работа со строками, форматирование,методы split, strip
В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Вы уже видели операторы + и * в применении их к числовым значениям в уроке по операторам в Python . Эти два оператора применяются и к строкам.
Оператор сложения строк
++ — оператор конкатенации строк.
>>> s = 'py'
>>> t = 'th'
>>> u = 'on'
>>> s + t
'pyth'
>>> s + t + u
'python'
>>> print('Привет, ' + 'Мир!')
Go team!!!
Оператор умножения строк
** — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s:
s * nn * s
>>> s = 'py.'
>>> s * 4
'py.py.py.py.'
>>> 4 * s
'py.py.py.py.'
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
>>> 'py' * -6
''
Если вы создадите строковую переменную и превратите ее в пустую строку, с помощью 'py' * -6, кто-нибудь будет справедливо считать вас немного глупым. Но это сработает.
Но это сработает.
Оператор принадлежности подстроки
inPython также предоставляет оператор принадлежности, который можно использоваться для манипуляций со строками. Оператор True, если подстрока входит в строку, и False, если нет:
>>> s = 'Python'
>>> s in 'I love Python.'
True
>>> s in 'I love Java.'
False
Есть также оператор not in, у которого обратная логика:
>>> 'z' not in 'abc'
True
>>> 'z' not in 'xyz'
False
Встроенные функции строк в python
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
Самая простая схема в повседневном использовании называется ASCII . Она охватывает латинские символы, с которыми мы чаще работает. Для этих символов ord(c) возвращает значение ASCII для символа c:
>>> ord('a')
97
>>> ord('#')
35
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе.
Функция ord() также возвращает числовые значения для символов Юникода:
>>> ord('€')
8364
>>> ord('∑')
8721
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() действует обратно ord(). Если задано числовое значение n, chr(n) возвращает строку, представляющую символ n
>>> chr(97)
'a'
>>> chr(35)
'#'
chr() также обрабатывает символы Юникода:
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s:
>>> s = 'Простоя строка. '
>>> len(s)
15
'
>>> len(s)
15
 '
>>> len(s)
15
'
>>> len(s)
15
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('py')
'py'
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
В Python строки являются упорядоченными последовательностями символьных данных и могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках
Индексация строк начинается с нуля: у первого символа индекс 0, следующего 1 и так далее. Индекс последнего символа в python — ‘‘длина строки минус один’’.
Индекс последнего символа в python — ‘‘длина строки минус один’’.
Например, схематическое представление индексов строки 'foobar' выглядит следующим образом:
Отдельные символы доступны по индексу следующим образом:
>>> s = 'foobar' >>> s[0] 'f' >>> s[1] 'o' >>> s[3] 'b' >>> s[5] 'r'
Попытка обращения по индексу большему чем len(s) - 1, приводит к ошибке IndexError:
>>> s[6]
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
s[6]
IndexError: string index out of range
Индексы строк также могут быть указаны отрицательными числами. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее. Вот такая же диаграмма, показывающая как положительные, так и отрицательные индексы строки 'foobar'
Вот несколько примеров отрицательного индексирования:
>>> s = 'foobar'
>>> s[-1]
'r'
>>> s[-2]
'a'
>>> len(s)
6
>>> s[-len(s)]
'f'
Попытка обращения по индексу меньшему чем -len(s), приводит к ошибке IndexError:
>>> s[-7]
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
s[-7]
IndexError: string index out of range
Для любой непустой строки s, код s[len(s)-1] и s[-1] возвращают последний символ.
Срезы строк
Python также допускает возможность извлечения подстроки из строки, известную как ‘‘string slice’’. Если s это строка, выражение формы s[m:n] возвращает часть s, начинающуюся с позиции m, и до позиции n, но не включая позицию:
>>> s = 'python'
>>> s[2:5]
'tho'
Помните: индексы строк в python начинаются с нуля. Первый символ в строке имеет индекс
0. Это относится и к срезу.
Опять же, второй индекс указывает символ, который не включен в результат. Символ s[m:n] вернет подстроку, которая является разницей n - m, в данном случае 5 - 2 = 3.
Если пропустить первый индекс, срез начинается с начала строки. Таким образом,
Таким образом, s[:m] = s[0:m]:
>>> s = 'python'
>>> s[:4]
'pyth'
>>> s[0:4]
'pyth'
Аналогично, если опустить второй индекс s[n:], срез длится от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздкой s[n:len(s)]:
>>> s = 'python'
>>> s[2:]
'thon'
>>> s[2:len(s)]
'thon'
Для любой строки s и любого целого n числа (0 ≤ n ≤ len(s)), s[:n] + s[n:]будет s:
>>> s = 'python'
>>> s[:4] + s[4:]
'python'
>>> s[:4] + s[4:] == s
True
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
>>> s = 'python'
>>> t = s[:]
>>> id(s)
59598496
>>> id(t)
59598496
>>> s is t
True
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
>>> s[2:2]
''
>>> s[4:2]
''
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
>>> s = 'python'
>>> s[-5:-2]
'yth'
>>> s[1:4]
'yth'
>>> s[-5:-2] == s[1:4]
True
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
Например , для строки 'python' срез 0:6:2 начинается с первого символа и заканчивается последним символом (всей строкой), каждый второй символ пропускается. Это показано на следующей схеме:
Иллюстративный код показан здесь:
>>> s = 'foobar'
>>> s[0:6:2]
'foa'
>>> s[1:6:2]
'obr'
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::5]
'11111'
>>> s[4::5]
'55555'
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
Начальный/первый индекс должен быть больше конечного/второго индекса:
>>> s = 'python'
>>> s[5:0:-2]
'nhy'
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::-5]
'55555'
Это общая парадигма для разворота (reverse) строки:
>>> s = 'Если так говорит товарищ Наполеон, значит, так оно и есть.'
>>> s[::-1]
'.ьтсе и оно кат ,тичанз ,ноелопаН щиравот тировог кат илсЕ'
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале (f'string'), и python заменит имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого print() и оператора ,, разделяющего числовые значения и строковые:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('Произведение', n, 'на', m, 'равно', prod)
Произведение 20 на 25 равно 500
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
- Напишите
fилиFперед кавычками строки. Это укажет python, что это f-строка вместо стандартной. - Укажите любые переменные для воспроизведения в фигурных скобках (
{}).
 Это укажет python, что это f-строка вместо стандартной.
Это укажет python, что это f-строка вместо стандартной.Код с использованием f-string, приведенный ниже выглядит намного чище:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'Произведение {n} на {m} равно {prod}')
Произведение 20 на 25 равно 500
Любой из трех типов кавычек в python можно использовать для f-строки:
>>> var = 'Гав'
>>> print(f'Собака говорит {var}!')
Собака говорит Гав!
>>> print(f"Собака говорит {var}!")
Собака говорит Гав!
>>> print(f'''Собака говорит {var}!''')
Собака говорит Гав!
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError:
>>> s = 'python'
>>> s[3] = 't'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[3] = 't'
TypeError: 'str' object does not support item assignment
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
>>> s = s[:3] + 't' + s[4:]
>>> s
'pytton'
Есть встроенный метод string.replace(x, y):
>>> s = 'python'
>>> s = s.replace('h', 't')
>>> s
'pytton'
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
obj.foo(<args>)
Этот код вызывает метод .foo() объекта obj. <args> — аргументы, передаваемые методу (если есть).
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ([]), являются необязательными.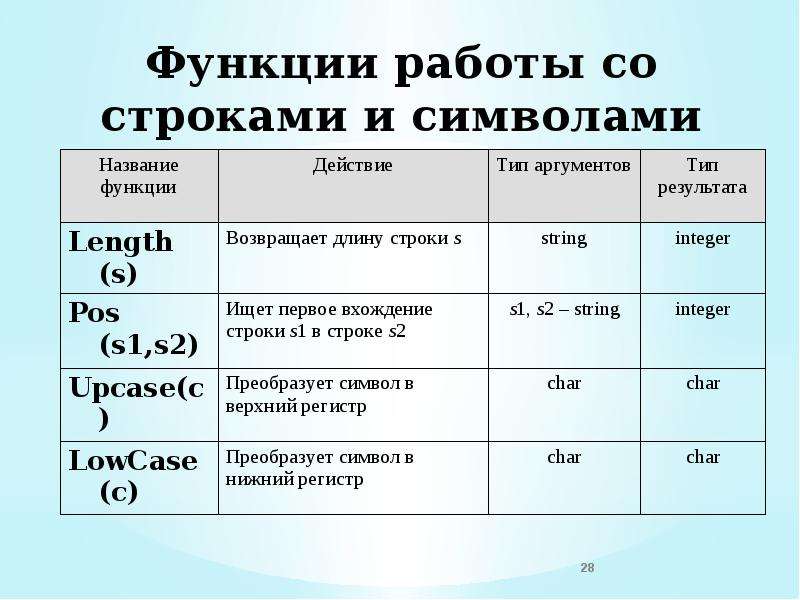
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
>>> s = 'everyTHing yoU Can IMaGine is rEAl'
>>> s.capitalize()
'Everything you can imagine is real'
Не алфавитные символы не изменяются:
>>> s = 'follow us @PYTHON'
>>> s.capitalize()
'Follow us @python'
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
>>> 'everyTHing yoU Can IMaGine is rEAl'. lower()
'everything you can imagine is real'
 lower()
'everything you can imagine is real'
lower()
'everything you can imagine is real'
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
>>> 'everyTHing yoU Can IMaGine is rEAl'.swapcase()
'EVERYthING YOu cAN imAgINE IS ReaL'
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
>>> 'the sun also rises'.title()
'The Sun Also Rises'
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
>>> 'follow us @PYTHON'. title()
'Follow Us @Python'
 title()
'Follow Us @Python'
title()
'Follow Us @Python'
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
>>> 'follow us @PYTHON'.upper()
'FOLLOW US @PYTHON'
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы <start> и <end> аргументы. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа <start> и продолжающейся вплоть до позиции символа <end>, но не включая его. Если <start> указано, а <end> нет, метод применяется к части строки от <start> конца.
string. подсчитывает количество вхождений подстроки в строку. count(<sub>[, <start>[, <end>]])
count(<sub>[, <start>[, <end>]])
s.count(<sub>) возвращает количество точных вхождений подстроки <sub> в s:
>>> 'foo goo moo'.count('oo')
3
Количество вхождений изменится, если указать <start> и <end>:
>>> 'foo goo moo'.count('oo', 0, 8)
2
string.endswith(<suffix>[, <start>[, <end>]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith(<suffix>) возвращает, True если s заканчивается указанным <suffix> и False если нет:
>>> 'python'.endswith('on')
True
>>> 'python'.endswith('or')
False
Сравнение ограничено подстрокой, между <start> и <end>, если они указаны:
>>> 'python'. endswith('yt', 0, 4)
True
>>> 'python'.endswith('yt', 2, 4)
False
 endswith('yt', 0, 4)
True
>>> 'python'.endswith('yt', 2, 4)
False
endswith('yt', 0, 4)
True
>>> 'python'.endswith('yt', 2, 4)
False
string.find(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку.
s.find(<sub>) возвращает первый индекс в s который соответствует началу строки <sub>:
>>> 'Follow Us @Python'.find('Us')
7
Этот метод возвращает, -1 если указанная подстрока не найдена:
>>> 'Follow Us @Python'.find('you')
-1
Поиск в строке ограничивается подстрокой, между <start> и <end>, если они указаны:
>>> 'Follow Us @Python'.find('Us', 4)
7
>>> 'Follow Us @Python'.find('Us', 4, 7)
-1
string.index(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку.
Этот метод идентичен .find(), за исключением того, что он вызывает исключение ValueError, если <sub> не найден:
>>> 'Follow Us @Python'.index('you')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'Follow Us @Python'.index('you')
ValueError: substring not found
string.rfind(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку, начиная с конца.
s.rfind(<sub>) возвращает индекс последнего вхождения подстроки <sub> в s, который соответствует началу <sub>:
>>> 'Follow Us @Python'.rfind('o')
15
Как и в .find(), если подстрока не найдена, возвращается -1:
>>> 'Follow Us @Python'.rfind('a')
-1
Поиск в строке ограничивается подстрокой, между <start> и <end>, если они указаны:
>>> 'Follow Us @Python'. rfind('Us', 0, 14)
7
>>> 'Follow Us @Python'.rfind('Us', 9, 14)
-1
 rfind('Us', 0, 14)
7
>>> 'Follow Us @Python'.rfind('Us', 9, 14)
-1
rfind('Us', 0, 14)
7
>>> 'Follow Us @Python'.rfind('Us', 9, 14)
-1
string.rindex(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение ValueError, если <sub> не найден:
>>> 'Follow Us @Python'.rindex('you')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'Follow Us @Python'.rindex('you')
ValueError: substring not found
string.startswith(<prefix>[, <start>[, <end>]]) определяет, начинается ли строка с заданной подстроки.
s.startswith(<suffix>) возвращает, True если s начинается с указанного <suffix> и False если нет:
>>> 'Follow Us @Python'. startswith('Fol')
True
>>> 'Follow Us @Python'.startswith('Go')
False
 startswith('Fol')
True
>>> 'Follow Us @Python'.startswith('Go')
False
startswith('Fol')
True
>>> 'Follow Us @Python'.startswith('Go')
False
Сравнение ограничено подстрокой, между <start> и <end>, если они указаны:
>>> 'Follow Us @Python'.startswith('Us', 7)
True
>>> 'Follow Us @Python'.startswith('Us', 8, 16)
False
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
s.isalnum() возвращает True, если строка s не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра). В другом случае False :
>>> 'abc123'.isalnum()
True
>>> 'abc$123'.isalnum()
False
>>> ''.isalnum()
False
string. определяет, состоит ли строка только из букв. isalpha()
isalpha()
s.isalpha() возвращает True, если строка s не пустая, а все ее символы буквенные. В другом случае False:
>>> 'ABCabc'.isalpha()
True
>>> 'abc123'.isalpha()
False
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
>>> '123'.isdigit()
True
>>> '123abc'.isdigit()
False
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
s.isidentifier() возвращает True, если s валидный идентификатор (название переменной, функции, класса и т. д.) python, а в
д.) python, а в False если нет:
>>> 'foo32'.isidentifier()
True
>>> '32foo'.isidentifier()
False
>>> 'foo$32'.isidentifier()
False
Важно: .isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову python, даже если его нельзя использовать:
>>> 'and'.isidentifier()
True
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword(), которая находится в модуле keyword. Один из возможных способов сделать это:
>>> from keyword import iskeyword
>>> iskeyword('and')
True
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор python, вы должны проверить, что .isidentifier() = True и iskeyword() = False.
string.islower() определяет, являются ли буквенные символы строки строчными.
s.islower() возвращает True, если строка s не пустая, и все содержащиеся в нем буквенные символы строчные, а False если нет. Не алфавитные символы игнорируются:
>>> 'abc'.islower()
True
>>> 'abc1$d'.islower()
True
>>> 'Abc1$D'.islower()
False
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
>>> 'a\tb'.isprintable()
False
>>> 'a b'. isprintable()
True
>>> ''.isprintable()
True
>>> 'a\nb'.isprintable()
False
 isprintable()
True
>>> ''.isprintable()
True
>>> 'a\nb'.isprintable()
False
isprintable()
True
>>> ''.isprintable()
True
>>> 'a\nb'.isprintable()
False
Важно: Это единственный .is****() метод, который возвращает True, если s пустая строка. Все остальные возвращаются False.
string.isspace() определяет, состоит ли строка только из пробельных символов.
s.isspace() возвращает True, если s не пустая строка, и все символы являются пробельными, а False, если нет.
Наиболее часто встречающиеся пробельные символы — это пробел ' ', табуляция '\t' и новая строка '\n':
>>> ' \t \n '.isspace()
True
>>> ' a '.isspace()
False
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
>>> '\f\u2005\r'. isspace()
True
 isspace()
True
isspace()
True
'\f' и '\r' являются escape-последовательностями для символов ASCII; '\u2005' это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
s.istitle() возвращает True когда s не пустая строка и первый алфавитный символ каждого слова в верхнем регистре, а все остальные буквенные символы в каждом слове строчные. Возвращает False, если нет:
>>> 'This Is A Title'.istitle()
True
>>> 'This is a title'.istitle()
False
>>> 'Give Me The #$#@ Ball!'.istitle()
True
string.isupper() определяет, являются ли буквенные символы строки заглавными.
s.isupper() возвращает True, если строка s не пустая, и все содержащиеся в ней буквенные символы являются заглавными, и в False, если нет. Не алфавитные символы игнорируются:
Не алфавитные символы игнорируются:
>>> 'ABC'.isupper()
True
>>> 'ABC1$D'.isupper()
True
>>> 'Abc1$D'.isupper()
False
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center(<width>[, <fill>]) выравнивает строку по центру.
s.center(<width>) возвращает строку, состоящую из s выровненной по ширине <width>. По умолчанию отступ состоит из пробела ASCII:
>>> 'py'.center(10)
' py '
Если указан необязательный аргумент <fill>, он используется как символ заполнения:
>>> 'py'.center(10, '-')
'----py----'
Если s больше или равна <width>, строка возвращается без изменений:
>>> 'python'. center(2)
'python'
 center(2)
'python'
center(2)
'python'
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ('\t') пробелами. По умолчанию табуляция заменяются на 8 пробелов:
>>> 'a\tb\tc'.expandtabs()
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs()
'aaa bbb c'
tabsize необязательный параметр, задающий количество пробелов:
>>> 'a\tb\tc'.expandtabs(4)
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs(tabsize=4)
'aaa bbb c'
string.ljust(<width>[, <fill>]) выравнивание по левому краю строки в поле.
s.ljust(<width>) возвращает строку s, выравненную по левому краю в поле шириной <width>. По умолчанию отступ состоит из пробела ASCII:
>>> 'python'. ljust(10)
'python '
 ljust(10)
'python '
ljust(10)
'python '
Если указан аргумент <fill> , он используется как символ заполнения:
>>> 'python'.ljust(10, '-')
'python----'
Если s больше или равна <width>, строка возвращается без изменений:
>>> 'python'.ljust(2)
'python'
string.lstrip([<chars>]) обрезает пробельные символы слева
s.lstrip()возвращает копию s в которой все пробельные символы с левого края удалены:
>>> ' foo bar baz '.lstrip()
'foo bar baz '
>>> '\t\nfoo\t\nbar\t\nbaz'.lstrip()
'foo\t\nbar\t\nbaz'
Необязательный аргумент <chars>, определяет набор символов, которые будут удалены:
>>> 'https://www.pythonru.com'.lstrip('/:pths')
'www.pythonru.com'
string. заменяет вхождения подстроки в строке. replace(<old>, <new>[, <count>])
replace(<old>, <new>[, <count>])
s.replace(<old>, <new>) возвращает копию s где все вхождения подстроки <old>, заменены на <new>:
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love')
'I love python! I love python! I love python!'
Если указан необязательный аргумент <count>, выполняется количество <count> замен:
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love', 2)
'I love python! I love python! I hate python!'
string.rjust(<width>[, <fill>]) выравнивание по правому краю строки в поле.
s.rjust(<width>) возвращает строку s, выравненную по правому краю в поле шириной <width>. По умолчанию отступ состоит из пробела ASCII:
По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.rjust(10)
' python'
Если указан аргумент <fill> , он используется как символ заполнения:
>>> 'python'.rjust(10, '-')
'----python'
Если s больше или равна <width>, строка возвращается без изменений:
>>> 'python'.rjust(2)
'python'
string.rstrip([<chars>]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
>>> ' foo bar baz '.rstrip()
' foo bar baz'
>>> 'foo\t\nbar\t\nbaz\t\n'.rstrip()
'foo\t\nbar\t\nbaz'
Необязательный аргумент <chars>, определяет набор символов, которые будут удалены:
>>> 'foo. $$$;'.rstrip(';$.')
'foo'
 $$$;'.rstrip(';$.')
'foo'
$$$;'.rstrip(';$.')
'foo'
string.strip([<chars>]) удаляет символы с левого и правого края строки.
s.strip() эквивалентно последовательному вызову s.lstrip()и s.rstrip(). Без аргумента <chars> метод удаляет пробелы в начале и в конце:
>>> s = ' foo bar baz\t\t\t'
>>> s = s.lstrip()
>>> s = s.rstrip()
>>> s
'foo bar baz'
Как в .lstrip() и .rstrip(), необязательный аргумент <chars> определяет набор символов, которые будут удалены:
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
>>> ' foo bar baz\t\t\t'.lstrip(). rstrip()
'foo bar baz'
>>> ' foo bar baz\t\t\t'.strip()
'foo bar baz'
>>> 'www.pythonru.com'.lstrip('w.').rstrip('.moc')
'pythonru'
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
 rstrip()
'foo bar baz'
>>> ' foo bar baz\t\t\t'.strip()
'foo bar baz'
>>> 'www.pythonru.com'.lstrip('w.').rstrip('.moc')
'pythonru'
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
rstrip()
'foo bar baz'
>>> ' foo bar baz\t\t\t'.strip()
'foo bar baz'
>>> 'www.pythonru.com'.lstrip('w.').rstrip('.moc')
'pythonru'
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
string.zfill(<width>) дополняет строку нулями слева.
s.zfill(<width>) возвращает копию s дополненную '0' слева для достижения длины строки указанной в <width>:
>>> '42'.zfill(5)
'00042'
Если s содержит знак перед цифрами, он остается слева строки:
>>> '+42'.zfill(8)
'+0000042'
>>> '-42'.zfill(8)
'-0000042'
Если s больше или равна <width>, строка возвращается без изменений:
>>> '-42'.zfill(3)
'-42'
. наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел: zfill()
zfill()
>>> 'foo'.zfill(6)
'000foo'
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( []), а кортеж заключен в простые (()).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join(<iterable>) объединяет список в строку.
s.join(<iterable>) возвращает строку, которая является результатом конкатенации объекта <iterable> с разделителем s.
Обратите внимание, что .join() вызывается строка-разделитель s . <iterable> должна быть последовательностью строковых объектов.
