Быстрый способ извлечения текста из PDF-изображений
Иногда бывает нужно отредактировать отсканированный PDF-документ. Например, изменить размер шрифта и изображений, или извлечь текст из отсканированных PDF-документов. В этой статье мы покажем вам наиболее эффективный способ извлечения текста из отсканированного PDF-файла с помощью PDFelement.
PDFelement позволяет с легкостью распознавать и редактировать текст отсканированных PDF-документов, а также извлекать текст из PDF-файлов и PDF-изображений с использованием специальных инструментов для извлечения текста из PDF. Кроме того, функция распознавания текста доступна на 20 языках мира, что существенно расширяет ваши возможности.
Теперь давайте ознакомимся с некоторыми другими функциями данного программного обеспечения и практическим руководством по данным функциям.
- Преобразование PDF в различные форматы: Excel, TXT, PowerPoint, Word, изображения и многие другие типы файлов.
- Редактирование содержимого PDF-файла: шрифтов, страниц, изображений, текстов и даже водяных знаков.
- Создание PDF из чистого документа, HTML, существующего PDF-файла, изображений и т.д.
- Защита вашего PDF-документа с помощью паролей и ограничения доступа к документам.
- Заполнение PDF-форм, в том числе отсканированных PDF-файлов. Возможность создания собственной PDF-формы с использованием специальных инструментов.
Инструкция по извлечению текста из PDF
Для извлечения текста из PDF с помощью PDFelement необходимо выполнить следующие действия.
Шаг 1. Добавление PDF-файлов в программу
Загрузите и установите PDFelement. Затем откройте PDF-файлы, из которых необходимо извлечь текст, нажав кнопку «Открыть файл».
Затем откройте PDF-файлы, из которых необходимо извлечь текст, нажав кнопку «Открыть файл».
Шаг 2. Извлечение текста из PDF-файла
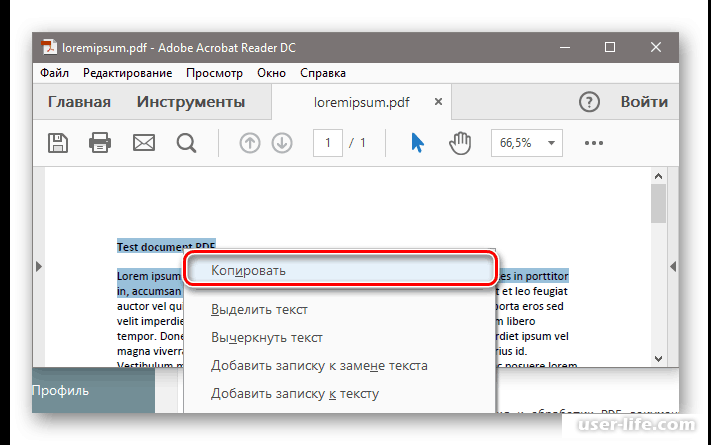
После открытия файла перейдите во вкладку «Редактировать» и нажмите кнопку «Выбрать». Чтобы извлечь нужный текст, щелкните правой кнопкой мыши по нужному вам фрагменту и выберите «Копировать текст».
Как извлечь текст из PDF-изображения
Шаг 1. Откройте PDF-файл, созданный на основе изображений
После установки PDFelement откройте программу и выполните распознавание текста в вашем PDF-файле. Для выбора и открытия отсканированного файла нажмите «Открыть файл».
Шаг 2. Выполнить распознавание текста
После открытия файла программа обнаружит, что это отсканированный документ, и предложит вам выполнить распознавание символов (OCR). Нажмите кнопку «Выполнить OCR» на верхней желтой панели, затем выберите язык распознавания текста и нажмите «OK».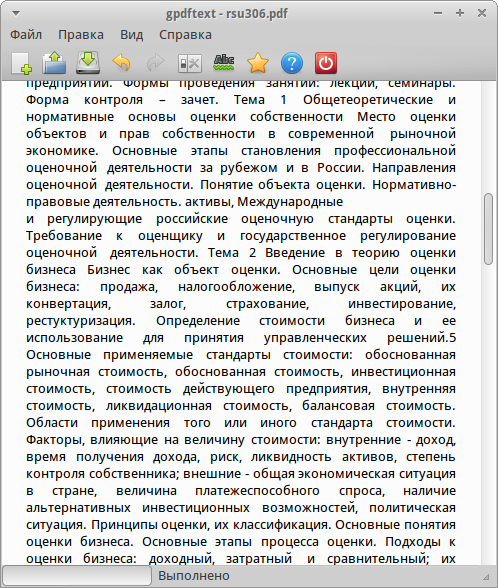
Шаг 3. Извлечение текста из PDF-изображения
После выполнения OCR вы сможете извлечь текст из PDF. Для этого перейдите во вкладку «Редактирование» и нажмите кнопку «Редактировать». Выделите текст, который необходимо извлечь, щелкните правой кнопкой мыши и выберите «копировать».
Также вы можете конвертировать PDF в формат Word. Нажмите на кнопку «В Word», расположенную под вкладкой «Главная». Чтобы преобразовать PDF в формат Word, нажмите кнопку «Сохранить» во всплывающем окне. После того, как содержимое PDF будет представлено в виде редактируемого документа Word, вы сможете извлекать содержимое из преобразованного файла.
Как вставить отсканированный текст или изображения в Word
Если вы хотите вставить в документ Word печатный документ или рисунок, это можно сделать несколькими способами.
Примечание: Если вы ищете инструкции по подключению сканера или скопатора к Microsoft Windows, посетите веб-сайт поддержки изготовителя вашего устройства.
Сканирование изображения в Word
Для сканирования изображения в документ Word можно использовать сканер, многофункциональный принтер, копировальный аппарат с возможностью сканирования или цифровую камеру.
-
Отсканируйте изображение или сделайте его снимок с помощью цифровой камеры или смартфона.
-
Сохраните изображение в стандартном формате, таком как JPG, PNG или GIF. Поместите его в папку на своем компьютере.
-
В Word, поместите курсор туда, куда вы хотите вставить отсканированное изображение, а затем на вкладке Вставка нажмите кнопку
-
Выберите отсканированный рисунок в диалоговом окне и нажмите кнопку Вставить.
Вставка отсканированного текста в Word
Для сканирования документа в Microsoft Word проще всего использовать наше бесплатное приложение Office Lens на смартфоне или планшете. Оно получает снимок документа с помощью камеры устройства и сохраняет его в виде редактируемого документа непосредственно в Word. Она доступна бесплатно на iPad ,iPhone, Windows Phone и Android.
Оно получает снимок документа с помощью камеры устройства и сохраняет его в виде редактируемого документа непосредственно в Word. Она доступна бесплатно на iPad ,iPhone, Windows Phone и Android.
Если вы не хотите использовать Office Lens, лучше всего отсканировать документ в формате PDF с помощью программного обеспечения сканера, а затем открыть его в Word.
-
В Word выберите Файл > Открыть.
-
Перейдите к папке, в которой хранится PDF-файл, и откройте его.
-
Word откроет диалоговое окно, в котором нужно подтвердить импорт текста PDF-файла. Нажмите кнопку ОК, Word импортировать текст. Word постарается сохранить форматирование текста.
Дополнительные сведения см. в статье Редактирование содержимого PDF-документа в Word.
Примечание: Точность распознавания текста зависит от качества сканирования и четкости отсканированного текста. Рукописный текст редко распознается, поэтому для лучших результатов сканируйте печатные материалы. Всегда проверяйте текст после его открытия в Word, чтобы убедиться, что он правильно распознан.
Кроме того, со сканером может поставляться приложение для распознавания текста (OCR). Обратитесь к документации своего устройства или к его производителю.
Остались вопросы о Word?
Задайте их на форуме сообщества Word Answers
Помогите нам улучшить Word
У вас есть предложения, как улучшить Word? Дайте нам знать, предоставив нам отзыв. Дополнительные сведения см. в Microsoft Office.
См. также
4 способа конвертировать PDF в Word DOCX в Mac OS
Получали ли вы когда-нибудь файл PDF, который хотели бы преобразовать в формат Word DOC или DOCX? Обычно это необходимо, когда у вас есть PDF-файл, в котором вы хотите немного отредактировать содержимое, возможно, резюме или диссертацию, но, конечно, PDF-файл может быть более сложным.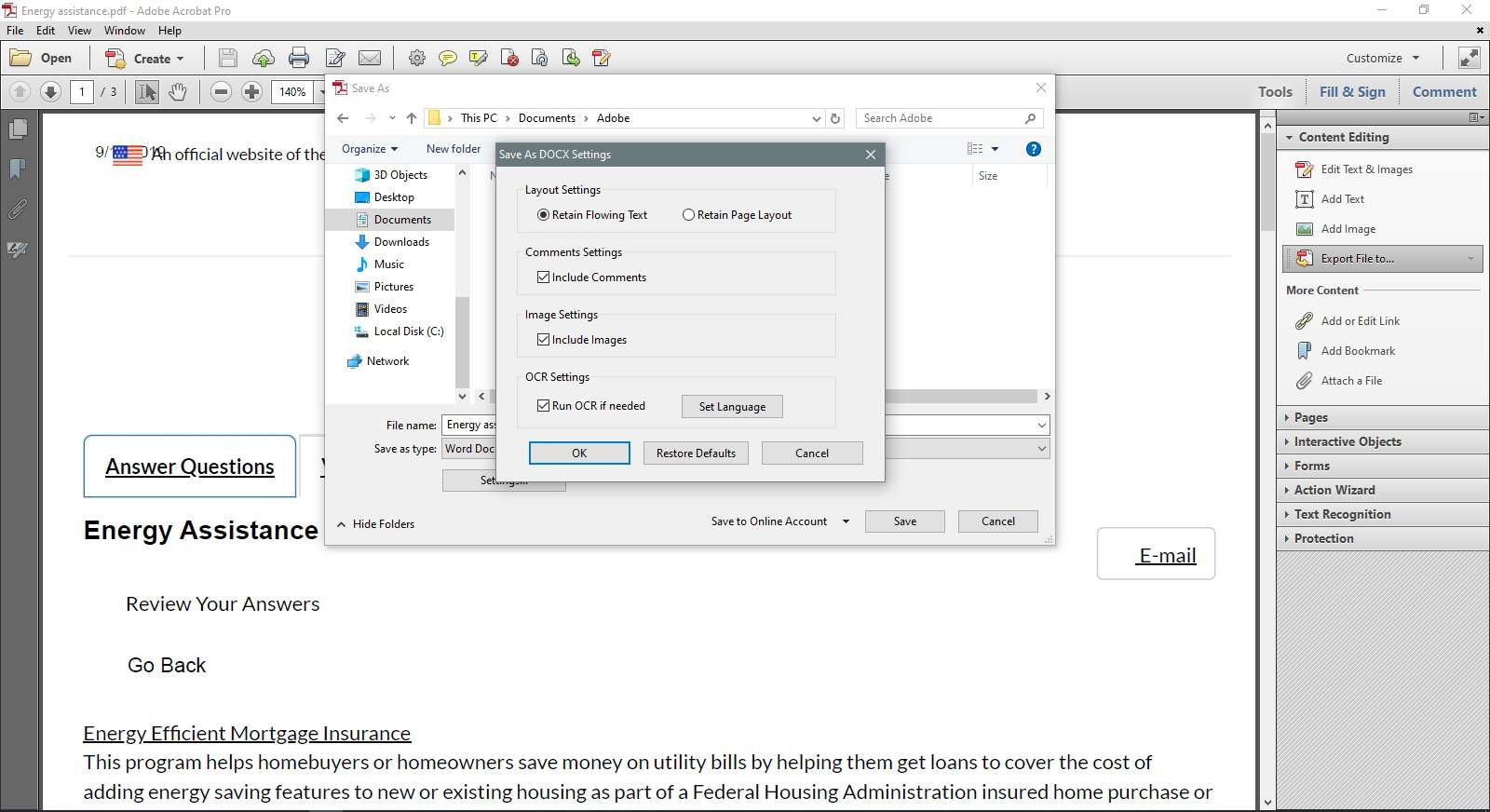
Сначала мы рассмотрим, как вы можете использовать Google Docs для преобразования файла в формат Word, а затем расскажем, как потенциально можно извлечь текст из PDF-документа, который затем можно преобразовать в DOC или DOCX самостоятельно. Далее мы покажем вам платное решение от Adobe, которое представляет собой тщательный и сложный инструмент для преобразования PDF в DOC, который лучше всего подходит для профессиональных приложений, и альтернативное собственное приложение для Mac, которое предлагает аналогичные функции. Наконец, мы рассмотрим более автоматизированный метод, который является расширением первого подхода к извлечению текста, который может преобразовывать PDF в текстовые файлы, которые вы можете редактировать, что, возможно, наиболее подходит для случайного использования и с простыми файлами PDF.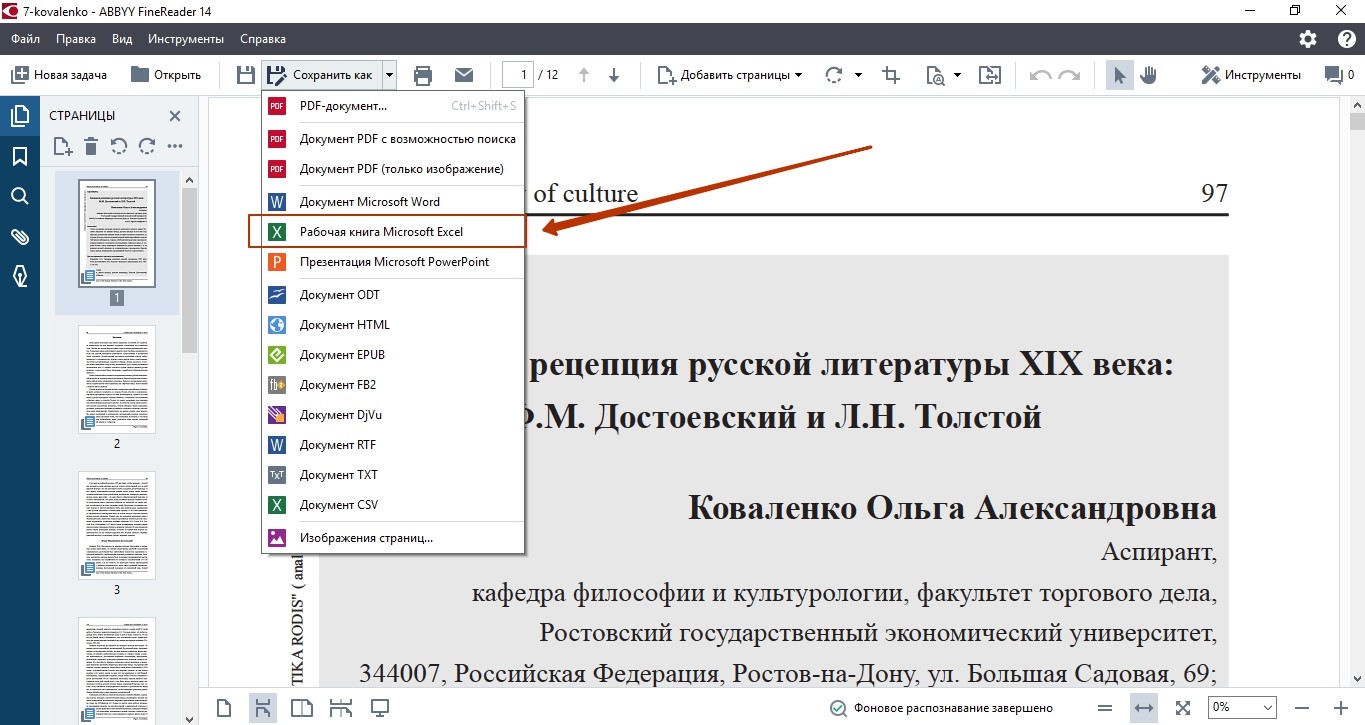
Имейте в виду, что если файл, о котором идет речь, защищен паролем, вам необходимо сначала удалить пароль файла PDF, а затем запустить процесс преобразования.
Вариант 1. Преобразование файлов PDF в DOCX с помощью Документов Google
Интернет-документы Google имеют довольно впечатляющие встроенные инструменты преобразования PDF, как мы уже обсуждали ранее, и они работают довольно хорошо.
- Перейдите на сайт Google Документов и войдите в систему с учетной записью Google
- Нажмите кнопку «Загрузить» и выберите нужный файл PDF на Mac.
- Откройте меню «Файл» в Документах Google и выберите «Загрузить как», затем выберите «Microsoft Word (DOCX)» и сохраните файл Word DOCX на Mac.
