часть продуктов сочетают дедупликацию с компрессией, чтобы еще сильнее сократить объем хранимых данных. В то время, как некоторые производители не разделяют эти термины, некоторые разделяют их и вводят такие термины, как «уплотнение» (compaction), что, по сути, является просто другим названием «дедупликации плюс сжатие». К сожалению, не существует единственного определения дедупликации. В обывательском уровне вам будет важно, как вы сможете сэкономить на дисковых ресурсах вашей системы хранения и резервного копирования, применяя дедупликацию. Ниже мы раскроем эту тему.
К сожалению, не существует единственного определения дедупликации. В обывательском уровне вам будет важно, как вы сможете сэкономить на дисковых ресурсах вашей системы хранения и резервного копирования, применяя дедупликацию. Ниже мы раскроем эту тему.
Говоря про линейку систем хранения и резервного копирования HPE важно отметить, что и системы хранения, и системы резервного копирования обладают интересным функционалом, позволяющим заказчикам экономить на дисковых ресурсах.
Для систем хранения оперативных данных в массиве 3PAR разработан целый комплекс утилит и механизмов, позволяющий сократить объем данных на продуктивном массиве.
Этот комплекс носит название HPE 3PAR Thin Technologies и состоит из нескольких механизмов:
- Thin Provisioning – наиболее эффективно реализованная в системах хранения 3PAR, т.к. применяется виртуализация дискового пространства и массив используют свою внутреннюю карту хранимых блоков, при высвобождении ресурсов массиву не нужно проводить ревизию (garbage collection), высвободившиеся блоки сразу готовы к дальнейшему использованию… Позволяет выделять логическому тому ровно столько объема, сколько он требует, но на массиве занять всего лишь столько, сколько на этот том физически записано.
- Thin Conversion — технология, позволяющая переводить в реальном времени тома со старых массивов данных HPE (3PAR, EVA), EMC, Hitachi и других производителей в «тонкие тома» (которые используют Thin Provisioning) на массиве 3PAR с сокращением объема тома на целевом устройстве.
- Thin Persistence и Thin Copy Reclamation — технология, позволяющая массиву 3PAR на очень низком гранулярном уровне понимать работу всех популярных файловых систем и гипервизоров и в случае удаления файлов (освобождения физического объема) переводить соответствующие блоки в пул свободных ресурсов.
- Thin Deduplication — технология позволяющая использовать дедупликацию на продуктивном массиве в реальном времени, без существенной просадки производительности.

Все три технологии доступны бесплатно и без ограничений по времени или объему для любой системы хранения 3PAR, в том числе, установленных у наших заказчиков,
подробнее об этих технологиях.
Рис.
 2 Технологии Thin в массивах 3PAR
2 Технологии Thin в массивах 3PARМиф3. Коэффициенты дедупликации на основном массиве такие же, как и на массиве с резервными копиями.
Разработчики систем хранения данных используют различные алгоритмы дедупликации. Некоторые из них требуют больших ресурсов CPU и сложнее, чем остальные, следовательно, не должен удивлять тот факт, что коэффициент дедупликации варьируется достаточно сильно.
Однако, самый большой фактор, влияющий на то, какой коэффициент дедупликации вы получите — как много у вас повторяющихся данных. По этой причине системы резервного копирования, содержащие несколько копий одних и тех же данных (дневные, недельные, месячные, квартальные, годичные) имеют такой высокий коэффициент дедупликации. В то время как оперативные системы хранения имеют практически уникальный набор данных, что практически всегда дает невысокий коэффициент дедупликации. В случае, если вы храните несколько копий оперативных данных на продуктивном массиве (например, в виде клонов) — это увеличивает коэффициент дедупликации, т. к. применяются механизмы сокращения места хранения.
к. применяются механизмы сокращения места хранения.
Поэтому для оперативных массивов хранения данных иметь коэффициент 5:1 также замечательно, как иметь коэффициент 30:1 или 40:1 для систем резервного копирования, поскольку коэффициент этот зависит от того, сколько копий продуктивных данных хранится на таких массивах.
Если рассматривать продукты компании HPE, то в массивах для оперативного хранения HPE 3PAR поиск повторяющихся последовательностей (например, при инициализации виртуальных машин или создании снэпшотов) проходит «на лету» на специальной микросхеме ASIC, установленной в каждом контроллере массива. Этот подход позволяет разгрузить центральные процессоры массива для других, более важных, задач и дает возможность включить дедупликацию для всех типов данных, не боясь, что массив «просядет» под нагрузкой. Подробнее про дедупликацию на массиве 3PAR можно прочитать.
Рис.3 Дедупликация в массивах 3PAR выполняется на выделенной микросхеме ASIC
В портфеле HPE также есть аппаратные комплексы для резервного копирования данных с онлайн дедупликацией на уровне блоков переменной длины — HPE StoreOnce. Варианты систем охватывают полный спектр заказчиков от начального до корпоративного уровня:
Варианты систем охватывают полный спектр заказчиков от начального до корпоративного уровня:
Рис. 4 Портфель систем резервного копирования HPE StoreOnce
Про преимущества систем резервного копирования StoreOnce можно почитать в других статьях.
Для заказчиков может быть интересно, что связка HPE 3PAR и StoreOnce позволяет упростить и ускорить процесс переноса данных с продуктивного массива на систему резервного копирования без использования ПО резервного копирования или выделенного сервера бэкапа. Такая связка получила название HPE StoreOnce RMC и подробнее о ней также можно почитать в нашей статье.
Миф4. Все данные одинаковы
Здесь не должно быть никаких сомнений- все данные разные. Даже данные одного и того же приложения в различных условиях будут иметь разные коэффициенты дедупликации на одном и том же массиве. Коэффициент дедупликации для конкретных данных зависит от разных факторов:
- Тип данных — данные, прошедшие программное сжатие, метаданные, медиа-потоки и зашифрованные данные всегда имеют очень невысокий коэффициент дедупликации или не сжимаются вовсе.
- Степень изменяемости данных — чем выше объем дневных изменений данных на блочном или файловом уровне, тем ниже коэффициент дедупликации. Это особенно актуально для систем резервного копирования.
- Срок хранения — чем больше копий данных вы имеете, тем выше коэффициент дедупликации.
- Политика резервного копирования — политика создания дневных полных копий, в противовес политике с инкрементными или дифференциальными бэкапами, даст больший коэффициент дедупликации (см. исследование ниже).
.png)
Таблица ниже дает поверхностную оценку коэффициента дедупликации, в зависимости от типа данных. Необходимо помнить, что коэффициент дедупликации на основном массиве данных будет всегда ниже коэффициента дедупликации на резервном массиве.
Рис. 5 Оценка коэффициента дедупликации в зависимости от типов данных и политики резервного копирования
Миф5. Группировка несвязных типов данных повышает уровень дедупликации
В теории, вы можете смешивать совершенно разные типы данных в общем пуле хранения для дедупликации. Может возникнуть ощущение, что вы имеете очень большой набор уникальных данных и, следовательно, вероятность нахождения в этом пуле уже записанных ранее блоков или объектов будет велика. На практике же этот подход не работает между несвязанными типами данных, например, между БД и Exchange, поскольку форматы данных разные, даже если хранится один и тот же набор данных. Такой, все время растущий пул, становится более сложным и требует больше времени для поиска повторяющихся последовательностей. Лучшей практикой является разделение пулов по типу данных.
Может возникнуть ощущение, что вы имеете очень большой набор уникальных данных и, следовательно, вероятность нахождения в этом пуле уже записанных ранее блоков или объектов будет велика. На практике же этот подход не работает между несвязанными типами данных, например, между БД и Exchange, поскольку форматы данных разные, даже если хранится один и тот же набор данных. Такой, все время растущий пул, становится более сложным и требует больше времени для поиска повторяющихся последовательностей. Лучшей практикой является разделение пулов по типу данных.
Например, если выполнить дедупликацию одной виртуальной машины, вы получите некоторый коэффициент, если создать несколько копий этой виртуальной машины и выполнить дедупликацию на этом пуле, ваш коэффициент дедупликации вырастет, а если сгруппировать несколько виртуальных машин по типу приложения и создать несколько копий этих виртуальных машин — коэффициент увеличится еще больше.
Рис.6 Зависимость коэффициента дедупликации от количества виртуальных машин в пуле и размеров блока данных.
Миф6. Ваше первое резервное копирование покажет вам ожидаемый коэффициент дедупликации.
Это ошибочное мнение появляется при сравнении коэффициентов на основном массиве и системе резервного копирования. Если вы храните только одну копию данных – возможно, вы увидите некоторый коэффициент дедупликации, больший единицы. Этот коэффициент сможет вырасти в том случае, если вы увеличите количество копий очень похожих данных, таких как резервные копии текущей БД.
График ниже показывает очень типичную кривую коэффициента дедупликации. Приложение, в этом графике — БД SAP HANA, но большинство приложений показывает схожую кривую. Ваше первое резервное копирование показывает определенную дедупликацию, но большая экономия достигается благодаря сжатию данных. Как только вы начинаете держать в пуле больше копий данных — коэффициент дедупликации пула начинает расти (голубая линия). Коэффициент индивидуального бэкапа взмывает вверх уже после создания второй копии (орнжевая линия), т. к. на блочном уровне первый и второй бэкап очень похожи.
к. на блочном уровне первый и второй бэкап очень похожи.
Рис. 7 График роста коэффициента дедупликации при увеличении количества резервных копий (подробнее в документе).
Миф7. Вы не можете увеличить уровень дедупликации
Наивно рассуждать, что нет возможности искусственно увеличить уровень дедупликации. Другой вопрос — зачем? Если показать маркетинговые цифры — это одно, если необходимо создать эффективную схему резервного копирования — это другое. Если цель — иметь синтетический наивысший коэффициент дедупликации, то необходимо просто хранить больше как можно больше копий одних и тех же данных. Конечно, это увеличит объем хранимых данных, но ваш коэффициент дедупликации взмоет до небес.
Изменение политики резервного копирования, определенно также влияет на коэффициент дедупликации, как можно увидеть в примере ниже для реального типа данных, где сравниваются политики создания полных копий и комбинации полных копий с инкрементальными и дифферентальными бэкапами. В примере ниже лучший коэффициент получается при использовании только дневных полных бэкапов. Тем не менее, на одних и тех же данных объем хранения является довольно разным для всех трех подходов. Поэтому необходимо понимать, что изменение в вашем подходе к резервному копированию может довольно сильно повлиять на коэффициент дедупликации и на физический объем хранимых данных.