Примеры кода помогут вникнуть. В первом примере разделителем s является строка ', ', а <iterable> список строк:
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере <iterable> указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
Таким образом, результатом ':'.join('corge') является строка, состоящая из каждого символа в 'corge', разделенного символом ':'.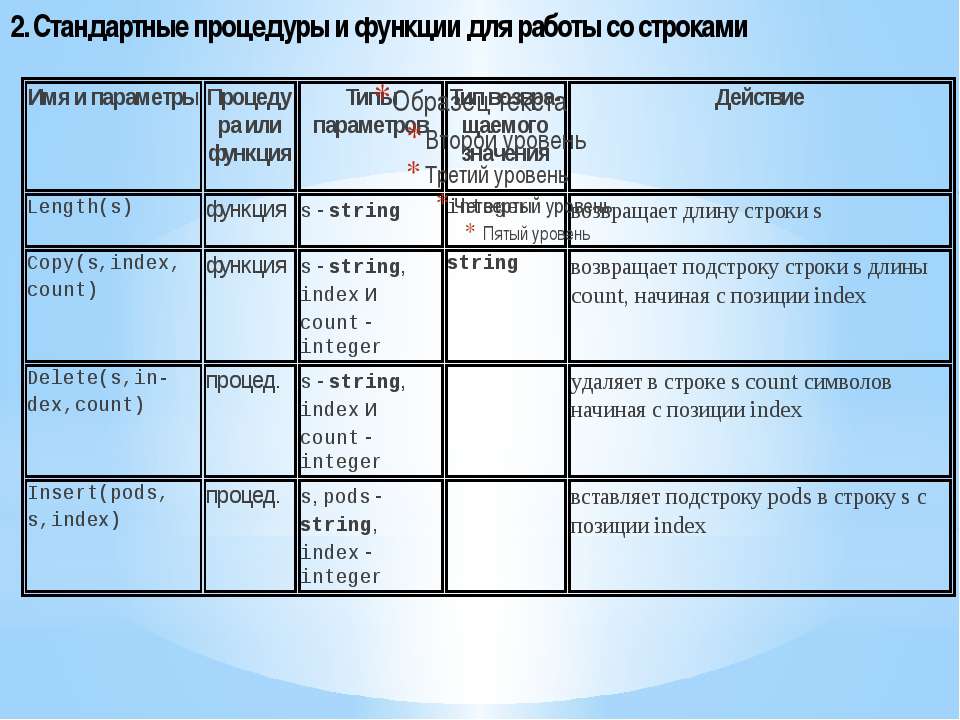
Этот пример завершается с ошибкой TypeError, потому что один из объектов в <iterable> не является строкой:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
Это можно исправить так:
>>> '---'.join(['foo', str(23), 'bar'])
'foo---23---bar'
Как вы скоро увидите, многие объекты в Python можно итерировать, и .join() особенно полезен для создания из них строк.
string.partition(<sep>) делит строку на основе разделителя.
s.partition(<sep>) отделяет от s подстроку длиной от начала до первого вхождения <sep>. Возвращаемое значение представляет собой кортеж из трех частей:
- Часть
sдо<sep> - Разделитель
<sep> - Часть
sпосле<sep>
Вот пара примеров .в работе: partition()
partition()
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
Если <sep> не найден в s, возвращаемый кортеж содержит s и две пустые строки:
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
s.rpartition(<sep>) делит строку на основе разделителя, начиная с конца.
s.rpartition(<sep>) работает как s.partition(<sep>), за исключением того, что s делится при последнем вхождении <sep> вместо первого:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
>>> 'foo bar baz qux'.rsplit()
['foo', 'bar', 'baz', 'qux']
>>> 'foo\n\tbar baz\r\fqux'.rsplit()
['foo', 'bar', 'baz', 'qux']
Если <sep> указан, он используется в качестве разделителя:
>>> 'foo.bar.baz.qux'.rsplit(sep='.')
['foo', 'bar', 'baz', 'qux']
Если <sep> = None, строка разделяется пробелами, как если бы <sep> не был указан вообще.
Когда <sep> явно указан в качестве разделителя s, последовательные повторы разделителя будут возвращены как пустые строки:
>>> 'foo...bar'.rsplit(sep='.')
['foo', '', '', 'bar']
Это не работает, когда <sep> не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
>>> 'foo\t\t\tbar'.rsplit()
['foo', 'bar']
Если указан необязательный параметр <maxsplit>, выполняется максимальное количество разделений, начиная с правого края s:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=1)
['www.pythonru', 'com']
Значение по умолчанию для <maxsplit> — -1. Это значит, что все возможные разделения должны быть выполнены:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=-1)
['www', 'pythonru', 'com']
>>> 'www.pythonru.com'.rsplit(sep='.')
['www', 'pythonru', 'com']
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
s.split() ведет себя как s., за исключением того, что при указании  rsplit()
rsplit()<maxsplit>, деление начинается с левого края s:
>>> 'www.pythonru.com'.split('.', maxsplit=1)
['www', 'pythonru.com']
>>> 'www.pythonru.com'.rsplit('.', maxsplit=1)
['www.pythonru', 'com']
Если <maxsplit> не указано, между .rsplit() и .split() в python разницы нет.
string.splitlines([<keepends>]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
>>> 'foo\nbar\r\nbaz\fqux\u2028quux'. splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
 splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
>>> 'foo\f\f\fbar'.splitlines()
['foo', '', '', 'bar']
Если необязательный аргумент <keepends> указан и его булевое значение True, то символы границы строк сохраняются в списке подстрок:
>>> 'foo\nbar\nbaz\nqux'.splitlines(True)
['foo\n', 'bar\n', 'baz\n', 'qux']
>>\> 'foo\nbar\nbaz\nqux'.splitlines(8)
['foo\n', 'bar\n', 'baz\n', 'qux']
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:
Работа со строками в Python.
 Готовимся к собеседованию: вспоминаем азы
Готовимся к собеседованию: вспоминаем азыПетр Смолович
ведущий разработчик хостинг-провайдера и регистратора доменов REG.RU
В этой статье мы разберем работу со строками в Python с необычного угла — глазами интервьюера на собеседовании. Информация будет полезна как новичку, так и уверенному джуну. В первой части поговорим о базовых операциях. Во второй — разберем примеры задач и вопросов, к которым стоит быть готовым.
Итак, мы на собеседовании, и я хочу узнать, умеете ли вы обращаться со строками.
Как склеить две строки?
>>> s = "abc" + "def"
>>> s += "xyz"Элементарно? Почти. Важно помнить, что строки — это неизменяемые объекты. Каждый раз, когда мы говорим про «изменение» строки, технически мы создаем новый объект и записываем туда вычисленное значение.
А как склеить три строки? Напрашивается ответ «точно так же», и иногда это самый лучший способ. Но интервьюер скорее всего хочет проверить, знаете ли вы про метод .. join()
join()
>>> names = ["John", "Paul", "Ringo", "George"]
>>> ", ".join(names)
'John, Paul, Ringo, George'join() — очень удобный метод, позволяющий склеить N строк, причём с произвольным разделителем.
Здесь важно не только получить результат, но и понимать, как работает приведённая конструкция. А именно, что join() — это метод объекта «строка», принимающий в качестве аргумента список и возвращающий на выходе новую строку.
Кстати, хорошая задачка для интервью — написать свою реализацию join().
Разделить строки?
Есть несколько способов получить часть строки. Первый — это split, обратный метод для join. В отличие от join’а, он применяется к целевой строке, а разделитель передаётся аргументом.
>>> s = "Альфа, Браво, Чарли"
>>> s.split(", ")
['Альфа', 'Браво', 'Чарли']Второй — срезы (slices).
Срез s[x:y] позволяет получить подстроку с символа x до символа y. Можно не указывать любое из значений, чтобы двигаться с начала или до конца строки. Отрицательные значения используются для отсчёта с конца (-1 — последний символ, -2 — предпоследний и т.п.).
>>> s = "Hello, world!"
>>> print(s[0:5])
Hello
>>> print(s[-6:])
world!При помощи необязательного третьего параметра s[x:y:N] можно выбрать из подстроки каждый N-ый символ. Например, получить только чётные или только нечётные символы:
>>> s = "0123456789"
>>> print(s[::2])
02468
>>> print(s[1::2])
13579Что насчёт поиска в строке?
Самое быстрое — проверить, начинается ли (заканчивается ли) строка с выбранных символов. Для этого в Python предусмотрены специальные строковые методы.
>>> s = "0123456789"
>>> s.startswith("012")
True
>>> s. /]+)(.*)$", s)
>>> print(result.group(1))
https
>>> print(result.group(2))
www.reg.ru
>>> print(result.group(3))
/hosting/ /]+)(.*)$", s)
>>> print(result.group(1))
https
>>> print(result.group(2))
www.reg.ru
>>> print(result.group(3))
/hosting/
/]+)(.*)$", s)
>>> print(result.group(1))
https
>>> print(result.group(2))
www.reg.ru
>>> print(result.group(3))
/hosting/А замену в строке сделать сможете?
Во-первых, при помощи срезов и склейки строк можно заменить что угодно.
>>> s = "Hello, darling! How are you?"
>>> s[:7] + "Василий" + s[14:]
'Hello, Василий! How are you?'Во-вторых, умеешь find(), умей и replace().
>>> s.replace("darling", "Василий")
'Hello, Василий! How are you?'В-третьих, любую проблему можно решить регулярными выражениями. Либо получить две проблемы 🙂 В случае с заменой вам нужен метод re.sub().
>>> s = "https://www.reg.ru/hosting/";
>>> import re
>>> print(re.sub('[a-z]', 'X', s))
XXXXX://XXX.XXX.XX/XXXXXXX/Посимвольная обработка?
Есть бесчисленное множество задачек, которые можно решить, пройдясь в цикле по строке. Например, посчитать количество букв «о».
>>> s = "Hello, world!"
>>> for c in s:
>>> if c == "o":
>>> counter += 1
>>> print(counter)
2Иногда удобнее бежать по индексу.
>>> for i in range(len(s)):
>>> if s[i] == "o":
>>> counter += 1Помним, что строки неизменяемы, поэтому подменить i-ый символ по индексу не получится, нужно создавать новый объект:
>>> s[i] = "X"
Traceback (most recent call last):
File "", line 1, in
TypeError: 'str' object does not support item assignment
>>> s[:i] + "X" + s[i+1:]
'HellX, world!'Либо можно преобразовать строку в список, сделать обработку, а потом склеить список обратно в строку:
>>> arr = list(s)
>>> "".join(arr)
'Hello, world!'А форматирование строк?
Типичная жизненная необходимость — сформировать строку, подставив в неё результат работы программы. Начиная с Python 3.6, это можно делать при помощи f-строк:
>>> f"Строка '{s}' содержит {len(s)} символов."
"Строка 'Hello, world!' содержит 13 символов."В более старом коде можно встретить альтернативные способы
>>> "Строка '%s' содержит %d символов" % (s, len(s))
>>> "Строка '{}' содержит {} символов".format(s, len(s))Технически можно было обойтись склейкой, но это менее элегантно, а еще придётся следить, чтобы все склеиваемые кусочки были строками. Не рекомендую:
>>> "Строка '" + s + "' содержит " + str(len(s)) + " символов."
"Строка 'Hello, world!' содержит 13 символов."***
Цель работодателя на собеседовании — убедиться что вы соображаете и что вы справитесь с реальными задачами. Однако погружение в реальные задачи занимает несколько недель, а время интервью ограничено. Поэтому вас ждут учебные задания, которые можно решить за 10-30 минут, а также вопросы на понимание того, как работает код. О них и поговорим в следующей части.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
41 вопрос о работе со строками в Python / Блог компании RUVDS.com / Хабр
Я начал вести список наиболее часто используемых функций, решая алгоритмические задачи на LeetCode и HackerRank.
Быть хорошим программистом — это не значит помнить все встроенные функции некоего языка. Но это не означает и того, что их запоминание — бесполезное дело. Особенно — если речь идёт о подготовке к собеседованию.
Хочу сегодня поделиться со всеми желающими моей шпаргалкой по работе со строками в Python. Я оформил её в виде списка вопросов, который использую для самопроверки. Хотя эти вопросы и не тянут на полноценные задачи, которые предлагаются на собеседованиях, их освоение поможет вам в решении реальных задач по программированию.
1. Как проверить два объекта на идентичность?
Оператор
isвозвращает
Trueв том случае, если в две переменные записана ссылка на одну и ту же область памяти. Именно об этом идёт речь при разговоре об «идентичности объектов».
Не стоит путать is и ==. Оператор == проверяет лишь равенство объектов.
animals = ['python','gopher']
more_animals = animals
print(animals == more_animals) #=> True
print(animals is more_animals) #=> True
even_more_animals = ['python','gopher']
print(animals == even_more_animals) #=> True
print(animals is even_more_animals) #=> False
Обратите внимание на то, что
animalsи
even_more_animalsне идентичны, хотя и равны друг другу.
Кроме того, существует функция id(), которая возвращает идентификатор адреса памяти, связанного с именем переменной. При вызове этой функции для двух идентичных объектов будет выдан один и тот же идентификатор.
name = 'object'
id(name)
#=> 4408718312
2. Как проверить то, что каждое слово в строке начинается с заглавной буквы?
Существует строковый метод
istitle(), который проверяет, начинается ли каждое слово в строке с заглавной буквы.
print( 'The Hilton'.istitle() ) #=> True
print( 'The dog'.istitle() ) #=> False
print( 'sticky rice'.istitle() ) #=> False
3. Как проверить строку на вхождение в неё другой строки?
Существует оператор
in, который вернёт
Trueв том случае, если строка содержит искомую подстроку.
print( 'plane' in 'The worlds fastest plane' ) #=> True
print( 'car' in 'The worlds fastest plane' ) #=> False
4. Как найти индекс первого вхождения подстроки в строку?
Есть два метода, возвращающих индекс первого вхождения подстроки в строку. Это —
find()и
index(). У каждого из них есть определённые особенности.
Метод find() возвращает -1 в том случае, если искомая подстрока в строке не найдена.
'The worlds fastest plane'.find('plane') #=> 19
'The worlds fastest plane'.find('car') #=> -1
Метод
index()в подобной ситуации выбрасывает ошибку
ValueError.
'The worlds fastest plane'.index('plane') #=> 19
'The worlds fastest plane'.index('car') #=> ValueError: substring not found
5. Как подсчитать количество символов в строке?
Функция
len()возвращает длину строки.
len('The first president of the organization..') #=> 41
6. Как подсчитать то, сколько раз определённый символ встречается в строке?
Ответить на этот вопрос нам поможет метод
count(), который возвращает количество вхождений в строку заданного символа.
'The first president of the organization..'.count('o') #=> 3
7. Как сделать первый символ строки заглавной буквой?
Для того чтобы это сделать, можно воспользоваться методом
capitalize().
'florida dolphins'.capitalize() #=> 'Florida dolphins'
8. Что такое f-строки и как ими пользоваться?
В Python 3.6 появилась новая возможность — так называемые «f-строки». Их применение чрезвычайно упрощает интерполяцию строк. Использование f-строк напоминает применение метода
format().
При объявлении f-строк перед открывающей кавычкой пишется буква f.
name = 'Chris'
food = 'creme brulee'
f'Hello. My name is {name} and I like {food}.'
#=> 'Hello. My name is Chris and I like creme brulee'
9. Как найти подстроку в заданной части строки?
Метод
index()можно вызывать, передавая ему необязательные аргументы, представляющие индекс начального и конечного фрагмента строки, в пределах которых и нужно осуществлять поиск подстроки.
'the happiest person in the whole wide world.'.index('the',10,44)
#=> 23
Обратите внимание на то, что вышеприведённая конструкция возвращает
23, а не
0, как было бы, не ограничь мы поиск.
'the happiest person in the whole wide world.'.index('the')
#=> 0
10. Как вставить содержимое переменной в строку, воспользовавшись методом format()?
Метод
format()позволяет добиваться результатов, сходных с теми, которые можно получить, применяя f-строки. Правда, я полагаю, что использовать
format()не так удобно, так как все переменные приходится указывать в качестве аргументов
format().
difficulty = 'easy'
thing = 'exam'
'That {} was {}!'.format(thing, difficulty)
#=> 'That exam was easy!'
11. Как узнать о том, что в строке содержатся только цифры?
Существует метод
isnumeric(), который возвращает
Trueв том случае, если все символы, входящие в строку, являются цифрами.
'80000'.isnumeric() #=> True
Используя этот метод, учитывайте то, что знаки препинания он цифрами не считает.
'1.0'.isnumeric() #=> False
12. Как разделить строку по заданному символу?
Здесь нам поможет метод
split(), который разбивает строку по заданному символу или по нескольким символам.
'This is great'.split(' ')
#=> ['This', 'is', 'great']
'not--so--great'.split('--')
#=> ['not', 'so', 'great']
13. Как проверить строку на то, что она составлена только из строчных букв?
Метод
islower()возвращает
Trueтолько в том случае, если строка составлена исключительно из строчных букв.
'all lower case'.islower() #=> True
'not aLL lowercase'.islower() # False
14. Как проверить то, что строка начинается со строчной буквы?
Сделать это можно, вызвав вышеописанный метод
islower()для первого символа строки.
'aPPLE'[0].islower() #=> True
15. Можно ли в Python прибавить целое число к строке?
В некоторых языках это возможно, но Python при попытке выполнения подобной операции будет выдана ошибка
TypeError.
'Ten' + 10 #=> TypeError
16. Как «перевернуть» строку?
Для того чтобы «перевернуть» строку, её можно разбить, представив в виде списка символов, «перевернуть» список, и, объединив его элементы, сформировать новую строку.
''.join(reversed("hello world"))
#=> 'dlrow olleh'
17. Как объединить список строк в одну строку, элементы которой разделены дефисами?
Метод
join()умеет объединять элементы списков в строки, разделяя отдельные строки с использованием заданного символа.
'-'.join(['a','b','c'])
#=> 'a-b-c'
18. Как узнать о том, что все символы строки входят в ASCII?
Метод
isascii()возвращает
Trueв том случае, если все символы, имеющиеся в строке, входят в ASCII.
print( 'Â'.isascii() ) #=> False
print( 'A'.isascii() ) #=> True
19. Как привести всю строку к верхнему или нижнему регистру?
Для решения этих задач можно воспользоваться методами
upper()и
lower(), которые, соответственно, приводят все символы строк к верхнему и нижнему регистрам.
sentence = 'The Cat in the Hat'
sentence.upper() #=> 'THE CAT IN THE HAT'
sentence.lower() #=> 'the cat in the hat'
20. Как преобразовать первый и последний символы строки к верхнему регистру?
Тут, как и в одном из предыдущих примеров, мы будем обращаться к символам строки по индексам. Строки в Python иммутабельны, поэтому мы будем заниматься сборкой новой строки на основе существующей.
animal = 'fish'
animal[0].upper() + animal[1:-1] + animal[-1].upper()
#=> 'FisH'
21. Как проверить строку на то, что она составлена только из прописных букв?
Имеется метод
isupper(), который похож на уже рассмотренный
islower(). Но
isupper()возвращает
Trueтолько в том случае, если вся строка состоит из прописных букв.
'Toronto'.isupper() #=> False
'TORONTO'.isupper() #= True
22. В какой ситуации вы воспользовались бы методом splitlines()?
Метод
splitlines()разделяет строки по символам разрыва строки.
sentence = "It was a stormy night\nThe house creeked\nThe wind blew."
sentence.splitlines()
#=> ['It was a stormy night', 'The house creeked', 'The wind blew.']
23. Как получить срез строки?
Для получения среза строки используется синтаксическая конструкция следующего вида:
string[start_index:end_index:step]
Здесь
step— это шаг, с которым будут возвращаться символы строки из диапазона
start_index:end_index. Значение
step, равное 3, указывает на то, что возвращён будет каждый третий символ.
string = 'I like to eat apples'
string[:6] #=> 'I like'
string[7:13] #=> 'to eat'
string[0:-1:2] #=> 'Ilk oetape' (каждый 2-й символ)
24. Как преобразовать целое число в строку?
Для преобразования числа в строку можно воспользоваться конструктором
str().
str(5) #=> '5'
25. Как узнать о том, что строка содержит только алфавитные символы?
Метод
isalpha()возвращает
Trueв том случае, если все символы в строке являются буквами.
'One1'.isalpha() #=> False
'One'.isalpha() #=> True
26. Как в заданной строке заменить на что-либо все вхождения некоей подстроки?
Если обойтись без экспорта модуля, позволяющего работать с регулярными выражениями, то для решения этой задачи можно воспользоваться методом
replace().
sentence = 'Sally sells sea shells by the sea shore'
sentence.replace('sea', 'mountain')
#=> 'Sally sells mountain shells by the mountain shore'
27. Как вернуть символ строки с минимальным ASCII-кодом?
Если взглянуть на ASCII-коды элементов, то окажется, например, что прописные буквы имеют меньшие коды, чем строчные. Функция
min()возвращает символ строки, имеющий наименьший код.
min('strings') #=> 'g'
28. Как проверить строку на то, что в ней содержатся только алфавитно-цифровые символы?
В состав алфавитно-цифровых символов входят буквы и цифры. Для ответа на этот вопрос можно воспользоваться методом
isalnum().
'Ten10'.isalnum() #=> True
'Ten10.'.isalnum() #=> False
29. Как удалить пробелы из начала строки (из её левой части), из её конца (из правой части), или с обеих сторон строки?
Здесь нам пригодятся, соответственно, методы
lstrip(),
rstrip()и
strip().
string = ' string of whitespace '
string.lstrip() #=> 'string of whitespace '
string.rstrip() #=> ' string of whitespace'
string.strip() #=> 'string of whitespace'
30. Как проверить то, что строка начинается с заданной последовательности символов, или заканчивается заданной последовательностью символов?
Для ответа на этот вопрос можно прибегнуть, соответственно, к методам
startswith()и
endswith().
city = 'New York'
city.startswith('New') #=> True
city.endswith('N') #=> False
31. Как закодировать строку в ASCII?
Метод
encode()позволяет кодировать строки с использованием заданной кодировки. По умолчанию используется кодировка
utf-8. Если некий символ не может быть представлен с использованием заданной кодировки, будет выдана ошибка
UnicodeEncodeError.
'Fresh Tuna'.encode('ascii')
#=> b'Fresh Tuna'
'Fresh Tuna Â'.encode('ascii')
#=> UnicodeEncodeError: 'ascii' codec can't encode character '\xc2' in position 11: ordinal not in range(128)
32. Как узнать о том, что строка включает в себя только пробелы?