Документы Google действительно хороши в преобразовании файлов PDF в пригодный для использования формат DOCX и часто очень хорошо сохраняют форматирование. Затем вы можете открыть файл DOCX в Microsoft Office или в приложении Apple Pages, чтобы убедиться, что преобразование прошло гладко.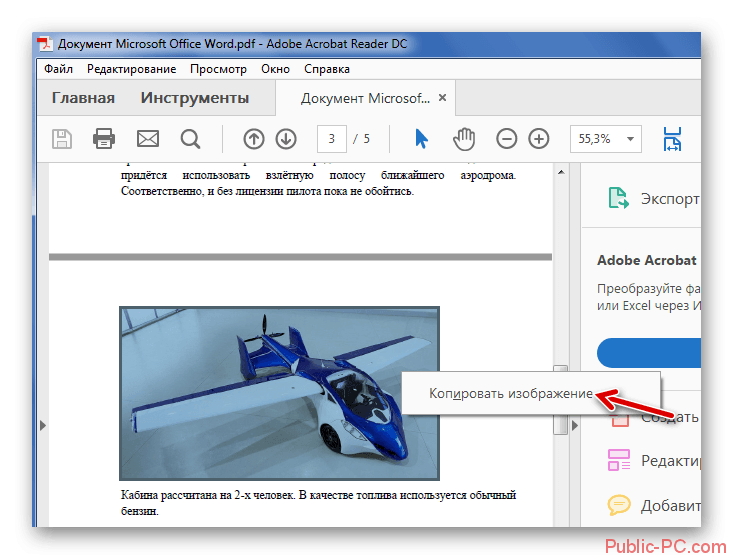
Основным недостатком Google Docs является то, что для его использования требуется доступ в Интернет и доступ в Интернет, в противном случае это бесплатно и легко попробовать, и это может сработать для вас.
Вариант 2: скопировать текст из PDF и вставить в DOC в Mac OS X
Вы могли догадаться, что копирование и вставка достаточно эффективны для извлечения текста из файла PDF и его преобразования в файл DOC или DOCX? Это не совсем автоматическое преобразование PDF в DOC, и это довольно низкотехнологично, но если рассматриваемый PDF-файл в основном (или полностью) основан на тексте, он работает на удивление хорошо. Кроме того, вы можете преобразовать файл во что угодно, будь то doc, docx, rtf или даже pdf.
- Откройте файл PDF в приложении предварительного просмотра на Mac.
- С помощью курсора мыши выделите текст, который хотите скопировать, и нажмите Command + C.
- Перейдите в Microsoft Office, Word, Pages или любой текстовый редактор по выбору, вставьте его с помощью Command + V в документ и сохраните как обычно.

Вы также можете использовать Command + A для Select All, если хотите попытаться скопировать все содержимое документа.
Очень низкотехнологичный, правда? Но знаете что, это может сработать! Иногда это отлично работает, иногда не работает, это во многом зависит от файла PDF, из которого вы пытаетесь скопировать и получить текст. Затем вы можете сохранить файл как файл DOC или DOCX, когда закончите в Pages, Microsoft Office или в другом приложении.
Очевидно, что это наименее технический подход, и с такими минимальными усилиями, по крайней мере, стоит попробовать, прежде чем вы попробуете другие, более сложные методы, или прежде чем вкладывать деньги в продукт Adobe.
Вариант 3. Используйте экспорт PDF в Doc / DOCX / веб-приложение из Adobe
Безусловно, самый качественный вариант — это платный вариант от Adobe, который для начала создал формат PDF, поэтому неудивительно, что у них есть продукт, который позволяет конвертировать их формат файлов во что-то другое. Предложение Adobe представляет собой веб-приложение и поэтому работает в Mac OS X, iOS, Windows или Linux и может преобразовывать файл PDF в файлы DOC, DOCX, RTF или даже Excel XLSX.
Предложение Adobe представляет собой веб-приложение и поэтому работает в Mac OS X, iOS, Windows или Linux и может преобразовывать файл PDF в файлы DOC, DOCX, RTF или даже Excel XLSX.
Инструмент Adobe Converter, вероятно, является лучшим решением, если у вас есть тонны файлов PDF для преобразования и вам нужно сделать что-то с максимально возможным качеством, но цена кажется немного высокой просто для преобразования одного или двух файлов из PDF в Word, так что вы ‘ Придется определить, стоит оно того или нет.
К сожалению, самым большим недостатком этого решения Adobe является отсутствие возможности пробного запуска или тестирования, вам нужно заплатить, прежде чем вы сможете выяснить, работает оно или нет. Это звучит не слишком хорошо для многих пользователей, поэтому следующий вариант может быть более привлекательным для многих пользователей Mac, которые хотят выполнить преобразование файлов PDF.
Вариант 3B: попробуйте конвертер PDF в DOCX / DOC и т. Д.
Существует множество других платных вариантов, но если вы собираетесь искать PDF-конвертеры, которые не являются решением Adobe, вам следует стремиться к одному с возможностями OCR (оптическое распознавание символов), поскольку оно может помочь идентифицировать и более точно извлекать содержимое файла PDF. Это никогда не бывает особенно дешевыми решениями, но, к счастью, многие из них включают бесплатные пробные версии, так что вы можете провести тестовый запуск, чтобы определить, будут ли они работать для ваших нужд. Мы обсудим один из этих вариантов, называемый CISDEM PDF Converter OCR, но есть и многие другие.
- CISDEM PDF Converter OCR стоит 60 долларов США, доступна бесплатная пробная версия. позволяет выполнить тестовый запуск извлечения PDF, загрузить приложение и загрузить образ диска
- Перетащите PDF-файл, который хотите преобразовать, в открытое приложение.
- При необходимости отрегулируйте указанный PDF-файл и выберите выходной формат.
- Нажмите «Предварительный просмотр» или «Преобразовать», когда закончите, хорошо посмотрите экспортированный файл DOC / DOCX.
В нескольких тестах с различными файлами PDF это решение работает очень хорошо для извлечения всех данных из PDF и преобразования их в расширенные форматы файлов DOCX, но, как это часто бывает с этим типом преобразования файлов, точное форматирование документа часто теряется при сложных планировках. Это намного превосходит многие другие инструменты преобразования PDF, и с довольно простыми документами PDF результат почти идеален. Он также имеет то преимущество, что не требует доступа в Интернет или веб-браузера, поскольку приложение является родным для Mac. По сравнению с методами копирования и вставки или методами Automator он намного лучше, но вы действительно захотите протестировать его с помощью одного или двух пробных документов, прежде чем самостоятельно переходить к приложению.
Вариант 4: извлечение текста из файлов PDF с помощью Automator для Mac OS X
По сути, это автоматизированный подход к методу копирования и вставки, который мы обозначили как первый трюк, он не выполняет истинного преобразования PDF в Word DOC, но пытается извлечь текст и вывести его как RTF или TXT.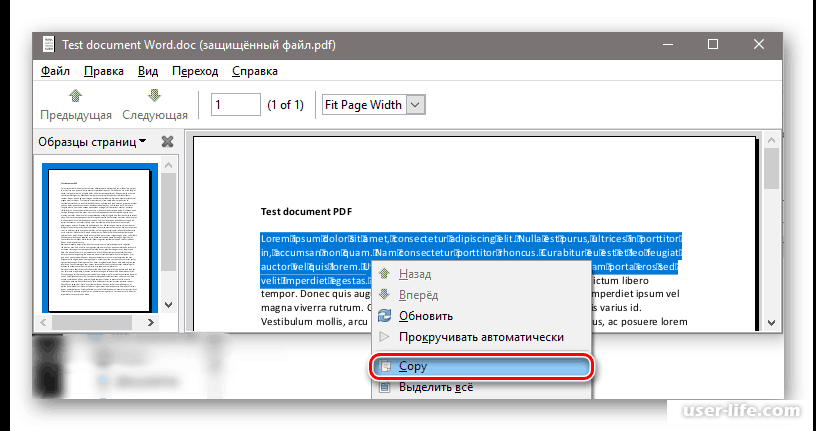 файл, который при желании можно сохранить вручную в формате Word DOC или DOCX. Automator считается немного более продвинутым, поскольку он в основном создает автоматический макрос для задачи, которую вы настраиваете, но это не особенно сложно, если вы следуете инструкциям по настройке:
файл, который при желании можно сохранить вручную в формате Word DOC или DOCX. Automator считается немного более продвинутым, поскольку он в основном создает автоматический макрос для задачи, которую вы настраиваете, но это не особенно сложно, если вы следуете инструкциям по настройке:
- Откройте Automator на Mac (в папке / Applications /) и создайте новый рабочий процесс, приложение или службу.
- Найдите и выберите «Получить выбранные элементы поиска», если вы хотите использовать это как услугу из контекстного меню, вызываемого правой кнопкой мыши (или используйте «Спросить элементы поиска», если вы хотите вызвать открытое диалоговое окно при запуске приложения или службы) , затем перетащите его в правую часть экрана действий
- Затем найдите «Извлечь текст PDF» и перетащите его под свой предыдущий выбор, затем выберите, хотите ли вы, чтобы вывод текста PDF был «Обычный текст» (TXT) или «Форматированный текст» (RTF).
- Нажмите кнопку «Выполнить», чтобы выполнить тестовое действие Automator Action, выберите файл PDF и позвольте ему преобразовать его в текстовый документ.
- Откройте экспортированный файл PDF и просмотрите его содержимое, чтобы определить, является ли это удовлетворительным методом.
Вам действительно нужно хорошенько взглянуть на экспортный документ PDF, чтобы определить, удовлетворительно ли полученное содержимое. Для стилизованного файла PDF вы можете заметить, что некоторые буквы и символы отсутствуют, но суть текста присутствует, как в этом примере ниже :
Опять же, это не сильно отличается от Варианта 1 копирования и вставки данных PDF в DOC или текстовый файл самостоятельно, но это полезно, если вы работаете со многими документами, поскольку автоматизирует этот процесс. Помните, что чем проще PDF-файл, тем лучше будет работать этот метод. Сложные PDF-файлы или PDF-файлы изображений не будут работать, поскольку текст не распознается (поскольку здесь нет OCR, это просто извлечение текста).
Почему бы не открыть PDF-файл в приложениях Pages, Office, TextEdit или XYZ?
Возможно, вы уже заметили, что вы не можете просто попытаться открыть файл PDF с помощью обычного текстового редактора в Mac OS X или любой другой ОС, так как он просто откроет тарабарщину. Вот почему вы должны либо извлечь содержимое PDF-файла вручную, а затем импортировать его в формат файла по вашему выбору, либо использовать доступные инструменты преобразования. Например, вот что происходит, когда вы пытаетесь загрузить PDF-файл в текстовый редактор Mac OS X, ни один из PDF-файлов не отображается без преобразования, копирования / вставки или извлечения, все отображается тарабарщиной:
Вот почему вы должны либо извлечь содержимое PDF-файла вручную, а затем импортировать его в формат файла по вашему выбору, либо использовать доступные инструменты преобразования. Например, вот что происходит, когда вы пытаетесь загрузить PDF-файл в текстовый редактор Mac OS X, ни один из PDF-файлов не отображается без преобразования, копирования / вставки или извлечения, все отображается тарабарщиной:
Сработал ли один из вышеперечисленных методов для вашей конверсии? Сработал ли простой метод извлечения текста, чтобы захватить данные PDF и превратить их в DOC? Вы выбрали продукт Adobe? Знаете ли вы о другом решении для преобразования файлов PDF в формат DOC и DOCX в Mac OS X (или через Интернет)? Расскажите нам о своем опыте в комментариях!
Распознать текст из PDF в WORD
Автор Евгения На чтение 11 мин. Опубликовано
Распознать текст из PDF в WORD
OCR распознавание текста из PDF и изображений
Как работает наш OCR сервис
Что такое OCR
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ? Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Оптическое распознавание символов или OCR – это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие “машинного распознавания текста” не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
Метод сопоставления матриц
Первый метод – это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, – это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения». Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию – использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR – это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
 Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Преобразование PDF в текстовый файл
Как отредактировать текст из PDF-файла? Преобразуйте PDF в текстовый документ при помощи функции оптического распознавания символов (OCR). Если вам надо извлечь текст, студия PDF2Go — идеальное решение.

- Загрузите PDF-документ.
- Нажмите на «Сохранить изменения».
Оставайтесь на связи:
Преобразуйте PDF в текст при помощи функции OCR
бесплатно в любом месте
Преобразование PDF в текстовый файл
Вам доводилось редактировать текст в PDF-файле? Мы знаем, как справиться с этой задачей. Преобразуйте PDF-документ в простой текстовый файл при помощи функции оптического распознавания символов (OCR).
Просто загрузите PDF, а мы сделаем всё остальное. После загрузки документа на PDF2Go мы извлечём текст при помощи функции OCR и создадим файл формата TXT.
Просто и безопасно
PDF2Go не занимает место в телефоне и не представляет угрозы для компьютера.
Этот конвертер с функцией OCR работает онлайн и не требует регистрации или установки приложения для извлечения текста из PDF-файлов.
Для сканов и не только
Вам больше не надо перепечатывать отсканированную книгу или статью вручную. Наш онлайн-инструмент позволяет преобразовать PDF-файл и извлечь текст из любого скана (даже с картинки!).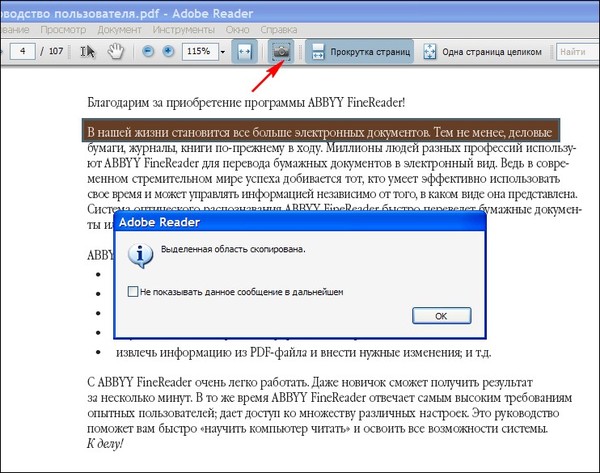
Если у вас есть PDF, в котором нельзя редактировать текст, воспользуйтесь нашим конвертером, чтобы преобразовать документ в текстовый файл формата TXT.
Переживаете за безопасность?
Когда загружаешь PDF на сайт для преобразования в текстовый формат, последнее, о чём хочется беспокоиться, — что станет с файлом. Мы избавим вас от сомнений.
Все права остаются за вами, никто не просматривает содержимое файлов. Читайте подробности в Политике конфиденциальности.
Что можно преобразовать?
Этот онлайн-конвертер отвечает поставленной задаче: вы можете преобразовать PDF в текстовый формат. Из любого PDF-файла можно получить редактируемый текст.
Из:
В:
Текстовый файл TXT
Оптическое распознавание символов
Всё, что вам потребуется для преобразования PDF-файла на сайте PDF2Go — это надёжное подключение к сети и браузер. Приложение работает с любого устройства. Конвертируйте PDF-файлы в формат TXT:
- дома
- на работе
- в пути
- в любом удобном месте
Вам надо сконвертировать и скачать хотя бы один файл, чтобы оценить конвертацию
Конвертировать PDF в Word онлайн бесплатно
Перетащите PDF в это окно –>
| Или нажмите сюда и выберите файл на компьютере |
Нажмите для загрузки
Как конвертировать PDF в Word
На этом сайте вы можете абсолютно бесплатно перевести PDF в Word. Конвертация происходит очень просто.
Конвертация происходит очень просто.
Шаг 1. Загрузите PDF документ на сайт. Это можно сделать простым перетаскиванием или с помощью клика по конвертеру (откроется файловый менеджер). Обратите внимание, что к конвертации принимаются только файлы с расширением .pdf.
| Загрузите PDF в это окно | Подождите, пока файл зальется на сервер |
Шаг 2. Дождитесь своей очереди. Очереди может и не быть. Но часто, особенно днем, файлы конвертируют одновременно несколько пользователей. А поскольку преобразование PDF в Word является довольно ресурсоемкой операцией, то все файлы выстраиваются в очередь и конвертируются по одному. Обычно, очередь занимает не больше 2-5 минут.
| Процесс конвертации PDF в Word |
Шаг 3. Скачайте готовый Word файл. После окончания конвретации вы можете сохранить готовый Word в формате .doc. Обратите внимание, что файлы удаляются с нашего сервера сразу после того, как вы покидаете сайт.
Скачайте готовый Word файл. После окончания конвретации вы можете сохранить готовый Word в формате .doc. Обратите внимание, что файлы удаляются с нашего сервера сразу после того, как вы покидаете сайт.
| Word успешно сконвертирован |
Какие PDF файлы можно преобразовать?
Конвертер pdf2word поддерживает все виды PDF файлов, кроме отсканированных картинок. Поскольку распознавание текста пока не поддерживается, то преобразование в текст сканов и фотографий в данный момент не доступно. Мы работаем над этой функцией и собираемся ввести ее в самое ближайшее время.
Остальные PDF документы можно конвертировать без проблем. Особенно наш онлайн конвертер пригодится представителям бизнеса, которым постоянно требуется переводить в формат Word прайс-листы, договора и прочее. Преимущество .doc файлов перед PDF заключается в том, что их можно легко редактировать и отправлять своим деловым партнерам.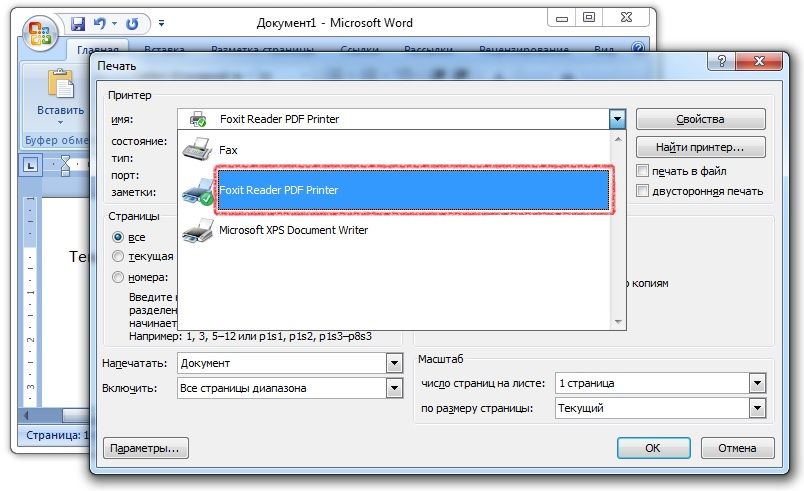 Поэтому, вместо того, чтобы заново создавать на компьютере какой-либо документ с изменениями, можно просто сделать Word из PDF онлайн.