В примере ниже лучший коэффициент получается при использовании только дневных полных бэкапов. Тем не менее, на одних и тех же данных объем хранения является довольно разным для всех трех подходов. Поэтому необходимо понимать, что изменение в вашем подходе к резервному копированию может довольно сильно повлиять на коэффициент дедупликации и на физический объем хранимых данных.
Миф8. Нет возможности заранее спрогнозировать коэффициент дедупликации
Всякая окружающая среда уникальна и очень сложно аккуратно спрогнозировать реальный коэффициент дедупликации. Но тем не менее, производители систем резервного копирования выпускают наборы небольших утилит для основных систем хранения и систем резервного копирования, позволяющие получить представление о типе данных, политике резервного копирования, сроке хранения. Эти утилиты позволяют в какой-то мере получить представление об ожидаемом коэффициенте дедупликации.
Также производители имеют представление о коэффициентах, получаемых у других заказчиках на примерно похожей среде и отраслевом сегменте и могут использовать эту информацию для построения прогноза. В то время как это не дает гарантии, что на ваших данных вы получите схожий коэффициент, к этим цифрам, как минимум, стоит присмотреться.
В то время как это не дает гарантии, что на ваших данных вы получите схожий коэффициент, к этим цифрам, как минимум, стоит присмотреться.
Но наиболее точный прогноз по коэффициенту дедупликации получается в ходе проведения испытаний на реальных данных.
Рис. 8 Изменение коэффициента дедупликации и объема занимаемых данных в зависимости от политики резервного копирования на данных конкретного заказчика
У компании HPE есть набор утилит и сайзеров, позволяющий спрогнозировать (с неким допущением) тот объем систем хранения, который необходим заказчикам.
- Для оперативного хранилища данных есть бесплатная программа оценки текущей утилизации массива и оценки экономии места, в случае перехода на 3PAR.
- Для оценки утилизации ресурсов на оперативном массиве и построения прогноза по росту объема данных на уже установленных системах, при условии разрешения отправки массивом информации о его состоянии в службу технической поддержки HPE: www.storefrontremote. com
- Аналогичная программа по оценке утилизации систем резервного копирования.
 com
comТакже есть возможность оценить предполагаемый объем, который мы получим после включения на системе 3PAR дедупликации в режиме симулятора, для этого необходимо на 3PAR запустить команду оценки, выполняемую в онлайн режиме, прозрачно для хоста:
checkvv -dedup_dryrun {Имена виртуальных томов}И получить предварительную оценку:
Итак, нет никакой магии за понятием дедупликации, а развенчивание мифов, приведенное выше, позволит вам лучше понять, на что способны ваши данные и позволит вам спрогнозировать утилизацию ваших массивов.
Следует отметить, что современный рост объемов SSD и снижения стоимости хранения на 1ГБ на flash накопителях (а стоимость уже соответствует $1.5 за ГБ) отодвигают вопросы, связанные с эффективностью дедупликации на второй план для оперативного хранилища, но становятся все более актуальными для систем резервного копирования.
К слову, есть альтернативное видение будущего (без дедупликации): Викибон считает, что устранение копий одних и тех же данных эффективнее, чем рост коэффициенотв дедупликации и компрессии (см. по ссылке в середине отчета), но такой подход требует кардинального внедрения целого комплекса технических мер, изменения всей инфраструктуры, правил одновременной работы приложений (процессинг, аналитика) с данными так, чтобы они не снижали производительность (при внедрении хороших средств работы с SLA) и надежность.
И, самое главное, если все это внедрить во всей экосистеме — и разработчикам ПО, и вендорам, и CIO, то через несколько лет экономия от этого будет больше, чем от дедупликации.
Какая школа мысли победит – покажет время.
Использованы материалы
Что такое дедупликация данных?
Дедупликация данных — это метод сжатия данных, при котором дублирующиеся данные удаляются, сохраняя одну копию каждой единицы информации в системе, а не позволяя мультипликаторам процветать. Сохраненные копии имеют ссылки, позволяющие системе их извлекать. Этот метод уменьшает потребность в объеме памяти и может поддерживать быстродействие систем в дополнение к ограничению расходов, связанных с хранением данных Он может работать разными способами и используется во многих типах компьютерных систем.
При дедупликации данных на уровне файлов система ищет дубликаты файлов и удаляет дополнительные элементы. Дедупликация на уровне блоков просматривает блоки данных в файлах для выявления посторонних данных. Люди могут получить двойные данные по самым разным причинам, а дедупликация данных может упростить систему, упрощая ее использование. Система может периодически просматривать данные, чтобы проверять наличие дубликатов, устранять лишние элементы и генерировать ссылки на оставленные файлы.
Такие системы иногда называют интеллектуальными системами сжатия или системами хранения одного экземпляра. Оба термина ссылаются на идею, что система интеллектуально работает для хранения и хранения данных, чтобы уменьшить нагрузку на систему. Дедупликация данных может быть особенно полезна в больших системах, где хранятся данные из нескольких источников, а затраты на хранение постоянно растут, так как система должна расширяться со временем.
Эти системы предназначены для того, чтобы быть частью более крупной системы сжатия и управления данными. Дедупликация данных не может защитить системы от вирусов и сбоев, поэтому важно использовать адекватную антивирусную защиту для обеспечения безопасности системы и ограничения вирусного заражения файлов, а также для резервного копирования в отдельном месте, чтобы решить проблемы потери данных из-за отключений, повреждения оборудование и пр. Сжатие данных перед резервным копированием сэкономит время и деньги.
Системы, использующие дедупликацию данных в своих хранилищах, могут работать быстрее и эффективнее. Они по-прежнему будут нуждаться в периодическом расширении для размещения новых данных и решения проблем безопасности, но они должны быть менее склонны к быстрому заполнению дублирующимися данными. Это особенно распространенная проблема на почтовых серверах, где сервер может хранить большие объемы данных для пользователей, и значительная их часть может состоять из дубликатов, таких как вложения, повторяемые снова и снова; например, многие люди, пишущие по электронной почте с работы, прикрепили нижние колонтитулы с заявлениями об отказе от электронной почты и логотипами компаний, и они могут быстро поглотить пространство сервера.
ДРУГИЕ ЯЗЫКИ
Как и для чего производить дедупликацию данных на предприятии
Статья из серии, посвященной организации корпоративной IT-инфраструктуры: речь пойдет о дедупликации данных в компании.
В большинстве организаций файловый сервер является одним из самых неэффективных сервисов, если проанализировать соотношение важной информации со всем объемом данных, который хранится на жестких дисках. Иными словами, часто файловые сервера забиты дубликатами файлов и утратившими актуальность бэкапами. Это происходит из-за плохо организованной структуры хранения данных. Так, например, на сервере могут храниться шаблоны писем, договоров или коммерческих предложений, отличающихся буквально парой-тройкой бит информации: разные имена, даты, индексы и т.д. В результате файловые сервера в организациях распухают, начинают использовать колоссальные объемы для хранения на жестких дисках, увеличивается потребность в устройствах для хранения бэкапов и серьезно повышаются требования к производительности сетевой части инфраструктуры.
Служба дедупликации в Windows Server 2012 R2: алгоритмы и преимущества
Использование в качестве файлового сервера Windows Server, являющееся наиболее распространенным в небольших компаниях, долгое время не оставляло возможности для адекватного решения проблемы неоптимального использования места на дисках. Однако с выходом Windows Server 2012 R2 ситуация изменилась – был добавлен сервис для осуществления процесса дедупликации файлов на серверах.
Дедупликация – это один из способов сжатия корпуса данных, построенный на алгоритме, в процессе выполнения которого идентичные копии данных исключаются при сжатии. Этот метод имеет несколько сфер применения, в частности он помогает уменьшать объемы данных, передаваемых по сети, однако наибольшую популярность он имеет именно в контексте оптимизации пространства файловых серверов.
Во время осуществления дедупликации происходит анализ файлов, в ходе которого опознаются и запоминаются фрагменты данных установленного размера. Пока идет анализ, новые элементы, попадающие в поле зрения алгоритма, сравниваются друг с другом и, если среди них обнаруживаются дубли, то вместо них прописываются ссылки на уникальные вхождения, что ведет к разгрузке дискового пространства. Важно не путать дедупликацию с более ранними методами сжатия данных, такими как LZ77 и LZO, поскольку их алгоритмы ограничиваются поиском лишь в определенных буферах конкретного файла, в то время как дедупликация помогает находить копии по обширному информационному массиву.
Дедупликация в Windows Server 2012 R2 нужна именно для этого. Благодаря его использованию в случае замены в любом документе нескольких фраз и сохранению его как нового файла, место на сервере будут занимать только эти изменения, а не весь новый файл. Наиболее впечатляющие результаты дедупликации можно наблюдать на примере резервных копий, когда на файловом сервере хранятся, к примеру, регулярно записываемые бэкапы серверов – экономия места может превышать 50%.
Подводные камни дедупликации в Windows Server и рекомендации
Однако у любого сложного процесса есть свои подводные камни, и служба дедупликации Windows Server не является исключением – ее работа серьезно замедляет файловый сервер. Некоторые другие операционные системы отличаются тем, что их сервисы дедупликации позволяют сохранять информацию о дублях в оперативной памяти, а на диски записываются только данные об изменениях в файлах, благодаря чему дедупликация осуществляется на порядок быстрее, фактически «в реальном времени». Windows Server не может похвастаться такой расторопностью т.к. файлы сначала копируются на диски и лишь после этого сравниваются между собой – по определенному расписанию или в фоновом режиме. Впрочем, для не слишком перегруженных систем это обычно не является проблемой – а именно таковы системы небольших фирм, которые могут позволить себе иметь в штате компетентного системного администратора. В крайнем случае проводить дедупликацию можно в нерабочее время или лишь для наиболее чувствительных к изменениям групп файлов.
Регулярное выполнение процедуры дедупликации позволяет снизить объемы энтропии на файловых серверах и способствовать лучшему качеству их работы, что в конечном итоге должно играть на руку бизнес-процессам компании.