Есть метод
isspace(), который возвращает
Trueтолько в том случае, если строка состоит исключительно из пробелов.
''.isspace() #=> False
' '.isspace() #=> True
' '.isspace() #=> True
' the '.isspace() #=> False
33. Что случится, если умножить некую строку на 3?
Будет создана новая строка, представляющая собой исходную строку, повторённую три раза.
'dog' * 3
# 'dogdogdog'
34. Как привести к верхнему регистру первый символ каждого слова в строке?
Существует метод
title(), приводящий к верхнему регистру первую букву каждого слова в строке.
'once upon a time'.title() #=> 'Once Upon A Time'
35. Как объединить две строки?
Для объединения строк можно воспользоваться оператором
+.
'string one' + ' ' + 'string two'
#=> 'string one string two'
36. Как пользоваться методом partition()?
Метод
partition()разбивает строку по заданной подстроке. После этого результат возвращается в виде кортежа. При этом подстрока, по которой осуществлялась разбивка, тоже входит в кортеж.
sentence = "If you want to be a ninja"
print(sentence.partition(' want '))
#=> ('If you', ' want ', 'to be a ninja')
37. Строки в Python иммутабельны. Что это значит?
То, что строки иммутабельны, говорит о том, что после того, как создан объект строки, он не может быть изменён. При «модификации» строк исходные строки не меняются. Вместо этого в памяти создаются совершенно новые объекты. Доказать это можно, воспользовавшись функцией
id().
proverb = 'Rise each day before the sun'
print( id(proverb) )
#=> 4441962336
proverb_two = 'Rise each day before the sun' + ' if its a weekday'
print( id(proverb_two) )
#=> 4442287440
При конкатенации
'Rise each day before the sun'и
' if its a weekday'в памяти создаётся новый объект, имеющий новый идентификатор. Если бы исходный объект менялся бы, тогда у объектов был бы один и тот же идентификатор.
38. Если объявить одну и ту же строку дважды (записав её в 2 разные переменные) — сколько объектов будет создано в памяти? 1 или 2?
В качестве примера подобной работы со строками можно привести такой фрагмент кода:
animal = 'dog'
pet = 'dog'
При таком подходе в памяти создаётся лишь один объект. Когда я столкнулся с этим в первый раз, мне это не показалось интуитивно понятным. Но этот механизм помогает Python экономить память при работе с длинными строками.
Доказать это можно, прибегнув к функции id().
animal = 'dog'
print( id(animal) )
#=> 4441985688
pet = 'dog'
print( id(pet) )
#=> 4441985688
39. Как пользоваться методами maketrans() и translate()?
Метод
maketrans()позволяет описать отображение одних символов на другие, возвращая таблицу преобразования.
Метод translate() позволяет применить заданную таблицу для преобразования строки.
# создаём отображение
mapping = str.maketrans("abcs", "123S")
# преобразуем строку
"abc are the first three letters".translate(mapping)
#=> '123 1re the firSt three letterS'
Обратите внимание на то, что в строке произведена замена символов
a,
b,
cи
s, соответственно, на символы
1,
2,
3и
S.
40. Как убрать из строки гласные буквы?
Один из ответов на этот вопрос заключается в том, что символы строки перебирают, пользуясь механизмом List Comprehension. Символы проверяют, сравнивая с кортежем, содержащим гласные буквы. Если символ не входит в кортеж — он присоединяется к новой строке.
string = 'Hello 1 World 2'
vowels = ('a','e','i','o','u')
''.join([c for c in string if c not in vowels])
#=> 'Hll 1 Wrld 2'
41. В каких ситуациях пользуются методом rfind()?
Метод
rfind()похож на метод
find(), но он, в отличие от
find(), просматривает строку не слева направо, а справа налево, возвращая индекс первого найденного вхождения искомой подстроки.
story = 'The price is right said Bob. The price is right.'
story.rfind('is')
#=> 39
Итоги
Я часто объясняю одному продакт-менеджеру, человеку в возрасте, что разработчики — это не словари, хранящие описания методов объектов. Но чем больше методов помнит разработчик — тем меньше ему придётся гуглить, и тем быстрее и приятнее ему будет работаться. Надеюсь, теперь вы без труда ответите на рассмотренные здесь вопросы.
Уважаемые читатели! Что, касающееся обработки строк в Python, вы посоветовали бы изучить тем, кто готовится к собеседованию?
работа со строками в 1С
Внимание! Перед вами ознакомительная версия урока, материалы которого могут быть неполными.
Войдите на сайт как ученик
Войдите как ученик, чтобы получить доступ к материалам школы
Внутренний язык программирования 1С 8.3 для начинающих программистов: работа со строками в 1С
Автор уроков и преподаватель школы: Владимир Милькин
Друзья, сегодня будет интереснейший урок. Мы научимся выполнять операции со строками (мы проходили их здесь).
Наверное, не найдётся ни одного языка программирования, который не давал бы возможностей для обработки строк. Настолько это фундаментальный и необходимый тип данных.
И 1с в этом смысле не исключение. Я, как обычно, прошу вас повторять и проверять у себя весь код, который мы будем писать в этом уроке.
Откуда в программе появляются строкиСам программист может закодировать определенное значение строки прямо в коде, используя двойные кавычки …
ИмяПеременной = "Привет, Мир!"; |
… и далее использовать его по своему усмотрению:
// Выводим значение строки пользователю в отдельном диалоге. ОткрытьЗначение(ИмяПеременной); |
Бывает и так, что значение строки должен ввести сам пользователь. Это делается при помощи команды ВвестиСтроку:
// Определим переменную с пустым значением строки. ИмяПеременной = ""; // Попросим пользователя ввести новое значение строки. ВвестиСтроку(ИмяПеременной); // Сообщим пользователю его же строку. ОткрытьЗначение(ИмяПеременной); |
Любая строка состоит из символов.
К примеру, строка «привет» состоит из символов ‘п’, ‘р’, ‘и’, ‘в’, ‘е’, ‘т’.
К этим символам можно обращаться по их порядковому номеру. При этом нумерация символов в строке (в отличие от коллекций) начинается не с 0, а с 1.
Узнать общее количество символов в строке можно при помощи функции СтрДлина. Она принимает на вход строку и возвращает нам число символов в этой строке.
Таким образом, цикл обхода строки будет таким:
ИмяПеременной = "привет";
Для НомерСимвола = 1 По СтрДлина(ИмяПеременной) Цикл
Сообщить(НомерСимвола);
КонецЦикла; |
Если мы запустим эту программу на компьютере, то увидим такой результат:
Мы научились получать номера символов в строке, но как получать сами символы?
За получение нужного символа (или даже группы символов) из строки отвечает функция Сред (сокращение от слов «средина», «средний»).
Она принимает три параметра:
- Саму строку.
- Номер символа в строке, который нужно получить.
- Количество символов, которое нужно получить.
В нашем случае мы будем получать по одному символу, поэтому третий параметр у нас всегда будет равен 1.
Итак, перепишем наш код вот так:
ИмяПеременной = "привет";
Для НомерСимвола = 1 По СтрДлина(ИмяПеременной) Цикл
Сообщить(Сред(ИмяПеременной, НомерСимвола, 1));
КонецЦикла; |
Теперь вывод будет совсем другим:
Что представляет из себя символМне иногда кажется, что всё в этом мире есть числа … И символы строки, кстати, не исключение.
И это на самом деле так, ведь каждому значению символа соответствует определенное число, его код.
Зачем вообще может понадобиться переводить символ в числовой код и обратно? Например, если мы захотим написать программу для шифрования и дешифрования текстов. А мы захотим и сделаем это в следующем модуле школы.
За перевод символа в числовой код отвечает функция КодСимвола. Она принимает строку и порядковый номер символа в ней, а возвращает числовой код этого символа.
Давайте выведем числовой код каждого символа нашей строки:
ИмяПеременной = "привет";
Для НомерСимвола = 1 По СтрДлина(ИмяПеременной) Цикл
Сообщить(КодСимвола(ИмяПеременной, НомерСимвола));
КонецЦикла; |
Запустим эту программу, вывод будет таким:
1087 1088 1080 1074 1077 1090 |
Получается, что, к примеру, символу ‘п’ соответствует числовой код 1087? Да, это действительно так. Проверим это.
Для этого я сообщу вам способ для обратного перевода: из числового кода в символ. За такой перевод отвечает функция Символ. Она принимает на вход числовой код, а возвращает символ.
Сообщить(Символ(1087)); // выведет п |
Давайте представим, что у нас есть две вот такие строки …
Строка1 = "Привет"; Строка2 = "Вова"; |
… и мы хотим сложить (ещё говорят «склеить», «объединить») эти строки вместе, чтобы за значением первой строки сразу следовало значение второй.
Это делается при помощи оператора плюс (+), вот так:
Строка1 = "Привет"; Строка2 = "Вова"; // используйте ваше имя, Вова - моё имя ;) Строка3 = Строка1 + Строка2; |
Выведем эту строку пользователю:
Сообщить(Строка3); // ПриветВова |
Выглядит не очень, правда?
Давайте усложним задачу — требуется объединить эти строки, но между ними вставить пробел, а в конце добавить восклицательный знак.
Строка1 = "Привет"; Строка2 = "Вова"; Строка3 = Строка1 + " " + Строка2 + "!"; Сообщить(Строка3); // Привет Вова! |
Вот так гораздо лучше!
Поиск в строкеДавайте рассмотрим такую интересную задачу. Попросим пользователя ввести любой текст, но чтобы в нём встречалось (или нет) слово «счастье».
А в ответ мы будем говорить пользователю в какой позиции в строке находится это слово.
К примеру, если пользователь введёт строку «высыпаться по утрам — счастье», то программа должна ему сказать, что слово «счастье» есть в строке и оно находится в позиции 23.
Будем писать программу по частям.
Сначала напишем ввод строки от пользователя:
Текст = ""; ВвестиСтроку(Текст); |
За поиск в строке отвечает функция СтрНайти.
На вход она принимает 2 параметра (на самом деле параметров больше, но мы рассмотрим только первые два):
- Строку, в которой надо искать.
- Часть строки (её ещё называют «подстрока»), которую надо найти.
Функция возвращает 0, если вхождение не найдено и позицию в строке, если вхождение найдено. Функция ищет только первое вхождение подстроки в строку.
С учётом этого продолжим написание программы вот так:
ПозицияВхождения = СтрНайти(Текст, "счастье");
Если ПозицияВхождения = 0 Тогда
ОткрытьЗначение("Слово счастье в строке не найдено!");
Иначе
ОткрытьЗначение("Слово счастье находится в " + ПозицияВхождения + " позиции!");
КонецЕсли; |
А давайте подшутим над пользователем?
Пусть он введёт строку со словом «счастье», а мы выведем его же строку, в которой заменим слово «счастье», например, на «удовольствие».
За замену одной части строки на другую отвечает функция СтрЗаменить.
На вход она принимает 3 параметра:
- Строку, в которой нужно сделать замену.
- Подстроку, которую надо найти и заменить.
- Подстроку, на которую нужно заменить.
Функция возвращает строку, полученную в результате замены. При этом функция заменяет все вхождения.
Итак, поехали:
Текст = ""; ВвестиСтроку(Текст); НовыйТекст = СтрЗаменить(Текст, "счастье", "удовольствие"); ОткрытьЗначение(НовыйТекст); |
А вы заметили, что один и тот же символ может иметь два варианта, например: ‘п’ и ‘П’. Первый вариант называется «нижний регистр», а второй — «верхний регистр».
И для компьютера это разные буквы. Мы можем легко в этом убедиться, если выведем числовые коды этих букв:
Сообщить(КодСимвола("п", 1)); // 1087
Сообщить(КодСимвола("П", 1)); // 1055 |
Именно поэтому для компьютера, к примеру, строка «привет» будет не равна строке «Привет»:
// Кстати, сравнение строк на равенство делается
// при помощи знака равно (точно также как с числами).
Сообщить("привет" = "Привет"); // нет |
Компьютер при сравнении строк сравнивает числовой код каждого символа одной строки с соответствующим ему (по порядку) числовым кодом символа другой строки. И если есть хотя бы одно неравенство — строки считаются различными.
Но у нас есть замечательная возможность менять регистр строк: из верхнего в нижний и наоборот. За это отвечают функции НРег (сокращение от «нижний регистр») и ВРег (сокращение от «верхний регистр»).
Текст = "оТпУсК"; Сообщить(НРег(Текст)); // отпуск Сообщить(ВРег(Текст)); // ОТПУСК |
Когда это может быть полезно? Вспомните задачу, когда мы заменяли слово «счастье» на «удовольствие».
Функция СтрЗаменить (как и Найти) ищет подстроку с учётом регистра. То есть если пользователь введет вместо «счастье», например, «Счастье», то программа не найдёт этого вхождения.
И чтобы поиск и замена не зависели от того в каком регистре ввёл строку пользователь, мы напишем вот так:
Текст = ""; ВвестиСтроку(Текст); НовыйТекст = СтрЗаменить(НРег(Текст), "счастье", "удовольствие"); ОткрытьЗначение(НовыйТекст); |
Теперь, даже если пользователь введёт «Любимая работа — это СЧАСТЬЕ!» программа сможет найти слово «счастье» и вывести пользователю «любимая работа — это удовольствие!».
Подведём итогиМы рассмотрели основные операции над строками, но на самом деле их больше.
Некоторые из них вы можете изучить вместе с примерами в справочнике по языку 1с.
Но наиболее полный перечень представлен в синтакс-помощнике:
Пройдите тестВведите от пользователя строку. Посчитайте сколько раз в этой строке встречается пробел и скажите об этом пользователю.
Строки. Функции и методы строк — Документация Python Summary 1
# Литералы строк
S = 'str'; S = "str"; S = '''str'''; S = """str"""
# Экранированные последовательности
S = "s\np\ta\nbbb"
# Неформатированные строки (подавляют экранирование)
S = r"C:\temp\new"
# Строка байтов
S = b"byte"
# Конкатенация (сложение строк)
S1 + S2
# Повторение строки
S1 * 3
# Обращение по индексу
S[i]
# Извлечение среза
S[i:j:step]
# Длина строки
len(S)
# Поиск подстроки в строке. Возвращает номер первого вхождения или -1
S.find(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер последнего вхождения или -1
S.rfind(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError
S.index(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError
S.rindex(str, [start],[end])
# Замена шаблона
S.replace(шаблон, замена)
# Разбиение строки по разделителю
S.split(символ)
# Состоит ли строка из цифр
S.isdigit()
# Состоит ли строка из букв
S.isalpha()
# Состоит ли строка из цифр или букв
S.isalnum()
# Состоит ли строка из символов в нижнем регистре
S.islower()
# Состоит ли строка из символов в верхнем регистре
S.isupper()
# Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы ('\f'), "новая строка" ('\n'), "перевод каретки" ('\r'), "горизонтальная табуляция" ('\t') и "вертикальная табуляция" ('\v'))
S.isspace()
# Начинаются ли слова в строке с заглавной буквы
S.istitle()
# Преобразование строки к верхнему регистру
S.upper()
# Преобразование строки к нижнему регистру
S.lower()
# Начинается ли строка S с шаблона str
S.startswith(str)
# Заканчивается ли строка S шаблоном str
S.endswith(str)
# Сборка строки из списка с разделителем S
S.join(список)
# Символ в его код ASCII
ord(символ)
# Код ASCII в символ
chr(число)
# Переводит первый символ строки в верхний регистр, а все остальные в нижний
S.capitalize()
# Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию)
S.center(width, [fill])
# Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию)
S.count(str, [start],[end])
# Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам
S.expandtabs([tabsize])
# Удаление пробельных символов в начале строки
S.lstrip([chars])
# Удаление пробельных символов в конце строки
S.rstrip([chars])
# Удаление пробельных символов в начале и в конце строки
S.strip([chars])
# Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки
S.partition(шаблон)
# Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку
S.rpartition(sep)
# Переводит символы нижнего регистра в верхний, а верхнего – в нижний
S.swapcase()
# Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний
S.title()
# Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями
S.zfill(width)
# Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar
S.ljust(width, fillchar=" ")
# Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar
S.rjust(width, fillchar=" ")
Работа со строками в Python OTUS
Язык программирования Python поддерживает разные виды данных. В этой статье, предназначенной для начинающих, будет рассмотрен строковый тип string и основные операции, связанные с обработкой строк. Среди них:
- создание строк;
- конкатенация строк;
- выборка символов по индексам.
Строки (strings) используются для хранения текстовых данных. Их создание возможно одним из 3-х способов. Тут все просто, т. к. возможно применение разных кавычек: одинарных, двойных либо тройных. То есть в эти кавычки и нужно обернуть текст:
otus_string_1 = 'Привет, друзья!'
otus_string_2 = "Хотите выучить Python?"
otus_string_3 = """Ждем вас на наших курсах!"""
Кавычки в данном случае — это строковые литералы, позволяющие создавать в памяти программы Python объект типа string.
Нужно понимать, что разницы, какие именно кавычки использует разработчик, нет. Главное — открывающие и закрывающие кавычки должны быть однотипными. Если же поставить вначале одинарную кавычку, а в конце двойную — ошибки не избежать.
Можно ли применять кавычки внутри строк?
Можно, для чего есть несколько вариантов. Один из них — использовать внутри строки кавычки другого типа. К примеру, наружные кавычки являются двойными, а внутренние — одинарными. Или наоборот:
otus_string_1 = 'Хотите выучить "Пайтон?" и стать профессионалом'
otus_string_2 = "Запишитесь на курс в 'Отус' уже сегодня!"
Второй метод — экранирование. Для экранирования используется обратный слэш. Вот, как это выглядит в коде:
otus_string_1 = "Я и \'Пайтон\' созданы друг для друга"
У тройных кавычек есть особенности. Заключенные в них строки поддерживают многострочность, то есть для переноса не нужен символ \n. А еще внутри тройных кавычек можно вставлять как двойные, так и одинарные кавычки:
my_string = """Учитесь
программированию
в "Отус"!"""
print (my_string)
Вывод будет следующим:
Строки являются неизменяемыми объектами (как и числа). В этом легко убедиться, если создать переменные с одинаковыми именами, а потом вывести на экран их id — идентификаторы будут различаться:
otus_string = 'Привет, друзья!'
print(id(otus_string))
otus_string = "Хотите выучить Python?"
print(id(otus_string))
Рекомендуется повторить вышеописанные операции самостоятельно и попрактиковаться. Сделать это можно, даже не устанавливая «Пайтон», используя любой онлайн-компилятор.
Конкатенация строкКонкатенация — это сложение строк, в результате чего они соединяются друг с другом. Самый простой способ сделать это — использовать простейший оператор сложения, то есть знак «+».
Это простейший синтаксис, причем можно брать сколько угодно строк и соединять их:
otus_string = "Я " + "просто " + "обожаю " + "Python!"
print(otus_string)
Если надо, можно задействовать и операнд умножения. Он позволит продублировать строку, умножив ее на соответствующее значение, которое разработчик передаст в коде.
otus_string = "Code" * 10
print(otus_string)
Важное свойство строк — длина (число символов). Узнать количество символов, из которых состоит строка, можно, задействовав встроенную функцию len (от англ. length — длина).
Код ниже посчитает число символов:
otus_string = "Python is a good for coding"
print(len(otus_string))
Итого: строка содержит 27 символов (пробел — тоже символ):
Можно попробовать передать пустую строку и постараться посчитать число символов в ней. Если вставить хотя бы пробел, на выходе получится 1 символ, если не вставлять вообще ничего, число символов будет равняться нулю.
otus_string_1 = ""
print(len(otus_string_1))
otus_string_2 = " "
print(len(otus_string_2))
Ранее уже использовались такие методы, как print и id. Есть свои методы и у строковых данных — они принадлежат конкретному классу str. Чтобы вывести их, можно воспользоваться функцией dir:
Зубрить каждый из них нет необходимости, так как нужные методы будут запоминаться с практикой. Чтобы обратиться к одному из них, следует сначала обратиться к соответствующему объекту, потом поставить точку, потом написать нужный метод и круглые скобки. Лучше это увидеть:
string_1 = "oTUs"
string_1 = string_1.title()
print(string_1)
string_1 = string_1.upper()
print(string_1)
string_1 = string_1.lower()
print(string_1)
Что отображено на скриншоте выше:
- была создана новая строка string_1 с содержимым “oTUs”;
- вначале задействовали метод title — вывод слова получился с заглавной буквы;
- потом использовали метод для верхнего регистра upper — заглавными (прописными) стали все символы строки;
- далее применили lower — все символы стали маленькими (строчными), то есть перешли в нижний регистр.
Какие еще есть методы:
- replace —для замены одной части исходной строки (подстроки) на другую;
- split — позволяет разделить (не удалить!) строку по переданному делителю, возвращает список;
- join — склеивает подстроки по конкретному разделителю;
- strip. В языке программирования Python strip используется для обрезки ненужных символов, причем ненужный символ передается в виде аргумента. Обрезку можно выполнять по-разному: если с первого символа слева, то применяют не strip, а lstrip, если справа, то rstrip (с конца строки, если интересует последний символ).
В «Питоне» у каждого символа есть свой номер — индекс. Если разработчика интересует поиск какого-нибудь символа, к нему можно обратиться. Код ниже возвращает индекс для каждого символа из слова Otus:
string_1 = "Otus"
print(string_1[0])
print(string_1[1])
print(string_1[2])
print(string_1[3])
Тут важен один момент: индексация начинается не с единицы, а с нуля, поэтому первый символ имеет индекс 0.
Дополнительно: преобразование символа в целое число
Компьютеры хранят все данные в виде цифр, и символьных данных это тоже касается. Для представления символов строкового типа String применяют схему перевода. Самая простая из них — ASCII. Если нужно вернуть число для какого-нибудь конкретного символа, используют функцию ord. К примеру, для символа «a» кодовое значение по ASCII будет равняться 97, а для «#» — 35.
Кроме ASCII, также широко известен Unicode, который тоже поддерживается «Питоном».
Источники:
- https://zen.yandex.ru/media/id/5cab3ea044061700afead675/vse-o-strokah-v-python-5f60744e5622142b93b2031e;
- https://pythonru.com/osnovy/stroki-python.