Поэтому, вместо того, чтобы заново создавать на компьютере какой-либо документ с изменениями, можно просто сделать Word из PDF онлайн.
Конвертировать PDF в WORD
Он-лайн конвертер документов
Конвертируйте ваши файлы Portable Document Format в Microsoft Word Open XML Document с помощью этого конвертера PDF в WORD.
Ошибка: количество входящих данных превысило лимит в 10.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил лимит в 100 MB.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил абсолютный лимит в 8GB.
Для платных аккаунтов мы предлагаем:
- Вплоть до 8GB общего размера файла за один сеанс конвертирования 200 файлов на одно конвертирование Высокий приоритет и скорость конвертирования Полное отсутствие рекламы на странице Гарантированный возврат денег
- До 100 Мб общего размера файла за один сеанс конвертирования 10 файлов на одно конвертирование Обычный приоритет и скорость конвертирования Наличие объявлений
Мы не может загружать видео с Youtube.
Чтобы конвертировать в обратном порядке из WORD в PDF, нажмите здесь:
Конвертер WORD в PDF
Оцените конвертирование WORD с помощью тестового файла PDF
Не впечатлило? Нажмите на ссылку, чтобы конвертировать наш демонстрационный файл из формата PDF в формат WORD:
Конвертирование PDF в DOCX с помощью нашего тестового файла PDF.
PDF, Portable Document Format
(.pdf)PDF – портативный формат документов (Portable Document Format), разработанный Adobe. PDF-файлы трансформируют документ в фиксированный макет, похожий на изображение, который сохраняет свой формат во всех программах, на всех устройствах и операционных системах. Это позволяет пользователю интегрировать в единый документ различные изображения, шрифты и текстовые форматы (иногда содержащие.
Что такое PDF?
DOCX, Microsoft Word Open XML Document
(.docx)Формат DOCX представляет собой модернизированную версию формата DOC, причем по сравнению со своим предшественником этот формат гораздо более популярен и доступен.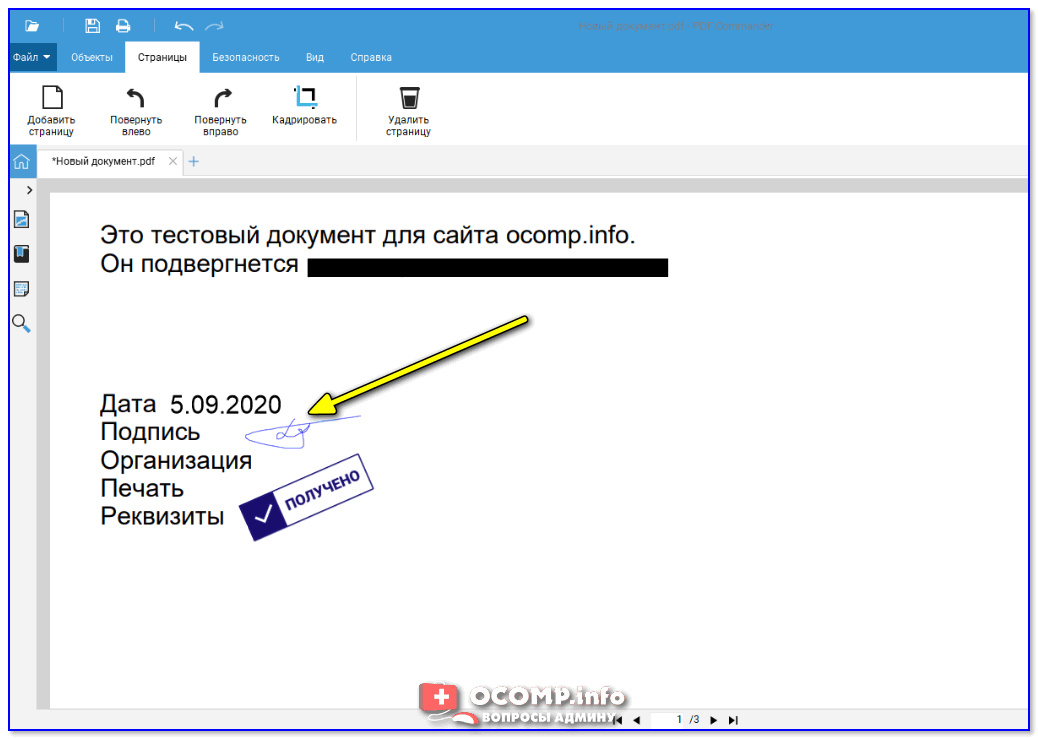 В отличие от файлов DOC формат DOCX не является расширенным файловым форматом. Он скорее представляет собой файл-архив, который содержит небольшой пакетный файл размером не более 10 Кб. Именно это превращает формат в популярное.
В отличие от файлов DOC формат DOCX не является расширенным файловым форматом. Он скорее представляет собой файл-архив, который содержит небольшой пакетный файл размером не более 10 Кб. Именно это превращает формат в популярное.
Что такое WORD?
Бесплатный сервис по распознаванию
текста из изображений
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания
Загрузите файл
Выберите язык содержимого текста в файле
После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 6.6M+ запросов
 Данные между серверами передаются по SSL + автоматически будут удалены
Данные между серверами передаются по SSL + автоматически будут удаленыОсновные возможности
Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста.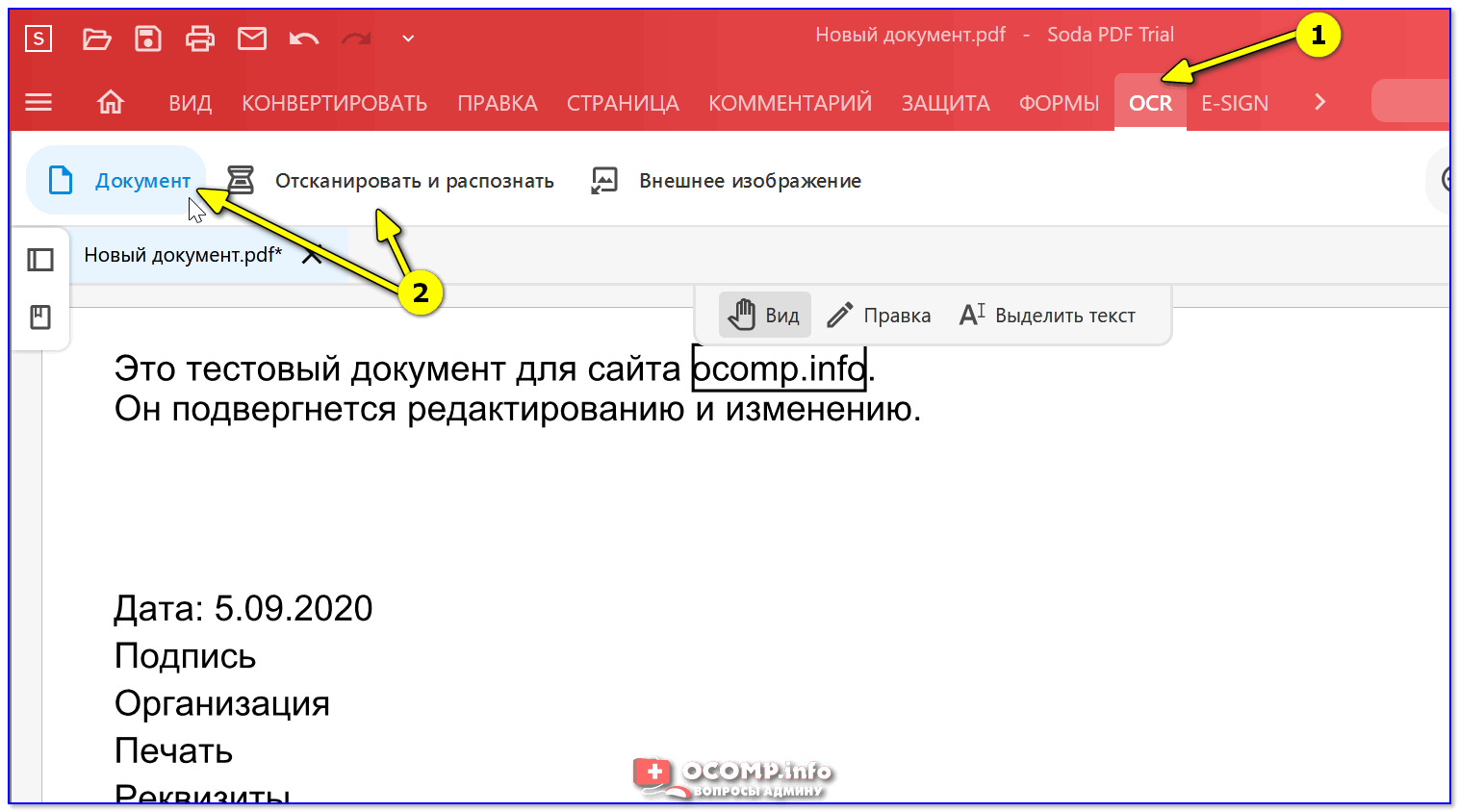 Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani – Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese – Simplified, Chinese – Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian – Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian – Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek – Cyrillic, Vietnamese
© 2014-2020 img2txt Сервис распознавания изображений / v. 0.6.5.0
0.6.5.0
Извлечение Текста И Изображений Из Документов Онлайн
Извлекайте текст и изображения из документов с высокой скоростью. Получите редактируемый и доступный для поиска текст из Word, PDF, HTML, электронных книг.
Извлекайте текст или изображения из Word, PDF, HTML, электронных книг. Используйте их в другом документе, презентации или веб-странице. Забудьте тратить драгоценное время на выполнение этих операций вручную! Aspose предлагает вам это мощное и простое в использовании приложение для анализа документов, продвигая вперед полнофункциональное текстовое решение и повышая эффективность офисной работы.
Надежный бесплатный онлайн-анализатор документов предназначен для извлечения текста и изображений из Word, PDF, веб-файлов и электронных книг в отдельные файлы. С помощью этого надежного инструмента извлечения текста вы можете легко получить текст практически из любого типа документа, включая Word и OpenOffice.
Легко разбирать файл и читать текст
Aspose Document Parser основан на браузере и работает на всех платформах, включая Windows, Linux, macOS и Android. Никаких плагинов или установки программного обеспечения не требуется. Это абсолютно бесплатно. Извлечение всего текста и изображений осуществляется с помощью API-интерфейсов Aspose, которые используются многими компаниями из Fortune 100 в 114 странах.
Никаких плагинов или установки программного обеспечения не требуется. Это абсолютно бесплатно. Извлечение всего текста и изображений осуществляется с помощью API-интерфейсов Aspose, которые используются многими компаниями из Fortune 100 в 114 странах.
Программная платформа Aspose Words
Онлайн-приложение Parser создано на базе программной платформы Aspose Words. Наша компания разрабатывает современные высокопроизводительные решения обработки документов для различных ОС и языков программирования.
Шаг 2 из 4
Пропустить Следующий
Шаг 3 из 4
Каким образом мы можем улучшить ваш опыт?
Пропустить Следующий
Большое спасибо за ваш отзыв!
Мы действительно это ценим!
С вашей помощью наши продукты становятся лучше с каждым днем!
Мы рады, что вам понравилось наше приложение, и будем очень признательны, если вы поделитесь следующими ссылками со своими друзьями и коллегами:
Поделиться в Facebook
Поделиться в Twitter
Поделиться в LinkedIn
Оставить отзыв
Добавить в закладки
c# — Как извлечь текст из документов PDF, Word и Excel?
Как человек, который потратил много дней на поиски бесплатных решений (почти) этой конкретной проблемы, я могу честно сказать вам, что вы не найдете бесплатную библиотеку, которая сможет извлекать текст из всех из этих форматов хорошо.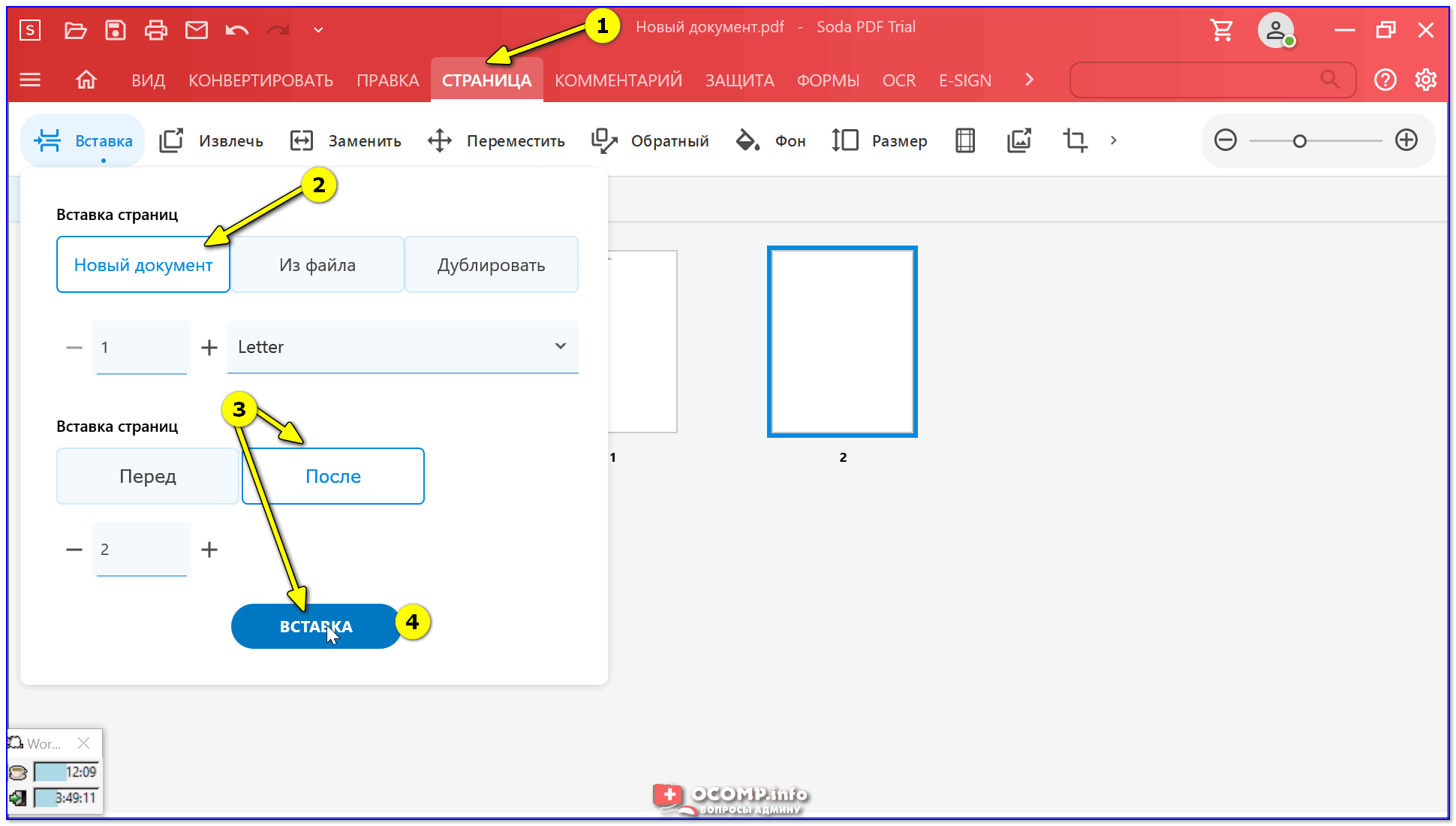 Единственная библиотека, о которой мне известно, которая отлично работает со всеми этими форматами (и более), это коммерческая библиотека, и она на самом деле не является родной для .NET, это библиотека C++/COM с C++/CLI. NET обертка.
Единственная библиотека, о которой мне известно, которая отлично работает со всеми этими форматами (и более), это коммерческая библиотека, и она на самом деле не является родной для .NET, это библиотека C++/COM с C++/CLI. NET обертка.
Какие есть варианты?
iTextSharp — Это совершенно фантастический способ извлечения текста из PDF-файлов. В то время как более поздние версии этой библиотеки были коммерчески дружественными (LGPL), авторы решили вместо этого, что они хотят взимать плату за программное обеспечение, поэтому вместо этого они выпустили его под AGPL, так что если вы не хотите выпускать весь свой исходный код, Вы, вероятно, не хотите использовать одну из этих версий. Однако последнюю версию (4.1.6), лицензированную по лицензии LGPL, можно найти по всему Интернету. Этот вопрос SO содержит ссылку на версию, находящуюся под LGPL.
PdfBox — Другая PDF библиотека. Этот, IMO, лучше, потому что он под лицензией Apache 2.0. Есть несколько проблем с ним, так как он иногда (возможно, редко) не будет работать так же хорошо, как iTextSharp.