Сисадмин на аутсорс: что может пойти не так?
15 Октября 2019
ЧитатьМониторинг серверов: что это и для необходимо
2 Октября 2020
ЧитатьКто покупает башенные серверы
29 Августа 2018
Читать
|
Дедупликация данных для корпоративных решений.
Дедупликация данных для корпоративных решений.
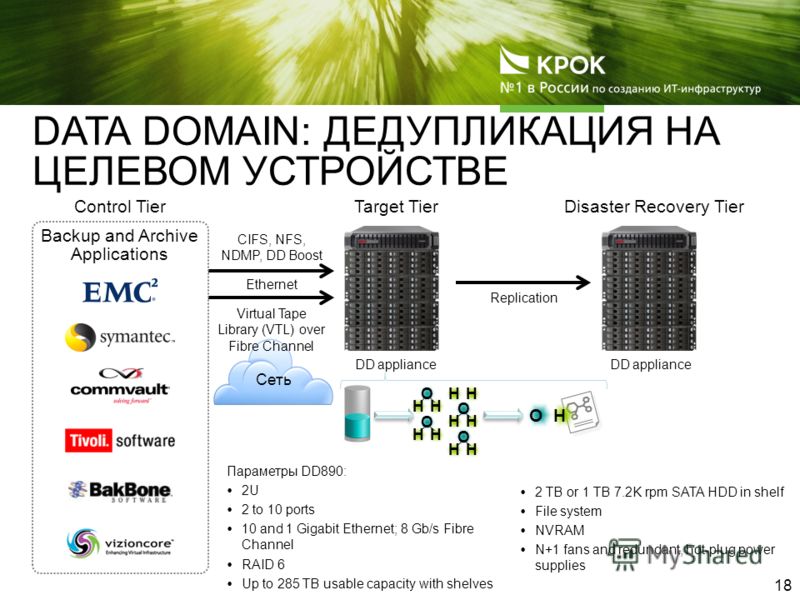
Под дедупликацией данных понимают технологию, которая обнаруживает и исключает избыточные данные в дисковом репозитории (хранилище). В результате этой операции потребности в хранении при тех же самых объемах данных сокращаются наполовину и более, в зависимости от количества избыточных копий. Сегодня функция дедупликации данных стала обязательной для целевых устройств резервного копирования на диски.
Надо сказать, что технологии дедупликации данных сейчас применяют не только для резервного копирования: их все шире внедряют для архивирования информации на основные накопители и оптимизации использования WAN-каналов (рис. 1). Прежде чем мы расскажем об этих технологиях, давайте посмотрим, как появляются идентичные резервные копии.
Рис. 1. Планы использования технологии дедупликации.
Это происходит по двум основным причинам:
— первая — многократное копирование одних и те же файлов с одного и того же сервера. Например, дубликаты некоего файла могут оказаться в еженедельно создаваемых полных резервных копиях, которые хранятся 30 дней. Еще один пример многократно копируемых данных — это первые 900 Мбайт файла почтового ящика объемом 1 Гбайт, в котором, предположим, хранится электронная почта директора некоего предприятия. Поскольку он получает новую почту ежедневно, то каждую ночь программа, осуществляющая инкрементальное резервное копирование, создает новую копию этого файла. И хотя большая часть файла почтового ящика остается неизменной, всякий раз он копируется целиком.
— вторая причина — копирование одинаковых файлов с разных узлов сети. Если вы резервируете содержимое системных дисков 50 Windows-серверов, то получаете 50 копий системных файлов Windows, занимающих значительное дисковое пространство. Ненужные дубликаты могут сохраняться и на субфайловом уровне. Речь идет, например, об изображении логотипа той или иной компании, вставленного в тысячи ее документов, которые хранятся на ее файловых серверах.
Фирмы-производители реализуют дедупликацию самыми разными способами (физически это может быть программная или аппаратная реализация), однако всем им приходится решать несколько схожих проблем.
Производительность. Часто даже не имеет значения, насколько эффективна технология, уменьшающая требования к емкости хранения, если она не может обработать поступающие данные в заданный период времени («временное окно»). Таким образом, производительность – это основной критерий при анализе решений дедупликации.
Гранулярность (степень детализации). Дедупликация может выполняться на файловом, блоковом и битовом уровнях. Считается, что более высокая степень детализации обеспечивает более эффективную обработку.
Факторизация (распознавание избыточных данных). Дедупликация основывается на проприетарных (фирменных) алгоритмах, базирующихся, в свою очередь, либо на хэшировании (когда первым делом создается некий «отпечаток пальца» для каждого блока данных, а затем эти «отпечатки» сравниваются), либо на сравнении действительных данных. Факторизация — важный определяющий элемент скорости дедупликации.
Архитектура. Обычно рассматриваются две основные архитектуры дедупликации, хотя на самом деле их существует все-таки три. Первая из них — это постобработка (пост-процессинг). В этом случае сначала сохраняют резервные копии, а затем дедуплицируют их. При таком подходе к дедупликации для кеширования копируемых данных требуется дополнительное дисковое пространство, что снижает эффективность этой процедуры. Таким образом, постпроцессинговая обработка обеспечивает максимально быстрое поступление данных, однако для временного хранения требуется дополнительная емкость.
Далее, онлайновая обработка («на лету») означает, что дедупликация данных происходит перед их записью в хранилище. Это требует довольно высокой процессорной мощности, но позволяет существенно сократить объем хранения и количество операций ввода-вывода. В этом случае важно, чтобы выполнение процесса дедупликации не тормозило резервное копирование. И третий вариант — параллельная обработка; в этом случае запись «сырых» данных на диск, их дедупликация и перезапись факторизованных данных происходят в одно и то же время. Для параллельного выполнения этих трех операций требуется очень высокая вычислительная мощность и дополнительное дисковое пространство в хранилище.
Место проведения дедупликации. Дедупликация может выполняться на источнике или приемнике. В последнем случае данный процесс выполняется прозрачно и никак не влияет на существующую и новую функциональность системы. К недостаткам его следует отнести большой объем пересылаемых данных. В первом же случае, хотя и удается снизить нагрузку на сеть, но приходится мириться с целым рядом неудобств, поскольку дедупликация происходит непрозрачно, требуя установки специализированного ПО на клиентских компьютерах.
Коэффициент дедупликации. Значение данного коэффициента вычисляется путем деления первоначального объема данных на объем данных, полученных после дедупликации. Наиболее эффективной дедупликация оказывается в том случае, когда данные обладают большой избыточностью на уровне файлов, а также когда они копируются и/или сохраняются после внесения незначительных изменений. В общем случае неструктурированные данные (файлы Microsoft Office, виртуальные диски, резервные копии, файлы электронной почты и архивов) показывают лучшие коэффициенты, чем при дедупликации файлов баз данных (структурированных данных).
Многие специалисты признают функцию дедупликации данных очень полезной, но среди них не утихают споры о том, как и где ее нужно выполнять. Наиболее горячо обсуждаются достоинства и недостатки онлайновой дедупликации (в ходе процесса резервного копирования) и дедупликации в виде постобработки (после окончания этого процесса). Онлайновую дедупликацию выполняют устройства, подобные продуктам фирмы Data Domain, или VTL-системы на базе ПО ProtecTier компании Diligent Technologies, которые обрабатывают данные в масштабе реального времени и сохраняют только дедуплицированные данные. Поскольку для такой дедупликации нужно много вычислительной мощности, общая производительность дедуплицирующих устройств ограничивается скоростью выполнения ими этой функции.
Обзор дедупликации данных
| Документы Microsoft
- 3 минуты на чтение
В этой статье
Применимо к: Windows Server 2022, Windows Server 2019, Windows Server 2016
Что такое дедупликация данных?
Дедупликация данных, часто сокращенно называемая дедупликацией, — это функция, которая может помочь снизить влияние избыточных данных на затраты на хранение.Если эта функция включена, дедупликация данных оптимизирует свободное пространство на томе, исследуя данные на томе путем поиска дублированных частей на томе. Дублированные части набора данных тома сохраняются один раз и (необязательно) сжимаются для дополнительной экономии. Дедупликация данных оптимизирует избыточность без ущерба для точности или целостности данных. Дополнительную информацию о том, как работает дедупликация данных, можно найти в разделе «Как работает дедупликация данных?» на странице «Общие сведения о дедупликации данных».
Важно
KB4025334 содержит набор исправлений для дедупликации данных, включая важные исправления надежности, и мы настоятельно рекомендуем установить его при использовании дедупликации данных с Windows Server 2016 и Windows Server 2019.
Чем полезна дедупликация данных?
Дедупликация данных помогает администраторам хранилищ сократить расходы, связанные с дублированием данных. Большие наборы данных часто имеют много дублирования , что увеличивает затраты на хранение данных.Например:
- Общие файловые ресурсы пользователей могут содержать множество копий одних и тех же или похожих файлов.
- Гости виртуализации могут быть почти идентичны от ВМ к ВМ.
- Моментальные снимки резервных копий изо дня в день могут незначительно отличаться.
Экономия места, которую вы можете получить за счет дедупликации данных, зависит от набора данных или рабочей нагрузки на томе. Наборы данных с высоким уровнем дублирования могут быть оптимизированы до 95% или 20-кратного сокращения использования хранилища.В следующей таблице показаны типичные сокращения дедупликации для различных типов контента:
| Сценарий | Содержимое | Типичная экономия места |
|---|---|---|
| Документы пользователя | Офисные документы, фотографии, музыка, видео и т. Д. | 30-50% |
| Доли развертывания | Программные двоичные файлы, CAB-файлы, символы и т. Д. | 70-80% |
| Библиотеки виртуализации | ISO, файлы виртуального жесткого диска и т. Д. | 80-95% |
| Общий файловый ресурс | Все вышеперечисленное | 50-60% |
Примечание
Если вы просто хотите освободить место на томе, рассмотрите возможность использования службы «Синхронизация файлов Azure» с включенным многоуровневым облаком. Это позволяет кэшировать наиболее часто используемые файлы локально и размещать наименее часто используемые файлы по уровням в облаке, экономя место на локальном хранилище при сохранении производительности. Дополнительные сведения см. В разделе Планирование развертывания службы «Синхронизация файлов Azure».
