Распознать (перевести) картинку в текст (ONLINE)
Программы для разработки (интегрированные среды для разработки IDE)
HTML
Интерактивная реклама в HTML (animate banner)
WEB сайт
Javascript, TypeScript
Кнопки, текстовые поля и другие элементы на WEB странице
JavaScript технологии
JavaScript графика, анимация для игр
JavaScript менеджер пакетов (добавление JavaScript библиотек в ваш Web проект)
Автоматическое выполнение задач в вашем Web проекте
База данных (My SQL)
База данных (SQL Server)
База данных (PostgreSQL)
Работа с базой данных на C#
Интернет, HTTP, TCP, UDP, FTP протоколы
Microsoft C# и .NET
Microsoft Office 365 E3 (Web services)
Python
Java программирование (приложения для windows, андроид телефонов)
Mobile Development with C++ (Android, iOS)
Flutter & Dart
Облачные технологии
Резюме (как найти работу)
Автоматизированное тестирование
Рефакторинг & Паттерны
Методологии управления проектами
Управление версиями проекта, история измененных файлов
Математические алгоритмы
CI/CD
Docker
Kubernetes
Микрослужбы
Разработка игр
Создания 2D графики для игры
Технологии для написания игр
Еще языки программирования
Интернет браузеры
Telegram (месенджер)
WEB сервер
bat файлы
.htaccess файлы
Viber
Операционная система LINUX
Операционная система Mac OS
Операционная система WINDOWS и программы
Операционная система ANDRIOD
Операционная система iOS
Компьютерная платформа (процессор)
Ноутбук (BIOS)
Быстродействие компьютера (процессора)
Графика и видео
2D графические редакторы
3D графические редакторы
Видео
Online: просмотр Word файлов, конвертация PDF файлов, распознование картинки в текст
PDF to word, images
Распознавание картинки в текст
Регулярные выражения
Поставить HD Video Box в Windows
Открыть ИП в Минске (через интернет)
App Store: TextGrabber переводчик по фото
ABBYY TextGrabber на лету оцифрует фрагменты печатного текста или QR-коды и превратит распознанный результат в действия: звоните, пишите, переводите на 100+ языков онлайн и 10 языков оффлайн, просматривайте в интернете или на картах, создавайте события в календаре, редактируйте, озвучивайте и делитесь любым удобным способом.
При наведении камеры на печатный текст приложение моментально захватывает информацию и распознает ее без подключения к интернету. Уникальный режим распознавания в реальном времени извлекает информацию на 60+ языках не только из документов, но и с любых поверхностей.
————————
***** Победитель Mobile Star Awards в категориях «Mobile Productivity App» и «Mobile Image Capture App»
“The results get delivered relatively fast, which is great. A must have for students” — appadvice.com
“The Best Image-to-Text App for iPhone” — lifehacker.com
КЛЮЧЕВЫЕ ПРЕИМУЩЕСТВА
• Перевод в режиме реального времени прямо на экране телефона на более чем 100 языков онлайн (полнотекстовый перевод) и 10 языков оффлайн (пословный перевод)
• Инновационный режим Real-Time Recognition на основе технологии ABBYY RTR SDK оцифрует печатный текст прямо в экране камеры без фотографирования.
• Распознавание текста на 60+ языках, в том числе русском, английском, немецком, испанском, греческом, турецком, китайском и корейском, без подключения к интернету.
• Все ссылки, номера телефонов, адреса электронной почты, почтовые адреса и даты после оцифровки становятся кликабельны: можно перейти по ссылке, позвонить по телефону, написать email, найти адрес на картах или добавить событие в календарь.
• Cчитыватель QR кодов.
• Озвучивание распознанного и переведенного текста с помощью системной функции VoiceOver.
• Удобный интерфейс для слабовидящих людей: можно увеличить размер шрифта и воспользоваться звуковыми подсказками к элементам интерфейса.
• Публикация текста в любое установленное на девайсе приложение через системное меню.
• Все оцифрованные данные сохраняются в истории, где их можно удалить, отредактировать или объединить.
————————
С ABBYY TextGrabber легко сканировать и переводить:
• Любые бумажные документы
• Tекст с экрана монитора, ТВ, смартфона
• Рецепты из кулинарных книг
• Статьи в журналах, газетах, книгах
• Этикетки и счетчики
• Инструкции и руководства по эксплуатации
• Текст состава продуктов на упаковке и многое другое…
————————
Совет по распознаванию:
Выбирайте соответствующий оригинальному тексту язык распознавания. Это особенно важно, если он отличается от установленного по умолчанию английского и русского.
Автовозобновляемая Премиум-подписка позволяет получить доступ ко всем функциям приложения. Подписка продлевается автоматически в конце периода, если только вы не решите отменить подписку по крайней мере за 24 часа до окончания текущего периода. Оплата будет снята с вашего счета ITunes при подтверждении покупки. Вы можете управлять подпиской и отключить автоматическое обновление в настройках учетной записи после покупки. Все личные данные обрабатываются в соответствии с условиями стандартной политики конфиденциальности App Store.
Privacy: https://www.abbyy.com/privacy/
————————
Твиттер: @ABBYY_Mobile
fb.com/Abbyy.Lingvo
vk.com/abbyylingvo
youtube.com/AbbyyMobile
————————
Пожалуйста, оставьте отзыв, если вам понравилось приложение ABBYY TextGrabber. Спасибо!
Как перевести картинку в текст. Преобразование изображения в текст.
Как преобразовать изображение в текст
Работая с документами, часто возникает необходимость в редактировании файлов различных форматов. Тем, кто не знаком с программами по преобразованию изображений в текст, приходится вручную перепечатывать довольно большие куски текста в Word. А затем уже редактировать и форматировать.
Так как я совсем недавно была в числе тех, “кто не знаком” с такими программами, хочу поделиться своей находкой, которая значительно сэкономила мое время, что повлияло на продуктивность.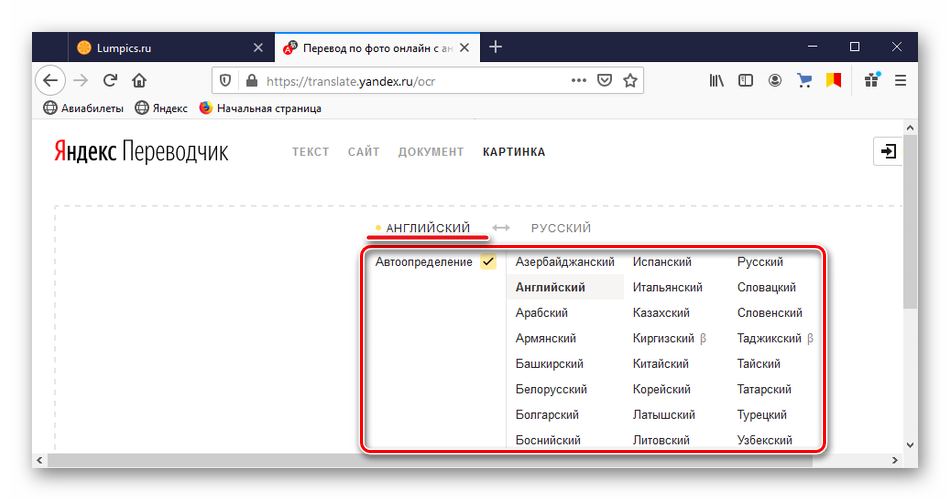 А значит – повысилась моя деловая эффективность в целом.
А значит – повысилась моя деловая эффективность в целом.
Зачем нужно преобразовывать изображение в текст?
Довольно распространенный пример: клиент присылает вместо напечатанных в Word реквизитов фирмы – сканированное изображение какого-либо договора со своими реквизитами. Ничего не остается делать, как перепечатывать реквизиты, затрачивая на это драгоценное время, которое вполне можно было бы использовать по другому назначению.
Или, предположим, вы встречаете интересную информацию на страницах книги в формате PDF, который и перепечатывать долго, и материал ценный, нужный для работы. В итоге, приходится подыскивать что-то другое. И невольно, возникал вопрос: как перевести картинку в текст.
Очень часто встречаются с необходимостью преобразования изображения в редактируемый текст студенты. Помните, как единственный учебник или книгу всей группе приходилось переписывать от руки?
Теперь у меня есть онлайн-сервис ocronline.com, который за меня сделает при необходимости эту работу.
Как перевести картинку в текст?
Процесс преобразования файлов, таких как JPEG в WORD, TEXT или RTF, называется OCR или оптическое распознавание символов. Специальное программное обеспечение определяет формы букв и цифр в изображении и преобразует их в самом тексте, что позволяет копировать, вставлять и редактировать .
Как преобразовать отсканированное изображение в текст?
Если вы устали тратить время на перепечатывание документов, тогда онлайн-система распознавания для вас.
Система распознает для вас документы любого формата JPG, PNG, GIF, TIFF и файлов в формате PDF. Файлы не могут быть более 10 Мб и содержать не более 100 страниц. Свой язык можно выбрать из 150 языков. На выходе можно получить файл в формате DOC, PDF, RTF или TXT.
На самом сервисе все довольно просто. Разобраться сможет даже ребенок. Перевести картинку в текст очень легко. Выбираете язык, загружаете документ, обрабатываете и сохраняете результат.
Небольшим недостатком является невозможность работы сразу с несколькими языками. Если перед вами текст с иностранными словами, то в этом случае ocronline не сможет его перевести.
Плюсом данного онлайн-сервиса станет возможность в одно и то же время работать сразу с несколькими изображениями, например, книгой.
В любом случае, советую этот онлайн-сервис добавить в закладки или в мой любимый Evernote, чтобы когда возникла необходимость, можно было быстро призвать себе на помощь великолепного помощника – бесплатный онлайн-сервис по преобразованию отсканированного изображения в текст. Замечу, что в бесплатном режиме можно обработать 5 страниц. Дальнейшее использование сервиса стоит от 8$. Тем не менее, этот ресурс может быть хорошим выходом из сложной ситуации.