Я приписываю это больше факту, что это более новая библиотека чем что-либо еще. Однако, мой опыт работы с этой библиотекой был месяцев назад. Этот проект активно развивается, и только за последний месяц было решено 52 вопроса. Я бы следил за этим. Обратите внимание, что это библиотека Java. (Продолжайте читать ниже для получения дополнительной информации о том, почему я включил это.)POI или NPOI — это библиотеки, специально написанные для офисных документов Microsoft, в частности, до 2007 года, OLE двоичные форматы файлов , Он поддерживает новые форматы OpenXML, хотя я не уверен, насколько зрелой является эта часть библиотеки. POI является версией Java (продолжайте читать ниже для получения дополнительной информации о том, почему я включил это.), Где NPOI является нативной версией .NET. Однако NPOI поддерживает только документы Excel, где POI может извлекать текст в многие другие типы .
Open XML SDK 2. — Библиотека для чтения/изменения документов Office 2007+ (незашифрованные OpenXML) создала мой Microsoft самостоятельно! Это удивительная библиотека для работы с такими документами.
Тем не менее, это библиотека более низкого уровня, и поэтому на самом деле (насколько я знаю) нет , она делает все класс извлечения текста. Есть довольно хороший пример (я не уверен, что он охватывает некоторые случаи, такие как текст в таблицах и т.д.), Извлечения текста из документа Word на этот SO ответTika — Еще раз, еще одна библиотека Java (я не говорю вам о библиотеках Java без причины. Продолжайте читать! :)), и это будет как можно ближе к «одной библиотеке» для извлечения текста. Tika может извлекать метаданные и структурированный текстовый контент из множества различных типов файлов, используя существующие библиотеки синтаксического анализа. Он фактически использует POI и PdfBox под капотом для офиса и PDF документов.
 Я приписываю это больше факту, что это более новая библиотека чем что-либо еще. Однако, мой опыт работы с этой библиотекой был месяцев назад. Этот проект активно развивается, и только за последний месяц было решено 52 вопроса. Я бы следил за этим. Обратите внимание, что это библиотека Java. (Продолжайте читать ниже для получения дополнительной информации о том, почему я включил это.)
Я приписываю это больше факту, что это более новая библиотека чем что-либо еще. Однако, мой опыт работы с этой библиотекой был месяцев назад. Этот проект активно развивается, и только за последний месяц было решено 52 вопроса. Я бы следил за этим. Обратите внимание, что это библиотека Java. (Продолжайте читать ниже для получения дополнительной информации о том, почему я включил это.) Тем не менее, это библиотека более низкого уровня, и поэтому на самом деле (насколько я знаю) нет , она делает все класс извлечения текста. Есть довольно хороший пример (я не уверен, что он охватывает некоторые случаи, такие как текст в таблицах и т.д.), Извлечения текста из документа Word на этот SO ответ
Тем не менее, это библиотека более низкого уровня, и поэтому на самом деле (насколько я знаю) нет , она делает все класс извлечения текста. Есть довольно хороший пример (я не уверен, что он охватывает некоторые случаи, такие как текст в таблицах и т.д.), Извлечения текста из документа Word на этот SO ответНекоммерческий
- dtSearch — Это библиотека, с которой я очень хорошо знаком. Это делает фантастическую работу, и может анализировать смешное количество форматов файлов. Однако это стоит денег и, вероятно, излишне для того, что вам нужно. Это на самом деле точно то, что нам нужно, но мы пытаемся избавиться от него сами, потому что мы используем его только для анализа (на самом деле это полнотекстовая поисковая система), и существует множество библиотек для разбора, которые мы можем использовать или модифицировать в соответствии с нашими потребностями, но это, честно говоря, выбрасывает все остальные библиотеки из воды. Как я упоминал ранее, это также не нативный код .NET. Оболочка C++/CLI используется для взаимодействия между DLL и средой выполнения .NET.
 Это на самом деле точно то, что нам нужно, но мы пытаемся избавиться от него сами, потому что мы используем его только для анализа (на самом деле это полнотекстовая поисковая система), и существует множество библиотек для разбора, которые мы можем использовать или модифицировать в соответствии с нашими потребностями, но это, честно говоря, выбрасывает все остальные библиотеки из воды. Как я упоминал ранее, это также не нативный код .NET. Оболочка C++/CLI используется для взаимодействия между DLL и средой выполнения .NET.
Это на самом деле точно то, что нам нужно, но мы пытаемся избавиться от него сами, потому что мы используем его только для анализа (на самом деле это полнотекстовая поисковая система), и существует множество библиотек для разбора, которые мы можем использовать или модифицировать в соответствии с нашими потребностями, но это, честно говоря, выбрасывает все остальные библиотеки из воды. Как я упоминал ранее, это также не нативный код .NET. Оболочка C++/CLI используется для взаимодействия между DLL и средой выполнения .NET.iFilters можно использовать, и они упоминаются в нескольких других SO ответах на разные вопросы, но текст, который вы получите, неструктурирован. Иногда это просто плохо … нечитаемо для людей, по крайней мере. Я считаю, что iFilters также устарели, и в зависимости от лицензионных проблем, вы не сможете распространять их.
Почему я упомянул все эти библиотеки Java? Ну, по двум причинам. Во-первых, нет свободных .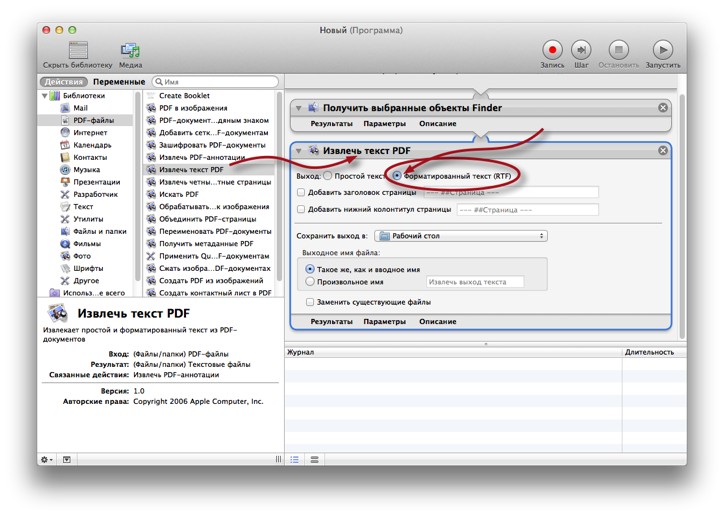 NET-эквивалентов, которые приближаются к качеству этих библиотек Java. Во-вторых, вы можете использовать эти библиотеки в .NET (я лично сделал это с этими библиотеками, так что я могу по крайней мере поручиться за это), используя IKVM . Это реализация Java внутри .NET. Вот хороший пример об использовании IKVM для преобразования Tika в сборку .NET, которую можно использовать в вашем проекте. Возможно, самая страшная вещь об IKVM, это то, что это просто работает!
NET-эквивалентов, которые приближаются к качеству этих библиотек Java. Во-вторых, вы можете использовать эти библиотеки в .NET (я лично сделал это с этими библиотеками, так что я могу по крайней мере поручиться за это), используя IKVM . Это реализация Java внутри .NET. Вот хороший пример об использовании IKVM для преобразования Tika в сборку .NET, которую можно использовать в вашем проекте. Возможно, самая страшная вещь об IKVM, это то, что это просто работает!
Правка: я забыл, что автор этого блога на самом деле опубликовал код и преобразовал библиотеки на проект GitHub . Так что, если вы хотите быстро проверить это, вы можете сделать это там. Тем не менее, это гораздо более старая версия Тики и старше года. Если результаты не такие, как вы ожидали, я бы посоветовал попробовать сами с последней версией.
Копирование данных с PDF-страниц. Как вставить содержимое файла pdf в Microsoft Word
Превосходно подходит для компактного хранения файлов. Это обстоятельство привело к тому, что формат PDF используется сейчас практически повсеместно, и почти на каждом компьютере установлено для его прочтения специальное приложение. Но если открытие такого документа не вызывает особых сложностей (в сети полно бесплатных программ), то при попытке копирования сохраненной в нем информации нередко возникают проблемы. Связано это с тем, что иногда авторы файлы решают поставить на него защиту. Как скопировать текст из PDF, если на нем стоит пароль? Выход есть, и таких способов несколько.
Но если открытие такого документа не вызывает особых сложностей (в сети полно бесплатных программ), то при попытке копирования сохраненной в нем информации нередко возникают проблемы. Связано это с тем, что иногда авторы файлы решают поставить на него защиту. Как скопировать текст из PDF, если на нем стоит пароль? Выход есть, и таких способов несколько.
Виртуальный принтер
Стандартные установки безопасности позволяют при создании PDF-документа ограничить любое из следующих действий:
- печать;
- внесение в файл каких-либо изменений;
- извлечение или копирования контента;
- редактирование или добавление полей форм и комментариев.
Если автор решил защитить свой документ паролем, он может выбрать одну или несколько данных опций. Предположим, что выбрана третья опция (запрещено копирование), и вместе с тем пользователю доступен первый вариант (разрешена печать). Как скопировать текст из PDF в этом случае? Воспользоваться виртуальным принтером! Набрав в строке поиска слово «pdfforge», вы попадете на соответствующий сайт, на котором можно бесплатно скачать себе PDF-принтер.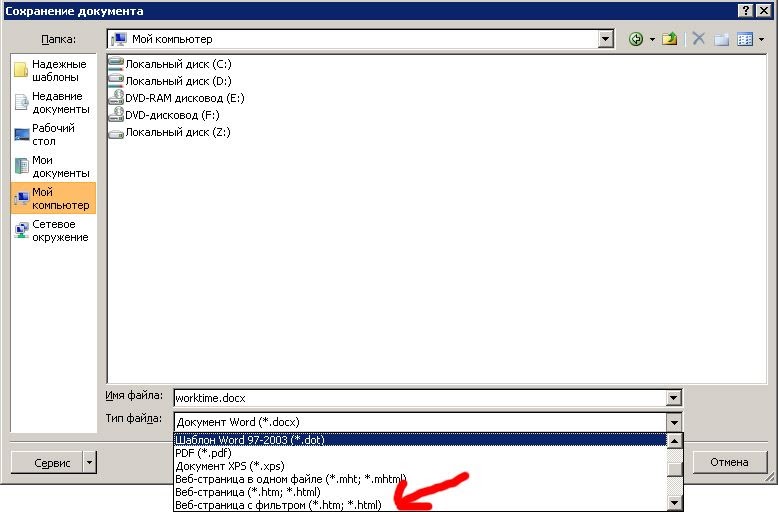 В принципе, не обязательно использовать именно это приложение. В интернете существует свыше миллиона похожих программ, так что даже самые привередливые юзеры смогут себе подобрать наиболее подходящий вариант. После установки такого приложения в списке установленных принтеров появится соответствующая иконка. Такой принтер можно использовать для создания PDF-файла практически из любого формата. И здесь мы подходим к самому интересному: если отправить на печать документ, защищенный паролем, то при этом будет создан новый PDF-документ, полностью лишенный всяких ограничений. Его как раз и можно будет использовать для копирования.
В принципе, не обязательно использовать именно это приложение. В интернете существует свыше миллиона похожих программ, так что даже самые привередливые юзеры смогут себе подобрать наиболее подходящий вариант. После установки такого приложения в списке установленных принтеров появится соответствующая иконка. Такой принтер можно использовать для создания PDF-файла практически из любого формата. И здесь мы подходим к самому интересному: если отправить на печать документ, защищенный паролем, то при этом будет создан новый PDF-документ, полностью лишенный всяких ограничений. Его как раз и можно будет использовать для копирования.
Сетевые сервисы
Первый вариант хорош для домашнего использования. Но что делать, если компьютер стоит на работе и на него запрещено устанавливать стороннее ПО, но при этом есть выход во всемирную паутину? Как скопировать текст из защищенного PDF в таком случае? Использовать сетевой сервис! В интернете в статьях на эту тему часто упоминают службу PDF Пират, которая способна справиться с любым документом, не превышающим по весу 150 мегабайт. При проверке оказалось, что она в настоящий момент не работает. Поэтому вот еще парочка вариантов: ресурс Pdfunlock и сервис FreeMyPDF. Несмотря на то, что эти сайты зарубежные и в интерфейсе нет русского языка, они способны освободить файл независимо от того, на каком языке хранится в нем текст.
При проверке оказалось, что она в настоящий момент не работает. Поэтому вот еще парочка вариантов: ресурс Pdfunlock и сервис FreeMyPDF. Несмотря на то, что эти сайты зарубежные и в интерфейсе нет русского языка, они способны освободить файл независимо от того, на каком языке хранится в нем текст.
Как справиться с «кракозябрами»?
Иногда пользователи сталкиваются с такой проблемой: после снятия защиты с PDF-документа и вставки скопированного текста в Word, вместо нормального текста появляются непонятные символы. Проблема состоит в неверно выбранной кодировке текста. Как скопировать из PDF, если в итоге получаются «крякозябры»? Самый простой способ — это повторное снятие пароля с файла через другой аналогичный сервис.
Софт
Поскольку вопрос «как скопировать текст из PDF» интересует многих, разработчики программ не могли оставить его без внимания. И по желанию можно ради эксперимента поставить себе PDF Password Remover, PDF Advanced Password Recovery, PDF Unlocker или любую другую утилиту подобного рода. Но их нужно сначала найти, затем скачать, разобраться, как та или другая работает… И все ради одного несчастного документа! Впрочем, случаи бывают разные, если ничто другое не помогает, а информация в документе действительно очень важна, то такой вариант будет, пожалуй, самым лучшим. Тем более что некоторые из таких программ не требуют установки, а значит, их можно будет запустить на рабочем компьютере и с обычной флешки.
Но их нужно сначала найти, затем скачать, разобраться, как та или другая работает… И все ради одного несчастного документа! Впрочем, случаи бывают разные, если ничто другое не помогает, а информация в документе действительно очень важна, то такой вариант будет, пожалуй, самым лучшим. Тем более что некоторые из таких программ не требуют установки, а значит, их можно будет запустить на рабочем компьютере и с обычной флешки.
Предупреждение
Хоть вышеперечисленные методы и описывают, как скопировать текст из PDF при наличии пароля, это вовсе не означает, что можно игнорировать действующее законодательство. Поэтому во избежание неприятностей желательно проверить, нет ли в защищенном документе заявления о конфиденциальности либо попросту посоветоваться с юристом.
Довольно часто используется для публикации разного рода электронных документов. В PDF публикуются научные работы, рефераты, книги, журналы и многое другие.
Сталкиваясь с документом в PDF формате, пользователи часто не знают, как скопировать текст в Ворд. Если у вас также возникла подобная проблема, то наша статья должна вам помочь. Здесь вы узнаете 4 способа, как скопировать текст из PDF в Ворд.
Если у вас также возникла подобная проблема, то наша статья должна вам помочь. Здесь вы узнаете 4 способа, как скопировать текст из PDF в Ворд.
Самый простой способ скопировать текст из PDF в Ворд это обычное копирование, которым вы пользуетесь постоянно. Откройте ваш PDF файл в любой программе для просмотра PDF файлов (например, можно использовать Adobe Reader), выделите нужную часть текста, кликните по ней правой кнопкой мышки и выберите пункт «Копировать».
Также вы можете скопировать текст с помощью комбинации клавиш CTRL-C. После копирования текст можно вставить в Ворд или любой другой текстовый редактор.
К сожалению, данный способ копирования текста далеко не всегда подходит. от копирования, тогда вам не удастся выполнить копирование текста. Также в PDF документе могут быть таблицы или картинки, которые нельзя просто так скопировать. Если вы столкнулись с подобной проблемой, то следующие способы копирования текста из ПДФ должны вам помочь.
Копируем текст из PDF файла в Word с помощью ABBYY FineReader
ABBYY FineReader это программа для распознавания текста. Обычно данную программу используют для распознавания текста на отсканированных изображениях. Но, с помощью ABBYY FineReader можно распознавать и PDF файлы. Для этого откройте ABBYY FineReader, нажмите на кнопку «Открыть» и выберите нужный вам PDF файл.
Обычно данную программу используют для распознавания текста на отсканированных изображениях. Но, с помощью ABBYY FineReader можно распознавать и PDF файлы. Для этого откройте ABBYY FineReader, нажмите на кнопку «Открыть» и выберите нужный вам PDF файл.
После того как программа закончит распознавание текста нажмите на кнопку «Передать в Word».
После этого перед вами должен открыться документ Ворд с текстом из вашего PDF файла.
Копируем текст из PDF файла в Word c помощью конвертера
Если у вас нет возможности воспользоваться программой ABBYY FineReader, то можно прибегнуть к программам-конвертерам. Такие программы позволят конвертировать PDF документ в Word файл. Например, можно использовать бесплатную программу .
Для того чтобы сконвертировать PDF документ в Word файл с помощью UniPDF вам нужно просто открыть программу, добавить в нее нужный PDF файл, выбрать конвертацию в Word и нажать на кнопку «Convert».
Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Также существуют онлайн конвертеры, которые позволяют сконвертировать PDF файл в Word файл. Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Использовать такие конвертеры довольно просто. Все что вам нужно сделать, это загрузить файл и нажать на кнопку «Конвертировать». А после завершения конвертации нужно будет скачать файл обратно.
Популярные онлайн конвертеры из PDF в Word.
Хочу рассказать несколько хитростей для работы с текстом в файлах формата PDF, а именно как выделить текст в PDF. Раньше я работала в небольшой веб-студии, где много внимания уделялось контенту, поэтому часто приходилось обращаться к услугам внештатных копирайтеров. Так вот, по долгу службы мне приходилось тестировать новых сотрудников на знание офисных программ. Как оказалось, многие гуманитарии не имели понятия, как создать таблицу в Excel или как выделить текст в PDF файле и перенести выделенный текст в документ Word.