Когда можно использовать дедупликацию данных?
| Файловые серверы общего назначения Файловые серверы общего назначения — это файловые серверы общего назначения, которые могут содержать любые из следующих типов общих ресурсов:
| |
| Развертывания инфраструктуры виртуальных рабочих столов (VDI) Серверы VDI, такие как службы удаленных рабочих столов, предоставляют организациям облегченный вариант предоставления рабочих столов пользователям. У организации есть много причин полагаться на такую технологию:
| |
| Целевые объекты резервного копирования, такие как виртуализированные приложения резервного копирования Приложения резервного копирования, такие как Microsoft Data Protection Manager (DPM), являются отличными кандидатами для дедупликации данных из-за значительного дублирования между моментальными снимками резервных копий. | |
| Другие рабочие нагрузки Другие рабочие нагрузки также могут быть отличными кандидатами для дедупликации данных. |
Что такое дедупликация данных | Документы Microsoft
- 7 минут на чтение
В этой статье
Применимо к: Windows Server 2022, Windows Server 2019, Windows Server 2016
В этом документе описывается, как работает дедупликация данных.
Как работает дедупликация данных?
Дедупликация данныхв Windows Server была создана на основе следующих двух принципов:
Оптимизация не должна мешать записи на диск Дедупликация данных оптимизирует данные с помощью модели постобработки. Все данные записываются на диск без оптимизации, а затем оптимизируются с помощью дедупликации данных.
Оптимизация не должна изменять семантику доступа Пользователи и приложения, которые обращаются к данным на оптимизированном томе, совершенно не знают, что файлы, к которым они обращаются, были дедуплицированы.
После включения для тома дедупликация данных выполняется в фоновом режиме до:
- Определите повторяющиеся шаблоны в файлах на этом томе.
- Плавно перемещайте эти части или фрагменты с помощью специальных указателей, называемых точками повторной обработки, которые указывают на уникальную копию этого фрагмента.
Это происходит в следующие четыре этапа:
- Сканировать файловую систему на наличие файлов, соответствующих политике оптимизации.
- Разбивайте файлы на куски переменного размера.
- Определите уникальные фрагменты.
- Поместите фрагменты в хранилище фрагментов и при необходимости сожмите.
- Заменить исходный файловый поток теперь оптимизированных файлов точкой повторной обработки для хранилища фрагментов.
При чтении оптимизированных файлов файловая система отправляет файлы с точкой повторной обработки фильтру файловой системы дедупликации данных (Dedup.sys). Фильтр перенаправляет операцию чтения на соответствующие фрагменты, составляющие поток для этого файла в хранилище фрагментов.Изменения диапазонов дедуплицированных файлов записываются на диск без оптимизации и оптимизируются заданием оптимизации при следующем запуске.
Типы использования
Следующие типы использования обеспечивают разумную конфигурацию дедупликации данных для общих рабочих нагрузок:
| Тип использования | Идеальные рабочие нагрузки | Чем отличается |
|---|---|---|
| По умолчанию | Файловый сервер общего назначения:
|
|
| Hyper-V | Серверы Virtualized Desktop Infrastructure (VDI) |
|
| Резервное копирование | Виртуализированные приложения для резервного копирования, такие как Microsoft Data Protection Manager (DPM) |
|
Вакансии
Data Deduplication использует стратегию пост-обработки для оптимизации и поддержания эффективности использования пространства тома.
| Название работы | Должностные инструкции | График по умолчанию |
|---|---|---|
| Оптимизация | Задание Optimization выполняет дедупликацию путем разбиения данных на том в соответствии с настройками политики тома, (необязательно) сжатия этих фрагментов и уникального сохранения фрагментов в хранилище фрагментов. Процесс оптимизации, который использует дедупликация данных, подробно описан в разделе Как работает дедупликация данных ?. | Раз в час |
| Сборка мусора | Задание «Сборка мусора» освобождает дисковое пространство, удаляя ненужные фрагменты, на которые больше не ссылаются файлы, которые были недавно изменены или удалены. | Каждую субботу в 2:35 |
| Очистка целостности | Задание Integrity Scrubbing выявляет повреждение в хранилище фрагментов из-за сбоев диска или поврежденных секторов. Когда это возможно, дедупликация данных может автоматически использовать функции тома (такие как зеркалирование или четность на томе дисковых пространств) для восстановления поврежденных данных. Кроме того, дедупликация данных сохраняет резервные копии популярных фрагментов, когда на них ссылаются более 100 раз в области, называемой горячей точкой. | Каждую субботу в 3:35 |
| Неоптимизация | Задание Неоптимизация , специальное задание, которое следует запускать только вручную, отменяет оптимизацию, выполненную дедупликацией, и отключает дедупликацию данных для этого тома. | Только по запросу |
Терминология дедупликации данных
| Срок | Определение |
|---|---|
| Фрагмент | Фрагмент — это часть файла, которая была выбрана алгоритмом фрагментации дедупликации данных как имеющая вероятность появления в других подобных файлах. |
| Магазин кусков | Хранилище фрагментов — это организованная серия файлов-контейнеров в папке System Volume Information, которую дедупликация данных использует для уникального хранения фрагментов. |
| Отмена | Аббревиатура дедупликации данных, которая обычно используется в PowerShell, API-интерфейсах и компонентах Windows Server, а также в сообществе Windows Server. |
| Метаданные файла | Каждый файл содержит метаданные, которые описывают интересные свойства файла, не связанные с основным содержимым файла.Например, Дата создания, Дата последнего прочтения, Автор и т. Д. |
| Файловый поток | Файловый поток — это основное содержимое файла. Это часть файла, которую оптимизирует дедупликация данных. |
| Файловая система | Файловая система — это программное обеспечение и структура данных на диске, которые операционная система использует для хранения файлов на носителе. Дедупликация данных поддерживается на томах в формате NTFS. |
| Фильтр файловой системы | Фильтр файловой системы — это плагин, который изменяет поведение файловой системы по умолчанию.Чтобы сохранить семантику доступа, дедупликация данных использует фильтр файловой системы (Dedup.sys) для перенаправления операций чтения в оптимизированное содержимое, полностью прозрачно для пользователя или приложения, которое делает запрос на чтение. |
| Оптимизация | Файл считается оптимизированным (или дедуплицированным) с помощью дедупликации данных, если он был разбит на фрагменты, а его уникальные фрагменты были сохранены в хранилище фрагментов. |
| Политика оптимизации | Политика оптимизации определяет файлы, которые следует учитывать для дедупликации данных.Например, файлы могут считаться не соответствующими политике, если они совершенно новые, открытые, по определенному пути на томе или с определенным типом файлов. |
| Точка повторной обработки | Точка повторной обработки — это специальный тег, который уведомляет файловую систему о передаче ввода-вывода указанному фильтру файловой системы. Когда файловый поток оптимизирован, дедупликация данных заменяет файловый поток точкой повторной обработки, что позволяет дедупликации данных сохранить семантику доступа для этого файла. |
| Объем | Том — это конструкция Windows для логического накопителя, который может охватывать несколько физических запоминающих устройств на одном или нескольких серверах.Дедупликация включается для каждого тома. |
| Рабочая нагрузка | Рабочая нагрузка — это приложение, работающее на Windows Server. Примеры рабочих нагрузок включают файловый сервер общего назначения, Hyper-V и SQL Server. |
Предупреждение
Не пытайтесь вручную изменить хранилище фрагментов без инструкций уполномоченного персонала службы поддержки Microsoft. Это может привести к повреждению или потере данных.
Часто задаваемые вопросы
Чем дедупликация данных отличается от других продуктов для оптимизации? Есть несколько важных отличий между дедупликацией данных и другими распространенными продуктами для оптимизации хранилища:
Чем дедупликация данных отличается от хранилища единственного экземпляра? Хранилище единственных экземпляров или SIS — это технология, предшествовавшая дедупликации данных и впервые представленная в Windows Storage Server 2008 R2.Чтобы оптимизировать том, Single Instance Store идентифицировал файлы, которые были полностью идентичны, и заменил их логическими ссылками на единственную копию файла, которая хранится в общем хранилище SIS. В отличие от хранилища единственного экземпляра, дедупликация данных позволяет сэкономить место за счет файлов, которые не идентичны, но имеют много общих шаблонов, а также файлов, которые сами содержат множество повторяющихся шаблонов. Хранилище единственного экземпляра было объявлено устаревшим в Windows Server 2012 R2 и удалено в Windows Server 2016 в пользу дедупликации данных.
Чем дедупликация данных отличается от сжатия NTFS? Сжатие NTFS — это функция NTFS, которую можно дополнительно включить на уровне тома. При сжатии NTFS каждый файл оптимизируется индивидуально посредством сжатия во время записи. В отличие от сжатия NTFS, дедупликация данных позволяет сэкономить пространство во всех файлах на томе. Это лучше, чем сжатие NTFS, потому что файлы могут иметь как , так и внутреннее дублирование (которое решается сжатием NTFS) и иметь сходство с другими файлами на томе (что не обрабатывается сжатием NTFS).Кроме того, дедупликация данных имеет модель постобработки, что означает, что новые или измененные файлы будут записываться на диск неоптимизированными и будут оптимизированы позже с помощью дедупликации данных.
Чем дедупликация данных отличается от форматов архивных файлов, таких как zip, rar, 7z, cab и т. Д.? Форматы файлов архивов, такие как zip, rar, 7z, cab и т. Д., Выполняют сжатие по указанному набору файлов. Как и дедупликация данных, оптимизированы повторяющиеся шаблоны в файлах и повторяющиеся шаблоны в файлах.Однако вы должны выбрать файлы, которые хотите включить в архив. Семантика доступа тоже разная. Чтобы получить доступ к определенному файлу в архиве, вы должны открыть архив, выбрать конкретный файл и распаковать этот файл для использования. Дедупликация данных работает прозрачно для пользователей и администраторов и не требует запуска вручную. Кроме того, дедупликация данных сохраняет семантику доступа: оптимизированные файлы остаются неизменными после оптимизации.
Могу ли я изменить настройки дедупликации данных для выбранного типа использования? да.Хотя дедупликация данных обеспечивает разумные значения по умолчанию для Рекомендуемые рабочие нагрузки , вы все равно можете захотеть настроить параметры дедупликации данных, чтобы максимально эффективно использовать свое хранилище. Кроме того, другие рабочие нагрузки потребуют некоторой настройки, чтобы дедупликация данных не влияла на рабочую нагрузку.