Работа со строками в Delphi 10.1 Berlin
Для работы со строками в последних версиях Delphi разработчикам доступно большое количество функций, помимо которых ещё есть помощники для работы со строками, такие как TStringHelper, TStringBuilder и TRegEx. Во всём этом разнообразии бывает сложно найти нужную функцию. Я попытался разобраться, что есть в Delphi 10.1 Berlin для работы со строками и как этим всем пользоваться.
Итак, прежде чем начнём разбираться с функциями, замечу, что начиная с Delphi XE3, появился помощник TStringHelper, и теперь работать со строками можно как с записями. Т.е., если вы определили переменную со строкой (на картинке снизу – это myStr), то вы можете поставить точку и посмотреть, какие функции доступны. Это очень удобно.
Кстати аналогичные помощники появились и для работы с типами Single, Double и Extended: TSingleHelper, TDoubleHelper и TExtendedHelper.
Ну и конечно, помимо помощника TStringHelper, никуда не делся класс TStringBuilder, который используется для работы со строкой как с массивом, и который является полностью совместимым с .NET классом StringBuilder.
А для работы с текстовыми документами незаменимым окажется класс TRegEx, который является обёрткой над библиотекой PCRE, позволяющий использовать регулярные выражения для поиска, замены подстрок и расщепления текста на части.
Все приведённые в статье примеры сделаны с помощью Delphi 10.1 Berlin, поэтому в других версиях Delphi их работа не гарантируется.
Вот основные моменты, которые мы рассмотрим в статье:
Строки в Delphi
В последних версиях Delphi тип string, обозначающий строку, является псевдонимом встроенного типа System.UnicodeString. Т.е. когда вы объявляете переменную str: string, то автоматически вы объявляете переменную типа UnicodeString.
Кстати, на платформе Win32 вы можете использовать директиву «{$H-}», которая превратит тип string в ShortString. С помощью этого способа вы можете использовать старый 16-битный код Delphi или Turbo Pascal в ваших проектах.
Обратите внимание, что кроме типа UnicodeString и ShortString в Delphi есть и другие типы строк, такие как AnsiString и WideString, однако дальше в статье мы будем рассматривать только работу со строками типа string.
Более глубокое изучение строк в Delphi вы можете начать с прочтения документации здесь.
Инициализация строк
Конечно, начнём мы с инициализации строк. Итак, рассмотрим объявление переменной с типом string.
В этой строчке кода мы объявляем переменную s с типом string, т.е., как было написано выше, по умолчанию с типом UnicodeString. Объявленные переменные с типом UnicodeString, в которые не присвоено значение, всегда гарантированно содержат строку нулевой длины. Чтобы теперь в переменной s была нужная нам строка, нужно просто присвоить переменной другое значение, например:
Это самый простой и часто используемый способ инициализации. Кроме этого есть ряд полезных функций, которые пригодятся вам для инициализации строк в некоторых ситуациях (здесь и далее я буду давать полный код проекта консольного Win32 приложения):
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils;
var
str1, str2, str3, str4, str5, str6: string;
arr4: array of char;
begin
try
//Способ 1: инициализируем строку повторяющимися символами.
//В результате в str1 будет строка "ААААА".
str1 := StringOfChar('А', 5);
//Способ 2: инициализируем строку повторяющимися символами.
//В результате в str2 будет строка "ААААА".
str2 := string.Create('А', 5);
//Способ 3: инициализируем строку повторяющимися подстроками.
//В результате в str3 будет строка "ХаХаХаХаХа".
str3 := DupeString('Ха', 5);
//Способ 4: инициализируем строку символами из массива.
//В результате в str4 будет строка "Абвгд"
arr4 := ['А', 'б', 'в', 'г', 'д'];
str4 := string(arr4);
//Способ 5: инициализируем строку символами из массива.
//В результате в str5 будет строка "Абвгд"
str5 := string.Create(['А', 'б', 'в', 'г', 'д']);
//Способ 6: инициализируем строку символами из массива (берём только часть символов).
//В результате в str6 будет строка "бвг"
str6 := string.Create(['А', 'б', 'в', 'г', 'д'], 1, 3);
//Отображаем результат.
Writeln(str1);
Writeln(str2);
Writeln(str3);
Writeln(str4);
Writeln(str5);
Writeln(str6);
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Изменение регистра
Для изменения регистра строк в Delphi есть функции LowerCase, UpperCase, TStringHelper.ToLower, TStringHelper.ToUpper, TStringHelper.ToLowerInvariant и TStringHelper.ToUpperInvariant. В нижний регистр строки меняют функции LowerCase, TStringHelper.ToLower и TStringHelper.ToLowerInvariant, остальные – в верхний. Обратите внимание, что функции LowerCase и UpperCase не работают с кириллицей. Функции TStringHelper.ToUpperInvariant и TStringHelper.ToLowerInvariant всегда работают независимо от текущей пользовательской локали. Вот примеры использования функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
begin
try
//В нижний регистр меняются только латинские буквы. Результат будет 'АбВгД - abcde'.
Writeln(LowerCase('АбВгД - AbCdE'));
//В верхний регистр меняются только латинские буквы. Результат будет 'АбВгД - ABCDE'.
Writeln(UpperCase('АбВгД - AbCdE'));
//В нижний регистр меняются и русские и латинские буквы. Результат будет 'абвгд - abcde'.
Writeln('АбВгД - AbCdE'.ToLower);
//В верхний регистр меняются и русские и латинские буквы. Результат будет 'АБВГД - ABCDE'.
Writeln('АбВгД - AbCdE'.ToUpper);
//Указываем локаль при изменении регистра. Результат будет 'АБВГД - ABCDE'.
Writeln('АбВгД - AbCdE'.ToUpper(TLanguages.GetLocaleIDFromLocaleName('ru-RU')));
//В нижний регистр меняются и русские и латинские буквы. Результат будет 'абвгд - abcde'.
Writeln('АбВгД - AbCdE'.ToLowerInvariant);
//В верхний регистр меняются и русские и латинские буквы. Результат будет 'АБВГД - ABCDE'.
Writeln('АбВгД - AbCdE'.ToUpperInvariant);
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Конкатенация строк
Здесь конечно самый простой вариант – это использование оператора +. Но есть и другие варианты, например, функция Concat. А если вам нужно в цикле добавлять в конец одной строки большое количество других строк, то здесь пригодится метод Append класса TStringBuilder. Вот пример использования перечисленных способов:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
var
str1, str2, str3, str4: string;
stringBuilder: TStringBuilder;
begin
try
//Способ 1: используем оператор +.
str1 := 'Абвг' + 'деёжз' + 'иклмн' + 'опрст';
// Способ 2: используем функцию Concat.
str2 := Concat('Абвг', 'деёжз', 'иклмн', 'опрст');
// Способ 3: используем функцию TStringHelper.Join.
str3 := String.Join('', ['Абвг', 'деёжз', 'иклмн', 'опрст']);
// Способ 4: используем TStringBuilder.
// Способ 4: используем TStringBuilder.
stringBuilder := TStringBuilder.Create;
try
stringBuilder
.Append('Абвг')
.Append('деёжз')
.Append('иклмн')
.Append('опрст');
str4 := stringBuilder.ToString;
finally
stringBuilder.Free;
end;
//Отображаем результат.
Writeln(str1);
Writeln(str2);
Writeln(str3);
Writeln(str4);
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Во всех четырёх переменных, после выполнения нашей программы, будет следующая строка: «Абвгдеёжзиклмнопрст». Четвёртый способ выглядит более громоздким, но у такого способа есть три преимущества. Во-первых, при большом количестве конкатенаций этот способ даст выигрыш по времени по сравнению с первыми тремя способами. Во-вторых, при создании объекта TStringBuilder вы сразу можете задать нужный размер массива для хранения строки, если он конечно известен. Это тоже даст выигрыш по времени. В-третьих, функция Append принимает на вход не только строки, но и другие типы, такие как Integer и Single, автоматически преобразуя их в строку.
Третий способ удобно использовать, если нужно сложить строки, находящиеся в массиве или списке. К тому же здесь первым параметром можно задать строку-разделитель, которая будет вставлена между строками, взятыми из массива. Вот пример, в котором формируется строка со списком городов, разделённых запятыми:
str3 := String.Join(', ', ['Москва', 'Санкт-Петербург', 'Севастополь']);В результате выполнения этой функции получится строка «Москва, Санкт-Петербург, Севастополь».
Вставка подстроки в строку
Для того чтобы вставить внутрь строки подстроку вы можете использовать процедуру Insert или функцию TStringHelper.Insert. У класса TStringBuilder тоже есть аналогичная функция. Кстати, функция TStringBuilder.Insert, кроме строк умеет вставлять и другие типы, такие как Integer и Single, автоматически преобразуя их в строку. Вот пример использования:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
var
str1, str2: string;
stringBuilder: TStringBuilder;
begin
try
//В результате вставки получится строка 'Абв--гд'
str1 := 'Абвгд';
Insert('--', str1, 4);
Writeln(str1);
//В результате вставки получится строка 'Абв--гд'
str2 := 'Абвгд';
Writeln(str2.Insert(3, '--')); //Будет отображено 'Абв--гд'.
Writeln(str2); //Здесь тоже будет отображено 'Абв--гд'.
//В результате вставки получится строка 'Абв--гд'
stringBuilder := TStringBuilder.Create('Абвгд');
try
stringBuilder.Insert(3, '--');
Writeln(stringBuilder.ToString);
finally
stringBuilder.Free;
end;
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Обратите внимание, в процедуре Insert нумерация символов начинается с 1, а в функциях TStringHelper.Insert и TStringBuilder.Insert – с 0. Все приведённые способы меняют строку, хранящуюся в переменной.
Удаление части строки
Допустим, вам нужно удалить из строки часть символов. Здесь нам помогут процедура Delete и функция TStringHelper.Remove. У класса TStringBuilder тоже есть функция Remove. Вот примеры использования:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
var
str1, str2, str3: string;
stringBuilder: TStringBuilder;
begin
try
//Способ 1: используем функцию Delete.
str1 := 'Абвгд';
Delete(str1, 2, 2);
//Способ 2: используем функцию TStringHelper.Remove.
str2 := 'Абвгд';
str2 := str2.Remove(1, 2);
//Способ 3: удаляем символы внутри TStringBuilder.
stringBuilder := TStringBuilder.Create('Абвгд');
try
stringBuilder.Remove(1, 2);
str3 := stringBuilder.ToString;
finally
stringBuilder.Free;
end;
//Отображаем результат.
Writeln(str1);
Writeln(str2);
Writeln(str3);
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Во всех трёх способах из строки «Абвгд» получится строка «Агд». Обратите внимание, что в процедуре Delete нумерация символов начинается с 1, а в функциях Remove – с 0.
Также интересно, что функция TStringHelper.Remove не трогает исходную строку. Вместо этого она возвращает новую строку с удалёнными символами. Именно поэтому мы присваиваем результат обратно в переменную. Процедура Delete работает по-другому: она меняет исходную строку.
Помимо приведённых здесь вариантов, для удаления части строки можно использовать функции замены подстроки, просто для этого искомая подстрока заменяется на пустую, например, StringReplace(str1, substr1, »).
Копирование части строки
Здесь идёт речь о том, что часть длиной строки нужно скопировать в новую строку или массив символов. Для этого в Delphi есть функции LeftStr, RightStr, Copy, TStringHelper.Substring и TStringHelper.CopyTo. А в классе TStringBuilder – только функция CopyTo. Есть также функция MidStr в юните System.StrUtils, которая работает аналогично функции Copy, поэтому в примере её не будет.
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils;
var
str1, str2, str3, str4: string;
arr5: array of char;
arr6: TCharArray;
stringBuilder: TStringBuilder;
begin
try
//Способ 1: копируем три символа слева.
//В результате в строке str2 будет "Абв".
str1 := LeftStr('Абвгдеёжз', 3);
//Способ 2: копируем три символа справа.
//В результате в строке str3 будет "ёжз".
str2 := RightStr('Абвгдеёжз', 3);
//Способ 3: копируем символы из середины.
//В результате в строке str1 будет "вгд".
str3 := Copy('Абвгдеёжз', 3, 3);
//Способ 4: копируем символы из середины.
//В результате в строке str4 будет "вгд".
str4 := 'Абвгдеёжз'.Substring(2, 3);
//Способ 5: копируем часть строки в массив символов.
//В результате в массиве arr5 будет ['в', 'г', 'д'].
SetLength(arr5, 3);
'Абвгдеёжз'.CopyTo(2, arr5, 0, 3);
//Способ 6: копируем часть символов из TStringBuilder в массив символов.
//В результате в массиве arr6 будет ['в', 'г', 'д'].
stringBuilder := TStringBuilder.Create('Абвгдеёжз');
try
SetLength(arr6, 3);
stringBuilder.CopyTo(2, arr6, 0, 3);
finally
stringBuilder.Free;
end;
//Отображаем результат.
Writeln(str1);
Writeln(str2);
Writeln(str3);
Writeln(str4);
Writeln(string(arr5));
Writeln(string(arr6));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Первые два способа копируют часть строки слева (функция LeftStr) или справа (RightStr). Остальные четыре способа подходят, как для копирования части строки слева или справа, так и из середины.
В способах 3-6 из примера мы получим сроку «вгд» или массив [‘в’, ‘г’, ‘д’]. Обратите внимание, что в функциях Copy и MidStr нумерация символов начинается с 1, а во всех остальных с 0. Исходная строка или массив символов во всех четырёх способах не меняется.
Сравнение строк
Конечно, сравнивать строки можно с помощью операторов =, <, <=, >, >= и <>. Но кроме этого существуют ещё много функций: StrComp, StrIComp, StrLComp, StrLIComp, CompareStr, CompareText, TStringHelper.Compare, TStringHelper.CompareOrdinal, TStringHelper.CompareTo, TStringHelper.CompareText, SameStr, SameText, TStringHelper.Equals и TStringBuilder.Equals. Функции SameText, StrIComp, CompareText, TStringHelper.CompareText и TStringHelper.Compare умеют производить регистронезависимое сравнение строк, остальные функции и операторы — регистрозависимое.
Третьим параметром в функциях CompareText и SameText можно указать, что нужно использовать для сравнения строк пользовательскую локаль. В этом случае вы сможете сравнивать строки с русскими буквами независимо от регистра, если конечно в ОС используется русский язык.
Самая продвинутая здесь функция – это TStringHelper.Compare. С помощью неё можно сравнивать не только целые строки, но и части строк. Здесь можно настроить зависимость от регистра, включить игнорирование символов и знаков препинания или сравнение цифр как чисел и т.д.
Операторы, а также функции TStringHelper.Equals и TStringBuilder.Equals, в результате сравнения, отдадут вам True, если условие верно, и False, если условие не верно. Функции CompareStr, CompareText, TStringHelper.Compare, TStringHelper.CompareTo, TStringHelper.CompareOrdinal и TStringHelper.CompareText работают по-другому. Они сравнивают строки с точки зрения сортировки. Функции возвращают отрицательное число, если строка, указанная в первом параметре, сортируется до строки, указанной во втором параметре, положительное число — если первая строка сортируется после второй и 0 – если строки равны.
Функции SameStr, SameText, TStringHelper.Equals и TStringBuilder.Equals сравнивают строки на соответствие.
Итак, вот примеры использования вышеперечисленных функций и операторов:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils, Winapi.Windows;
var
stringBuilder1, stringBuilder2: TStringBuilder;
begin
try
//Сравнение строк с помощью операторов (регистрозависимое).
//В результате будет TRUE (т.е. строка 1 сортируется до строки 2).
Writeln('Арбуз' < 'Банан');
//В результате будет TRUE (т.е. строка 1 сортируется после строки 2).
Writeln('Арбуз' > 'Арбалет');
//В результате будет TRUE (т.е. строка 1 сортируется до строки 2 или строки равны).
Writeln('Арбуз' <= 'арбуз');
//В результате будет FALSE (т.е. строки не равны).
Writeln('Арбуз' = 'арбуз');
//Сравнение с помощью регистрозависимых функций.
//Результат будет FALSE.
Writeln('Арбуз'.Equals('арбуз'));
//Результат будет TRUE.
Writeln('Банан'.Equals('Банан'));
//Результат будет FALSE.
Writeln(SameStr('Арбуз', 'арбуз'));
//Результат будет TRUE.
Writeln(SameStr('Банан', 'Банан'));
//Результат будет -1 (т.е. строка 1 сортируется до строки 2).
Writeln(string.CompareOrdinal('Арбуз', 'Банан'));
//Результат будет -1 (т.е. строка 1 сортируется до строки 2).
Writeln(StrComp('Арбуз', 'Банан'));
//Сравниваем только первые 2 символа. Результат будет -1 (т.е. строка 1 сортируется до строки 2).
Writeln(StrLComp('Арбуз', 'Банан', 2));
//Результат будет -1 (т.е. строка 1 сортируется до строки 2).
Writeln('Арбуз'.CompareTo('Банан'));
//Результат будет 19 (т.е. строка 1 сортируется после строки 2).
Writeln('Арбуз'.CompareTo('Арбалет'));
//Результат будет -1 (т.е. строка 1 сортируется до строки 2).
Writeln(CompareStr('Арбуз', 'Банан'));
//Результат будет 19 (т.е. строка 1 сортируется после строки 2).
Writeln(CompareStr('Арбуз', 'Арбалет'));
//Сравнение с помощью регистроНЕзависимых функций (работает только для латинских букв).
//Результат будет FALSE.
Writeln(SameText('Арбуз', 'арбуз'));
//Результат будет -32 (т.е. строка 1 сортируется до строки 2).
Writeln(StrIComp('Арбуз', 'арбуз'));
//Сравниваем только первые 2 символа. Результат будет -32 (т.е. строка 1 сортируется до строки 2).
Writeln(StrLIComp('Арбуз', 'арбуз', 2));
//Результат будет -32 (т.е. строка 1 сортируется до строки 2).
Writeln(CompareText('Арбуз', 'арбуз'));
//Результат будет -32 (т.е. строка 1 сортируется до строки 2).
Writeln(string.CompareText('Арбуз', 'арбуз'));
//Результат будет 0 (т.е. строки 1 и 2 равны).
Writeln(string.CompareText('Watermelon', 'watermelon'));
//Результат будет 0 (т.е. строки 1 и 2 равны).
Writeln(StrIComp('Watermelon', 'watermelon'));
//Сравниваем только первые 2 символа. Результат будет 0 (т.е. строки 1 и 2 равны).
Writeln(StrLIComp('Watermelon', 'watermelon', 2));
//Результат будет 0 (т.е. строки 1 и 2 равны).
Writeln(CompareText('Watermelon', 'watermelon'));
//Сравнение с помощью регистроНЕзависимых функций (использование пользовательской локали).
//Результат будет TRUE.
Writeln(SameText('Арбуз', 'арбуз', TLocaleOptions.loUserLocale));
//Результат будет 0 (т.е. строки 1 и 2 равны).
Writeln(CompareText('Арбуз', 'арбуз', TLocaleOptions.loUserLocale));
//Сравнение с помощью функции TStringHelper.Compare.
//Регистрозависимое сравнение. В результате будет 1 (т.е. строка 1 сортируется после строки 2).
Writeln(string.Compare('Арбуз', 'арбуз'));
//РегистроНЕзависимое сравнение. В результате будет 0 (т.е. строки 1 и 2 одинаковые).
Writeln(string.Compare('Арбуз', 'арбуз', true));
//РегистроНЕзависимое сравнение с игнорированием символов и знаков препинания.
//В результате будет 0 (т.е. строки 1 и 2 одинаковые).
Writeln(string.Compare('Арбуз!', '-арбуз',
[TCompareOption.coIgnoreSymbols, TCompareOption.coIgnoreCase]));
//Сравнение цифр как чисел, а не как строки.
//В результате будет -1 (т.е. первое число меньше чем второе).
Writeln(string.Compare('2', '10', [TCompareOption.coDigitAsNumbers]));
//Сравнение цифр как строки.
//В результате будет 1 (т.е. строка 1 сортируется после строки 2).
Writeln(string.Compare('2', '10'));
//РегистроНЕзависимое сравнение с определённым языком и регионом. В результате будет 0 (т.е. строки 1 и 2 одинаковые).
Writeln(string.Compare('Арбуз', 'арбуз', true, TLanguages.GetLocaleIDFromLocaleName('ru-RU')));
//Сравнение двух строк в двух экземплярах класса TStringBuilder (регистрозависимое).
stringBuilder1 := TStringBuilder.Create('Арбуз');
try
stringBuilder2 := TStringBuilder.Create('арбуз');
try
//Результат будет FALSE.
Writeln(stringBuilder1.Equals(stringBuilder2));
//Результат будет TRUE.
stringBuilder2.Clear;
stringBuilder2.Append('Арбуз');
Writeln(stringBuilder1.Equals(stringBuilder2));
finally
stringBuilder2.Free;
end;
finally
stringBuilder1.Free;
end;
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Поиск подстроки в строке
Теперь давайте посмотрим, как можно найти подстроку (определённую последовательность символов) в строке. Здесь у вас есть большой выбор функций, которые возвращают либо индекс найденной подстроки, либо true или false в зависимости от того, найдена подстрока в строке или нет. Итак, давайте перечислим все функции для поиска подстроки:
В первую очередь – это функция Pos, которая ищет подстроку, начиная с указанного номера символа. Функция осуществляет регистрозависимый поиск. Здесь нумерация символов начинается с 1. Если подстрока найдена, то возвращается номер первого символа найденной подстроки, иначе – 0. Есть также функция PosEx (в юните System.StrUtils), которая работает абсолютно также. Вот пример использования функции Pos:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
begin
try
//Поиск с первого символа. В результате отобразится 8.
Writeln(Pos('строка', 'Первая строка, вторая строка', 1));
//Поиск с десятого символа. В результате отобразится 23.
Writeln(Pos('строка', 'Первая строка, вторая строка', 10));
//Поиск несуществующей подстроки. В результате отобразится 0.
Writeln(Pos('третья', 'Первая строка, вторая строка', 1));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Аналогично функции Pos работают и функции IndexOf и LastIndexOf помощника TStringHelper. Они также осуществляют регистрозависимый поиск. Функция IndexOf ищет подстроку (или символ) с начала и до конца строки, а функция LasIndexOf – наоборот, т.е. с конца и до начала. Если подстрока найдена, то функции возвращают индекс первого символа найденной подстроки в строке. Здесь нумерация символов начинается с 0. Если подстрока не найдена, то функции возвращают -1. Также при поиске вы можете задать начало и интервал поиска. Вот примеры использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
begin
try
//Поиск с начала строки. В результате отобразится 7.