Примечание от 18.02.14
По многочисленным просьбам читателей поясню на своем примере, как шаг за шагом конвертировать IPEG в Word.
1 шаг. Регистрируетесь на сервисе,
и после регистрации у вас появится вот такая страница.
2 шаг. Загрузите картинку, выберите язык, и формат будущего документа. На скриншоте стрелочкой показаны пути.
Шаг 3. После загрузки вас перебросит на следующую страницу, где нужно нажать на слово process.
Шаг 4. Последний шаг – скачать полученный результат. Скачивайте на компьютер в нужное место и открывайте документ.
Вот мой результат. Верхняя картинка – это то, что я загрузила, а внизу две картинки – это скриншот двух листов получившегося документа word. Теперь я имею возможность скопировать текст и редактировать.
Дорогие друзья, если еще остались вопросы, как перевести картинку в текст, пишите в комментариях, обязательно помогу разобраться. Сервис работает!
Желаю успехов в работе!
Просмотры: 2 275
PDF в Excel и Word Онлайн бесплатно. Перевести ПДФ в Эксель и Ворд. Распознать таблицу или картинку
Заменить точку на запятую в Excel. Разделитель в Excel, как поменять? Как сделать красивую надпись в Excel
Разделитель в Excel, как поменять? Как сделать красивую надпись в ExcelКак перевести картинку или PDF в Excel и Word онлайн бесплатно? Вопрос насущный и постоянно возникающий у коллег. У меня, конечно, есть FineReader — программа для перевода картинок и сканов в текстовые документы любого формата. Я пользуюсь ей со студенческих времен, когда теорию с книг надо было перенести в рефераты или диплом, не перепечатывая их. Помнится, мне это замечательно сэкономило время, чтобы глубже изучить Excel и использовать его в дипломе! Но ноутбук не всегда со мной, поэтому ниже я сделал обзор сервисов по бесплатному распознаванию текстов онлайн (и никаких пиратских скачиваний).
Часто меня спрашивают, как быстро заменить FineReader, да еще online и бесплатно. Пришлось заняться этой проблемой 😉 5-7 лет назад веб-сервисы казались в России еще каким-то далеким будущим, поэтому я каждый раз открываю для себя бесплатные облачные сервисы привычных оффлайн программ. Поэтому приведу небольших список самых популярных программ конвертеров изображений — для этого будем конвертировать текст на фоне таблицы Excel в не самом лучшем качестве (чтобы проверить качество распознавания текста):
и фото таблицы в стандартном качестве (чтобы посмотреть как распознаются таблицы):
посмотрим, что представлено в интернете
1. PDF в Excel и Word онлайн бесплатно ABBYY FineReader Onlinefinereaderonline.com
Как, наверное, и должно быть, на первом месте «родной» ABBYY FineReader. Сервис в полном объеме был запущен в середине 2011 года и за эти годы претерпел положительные изменения.
Зарегистрировался. Загрузил фото или PDF, выбрал язык, выбрал формат выводимого документа. Можно сохранить в Excel. Распознает таблицы и выводит их в xlsx документы. Все здорово, все работает на 5+
Распознование (текст) на 9,5 из 10.
Но это был бы не ABBYY, если бы сервис был полностью бесплатным.
После регистрации вам дается только 10 бесплатных страниц, для разового использования идеально подходит. Но если нужно распознавать каждый день или если у вас 100 страниц, сервис не подходит. Будем искать альтернативу.
2. FRee OCR, convertio.co и прочееВсе это довольно известные сервисы распознавания. Их в интернете достаточно много. К сожалению, для PDF распознает только первую страницу в большинстве случаев, или заявлено, что распознает, но не делает этого
Тут все просто. Во всех конвертерах загружаем документ с компьютера, выбираем язык (не везде), жмем Start. Распознается, скачиваем, сохраняем.
Качество распознования 7 из 10.
Распознает довольно сносно обычный текст. Не распознает таблицы (не сохраняет их форму тем более). Нельзя сохранить в Excel или любой табличный редактор текст.
Таких сервисов как эти я пересмотрел штук 15 и сперва опечалился, т.к. считаю, сервис перевода PDF в Excel Онлайн бесплатно очень нужен.
Но потом, я нашел:
3. www.onlineocr.netОтличный бесплатный сервис все же есть. Здесь можно выбрать язык, что сразу увеличивает качество распознавания текста. Получившиеся данные можно сохранить как в Word, так и в Excel. Можно скопировать результат сразу из браузера. Скачав файл xlsx, вы сохраните даже структуру таблицы — поверьте мне, для бесплатных сервисов — это огромная редкость! Можно распознать PDF или картинку, так же без видимо усложнений.
Работает быстро.
Качество распознавания 7 из 10 (если смотреть по PNG или JPEG).
Уточнение: Неплохо распознает таблицу в PDF, но я рекомендую перевести скан таблицы в jpeg перед началом работы и после распознавать уже как картинку. Так качество опознанного текста получится еще лучше!
Хороший сервис для распознавания PDF в Excel Онлайн, а также распознавания картинок в текст.
Воду в сите не удержишь, как говорится, и на хороший платный продукт всегда появится бесплатный аналог, сопоставимого качества. Будь это Excel или FineReader.
Будь это Excel или FineReader.
Уверен, сервис online распознания картинок и защищенных текстов бесплатно будет вам полезен. PDF в Excel и Word онлайн бесплатно может помочь для диплома или лабораторных студентам, а может и сотрудникам компании, которым надо использовать документ, сохраненный только на бумаге.
Удачи!
Поделитесь нашей статьей в ваших соцсетях:
Похожие статьи
Заменить точку на запятую в Excel. Разделитель в Excel, как поменять? Как сделать красивую надпись в ExcelСканер + распознавание текста на айфоне: Обзор Adobe Scan для iOS
♥ ПО ТЕМЕ: Как передать гостям пароль от Wi-Fi, при этом не называя его (QR-код).
Office Lens
Какие форматы распознает: изображения, снятые камерой.
В каких форматах сохраняет: DOCX, PPTX, PDF.
Данный сервис позволяет сканировать документы с помощью камеры телефона или компьютера. Office Lens поддерживает сохранение в популярных форматах. Получившиеся файлы можно редактировать в текстовых редакторах Microsoft, интегрированных с Office Lens, таких как Word и One Note.
Скачать Office Lens для ПК
Скачать Office Lens для iPhone и iPad
Скачать Office Lens для Android
♥ ПО ТЕМЕ: ПДФ → Ворд (текст), МП3 → Вав (аудио) конвертер онлайн: 5 лучших бесплатных онлайн-сервисов.
Adobe Scan
Какие форматы распознает: изображения, снятые камерой.
В каких форматах сохраняет: PDF.
Разработанный компанией Adobe продукт несколько уступает предыдущему сервису, так как позволяет сохранять распознанный текст только в формате PDF. Его сильной стороной является возможность экспорта документов в Adobe Acrobat, в котором можно удобно редактировать PDF-файлы.
Скачать Adobe Scan для iPhone и iPad
Скачать Adobe Scan для Android
♥ ПО ТЕМЕ: Как правильно фотографировать: 12 простых советов для тех, кто хочет улучшить качество своих фотографий.
Free OCR to Word
Какие форматы распознает: JPG, TIF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и пр.
В каких форматах сохраняет: DOC, DOCX, TXT.
Программа доступна для компьютера на базе Windows и Mac и позволяет распознавать текст на изображениях во множестве форматов. Присутствует поддержка экспорта в Word, сохранения не отформатированного текста в формате TXT и сохранения содержимого в буфере обмена.
Скачать Free OCR to Word для Windows и Mac.
ПО ТЕМЕ: 20 полезных сервисов Google, о которых вы могли не знать.
FineReader Online
Какие форматы распознает: JPG, TIF, BMP, PNG, PCX, DCX, PDF.
В каких форматах сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A.
Сервис позволяет распознавать и редактировать тексты и таблицы в режиме online. Бесплатно можно распознать только 10 страниц, после чего каждый месяц можно будет без оплаты загрузить еще по 5 страниц.
Пользоваться FineReader Online.
♥ ПО ТЕМЕ: Обрезать видео онлайн: 3 быстрых бесплатных сервиса.

Online OCR
Какие форматы распознает: JPG, BMP, TIFF, GIF, PDF.
В каких форматах сохраняет: DOCX, XLSX, TXT.
Еще один online-сервис, позволяющий, в отличие от предыдущего, распознавать тексты и таблицы совершенно бесплатно и без регистрации. У зарегистрировавшихся пользователей есть возможность загружать больше одного файла за один раз.
Пользоваться Online OCR.
♥ ПО ТЕМЕ: Как сделать фотоколлаж онлайн: обзор лучших сервисов.
Soda PDF OCR
Какие форматы распознает: JPG, GIF, TIFF BMP, PNG, PDF.
В каких форматах сохраняет: TXT.
Один из простейших сервисов, предоставляющий на выходе чистый, не отформатированный текст. Не требует регистрации и поддерживает работу с документами на нескольких языках.
Пользоваться Soda PDF OCR.
♥ ПО ТЕМЕ: Бесплатный редактор ПДФ: лучшие программы для редактирования PDF-документов на компьютере.
Microsoft OneNote
Какие форматы распознает: большинство распространенных форматов изображений.
В каких форматах сохраняет: файлы OneNote.
Функция распознавания текста присутствует в версии OneNote для персональных компьютеров. Для того чтобы провести данную операцию, необходимо нажать на изображение текста правой кнопкой мыши и выбрать опцию «Копировать текст из рисунка» → «Текст». Распознанное содержимое будет перемещено в буфер обмена.