Могу ли я вручную запустить задание дедупликации данных? Да, все задания дедупликации данных можно запускать вручную. Это может быть желательно, если запланированные задания не выполнялись из-за нехватки системных ресурсов или из-за ошибки.Кроме того, задание неоптимизации можно запустить только вручную.
Могу ли я отслеживать исторические результаты заданий дедупликации данных? Да, все задания дедупликации данных делают записи в журнале событий Windows.
Могу ли я изменить расписания по умолчанию для заданий дедупликации данных в моей системе? Да, все расписания можно настраивать. Изменение расписаний дедупликации данных по умолчанию особенно желательно, чтобы гарантировать, что задания дедупликации данных успеют завершиться и не будут конкурировать за ресурсы с рабочей нагрузкой.
Установка и включение дедупликации данных
- 8 минут на чтение
В этой статье
Применимо к: Windows Server 2022, Windows Server 2019, Windows Server 2016
В этом разделе объясняется, как установить дедупликацию данных, оценить рабочие нагрузки для дедупликации и включить дедупликацию данных на определенных томах.
Примечание
Если вы планируете запускать дедупликацию данных в отказоустойчивом кластере, на каждом узле кластера должна быть установлена роль сервера дедупликации данных.
Установить дедупликацию данных
Важно
KB4025334 содержит набор исправлений для дедупликации данных, включая важные исправления надежности, и мы настоятельно рекомендуем установить его при использовании дедупликации данных с Windows Server 2016.
Установите дедупликацию данных с помощью диспетчера сервера
- В мастере добавления ролей и компонентов выберите Роли сервера , а затем выберите Дедупликация данных .
- Нажимайте Далее , пока не станет активной кнопка Установить , а затем щелкните Установить .
Установка дедупликации данных с помощью PowerShell
Чтобы установить дедупликацию данных, выполните следующую команду PowerShell от имени администратора: Install-WindowsFeature -Name FS-Data-Deduplication
Для установки дедупликации данных в установке Nano Server:
Создайте установку Nano Server с установленным хранилищем, как описано в Приступая к работе с Nano Server.
С сервера под управлением Windows Server 2016 в любом режиме, кроме Nano Server, или с ПК с Windows с установленными средствами удаленного администрирования сервера (RSAT) установите дедупликацию данных с явной ссылкой на экземпляр Nano Server (замените MyNanoServer) с настоящим именем экземпляра Nano Server):
Install-WindowsFeature -ComputerName-Name FS-Data-Deduplication
— ИЛИ —
Подключитесь удаленно к экземпляру Nano Server с помощью удаленного взаимодействия PowerShell и установите дедупликацию данных с помощью DISM:Enter-PSSession -ComputerName MyNanoServer DISM / онлайн / включить-функцию / имя: дедуп-ядро / все
Включить дедупликацию данных
Определите, какие рабочие нагрузки являются кандидатами для дедупликации данных
Дедупликация данных может эффективно минимизировать затраты на потребление данных серверным приложением за счет уменьшения объема дискового пространства, потребляемого избыточными данными.Перед включением дедупликации важно понимать характеристики своей рабочей нагрузки, чтобы обеспечить максимальную производительность хранилища. Следует учитывать два класса рабочих нагрузок:
- Рекомендуемые рабочие нагрузки , которые, как было доказано, содержат оба набора данных, которые сильно выигрывают от дедупликации, и модели потребления ресурсов, совместимые с моделью постобработки дедупликации данных. Мы рекомендуем всегда включать дедупликацию данных для следующих рабочих нагрузок:
- Файловые серверы общего назначения (GPFS), обслуживающие общие ресурсы, такие как общие ресурсы группы, домашние папки пользователей, рабочие папки и общие ресурсы разработки программного обеспечения.
- Серверы инфраструктуры виртуальных рабочих столов (VDI).
- Виртуализированные приложения для резервного копирования, такие как Microsoft Data Protection Manager (DPM).
- Рабочие нагрузки, которые могут выиграть от дедупликации, но не всегда подходят для дедупликации. Например, следующие рабочие нагрузки могут хорошо работать с дедупликацией, но сначала вы должны оценить преимущества дедупликации:
- Хосты Hyper-V общего назначения
- SQL-серверы
- Бизнес-серверы
Оценка рабочих нагрузок для дедупликации данных
Важно
Если вы выполняете рекомендованную рабочую нагрузку, вы можете пропустить этот раздел и перейти к включению дедупликации данных для своей рабочей нагрузки.
Чтобы определить, хорошо ли работает рабочая нагрузка с дедупликацией, ответьте на следующие вопросы. Если вы не уверены в рабочей нагрузке, рассмотрите возможность пилотного развертывания дедупликации данных на тестовом наборе данных для вашей рабочей нагрузки, чтобы увидеть, как она работает.
Достаточно ли дублирования в наборе данных моей рабочей нагрузки, чтобы использовать дедупликацию? Перед включением дедупликации данных для рабочей нагрузки выясните, насколько сильно дублируется набор данных вашей рабочей нагрузки, с помощью инструмента оценки экономии при дедупликации данных или DDPEval.После установки дедупликации данных вы можете найти этот инструмент по адресу
C: \ Windows \ System32 \ DDPEval.exe. DDPEval может оценить потенциал оптимизации для напрямую подключенных томов (включая локальные диски или общие тома кластера) и подключенных или несопоставленных сетевых ресурсов. Запуск DDPEval.exe вернет результат, подобный следующему:Средство оценки экономии за счет дедупликации данныхАвторские права 2011-2012 Microsoft Corporation. Все права защищены.Проверенная папка: E: \ TestОбработано файлов: 34Размер обрабатываемых файлов: 12.03MBОптимизированный размер файлов: 4,02 МБЭкономия места: 8.01MBПроцент экономии места: 66Оптимизированный размер файлов (без сжатия): 11,47 МБЭкономия места (без сжатия): 571,53 КБПроцент экономии места (без сжатия): 4Файлов с дублированием: 2Файлов, исключенных политикой: 20Файлы, исключенные из-за ошибки: 0Как выглядят шаблоны ввода-вывода моей рабочей нагрузки для набора данных? Какая у меня производительность для моей рабочей нагрузки? Дедупликация данных оптимизирует файлы как периодическое задание, а не когда файл записывается на диск.В результате важно изучить ожидаемые шаблоны чтения рабочей нагрузки на дедуплицированный том. Поскольку дедупликация данных перемещает содержимое файла в хранилище фрагментов и пытается максимально упорядочить хранилище фрагментов по файлам, операции чтения работают лучше всего, когда они применяются к последовательным диапазонам файла.
Рабочие нагрузки, подобные базам данных, обычно имеют больше шаблонов случайного чтения, чем шаблоны последовательного чтения, поскольку базы данных обычно не гарантируют, что структура базы данных будет оптимальной для всех возможных запросов, которые могут быть выполнены.Поскольку разделы Хранилища фрагментов могут существовать по всему тому, доступ к диапазонам данных в Хранилище фрагментов для запросов к базе данных может вызвать дополнительную задержку. Высокопроизводительные рабочие нагрузки особенно чувствительны к этой дополнительной задержке, но другие рабочие нагрузки, подобные базам данных, могут не быть.
Примечание
Эти проблемы в первую очередь относятся к рабочим нагрузкам хранилища на томах, состоящих из традиционных ротационных носителей данных (также известных как жесткие диски или HDD). Инфраструктура хранения на основе флэш-памяти (также известная как твердотельные диски или твердотельные накопители) меньше подвержена влиянию случайных шаблонов ввода-вывода, поскольку одним из свойств флэш-носителя является равное время доступа ко всем расположениям на носителе.Следовательно, дедупликация не приведет к такой же задержке при чтении наборов данных рабочей нагрузки, хранящихся на флэш-носителях, как на традиционных ротационных носителях.
Каковы требования к ресурсам моей рабочей нагрузки на сервере? Поскольку дедупликация данных использует модель постобработки, дедупликации данных периодически необходимо иметь достаточные системные ресурсы для выполнения своей оптимизации и других заданий. Это означает, что рабочие нагрузки, у которых есть время простоя, например, вечером или в выходные, являются отличными кандидатами для дедупликации, а рабочие нагрузки, которые выполняются весь день, могут не подходить.Рабочие нагрузки, у которых нет времени простоя, могут по-прежнему быть хорошими кандидатами для дедупликации, если рабочая нагрузка не имеет высоких требований к ресурсам на сервере.
Включить дедупликацию данных
Перед включением дедупликации данных необходимо выбрать тип использования, наиболее соответствующий вашей рабочей нагрузке. Дедупликация данных включает три типа использования.
- По умолчанию — настроен специально для файловых серверов общего назначения
- Hyper-V — настроен специально для серверов VDI
- Backup — настроен специально для виртуализированных приложений резервного копирования, таких как Microsoft DPM
Включение дедупликации данных с помощью диспетчера сервера
- Выберите File and Storage Services в диспетчере сервера.
- Выберите Volumes из File and Storage Services .
- Щелкните правой кнопкой мыши нужный том и выберите Настроить дедупликацию данных .
- Выберите желаемый Тип использования из раскрывающегося списка и выберите OK .
- Если вы выполняете рекомендованную рабочую нагрузку, все готово. Для других рабочих нагрузок см. Прочие соображения.
Примечание
Дополнительную информацию об исключении расширений файлов или папок и выборе расписания дедупликации, в том числе о причинах этого, можно найти в разделе «Настройка дедупликации данных».
Включение дедупликации данных с помощью PowerShell
В контексте администратора выполните следующую команду PowerShell:
Enable-DedupVolume -Volume-UsageType Если вы выполняете рекомендованную рабочую нагрузку, все готово. Для других рабочих нагрузок см. Прочие соображения.
Примечание
Командлеты PowerShell для дедупликации данных, включая Enable-DedupVolume , можно запускать удаленно, добавив параметр -CimSession к сеансу CIM.Это особенно полезно для удаленного запуска командлетов PowerShell дедупликации данных на экземпляре Nano Server. Чтобы создать новый сеанс CIM, запустите New-CimSession .
Прочие соображения
Важно
Если вы выполняете рекомендованную рабочую нагрузку, вы можете пропустить этот раздел.