За год работы у меня сложился определенный мануал для таких новичков. Уверена, что многим пользователям могут пригодиться советы по извлечению текста из PDF документов.
Уверена, что многим пользователям могут пригодиться советы по извлечению текста из PDF документов.
Для тех, кто впервые работает с файлами такого формата, поясню, что во время чтения PDF документа можно скопировать текст. Просто выделите текст (как будто маркером в обычном бумажном файле), а сделать это можно следующими способами.
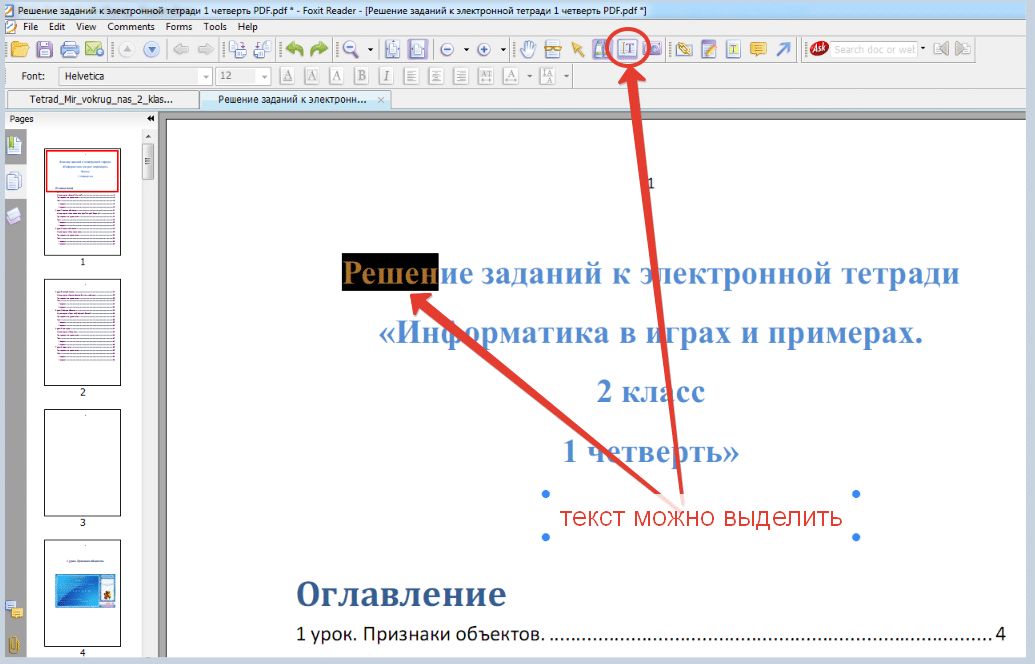
Как выделить весь текст в PDF через Adobe Acrobat Pro:
- Открыть PDF-документ при помощи Acrobat.
- Найти на верхней панели инструментов кнопку “T” (то есть “text”), подсвеченную желтым цветом.
- Нажать на нее и провести курсором мышки по тексту, который нужно выделить.
Скопировать текст из документа PDF через Adobe Reader (бесплатно):
Открыть PDF файл через программу Adobe Reader. Для этого дважды кликните на PDF документ -обычно и так открывается программой Reader по умолчанию. Дальше повторите действия как в предыдущем методе.
Как извлечь текст из PDF в браузере?
Как правило, PDF документы нельзя менять в веб-браузере, поэтому для начала нужно сохранить копию документа на ваш ПК. Сохраните файл в любую папку или на Рабочий стол, откройте его (дважды кликните) и выделите текст, как описано выше.
Сохраните файл в любую папку или на Рабочий стол, откройте его (дважды кликните) и выделите текст, как описано выше.
Через программу Preview (только для пользователей Mac):
- Нужно открыть документ PDF через программу Preview (стандартная на Mac-устройствах).
- Потом можно зайти в меню «Инструменты», выбрать пункт «Разметка», а потом нажать «Выделение текста» (или нажать на «горячие» клавиши Сontrol+Сommand+H)
- Потом, зажимая кнопку, проведите курсором по файлу, чтобы выделить весь текст в PDF .
Как перенести текст из PDF в Word?
Откройте PDF файл через программу AdobeReader. Потом нужно выделить текст в PDF документе, как описано выше. Потом нужно нажать Ctrl-C или на кнопку «Вставить» на верхней панели, а там выбрать «Специальная вставка», после – «Неформатированный текст».
Еще один способ для переноса текста из PDF в Word, это после выделения фрагмента текста в PDF файле, нажать сочетание клавиш Ctrl/Insert, потом в пустом документе Word нажать Shift/Insert.
Иногда тексты в PDF-файлах закрыты паролем от копирования, поэтому копировать их вышеописанным способом может быть проблематично. В таких случаях вам может пригодиться данная видео-инструкция по копированию текста и картинок в PDF :
Чтобы скопировать текст из файла формата PDF, необходимо провести некоторые простые процедуры. Какие именно, мы сейчас расскажем.
Как скопировать текст в простом файле
Как скопировать текст из PDF проще всего? Если в PDF просто текст, а не текст в виде картинки, то посмотрите на верхнюю панель программы. Если там найдете значок с большой буквой «T», то смело жмите на него. Это инструмент «Select text», после выбора его вы можете копировать нужный текст и потом вставлять в Word.
Если есть Adobe Reader, откройте PDF-документ при помощи этой программы, и сможете скопировать текст. Если же эти варианты невозможны, то нужно попробовать скопировать текст иначе.
Перед тем как скопировать текст из PDF, нужно выбрать в Интернете программу, которая переведёт документ из формата PDF в обычный текстовый документ. Подобных программ-помощников существует много, их можно скачать, а можно и провести процедуру перевода в режиме онлайн. Такими программами можно пользоваться бесплатно. Просто вставляете необходимый вам текст в окно на сайте, указываете свою электронную почту, прикрепляете файл с документом PDF и получаете письмо с текстовым документом.
Можно загрузить на компьютер программу, которая распознает файл и конвертирует его в простой текстовый документ из формата PDF в формат doc. Программа называется «ABBYY FineReader». Вот в этой программе и открывайте ваш файл. Загрузите файл в программу, она распознает и сконвертирует документ. Сохраните его в Word. Теперь можно читать и пользоваться файлом без путаницы и странных символов.
Работа с защищённым файлом
Можно столкнуться с такой проблемой, как защита от копирования или перевода в документе PDF. Скопировать текст не удаётся, а информация просто необходима. Что же делать, если скопировать текст из защищенного PDF просто не получается? Необходимо снять защиту, перевести документ в формат doc способом, указанным выше. Введите в поисковике запрос «программа для снятия защиты с PDF файла» и найдите подходящую. Нужный документ требуется перенести в окно программы, нажать на кнопку «Снять защиту» или «Снять кодировку» (зависит от ресурса, которым вы пользуетесь). Снимите ограничения — защиту с файла, сохраните его в Word. Или в окне может быть указано «Загрузить файл». Нажимаете на окно, выбираете нужный документ, нажимаете «Ок».
Введите в поисковике запрос «программа для снятия защиты с PDF файла» и найдите подходящую. Нужный документ требуется перенести в окно программы, нажать на кнопку «Снять защиту» или «Снять кодировку» (зависит от ресурса, которым вы пользуетесь). Снимите ограничения — защиту с файла, сохраните его в Word. Или в окне может быть указано «Загрузить файл». Нажимаете на окно, выбираете нужный документ, нажимаете «Ок».
Можно, конечно, использовать вирусы, которые снимают защиту с документа PDF. Но это небезопасно, поскольку имеется вероятность, что после использования такого способа перевести файл в формат doc не получится.
Возможно, вам не удастся скопировать текст из PDF с помощью программы, которую вы используете. В таком случае нужно попытаться воспользоваться другими программами. Методом проб найдите оптимальную программу, даже если она англоязычная. Такие программы переводят файлы и на русском языке.
При работе в Интернет начинающие пользователи (если вы — начинающий, то уже знаете ), равно как и опытные гуру, постоянно сталкиваются с необходимостью копировать и видоизменять для себя ту или иную информацию. И если с копированием все более-менее понятно, то, что касается обработки информации, не все так однозначно. Некоторые форматы файлов не позволяют взять и просто так изменить занесенную в них информацию. Но ведь именно это и необходимо! Как быть? В данной статье будут рассмотрены три способа, которыми можно скопировать текст из pdf файла в любой текстовый редактор, чтобы там можно было его отредактировать по своему усмотрению. Сначала рассмотрим самый простой вариант, потом – те, что посложнее. Итак, начнем.
И если с копированием все более-менее понятно, то, что касается обработки информации, не все так однозначно. Некоторые форматы файлов не позволяют взять и просто так изменить занесенную в них информацию. Но ведь именно это и необходимо! Как быть? В данной статье будут рассмотрены три способа, которыми можно скопировать текст из pdf файла в любой текстовый редактор, чтобы там можно было его отредактировать по своему усмотрению. Сначала рассмотрим самый простой вариант, потом – те, что посложнее. Итак, начнем.
Как скопировать текст из pdf-файла стандартным способом?
Когда для pdf-файла соблюдаются два условия:- текст, который нужно скопировать из pdf , является текстом, а не изображением;
- pdf-документ не защищен,
тогда можно скопировать текст стандартным способом, то есть использованием сочетания клавиш для выделения нужного фрагмента (Shft+стрелки управления курсором), его копирования (Ctrl+c) и вставки (Ctrl+v). Ниже скриншоты, как это сделать.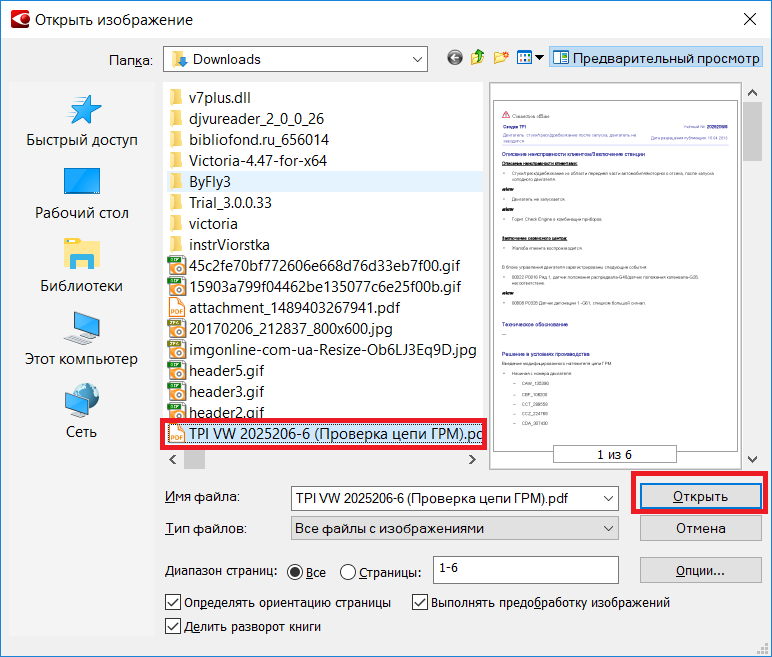
Используем AdobeReader XI
Второй вариант копирования текста из pdf – используем сторонние программы
Если по-простому ничего не получается, для копирования нужной информации из pdf придется использовать сторонние программы, способные выполнять конвертацию данного формата в текст. В Сети есть большое множество таких программ, причем часть из них может быть скачана и установлена на ваш компьютер, а часть – существует в виде онлайн сервисов для преобразования pdf-файла в текст.
Управляющие элементы программ, устанавливаемых на компьютер обычно интуитивно понятны, поэтому вам не придется долго разбираться с вопросом, как скопировать текст из pdf с помощью такого ПО, тем более, если оно русскоязычное. Что касается онлайн сервисов, то для них обычно необходимо указать ваш электронный адрес и загрузить исходный документ. После обработки файла, на ваш e-mail будет выслан файл с текстом, извлеченным из pdf-документа.
И программы, устанавливаемые локально, и онлайн сервисы позволяют бесплатно скопировать текст из pdf файлов, но бесплатные версии обычно ограничены максимальным количеством страниц, которые можно обработать. Платные программы таких ограничений не имеют. Переходим к третьему способу.
Платные программы таких ограничений не имеют. Переходим к третьему способу.
Как извлечь PDF в Word двумя способами
2021-08-25 19:51:20 • Отправлено в: Практическое руководство • Проверенные решения
Файлы PDFпереносимы, поддерживаются на большом количестве платформ, а содержимое документа нелегко редактировать или переформатировать. В некоторых случаях вам может потребоваться отредактировать, скопировать или даже добавить аннотации к содержимому вашего файла PDF, что вызывает необходимость извлечения PDF в документ Word с помощью надежного экстрактора PDF в Word.Следуйте этому руководству.
Метод 1. Как извлечь PDF-файл в Word
PDFelement — это решение большинства проблем с файлами PDF в течение длительного времени и, таким образом, завоевал популярность на рынке как лучший менеджер PDF.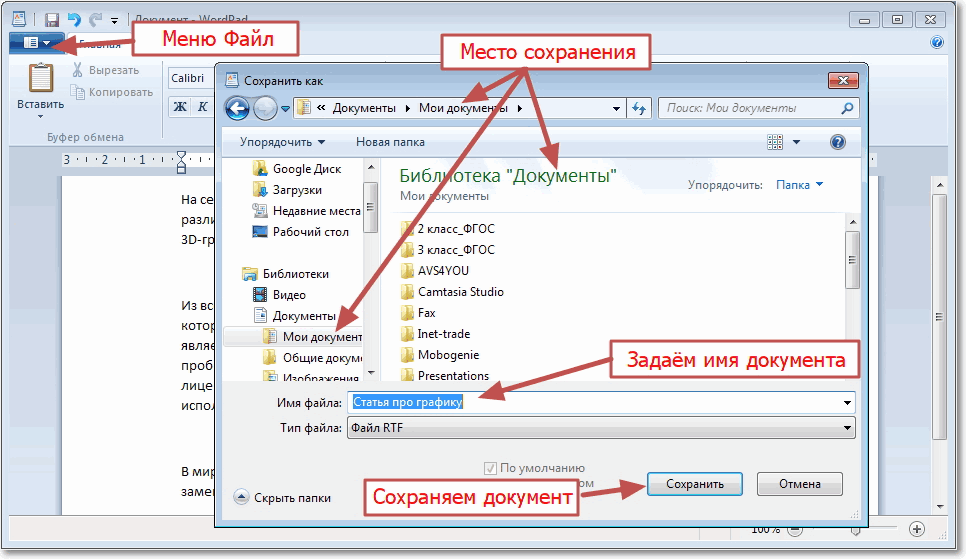 Будучи многофункциональным инструментом, эта программа может создавать, редактировать и конвертировать PDF в файлы различных форматов. В этом разделе мы рассмотрим один из способов извлечения из документа PDF в документ Word.
Будучи многофункциональным инструментом, эта программа может создавать, редактировать и конвертировать PDF в файлы различных форматов. В этом разделе мы рассмотрим один из способов извлечения из документа PDF в документ Word.
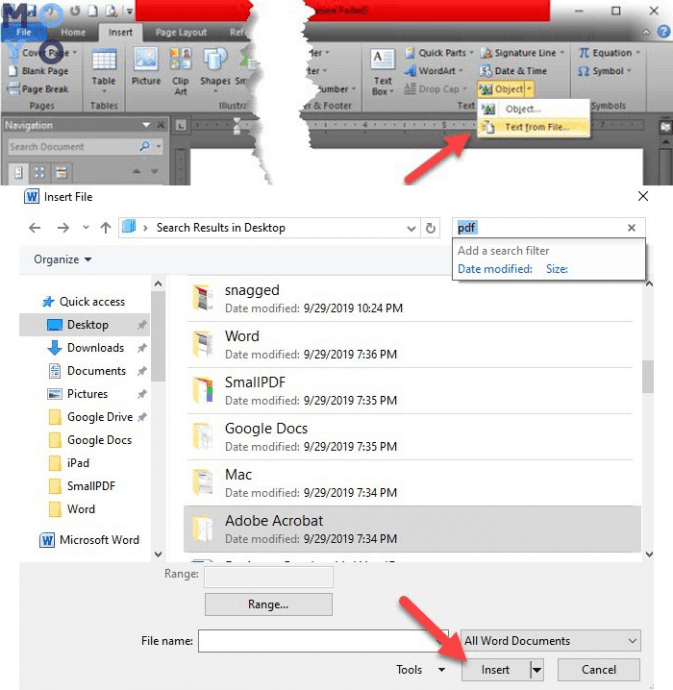
Шаг 1. Импортируйте файл PDF
Нажмите на панель «Открыть файл» на главной странице программы.В новом всплывающем окне проводника выберите PDF-файл, который нужно извлечь в Word, и нажмите кнопку «Открыть», чтобы импортировать его.
Кроме того, вы можете выбрать целевой PDF-файл из своих файлов, перетащить его в открытое пространство на домашней странице программы, чтобы импортировать.
Шаг 2. Отредактируйте PDF (необязательно)
Мы рекомендуем вам отредактировать или внести необходимые изменения в ваш PDF-файл на этом этапе и до начала извлечения документа, однако этот шаг не является обязательным.Чтобы отредактировать файл PDF, нажмите на панель «Редактировать», расположенную вверху страницы. PDFelement содержит великолепные и удивительные инструменты для редактирования PDF-файлов, которые не подведут вас в ваших поисках.