Скачать Microsoft OneNote для ПК
Скачать Microsoft OneNote для iPhone и iPad
Скачать Microsoft OneNote для Android
Смотрите также:
Проект Нафта
Если вы будете смотреть на эти три анимированных гифки достаточно долго и внимательно, возможно, вам не придется ничего читать.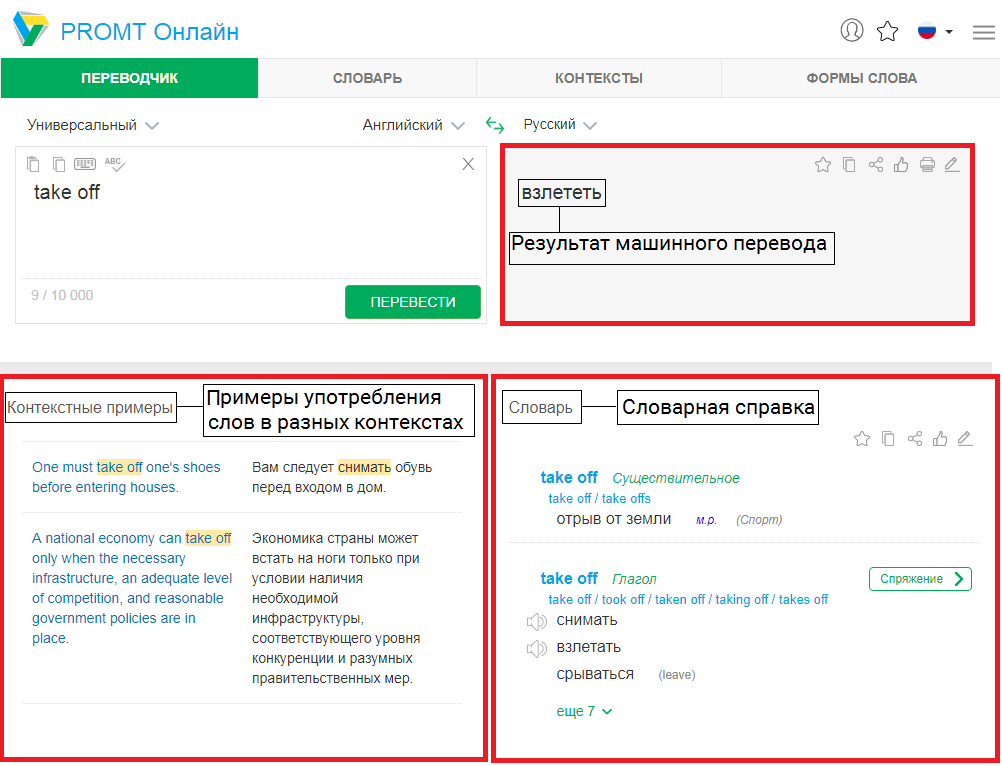
В течение мая 2012 года я читал о резьбе по швам, интересном и почти волшебном алгоритме, который может изменять масштаб изображения, явно не сжимая его. Поигравшись с маленькими швами, которые обычно создавал резчик по швам, я заметил, что они имеют тенденцию сходиться и располагаться таким образом, чтобы прорезать промежутки между буквами (подходы динамического программирования на самом деле довольно распространены, когда дело доходит до сегментации букв, но я этого не знал).Именно тогда, читая особенно подробный комикс smbc, я подумал, что должно быть возможно придумать что-то, что будет читать изображения (с
Моя первая попытка была простой. Изображение проецировалось сбоку, образуя вертикальную пиксельную гистограмму. Значительные впадины полученных гистограмм служили подписью для концов текстовых строк.После того, как горизонтальные линии были найдены, он обрезал каждую строку и повторил процесс гистограммы, но на этот раз вертикально, чтобы определить положение букв. Это работало только для строго горизонтального машинно-напечатанного текста, потому что в противном случае гистограммы проекции были бы слишком зашумленными. По тем или иным причинам я решил, что либо проблема не стоит того, чтобы ее решать, либо я не готов к этому.
Перенесемся на полтора года вперед, я учусь на первом курсе Массачусетского технологического института на втором месяце учебы.Есть хакатон, на который, как мне кажется, я мог бы записаться за несколько месяцев вперед, он позиционируется как крупнейший в Массачусетском технологическом институте. Я проспал допоздна накануне совершенно без особой причины и проснулся в 7 утра, потому что хотел убедиться, что моя регистрация прошла. Я вошел на незамерзший каток, где более 1000 человек требовали столы и раскладывали кабели для ноутбуков на земле — так вот как будет выглядеть мой первый хакатон.
Все остальные были «подключены» или что-то в этом роде; большие наушники, пристально глядя на десятки окон Sublime Text.Честно говоря, это было довольно громко. Я понятия не имел, чем бы в итоге стал заниматься, и не мог встретить никого, кто одновременно был готов сотрудничать и имел идею, достаточно интересную для меня. Поэтому я решил вернуться в свою спальню и вздремнуть.
Я проснулся от этого сна с ощущением, что я немного устал от до и не мог даже приблизиться к пониманию того, что я собираюсь делать. Я решил вернуться на хакатон, потому что там бесплатная еда или что-то в этом роде.
Если вы обратили внимание на разрешения, запрашиваемые в диалоговом окне установки, вы, возможно, задались вопросом, почему именно это расширение требует такого широкого доступа к вашей информации. Project Naptha работает на очень низком уровне, в идеале это та функциональность, которая изначально встроена в браузеры и операционные системы. Чтобы вы могли выделять изображения повсюду, и взаимодействовать с ними, ему нужна возможность читать изображения, расположенные повсюду.
Одна из наиболее впечатляющих особенностей этого проекта — то, что он почти полностью написан на клиентском javascript. Это означает, что он практически полностью функционален без доступа к удаленному серверу. Здесь есть небольшая оговорка, заключающаяся в том, что онлайн-перевод, работающий в автономном режиме, является оксюмороном, а отсутствие доступа к кэшированной службе OCR, работающей в облаке, означает снижение производительности и более низкую точность транскрипции.
Таким образом, необходимо найти компромисс между конфиденциальностью и удобством использования.И я думаю, что настройки по умолчанию обеспечивают тонкий баланс между предоставлением всех функциональных возможностей и соблюдением конфиденциальности пользователей. Я слышал жалобы с обеих сторон (примерно равные по количеству, на самом деле, что немного интригует) — многие люди хотят высококачественной транскрипции по умолчанию, а другие не хотят никакой связи с сервером по умолчанию.
По умолчанию, когда вы начинаете выделять текст, он отправляет защищенный запрос HTTPS, содержащий URL-адрес конкретного изображения и буквально ничего другого (без токенов пользователя, без информации о веб-сайте, без файлов cookie или аналитики), и запросы не регистрируются.Сервер отвечает списком существующих переводов и языков OCR, которые были выполнены. Это позволяет распознавать текст на изображении с гораздо большей точностью, чем это было возможно в противном случае. Однако это можно отключить, просто установив флажок «Отключить поиск» в меню «Параметры».
Функция перевода в настоящее время находится в ограниченном развертывании из-за проблем с масштабируемостью. Онлайн-сервис OCR также имеет индивидуальное измерение для каждого пользователя, поэтому такие запросы включают токен уникального идентификатора.Однако токен полностью анонимен и не связан с какой-либо личной информацией (он обрабатывается полностью отдельно от запросов поиска).
Так что на самом деле то, что работает на этой странице, не является полноценным Project Naptha. По сути, это всего лишь интерфейс, поэтому ему не хватает вычислительной тяжелой работы, которая на самом деле делает его крутым. Все текстовые метрики и анализ макета были предварительно рассчитаны. Прежде чем поднимать вилы, на самом деле есть веская причина, по которой эта демонстрационная страница запускает то, что составляет Weenie Hut Jr.версия скрипта.
Бэкэнд, требующий больших вычислительных ресурсов, широко использует WebWorkers, который, хотя и имеет довольно хорошую поддержку современных браузеров, имеет тонкие различия между платформами. Когда дело доходит до отправки экземпляров ImageData, Safari ведет себя странно, а переносимые типизированные массивы немного отличаются в Firefox и Chrome. Но самое главное, что текущая стабильная версия (34) Google Chrome на момент написания действительно страдает от изнурительной неработающей реализации WebWorkers.К счастью, расширения Chrome, похоже, не страдают той же проблемой.
Дихотомия между словами, выраженными в виде текста, и словами, заключенными в изображениях, настолько прочно укоренилась в процессе просмотра, что вы можете даже не распознать ее как противоречащую интуиции. Для технических специалистов ограничение является естественным, поскольку изображения являются в основном «растровыми» объектами, лишенными семантической информации, необходимой для указания, какие области должны быть выбраны и какой текст содержится.
Компьютерное зрение — это активная область исследований, в основном посвященных обучению компьютеров тому, как на самом деле «видеть» вещи, распознавать буквы, формы и объекты, а не просто перемещать копии пикселей.
На самом деле в оптическом распознавании символов (OCR) нет ничего нового. Библиотеки и юридические фирмы использовали его для оцифровки книг и документов не менее 30 лет. Совсем недавно он был объединен с алгоритмами обнаружения текста для считывания слов с фотографий уличных знаков, номеров домов и визитных карточек.
Основной особенностью Project Naptha является обнаружение текста, а не оптическое распознавание символов. Он запускает алгоритм под названием Stroke Width Transform, изобретенный Microsoft Research в 2008 году, который способен определять области текста независимо от языка. В некотором смысле это похоже на то, что может сделать человек: мы можем распознать, что знак имеет письменность, не зная, на каком языке он написан, не говоря уже о том, что он означает.
Тем не менее, полсекунды все еще довольно заметны, поскольку исследования показали, что пользователи не только различают, но и легко раздражаются задержками, составляющими всего сотню миллисекунд.Чтобы обойти это, Project Naptha на самом деле постоянно наблюдает за перемещениями курсора и экстраполирует полсекунды в будущее, чтобы можно было заранее запустить обработку, чтобы она выглядела мгновенно.
В сочетании с другими алгоритмами, такими как анализ связанных компонентов (определение отдельных букв), определение пороговых значений otsu (определение расстояния между словами), непересекающиеся леса наборов (определение строк текста), Project Naptha может очень быстро построить модель текстовых областей, слов и букв.![]() — при этом совершенно не осознавая специфики, какие именно буквы существуют.