Writeln('Первая строка, вторая строка'.IndexOf('строка'));
//Поиск с десятого символа до конца. В результате отобразится 22.
Writeln('Первая строка, вторая строка'.IndexOf('строка', 9));
//Поиск несуществующей подстроки. В результате отобразится -1.
Writeln('Первая строка, вторая строка'.IndexOf('третья'));
//Поиск с начала только среди первых 10-ти символов. В результате отобразится -1.
Writeln('Первая строка, вторая строка'.IndexOf('строка', 0, 10));
//Поиск с начала только среди первых 20-ти символов. В результате отобразится 7.
Writeln('Первая строка, вторая строка'.IndexOf('строка', 0, 20));
//Поиск с конца строки. В результате отобразится 22.
Writeln('Первая строка, вторая строка'.LastIndexOf('строка'));
//Поиск с двадцать третьего символа и до начала. В результате отобразится 7.
Writeln('Первая строка, вторая строка'.LastIndexOf('строка', 22));
//Поиск с конца только среди последних 10 символов. В результате отобразится -1.
Writeln('Первая строка, вторая строка, третья'.LastIndexOf('строка', 36, 10));
//Поиск с конца только среди последних 20 символов. В результате отобразится 22.
Writeln('Первая строка, вторая строка, третья'.LastIndexOf('строка', 36, 20));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Теперь рассмотрим функции для проверки, есть ли подстрока в строке, и не важно, в каком месте. Для этого есть функции ContainsStr и ContainsText в юните System.StrUtils, а также функция Contains в помощнике TStringHelper.Contains. Функции ContainsStr и TStringHelper.Contains – регистрозависимые, а функция ContainsText – нет. Вот примеры использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils;
begin
try
//В результате отобразится TRUE.
Writeln(ContainsStr('Раз, два, три, четыре, пять', 'Раз'));
//В результате отобразится FALSE.
Writeln(ContainsStr('Раз, два, три, четыре, пять', 'Два'));
//В результате отобразится TRUE.
Writeln(ContainsText('Раз, два, три, четыре, пять', 'Три'));
//В результате отобразится TRUE.
Writeln('Раз, два, три, четыре, пять'.Contains('четыре'));
//В результате отобразится FALSE.
Writeln('Раз, два, три, четыре, пять'.Contains('Пять'));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Дополнительно есть функции проверяющие, наличие определённой подстроки в начале или в конце текста. Это функции StartsStr, StartsText, EndsStr и EndsText в юните System.StrUtils, а также функции StartsWith, EndsWith и EndsText у помощника TStringHelper. Функции StartsStr и EndsStr регистрозависимые, функции StartsText, EndsText и TStringHelper.EndsText регистронезависимые, а у функций TStringHelper.StartsWith и TStringHelper.EndsWith есть второй параметр для выбора режима поиска. Учтите, что регистронезависимый поиск в функции TStringHelper.StartsWith работает только с буквами латинского алфавита. По умолчанию поиск в функциях TStringHelper.StartsWith и TStringHelper.EndsWith регистрозависимый.
Обратите внимание, что регистронезависимый поиск в функциях StartsText, EndsText и TStringHelper.EndsText и TStringHelper.EndsWith ведётся для текущей локали. Т.е. если на компьютере будет установлена английская локаль, то регистронезависимый поиск по русскому тексту работать не будет.
Вот примеры использования функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils;
begin
try
//Ищем подстроку в начале строки. Результат будет TRUE.
Writeln(StartsStr('Раз', 'Раз, два, три'));
//Ищем подстроку в начале строки. Результат будет FALSE.
Writeln(StartsStr('раз', 'Раз, два, три'));
//Ищем подстроку в начале строки. Результат будет FALSE.
Writeln(StartsStr('два', 'Раз, два, три'));
//Ищем подстроку в начале строки. Результат будет TRUE.
Writeln(StartsText('Раз', 'Раз, два, три'));
//Ищем подстроку в начале строки. Результат будет TRUE.
Writeln(StartsText('раз', 'Раз, два, три'));
//Ищем подстроку в начале строки. Результат будет FALSE.
Writeln(StartsText('два', 'Раз, два, три'));
//Ищем подстроку в начале строки. Результат будет TRUE.
Writeln('Раз, два, три'.StartsWith('Раз'));
//Ищем подстроку в начале строки. Результат будет FALSE.
Writeln('Раз, два, три'.StartsWith('раз'));
//Ищем подстроку в начале строки. Результат будет FALSE (для кириллицы).
Writeln('Раз, два, три'.StartsWith('раз', true));
//Ищем подстроку в начале строки. Результат будет TRUE (для латиницы).
Writeln('One, two, three'.StartsWith('one', true));
//Ищем подстроку в начале строки. Результат будет FALSE.
Writeln('Раз, два, три'.StartsWith('два'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln(EndsStr('три', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет FALSE.
Writeln(EndsStr('Три', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет FALSE.
Writeln(EndsStr('два', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln(EndsText('три', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln(EndsText('Три', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет FALSE.
Writeln(EndsText('два', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln(string.EndsText('три', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln(string.EndsText('Три', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет FALSE.
Writeln(string.EndsText('два', 'Раз, два, три'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln('Раз, два, три'.EndsWith('три'));
//Ищем подстроку в конце строки. Результат будет FALSE.
Writeln('Раз, два, три'.EndsWith('Три'));
//Ищем подстроку в конце строки. Результат будет TRUE.
Writeln('Раз, два, три'.EndsWith('Три', true));
//Ищем подстроку в конце строки. Результат будет FALSE.
Writeln('Раз, два, три'.EndsWith('два'));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.И конечно самые продвинутые условия для поиска подстрок можно задавать при помощи регулярных выражений. Для этого есть функции TRegEx.Match и TRegEx.Matches. Вот несколько примеров использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.RegularExpressions;
var
regEx: TRegEx;
match: TMatch;
matches: TMatchCollection;
begin
try
//Ищем в строке любой IP-адрес, с начала строки.
regEx := TRegEx.Create('\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b');
match := regEx.Match('В этой строке два IP-адреса 192.168.1.1 и 192.168.1.15');
//Найдена ли подстрока. Результат будет TRUE.
Writeln(match.Success);
//Номер первого символа найденной подстроки. Результат будет 29.
Writeln(match.Index);
//Длина найденной подстроки. Результат будет 11.
Writeln(match.Length);
//Найденная подстрока. Результат будет 192.168.1.1.
Writeln(match.Value);
//Ищем следующий IP-адрес в этой же строке.
match := match.NextMatch;
//Найдена ли следующая подстрока. Результат будет TRUE.
Writeln(match.Success);
//Номер первого символа найденной подстроки. Результат будет 43.
Writeln(match.Index);
//Длина найденной подстроки. Результат будет 12.
Writeln(match.Length);
//Найденная подстрока. Результат будет 192.168.1.15.
Writeln(match.Value);
//Ищем следующий IP-адрес в этой же строке.
match := match.NextMatch;
//Найдена ли следующая подстрока. Результат будет FALSE.
Writeln(match.Success);
//Ищем адреса почтовых ящиков в тексте, игнорируя регистр.
regEx := TRegEx.Create('\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,}\b', [roIgnoreCase]);
matches := regEx.Matches('В этой Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра.
строке Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра.
содержатся три Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра.
почтовых адреса.');
//В результате будет выдано три адреса:
//Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра.
//Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра.
//Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра.
for match in matches do
Writeln(match.Value);
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Примеры и описание регулярных выражений смотрите на сайте библиотеки PCRE.
Поиск символов в строке
Случается, что нужно найти определённые символы в строке. Конечно, для этого вы можете воспользоваться функциями для поиска подстроки, о которых было написано выше, но есть и специальные функции, позволяющие найти первый попавшийся в строке символ из нескольких искомых. Это функции помощника TStringHelper: IndexOfAny, IndexOfAnyUnquoted и LastIndexOfAny. Функции IndexOfAny и IndexOfAnyUnquoted ищут, перебирая символы сначала до конца строки, а функция LastIndexOfAny – наоборот. Во всех функциях можно указать интервал поиска. Функция IndexOfAnyUnquoted умеет игнорировать символы, заключенные в кавычки, скобки и т.п. Вот пример использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils, Winapi.Windows;
begin
try
//Ищем символ 'р' или 'о'. В результате будет 2.
Writeln('Это строка!'.IndexOfAny(['р', 'о']));
//Ищем символ 'р' или 'о' начиная с пятого символа. В результате будет 6.
Writeln('Это строка!'.IndexOfAny(['р', 'о'], 4));
//Ищем символ 'р' или 'о' с пятого по шестой символ. В результате будет -1.
Writeln('Это строка!'.IndexOfAny(['р', 'о'], 4, 2));
//Ищем символ 'р' или 'о' с конца строки. В результате будет 7.
Writeln('Это строка!'.LastIndexOfAny(['р', 'о']));
//Ищем символ 'р' или 'о' начиная с пятого символа и до начала. В результате будет 2.
Writeln('Это строка!'.LastIndexOfAny(['р', 'о'], 4));
//Ищем символ 'р' или 'о' с пятого по третий символ. В результате будет 2.
Writeln('Это строка!'.LastIndexOfAny(['р', 'о'], 4, 3));
//Ищем символ 'р' или 'о', но не среди символов заключенных в кавычки. В результате будет 8.
Writeln('"Это" строка!'.IndexOfAnyUnquoted(['р', 'о'], '"', '"'));
//Ищем символ 'р' или 'о', но не среди символов заключенных в скобки, в том числе вложенных. В результате будет 17.
Writeln('(Это (вторая)) строка!'.IndexOfAnyUnquoted(['р', 'о'], '(', ')'));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Замена подстроки в строке
Для поиска и замены подстроки (или символа) в строке можно использовать функции StringReplace, ReplaceStr и ReplaceText, TStringHelper.Replace, TStringBuilder.Replace и TRegEx.Replace. Функции ReplaceStr и TStringBuilder.Replace – регистрозависимые, функция ReplaceText – регистронезависимая, в функциях StringReplace, TStringHelper.Replace и TRegEx.Replace зависимость от регистра настраивается флажком rfIgnoreCase. Функции TRegEx.Replace ищут подстроку, используя регулярные выражения. В функции TStringBuilder.Replace можно задать диапазон поиска подстроки. Вот примеры использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.StrUtils, System.RegularExpressions;
var
stringBuilder: TStringBuilder;
regEx: TRegEx;
begin
try
//Ищет все подстроки в строке и заменяет их на новые (регистрозависимый поиск).
//В результате будет 'Раз, два, три, два'.
Writeln(ReplaceStr('Раз, четыре, три, четыре', 'четыре', 'два'));
//Ищет все подстроки в строке и заменяет их на новые (регистрозависимый поиск).
//В результате будет 'Раз, Четыре, три, два'.
Writeln(ReplaceStr('Раз, Четыре, три, четыре', 'четыре', 'два'));
//Ищет все подстроки в строке и заменяет их на новые (регистронезависимый поиск).
//В результате будет 'Раз, два, три, два'.
Writeln(ReplaceText('Раз, четыре, три, четыре', 'четыре', 'два'));
//Ищет все подстроки в строке и заменяет их на новые (регистронезависимый поиск).
//В результате будет 'Раз, два, три, два'.
Writeln(ReplaceText('Раз, Четыре, три, четыре', 'четыре', 'два'));
//Ищет только первую подстроку в строке и заменяет её на новую.
//В результате будет 'Раз, два, три, четыре'.
Writeln(StringReplace('Раз, четыре, три, четыре', 'четыре', 'два', []));
//Ищет все подстроки в строке и заменяет их на новые.
//В результате будет 'Раз, два, три, два'.
Writeln(StringReplace('Раз, четыре, три, четыре', 'четыре', 'два', [rfReplaceAll]));
//Пример регистрозависимого поиска и замены подстрок.
//В результате будет 'Раз, Четыре, три, два'.
Writeln(StringReplace('Раз, Четыре, три, четыре', 'четыре', 'два', [rfReplaceAll]));
//Пример регистронезависимого поиска и замены подстрок.
//В результате будет 'Раз, два, три, два'.
Writeln(StringReplace('Раз, Четыре, три, четыре', 'четыре', 'два', [rfReplaceAll, rfIgnoreCase]));
//Ищет все подстроки в строке и заменяет их на новые
//(т.к. по умолчанию установлен флаг rfReplaceAll).
//В результате будет 'Раз, два, три, два'.
Writeln('Раз, четыре, три, четыре'.Replace('четыре', 'два'));
//Ищет только первую подстроку в строке и заменяет её на новую
//(т.к нет флага rfReplaceAll).
//В результате будет 'Раз, два, три, четыре'.
Writeln('Раз, четыре, три, четыре'.Replace('четыре', 'два', []));
//Пример регистрозависимого поиска и замены подстрок
//(т.к. по умолчанию не установлен флаг rfIgnoreCase).
//В результате будет 'Раз, Четыре, три, два'.
Writeln('Раз, Четыре, три, четыре'.Replace('четыре', 'два'));
//Пример регистронезависимого поиска и замены подстрок
//(т.к. установлен флаг rfIgnoreCase).
//В результате будет 'Раз, два, три, четыре'.
Writeln('Раз, Четыре, три, четыре'.Replace('четыре', 'два', [rfIgnoreCase]));
stringBuilder := TStringBuilder.Create;
try
//Ищет все подстроки в строке и заменяет их на новые.
//Результат будет 'Раз, два, три, два'.
stringBuilder.Append('Раз, четыре, три, четыре');
Writeln(stringBuilder.Replace('четыре', 'два').ToString);
//Ищет все подстроки в строке и заменяет их на новые.
//Результат будет 'Раз, Четыре, три, два'.
stringBuilder.Clear;
stringBuilder.Append('Раз, Четыре, три, четыре');
Writeln(stringBuilder.Replace('четыре', 'два').ToString);
//Ищет все подстроки начиная с 4-го символа в пределах 10-ти символов и заменяет их на новые.
//Результат будет 'Раз, два, три, четыре'.
stringBuilder.Clear;
stringBuilder.Append('Раз, четыре, три, четыре');
Writeln(stringBuilder.Replace('четыре', 'два', 3, 10).>]*>(.*?)</\1>', [roIgnoreCase]);
Writeln(regEx.Replace('Здесь содержатся <b>выделенное</b> и <u>подчёркнутое</u> слова и <a href="http://www.proghouse.ru">ссылка</a>.', '\2'));
//Ищем определённое слово и заменяем его звёздочками.
//В результате получится: Закрываем *** слова звёздами. *** слов не будет! *** слово - это ***!
regEx := TRegEx.Create('плох[ио][емх]?', [roIgnoreCase]);
Writeln(regEx.Replace('Закрываем плохие слова звёздами. Плохих слов не будет! Плохое слово - это плохо!', '***'));
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Обрезка пробелов и управляющих символов
Для такой часто встречающейся операции, как удаление пробелов и управляющих символов в начале и в конце строки, есть несколько функций: Trim, TrimLeft, TrimRight, TStringHelper.Trim, TStringHelper.TrimLeft и TStringHelper.TrimRight. При вызове функций TStringHelper.Trim, TStringHelper.TrimLeft и TStringHelper.TrimRight вы можете перечислить, какие символы нужно удалять. Вот пример использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
begin
try
//Удаляем пробелы и управляющие символы в начале и конце строки.
//Результат будет 'Строка без лишних пробелов и управляющих символов!'.
Writeln(Trim(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10));
//Удаляем пробелы и управляющие символы в начале и конце строки.
//Результат будет 'Строка без лишних пробелов и управляющих символов!'.
Writeln(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10.Trim);
//Удаляем только символы #13 и #10 в начале и конце строки.
//Результат будет ' Строка без лишних пробелов и управляющих символов! '.
Writeln(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10.Trim([#13, #10]));
//Удаляем пробелы и управляющие символы только в начале строки.
//Результат будет 'Строка без лишних пробелов и управляющих символов! '#13#10.
Writeln(TrimLeft(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10));
//Удаляем пробелы и управляющие символы только в начале строки.
//Результат будет 'Строка без лишних пробелов и управляющих символов! '#13#10.
Writeln(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10.TrimLeft);
//Удаляем пробелы и управляющие символы только в конце строки.
//Результат будет #13#10' Строка без лишних пробелов и управляющих символов!'.
Writeln(TrimRight(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10));
//Удаляем пробелы и управляющие символы только в конце строки.
//Результат будет #13#10' Строка без лишних пробелов и управляющих символов!'.
Writeln(#13#10' Строка без лишних пробелов и управляющих символов! '#13#10.TrimRight);
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Выравнивание текста за счёт установки пробелов
И напоследок ещё пара интересных функций, которые умеют дополнять строку пробелами или другими символами, пока она не станет нужной длины. Это функции TStringHelper.PadLeft и TStringHelper.PadRight. С помощью этих функций, например, для лучшего восприятия можно добавить пробелы в начало чисел, которые вы выдаёте столбиком в консоли или дополнить числа ведущими нулями. Вот пример использования этих функций:
program Project1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils;
begin
try
//Дополняем числа пробелами. В результате получится:
//' 123'
//'12345'
//' 1234'
Writeln('123'.PadLeft(5));
Writeln('12345'.PadLeft(5));
Writeln('1234'.PadLeft(5));
//Дополняем числа нулями. В результате получится.
//'00123'
//'12345'
//'01234'
Writeln('123'.PadLeft(5, '0'));
Writeln('12345'.PadLeft(5, '0'));
Writeln('1234'.PadLeft(5, '0'));
//Дополняем строки чёрточками, чтобы сделать красивое содержание.
//В результате получится:
//'Вступление --------- стр. 1'
//'Доклад ------------- стр. 2'
//'Выводы ------------- стр. 7'
//'Заключение --------- стр. 9'
Writeln('Вступление '.PadRight(20, '-') + ' стр. 1');
Writeln('Доклад '.PadRight(20, '-') + ' стр. 2');
Writeln('Выводы '.PadRight(20, '-') + ' стр. 7');
Writeln('Заключение '.PadRight(20, '-') + ' стр. 9');
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.Вместо заключения
Итак, в статье я постарался собрать все возможные функции Delphi, которые постоянно нужны при работе со строками. Надеюсь, вы найдёте в этой статье что-то новое и интересное для себя. Если я упустил что-то важное на ваш взгляд, просьба не держать это в себе, а написать об этом в комментариях.
14 струн | R для науки о данных
Введение
Эта глава знакомит вас с манипуляциями со строками в R. Вы узнаете основы того, как работают строки и как создавать их вручную, но основное внимание в этой главе будет уделено регулярным выражениям или, для краткости, регулярным выражениям. Регулярные выражения полезны, потому что строки обычно содержат неструктурированные или частично структурированные данные, а регулярные выражения — это краткий язык для описания шаблонов в строках. Когда вы впервые посмотрите на регулярное выражение, вы подумаете, что кошка прошла по клавиатуре, но по мере того, как вы лучше понимаете, они скоро начнут обретать смысл.
Предпосылки
В этой главе основное внимание будет уделено пакету stringr для манипуляций со строками, который является частью основного тидиверса.
Основы работы со струнами
Вы можете создавать строки как в одинарных, так и в двойных кавычках. В отличие от других языков, нет никакой разницы в поведении. Я рекомендую всегда использовать ", если вы не хотите создать строку, содержащую несколько " .
string1 <- "Это строка"
string2 <- 'Если я хочу включить «кавычку» внутри строки, я использую одинарные кавычки » Если вы забудете закрыть цитату, вы увидите + , символ продолжения:
> "Это строка без закрывающей кавычки.
+
+
+ ПОМОГИТЕ Я застрял Если это случилось с вами, нажмите Escape и попробуйте еще раз!
Чтобы включить буквальную одинарную или двойную кавычку в строку, вы можете использовать \ , чтобы «экранировать» ее:
double_quote <- "\" "# или '"'
single_quote <- '\' '# или "'" Это означает, что если вы хотите включить буквальную обратную косую черту, вам нужно будет удвоить ее: "\\" .
Помните, что напечатанное представление строки не совпадает с самой строкой, потому что напечатанное представление показывает escape-последовательности. Чтобы увидеть необработанное содержимое строки, используйте writeLines () :
x <- c ("\" "," \\ ")
Икс
#> [1] "\" "" \\ "
writeLines (x)
#> "
#> \ Есть несколько других специальных символов. Наиболее распространены "\ n" , новая строка и "\ t" , вкладка, но вы можете увидеть полный список, запросив помощь по телефону ": ? '"' или ? "' «.Иногда встречаются строки вроде "\ u00b5" , это способ написания неанглийских символов, который работает на всех платформах:
x <- "\ u00b5"
Икс
#> [1] "µ" Несколько строк часто хранятся в векторе символов, который можно создать с помощью c () :
c («один», «два», «три»)
#> [1] "один" "два" "три" Длина струны
Base R содержит множество функций для работы со строками, но мы будем избегать их, потому что они могут быть несовместимыми, что затрудняет их запоминание.Вместо этого мы будем использовать функции из stringr. У них более интуитивно понятные названия, и все они начинаются с str_ . Например, str_length () сообщает количество символов в строке:
str_length (c ("a", "R для науки о данных", NA))
#> [1] 1 18 NA Общий префикс str_ особенно полезен, если вы используете RStudio, потому что ввод str_ вызовет автозаполнение, что позволит вам увидеть все функции строкового преобразования:
Объединение струн
Чтобы объединить две или более строк, используйте str_c () :
str_c ("x", "y")
#> [1] "ху"
str_c ("x", "y", "z")
#> [1] "xyz" Используйте аргумент sep , чтобы контролировать, как они разделяются:
str_c ("x", "y", sep = ",")
#> [1] "x, y" Как и в большинстве других функций в R, пропущенные значения заразительны.Если вы хотите, чтобы они печатались как «NA» , используйте str_replace_na () :
x <- c ("abc", нет данных)
str_c ("| -", x, "- |")
#> [1] "| -abc- |" NA
str_c ("| -", str_replace_na (x), "- |")
#> [1] "| -abc- |" "| -NA- |" Как показано выше, str_c () векторизован, и он автоматически перерабатывает более короткие векторы до той же длины, что и самый длинный:
str_c ("префикс-", c ("a", "b", "c"), "-suffix")
#> [1] «префикс-а-суффикс» «префикс-b-суффикс» «префикс-с-суффикс» Объекты длины 0 отбрасываются без уведомления.Это особенно полезно в сочетании с , если :
имя <- "Хэдли"
time_of_day <- "утро"
день рождения <- ЛОЖЬ
str_c (
"Хорошо", время_дня, "", имя,
if (день рождения) "и С ДНЕМ РОЖДЕНИЯ",
"."