Шаг 3. Выберите выходной формат
После того, как вы удовлетворены изменениями, внесенными в документ, щелкните вкладку «Преобразовать» на главной панели управления. Под панелью управления появится новое подменю, в котором вы можете выбрать один из нескольких форматов вывода. Нажмите на опцию «В Word», чтобы начать извлекать текст из PDF в Word.
Шаг 4. Извлечь PDF в Word
Введите имя и укажите место, где вы хотите сохранить извлеченный документ. Убедитесь, что «Файлы Word (* .docx)» выбраны для вывода в разделе «Сохранить как тип», и нажмите кнопку «Сохранить», чтобы извлечь PDF-файл в документ Word.
Метод 2: как извлечь текст из PDF в Word
Знаете ли вы, что помимо преобразования PDF-файла в Word, вы также можете извлечь PDF-файл в Word с помощью функции «Копировать и вставить»? Этот метод немного отличается от описанного выше, и всего за несколько шагов и щелчков мышью все содержимое вашего PDF-файла будет извлечено в файл Word.
Шаг 1. Извлечь PDF в Word
Нажмите на панель «Редактировать» на панели управления вверху страницы. Выберите и коснитесь панели «Редактировать текст и объект изображения», чтобы включить режим редактирования файла PDF. Выберите и выделите все содержимое файла PDF или только страницы, которые вы хотите извлечь в Word.
Щелкните правой кнопкой мыши выделенный текст и коснитесь параметра «Копировать текст». Кроме того, вы можете нажать сочетание клавиш «Ctrl + C» на вашем компьютере с Windows, чтобы скопировать текст.
Шаг 2. Вставьте текст в Word
Откройте новый документ в программе MS Word и нажмите сочетание клавиш «Ctrl + V», чтобы вставить все содержимое, извлеченное и скопированное из файла PDF. Кроме того, вы можете щелкнуть правой кнопкой мыши новый документ Word и нажать на опцию «Вставить».
За последние несколько лет PDFelement имел серьезную конкуренцию со стороны онлайн-программ и загружаемых программ, однако он не поколебался и по-прежнему сохраняет свои позиции в качестве ведущего инструмента для извлечения данных из PDF в файл Word. Эта программа бесплатно загружается с их веб-сайта, и процесс установки также прост. Его интерфейс интуитивно понятен и удобен, поэтому его легко использовать даже для новичков.
Эта программа бесплатно загружается с их веб-сайта, и процесс установки также прост. Его интерфейс интуитивно понятен и удобен, поэтому его легко использовать даже для новичков.
Функции, которые делают этот инструмент лучшим менеджером и редактором PDF, включают:
- 1. Функция аннотаций позволяет пользователю добавлять комментарии, заметки, рисунки, плавающие текстовые поля и даже штампы в файл PDF.
- 2. Инструмент преобразования является основной функцией, поскольку он помогает преобразовывать файлы PDF в другие различные форматы файлов.
- 3. С помощью этой программы вы можете легко создавать и даже заполнять формы PDF.
- 4. Функция распознавания текста делает это программное обеспечение выдающимся, поскольку оно распознает текст, скрытый в цифровых изображениях, а также помогает преобразовывать отсканированные файлы PDF.
- 5. Он предлагает систему защиты паролем, которая гарантирует безопасность конфиденциальных данных в вашем документе, а также всего содержимого файла PDF.

Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Как я могу извлечь текст из файла PDF? — Мворганизация.org
Как извлечь текст из файла PDF?
- Откройте Microsoft Word из меню «Пуск» или с помощью ярлыка на рабочем столе.
- Откройте файл PDF, который вы хотите преобразовать, в Adobe Reader.
- Нажмите «Выбрать» на панели инструментов Adobe Reader в верхней части экрана.
- Щелкните текст, который вы хотите извлечь в PDF.
- Щелкните «Редактировать» на панели инструментов Adobe Reader и выберите «Копировать».
Как преобразовать PDF в текст на Python?
PDF в текст Python с использованием полного кода PyPDF2
- импорт PyPDF2.
- pdfFileObject = open (r »F: \ pdf. pdf», «rb»)
- pdfReader = PyPDF2. PdfFileReader (pdfFileObject)
- print («Кол-во страниц:», pdfReader. NumPages)
- pageObject = pdfReader. getPage (0)
- печать (pageObject. ExtractText ())
- pdfFileObject. закрыть ()
Как разобрать PDF-файл в Python?
Tabula-py — это простая Python-оболочка для tabula-java, которая может читать таблицы PDF. Вы можете читать таблицы из PDF и конвертировать их в DataFrame панд.tabula-py также позволяет конвертировать файл PDF в файл CSV / TSV / JSON. PDFQuery — это легкая оболочка для pdfminer, lxml и pyquery.
Что такое PDFMiner в Python?
PDFMiner — это инструмент для извлечения текста из документов PDF. Предупреждение: Начиная с версии PDFMiner поддерживает только Python 3. Для поддержки Python 2 посетите pdfminer.
Что такое Textract в Python?
textract.parsers. process (имя файла, кодировка = ’utf_8 ′, extension = None, ** kwargs) [источник] Это основная функция, используемая для извлечения текста. Он направляет имя файла соответствующему синтаксическому анализатору и возвращает извлеченный текст в виде байтовой строки, закодированной с помощью кодировки.
Он направляет имя файла соответствующему синтаксическому анализатору и возвращает извлеченный текст в виде байтовой строки, закодированной с помощью кодировки.
Как установить PDFMiner в Python?
Как установить
- Установите Python 2.6 или новее. (Python 3 не поддерживается.)
- Загрузите исходный код PDFMiner.
- Распаковать.
- Запустите setup.py для установки: # python setup.py install.
- Выполните следующий тест: $ pdf2txt.py samples / simple1.pdf Hello World Hello World H e l o W o r l d H e l o W o r l d.
- Готово!
Как установить PDFMiner 6?
Как использовать
- Установить Python 3.6 или новее (3.4 и 3.5 устарели)
- Установить. pip install pdfminer.six.
- Используйте интерфейс командной строки для извлечения текста из pdf: python pdf2txt.py samples / simple1.pdf.
Как преобразовать PDF в XML в Python?
Конвертируйте PDF в Excel, CSV или XML с помощью Python
- Если вы еще этого не сделали, установите Anaconda на свой компьютер с веб-сайта Anaconda.
- В терминале / командной строке установите библиотеку Python PDFTables с помощью: pip install git + https: //github.com/pdftables/python-pdftables-api.git.
Как преобразовать PDF в текст в Adobe?
Откройте файл PDF в Acrobat DC. Щелкните инструмент «Экспорт PDF» на правой панели. Выберите Microsoft Word в качестве формата экспорта, а затем выберите «Документ Word». Нажмите «Экспорт». Если ваш PDF-файл содержит отсканированный текст, конвертер Acrobat Word автоматически выполнит распознавание текста.
Как преобразовать PDF в обычный текст?
Чтобы преобразовать файл PDF в обычный текст: На вкладке «Главная» на панели «Преобразовать» щелкните «В другой», затем в «Обычный текст». Откроется диалоговое окно «Преобразовать PDF в обычный текст».
Как выделить текст в PDF в Microsoft Edge?
Чтобы включить эту функцию, выполните следующие действия.
- Откройте Microsoft Edge.
- Поиск флажка «Включить выделение текста для PDF». Измените его на Включить.
- Перезапустите Edge и откройте PDF-документ в Edge.
- Выделите текст и щелкните правой кнопкой мыши, чтобы выбрать Highlights. Выбирайте тот цвет, который вам больше нравится.
 Измените его на Включить.
Измените его на Включить.Как выделить текст в Adobe?
Щелкните документ правой кнопкой мыши и выберите «Выбрать инструмент» во всплывающем меню. Перетащите, чтобы выделить текст, или щелкните, чтобы выбрать изображение. Щелкните выбранный элемент правой кнопкой мыши и выберите «Копировать».
Могу ли я выделить текст в PDF?
Вы можете легко выделить, подчеркнуть и зачеркнуть текст в документе в Adobe Acrobat Creative Suite 5 с помощью инструмента «Выделить текст» на панели инструментов «Комментарии и пометки», к которой можно получить доступ, щелкнув параметр «Комментарий» на панели инструментов «Задачи».Перетащите текст, который хотите выделить. Теперь текст выделен.
Как выделить текст в PDF на моем ноутбуке?
Выделить, зачеркнуть или подчеркнуть текст
- Выберите «Инструменты»> «Комментарий» и выберите инструмент «Выделение текста», инструмент «Зачеркнутый текст» или инструмент «Подчеркнутый текст». Примечание:
- Перетащите текст, который нужно пометить, от начала.
- (Необязательно) Чтобы добавить заметку, дважды щелкните разметку и добавьте текст во всплывающую заметку.
 Примечание:
Примечание:Как выделить текст в Adobe Reader?
Выделить текст
- Откройте документ с помощью «Adobe Reader».
- Выберите «Просмотр»> «Комментарий»> «Аннотации».
- Параметры «Аннотации» отображаются на правой панели. Щелкните правой кнопкой мыши значок выделения, затем выберите «Свойства инструмента по умолчанию».
- Выберите цветовую палитру, затем выберите желаемый цвет.
Как вы прокомментируете документ PDF?
Добавьте линию, стрелку или фигуру
- Выберите «Инструменты»> «Комментарий».
- Чертеж в PDF:
- Чтобы отредактировать или изменить размер разметки, выберите ее и перетащите один из маркеров, чтобы внести изменения.
- Чтобы добавить всплывающую заметку к разметке, выберите инструмент «Рука» и дважды щелкните разметку.
- (Необязательно) Нажмите кнопку закрытия во всплывающей заметке.

Как добавить примечания к PDF без Acrobat?
Нажмите «Создать» на странице Документов Google и загрузите файл на диск. После загрузки файла в главном окне щелкните файл правой кнопкой мыши и выберите «Открыть с помощью», а затем «Документы Google.В вашем браузере откроется новая вкладка с редактируемым содержимым.
Может ли Windows 10 конвертировать PDF в Word?
Сначала откройте PDF-файл в Acrobat. В правой части окна щелкните команду «Экспорт PDF». Затем выберите слева опцию «Microsoft Word». Справа при выборе «Документ Word» PDF-файл преобразуется в современный документ Word в формате DOCX.
6 способов извлечения текста из файлов PDF
При работе с файлами PDF или Portable Document Format иногда может потребоваться извлечь весь текст из файла PDF.В этом руководстве мы покажем, как легко извлекать текст из файлов PDF или преобразовывать файлы PDF в текстовые файлы в Windows с помощью онлайн-инструментов или без них.
Самый простой и быстрый способ извлечь текст из файлов PDF — это использовать бесплатные онлайн-сервисы. Эти онлайн-сервисы не требуют какого-либо дополнительного программного обеспечения, а это означает, что вы можете выполнять свою работу без установки какого-либо дополнительного программного обеспечения на свой компьютер.
Если нижеперечисленные онлайн-сервисы не дают желаемых результатов или вы хотите извлечь текст из конфиденциальной информации, которую вы не хотите загружать на удаленный сервер, вы можете воспользоваться бесплатным программным обеспечением Windows, упомянутым в методах 3–5.Также прочтите наше руководство по 6 способам сжатия файлов PDF.
Метод 1 из 6
ExtractPDF
ExtractPDF — это бесплатный онлайн-сервис для полного извлечения текста и изображений из файлов PDF. Сервис предлагает простой для понимания макет. После открытия страницы ExtractPDF в веб-браузере нажмите кнопку «Обзор», чтобы выбрать файл PDF, нажмите кнопку «Загрузить», чтобы загрузить выбранный файл на сервер ExtractPDF и начать извлечение.
После завершения работы вы увидите варианты загрузки текстового контекста, шрифтов и изображений из загруженного файла PDF.Чтобы загрузить извлеченный текст в виде файла .txt (для открытия в Блокноте или Word), перейдите на вкладку «Текст» и нажмите кнопку «Загрузить результат в виде файла».
Как видно на картинке выше, сервис не поддерживает файлы размером более 12 МБ. Это ограничение не должно быть программным, так как большинство файлов PDF имеют размер менее 12 МБ.
Во время нашего тестирования мы заметили, что для некоторых файлов PDF служба не дает желаемого результата. Если у вас возникли проблемы с этой службой, обратитесь к следующей.
Метод 2 из 6
Онлайн OCR
Online OCR — это онлайн-инструмент, помогающий извлекать текст из файлов PDF размером менее 5 МБ. Служба конвертирует PDF-файлы в редактируемые файлы Microsoft Word (.docx) или текстовые (.txt) файлы.
Метод 3 из 6
Программа просмотра STDU
По сути, STDU Viewer — это бесплатное программное обеспечение, предназначенное для открытия и просмотра файлов различных форматов. В дополнение к этому бесплатная версия STDU Viewer поддерживает экспорт текстового содержимого из файлов PDF.
Чтобы экспортировать текстовое содержимое файла PDF, откройте файл PDF с помощью STDU Viewer, выберите меню «Файл», щелкните «Экспорт», щелкните «В текст», выберите место для сохранения нового текстового файла и затем нажмите кнопку «ОК».
Параметр экспорта позволяет извлекать текст с одной, нескольких или всех страниц. Размер загружаемой программы STDU Viewer составляет менее 3 МБ. Бесплатная версия STDU Viewer предназначена только для личного и некоммерческого использования.
Метод 4 из 6
PDF2Text Pilot
PDF2Text Pilot — это бесплатное программное обеспечение для Windows, позволяющее конвертировать файлы PDF в текстовые файлы одним щелчком мыши.После установки и запуска программного обеспечения вам просто нужно выбрать файлы PDF, которые вы хотите видеть в виде текстовых файлов, а затем нажать кнопку «Преобразовать». Ваши преобразованные файлы будут готовы через пару секунд.
Сильной стороной PDF2Text Pilot является простой интерфейс и возможность конвертировать несколько файлов PDF одновременно.
Метод 5 из 6
Инструмент для извлечения текста в формате A-PDFA-PDF Text Extractor — еще одно программное обеспечение для Windows, предназначенное для извлечения текста из файлов PDF.Программа абсолютно бесплатна как для личного, так и для коммерческого использования.
После установки A-PDF Text Extractor (размер установщика меньше 1 МБ) запустите A-PDF Text Extractor. Нажмите кнопку «Открыть», чтобы открыть файл PDF, а затем нажмите кнопку «Извлечь текст», чтобы начать извлечение текста из него.
Метод 6 из 6
Читатель Gaaiho PDFGaaiho PDF Reader — отличная программа, предназначенная для работы с файлами PDF.Это бесплатное программное обеспечение предлагает множество функций, которых вы не найдете в других бесплатных программах для чтения PDF-файлов. Одна из функций — возможность с легкостью извлекать текст из файлов PDF.
Чтобы сохранить PDF-файл в виде текстового файла, после открытия PDF-файла в Gaaiho Reader выберите меню «Файл», нажмите «Сохранить как», а затем выберите параметр «PDF в текст» в раскрывающемся меню рядом с «Сохранить как тип».
Что вы думаете об этих инструментах? Знаете ли вы, что лучший бесплатный инструмент для той же работы? Дайте нам знать в комментариях.
Как извлечь текст из изображения или картинки с помощью OneNote
Существует несколько онлайн-инструментов для извлечения или получения текста из файла PDF. Если файл PDF не защищен от записи, вы можете выбрать и скопировать текст из файла PDF. Однако есть несколько инструментов для извлечения текста из файла изображения. Перед этим постом мы поделились бесплатным инструментом под названием Some PDF Images Extract, который позволяет извлекать изображения из файла PDF. Все новейшие программы Microsoft Word имеют встроенную опцию преобразования изображения в PDF.С помощью документа Microsoft Office Word также можно извлечь текст из файла изображения, но процедура долгая. Сначала нужно преобразовать изображение в файл PDF, а затем вы можете извлечь текст из изображения.
Если вы приобрели лицензию Microsoft Office и не хотите использовать сторонний инструмент для извлечения текста из изображений или изображений, вы даже можете использовать программу Microsoft OneNote, чтобы получить текст из изображения или снимка экрана. Извлечь текст из снимка экрана очень просто, а это значит, что вам не нужно конвертировать изображение или снимок экрана в файл PDF, а затем использовать документ Microsoft Word для получения текстов из файла изображения.
Приложение Microsoft OneNote менее известно пользователям ПК с Windows. По сути, этот инструмент учит вас, как использовать приложение Office для создания, редактирования и сохранения заметок. В дополнение к этому, этот хранитель заметок также может использоваться для вставки практически любого типа контента, включая таблицы, изображения, ссылки, распечатки файлов, видеоклипы, аудиозаписи и многое другое. Помимо поддержки таблицы, изображения, ссылки, распечатки файла, видеоклипа и аудиозаписи, он также имеет встроенную поддержку оптического распознавания символов (OCR), инструмента, который позволяет копировать текст из файла изображения.Скопировав текст из OneNote, вы можете вставить его в любое другое приложение, например Microsoft Word, Блокнот или Wordpad.
OCR (оптическое распознавание символов) — удобный инструмент, когда вам нужно скопировать информацию с любого изображения или отсканированных документов. Вы можете извлечь текст из любого типа изображения, отсканированного документа или снимка экрана, а также вставить его в другое место, чтобы сделать распечатку или отредактировать.