— при этом совершенно не осознавая специфики, какие именно буквы существуют.
Однако, как только пользователь начинает выделять текст, он запускает алгоритмы распознавания символов, чтобы определить, что именно выбирается. Этот процесс распознавания происходит для каждого региона, поэтому нет лишних усилий, чтобы сделать это до того, как пользователь сделает окончательный выбор.
Процесс распознавания включает в себя увеличение интересующей области так, чтобы каждая линия была порядка 100 пикселей в высоту, что может достигать 5-кратного увеличения.Затем он выполняет интеллектуальный фильтр маскировки цвета перед отправкой на встроенный порт чистого javascript движка Ocrad OCR с открытым исходным кодом.
Поскольку этот процесс является относительно дорогостоящим с точки зрения вычислений, имеет смысл выполнять этот тип «ленивого» распознавания, откладывая выполнение процесса до последнего возможного момента. Это может занять от пяти до десяти секунд, в зависимости от размера изображения и выделения. Так что есть большая вероятность, что к тому моменту, когда вы нажмете Ctrl + C и текст будет скопирован в буфер обмена, механизм распознавания текста еще не завершит обработку текста.
Это все в порядке, потому что вместо текста, который все еще обрабатывается, он вставляет небольшой флаг, описывающий, где находится выделенный фрагмент и из какой части изображения следует читать. В течение следующих 60 секунд Naptha отслеживает этот флаг и заменяет его окончательным распознанным текстом, как только может.
Иногда встроенного механизма распознавания текста недостаточно. Он поддерживает только языки с латинским алфавитом и ограниченным количеством диакритических знаков и не содержит языковой модели, так что он выводит серию букв в зависимости от вероятности данного контекста (например, алгоритм может решить, что «he1 | o »лучше подходит, чем« привет », потому что он учитывает только форму буквы).Таким образом, есть возможность отправить выбранный регион в облачную службу распознавания текста на основе Tesseract, отмеченного наградами механизма распознавания текста с открытым исходным кодом Google (ранее HP), который поддерживает десятки языков и использует расширенную языковую модель.
Если кто-то запускает движок Tesseract на общедоступном изображении, результат распознавания сохраняется, так что будущие пользователи, наткнувшиеся на то же изображение, мгновенно загрузят кешированную версию текста.
Существует класс алгоритмов для чего-то, что называется «Inpainting», который предназначен для восстановления изображений или видео, несмотря на недостающие части.Это широко используется для восстановления пленки и обычно используется в Adobe Photoshop как функция «Заливка с учетом содержимого».
В Project Naptha области, определенные как текст, используются в качестве маски для определенного алгоритма рисования, разработанного в 2004 году на основе метода Fast Marching Method Александру Телеа. Эту маску можно использовать для заполнения мест, откуда берется текст, создавая чистый лист, для которого можно распечатать новое содержимое.
С помощью элементарного анализа макета и текстовых метрик Project Naptha может определить параметры выравнивания текста (по центру, по ширине, по правому или левому краю), размер и толщину шрифта (полужирный, светлый или нормальный).Имея эту информацию, он может напечатать текст аналогичным шрифтом в том же месте. Или вы даже можете изменить текст, чтобы сказать все, что вы хотите.
Его даже можно привязать к сервису онлайн-перевода, Google Translate, Microsoft Translate или Yandex Translate, чтобы выполнять автоматический перевод документов. Благодаря усовершенствованному механизму распознавания текста Tesseract это означает, что можно читать текст на языках с различными сценариями (китайский, японский или арабский), которые вы, возможно, не сможете ввести в систему перевода.
Прототип, который был продемонстрирован на HackMIT 2013, позже заняв 2-е место, был довольно мягко назван «Изображения как текст». Конечно, он довольно точно описал точную функцию расширения, но в нем действительно не хватало этой маленькой искры жизни.
Итак, с тех пор я начал поиск нового имени, которое было бы изобилует пунтастическими возможностями. Одним из возможных вариантов был «Пиранин», химическое вещество, используемое при создании чернил для флюоресцентных хайлайтеров (моему соседу по комнате, химическому специалисту, это имя очень нравилось).Я проспал эту идею несколько ночей и понял, что совершенно забыл, как ее произносить, и поэтому ее вычеркнули из списка кандидатов.
Одним из возможных вариантов был «Пиранин», химическое вещество, используемое при создании чернил для флюоресцентных хайлайтеров (моему соседу по комнате, химическому специалисту, это имя очень нравилось).Я проспал эту идею несколько ночей и понял, что совершенно забыл, как ее произносить, и поэтому ее вычеркнули из списка кандидатов.
Нафта, его нынешнее название, происходит от еще более тонкой ассоциации. Видите ли, это происходит из-за того, что «маркер» звучит как «зажигалка», и что нафта — это тип топлива, часто используемый для зажигалок. Фактически, это было одно из самых ранних кодовых имен проекта, и оно привело к довольно забавному маленькому пасхальному яйцу , с которым вы можете поиграть, быстро щелкнув примерно дюжину раз по некоторому блоку текста внутри изображения.
Как извлечь текст из изображения
Приходит время, когда вы сталкиваетесь с изображениями и PDF-файлами, содержащими важный текстовый контент, который вы хотите извлечь для дальнейшего использования. Что вы будете делать? Большинство из вас может ввести слова или фразу в отдельный документ Word или блокнот. Но этот процесс может занять довольно много времени. К счастью, была разработана новая технология извлечения текста из изображения , которую они называют OCR или оптическим распознаванием символов.Если вы впервые слышите об оптическом распознавании текста, вот несколько программ, оснащенных такой функцией, которые просты в использовании и эффективно извлекают слова из изображений.
3 Отличные инструменты OCR для извлечения слов из изображения
LightPDFi2OCR
OCR.Space
LightPDF
LightPDF — это выдающаяся веб-программа для работы с PDF, которая предлагает различные инструменты для управления PDF. Он имеет встроенную функцию распознавания текста, которой очень легко пользоваться. Он поддерживает широкий спектр языков, например английский, французский, итальянский, японский и т. Д.Кроме того, этот инструмент OCR может обрабатывать такие форматы, как JPG, PNG и PDF.![]() Вот пошаговое руководство по извлечению текста.
Вот пошаговое руководство по извлечению текста.
- Откройте страницу OCR.
- Загрузите изображение, которое необходимо обработать, либо перетащив мышью, либо нажав «Выбрать файл».
- Затем вы можете выбрать один или несколько языков, содержащихся в вашем файле.
- Выберите формат вывода, который вы хотите получить. После завершения всех процессов нажмите «Преобразовать», чтобы начать преобразование.
- Чтобы сохранить файл на локальном диске, просто нажмите кнопку загрузки.
Почему мы рекомендуем это:
- Программа может преобразовывать изображения в различные редактируемые форматы, такие как PDF, Word, PPT, Excel и так далее. И сохраняет высокую точность.
- Инструмент имеет удобный интерфейс — на странице нет рекламы. И вам просто нужно открыть файл изображения, сделать несколько щелчков мышью, и ваш файл готов к работе.
- Что касается конфиденциальности ваших загруженных файлов, страница автоматически удаляет изображения или другие файлы после того, как вы закончите использовать инструмент.
i2OCR
Второй инструмент для извлечения текста из изображения онлайн — i2OCR. Как следует из названия, он предназначен для работы со службами, связанными с OCR. Несмотря на то, что это онлайн-приложение, этот инструмент работает так же хорошо, как и другие настольные инструменты распознавания текста. Эта программа поддерживает такие форматы, как JPG, PNG, PGM, TIF, PPM и PBM. Что касается языков, инструмент может распознавать до 60 языков. Он также имеет чистый и простой в использовании интерфейс, а также обеспечивает конфиденциальность для пользователей, поскольку их сервер удаляет файлы мгновенно через час.
- Перейти на главную страницу этого инструмента.
- На странице выберите язык текста, который нужно извлечь.
- После этого выберите, откуда вы хотите загрузить изображения. У вас будет 2 варианта: загрузить его с компьютера или получить по URL-ссылке.
- Чтобы начать процесс, установите флажок для проверки и нажмите «Извлечь текст».
- После этого вы можете скачать файл.
Почему мы рекомендуем:
- Программа также бесплатна для использования.
- Он предлагает два способа загрузки изображения. Таким образом, если вы хотите извлечь текст из изображения, размещенного в Интернете, вам не нужно загружать его заранее.
- Имеет несколько методов вывода.
- Позволяет предварительно просмотреть изображение и извлеченные слова перед загрузкой.
- Он поддерживает переход к страницам перевода и позволяет редактировать в Документах Google.
OCR.Space
Последняя возможная программа, которую мы рекомендуем для преобразования изображений в текст, — это OCR.Космос. Это также веб-инструмент, специализирующийся на услугах, связанных с оптическим распознаванием текста. В настоящее время программа поддерживает около 20 языков, а среди поддерживаемых форматов файлов — PNG, JPG и PDF. Давайте извлечем слова из картинки, выполнив следующие действия.
- Посетите официальный сайт OCR.Space.
- Нажмите «Выбрать файл» или вставьте URL-адрес изображения. Затем выберите язык файла, с которым вы работаете.
- Выберите нужный режим извлечения и нажмите «Начать распознавание текста!»
- Когда процесс будет завершен, нажмите «Загрузить», чтобы сохранить извлеченный текст на жесткий диск вашего компьютера.
Почему мы рекомендуем:
- Этот онлайн-инструмент бесплатный.
- Он прост в использовании и имеет чистый интерфейс для работы.
- Он может предварительно просмотреть изображение или файл после загрузки.
Совет: Если ваше изображение содержит какие-либо числа, то перед началом процесса извлечения рекомендуется выбрать корейский или китайский язык.