Часто задаваемые вопросы (FAQ)
Я хочу запустить дедупликацию данных в наборе данных для рабочей нагрузки X. Это поддерживается? Помимо рабочих нагрузок, которые, как известно, не взаимодействуют с дедупликацией данных, мы полностью поддерживаем целостность данных дедупликации данных с любой рабочей нагрузкой.Рекомендуемые рабочие нагрузки также поддерживаются Microsoft для повышения производительности. Производительность других рабочих нагрузок во многом зависит от того, что они делают на вашем сервере. Вы должны определить, какое влияние на вашу рабочую нагрузку оказывает дедупликация данных, и допустимо ли это для данной рабочей нагрузки.
Каковы требования к размеру тома для дедуплицированных томов? В Windows Server 2012 и Windows Server 2012 R2 размер томов необходимо было тщательно подбирать, чтобы дедупликация данных могла идти в ногу с оттоком на томе.Обычно это означало, что средний максимальный размер дедуплицированного тома для рабочей нагрузки с большим оттоком составлял 1-2 ТБ, а абсолютный максимальный рекомендуемый размер составлял 10 ТБ. В Windows Server 2016 эти ограничения были сняты. Дополнительные сведения см. В разделе Что нового в дедупликации данных.
Нужно ли мне изменять расписание или другие параметры дедупликации данных для рекомендуемых рабочих нагрузок? Нет, указанные типы использования были созданы для обеспечения разумных значений по умолчанию для рекомендуемых рабочих нагрузок.
Каковы требования к памяти для дедупликации данных? Как минимум, дедупликация данных должна иметь 300 МБ + 50 МБ на каждый ТБ логических данных. Например, если вы оптимизируете том 10 ТБ, вам потребуется минимум 800 МБ памяти, выделенной для дедупликации (300 МБ + 50 МБ * 10 = 300 МБ + 500 МБ = 800 МБ ). Хотя дедупликация данных может оптимизировать том с таким небольшим объемом памяти, наличие таких ограниченных ресурсов замедлит выполнение задач дедупликации данных.
В оптимальном случае дедупликация данных должна иметь 1 ГБ памяти на каждый 1 ТБ логических данных. Например, если вы оптимизируете том 10 ТБ, вам оптимально потребуется 10 ГБ памяти, выделенной для дедупликации данных ( 1 ГБ * 10 ). Это соотношение обеспечит максимальную производительность для заданий дедупликации данных.
Каковы требования к хранилищу для дедупликации данных? В Windows Server 2016 дедупликация данных может поддерживать тома размером до 64 ТБ. Дополнительные сведения см. В разделе Что нового в дедупликации данных.
Что такое дедупликация данных? — Определение с сайта WhatIs.com
Дедупликация данных — часто называемая интеллектуальным сжатием или одноэкземплярным хранилищем — это процесс, который устраняет избыточные копии данных и снижает накладные расходы на хранилище. Методы дедупликации данных обеспечивают сохранение только одного уникального экземпляра данных на носителе, таком как диск, флэш-память или лента. Избыточные блоки данных заменяются указателем на уникальную копию данных.Таким образом, дедупликация данных тесно связана с инкрементным резервным копированием, при котором копируются только данные, которые изменились с момента предыдущего резервного копирования.
Например, типичная система электронной почты может содержать 100 экземпляров одного и того же файлового вложения размером 1 мегабайт (МБ). При резервном копировании или архивировании платформы электронной почты все 100 экземпляров сохраняются, для чего требуется 100 МБ дискового пространства. При дедупликации данных сохраняется только один экземпляр вложения; каждый последующий экземпляр ссылается на одну сохраненную копию.В этом примере потребность в хранилище 100 МБ снижается до 1 МБ.
Целевая дедупликация и исходнаяДедупликация данных может происходить на исходном или целевом уровне.
Дедупликация на основе источника удаляет избыточные блоки перед передачей данных в целевой объект резервного копирования на уровне клиента или сервера. Дополнительного оборудования не требуется. Дедупликация в источнике снижает пропускную способность и использование хранилища.
При дедупликации на основе целевого объекта резервные копии передаются по сети на дисковое оборудование в удаленном месте.Использование целей дедупликации увеличивает затраты, хотя обычно обеспечивает преимущество в производительности по сравнению с дедупликацией источника, особенно для наборов данных петабайтного масштаба.
Методы дедупликации данныхСуществует два основных метода дедупликации избыточных данных: встроенная дедупликация и дедупликация после обработки. Ваша среда резервного копирования будет определять, какой метод вы используете.
Встроенная дедупликация анализирует данные по мере их поступления в систему резервного копирования. Избыточность удаляется по мере записи данных в хранилище резервных копий.Встроенная дедупликация требует меньшего объема хранилища резервных копий, но может вызвать узкие места. Поставщики массивов хранения рекомендуют отключить свои встроенные инструменты дедупликации данных для высокопроизводительного основного хранилища.
Дедупликация после обработки — это асинхронный процесс резервного копирования, который удаляет избыточные данные после их записи в хранилище. Дублирующиеся данные удаляются и заменяются указателем на первую итерацию блока. Подход постобработки дает пользователям гибкость для дедупликации определенных рабочих нагрузок и быстрого восстановления самой последней резервной копии без гидратации.Компромисс — большая емкость хранилища резервных копий, чем требуется при встроенной дедупликации.
Дедупликация на уровне файлов и на уровне блоковДедупликация данных обычно работает на уровне файла или блока. Дедупликация файлов устраняет повторяющиеся файлы, но не является эффективным средством дедупликации.
Дедупликация данных на уровне файла сравнивает файл, подлежащий резервному копированию или архивированию, с уже сохраненными копиями. Это делается путем проверки его атрибутов по индексу.Если файл уникален, он сохраняется и индекс обновляется; в противном случае сохраняется только указатель на существующий файл. В результате сохраняется только один экземпляр файла, а последующие копии заменяются заглушкой, указывающей на исходный файл.
Дедупликация на уровне блоков просматривает файл и сохраняет уникальные итерации каждого блока. Все блоки разбиты на куски одинаковой фиксированной длины. Каждый фрагмент данных обрабатывается с использованием алгоритма хеширования, такого как MD5 или SHA-1.
Этот процесс генерирует уникальный номер для каждой части, который затем сохраняется в индексе. Если файл обновлен, сохраняются только измененные данные, даже если изменились только несколько байтов документа или презентации. Изменения не составляют полностью новый файл. Такое поведение делает дедупликацию блоков намного более эффективной. Однако блочная дедупликация требует большей вычислительной мощности и использует гораздо больший индекс для отслеживания отдельных частей.
Дедупликация переменной длины — это альтернатива, которая разбивает файловую систему на фрагменты различного размера, позволяя при дедупликации достичь лучших коэффициентов сокращения данных, чем блоки фиксированной длины.Недостатком является то, что он также производит больше метаданных и, как правило, работает медленнее.
Коллизии хэшей — потенциальная проблема при дедупликации. Когда часть данных получает хэш-номер, это число затем сравнивается с индексом других существующих хеш-номеров. Если этот хеш-номер уже есть в индексе, фрагмент данных считается дубликатом и не требует повторного сохранения. В противном случае к индексу добавляется новый хеш-номер и новые данные сохраняются. В редких случаях алгоритм хеширования может выдавать один и тот же номер хеш-функции для двух разных фрагментов данных.Когда происходит конфликт хешей, система не сохраняет новые данные, потому что видит, что ее хеш-номер уже существует в индексе. Это называется ложным срабатыванием и может привести к потере данных. Некоторые поставщики комбинируют хеш-алгоритмы, чтобы уменьшить вероятность хеш-коллизии. Некоторые поставщики также изучают метаданные для идентификации данных и предотвращения конфликтов.
Сравнение дедупликации данных, сжатия и тонкого выделения ресурсов АналитикМайк Матчетт обсуждает преимущества сжатия и дедупликации и объясняет, чем они отличаются друг от друга.
Другой метод, часто связанный с дедупликацией, — это сжатие. Однако эти два метода работают по-разному: дедупликация данных ищет избыточные фрагменты данных, в то время как сжатие использует алгоритм для уменьшения количества битов, необходимых для представления данных.
Сжатие и дельта-разность часто используются с дедупликацией. Взятые вместе, эти три метода сокращения объема данных предназначены для оптимизации емкости хранилища.
Thin provisioning оптимизирует использование емкости в сети хранения данных.И наоборот, стирающее кодирование — это метод защиты данных, который разбивает данные на фрагменты и кодирует каждый фрагмент с избыточными частями данных, чтобы помочь восстановить поврежденные наборы данных.
Другие преимущества дедупликации:
Дедупликация первичных данных и облакоДедупликация данных происходит в резервном и вторичном хранилище, хотя есть возможность дедупликации первичных наборов данных. Это особенно полезно для максимального увеличения емкости и производительности флэш-памяти.Дедупликация первичного хранилища происходит в зависимости от аппаратного обеспечения хранилища или программного обеспечения операционной системы.
Методы дедупликации данных обещают поставщикам облачных услуг сократить расходы. Возможность дедупликации того, что они хранят, приводит к снижению затрат на дисковое хранилище и пропускную способность для репликации за пределами площадки.
Что такое дедупликация данных и как она реализована?
Дедупликация, возможно, является самым большим достижением в технологии резервного копирования за последние два десятилетия.Он единолично отвечает за переход с ленты на диск для большей части данных резервного копирования, и его популярность только возрастает с каждым днем. Понимание различных видов дедупликации, также известных как дедупликация, важно для любого человека, интересующегося технологиями резервного копирования.
Что такое дедупликация данных?
Dedupe — это идентификация и устранение повторяющихся блоков в наборе данных. Это похоже на сжатие, которое определяет только избыточные блоки в одном файле.Дедупликация позволяет находить избыточные блоки данных между файлами из разных каталогов, разных типов данных, даже с разных серверов в разных местах.
Например, система дедупликации может идентифицировать уникальные блоки в электронной таблице и создавать их резервную копию. Если вы обновите его и снова создадите резервную копию, он сможет идентифицировать сегменты, которые изменились, и только выполнить их резервное копирование. Затем, если вы отправите его коллеге по электронной почте, он сможет определить те же блоки в вашей папке «Отправленные», их почтовом ящике и даже на жестком диске их ноутбука, если они сохранят их локально.Резервное копирование этих дополнительных копий тех же сегментов не потребуется; он только определит их местонахождение.