)
#> [1] "Доброе утро, Хэдли". Чтобы свернуть вектор строк в одну строку, используйте collapse :
str_c (c ("x", "y", "z"), collapse = ",")
#> [1] "x, y, z" Подмножество строк
Вы можете извлечь части строки с помощью str_sub () .Помимо строки, str_sub () принимает аргументы start и end , которые задают (включительно) позицию подстроки:
x <- c («Яблоко», «Банан», «Груша»)
str_sub (х, 1, 3)
#> [1] "App" "Ban" "Pea"
# отрицательные числа считают в обратном порядке от конца
str_sub (х, -3, -1)
#> [1] "ple" "ana" "ear" Обратите внимание, что str_sub () не завершится ошибкой, если строка слишком короткая: она просто вернет столько, сколько возможно:
str_sub ("а", 1, 5)
#> [1] "a" Вы также можете использовать форму назначения str_sub () для изменения строк:
str_sub (x, 1, 1) <- str_to_lower (str_sub (x, 1, 1))
Икс
#> [1] "яблоко" "банан" "груша" Регион
Выше я использовал str_to_lower () , чтобы изменить текст на нижний регистр.Вы также можете использовать str_to_upper () или str_to_title () . Однако изменить регистр сложнее, чем может показаться на первый взгляд, потому что разные языки имеют разные правила изменения регистра. Вы можете выбрать, какой набор правил использовать, указав локаль:
# Турецкий имеет два «i»: с точкой и без нее, и это
# имеет другое правило использования заглавных букв:
str_to_upper (c ("я", "ı"))
#> [1] «Я» «Я»
str_to_upper (c ("i", "ı"), locale = "tr")
#> [1] "İ" "I" Локаль указывается в виде кода языка ISO 639, который представляет собой двух- или трехбуквенное сокращение.Если вы еще не знаете код своего языка, в Википедии есть хороший список. Если вы оставите языковой стандарт пустым, он будет использовать текущий языковой стандарт, предоставленный вашей операционной системой.
Еще одна важная операция, на которую влияет локаль, - это сортировка. Базовые функции order () и sort () в R сортируют строки, используя текущую локаль. Если вам нужна надежная работа на разных компьютерах, вы можете использовать str_sort () и str_order () , которые принимают дополнительный аргумент locale :
x <- c («яблоко», «баклажан», «банан»)
str_sort (x, locale = "en") # английский
#> [1] "яблоко" "банан" "баклажан"
str_sort (x, locale = "haw") # гавайский
#> [1] "яблоко" "баклажан" "банан" Упражнения
В коде, который не использует stringr, вы часто увидите
paste ()иpaste0 ().В чем разница между двумя функциями? Какие функции Stringr они эквивалентны? Чем отличаются функции по обработкеNA?Опишите своими словами разницу между
sepиcollapseаргументы дляstr_c ().Используйте
str_length ()иstr_sub ()для извлечения среднего символа из строка. Что вы будете делать, если в строке будет четное количество символов?Что делает
str_wrap ()? Когда вы можете захотеть его использовать?Что делает
str_trim ()? Что противоположноstr_trim ()?Напишите функцию, которая поворачивает (например,g.) вектор
c («a», «b», «c»)в строкаa, b и c. Тщательно подумайте, что ему делать, если для вектора длины 0, 1 или 2.
Сопоставление шаблонов с регулярными выражениями
Регулярные выражения - очень сжатый язык, который позволяет описывать шаблоны в строках. На их понимание уходит время, но как только вы их поймете, вы найдете их чрезвычайно полезными.
Для изучения регулярных выражений мы будем использовать str_view () и str_view_all () .Эти функции принимают вектор символов и регулярное выражение и показывают, как они совпадают. Мы начнем с очень простых регулярных выражений, а затем постепенно будем усложнять их. Освоив сопоставление с образцом, вы научитесь применять эти идеи с различными строковыми функциями.
Основные матчи
Самые простые шаблоны соответствуют точным строкам:
x <- c («яблоко», «банан», «груша»)
str_view (x, "an") Следующая ступень сложности - ., что соответствует любому символу (кроме новой строки):
Но если «. »соответствует любому символу, как сопоставить символ« . ”? Вам нужно использовать «escape», чтобы указать регулярному выражению, которое вы хотите точно ему сопоставить, а не использовать его особое поведение. Как и строки, регулярные выражения используют обратную косую черту \ , чтобы избежать особого поведения. Таким образом, чтобы соответствовать . , вам нужно регулярное выражение \. . К сожалению, это создает проблему. Мы используем строки для представления регулярных выражений, а \ также используется как escape-символ в строках.Итак, чтобы создать регулярное выражение \. нам нужна строка "\\." .
# Для создания регулярного выражения нам понадобится \\
точка <- "\\."
# Но само выражение содержит только один:
writeLines (точка)
#> \.
# И это говорит R искать явное.
str_view (c ("abc", "a.c", "bef"), "a \\. c") Если \ используется как escape-символ в регулярных выражениях, как сопоставить литерал \ ? Что ж, вам нужно избежать этого, создав регулярное выражение \ .Чтобы создать это регулярное выражение, вам нужно использовать строку, которая также должна экранировать \ . Это означает, что для сопоставления букв \ вам нужно написать "\\\\" - вам нужно четыре обратной косой черты, чтобы соответствовать одной!
х <- "а \\ б"
writeLines (x)
#> a \ b
str_view (x, "\\\\") В этой книге я буду писать регулярное выражение как \. и строки, представляющие регулярное выражение как "\\." .
Упражнения
Объясните, почему каждая из этих строк не соответствует
\:"\","\\","\\\".Как бы вы сопоставили последовательность
"'\?Каким шаблонам будет соответствовать регулярное выражение
\ ., чтобы соответствовать началу строки. и$:x <- c («яблочный пирог», «яблоко», «яблочный пирог») str_view (x, "яблоко")Вы также можете сопоставить границу между словами с
\ b. Я не часто использую это в R, но иногда я использую его, когда выполняю поиск в RStudio, когда я хочу найти имя функции, которая является компонентом других функций. Например, я буду искать\ bsum \ b, чтобы не совпадать, сводка, сводкаrowumи т. Д.$ "?Учитывая совокупность общих слов в строке
stringr :: words, создайте регулярные выражения, которые находят все слова, которые:- Начните с буквы «y».
- Окончание на «x»
- Ровно три буквы. (Не обманывайте, используя
str_length ()!) - Имейте семь или более букв.
Поскольку этот список длинный, вы можете использовать аргумент
matchдляstr_view ()для отображения только совпадающих или несовпадающих слов. abc] : соответствует чему угодно, кроме a, b или c.Создавайте регулярные выражения, чтобы найти все слова, которые:
Начните с гласной.
Это только согласные. (Подсказка: подумайте о сопоставлении «Не» - гласные.)
Заканчивается на
ed, но не наeed.Конец с
ingилиise.
Эмпирически проверьте правило «i до e, кроме c».
Всегда ли за «q» следует «u»?
Напишите регулярное выражение, которое соответствует слову, если оно, вероятно, написано на британском, а не на американском английском.
Создайте регулярное выражение, которое будет соответствовать телефонным номерам, как обычно написано в вашей стране.
-
?: 0 или 1 -
+: 1 или более -
*: 0 или более -
{n}: ровно n -
{n,}: n или более -
{, m}: не более м -
{n, m}: между n и m -
"\\ {. + \\}" -
\ d {4} - \ d {2} - \ d {2} -
"\\\\ {4}"
Помните, чтобы создать регулярное выражение, содержащее \ d или \ s , вам нужно экранировать \ для строки, поэтому вы наберете "\\ d" или "\ \ s ".
Символьный класс, содержащий один символ, является хорошей альтернативой экранированию обратной косой черты, когда вы хотите включить один метасимвол в регулярное выражение. Многие люди находят это более читаемым.
# Ищите буквальный символ, который обычно имеет особое значение в регулярном выражении
str_view (c ("abc", "a.c »,« a * c »,« a c »),« a [.] c »)
str_view (c («abc», «a.c», «a * c», «a c»), «. [*] C»)
str_view (c («abc», «a.c», «a * c», «a c»), «a []») Это работает для большинства (но не для всех) метасимволов регулярных выражений: $ . | ? * + ( ) [ {. и - .
Вы можете использовать чередование , чтобы выбрать один или несколько альтернативных шаблонов. Например, abc | d..f будет соответствовать либо «abc», либо «глухой» . Обратите внимание, что приоритет для | является низким, поэтому abc | xyz соответствует abc или xyz , а не abcyz или abxyz . Как и в случае с математическими выражениями, если приоритеты когда-либо сбивают с толку, используйте круглые скобки, чтобы прояснить, что вы хотите:
str_view (c ("серый", "серый"), "gr (e | a) y") Упражнения
Повтор
Следующий шаг в развитии - это контроль количества совпадений шаблона:
x <- "1888 год - самый длинный год в римских цифрах: MDCCCLXXXVIII"
str_view (x, "CC?") Обратите внимание, что приоритет этих операторов высок, поэтому вы можете написать: colou? R для соответствия американскому или британскому написанию.Это означает, что в большинстве случаев требуются круглые скобки, например bana (na) + .
Также можно точно указать количество совпадений:
По умолчанию эти совпадения являются «жадными»: они будут соответствовать самой длинной возможной строке. Вы можете сделать их «ленивыми», сопоставив самую короткую строку, указав ? после них.* $
Создавайте регулярные выражения, чтобы найти все слова, которые:
- Начните с трех согласных.
- Имейте три или более гласных подряд.
- Имейте подряд две или более пары гласный-согласный.
Решите кроссворды с регулярным выражением для начинающих на https://regexcrossword.com/challenges/beginner.
Группировка и обратные ссылки
Ранее вы узнали о скобках как о способе устранения неоднозначности сложных выражений. Круглые скобки также создают группу захвата с номером (номер 1, 2 и т. Д.). Группа захвата хранит часть строки , совпадающую с частью регулярного выражения в круглых скобках. Вы можете ссылаться на тот же текст, который ранее соответствовал группе захвата с обратными ссылками , например \ 1 , \ 2 и т. Д.Например, следующее регулярное выражение находит все фрукты с повторяющейся парой букв.
str_view (fruit, "(..) \\ 1", match = TRUE) (Вскоре вы также увидите, насколько они полезны в сочетании с str_match () .)
Упражнения
Опишите словами, чему будут соответствовать эти выражения:
-
(.) \ 1 \ 1 -
"(.) (.) \\ 2 \\ 1" -
(..) \ 1 -
"(.). \\ 1. \\ 1" -
"(.) (.) (.). * \\ 3 \\ 2 \\ 1"
-
Создавать регулярные выражения для поиска слов, которые:
Начало и конец одного и того же символа.
Содержит повторяющуюся пару букв (например, «церковь» содержит дважды повторяемую букву «ч».)
Содержит одну букву, повторяющуюся как минимум в трех местах (например, «одиннадцать» содержит три буквы «е».)
Инструменты
Теперь, когда вы изучили основы регулярных выражений, пора научиться применять их к реальным задачам.В этом разделе вы познакомитесь с широким спектром строковых функций, которые позволят вам:
- Определите, какие строки соответствуют шаблону.
- Найдите позиции совпадений.
- Извлечь содержимое совпадений.
- Заменить совпадения новыми значениями.
- Разделить строку на основе совпадения.
Перед тем, как мы продолжим, сделаем небольшое предостережение: поскольку регулярные выражения настолько эффективны, легко попытаться решить любую проблему с помощью одного регулярного выражения.\ [\] \ r \\] | \\.) * \] (?: (?: \ r \ n)? [\ t]) *)) * \> (? 🙁 ?: \ r \ n)? [\ t]) *)) *)?; \ s *)
Это несколько патологический пример (потому что адреса электронной почты на самом деле удивительно сложны), но он используется в реальном коде. Подробнее см. Обсуждение stackoverflow на http://stackoverflow.com/a/201378.
Не забывайте, что вы изучаете язык программирования и в вашем распоряжении есть другие инструменты. Вместо создания одного сложного регулярного выражения часто проще написать серию более простых регулярных выражений.Если вы застряли, пытаясь создать одно регулярное выражение, которое решает вашу проблему, сделайте шаг назад и подумайте, можно ли разбить проблему на более мелкие части, решая каждую задачу, прежде чем переходить к следующей.
Обнаружить совпадения
Чтобы определить, соответствует ли вектор символов шаблону, используйте str_detect () . Он возвращает логический вектор той же длины, что и вход:
x <- c («яблоко», «банан», «груша»)
str_detect (x, "e")
#> [1] ИСТИНА ЛОЖЬ ИСТИНА Помните, что когда вы используете логический вектор в числовом контексте, FALSE становится 0, а TRUE становится 1.т "))
#> [1] 65
# Какая доля общих слов оканчивается на гласную?
означает (str_detect (слова, "[aeiou] $"))
#> [1] 0,2765306
Когда у вас есть сложные логические условия (например, соответствие a или b, но не c, кроме d), часто проще объединить несколько вызовов str_detect () с логическими операторами, чем пытаться создать одно регулярное выражение. Например, вот два способа найти все слова, не содержащие гласных:
# Найти все слова, содержащие хотя бы одну гласную, и убрать
no_vowels_1 <-! str_detect (слова, «[aeiou]»)
# Найти все слова, состоящие только из согласных (не гласных)
no_vowels_2 <- str_detect (слова, «^ [^ aeiou] + $»)
идентичные (no_vowels_1, no_vowels_2)
#> [1] ИСТИНА Результаты идентичны, но я думаю, что первый подход значительно легче понять.Если ваше регулярное выражение становится слишком сложным, попробуйте разбить его на более мелкие части, дать каждой части имя, а затем объединить части с помощью логических операций.
Обычно str_detect () используется для выбора элементов, соответствующих шаблону. Вы можете сделать это с помощью логического подмножества или удобной оболочки str_subset () :
слов [str_detect (words, "x $")]
#> [1] "коробка" "секс" "шестерка" "налог"
str_subset (слова, "x $")
#> [1] "коробка" "пол" "шестерка" "налог" Однако, как правило, ваши строки представляют собой один столбец фрейма данных, и вместо этого вы хотите использовать фильтр:
df <- tibble (
слово = слова,
я = seq_along (слово)
)
df%>%
фильтр (str_detect (слово, "x $"))
#> # Стол: 4 x 2
#> слово i
#>
#> 1 коробка 108
#> 2 пол 747
#> 3 шесть 772
#> 4 налог 841 Вариантом str_detect () является str_count () : вместо простого да или нет он сообщает вам, сколько совпадений в строке:
x <- c («яблоко», «банан», «груша»)
str_count (x, "а")
#> [1] 1 3 1
# Сколько в среднем гласных в слове?
означает (str_count (слова, "[aeiou]"))
#> [1] 1.aeiou] ")
)
#> # Стол: 980 x 4
#> слово i гласные согласные
#>
#> 1 а 1 1 0
#> 2 в состоянии 2 2 2
#> 3 примерно 3 3 2
#> 4 абсолютное 4 4 4
#> 5 принять 5 2 4
#> 6 счет 6 3 4
#> #… С еще 974 строками Обратите внимание, что совпадения никогда не перекрываются. Например, в «abababa» , сколько раз будет совпадать шаблон «aba» ? Регулярные выражения говорят два, а не три:
str_count ("abababa", "aba")
#> [1] 2
str_view_all ("abababa", "aba") Обратите внимание на использование str_view_all () .Как вы вскоре узнаете, многие строковые функции работают парами: одна функция работает с одним совпадением, а другая - со всеми совпадениями. Вторая функция будет иметь суффикс _all .
Упражнения
Для каждой из следующих задач попробуйте решить ее, используя как одну регулярное выражение и комбинация нескольких вызовов
str_detect ().Найдите все слова, которые начинаются или заканчиваются на
x.Найдите все слова, которые начинаются с гласной и заканчиваются согласной.
Существуют ли слова, содержащие хотя бы одно из разных гласный звук?
В каком слове больше всего гласных? Какое слово имеет высшее пропорция гласных? (Подсказка: какой знаменатель?)
Групповые матчи
Ранее в этой главе мы говорили об использовании круглых скобок для уточнения приоритета и для обратных ссылок при сопоставлении.] +) " has_noun <- предложения%>% str_subset (имя существительное)%>% голова (10) has_noun%>% str_extract (имя существительное) #> [1] "гладкая" "простыня" "глубина" "курица" "припаркованная" #> [6] "солнышко" "огромный" "мяч" "женщина" "помогает"
str_extract () дает нам полное совпадение; str_match () дает каждый отдельный компонент. Вместо вектора символов он возвращает матрицу с одним столбцом для полного соответствия, за которым следует один столбец для каждой группы:
has_noun%>%
str_match (имя существительное)
#> [, 1] [, 2] [, 3]
#> [1,] "гладкий" "" "гладкий"
#> [2,] "лист" "" "лист"
#> [3,] "глубина" "" "глубина"
#> [4,] "курица" "a" "курица"
#> [5,] "припаркованный" "" "припаркованный"
#> [6,] "солнце" "" "солнце"
#> [7,] "огромный" "" "огромный"
#> [8,] "мяч" "" "мяч"
#> [9,] "женщина" "" женщина "
#> [10,] «а помогает» «а» «помогает» (Неудивительно, что наша эвристика для определения существительных оставляет желать лучшего, и мы также подбираем такие прилагательные, как гладкий и припаркованный.] +) ",
remove = FALSE
)
#> # Таблица: 720 x 3
#> предложение статья существительное
#> Как и Найдите все слова, которые идут после «числа», например «один», «два», «три» и т. Д.
Вытяните и число, и слово. Найдите все схватки.Разделите части до и после
апостроф. С помощью Вместо замены фиксированной строкой вы можете использовать обратные ссылки для вставки компонентов соответствия.] +) "," \\ 1 \\ 3 \\ 2 ")%>%
голова (5)
#> [1] «Каноэ-береза скользила по гладким доскам».
#> [2] "Приклейте лист к темно-синему фону".
#> [3] «Глубину колодца легко определить».
#> [4] «В наши дни куриная ножка - редкое блюдо».
#> [5] «Рис часто подают в круглых мисках». Заменить все косые черты в строке обратными. Реализуйте простую версию Поменять местами первую и последнюю буквы в Используйте Поскольку каждый компонент может содержать разное количество частей, возвращается список. Если вы работаете с вектором длины 1, проще всего просто извлечь первый элемент списка: В противном случае, как и другие строковые функции, возвращающие список, вы можете использовать Вы также можете запросить максимальное количество штук: Вместо того, чтобы разделять строки по шаблонам, вы также можете разделить их по символам, строкам, предложениям и словам. Разделите строку Почему лучше разбить по границе Что делает разделение с пустой строкой ( SQL имеет несколько встроенных функций для управления строковыми данными в полях.