Заключение
Это возможные и простые методы, которые вы можете использовать для извлечения текста из изображения в Интернете.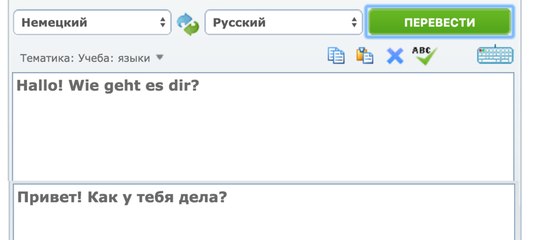 Но выходные результаты OCR не всегда так точны, как мы ожидаем, поэтому мы настоятельно рекомендуем вам проверять результат после обработки, особенно когда шрифт особенный или контент включает более одного языка.
Но выходные результаты OCR не всегда так точны, как мы ожидаем, поэтому мы настоятельно рекомендуем вам проверять результат после обработки, особенно когда шрифт особенный или контент включает более одного языка.
Более того, после тестирования мы обнаружили, что LightPDF работает лучше всего из трех инструментов, когда дело доходит до распознавания контента.
Рейтинг: 4.3 / 5 (на основе 25 оценок) Спасибо за вашу оценку!
3 лучших онлайн-инструмента для распознавания текста для извлечения текста из изображений
Расшифровка текста с изображений может быть настоящей проблемой.Когда текст представлен как изображение или какой-либо другой формат, который нельзя выбрать, учеба и работа становятся трудными. Единственное решение — заставить эти глаза и пальцы поработать и начать печатать — или так?
Оптимальное распознавание символов или OCR — это процесс преобразования напечатанного или рукописного текста с носителей, таких как отсканированные документы или фотографии, в простой текст.
Хотя возможны ошибки, в зависимости от четкости текста, использование OCR для извлечения текста из изображений может сэкономить часы монотонной работы.Один из вариантов использования OCR — это когда вы студент колледжа, которому нужна конкретная страница из учебника. Если бы друг отправил вам фотографию страницы, вы могли бы использовать OCR, чтобы извлечь весь текст из изображения, чтобы его было легко прочитать и скопировать.
В этой статье давайте рассмотрим три лучших онлайн-инструмента распознавания текста для извлечения текста из изображений, ни один из которых не требует загрузки какого-либо программного обеспечения или подключаемых модулей.
OnlineOCR — это один из самых простых и быстрых способов конвертировать изображение или файл PDF в несколько различных текстовых форматов.
Без учетной записи OnlineOCR.net позволит вам конвертировать до 15 файлов в текст в час. Регистрация учетной записи дает вам доступ к таким функциям, как преобразование многостраничных документов PDF и многое другое.
OnlineOCR.net поддерживает преобразование из форматов PDF, JPG, BMP, TIFF и GIF, вывод их как DOCX, XLSX или TXT.
OnlineOCR.net может распознавать текст на английском, африкаанс, албанском, баскском, бразильском, болгарском, каталонском, китайском, хорватском, чешском, датском, голландском, эсперанто, эстонском, финском, французском, галисийском, немецком, греческом, венгерском, исландском, Индонезийский, итальянский, японский, корейский, латинский, латышский, литовский, македонский, малайский, молдавский, норвежский, польский, португальский, румынский, русский, сербский, словацкий, словенский, испанский, шведский, тагальский, турецкий и украинский.
Процесс преобразования требует трех простых шагов. Вы загружаете файл размером 15 МБ, выбираете язык и формат вывода и нажимаете кнопку Convert .
Независимо от выбранного формата вывода, предварительный просмотр преобразования в виде обычного текста появится в поле под ссылкой для загрузки файла в выбранном формате. Это помогает предотвратить трату загрузки на извлечение, которое может быть неточным.
NewOCR в настоящее время предлагает только извлечение текста из файлов изображений, но поддерживает несколько других интересных функций, которых нет у многих онлайн-провайдеров OCR.
Чтобы начать использовать NewOCR, просто нажмите кнопку Выбрать файл , выберите изображение, из которого вы хотите извлечь текст, а затем нажмите синюю кнопку Предварительный просмотр . После этого появится предварительный просмотр вашего изображения и несколько дополнительных опций.
В отличие от большинства других онлайн-конвертеров изображений в текст, NewOCR фактически позволяет вам установить несколько языков распознавания. Это может быть очень полезно, если вы не знаете, на каком языке написан текст изображения, но у вас есть хорошее предположение и вы хотите получить правильный перевод простого текста.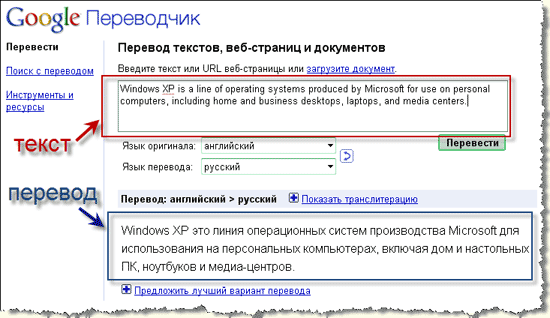
Если ваше изображение перекошено в одну сторону, вы также можете динамически повернуть его. Когда вы применили необходимые параметры, вы можете нажать синюю кнопку OCR , чтобы извлечь текст изображения.
Отсюда вы можете загрузить извлеченный текст в формате TXT, DOC или PDF или отправить его прямо в Google Translate или Google Docs для дальнейшего редактирования.
И последнее, но не менее важное: OCR.space, безусловно, является одним из самых надежных вариантов, которые мы нашли, и он должен помочь вам выполнить практически любую операцию преобразования изображения в текст.
OCR.space — один из лучших инструментов OCR, который поддерживает формат файла WEBP. Помимо этого, также поддерживаются PNG, JPG и PDF. Кроме того, вам не нужно загружать файл — вы можете установить на него удаленную ссылку, если он доступен где-то в Интернете.
Среди других нишевых функций — автоматический поворот, сканирование чеков, распознавание таблиц и автоматическое масштабирование. OCR.space — один из немногих онлайн-инструментов OCR, который поддерживает вывод файлов в виде PDF-файлов с возможностью поиска (с видимым или невидимым текстом), и вы даже можете выбрать один из двух различных механизмов OCR для наилучшего извлечения.
Все, что вам нужно сделать, это загрузить или связать файл, нажмите Start OCR! , и предварительный просмотр результатов будет динамически загружаться на той же странице. Если вы выбрали вывод как PDF-файл с возможностью поиска, также будут доступны кнопки Загрузить и Показать наложение .
Одна из самых интересных и уникальных особенностей OCR.space заключается в том, что он может выводить извлеченные данные в формате JSON. Этот JSON будет иметь поля, которые включают каждое слово в тексте и их координаты на самом изображении.Это очень важная функция, если вы программист, пытающийся программно извлекать текст из изображений.
С тремя вышеуказанными веб-инструментами извлечение текста практически из любого четкого и разборчивого изображения должно быть простым делом. Даже если вы умеете быстро набирать текст с несколькими мониторами, вам не нужно мучиться с расшифровкой текстовых изображений самостоятельно. OCR было создано не просто так, и эти веб-сайты помогут вам использовать его наилучшим образом!
Если у вас есть другие советы по выбору лучших инструментов или услуг оптического распознавания текста, которыми вы хотели бы поделиться, или если вам нужна помощь в использовании одного из перечисленных выше, напишите нам в комментариях ниже.
Лучшие инструменты оптического распознавания текста для преобразования изображений в текст
Программное обеспечение оптического распознавания текста позволяет легко преобразовывать изображения, такие как цифровые фотографии, отсканированные документы, печатные книги и т. Д., В текст. Выполнив оптическое распознавание текста для изображения, вы сможете копировать, вставлять или редактировать текстовое содержимое этого изображения без повторного ввода, а также оно становится более доступным для поиска.
Лучшие веб-службы оптического распознавания текста
Большинство сканеров поставляются с каким-либо программным обеспечением для оптического распознавания текста, но если у вас нет сканера, вы можете просто сделать снимок напечатанного текста с помощью цифровой камеры или даже мобильного телефона и затем используйте онлайн-утилиту OCR для извлечения текста из этого изображения.
Познакомьтесь с лучшими онлайн-сервисами оптического распознавания текста, которые помогут вам преобразовать изображения в текст.
1. Google Docs — Когда вы загружаете файл изображения или отсканированный PDF-файл в Google Docs, установите флажок «Преобразовать текст в формат Google Docs», и Google Docs автоматически выполнит оптическое распознавание текста для файла перед сохранением.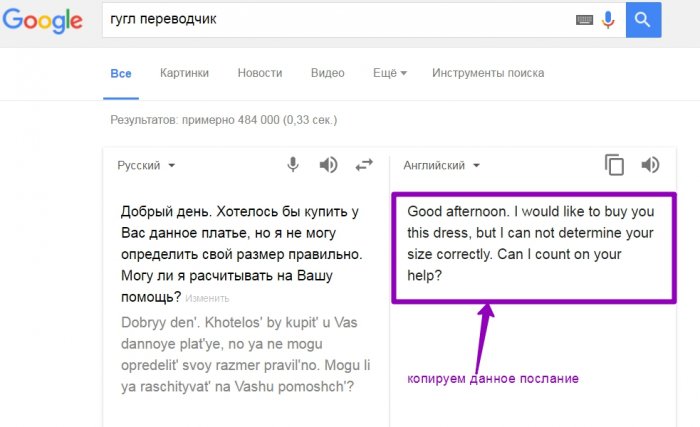 его в вашу учетную запись.
его в вашу учетную запись.
Если операция OCR прошла успешно, весь извлеченный текст сохраняется как новый документ, в противном случае Документы Google сохранят исходное изображение без каких-либо изменений.
С помощью Google Docs вы можете выполнять оптическое распознавание текста для изображений и PDF-файлов размером до 2 МБ, точность распознавания текста впечатляет, и нет никаких ограничений на количество файлов, которые вы можете обработать за день. Однако Документы Google не сохранят исходное форматирование документа, а механизм распознавания текста почти не работает с изображениями с низким разрешением.