Как работает дедупликация?
Обычный способ дедупликации состоит в том, что данные, подлежащие дедупликации, разбиваются на так называемые фрагменты . Блок — это один или несколько смежных блоков данных. Вопрос о том, где и как делятся блоки, является предметом многих патентов, но достаточно сказать, что каждый продукт создает серию блоков, которые затем будут сравниваться со всеми предыдущими блоками, обнаруженными данной системой дедупликации.
Способ сравнения заключается в том, что каждый фрагмент проходит через детерминированный алгоритм криптографического хеширования, такой как SHA-1, SHA-2 или SHA-256, который создает так называемый хэш . Например, если ввести «Быстрая коричневая лиса перепрыгивает через ленивую собаку» в хэш-калькулятор SHA-1, вы получите следующее значение хеш-функции:
2FD4E1C67A2D28FCED849EE1BB76E7391B93EB12. (Вы можете попробовать это сами здесь: https://passwordsgenerator.net/sha1-hash-generator/ .)
Если хэши двух блоков совпадают, они считаются идентичными, потому что даже самое маленькое изменение вызывает хэш кусок, который нужно изменить.Хеш SHA-1 составляет 160 бит. Если вы создаете 160-битный хэш для блока размером 8 МБ, вы экономите почти 8 МБ при каждом резервном копировании этого же блока. Вот почему дедупликация так экономит место.
Целевая дедупликация
Целевая дедупликация — это наиболее распространенный тип дедупликации, продаваемый сегодня на рынке. Идея состоит в том, что вы покупаете целевое дисковое устройство с дедупликацией и отправляете свои резервные копии на его общий сетевой ресурс или на виртуальные ленточные накопители, если продукт представляет собой виртуальную ленточную библиотеку (VTL). Все этапы разделения и сравнения выполняются на целевом объекте; ничего из этого не делается в источнике.Это позволяет получить преимущества дедупликации без изменения программного обеспечения для резервного копирования.
Этот инкрементный подход позволил многим компаниям перейти с ленты на диск в качестве основного целевого объекта резервного копирования. Большинство клиентов копировали резервные копии на ленту для внешних целей. Некоторые опытные клиенты с большим бюджетом использовали возможности репликации этих целевых устройств с дедупликацией для репликации своих резервных копий за пределы площадки. Хорошая система дедупликации уменьшит размер типичного файла на 99%, а размер инкрементной резервной копии на 90%, что сделает возможной репликацию всех резервных копий.(В пределах разумного, конечно. Не у всех достаточно полосы пропускания для обработки такого уровня репликации.)
Дедупликация источника
Дедупликация источника происходит на клиенте резервного копирования — в источнике — отсюда и название источник или на стороне клиента дедупликации. Процесс фрагментации происходит на клиенте, а затем он передает хеш-значение на сервер резервного копирования для процесса поиска. Если сервер резервного копирования сообщает, что данный фрагмент уникален, фрагмент будет передан на сервер резервного копирования и записан на диск.Если сервер резервного копирования сообщает, что данный фрагмент был замечен ранее, его даже не нужно передавать. Это экономит пропускную способность и место для хранения.
Одним из критических замечаний по поводу дедупликации источника является то, что процесс создания хэша является ресурсоемкой операцией, требующей большой мощности процессора. Хотя это правда, обычно это компенсируется значительным сокращением количества ЦП, необходимого для передачи резервной копии, поскольку более 90% всех фрагментов будут дублироваться в любой данной резервной копии.
Экономия полосы пропускания также позволяет выполнять дедупликацию источника там, где дедупликация цели не может выполняться.Например, это позволяет компаниям создавать резервные копии своих ноутбуков или мобильных устройств, все из которых используют Интернет в качестве полосы пропускания. Для резервного копирования таких устройств с помощью целевой системы дедупликации потребуется устройство, локальное для каждого устройства, для которого выполняется резервное копирование. Вот почему дедупликация источника является предпочтительным методом удаленного резервного копирования.
По нескольким причинам в поле не так много установок дедупликации источника, как целевых. Одна из причин заключается в том, что целевые продукты с дедупликацией отсутствуют и стабильны дольше, чем большинство исходных продуктов с дедупликацией.Но, возможно, самая главная причина заключается в том, что дедупликация целевого объекта может быть реализована постепенно (то есть с использованием того же программного обеспечения для резервного копирования и просто с изменением целевого объекта), тогда как дедупликация источника обычно требует полной замены вашей системы резервного копирования. Наконец, не все реализации дедупликации исходного кода созданы равными, и некоторые из них попадали в сложный путь.
Дедупликация плюсы и минусы
Главное преимущество целевой дедупликации состоит в том, что вы можете использовать ее практически с любым программным обеспечением для резервного копирования, если оно поддерживается устройством.Обратной стороной является то, что вам нужно устройство везде, где вы собираетесь выполнять резервное копирование, даже если это просто виртуальное устройство. Главное преимущество дедупликации исходного кода — противоположное; вы можете делать резервные копии буквально из любого места. Такая гибкость может создать ситуации, когда резервное копирование соответствует вашим потребностям, а скорость восстановления — нет, поэтому обязательно примите это во внимание.
Присоединяйтесь к сообществам Network World на Facebook и LinkedIn, чтобы комментировать самые важные темы.Copyright © IDG Communications, Inc., 2018.
Что такое дедупликация данных? | Barracuda Networks
Дедупликация данных — это метод сжатия данных, при котором из системы удаляются избыточные копии данных. Он администрируется как в схемах резервного копирования данных, так и в схемах сетевых данных, и позволяет хранить уникальную модель данных либо в базе данных, либо в более широкой информационной системе. Дедупликация данных также известна как интеллектуальное сжатие, хранение отдельных экземпляров, факторинг общности или сокращение данных.
Дедупликация данных работает путем изучения и последующего сравнения входящих данных с уже сохраненными данными. Если какие-либо конкретные данные уже присутствуют, алгоритмы дедупликации удаляют новые данные и заменяют их ссылкой на уже существующие данные.
Например, когда создается резервная копия старого файла с некоторыми изменениями, предыдущий файл и примененные изменения добавляются к общему сегменту данных. Однако, если нет никакой разницы, более новый файл данных отбрасывается и создается ссылка.
Дедупликация данных — одна из технологий, на которую полагаются поставщики систем хранения, чтобы лучше использовать пространство хранения; другой — сжатие. Эти функции хранения обычно объединяются в более крупную категорию, называемую сокращением данных. Все эти системы помогают достичь одной цели — повысить эффективность хранения. Благодаря правильным методам дедупликации предприятия могут эффективно хранить больше данных, чем можно предположить по их общей емкости хранилища. Например, бизнес с 15 ТБ хранилища в сочетании с надлежащими методами дедупликации и сжатия может получить преимущество сокращения 4: 1, что означает, что можно будет хранить 60 ТБ в массиве данных 15 ТБ.
Пример использования дедупликации данных
Рассмотрим этот сценарий как практический пример преимущества дедупликации: организация использует среду виртуального рабочего стола с сотнями идентичных рабочих станций, все они хранятся в дорогом массиве хранения, который был приобретен специально для поддержки. Организация использует сотни копий программного обеспечения Windows 8, Office 2013, ERP и любых других инструментов, которые могут потребоваться пользователям. Каждый отдельный образ рабочей станции занимает, скажем, 25 ГБ дискового пространства.При наличии всего 200 таких рабочих станций только эти образы потребляли бы 5 ТБ емкости.
Благодаря дедупликации можно сохранить только одну копию этих отдельных виртуальных машин. Каждый раз, когда механизм обнаруживает фрагмент данных, который хранится где-то еще в среде хранения, система хранения сохраняет небольшой указатель на месте копии данных, тем самым освобождая блоки, которые обычно были бы заняты.
Типы дедупликации данных
Как и следовало ожидать, разные поставщики обрабатывают дедупликацию по-разному.Фактически, есть два основных метода дедупликации, которые заслуживают обсуждения:
Встроенная дедупликация происходит в момент записи данных в хранилище. Пока данные находятся в движении, механизм дедупликации помечает данные последовательно. Этот процесс, хотя и эффективен, создает накладные расходы на вычисления. Система должна неоднократно маркировать входящие данные, а затем быстро определять, совпадает ли этот новый отпечаток пальца с чем-то в системе. Если это так, записывается флаг, указывающий на существующий тег.В противном случае блок сохраняется без изменений. Встроенная дедупликация — важная функция для многих устройств хранения данных, и, хотя она приводит к накладным расходам, она не слишком проблематична и дает гораздо больше преимуществ, чем затрат.
Постпроцессная дедупликация , также известная как Асинхронная дедупликация , происходит, когда все данные записываются полностью, до тех пор, пока система дедупликации через равные промежутки времени не выполнит и не помечает все новые данные, не удалит несколько копий и не заменит их флагами. указывая на исходную копию данных.
Дедупликация после обработки позволяет предприятиям использовать свои услуги по сокращению данных, не беспокоясь о повторяющихся накладных расходах на обработку, вызванных встроенной дедупликацией. Этот процесс позволяет предприятиям планировать дедупликацию, чтобы она могла происходить в нерабочее время.
Самым большим недостатком дедупликации после обработки является то, что все данные хранятся в полной форме (часто называемой полностью гидратированной). Из-за этого для данных требуется все пространство, необходимое для данных без дедупликации.Только после запланированного процесса дедупликации происходит уменьшение размера. Для предприятий, использующих дедупликацию после обработки, всегда должны быть большие накладные расходы на емкость хранилища.
Дедупликация данных на стороне клиента — это метод дедупликации данных, который используется, например, на клиенте резервного копирования и архивирования для удаления избыточных данных во время обработки резервного копирования и архивирования перед передачей данных на сервер. Использование дедупликации данных на стороне клиента может уменьшить объем данных, отправляемых по локальной сети.
Сравнение аппаратной дедупликации и программной дедупликации
Функциональные устройства дедупликации снижают нагрузку на обработку, связанную с программными продуктами. Эти аппаратные системы дедупликации могут также добавлять дедупликацию в различные виды оборудования для защиты данных, такие как устройства резервного копирования, виртуальные ленточные библиотеки или хранилище NAS.