Некоторые из наиболее распространенных: Полный список строковых функций см. В справочном разделе. Итоговая таблица выглядит так: Для удобства SQL также поддерживает объединение строк с помощью конкатенации
оператор Строковая функция и мы вернемся: Подобно , и возвращенные результаты будут выглядеть так: Функция Функция Для функции Строка представляет собой последовательность из одного или нескольких символов (букв, цифр, символов), которые могут быть константами. или переменная. Строки, состоящие из Unicode, являются неизменяемыми последовательностями, то есть неизменными. Поскольку текст - это очень распространенная форма данных, которую мы используем в повседневной жизни, строковый тип данных является очень важным строительным блоком программирования. Это руководство по Python расскажет, как создавать и печатать строки, как объединять и реплицировать строки и как хранить строки в переменных. Строки существуют либо в одинарных кавычках Вы можете использовать одинарные или двойные кавычки, но, что бы вы ни выбрали, вы должны быть последовательными в программе. Мы можем распечатать строки, просто вызвав функцию Разобравшись, как форматируются строки в Python, давайте посмотрим, как мы можем работать со строками и манипулировать ими в программах. Конкатенация означает сквозное соединение строк для создания новой строки. Для объединения строк мы используем оператор Давайте объединим строки Если нам нужен пробел между двумя строками, мы можем просто включить пробел в строку, например, после слова «Сэмми»: Не используйте оператор Мы получим следующую ошибку: Если бы мы хотели создать строку Когда мы объединяем две или более строк посредством конкатенации, мы создаем новую строку, которую можем использовать в нашей программе. Бывают случаи, когда вам нужно использовать Python для автоматизации задач, и один из способов сделать это - повторить строку несколько раз. Сделать это можно с помощью оператора Давайте распечатаем «Сэмми» 9 раз, не набирая «Сэмми» 9 раз с помощью оператора При репликации строки мы можем повторять одиночное строковое значение количество раз, эквивалентное целочисленному значению. Переменные - это символы, которые можно использовать для хранения данных в программе. Вы можете думать о них как о пустом поле, которое вы заполняете некоторыми данными или значениями. Строки - это данные, поэтому мы можем использовать их для заполнения переменной. Объявление строк как переменных может облегчить нам работу со строками в наших программах Python. Чтобы сохранить строку внутри переменной, нам просто нужно присвоить переменную строке. В этом случае давайте объявим Теперь, когда у нас есть переменная И мы получим следующий результат: Используя переменные вместо строк, нам не нужно повторно вводить строку каждый раз, когда мы хотим ее использовать, что упрощает нам работу со строками и манипулирование ими в наших программах. В этом руководстве были рассмотрены основы работы со строковым типом данных в языке программирования Python 3. Создание и печать строк, объединение и репликация строк и хранение строк в переменных предоставят вам основы для использования строк в ваших программах на Python 3. Чтобы продолжить изучение строк, ознакомьтесь со следующими руководствами: - Как форматировать текст в Python 3 - Введение в строковые функции - Как индексировать и нарезать строки - Как использовать средства форматирования строк Строки - один из наиболее часто используемых типов данных в Python.При программировании на Python чрезвычайно важно знать, как работать со строками и преобразовывать их в желаемую форму. В этом руководстве вы узнаете о различных функциях и методах, которые могут быть вызваны для строки, и о том, что именно они делают. В частности, это то, что вы узнаете к концу этого руководства. Давайте сразу перейдем к этому. Доступ к символам в строке можно получить с помощью индексации, при которой символ рассматривается как элемент строки. Например, в строке «Python» символы P, y, t, h, o и n являются элементами строки, и к ним можно получить доступ путем индексации. Если вы не понимаете разницу между индексированием и нарезкой, индексация включает получение только одного элемента в списке, т.е.е персонаж. С другой стороны, нарезка предполагает одновременный доступ к более чем одному элементу, то есть к подстроке. Интерпретаторы Python индексируют от 0 до количества элементов в строке. Итак, для строки «Python» каждый элемент / символ будет иметь следующий индекс. Давайте рассмотрим несколько примеров. В Python соединение строки с другой строкой называется конкатенацией.Например, если была строка «h3k» и другая строка «Infosys», их можно объединить в h3KInfosys. Итак, вопрос в том, как это сделать? Объединение выполняется с помощью оператора +. Давайте перейдем к нашей IDE и посмотрим, как это делается. Если вы хотите добавить пробел между обеими строками, вы можете добавить строку, заполненную пробелами.См. Пример ниже. Могут возникнуть ситуации, когда вам нужно заменить строку другой строкой. Для этой операции используется метод replace (). Допустим, у нас есть строка: «Я собираюсь работать». Если мы хотим изменить его на «Я прихожу с работы», мы можем использовать функцию замены, как показано в примере ниже. .upper () и .lower () используются для замены строки на прописные и строчные буквы соответственно. Давайте посмотрим на несколько примеров. Допустим, мы хотим перевести строку в верхний регистр. Точно так же мы можем изменить строчную строку на прописную с помощью метода .lower (). Метод соединения используется для вставки разделителя строк в другую строку. Это приложение в ситуации, когда вы хотите добавить некоторый разделитель к повторяемому объекту, например строке или списку. Ниже приведена строка документации для метода соединения. Давайте посмотрим, как использовать метод соединения. Как видно, разделитель добавляется к каждому символу строки. Поскольку список также является итерируемым, вы можете вызвать метод соединения для списка. Python позволяет вам изменить расположение строки с помощью метода reversed (). Важно отметить, что метод reversed () возвращает объект. Чтобы напечатать перевернутую строку, вам нужно будет соединить перевернутый объект с пустым разделителем строк.Давайте посмотрим на пример. Вы можете разделить строку на основе вхождения символа в эту строку, используя метод split (). Например, строковые данные могут быть в форме 22.01.2021, вы можете получить день, месяц и год, разделив их косой чертой (/).Метод split () возвращает список разделенных строк. Это может пригодиться при предварительной обработке текстовых данных. Если у вас есть функция, и вы хотите разбить корпус на список предложений, вы можете легко разделить его точкой. См. Пример ниже. Вы можете просмотреть список, чтобы получить более привлекательный результат.Для этого воспользуемся списком. Вы узнали, как играть со строками в Python.Вы узнали, как получить доступ к символам и подстрокам строки с помощью индексации и нарезки. Кроме того, мы обсудили, как заменить строку, перевернуть строку, преобразовать символы строки в нижний и верхний регистры, присоединить разделители к итератору и разделить строку по символу. Если у вас есть какие-либо вопросы, не стесняйтесь оставлять их в разделе комментариев, и я постараюсь на них ответить. Сначала я сделаю разминку. Вероятно, вы применили встроенную функцию Строку также можно преобразовать в список с помощью конструктора Объединение двух строк работает так же, как и обычное числовое сложение в математической функции. Точно так же вы можете получить копии строки, просто умножив столько раз! Как и все остальное, строки в Python являются объектами.Естественно, он поставляется со встроенными методами, которые вы можете обнаружить, нажав клавишу .tab после строки: Итак, что именно вы можете делать со строковыми методами? Некоторые основные функции включают преобразование строки в верхний или нижний регистр, использование заглавных букв и т. Д. Некоторые примеры приведены ниже: Помимо основных методов, вы также можете вызывать несколько очень полезных методов. Например, вы можете разделить строку (скажем, предложение), используя разделитель по вашему выбору (например, букву). Наиболее полезно разделить предложение на список отдельных слов с пробелом ( ' ') разделитель. Существует также способ разместить элементы строки в обратном порядке. Если вы обнаружите, что перевертывание строки не очень полезно для вашей работы, избавление от нежелательных элементов в строке обязательно является. Вы можете просто Также может пригодиться замена слов или символов. Используя метод Прежде чем закончить строковые методы, я просто хочу подчеркнуть, что если вы работаете с Python Следующей важной темой является подсчет - от подсчета символов до подсчета слов и т. Д. Встроенный метод подсчета - Python также поставляется с модулем С дополнительным Строка кода, Рекомендуется удалить любые знаки препинания в строке, иначе это может создать некоторые проблемы в строке. Ассоциированный Доступ к отдельным элементам по индексу или доступ индекс по пунктам весьма полезен. Для доступа к индексу символа / слова: Или для доступа к символу / слову по индексу: Нарезка строки работает так же, как и для объектов списка. В Python можно форматировать строку несколькими способами. До Python 3.6 большинство людей использовали бы% -formatting или Для числовых переменных вы можете указать точность значений в формате -> значение: ширина.точность регулярное выражение Если вы хотите найти соответствующий шаблон текста: В выходных данных span указывает позицию индекса совпадения (начиная с индекса 6 и заканчивая 8 в этом примере). Вы также можете искать числовые шаблоны в определенном формате, который, по вашему мнению, наиболее вероятен. И, наконец, есть так называемый «подстановочный знак», представленный расширением.(точка) метасимвол. Подводя итог всему, что я представил в этой статье: Я оставил много других методов и функций, но я надеюсь, что это станет хорошим началом для создания шпаргалки для работы со строковыми объектами. Если у вас есть комментарии, напишите их ниже или свяжитесь со мной через Medium, Twitter или LinkedIn. Python имеет встроенный строковый класс с именем «str» со многими удобными функциями (есть более старый модуль с именем «string», который вам не следует использовать).Строковые литералы могут быть заключены в двойные или одинарные кавычки, хотя чаще используются одинарные кавычки. Экраны с обратной косой чертой работают обычным образом в литералах с одинарными и двойными кавычками - например, \ n \ '\ ". Строковый литерал в двойных кавычках может содержать одинарные кавычки без всякой суеты (например,« Я этого не делал »), а аналогичная строка в одинарных кавычках может содержать двойные кавычки. Строковый литерал может занимать несколько строк, но есть должен быть обратной косой чертой \ в конце каждой строки, чтобы избежать новой строки. Строковые литералы в тройных кавычках, "" "или '' ', могут охватывать несколько строк текста. Строки Python являются «неизменяемыми», что означает, что они не могут быть изменены после создания (строки Java также используют этот неизменяемый стиль). Поскольку строки не могут быть изменены, мы создаем * новые * строки по мере представления вычисленных значений. Так, например, выражение ('hello' + 'there') принимает две строки hello и there и строит новую строку hellothere. Доступ к символам в строке можно получить с помощью стандартного синтаксиса [], и, подобно Java и C ++, Python использует индексирование с отсчетом от нуля, поэтому, если s равно 'hello' s [1] равно 'e'.Если индекс выходит за пределы строки, Python выдает ошибку. Стиль Python (в отличие от Perl) заключается в том, чтобы остановиться, если он не может сказать, что делать, а не просто создать значение по умолчанию. Удобный синтаксис «среза» (см. Ниже) также позволяет извлекать любую подстроку из строки. Функция len (строка) возвращает длину строки. Синтаксис [] и функция len () на самом деле работают с любым типом последовательности - строками, списками и т. Д. Python пытается заставить свои операции работать согласованно для разных типов.Новичок в Python: не используйте «len» в качестве имени переменной, чтобы не блокировать функцию len (). Оператор '+' может объединять две строки. Обратите внимание на то, что в приведенном ниже коде переменные не объявлены заранее - просто назначьте их и приступайте. В отличие от Java, знак «+» не преобразует автоматически числа или другие типы в строковую форму. Функция str () преобразует значения в строковую форму, чтобы их можно было комбинировать с другими строками. Для чисел стандартные операторы +, /, * работают как обычно. Оператора ++ нет, но работают + =, - = и т.д. Если вы хотите целочисленное деление, правильнее всего использовать две косые черты - например, 6 // 5 равно 1 (до python 3 единичное / делает деление int с int в любом случае, но движение вперед // является предпочтительным способом указать, что вы хотите деление int.) Оператор print выводит на печать один или несколько элементов Python, за которыми следует новая строка (оставьте запятую в конце элементов, чтобы запретить перевод строки). "Необработанный" строковый литерал имеет префикс 'r' и пропускает все символы без специальной обработки обратных косых черт, поэтому r'x \ nx 'оценивается как строка длины 4' x \ nx '. Префикс 'u' позволяет вам писать строковый литерал Unicode (Python имеет множество других функций поддержки Unicode - см. Документацию ниже). Вот некоторые из наиболее распространенных строковых методов. Метод похож на функцию, но он запускается «на» объекте. Если переменная s является строкой, то код s.lower () запускает метод lower () для этого строкового объекта и возвращает результат (эта идея метода, работающего на объекте, является одной из основных идей, составляющих Object Ориентированное программирование, ООП).Вот некоторые из наиболее распространенных строковых методов: Поиск в Google по запросу "python str" должен привести вас к официальным строковым методам python.org, в которых перечислены все методы str. Python не имеет отдельного символьного типа. Вместо этого выражение типа s [8] возвращает строку длиной 1, содержащую символ.С этой строкой-1 операторы ==, Синтаксис «slice» - удобный способ ссылаться на части последовательностей - обычно строки и списки. Срез s [начало: конец] - это элементы, начинающиеся с начала и продолжающиеся до конца, но не включая его. Предположим, у нас есть s = "Hello" Стандартные отсчитываемые от нуля порядковые номера обеспечивают легкий доступ к символам в начале строки.В качестве альтернативы Python использует отрицательные числа для облегчения доступа к символам в конце строки: s [-1] - последний символ 'o', s [-2] - 'l' предпоследний char и так далее. Отрицательные номера индекса отсчитываются от конца строки: Это чистый трюизм срезов, что для любого индекса n Python имеет похожее на printf () средство для объединения строк. Оператор% принимает строку формата типа printf слева (% d int,% s строка,% f /% g с плавающей запятой) и соответствующие значения в кортеже справа (кортеж состоит из значений, разделенных символом запятые, обычно сгруппированные в круглых скобках): Вышеупомянутая строка довольно длинная - предположим, вы хотите разбить ее на отдельные строки. Вы не можете просто разделить строку после символа «%», как в других языках, поскольку по умолчанию Python обрабатывает каждую строку как отдельный оператор (с положительной стороны, вот почему нам не нужно вводить точки с запятой для каждого линия). Чтобы исправить это, заключите все выражение в круглые скобки - тогда выражение может занимать несколько строк. Этот метод сквозного кода работает с различными конструкциями группирования, подробно описанными ниже: (), [], {}. Так и лучше, но очередь все равно длинновата. Python позволяет разрезать строку на части, которые затем автоматически объединяются. Итак, чтобы сделать эту строку еще короче, мы можем сделать это: Обычные строки Python * не * unicode, это просто байты. Чтобы создать строку Unicode, используйте префикс u в строковом литерале: Строка Юникода - это объект другого типа, чем обычная строка "str", но строка Юникода совместима (они используют общий суперкласс "basestring"), и различные библиотеки, такие как регулярные выражения, работают правильно, если вместо этого передается строка Юникода. обычной строки. Чтобы преобразовать строку Unicode в байты с кодировкой, такой как 'utf-8', вызовите метод ustring.encode ('utf-8') для строки Unicode. В другом направлении функция unicode (s, encoding) преобразует закодированные простые байты в строку Unicode: Правда Встроенная функция печати не полностью работает со строками Unicode.Вы можете сначала encode () печатать в utf-8 или что-то еще. В разделе чтения файлов есть пример, который показывает, как открыть текстовый файл с некоторой кодировкой и прочитать строки Unicode. Обратите внимание, что обработка Unicode - это одна из областей, где Python 3 значительно очищен по сравнению с поведением Python 2.x, описанным здесь. Python не использует {} для включения блоков кода для if / loops / function и т. Д. Вместо этого Python использует двоеточие (:) и отступы / пробелы для группировки операторов.Логический тест для if не обязательно должен быть в скобках (большое отличие от C ++ / Java), и он может иметь предложения * elif * и * else * (мнемоника: слово «elif» имеет ту же длину, что и слово « еще"). Любое значение может использоваться как if-test. Все «нулевые» значения считаются ложными: нет, 0, пустая строка, пустой список, пустой словарь. Существует также логический тип с двумя значениями: True и False (преобразованный в int, это 1 и 0). Python имеет обычные операции сравнения: ==,! =, <, <=,>,> =.В отличие от Java и C, == перегружен для правильной работы со строками. Логические операторы - это прописанные слова * и *, * или *, * not * (Python не использует C-стиль && ||!). Вот как может выглядеть код для полицейского, тянущего спидер - обратите внимание, как каждый блок операторов then / else начинается с:, а операторы сгруппированы по их отступам: Я считаю, что пропуск ":" является моей самой распространенной синтаксической ошибкой при вводе кода вышеупомянутого типа, вероятно, потому, что это дополнительная вещь, которую нужно набирать по сравнению с моими привычками к C ++ / Java. Кроме того, не помещайте логический тест в скобки - это привычка C / Java. Если код короткий, вы можете поместить его в ту же строку после ":", как это (это относится к функциям, циклам и т. Д.также), хотя некоторые люди считают, что удобнее размещать элементы в отдельных строках. Чтобы попрактиковаться в материале этого раздела, попробуйте упражнение string1.py в Базовых упражнениях. В терминологии программирования строка означает просто последовательность или массив символов.Отдельный символ - это буквенно-цифровое значение. Еще в те дни, когда был изобретен C, символ в компьютере был представлен 7-битным кодом ASCII. Таким образом, строка представляет собой набор из множества 7-битных символов ASCII. Однако по мере роста использования компьютеров во всем мире 7-битная схема ASCII стала недостаточной для поддержки символов других языков. Поэтому были предложены различные модели кодировки символов, такие как Unicode, UTF-8, UTF-16, UTF-32 и т. Д. Часто задаваемые вопросы по Unicode - интересное место для получения более подробной информации по ним. Различные языки программирования имеют свою собственную схему кодировки символов. Например, Java изначально использует UTF-16 для сопоставления последовательностей шестнадцатиразрядных кодовых единиц UTF-16 и последовательностей байтов. Go, с другой стороны, использует UTF-8. Оба они представляют собой многобайтовые кодировки символов. UTF-8 был первоначально разработан Робом Пайком и Кеном Томпсоном, теми же людьми, которые разработали Go. Строки Go значительно отличаются от строк C и не работают на том же низком уровне, что и C. Фактически, строки Go работают на гораздо более высоком уровне.В отличие от C / C ++ и Java или Python, где строки представляют собой постоянные типы последовательностей символов фиксированной длины, строки Go имеют переменную ширину, где каждый символ представлен одним или несколькими байтами в соответствии со схемой кодирования UTF-8. Хотя они ведут себя как массив или фрагмент байтов, на самом деле они представляют собой отдельный тип со своим собственным набором уникального поведения. Здесь мы обсудим несколько моментов, касающихся типа строки и манипулирования ею в Go. Golang имеет встроенную функцию len , которая возвращает длину строки или длину строки в байтах.Согласно схеме массива мы можем получить доступ к i-му байту , где 0 <= i <= len (theString). Обратите внимание на следующий фрагмент кода: Следующий код вызовет панику, потому что мы пытаемся получить доступ к индексу за пределами границ: Вместо этого мы хотели бы написать приведенный выше код следующим образом: Существует сокращение для извлечения подстроки в Go. Например, мы могли бы написать: , чтобы получить новую строку, состоящую из байтов исходной строки, начиная с индекса i и заканчивая индексом j-1 . Строка будет содержать j-i байтов. Следующий результат дает тот же результат, потому что мы можем опустить значения i и j , которые Go принимает по умолчанию 0 и len (theString) соответственно. Для извлечения подстроки мы можем написать следующий код: Неизменяемые характеристики строк Go гарантируют, что строковое значение никогда не может быть изменено, хотя мы можем присвоить новое значение - или объединить новое значение - без изменения исходного значения.Например: Но если мы попытаемся изменить исходное строковое значение, это помечает ошибку времени компиляции, потому что это нарушает неизменные ограничения строк Go: Нам, как разработчикам, часто приходится сравнивать две строки, а Go поддерживает все распространенные операторы сравнения, включая == , ! = , <, > , <= и > = .Сравнение выполняется побайтово и следует естественному лексическому порядку в процессе сравнения. Вот быстрый пример того, как сравнить две строки в Go: Работа с пакетом strconv в Go При работе со строками нам часто требуется преобразовать строковый тип в числовое значение. Пакет strconv содержит множество функций, которые преобразуют строковое значение для представления многих основных типов данных Go. Например, целочисленное значение может быть преобразовано из строкового представления следующим образом: Функция strconv.ParseInt принимает три параметра: анализируемое строковое значение, базовый тип и размер в битах. Аналогичные функции существуют для других базовых типов, таких как ParseFloat , ParseBool , ParseUint и ParseComplex для значений с плавающей запятой, логических, целых чисел без знака и комплексных значений соответственно. Мы также можем преобразовать обратно в числовое значение в строку в Go, как показано в следующем примере кода: Функции преобразования, предоставляемые strconv , более универсальны, чем аналогичные функции, такие как FormalBool , FormatInt , FormatUint и FormatComplex . Кроме того, быстрый способ преобразовать значение с плавающей запятой в строку в Go - использовать пакет fmt , как показано в этом примере кода: Пакет strconv содержит множество функций преобразования, которые работают со строковыми значениями. Ознакомьтесь с документацией Go strconv для получения более подробной информации Пакет strings - еще один служебный пакет для работы со строками. Например, здесь у нас есть строка, содержащая дни недели как данные, где каждый день недели разделен запятой (,). Мы можем проанализировать строку и извлечь каждый будний день, используя строк.Разделить функцию следующим образом: Таких служебных функций множество. Например, чтобы преобразовать строку в прописные или строчные буквы, мы можем использовать функцию strings.ToUpper (str) или strings.ToLower (str) соответственно. Существуют такие функции, как Trim , которые возвращают фрагмент строки с удаленными начальными и конечными кодовыми точками Unicode в наборах вырезок.Дополнительную информацию см. В документации по строкам Go. Пакет unicode / utf8 содержит множество функций для запроса и управления строкой и байтами UTF-8. Он предоставляет функции для перевода между рунами и последовательностями байтов UTF-8. Например, utf8.DecodeRuneInString () и utf8.DecodeLastRuneInString () возвращают первый и последний символы в строке. Вот быстрый пример: Дополнительные сведения см. В документации Go utf8. Go предоставляет обширную поддержку для управления строками. Существуют и другие пакеты, такие как unicode , которые предоставляют функции для запроса кодовых точек Unicode, чтобы определить, соответствуют ли они определенным критериям. Пакет regexp предоставляет функции для управления строками с помощью регулярных выражений.Одна из важных вещей, которую следует понять в отношении строки Go, заключается в том, что то, что мы вольно называем отдельные элементы строки символом, на самом деле является последовательностью байтов UTF-8, называемых кодовыми точками, обычно представленных словом руна, которое является псевдонимом для типа int32 . Пакеты Go изобилуют функциями манипулирования строками, здесь мы лишь коснулись поверхности. Следите за обновлениями, мы узнаем больше. Хотите узнать о других функциях Go? Ознакомьтесь с нашей статьей об отражении в Go. str_extract () , если вам нужны все совпадения для каждой строки, вам понадобится str_match_all () . Упражнения
Замена спичек
str_replace () и str_replace_all () позволяют заменять совпадения новыми строками. Самый простой способ - заменить шаблон фиксированной строкой:
x <- c («яблоко», «груша», «банан»)
str_replace (x, «[aeiou]», «-»)
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all (x, «[aeiou]», «-»)
#> [1] "-ppl-" "p - r" "b-n-n-" str_replace_all () вы можете выполнить несколько замен, указав именованный вектор:
x <- c («1 дом», «2 машины», «3 человека»)
str_replace_all (x, c ("1" = "один", "2" = "два", "3" = "три"))
#> [1] "один дом" "две машины" "три человека" Упражнения
str_to_lower () с помощью replace_all () . словах . Какая из этих струн
еще слова? Раскол
str_split () , чтобы разделить строку на части. Например, мы можем разбить предложения на слова:
предложений%>%
голова (5)%>%
str_split ("")
#> [[1]]
#> [1] "" березовая "каноэ" скользнула "" по "" "гладью"
#> [8] "доски".
#>
#> [[2]]
#> [1] "Приклейте" "" лист "" к "" "
#> [6] "темный" "синий" "фон."
#>
#> [[3]]
#> [1] «Легко» «сказать» «о« глубине »» «колодца».
#>
#> [[4]]
#> [1] "В эти" "дни" "" "курица" "нога" "" "" а "
#> [8] «редкое» «блюдо».
#>
#> [[5]]
#> [1] "Рис" "часто" подается "в" круглых "мисках."
"a | b | c | d"%>%
str_split ("\\ |")%>%
.[[1]]
#> [1] "a" "b" "c" "d" simpleify = TRUE для возврата матрицы:
предложений%>%
голова (5)%>%
str_split ("", simpleify = ИСТИНА)
#> [, 1] [, 2] [, 3] [, 4] [, 5] [, 6] [, 7] [, 8]
#> [1,] "" березовое "каноэ" скользило "" по "" гладким "доскам".
#> [2,] "Приклейте" "" лист "" к "" "" темному "" синему "" фону."
#> [3,] "" легко "" "сказать" "" глубину "" "" а "
#> [4,] "В эти" "дни" "" "курица" "нога" "" "а" "редко"
#> [5,] "Рис" "часто" подается "в" круглых "мисках." ""
#> [, 9]
#> [1,] ""
#> [2,] ""
#> [3,] "хорошо".