В этом посте будут показаны шаги по извлечению текста из изображения с помощью Microsoft OneNote 2019/2016/2013.
Как извлечь или скопировать текст из изображения с помощью OneNote 2019/2016/2013?
Шаг 1. Нажмите кнопку / меню «Пуск» в Windows 10/8/7 и введите OneNote .
Шаг 2. Из доступных результатов щелкните верхнюю запись OneNote , чтобы открыть ее.
Шаг 3. Скопируйте изображение со своего ПК, щелкнув его правой кнопкой мыши и выбрав опцию Копировать . Теперь в приложении OneNote вставьте изображение с помощью сочетания клавиш Ctrl + V .
Шаг 4. Теперь щелкните правой кнопкой мыши изображение в приложении OneNote и выберите параметр Копировать текст из изображения .
Шаг 5. Откройте любую программу Microsoft Word, Блокнот или Wordpad и нажмите Ctrl + V на клавиатуре, чтобы вставить скопированный текст.
После выполнения вышеуказанных шагов вы должны извлечь текст из изображения или картинки.
Вот и все !!!
СвязанныеАвтоматизируйте скучную работу с Python
Документы PDF и Word представляют собой двоичные файлы, что делает их намного сложнее, чем файлы с открытым текстом.В дополнение к тексту они хранят много информации о шрифтах, цвете и макете. Если вы хотите, чтобы ваши программы могли читать или писать в PDF-файлы или документы Word, вам нужно сделать больше, чем просто передать их имена в open () .
К счастью, есть модули Python, которые упрощают взаимодействие с документами PDF и Word. В этой главе будут рассмотрены два таких модуля: PyPDF2 и Python-Docx.
PDF означает Portable Document Format и использует .pdf расширение файла. Хотя PDF-файлы поддерживают множество функций, в этой главе основное внимание будет уделено двум вещам, которые вы будете с ними делать чаще всего: чтению текстового содержимого из PDF-файлов и созданию новых PDF-файлов из существующих документов.
Модуль, который вы будете использовать для работы с PDF, — PyPDF2. Чтобы установить его, запустите pip install PyPDF2 из командной строки. Это имя модуля чувствительно к регистру, поэтому убедитесь, что и написаны строчными буквами, а все остальное — прописными. (См. Приложение A для получения полной информации об установке сторонних модулей.) Если модуль был установлен правильно, запуск import PyPDF2 в интерактивной оболочке не должен отображать никаких ошибок.
Извлечение текста из PDF-файлов
PyPDF2 не имеет способа извлекать изображения, диаграммы или другие носители из документов PDF, но он может извлекать текст и возвращать его как строку Python. Чтобы начать изучение того, как работает PyPDF2, мы будем использовать его в примере PDF, показанном на рисунке 13-1.
Рисунок 13-1. Страница PDF, из которой мы будем извлекать текст из
Загрузите этот PDF-файл по адресу http: // nostarch.com / automatestuff / и введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFileObj = open ('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
❶ >>> pdfReader.numPages
19
❷ >>> pageObj = pdfReader.getPage (0)
❸ >>> pageObj.extractText ()
Заседание OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS от 7 марта 2015 г.
\ n Совет начального и среднего образования обеспечивает руководство
и разработать политику в области образования, которая расширяет возможности для детей,
расширять возможности семей и сообществ и продвигать Луизиану во все более
конкурентный глобальный рынок.КОЛЛЕГИЯ НАЧАЛЬНОГО И СРЕДНЕГО ОБРАЗОВАНИЯ ' Сначала импортируйте модуль PyPDF2 . Затем откройте файл meetingminutes.pdf в двоичном режиме чтения и сохраните его в pdfFileObj . Чтобы получить объект PdfFileReader , представляющий этот PDF-файл, вызовите PyPDF2.PdfFileReader () и передайте ему pdfFileObj . Сохраните этот объект PdfFileReader в pdfReader .
Общее количество страниц в документе хранится в атрибуте numPages объекта PdfFileReader ❶.В примере PDF 19 страниц, но давайте извлечем текст только с первой страницы.
Чтобы извлечь текст со страницы, вам необходимо получить объект Page , который представляет одну страницу PDF-файла, из объекта PdfFileReader . Вы можете получить объект Page , вызвав метод getPage () ❷ для объекта PdfFileReader и передав ему номер страницы, которая вас интересует — в нашем случае 0.
PyPDF2 использует индекс с отсчетом от нуля для получения страниц: первая страница — это страница 0, вторая — это Введение и так далее.Это всегда так, даже если страницы в документе пронумерованы по-разному. Например, предположим, что ваш PDF-файл представляет собой трехстраничный отрывок из более длинного отчета, и его страницы пронумерованы 42, 43 и 44. Чтобы получить первую страницу этого документа, вам нужно вызвать pdfReader.getPage (0) , а не getPage (42) или getPage (1) .
Получив объект Page , вызовите его метод extractText () , чтобы вернуть строку текста страницы ❸.Извлечение текста неидеально: текст Charles E. «Chas» Roemer, President из PDF-файла отсутствует в строке, возвращаемой функцией extractText () , а интервалы иногда отключены. Тем не менее, этого приближения к текстовому содержимому PDF может быть достаточно для вашей программы.
Некоторые PDF-документы имеют функцию шифрования, которая предотвращает их чтение до тех пор, пока открывающий документ не предоставит пароль. Введите в интерактивную оболочку следующее с загруженным PDF-файлом, который был зашифрован паролем rosebud :
>>> импорт PyPDF2
>>> pdfReader = PyPDF2.PdfFileReader (открытый ('encrypted.pdf', 'rb'))
❶ >>> pdfReader.isЗашифрованный
Правда
>>> pdfReader.getPage (0)
❷ Отслеживание (последний звонок последний):
Файл "", строка 1, в
pdfReader.getPage ()
- снип -
Файл "C: \ Python34 \ lib \ site-packages \ PyPDF2 \ pdf.py", строка 1173, в getObject
поднять utils.PdfReadError («файл не расшифрован»)
PyPDF2.utils.PdfReadError: файл не расшифрован
❸ >>> pdfReader.decrypt ('бутон розы')
1
>>> pageObj = pdfReader.getPage (0) Все объекты PdfFileReader имеют атрибут isEncrypted , который равен Истина , если PDF-файл зашифрован, и Ложь , если нет ❶. Любая попытка вызвать функцию, которая читает файл до того, как он был расшифрован с помощью правильного пароля, приведет к ошибке ❷.
Чтобы прочитать зашифрованный PDF-файл, вызовите функцию decrypt () и передайте пароль в виде строки ❸. После того, как вы вызовете decrypt () с правильным паролем, вы увидите, что вызов getPage () больше не вызывает ошибки. Если задан неправильный пароль, функция decrypt () вернет 0 , а getPage () продолжит сбой. Обратите внимание, что метод decrypt () расшифровывает только объект PdfFileReader , но не фактический файл PDF.После завершения программы файл на жестком диске остается зашифрованным. Ваша программа должна будет снова вызвать decrypt () при следующем запуске.
PyPDF2 объектам PdfFileReader — это объектов PdfFileWriter , которые могут создавать новые файлы PDF. Но PyPDF2 не может записывать произвольный текст в PDF, как Python может делать с файлами с открытым текстом. Вместо этого возможности PyPDF2 по написанию PDF-файлов ограничиваются копированием страниц из других PDF-файлов, поворотом страниц, наложением страниц и шифрованием файлов.
PyPDF2 не позволяет напрямую редактировать PDF. Вместо этого вам нужно создать новый PDF-файл, а затем скопировать содержимое из существующего документа. Примеры в этом разделе будут следовать этому общему подходу:
Откройте один или несколько существующих PDF-файлов (исходных PDF-файлов) в объектах
PdfFileReader.Создайте новый объект
PdfFileWriter.Копирует страницы из объектов
PdfFileReaderв объектPdfFileWriter.Наконец, используйте объект
PdfFileWriterдля записи выходного PDF.
Создание объекта PdfFileWriter создает только значение, представляющее документ PDF в Python. Он не создает фактический файл PDF. Для этого вы должны вызвать метод PdfFileWriter write () .
Метод write () принимает обычный объект File , который был открыт в режиме записи и двоичной записи .Вы можете получить такой объект File , вызвав функцию Python open () с двумя аргументами: строка того, что вы хотите, чтобы имя файла PDF было, и 'wb' , чтобы указать, что файл должен быть открыт в двоичном формате записи. режим.
Если это звучит немного запутанно, не волнуйтесь — вы увидите, как это работает, в следующих примерах кода.
PyPDF2 можно использовать для копирования страниц из одного документа PDF в другой. Это позволяет объединить несколько файлов PDF, вырезать ненужные страницы или изменить порядок страниц.
Загрузите meetingminutes.pdf и meetingminutes2.pdf из http://nostarch.com/automatestuff/ и поместите файлы PDF в текущий рабочий каталог. Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdf1File = open ('meetingminutes.pdf', 'rb')
>>> pdf2File = open ('meetingminutes2.pdf', 'rb')
❶ >>> pdf1Reader = PyPDF2.PdfFileReader (pdf1File)
❷ >>> pdf2Reader = PyPDF2.PdfFileReader (pdf2File)
❸ >>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdf1Reader.numPages):
❹ pageObj = pdf1Reader.getPage (pageNum)
❺ pdfWriter.addPage (pageObj)
>>> для pageNum in range (pdf2Reader.numPages):
❻ pageObj = pdf2Reader.getPage (pageNum)
❼ pdfWriter.addPage (pageObj)
❽ >>> pdfOutputFile = open ('Combinedminutes.pdf', 'wb')
>>> pdfWriter.write (pdfOutputFile)
>>> pdfOutputFile.close ()
>>> pdf1File.close ()
>>> pdf2File.close () Откройте оба файла PDF в двоичном режиме чтения и сохраните два результирующих объекта File в pdf1File и pdf2File .Вызовите PyPDF2.PdfFileReader () и передайте ему pdf1File , чтобы получить объект PdfFileReader для meetingminutes.pdf ❶. Вызовите его снова и передайте pdf2File , чтобы получить объект PdfFileReader для meetingminutes2.pdf ❷. Затем создайте новый объект PdfFileWriter , который представляет собой пустой документ PDF ❸.
Затем скопируйте все страницы из двух исходных PDF-файлов и добавьте их в объект PdfFileWriter .Получите объект Page , вызвав getPage () для объекта PdfFileReader ❹. Затем передайте этот объект Page методу addPage () вашего PdfFileWriter ❺. Эти шаги выполняются сначала для pdf1Reader , а затем снова для pdf2Reader . Когда вы закончите копирование страниц, напишите новый PDF-файл с именем commonutes.pdf , передав объект File методу PdfFileWriter write () ❻.
Примечание
PyPDF2 не может вставлять страницы в середину объекта PdfFileWriter ; метод addPage () добавит страницы только в конец.
Вы создали новый файл PDF, который объединяет страницы из meetingminutes.pdf и meetingminutes2.pdf в один документ. Помните, что объект File , переданный в PyPDF2.PdfFileReader () , необходимо открыть в двоичном режиме чтения, передав 'rb' в качестве второго аргумента функции open () . Точно так же объект File , переданный в PyPDF2.PdfFileWriter () , необходимо открыть в двоичном режиме записи с 'wb' .
Страницы PDF-файла также можно поворачивать с шагом 90 градусов с помощью методов rotateClockwise () и rotateCounterClockwise () . Передайте в эти методы одно из целых чисел 90 , 180 или 270 . Введите в интерактивную оболочку следующее, с файлом meetingminutes.pdf в текущем рабочем каталоге:
>>> импорт PyPDF2
>>> minutesFile = open ('meetingminutes.pdf ',' rb ')
>>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❶ >>> стр. = PdfReader.getPage (0)
❷ >>> стр. Поворот по часовой стрелке (90)
{'/ Contents': [IndirectObject (961, 0), IndirectObject (962, 0),
- снип -
}
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> pdfWriter.addPage (страница)
❸ >>> resultPdfFile = open ('rotatedPage.pdf ',' wb ')
>>> pdfWriter.write (resultPdfFile)
>>> результатPdfFile.close ()
>>> минутFile.close () Здесь мы используем getPage (0) для выбора первой страницы PDF ❶, а затем вызываем rotateClockwise (90) на этой странице ❷. Мы пишем новый PDF-файл с повернутой страницей и сохраняем его как rotatedPage.pdf ❸.
В результате PDF-файл будет содержать одну страницу, повернутую на 90 градусов по часовой стрелке, как показано на рисунке 13-2.Возвращаемые значения от rotateClockwise () и rotateCounterClockwise () содержат много информации, которую вы можете игнорировать.
Рисунок 13-2. Файл rotatedPage.pdf со страницей, повернутой на 90 градусов по часовой стрелке
PyPDF2 также может накладывать содержимое одной страницы на другую, что полезно для добавления на страницу логотипа, отметки времени или водяного знака. С Python легко добавлять водяные знаки в несколько файлов и только на страницы, указанные в вашей программе.
Загрузите watermark.pdf из http://nostarch.com/automatestuff/ и поместите PDF-файл в текущий рабочий каталог вместе с файлом meetingminutes.pdf . Затем введите в интерактивную оболочку следующее:
>>> импортировать PyPDF2
>>> minutesFile = open ('meetingminutes.pdf', 'rb')
❷ >>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❷ >>> minutesFirstPage = pdfReader.getPage (0)
❸ >>> pdfWatermarkReader = PyPDF2.PdfFileReader (open ('watermark.pdf', 'rb'))
❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0))
❺ >>> pdfWriter = PyPDF2.PdfFileWriter ()
❻ >>> pdfWriter.addPage (minutesFirstPage)
❼ >>> для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
>>> resultPdfFile = open ('watermarkedCover.pdf', 'wb')
>>> pdfWriter.написать (resultPdfFile)
>>> minutesFile.close ()
>>> resultPdfFile.close () Здесь мы создаем объект PdfFileReader из meetingminutes.pdf ❶. Мы вызываем getPage (0) , чтобы получить объект Page для первой страницы и сохранить этот объект через minutesFirstPage ❷. Затем мы создаем объект PdfFileReader для watermark.pdf ❸ и вызываем mergePage () на minutesFirstPage ❹.Аргумент, который мы передаем в функцию mergePage () , является объектом Page для первой страницы из watermark.pdf .
Теперь, когда мы вызвали mergePage () на minutesFirstPage , minutesFirstPage представляет первую страницу с водяными знаками. Мы создаем объект PdfFileWriter ❺ и добавляем первую страницу с водяным знаком ❻. Затем мы просматриваем остальные страницы в файле meetingminutes.pdf и добавляем их в объект PdfFileWriter ❼.Наконец, мы открываем новый PDF-файл с именем watermarkedCover.pdf и записываем содержимое PdfFileWriter в новый PDF-файл.
Рисунок 13-3 показывает результаты. Наш новый PDF-файл, watermarkedCover.pdf , содержит все содержимое файла meetingminutes.pdf , а первая страница снабжена водяными знаками.
Рисунок 13-3. Исходный PDF-файл (слева), PDF-файл с водяным знаком (в центре) и объединенный PDF-файл (справа)
Объект PdfFileWriter также может добавлять шифрование в документ PDF.Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFile = open ('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdfReader.numPages):
pdfWriter.addPage (pdfReader.getPage (pageNum))
❶ >>> pdfWriter.encrypt ('рыба-меч')
>>> resultPdf = open ('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write (resultPdf)
>>> результатPdf.close () Перед вызовом метода write () для сохранения в файл вызовите метод encrypt () и передайте ему строку пароля ❶. PDF-файлы могут иметь пароль пользователя (позволяющий просматривать PDF-файлы) и пароль владельца (позволяющий устанавливать разрешения на печать, комментирование, извлечение текста и другие функции).Пароль пользователя и пароль владельца являются первым и вторым аргументами функции encrypt () соответственно. Если в encrypt () передан только один строковый аргумент, он будет использоваться для обоих паролей.
В этом примере мы скопировали страницы meetingminutes.pdf в объект PdfFileWriter . Мы зашифровали PdfFileWriter паролем swordfish , открыли новый PDF-файл с именем encryptedminutes.pdf и записали содержимое PdfFileWriter в новый PDF-файл.Прежде чем кто-либо сможет просмотреть encryptedminutes.pdf , им нужно будет ввести этот пароль. Вы можете удалить исходный незашифрованный файл meetingminutes.pdf , убедившись, что его копия была правильно зашифрована.
Допустим, у вас скучная работа по объединению нескольких десятков PDF-документов в один PDF-файл. Каждая из них имеет титульный лист в качестве первой страницы, но вы не хотите, чтобы титульный лист повторялся в конечном результате. Несмотря на то, что существует множество бесплатных программ для объединения PDF-файлов, многие из них просто объединяют целые файлы вместе.Давайте напишем программу на Python, чтобы настроить, какие страницы вы хотите объединить в PDF.
На высоком уровне вот что будет делать программа:
Найти все файлы PDF в текущем рабочем каталоге.
Отсортируйте имена файлов, чтобы файлы PDF добавлялись по порядку.
Записать каждую страницу, кроме первой, каждого PDF-файла в выходной файл.