2. Abbyy FineReader — FineReader Online — это веб-служба OCR, которая может мгновенно преобразовывать ваши файлы PDF и изображения в соответствующие форматы офисных файлов.Это сервис Abbyy, поэтому точность распознавания символов неплохая.
В отличие от механизма распознавания текста в Документах Google, который может распознавать только печатный текст, написанный латинскими буквами, FineReader может понимать гораздо более широкий спектр языков. Он работает даже с многоязычными документами, в которых текст написан на нескольких языках.
Бесплатная учетная запись в FineReader Online позволит вам преобразовать только несколько изображений в текст, и вам придется выложить около 3 долларов за 10 страниц для дополнительных преобразований.
3. OnlineOCR.net — Online OCR, как следует из названия, представляет собой облачную службу OCR, которая может обрабатывать все распространенные форматы изображений, включая отсканированные PDF-файлы. Если у вас есть несколько изображений, которые вы хотите преобразовать в текст за один раз, вы можете поместить их все в один zip-файл и загрузить его в Online OCR.
Из всех сервисов OCR, которые я пробовал до сих пор, Online OCR произвела на меня наибольшее впечатление. Точность распознавания символов неплохая, а преобразованные документы выглядят как точные копии исходных изображений.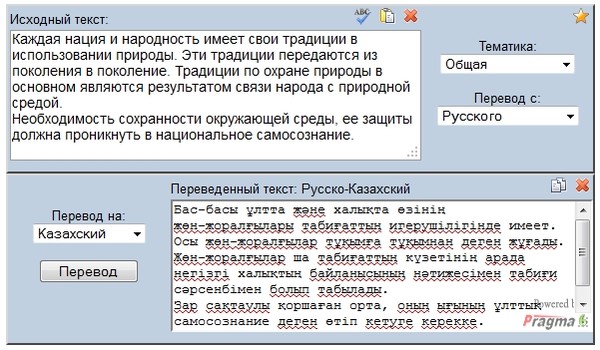 В моем ограниченном тесте с тремя различными типами изображений Online OCR смог сохранить структуру и форматирование после преобразования во всех трех случаях.
В моем ограниченном тесте с тремя различными типами изображений Online OCR смог сохранить структуру и форматирование после преобразования во всех трех случаях.
Как и FineReader, Online OCR предлагает кредиты для бесплатного преобразования примерно 5-6 изображений в текст, а после того, как лимит исчерпан, вам придется платить около 4 долларов за 50 страниц.
4. FreeOCR.com — Если вам когда-нибудь понадобится извлечь простой текст из изображения или отсканированного файла PDF, возможно, стоит попробовать бесплатное распознавание текста.Услуга не требует регистрации, и вы можете обрабатывать до 10 загрузок изображений в час.
Бесплатное распознавание текста похоже на графический интерфейс для механизма распознавания текста Tesseract от Google, который часто считается одним из самых точных механизмов распознавания текста. Однако Tesseract поддерживает только ограниченное количество языков и игнорирует большую часть форматирования отсканированного изображения.
5. Терминал оптического распознавания символов — Терминал оптического распознавания текста — одна из наиболее совершенных онлайн-служб оптического распознавания текста, которая поддерживает не только изображения и отсканированные PDF-файлы, но даже скриншоты программного обеспечения.
Например, если вы когда-нибудь получите сообщение об ошибке на вашем компьютере, сделайте снимок экрана, загрузите изображение в терминал OCR, и он вернет вам всю ошибку в виде простого текста, который вы можете скопировать и вставить в электронные письма или онлайн-форумы.
Терминал OCR имеет внутреннее питание от механизма OCR Abbyy. Бесплатная учетная запись с OCR Terminal дает вам 20 бесплатных конверсий каждый месяц, и вы можете заплатить около 7-9 центов за дополнительную конверсию.
6. OCR Online — Как и FreeOCR, OCR Online не требует регистрации, и вы можете перевести до 100 изображений в текст за один день.Он также поддерживает большое количество языков.
OCR Online обеспечивает хорошую точность распознавания и сохраняет большую часть исходного форматирования, но что вам больше всего нравится в этой услуге, так это пакетная обработка. Вы можете загрузить большое количество файлов одним пакетом, и результаты будут выводиться в виде одного документа.
Online OCR Software — Сравнение
PS: Один очевидный недостаток всех вышеупомянутых программ OCR заключается в том, что они работают только с печатным текстом, они не могут распознавать символы из рукописного текста.
Text Fairy — это приложение для Android OCR, которое вы ищете
Точное и простое в использовании приложение OCR на вашем устройстве Android может изменить ваш день. Джек Уоллен говорит, что Text Fairy превосходит другие приложения для распознавания текста почти во всех категориях.
Изображение: Джек Уоллен
Когда вам нужен текст из документа, квитанции или изображения, и у вас нет времени напечатать его, что вы делаете? Вы переключаетесь на свое Android-устройство, камеру и приложение для оптического распознавания символов (OCR) под названием Text Fairy.
Что особенного в Text Fairy?
Доступно множество приложений для оптического распознавания текста, в том числе приложение Office Lens (которое интегрируется в OneNote и One Drive). Text Fairy превосходит все другие приложения для распознавания текста практически во всех категориях. С помощью этого удобного приложения вы можете:
- Преобразовать изображение в текст
- Исправить точку обзора изображения
- Редактировать извлеченный текст
- Копировать текст в буфер обмена
- Использовать текст в других приложениях
- Преобразовать отсканированную страницу в PDF
- Распознавайте отпечатки на более чем 50 языках
- Пусть Android произносит текст
Это приложение может сканировать текст с изображений на вашем устройстве (ранее снятых камерой или с Google Диска) или сканировать текст с фотографий, снятых камерой.Самое приятное, что OCR Text Fairy действительно очень точное. Добавьте к этому тот факт, что Text Fairy бесплатна (по цене и рекламе), а также имеет открытый исходный код (загрузите исходный код), и у вас есть задатки для одного из лучших приложений OCR в магазине Google Play.
Установка Text Fairy
Text Fairy требуется Android 3.0 и выше. Установка так же проста, как установка любого другого приложения.
- Откройте Google Play Store на своем устройстве Android.
- Поиск текста феи.
- Найдите и коснитесь записи Ренарда Веллница.
- Нажмите «Установить».
- Прочтите список разрешений.
- Если список разрешений приемлем, нажмите Принять.
- Дождитесь завершения установки.
Вы должны увидеть средство запуска Text Fairy на главном экране, в панели приложений или в обоих местах. Коснитесь его, чтобы запустить приложение.
Использование текста Fairy
Прежде чем начать использовать Text Fairy, помните об этих моментах.
- Изображения должны быть резкими при хорошем освещении.
- Приложение не может читать рукописный ввод.
- Текст должен быть черным на белом фоне.
При первом запуске Text Fairy вы получите инструкции по его использованию. Это довольно просто: в главном окне есть две кнопки (, рис. A, ): одна для камеры и одна для открытия недавних изображений.
Рисунок A
Изображение: Джек Уоллен
Главное окно Text Fairy на Droid Turbo от Verizon.
Допустим, вам нужно извлечь текст из квитанции, которая у вас есть. Вот как.
- Open Text Fairy.
- Нажмите кнопку камеры в главном окне.
- Когда камера откроется, кадрируйте изображение на экране.
- Когда у вас будет изображение там, где вы хотите, коснитесь экрана.
- Когда появится изображение, если оно приемлемо, нажмите кнопку проверки.
- Поместите рамку вокруг текста, который вы хотите извлечь — здесь вы можете исправить точку обзора изображения (, рис. B, ).
- Нажмите стрелку, указывающую вправо.
- Нажмите, чтобы выбрать, сколько столбцов содержалось в исходном тексте.
- Выберите язык.
- Нажмите «Пуск».
- После завершения распознавания коснитесь, чтобы выбрать, что вы хотите сделать с текстом (, рис. C, ).
- Коснитесь ОК.
Рисунок B
Изображение: Джек Уоллен
Размещение в рамке только нужного текста.
Рисунок C
Изображение: Джек Уоллен
Выбор того, что делать с текстом.
Вы всегда можете вернуться к отсканированному изображению, чтобы снова поработать с текстом. В главном окне нажмите отсканированное изображение, которое хотите использовать, а затем нажмите кнопку меню (три вертикальные точки в верхнем левом углу) и выберите, что вы хотите сделать с текстом.
Языки
По умолчанию включены только два языка: английский и немецкий. Если вам нужен другой язык, нажмите дополнительное меню (три вертикальные линии в верхнем левом углу) и нажмите «Добавить язык». В списке языков нажмите кнопку загрузки, связанную с языком или языками, которые вы хотите добавить ( Рисунок D ).
Рисунок D
Изображение: Джек Уоллен
Добавление языка в Text Fairy.
Экономьте время с Text Fairy
Нет причин, по которым вам нужно тратить время на ввод текста из источника, если вы можете просто использовать Text Fairy для сканирования и извлечения необходимой информации. Попробуйте это очень точное приложение OCR и посмотрите, не упростит ли оно вашу мобильную жизнь.
См. Также
Image to Binary Converter — онлайн-изображение в массив
Поиск инструмента
Изображение в двоичном формате 0 1
Инструмент для преобразования изображения в двоичный код 0 и 1 (формат байтового массива).Черно-белое изображение / фото можно преобразовать в 0 и 1 (0 для черного и 1 для белого)
Результаты
Изображение в двоичном формате 0 1 — dCode
Тэги: Обработка изображений
Поделиться
dCode и другие
dCode является бесплатным, а его инструменты являются ценным подспорьем в играх, математике, геокэшинге, головоломках и задачах, которые нужно решать каждый день!
Предложение? обратная связь? Жук ? идея ? Запись в dCode !
Бинаризатор / преобразователь изображений
Изображение из двоичного генератора
Инструмент для преобразования изображения в двоичный код 0 и 1 (формат байтового массива).Черно-белое изображение / фото можно преобразовать в 0 и 1 (0 для черного и 1 для белого)
Ответы на вопросы (FAQ)
Как закодировать изображение в двоичном формате?