Несмотря на то, что программная дедупликация может эффективно устранить избыточность в ее источнике, аппаратные методы отдают приоритет сокращению данных на уровне хранилища.Из-за этого аппаратная дедупликация не принесет экономии полосы пропускания, достигаемой за счет дедупликации в источнике, но эта проблема компенсируется увеличением скорости сжатия.
Аппаратная дедупликация данных обеспечивает высокую производительность, масштабируемость и относительно бесперебойное развертывание. Он лучше всего подходит для развертываний корпоративного класса, а не для приложений малого и среднего бизнеса или удаленных офисов.
Программная дедупликация по большей части обходится дешевле и не требует каких-либо значительных изменений в физической сетевой инфраструктуре предприятия.Однако программную дедупликацию часто бывает сложнее установить и поддерживать. Необходимо установить агентов, чтобы обеспечить связь между локальным сайтом и сервером резервного копирования, на котором запущено одно и то же программное обеспечение.
Обзор дедупликации данных| N -able
За последние пару десятилетий технология резервного копированияпретерпела огромное количество улучшений, но немногие из них были столь же значительными, как развитие дедупликации данных. Дедупликация данных, которая удаляет дубликаты записей данных для экономии места для хранения, в той или иной форме используется с 1970-х годов.В то время клерки выявляли избыточные данные, которые просматривали данные строка за строкой, вручную выискивая дубликаты.
Сопутствующий продукт
Резервное копирование
Защита и восстановление данных никогда не было таким простым благодаря подходу, ориентированному на облако.
С тех пор, как объем данных рос в геометрической прогрессии, процесс стал автоматизированным. Фактически, в настоящее время объем данных растет настолько быстро, что даже новейшие решения для хранения данных с трудом справляются с этим — вот почему дедупликация данных важна как никогда.Как поставщик управляемых услуг (MSP) понимание того, что такое дедупликация данных и как она работает, может помочь вам оптимизировать емкость хранилища и сэкономить значительные суммы денег в долгосрочной перспективе.
Что такое дедупликация данных?Работая в качестве MSP, вы можете встретить клиентов, которые спрашивают: «Что такое дедупликация и сжатие данных?» Дедупликация данных — это процесс, при котором избыточные данные удаляются перед резервным копированием данных. Это позволяет хранить один уникальный экземпляр всех данных в базе данных без ненужного использования места для каких-либо копий.После удаления избыточных копий данных дедупликация данных дает вам возможность сжимать отдельные копии данных, которые хранятся, чтобы сэкономить еще больше места.
Важно помнить, что, хотя вы можете сжимать данные с помощью дедупликации, процесс дедупликации отличается от обычного сжатия данных. В последнем случае алгоритмы сжатия идентифицируют избыточные данные в отдельных файлах перед их более эффективным кодированием. С другой стороны, дедупликация проверяет большие объемы данных, выявляя одинаковые большие разделы (даже целые файлы).Затем он заменяет эти дубликаты одним общим файлом.
Например, если система электронной почты имеет 200 экземпляров одного и того же файлового вложения, дедупликация данных устранит избыточность в пользу одной сохраненной копии вложения. Это приводит к коэффициенту дедупликации (обсуждается ниже) 200: 1. Если вы представите себе, что размер каждого экземпляра вложения составляет 1 МБ, то ваши требования к хранилищу уменьшатся на 199 МБ.
Как работает дедупликация данных?Существует ряд различных процессов дедупликации данных, которые влияют на то, как работает дедупликация данных.По сути, функция дедупликации данных заключается в создании и сравнении групп данных, называемых «порциями». Однако есть несколько переменных, которые определяют, как работает каждый из этих различных процессов дедупликации данных.
Вы можете запустить дедупликацию на лету или дедупликацию после обработки. Разница между ними заключается в том, что при дедупликации постобработки дубликаты удаляются после того, как данные уже были записаны на диск. С другой стороны, при встроенном процессе дедупликация запускается по мере записи данных в систему хранения.С помощью программного обеспечения для дедупликации данных вы можете запускать как пост-обработку, так и встроенную дедупликацию данных для максимальной экономии.
Независимо от того, что вы используете, основные шаги дедупликации выполняются одинаково. Чтобы данные были дедуплицированы, они сначала разбиваются на блоки. Обычно это один или несколько смежных блоков данных. Каждая система дедупликации создает фрагменты по-разному, но независимо от того, каким образом фрагменты разбиваются, процесс сравнения фрагментов в основном остается одинаковым.
После разбивки данных начинается процесс анализа. Каждый отдельный фрагмент обрабатывается алгоритмом, который создает хэш — по сути, длинную серию цифр и букв, которые представляют данные, содержащиеся в фрагменте. Учитывая, что даже самое маленькое изменение данных в блоке вызывает изменение хэша, два разных блока, которые приводят к совпадению хэшей, считаются идентичными. Когда обнаруживается, что фрагмент избыточен, он заменяется небольшой ссылкой, указывающей на сохраненный фрагмент.
Какой метод дедупликации данных вам подходит?Еще одно различие между методами дедупликации данных заключается в дедупликации целевой и исходной. Основное различие между ними заключается в том, что дедупликация цели происходит рядом с местом, где хранятся данные, тогда как дедупликация источника происходит рядом с местом создания данных.
При целевой дедупликации процесс удаления дубликатов происходит, когда данные достигают целевого устройства хранения.Как только данные действительно достигают цели, дедупликацию можно выполнить до или после резервного копирования данных на устройство. Это означает, что сервер не знает о каких-либо усилиях по дедупликации, потому что работа по разделению на части и сравнению выполняется на целевом объекте. Как правило, это более популярный метод, хотя у него есть некоторые недостатки по сравнению с дедупликацией источника.
При дедупликации источника процесс удаления избыточных данных происходит в источнике, а не в целевом объекте. Обычно это происходит в самой файловой системе, где происходит периодическое сканирование новых файлов.Полученные хэши затем отправляются на сервер резервного копирования для сравнения. Если сервер находит блок уникальным, он затем передается на сервер резервного копирования и записывается на диск. Но если сервер находит идентичные хэши уже в системе, то блок не является уникальным и не передается на сервер резервного копирования. Это экономит как хранилище, так и полосу пропускания.
Одна из распространенных критических замечаний по поводу дедупликации источника заключается в том, что она использует большую мощность ЦП — больше, чем целевая дедупликация. Однако, учитывая значительное сокращение количества ЦП, необходимого для передачи резервных копий, увеличение количества ЦП, используемого в процессе дедупликации источника, обычно компенсируется в долгосрочной перспективе.
Основное отличие, которое необходимо учитывать при выборе подходящего для вас метода дедупликации данных, заключается в том, как на самом деле разыгрываются процессы дедупликации. При использовании метода целевой дедупликации вам необходимо приобрести целевые дисковые устройства для дедупликации. Эти устройства должны быть везде, где вы собираетесь выполнять резервное копирование. Хотя это может быть дорогостоящим, оно дает дополнительное преимущество в виде возможности инкрементной дедупликации. При инкрементной дедупликации вы используете то же программное обеспечение для резервного копирования, но просто меняете цель.Он также позволяет выполнять целевую дедупликацию практически с любым программным обеспечением для резервного копирования, если оно поддерживается устройством. Это означает, что вам не нужно проводить полную замену всей системы резервного копирования.
При дедупликации исходных данных обычно требуется полная замена всей системы резервного копирования. Однако, в отличие от целевой дедупликации, вам не нужно локальное устройство для каждого устройства, для которого требуется создать резервную копию. Поскольку вы можете выполнять резервное копирование из любого места с помощью дедупликации источника, это идеальный метод дедупликации данных, если у вас много удаленных устройств, таких как ноутбуки и мобильные устройства.
Дедупликация данных в облакеВсе более широкое использование облака открывает удивительные возможности для дедупликации данных. Некоторые из лучших коэффициентов дедупликации данных часто достигаются с помощью сред виртуальных серверов. Это связано с тем, что в виртуальных средах существует огромное количество избыточных данных, которые можно легко удалить с помощью процесса дедупликации данных.
По мере того, как все больше и больше компаний переходят на виртуальные облачные среды для хранения данных, дедупликация данных также открывает двери для новых возможностей с хранимыми данными.В частности, улучшается управление данными. Предоставляя исторический контекст для информации, дедупликация данных улучшает способность ИТ-отдела понимать закономерности использования данных. Это понимание затем можно использовать для упреждающей оптимизации избыточности данных для пользователей в распределенных средах.
Что такое коэффициент дедупликации?Как упоминалось ранее, коэффициент дедупликации данных — это сравнение между исходным размером данных и его размером после удаления избыточности.По сути, это показатель эффективности процесса дедупликации. По мере увеличения коэффициента дедупликации процесс дедупликации дает сравнительно более слабые результаты, учитывая, что большая часть избыточности уже удалена. Например, коэффициент дедупликации 500: 1 ненамного лучше, чем коэффициент 100: 1 — в первом случае удаляется 99,8% данных по сравнению с 99% данных во втором.
Факторы, которые имеют наибольшее влияние на коэффициент дедупликации:
- Хранение данных. Чем дольше хранятся данные, тем выше вероятность обнаружения избыточности.
- Тип данных. Некоторые типы файлов имеют более высокий уровень избыточности, чем другие.
- Скорость изменения. Если ваши данные часто меняются, у вас, вероятно, будет более низкий коэффициент дедупликации.
- Местоположение. Чем шире объем ваших усилий по дедупликации данных, тем выше вероятность обнаружения дубликатов. Например, глобальная дедупликация в нескольких системах обычно дает более высокий коэффициент, чем локальная дедупликация на одном устройстве.
Дедупликация данных важна, поскольку она значительно сокращает потребность в пространстве для хранения, экономит ваши деньги и сокращает потери полосы пропускания при передаче данных в / из удаленных хранилищ. В некоторых случаях дедупликация данных может снизить требования к хранилищу до 95%, хотя такие факторы, как тип данных, которые вы пытаетесь дедуплицировать, будут влиять на ваш конкретный коэффициент дедупликации. Даже если ваши требования к хранилищу уменьшатся менее чем на 95%, дедупликация данных все равно может привести к огромной экономии и значительному увеличению доступности полосы пропускания.