#> [4,] "блюдо".
#> [5,] ""
полей <- c ("Имя: Хэдли", "Страна: Новая Зеландия", "Возраст: 35")
поля%>% str_split (":", n = 2, simpleify = TRUE)
#> [, 1] [, 2]
#> [1,] "Имя" "Хэдли"
#> [2,] "Country" "NZ"
#> [3,] "Возраст" "35" border () s:
x <- "Это приговор.Это еще одно предложение ».
str_view_all (x, граница ("слово"))
str_split (x, "") [[1]]
#> [1] «Это» «есть» «предложение». "" "Этот"
#> [7] "это" еще одно "предложение".
str_split (x, граница ("слово")) [[1]]
#> [1] "This" "is" "" предложение "" This "" is "" другое "
#> [8] "предложение" Упражнения
"яблоки, груши и бананы" на отдельные
компоненты. ("слово") , чем "" ? "" )? Экспериментируйте и
затем прочтите документацию. Найти совпадения
str_locate () и str_locate_all () дают вам начальную и конечную позиции каждого совпадения. Это особенно полезно, когда ни одна из других функций не делает именно то, что вы хотите.Вы можете использовать str_locate (), , чтобы найти соответствующий шаблон, str_sub (), , чтобы извлечь и / или изменить их. Работа со струнами | Учебное пособие по SQL на data.world
CONCAT , LEFT , LOWER , UPPER , ПОДСТАВКА , STRING_SPLIT и ДЛИНА . КОНКАТ CONCAT принимает два или более строковых значения и объединяет их в одно значение.
Эти значения могут быть определены в запросе или выбраны из таблицы. в
В следующем примере запрос объединяет имя менеджера, разделительный пробел
(значение, указанное в запросе) и имя продавца:
SELECT CONCAT (менеджер, ",", sales_agent)
ОТ sales_teams concat Дастин Бринкманн, Анна Снеллинг Дастин Бринкманн, Сесили Лампкин Мелвин Марксен, Мей-Мей Джонс Cara Losch, Violet Mclelland Кара Лош, Корлисс Косме Кара Лош, Рози Пападопулос Кара Лош, Garret Kinder Кара Лош, Уилберн Фаррен Кара Лош, Элизабет Андерсон Рокко Нойберт, Даниэль Хэммак Рокко Нойберт, Кэсси Кресс || .Используя оператор конкатенации, предыдущий запрос может быть
написано так:
SELECT менеджер || "," || агент по продажам
ОТ sales_teams ЛЕВАЯ LEFT возвращает указанное количество
крайние левые символы значения. Если бы мы хотели использовать однобуквенный идентификатор
для каждого регионального офиса для агентов по продажам мы могли бы запустить запрос типа
это:
SELECT sales_agent,
ВЛЕВО (региональный_офис; 1)
ОТ sales_teams sales_agent осталось Анна Снеллинг С Сесили Лампкин С Мей-Мей Джонс С Вайолет Маклланд E Корлисс Cosme E Рози Пападопулос E Garret Kinder E Уилберн Фаррен E Элизабет Андерсон E Дэниэл Хэммак E Кэсси Кресс E Донн Кантрелл E Versie Hillebrand С НИЖНИЙ LOWER - полезная строковая функция для очистки представления данных в виде
он преобразует все символы в значении в нижний регистр.Например, мы могли бы
измените все названия продуктов на нижний регистр в следующем запросе:
ВЫБРАТЬ НИЖНИЙ (продукт)
ИЗ ПРОДУКТА нижний gtx базовый gtx pro мг специальный мг продвинутый gtx plus pro gtx plus базовый GTK 500 мг моно альфа ВЕРХНИЙ LOWER , UPPER возвращает все символы в строке как верхние
кейс.Если нам нужен список сотрудников в верхнем регистре, мы могли бы запустить
запрос:
ВЫБРАТЬ ВЕРХНИЙ (торговый_агент)
ОТ sales_teams верх АННА СНЕЛЛИНГ СЕСИЛИ ЛАМПКИН MEI-MEI JOHNS VIOLET MCLELLAND CORLISS COSME РОЗИ ПАПАДОПУЛОС GARRET KINDER УИЛБЕРН ФАРРЕН ЭЛИЗАБЕТ АНДЕРСОН ПОДСТАВКА SUBSTRING - это функция, которая используется для возврата
часть строки, основанная на ее размещении в строке.Например, если мы
рассматривали данные только по линейке продуктов GTX, и мы хотели удалить
Префикс GTX из результатов нашего запроса мы могли бы использовать следующий запрос:
ВЫБРАТЬ ТРУБУ (продукт, 5),
цена для продажи
ИЗ продуктов
ГДЕ продукт КАК "GTX%" подстрока sales_price Базовый 550 Pro 4 821 Plus Pro 5,482 Plus Basic 1,096 SUBSTRING требует двух аргументов и может принимать
треть.Первый аргумент - это строка, которую нужно найти, и ее можно указать
либо как строка, либо как столбец. Второй аргумент - это размещение в
строка первого возвращаемого символа. Третий (необязательный) аргумент:
количество возвращаемых символов. Если третий аргумент опущен,
запрос возвращает всю строку от первого возвращенного символа до конца
Струна. ДЛИНА ДЛИНА возвращает количество символов в
строка.Это может показаться странным, но это полезно, когда
вы хотите удалить символы из начала строки, оставив
указанное количество символов с конца. В нашем наборе данных нет
особенно хорошая строка, в которой эта операция имела бы смысл, но как
Например, мы можем запустить запрос, чтобы вернуть только последние пять букв каждой продажи
имя агента и оно будет выглядеть так:
SELECT sales_agent,
SUBSTRING (sales_agent, LENGTH (sales_agent) -5)
ОТ sales_teams sales_agent подстрока Анна Снеллинг эллинг Сесили Лампкин ampkin Мей-Мей Джонс Джонс Вайолет Маклланд элланд Корлисс Cosme Cosme Рози Пападопулос пулос Garret Kinder Киндер Уилберн Фаррен Фаррен Элизабет Андерсон derson Дэниэл Хэммак патрон Кэсси Кресс Кресс Донн Кантрелл ntrell STRING_SPLIT STRING_SPLIT - это функция, которая используется для разделения строки на несколько
строки, основанные на некотором разделителе.В отличие от других функций, STRING_SPLIT возвращает несколько строк для каждого ввода строки. Например, если вы искали
чтобы получить имя и фамилию ваших торговых агентов в одном столбце, вы
могут разделить свои имена, используя пробел в качестве разделителя:
SELECT sales_agent,
STRING_SPLIT (торговый_агент, "")
ОТ sales_teams sales_agent подстрока Анна Снеллинг Анна Анна Снеллинг Снеллинг Сесили Лампкин Сесили Сесили Лампкин Лампкин Мей-Мей Джонс Мэй-Мэй Мей-Мей Джонс Джонс STRING_SPLIT требуется два аргумента.Первый аргумент - это
строка, которую нужно разделить, и она может быть указана как строка или как столбец.
Второй аргумент - это символ-разделитель, используемый для разделения строки. «Введение в работу со строками» в «Как кодировать на Python 3» на стипендии Manifold Scholarship в CUNY
Создание и печать строк
', либо в двойных кавычках " в Python, поэтому для создания строки заключите последовательность символов в один или другой:
' Это строка в одинарных кавычках.'
«Это строка в двойных кавычках». print () :
Выход print («Давайте распечатаем эту строку.»)
Распечатаем эту строку. Конкатенация строк
+ . Имейте в виду, что когда мы работаем с числами, + будет оператором сложения, но при использовании со строками это оператор соединения. "Sammy" и "Shark" вместе с помощью конкатенации посредством оператора print () :
Выход print ("Sammy" + "Shark")
SammyShark
Выход print («Sammy» + «Shark»)
Sammy Shark + между двумя разными типами данных.Например, мы не можем объединить строки и целые числа вместе. Итак, если мы попытаемся написать:
print ("Sammy" + 27)
TypeError: Невозможно неявно преобразовать объект int в str «Sammy27» , мы могли бы сделать это, заключив число 27 в кавычки ( «27» ), так что это уже не целое число, а строка. Преобразование чисел в строки для объединения может быть полезно при работе с почтовыми индексами или номерами телефонов, например, поскольку мы не хотим выполнять сложение между кодом страны и кодом города, но мы хотим, чтобы они оставались вместе. Репликация строки
* . Как и оператор + , оператор * имеет другое использование при использовании с числами, где он является оператором умножения.При использовании с одной строкой и одним целым числом * является оператором репликации строки , повторяющим одну строку сколько угодно раз через указанное вами целое число. * :
Выход print («Сэмми» * 9)
SammySammySammySammySammySammySammySammySammy Сохранение строк в переменных
my_str как нашу переменную:
my_str = "Сэмми любит объявлять строки." my_str , установленная для этой конкретной строки, мы можем напечатать переменную следующим образом:
print (my_str)
Сэмми любит объявлять строки. Заключение
Работа со строками в Python : Заменить, объединить, разделить, прописные и строчные буквы
Доступ к подстрокам через индексацию и нарезку
# определить строку
строка = 'Python'
# доступ к элементам через индексацию
print ('ПРИМЕРЫ-УКАЗАТЕЛИ')
print ('строка [0]:', строка [0])
print ('строка [2]:', строка [2])
print ('строка [4]:', строка [4])
Распечатать()
print ('ПРИМЕРЫ РАЗРЕЗЫВАНИЯ')
# доступ к подстрокам через нарезку
print ('строка [0: 3]:', строка [0: 3])
print ('строка [2: 4]:', строка [2: 4])
print ('строка [1: 2]:', строка [1: 2])
Выход:
ПРИМЕРЫ ИНДЕКСА
строка [0]: P
строка [2]: t
строка [4]: o
ПРИМЕРЫ НАРЕЗКИ
строка [0: 3]: Pyt
строка [2: 4]: th
строка [1: 2]: y
Конкатенация строк
# определить две строки
строка1 = 'h3k'
строка2 = 'Infosys'
# объединить обе строки
print ('строка1 + строка2:', строка1 + строка2)
Выход:
строка1 + строка2: h3kInfosys
# объединить обе строки
print ('строка1 + строка2:', строка1 + '' + строка2)
Выход:
строка1 + строка2: h3kInfosys
Замена строки другой строкой
# определить строку
first_string = 'Я иду на работу'
# сделать замену
second_string = first_string.replace ('идёт к', 'идёт от')
печать (вторая_строка)
Выход:
Я иду с работы
Замена прописных букв на строчные и наоборот
# определить строку
string = 'Изучите Python в h3k Infosys'
# изменить на верхний регистр
печать (строка.upper ())
Выход:
УЗНАЙТЕ PYTHON В h3K INFOSYS
# определить строку
string = 'УЗНАТЬ PYTHON В h3K INFOSYS'
# изменить на верхний регистр
печать (string.lower ())
Выход:
изучить Python на h3k infosys
Общие сведения о методе соединения.
Подпись: string.join (итерация, /)
Строка документации:
Объедините любое количество строк.
Строка, метод которой вызывается, вставляется между каждой данной строкой.
Результат возвращается в виде новой строки.
# определить строку
строка = 'h3kInfosys'
# соединить каждый символ строки дефисом
connected_string = '-'. join (строка)
печать (объединенная_строка)
Выход:
H-2-k- -I-n-f-o-s-y-s
# создать список
list_1 = ['Сбор данных', 'Предварительная обработка', 'Построение модели', 'Оценка модели', 'Развертывание модели']
# присоединить к каждому элементу списка >>>
connected_list = '>>>'.присоединиться (список_1)
печать (присоединенный_список)
Выход:
Сбор данных >>> Предварительная обработка >>> Построение модели >>> Оценка модели >>> Развертывание модели
Переворачивание строки
# определить строку
строка = 'h3kInfosys'
# перевернуть строку
string_reversed = '' .join (перевернутая (строка))
печать (обратная строка)
Выход:
sysofnI k2H
Разделение строки
строка = '22 / 02/2021 '
# разделить строку на /
строка_сплит = строка.сплит ('/')
печать (строка_сплит)
Выход:
['22', '02', '2021']
string = '' 'Джон ничего не знал о программировании.
Однако он хотел изучить Python.
Он обнаружил h3k Infosys в Twitter.
Следовательно, он читает их учебник и подписывается на курс.
Теперь Джон - гуру Python.
Он работает разработчиком в компании из списка Fortune 500.
'' '
# разделить строку на /
строка_сплит = строка.сплит ('.')
печать (string_split)
Выход:
['Джон ничего не знал о программировании', '\ n Однако он хотел изучить Python', '\ n Он обнаружил h3k Infosys на
Twitter ',' \ n Следовательно, он читает их учебник и подписывается на курс ',' \ n Теперь Джон - гуру Python ',' \ n
Он работает разработчиком в компании из списка Fortune 500 ',' \ n ']
# разделить строку на /
строка_сплит = строка.сплит ('.')
[print (x) вместо x в string_split]
Выход:
Джон ничего не знал о программировании
Однако он хотел изучить Python.
Он обнаружил h3k Infosys в Twitter
Следовательно, он читает их учебник и подписывается на курс.
Теперь Джон - гуру Python
Он работает разработчиком в компании из списка Fortune 500.
Итого
Работа со строками в Python: шпаргалка | Махбубул Алам
Разминка
len () для подсчета элементов в списке, наборе, кортеже или словаре. Вы можете использовать то же самое для проверки общей длины строки. len ('hello') >> 5 list () . list ('hello!') >> ['h', 'e', 'l', 'l', 'o', '!'] first_string = 'hello'
second_string = 'world'
new_string = first_string + second_string >> 'hello world' string = 'hello'
(string + '') * 5 >> 'hello hello hello hello' Строковые методы
# сделать верхний регистр
'hello'.upper ()
>>' HELLO '# сделать нижний регистр
' HELLO'.lower ()
>> 'hello' # заглавными буквами
'hello'.capitalize ()
>>' Hello '# title
' hello world '.title ()
>> 'Hello World' # разделить слово
'hello'.split (sep =' e ') >> [' h ',' llo '] sent = 'hello world'
sent.split (sep = '') >> ['hello', 'world'] # перевернуть строку
s = 'hello'
s [:: - 1] >> 'olleh' strip () избавиться от всего, от чего хотите избавиться от строки. # удалить часть строки
'hi there'. Strip ('hi') >> 'there' # заменить символ
'hello'.replace (' l ',' L ')
>>' heLLo '# заменить слово
' hello world '.replace ('world', 'WORLD')
>> 'hello WORLD' join () , вы можете объединить список символов или слов в более длинный строковый объект. # присоединяемся к списку букв
s = ['h', 'e', 'l', 'l', 'o']
'' .join (s) >> 'hello' # присоединяемся к списку words
w = ['hello', 'world'] '-'. join (w) >> 'hello-world' pandas библиотеки, вы найдете также полезными встроенные строковые методы.Если вы просто используете .str. для объекта pandas (то есть строк), вы можете получить доступ ко всем этим методам. Подсчет
.count () , который применяется к объекту, и вы указываете, что вы хотите считать в качестве аргумента. Просто помните, что он чувствителен к регистру. # counting characters
sent = 'Его зовут Абдул.Абдул - хороший мальчик. Boy o boy '
sent.count (' a ') >> 2 # подсчет появления слова
sent.count (' name ') >> 1 Counter с его коллекциями Библиотека . Он может подсчитывать частоту каждого элемента в строке и возвращает объект словаря. # подсчитать ВСЕ символы в строке
из импорта коллекций Counter
Counter ('aaaaabbbbbbxxxxxx') >> Counter ({'a': 5, 'b': 6, 'x': 6}) Счетчик также может разделять слова и отображать частоты слов. # подсчет ВСЕХ слов в предложении
sent = 'Его зовут Абдул. Абдул хороший мальчик, мальчик о мальчик '
word_lis = sent.split (' ')
Counter (word_list) >> Counter ({' His ': 1,
' name ': 1,
' is ': 2,
'Абдул.': 1,
'Абдул': 1,
'а': 1,
'хорошо': 1,
'мальчик,': 1,
'мальчик': 2,
'о': 1 }) .Метод most_common () возвращает кортежи элементов, встречающихся с наибольшей частотой. Счетчик (word_list) .most_common (3) >> [('is', 2), ('boy', 2), ('His', 1)] Доступ
'hello how are you.find (' how ') >> 6 s =' hi there '
s [3] >> 't' s = 'hi there'
s [0: 4] >> 'hi t' f-string
.format () , но f-строки значительно упростили задачу - легкость использования и легкость чтения. Вот один пример: name = 'Anna'
age = 23
print (f "меня зовут {name} и мне {age} лет") >> меня зовут Анна, мне 23 года # f строковые числа
Регулярное выражение
div = 11/3
print (f 'результат деления равен {div: 2.3f}') >> результат деления равен 3,667 re - очень мощная библиотека в Python, и вы можете многое сделать с ее помощью, особенно для поиска шаблонов в наборе данных. Ниже представлен небольшой пример его возможностей. import re
text = 'привет, мой номер телефона (000) -111-2222'
pattern = 'phone're.поиск (шаблон, текст) >> <объект re.Match; span = (9, 14), match = 'phone'> text = 'мой почтовый индекс 22202'
pattern = r '\ d \ d \ d \ d \ d'
re.search (pattern, text) >> # input text
text = 'собака и свинья сидели в тумане' # regex search
re.findall (r'.og ', text) >> [' dog ',' hog ',' fog '] .count ( ) или с помощью модуля Counter re модуль для поиска по шаблону. строк Python | Обучение Python | Разработчики Google
s = 'привет'
печать s [1] ## i
распечатать len (s) ## 2
напечатайте s + 'там' ## привет там
пи = 3,14
## text = 'Значение пи' + pi ## НЕТ, не работает
text = 'Значение пи' + str (pi) ## да
raw = r 'это \ t \ n и это'
# это \ t \ n и это
печать в сыром виде
multi = "" "Это были лучшие времена.Это было худшее из времен "" "
# Это были лучшие времена.
# Это были худшие времена.
печать мульти
Строковые методы
Ломтики струн
s [: n] + s [n:] == s . Это работает даже при отрицательном n или за пределами допустимого значения. Или, по-другому, s [: n] и s [n:] всегда разделяют строку на две части, сохраняя все символы. Как мы увидим позже в разделе списков, срезы тоже работают со списками. Строка%
#% оператор
text = "% d поросят вылезут, или я% s, я% s, и я взорву ваш% s."% (3, 'huff', 'puff', 'house')
# Добавьте круглые скобки, чтобы длинная строка работала:
текст = (
«Вылезут% d поросят, или я% s, я% s, и я взорву ваш% s».
% (3, 'фырка', 'затяжка', 'хаус'))
# Разбиваем строку на куски, которые автоматически объединяются Python
текст = (
"% d поросят вышли",
"или я% s, и я% s,"
"и я взорву твой% s."
% (3, 'фырка', 'затяжка', 'хаус'))
Строки i18n (Unicode)
> ustring = u'A unicode \ u018e string \ xf1 '
> ustring
u'A unicode \ u018e строка \ xf1 '
## (ustring сверху содержит строку Unicode)
> s = ustring.encode ('utf-8')
> с
'Строка Unicode \ xc6 \ x8e \ xc3 \ xb1' ## байтов в кодировке utf-8
> t = unicode (s, 'utf-8') ## Преобразование байтов обратно в строку Unicode
> t == ustring ## Он такой же, как оригинал, ура!
Если заявление
если скорость> = 80:
распечатать 'Лицензия и регистрация, пожалуйста'
если настроение == 'ужасное' или скорость> = 100:
print 'Вы имеете право хранить молчание.'
elif mood == 'bad' или speed> = 90:
print "Мне придется выписать вам билет".
write_ticket ()
еще:
print "Давай попробуем сохранить меньше 80, ладно?"
если скорость> = 80: print 'Вы так разорились'
else: print "Хорошего дня"
Упражнение: string1.py
Работа со строками в Go и Golang
Строковые функции Go
theString: = "Любовь проявляется в приятном служении"
fmt.Println (len (theString))
fmt.Println (theString [0], "", theString [len (theString)]) // паника
fmt.Println (theString [0], "", theString [len (theString) -1]) // 76, 101 - (L, e)
строка [i: j] (где i <= j)
fmt.Println (theString [0: len (theString)]) // Любовь проявляется в приятном обслуживании
fmt.Println (theString [: len (theString)]) // Любовь проявляется в приятном обслуживании
fmt.Println (theString [0:]) // Любовь проявляется в приятном служении
fmt.Println (theString [:]) // Любовь проявляется в приятном служении
fmt.Println (theString [2: 8]) // человек
fmt.Println (theString [: 8]) // Любите мужчину
fmt.Println (theString [6:]) // отображается в приятном сервисе
str1: = "образец текста"
str2: = str1 // образец текста
str1 + = ", another sample" // образец текста, другой образец
str1 [4] = 'A' // ошибка!
Сравнение строк в Go
str1: = "Я видел пилу, чтобы пилить"
str2: = "Я видел" + "пилу для пиления"
если str1 == str2 {
fmt.Println ("str1 == str2")
}
str2 + = "дерево"
если str1! = str2 {
fmt.Println ("str1! = str2")
}
если str1 strInt: = "1234"
intVal, err: = strconv.ParseInt (strInt, 10, 32) // 1234, число с основанием 10 и 32-битное
if err == nil {
fmt.Println (intVal)
} еще {
fmt.Println (ошибка)
}
floatVal: = 3.1415
strFloat = strconv.FormatFloat (floatVal, 'E', -1, 64)
fmt.Println (strFloat)
f: = 2,5678
strFloat: = fmt.Sprintf ("% f", f)
fmt.Println (strFloat)
The
strings Package in Go str: = "вс, пн, вт, ср, чт, пт, сб"
будние дни: = strings.Split (str, ",")
для _, день: = диапазон рабочих дней {
fmt.Println (день)
}
Пакет Unicode / utf8 в Go
q: = "от А до Я"
fc, размер1: = utf8.DecodeRuneInString (q)
fmt.Println (fc, size1)
lc, size2: = utf8.DecodeLastRuneInString (q)
fmt.Println (lc, size2)
Последние мысли о струнных в го