Считайте каждый пиксель и, если он темный, преобразуйте его в 0, а если он ясный, преобразуйте его в 1 (или инвертируйте 1 и 0).
Если изображение не является черно-белым, оно будет преобразовано в оттенки серого в соответствии с Рек. 601 яркости (формула $ Y = 0,2989 R + 0,5870 G + 0,1140 B $), а затем преобразовать в двоичную форму в соответствии с выбранным порогом (обычно 0.5 = 50%)
Пример: +11111111111111111111111111
Бэтмен +11111111111111111111111111
+11111100111111111100111111
+11110001111100111110001111 +11000001111000011110000011
+10000000111000011100000001 +10000000000000000000000001
+00000000000000000000000000 +00000000000000000000000000
+10000000000000000000000001 +10000110001000010001100001
+11001111111100111111110011 +11100111111100111111100111
Некоторые люди видят в этом форму бинарного искусства: пиксельное искусство.
Какие форматы изображений принимаются?
Принимаются все форматы веб-изображений (JPG, PNG, GIF и т. Д.), Но предпочтительнее использовать формат, использующий сжатие без потерь (PNG, BMP и т. Д.), Потому что в этих случаях данные каждого цвета пикселя не изменено.
Многие иконки размером 16×16, 32×32, 64×64 отлично подходят для форматирования.
Что такое бинаризация изображения? (Изображение 1-бит)
Бинаризация — это бинаризация (создание двоичного кода с 2 элементами) данных.
С практической точки зрения, изображение с 2 цветами (закодировано в 1 бит) быстро сохраняется, каждый пиксель равен 0 или 1.
0 кодов для черного или для белого?
Не существует стандарта для 1-битных изображений, но обычно 0 кодов для черного и 1 для белого, но ничто не мешает использовать 1 для черного и 0 для белого.
NB: 8-битное изображение кодирует 0 для черного и 255 для белого.
Задайте новый вопросИсходный код
dCode сохраняет за собой право собственности на исходный код онлайн-инструмента «Изображение в двоичном формате 0 1».За исключением явной лицензии с открытым исходным кодом (обозначенной CC / Creative Commons / free), любой алгоритм, апплет или фрагмент (конвертер, решатель, шифрование / дешифрование, кодирование / декодирование, шифрование / дешифрование, переводчик) или любая функция (преобразование, решение, дешифрование / encrypt, decipher / cipher, decode / encode, translate), написанные на любом информатическом языке (PHP, Java, C #, Python, Javascript, Matlab и т. д.), доступ к данным, скриптам, копированию и API не будет бесплатным , то же самое для изображения в двоичном формате 0 1 скачать для автономного использования на ПК, планшете, iPhone или Android!
Нужна помощь?
Пожалуйста, заходите в наше сообщество Discord, чтобы получить помощь! Также для зашифрованных сообщений проверьте наш автоматический идентификатор шифра!
Вопросы / комментарии
Сводка
Инструменты аналогичные
Поддержка
Форум / Справка
Ключевые слова
двоичный, изображение, картинка, черный, белый, 0,1, bmp, png, преобразовать, пиксель, массив
Ссылки
Источник: https: // www.dcode.fr/binary-image
© 2021 dCode — Лучший «инструментарий» для решения любых игр / загадок / геокэшинга / CTF.Capture2Text
Capture2TextСодержание
Что такое Capture2Text?
Capture2Text позволяет пользователям быстро распознавать часть экрана с помощью Сочетание клавиш. Полученный текст по умолчанию будет сохранен в буфер обмена.
Концептуальная иллюстрация:
Capture2Text распространяется бесплатно и под лицензией GNU General Public License.
Скачать
Последнюю версию можно найти на странице загрузки Capture2Text, размещенной на SourceForge.
Системные требования
Поддерживаемые операционные системы:
- Windows 7
- Windows 8 / 8.1
- Windows 10
Примечание. Поддержка Windows XP была прекращена в Capture2Text v4.0.
Как запустить Capture2Text (установка не требуется)
- Распакуйте содержимое zip-файла.
- Дважды щелкните файл Capture2Text.exe. Вы должны увидеть значок Capture2Text на в правом нижнем углу экрана (хотя он может быть скрыт, и в этом случае вы нужно будет нажать на стрелку «Показать скрытые значки»).
Установка дополнительных языков OCR
По умолчанию Capture2Text поставляется со следующими языками: английский, французский, немецкий, японский, корейский, русский и испанский.
Если вы хотите установить дополнительные языки OCR, выполните следующие действия:
- Загрузите словарь соответствующего языка OCR.
- Откройте файл .zip, который вы только что загрузили, с помощью 7-Zip или аналогичной программы для распаковки.
- Перетащите все файлы, содержащиеся в zip-файле, в папку tessdata:
- Перезапустите Capture2Text.
Поддерживаются следующие языки распознавания текста:
| африкаанс (африкаанс) | греческий (элл) | одия (ори) | |||
| албанский (sqi) | гуджарати (гудж) | панджаби (амхарати) | панджаби (амхарати) | гаитянский (шляпа) | персидский (fas) |
| древнегреческий (grc) | иврит (heb) | польский (pol) | |||
| арабский (ара) | хинди (хин португальский) | por) | |||
| Ассамский (asm) | Венгерский (hun) | Пушту (pus) | |||
| Азербайджанский (aze) | Исландский (isl) | Румынский (ron) | |||
| Баскский (eus) | Индийский (inc) | Русский (rus) | |||
| Белорусский (bel) | Индонезийский (ind) | Санскрит (san) | |||
| Бенгальский (ben) | (iku)сербский (srp) | ||||
| боснийский (bos) | ирландский (gle) | сингальский (sin) | |||
| болгарский (bul) | итальянский (ita) | ksl | |||
| бирманский (mya) | японский (jpn) | словенский (slv) | |||
| каталонский (cat) | яванский (jav) | испанский (спа) | |||
| кебуано (ceb) | каннада (кан) | суахили (swa) | |||
| центральный кхмерский (khm) | казахский (каз) | шведский (swe) | |||
| чероки kir) | Сирийский (syr) | ||||
| Китайский упрощенный (chi_sim) | Корейский (kor) | Тагальский (tgl) | |||
| Китайский традиционный (chi_tra) | Курух32 ( | ) tgk) | |||
| Хорватский (hrv) | Лаосский (lao) | Тамильский (tam) | |||
| Чешский (ces) | Latin (lat) | Telugu (tel) | латышский (lav) | тайский (tha) | |
| голландский (nld) | литовский (lit) | тибетский (bod) | |||
| дзонгха (dzo) | македонский | Тигринья (тир) | |||
| Английский (англ.) | Малайский (мса) | Турецкий (тур) | |||
| Эсперанто (эпо) | Малаялам (малайский) | ||||
| Мальтийский (mlt) | Украинский (ukr) | ||||
| Финский (fin) | Marathi (mar) | Urdu (urd) | |||
| Frankish (frk) | Математика / уравнения (equ) | Узбекский (uzb) | |||
| Французский (fra) | Среднеанглийский (1100-1500) (enm) | Вьетнамский (vie) | |||
| Галицкий (glg) | Среднефранцузский (1400-1600) (frm) | Валлийский (cym) | |||
| Грузинский (kat) | Непальский (nep) | Идиш (yid) | |||
| Немецкий (deu) | Норвежский (норвежский) |
Как выполнить стандартное распознавание текста
Выполните следующие действия, чтобы выполнить стандартный захват OCR с помощью окна захвата:
- Поместите указатель мыши в верхний левый угол текста, который нужно распознать.
- Нажмите горячую клавишу OCR (Windows Key + Q), чтобы начать захват OCR.
- Переместите указатель мыши, чтобы изменить размер синего поля захвата над текстом, который нужно OCR. Вы можете удерживать правую кнопку мыши и перетаскивать, чтобы переместить весь блок захвата.
- Нажмите горячую клавишу OCR еще раз (или щелкните левой кнопкой мыши или нажмите ENTER), чтобы завершить захват OCR. Текст OCR будет помещен в буфер обмена, и появится всплывающее окно, показывающее захваченный текст (всплывающее окно может быть отключено в настройках).
Как и для всех снимков OCR, вы должны вручную выбрать язык, который вы хотите OCR, в настройках.
Чтобы изменить язык оптического распознавания текста, щелкните правой кнопкой мыши значок Capture2Text на панели задач, выберите параметр «Язык оптического распознавания текста», а затем выберите нужный язык.
Для быстрого переключения между 3 языками используйте клавиши быстрого доступа к языку OCR: Клавиша Windows + 1, Клавиша Windows + 2 и Клавиша Windows + 3. Языки быстрого доступа можно указать в настройках.
Если выбран китайский или японский язык, необходимо указать текст направление (вертикальное / горизонтальное / авто) с использованием направления текста горячая клавиша: Windows Key + O. Если выбрано авто, при ширина захвата более чем вдвое превышает высоту, в противном случае будет вертикальное использовал. Направление текста также влияет на то, как фуригана удаляется из японского текста.
(для японского) Capture2Text попытается автоматически удалить фуригану.
Как выполнить оптическое распознавание текста строки
Capture2Text может автоматически захватывать строку текста, ближайшую к указателю мыши.
Выполните следующие действия, чтобы выполнить оптическое распознавание текста строки:
- Наведите указатель мыши на строку текста, которую нужно захватить, или рядом с ней.
- Нажмите горячую клавишу Text Line OCR Capture (Windows Key + E).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR прямой текстовой строки
Capture2Text может автоматически захватывать строку текста, начиная с символа, ближайшего к указателю мыши, и продвигаясь вперед.
Выполните следующие действия, чтобы выполнить захват OCR прямой текстовой строки:
- Наведите указатель мыши на символ, с которого нужно начать, или рядом с ним.
- Нажмите горячую клавишу прямого ввода текста в строку OCR (Клавиша Windows + W).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR пузырьков
Capture2Text может автоматически захватывать текст, содержащийся в пузыре речи / мысли комиксов, если пузырек полностью закрыт.
Выполните следующие действия, чтобы выполнить захват OCR в виде пузырьков:
- Поместите указатель мыши в пустую часть пузыря (не на текст).
- Нажмите горячую клавишу «Захват OCR» (Клавиша Windows + S).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как указать активный язык OCR
Чтобы указать активный язык OCR, щелкните правой кнопкой мыши значок в области уведомлений, выберите Язык OCR и выберите языки OCR из списка:
Перевод
Чтобы включить функцию перевода, сначала откройте диалоговое окно настроек (щелкните правой кнопкой мыши значок в области уведомлений и выберите «Настройки… «) и щелкнув вкладку» Перевести «.
Установите флажок «Добавить перевод в буфер обмена», чтобы добавить переведенный текст в буфер обмена с помощью предоставленного разделителя. Установите флажок «Показать перевод во всплывающем окне», чтобы отображать переведенный текст рядом с текстом OCR во всплывающем окне. Например:.Каждый установленный язык OCR может быть переведен на другой язык.
Примечание 1. Некоторые языки OCR не поддерживают перевод.Неподдерживаемые языки отображаться не будут.
Примечание 2: Для перевода требуется доступ в Интернет.
Настройки
Щелкните правой кнопкой мыши значок Capture2Text на панели задач в правом нижнем углу экрана и затем выберите параметр «Настройки …», чтобы открыть диалоговое окно «Настройки». Вы можете навести указатель мыши на многие метки параметров, чтобы отобразить полезную подсказку, объясняющую этот параметр.
Вкладка «Горячие клавиши» позволяет вам указать, какие клавиши и модификаторы использовать для каждой горячей клавиши.Чтобы отключить горячую клавишу, выберите «
Текущий язык OCR: укажите используемый активный язык OCR. Вы также можете указать активный язык OCR в меню значка на панели задач.
Quick-Access Languages: языки, используемые для каждой из горячих клавиш быстрого доступа.
Белый список: Сообщите механизму OCR, что захваченный текст будет содержать только указанные символы.
Черный список: Сообщите механизму распознавания текста, что захваченный текст никогда не будет содержать указанные символы.
Ориентация текста: ориентация текста, который будет захвачен. Этот параметр используется только в том случае, если в качестве активного языка распознавания задан китайский или японский. Если выбран параметр «Авто», будет использоваться горизонтальное положение, если ширина захвата более чем в два раза превышает высоту, в противном случае будет использоваться вертикальное. Направление текста также влияет на то, как фуригана удаляется из японского текста. Вы также можете указать ориентацию текста в меню значка на панели задач или с помощью горячей клавиши «Ориентация текста».
Файл конфигурации Tesseract: расширенная функция, позволяющая указать файл конфигурации Tesseract.
Trim Capture: во время предварительной обработки OCR обрезайте захваченное изображение до пикселей переднего плана и добавьте тонкую границу. Точность распознавания текста будет более стабильной и может даже улучшиться.
Deskew Capture: во время предварительной обработки OCR попытайтесь компенсировать наклон текста, обнаруженный при захвате OCR.
Содержит параметры для настройки автоматических захватов. Чтобы получить дополнительную информацию, наведите указатель мыши на метки параметров.
Позволяет указать цвета поля захвата OCR.Прозрачность можно изменить, настроив значение «Альфа-канал» в диалоговом окне выбора цвета.
Позволяет указать положение, цвет и шрифт предварительного просмотра. Вы можете отключить предварительный просмотр, сняв флажок «Показать окно предварительного просмотра».
Сохранить в буфер обмена: сохранить захваченный текст OCR в буфер обмена.
Показать всплывающее окно: показать захваченный текст OCR во всплывающем окне:
Сохранять разрывы строк: установите этот флажок, если вы не хотите, чтобы символы возврата каретки и перевода строки удалялись из захваченного текста.
Logging: позволяет сохранять все записи в указанный файл в указанном формате. В формате могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}, $ {linebreak}, $ {tab}. Формат по умолчанию: «$ {capture} $ {linebreak}».
Вызов исполняемого файла: расширенная функция, позволяющая вызывать исполняемый файл после завершения распознавания текста. Могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}. Пример:
C: \ Anaconda3 \ python.exe "C: \ Scripts \ test.py" "$ {capture}" "$ {translation}"
Позволяет выполнять замену текста. Поддерживает регулярные выражения. Текст слева будет заменен текстом справа. Для каждого языка OCR могут быть указаны разные замены.
См. Раздел перевода.
Эта страница позволяет вам включить функцию преобразования текста в речь, установить громкость и выбрать параметры (голос, скорость, высота тона) для использования для каждого языка OCR.
Включить преобразование текста в речь: включить преобразование текста в речь при захвате текста.
Если этот параметр отмечен и голос не установлен на «
Громкость: основная громкость функции преобразования текста в речь. Применимо ко всем языкам.
Язык OCR: укажите параметры речи для выбранного языка OCR.
- Скорость: Скорость преобразования текста в речь.
- Pitch: Высота голоса для преобразования текста в речь.
- Голос: Голос для преобразования текста в речь. Установите значение «
», чтобы отключить функцию преобразования текста в речь только для выбранного языка OCR.
Предварительный просмотр: предварительный просмотр текущей скорости, высоты тона и голоса.
Параметры командной строки
Использование: Capture2Text_CLI.exe [параметры]
Capture2Text может использоваться для распознавания файлов изображений или части экрана.Примеры:
Capture2Text_CLI.exe --screen-rect "400 200 600 300"
Capture2Text_CLI.exe --vertical -l "Китайский - упрощенный" -i img1.png
Capture2Text_CLI.exe -i img1.png -i img2.jpg -o result.txt
Capture2Text_CLI.exe -l японский -f "C: \ Temp \ image_files.txt"
Capture2Text_CLI.exe --show-languages
Опции:
- ?, -h, --help Отображает эту справку.
-v, --version Отображает информацию о версии.
-b, --line-breaks Не удалять разрывы строк из текста OCR.-d, --debug Выводить захваченное изображение и предварительно обработанное
изображение для отладки.
--debug-timestamp Добавить метку времени для отладки изображений, когда
используя параметр -d.
-f, --images-file <файл> Файл, содержащий пути файлов изображений к
OCR. Один путь на строку.
-i, --image <файл> Файл изображения для OCR.Вы можете OCR несколько
файлы изображений, например: "-i -i
-i "
-l, --language <язык> используемый язык распознавания текста. Чувствительный к регистру.
По умолчанию "английский". Использовать
опция --show-languages для вывода списка установленных
Языки OCR.
-o, --output-file <файл> Выводить текст OCR в этот файл.Если не
указано, будет использоваться стандартный вывод.
--output-file-append Добавить в файл при использовании параметра -o.
-s, --screen-rect <"x1 y1 x2 y2"> Координаты прямоугольника, определяющего область
экрана в OCR.
-t, --vertical OCR вертикальный текст. Если не указано,
предполагается горизонтальный текст.
-w, --show-languages Показать установленные языки, которые можно использовать
с опцией "--language".--output-format Формат для использования при выводе текста OCR.
Вы можете использовать эти токены:
$ {capture}: текст OCR.
$ {linebreak}: разрыв строки (\ r \ n).
$ {tab}: символ табуляции.
$ {timestamp}: время для этого экрана или каждого
файл был обработан.$ {file}: файл, который был обработан или
экран прямоугольник.
Формат по умолчанию - "$ {capture} $ {linebreak}".
--whitelist <символы> Распознавать только указанные символы.
Пример: «0123456789».
--blacklist <символы> Не распознавать указанные символы.
Пример: «0123456789».--clipboard Выводить текст OCR в буфер обмена.
--trim-capture Во время предварительной обработки OCR выполняется обрезка
изображение в пиксели переднего плана и добавьте тонкий
граница.
--deskew Во время предварительной обработки OCR попытаться
компенсировать наклон текста.
--scale-factor Коэффициент масштабирования для использования во время предварительной обработки.Диапазон: [0,71, 5,0]. По умолчанию - 3,5.
--tess-config-file <файл> (Дополнительно) Путь к конфигурации Tesseract
файл.
------
Для Capture2Text.exe (в отличие от Capture2Text_CLI.exe) вы можете указать дополнительную опцию:
--portable Хранить файл настроек .ini в том же каталоге
как.EXE файл.
Устранение неполадок и часто задаваемые вопросы
- Я получаю сообщение об отсутствии файла DLL, когда дважды щелкаю Capture2Text.exe.
Решение: установите распространяемый пакет Visual Studio 2015.
- Capture2Text вообще не работает. Что я могу сделать?
Возможные решения:
Убедитесь, что вы разархивировали Capture2Text.Поищите в Google, если не знаете, как разархивировать файл.
Убедитесь, что ваше антивирусное программное обеспечение не блокирует Capture2Text. Обратитесь к документации, прилагаемой к вашему антивирусному программному обеспечению.
Убедитесь, что вы скачали последнюю версию с SourceForge.
Перезагрузите компьютер.
Попросите внука помочь вам 🙂
- Я обнаружил ошибку!
Отлично! Создайте заявку и опишите ошибку.
- Я хочу сделать предложение.
Отлично! Создайте заявку и опишите свое предложение.
- Capture2Text выводит символы мусора.
Решение: укажите правильный язык OCR.
- Интересующий меня язык не отображается в меню языка распознавания текста.
Прочтите Установка дополнительных языков распознавания текста.
- Я не вижу значок Capture2Text на панели задач.персонаж).
- Я щелкнул значок Capture2Text на панели задач, но он ничего не сделал.
Вместо этого щелкните его правой кнопкой мыши.
- Capture2Text не работает на моем Mac.
Capture2Text — это программное обеспечение только для Windows. Если у вас есть технический опыт, не стесняйтесь портировать его (но не просите меня помочь).
- Где деинсталлятор?
Нет ни одного.