С точки зрения реализации ваш код должен будет сделать следующее:
Позвоните по телефону
os.listdir (), чтобы найти все файлы в рабочем каталоге и удалить все файлы, отличные от PDF.Вызовите метод списка Python
sort (), чтобы расположить имена файлов в алфавитном порядке.Создайте объект
PdfFileWriterдля выходного PDF-файла.Перебирайте каждый файл PDF, создавая для него объект
PdfFileReader.Прокрутите каждую страницу (кроме первой) в каждом файле PDF.
Добавьте страницы в выходной PDF-файл.
Запишите выходной PDF-файл в файл с именем allminutes.pdf .
Для этого проекта откройте новое окно редактора файлов и сохраните его как commonPdfs.py .
Шаг 1. Найти все файлы PDF
Во-первых, ваша программа должна получить список всех файлов с расширением .pdf в текущем рабочем каталоге и отсортировать их.Сделайте так, чтобы ваш код выглядел следующим образом:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# в один PDF-файл.
❶ импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
для имени файла в os.listdir ('.'):
если filename.endswith ('. pdf'):
❷ pdfFiles.append (имя файла)
❸ pdfFiles.sort (ключ = str.lower)
❹ pdfWriter = PyPDF2.PdfFileWriter ()
# TODO: просмотреть все файлы PDF.# ЗАДАЧА: Прокрутите все страницы (кроме первой) и добавьте их.
# ЗАДАЧА: сохранить полученный PDF-файл в файл. После строки shebang и описательного комментария о том, что делает программа, этот код импортирует модули os и PyPDF2 ❶. Вызов os.listdir ('.') вернет список всех файлов в текущем рабочем каталоге. Код проходит по этому списку и добавляет только файлы с расширением .pdf в pdfFiles ❷.После этого этот список сортируется в алфавитном порядке с аргументом ключевого слова key = str.lower для функции sort () ❸.
Создается объект PdfFileWriter для хранения объединенных страниц PDF ❹. Наконец, несколько комментариев обрисовывают остальную часть программы.
Теперь программа должна читать каждый файл PDF в pdfFiles . Добавьте в свою программу следующее:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdf Файлы:
pdfFileObj = open (имя файла, 'rb')
pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
# ЗАДАЧА: Прокрутите все страницы (кроме первой) и добавьте их.
# ЗАДАЧА: сохранить полученный PDF-файл в файл. Для каждого PDF-файла цикл открывает имя файла в двоичном режиме чтения, вызывая open () с 'rb' в качестве второго аргумента.Вызов open () возвращает объект File , который передается в PyPDF2.PdfFileReader () для создания объекта PdfFileReader для этого PDF-файла.
Для каждого PDF-файла вы захотите перебрать каждую страницу, кроме первой. Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.для имени файла в pdfFiles:
- снип -
# Просмотрите все страницы (кроме первой) и добавьте их.
❶ за pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
# ЗАДАЧА: сохранить полученный PDF-файл в файл. Код внутри цикла для копирует каждый объект Page индивидуально в объект PdfFileWriter .Помните, вы хотите пропустить первую страницу. Поскольку PyPDF2 считает 0 первой страницей, ваш цикл должен начинаться с 1 ❶, а затем увеличиваться, но не включать целое число в pdfReader.numPages .
После того, как эти вложенные циклы для будут выполнены в цикле, переменная pdfWriter будет содержать объект PdfFileWriter со страницами для всех объединенных PDF-файлов. Последний шаг — записать это содержимое в файл на жестком диске.Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdfFiles:
- снип -
# Прокрутите все страницы (кроме первой) и добавьте их.
для pageNum в диапазоне (1, pdfReader.numPages):
- снип -
# Сохраните полученный PDF-файл в файл.
pdfOutput = open ('allminutes.pdf', 'wb')
pdfWriter.write (pdfOutput)
pdfOutput.close () Передача 'wb' в open () открывает выходной PDF-файл, allminutes.pdf , в двоичном режиме записи. Затем передача результирующего объекта File методу write () создает фактический файл PDF. Вызов метода close () завершает программу.
Идеи для похожих программ
Возможность создавать PDF-файлы из страниц других PDF-файлов позволит вам создавать программы, которые могут выполнять следующие действия:
Вырезайте определенные страницы из PDF-файлов.
Изменение порядка страниц в PDF.
Создайте PDF-файл только из тех страниц, на которых есть определенный текст, идентифицированный с помощью
extractText ().
Python может создавать и изменять документы Word с расширением файла .docx с помощью модуля python-docx . Вы можете установить модуль, запустив pip install python-docx . (Приложение A содержит полную информацию об установке сторонних модулей.)
Примечание
При использовании pip для первой установки Python-Docx обязательно установите python-docx , а не docx . Имя установки docx относится к другому модулю, который не рассматривается в этой книге. Однако, когда вы собираетесь импортировать модуль python-docx , вам нужно будет запустить import docx , а не import python-docx .
Если у вас нет Word, LibreOffice Writer и OpenOffice Writer — это бесплатные альтернативные приложения для Windows, OS X и Linux, которые можно использовать для открытия .docx файлов. Вы можете загрузить их с https://www.libreoffice.org и http://openoffice.org соответственно. Полная документация по Python-Docx доступна по адресу https://python-docx.readthedocs.org/ . Хотя существует версия Word для OS X, в этой главе основное внимание будет уделено Word для Windows.
По сравнению с обычным текстом файлы .docx имеют большую структуру. Эта структура представлена в Python-Docx тремя разными типами данных.На самом высоком уровне объект Document представляет весь документ. Объект Document содержит список объектов Paragraph для абзацев в документе. (Новый абзац начинается всякий раз, когда пользователь нажимает ENTER или RETURN при вводе документа Word.) Каждый из этих объектов Paragraph содержит список из одного или нескольких объектов Run . Абзац из одного предложения на рис. 13-4 состоит из четырех частей.
Рисунок 13-4.Объект Run , идентифицированный в объекте Paragraph
Текст в документе Word — это больше, чем просто строка. С ним связаны шрифт, размер, цвет и другая информация о стиле. Стиль в Word представляет собой набор этих атрибутов. Объект Run — это непрерывный фрагмент текста с одинаковым стилем. При изменении стиля текста требуется новый объект Run .
Давайте поэкспериментируем с модулем python-docx .Загрузите demo.docx из http://nostarch.com/automatestuff/ и сохраните документ в рабочем каталоге. Затем введите в интерактивную оболочку следующее:
>>> импорт docx
❶ >>> doc = docx.Document ('demo.docx')
❷ >>> len (док. Абзацы)
7
❸ >>> док. Абзацы [0]. Текст
'Название документа'
❹ >>> док. Абзацев [1].текст
'Простой абзац с полужирным шрифтом и курсивом'
❺ >>> len (док. Параграфы [1] .runs)
4
❻ >>> doc.paragraphs [1] .runs [0] .text
'Простой абзац с некоторыми'
❼ >>> док. Параграфы [1] .runs [1] .text
'жирный'
❽ >>> док. Параграфы [1] .runs [2] .text
' и немного '
➒ >>> док. Параграфы [1] .runs [3] .text
'курсив' В ❶ мы открываем .docx в Python, вызовите docx.Document () и передайте имя файла demo.docx . Это вернет объект Document , который имеет атрибут параграфов , который представляет собой список объектов Paragraph . Когда мы вызываем len () в doc.paragraphs , он возвращает 7 , что говорит нам о семи объектах Paragraph в этом документе ❷. Каждый из этих объектов Paragraph имеет атрибут text , который содержит строку текста в этом абзаце (без информации о стиле).Здесь первый атрибут text содержит 'DocumentTitle' ❸, а второй содержит 'Простой абзац с полужирным шрифтом и курсивом' ❹.
Каждый объект Paragraph также имеет атрибут Run , который представляет собой список объектов Run . Run Объекты также имеют атрибут text , содержащий только текст в этом конкретном прогоне. Давайте посмотрим на атрибут текста во втором объекте Paragraph , 'Простой абзац с полужирным шрифтом и курсивом' .Вызов len () для этого объекта Paragraph сообщает нам, что существует четыре объекта Run ❺. Объект первого запуска содержит 'Простой абзац с некоторым' ❻. Затем текст меняется на полужирный, поэтому «полужирный» запускает новый объект Run ❼. После этого текст возвращается к стилю без полужирного шрифта, что приводит к появлению третьего объекта Run , 'и некоторого количества' ❽. Наконец, четвертый и последний объект Run содержит «курсив» курсивом ➒.
С Python-Docx ваши программы Python теперь смогут читать текст из файла .docx и использовать его, как любое другое строковое значение.
Получение полного текста из файла .docx
Если вас интересует только текст, а не информация о стилях в документе Word, вы можете использовать функцию getText () . Он принимает имя файла .docx и возвращает одно строковое значение его текста. Откройте новое окно редактора файлов и введите следующий код, сохранив его как readDocx.py :
#! python3
импорт docx
def getText (имя файла):
doc = docx.Document (имя файла)
fullText = []
для пункта в пунктах документа:
fullText.append (параграф)
return '\ n'.join (fullText) Функция getText () открывает документ Word, перебирает все объекты Paragraph в списке параграфов , а затем добавляет их текст в список в fullText . После цикла строки в fullText объединяются с помощью символов новой строки.
Программа readDocx.py может быть импортирована как любой другой модуль. Теперь, если вам просто нужен текст из документа Word, вы можете ввести следующее:
>>> импорт чтения Docx
>>> печать (readDocx.getText ('demo.docx'))
Название документа
Простой абзац с полужирным шрифтом и курсивом
Заголовок, уровень 1
Интенсивная цитата
первый элемент в неупорядоченном списке
первая позиция в упорядоченном списке Вы также можете настроить getText () , чтобы изменить строку перед ее возвратом.Например, чтобы сделать отступ для каждого абзаца, замените вызов append () в readDocx.py следующим образом:
fullText.append ( '' + параграф текста)
Чтобы добавить двойной пробел между абзацами, измените код вызова join () на следующий:
return '\ n \ n ' .join (fullText)
Как видите, требуется всего несколько строк кода для написания функций, которые будут читать файл .docx и возвращать строку его содержимого по вашему вкусу.
Стилизация абзацев и объектов бега
В Word для Windows стили можно просмотреть, нажав CTRL-ALT-SHIFT-S, чтобы отобразить панель «Стили», как показано на рис. 13-5. В OS X вы можете просмотреть панель стилей, щелкнув пункт меню View ▸ Styles .
Рисунок 13-5. Откройте панель стилей, нажав CTRL-ALT-SHIFT -S в Windows.
Word и другие текстовые процессоры используют стили, чтобы визуальное представление похожих типов текста было согласованным и легко изменяемым.Например, возможно, вы хотите установить основные абзацы шрифтом Times New Roman размером 11 пунктов, с выравниванием по левому краю и неровным правым текстом. Вы можете создать стиль с этими настройками и назначить его всем абзацам основного текста. Затем, если вы позже захотите изменить представление всех основных абзацев в документе, вы можете просто изменить стиль, и все эти абзацы будут автоматически обновлены.
Для документов Word существует три типа стилей: стили абзацев могут применяться к объектам абзаца , стили символов могут применяться к объектам Run и связанные стили могут применяться к обоим типам объекты.Вы можете задать стили объектам Paragraph и Run , установив их атрибут style в строку. Эта строка должна быть именем стиля. Если для стиля установлено значение Нет , то не будет никакого стиля, связанного с объектом Paragraph или Run .
Строковые значения для стилей Word по умолчанию следующие:
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | |
При установке атрибута стиля не используйте пробелы в имени стиля.Например, хотя имя стиля может быть «Тонкое выделение», вы должны установить для атрибута стиля строковое значение «SubtleEmphasis» вместо «Тонкое выделение» . Включение пробелов приведет к тому, что Word неправильно прочитает имя стиля и не применит его.
При использовании связанного стиля для объекта Run вам нужно добавить 'Char' в конец его имени. Например, чтобы установить связанный стиль Quote для объекта Paragraph , вы должны использовать paragraphObj.style = 'Quote' , но для объекта Run вы должны использовать runObj.style = 'QuoteChar' .
В текущей версии Python-Docx (0.7.4) можно использовать только стили Word по умолчанию и стили в открытом .docx . Новые стили не могут быть созданы, хотя это может измениться в будущих версиях Python-Docx.
Создание документов Word со стилями не по умолчанию
Если вы хотите создать документы Word, в которых используются стили помимо стандартных, вам нужно будет открыть Word в пустой документ Word и самостоятельно создать стили, нажав кнопку New Style в нижней части панели стилей (рис. -6 показывает это в Windows).
Откроется диалоговое окно «Создать новый стиль из форматирования», в котором можно ввести новый стиль. Затем вернитесь в интерактивную оболочку и откройте этот пустой документ Word с помощью docx.Document () , используя его в качестве основы для документа Word. Имя, которое вы дали этому стилю, теперь будет доступно для использования с Python-Docx.
Рисунок 13-6. Кнопка «Новый стиль» (слева) и диалоговое окно «Создать новый стиль из форматирования» (справа)
Прогонам можно дополнительно стилизовать с помощью текстовых атрибутов .Каждому атрибуту можно присвоить одно из трех значений: True (атрибут всегда включен, независимо от того, какие другие стили применяются к запуску), False (атрибут всегда отключен) или None (по умолчанию независимо от того, установлен ли стиль запуска).
В таблице 13-1 перечислены атрибуты text , которые можно установить для объектов Run .
Таблица 13-1. Выполнить Объект текст Атрибуты
Атрибут | Описание |
|---|---|
| Текст выделен жирным шрифтом. |
| Текст выделен курсивом. |
| Текст подчеркнут. |
| Текст зачеркивается. |
| Текст выделен двойным зачеркиванием. |
| Текст отображается заглавными буквами. |
| Текст отображается заглавными буквами, а строчные буквы на два пункта меньше. |
| Текст отображается с тенью. |
| Текст выглядит обведенным, а не сплошным. |
| Текст пишется справа налево. |
| Текст кажется вдавленным на страницу. |
| Текст выглядит рельефно приподнятым над страницей. |
Например, чтобы изменить стили demo.docx , введите в интерактивную оболочку следующее:
>>> doc = docx.Document ('demo.docx')
>>> док. Абзацы [0]. Текст
'Название документа'
>>> док. Абзацы [0]. Стиль
'Заголовок'
>>> doc.paragraphs [0] .style = 'Normal'
>>> док. Абзацы [1]. Текст
'Простой абзац с полужирным шрифтом и курсивом'
>>> (док.параграфы [1] .runs [0] .text, doc.paragraphs [1] .runs [1] .text, doc.
абзацев [1] .runs [2] .text, doc.paragraphs [1] .runs [3] .text)
(«Обычный абзац с некоторыми», «полужирным», «и некоторыми», «курсивом»)
>>> doc.paragraphs [1] .runs [0] .style = 'QuoteChar'
>>> doc.paragraphs [1] .runs [1] .underline = True
>>> doc.paragraphs [1] .runs [3] .underline = True
>>> doc.save ('restyled.docx') Здесь мы используем атрибуты text и style , чтобы легко увидеть, что находится в абзацах в нашем документе.Мы видим, что разделить абзац на запуски и получить доступ к каждому запуску индивидуально просто. Итак, мы получаем первое, второе и четвертое прогоны во втором абзаце, стилизуем каждый прогон и сохраняем результаты в новом документе.
Слова Document Title в верхней части restyled.docx будут иметь стиль Normal вместо стиля Title, объект Run для текста Простой абзац с некоторым количеством будет иметь стиль QuoteChar, а два объекта Run для слов жирным шрифтом и курсивом будут иметь атрибуты подчеркивания , для которых установлено значение True .На рис. 13-7 показано, как выглядят стили абзацев и строк в файле restyled.docx .
Рисунок 13-7. рестайлинг.docx файл
Более полную документацию по использованию стилей Python-Docx можно найти по адресу https://python-docx.readthedocs.org/en/latest/user/styles.html .
Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> док.add_paragraph ('Привет, мир!')
>>> doc.save ('helloworld.docx') Чтобы создать собственный файл .docx , вызовите docx.Document () , чтобы вернуть новый пустой объект Word Document . Метод документа add_paragraph () добавляет в документ новый абзац текста и возвращает ссылку на добавленный объект Paragraph . Когда вы закончите добавлять текст, передайте строку имени файла методу документа save () , чтобы сохранить объект Document в файл.
Это создаст файл с именем helloworld.docx в текущем рабочем каталоге, который при открытии выглядит как на рис. 13-8.
Рисунок 13-8. Документ Word, созданный с использованием add_paragraph ('Hello world!')
Вы можете добавить абзацы, снова вызвав метод add_paragraph () с текстом нового абзаца. Или, чтобы добавить текст в конец существующего абзаца, вы можете вызвать метод абзаца add_run () и передать ему строку.Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Hello world!')
<объект docx.text.Paragraph по адресу 0x000000000366AD30>
>>> paraObj1 = doc.add_paragraph ('Это второй абзац.')
>>> paraObj2 = doc.add_paragraph ('Это еще один абзац.')
>>> paraObj1.add_run ('Этот текст добавляется ко второму абзацу.')
>>> doc.save ('multipleParagraphs.docx') В результате документ будет выглядеть как на Рисунке 13-9. Обратите внимание, что текст Этот текст добавляется ко второму абзацу. был добавлен к объекту Paragraph в paraObj1 , который был вторым абзацем, добавленным в doc . Функции add_paragraph (), и add_run (), возвращают абзац и Run , соответственно, чтобы избавить вас от необходимости извлекать их как отдельный шаг.
Имейте в виду, что начиная с версии 0.5.3 Python-Docx, новые объекты Paragraph можно добавлять только в конец документа, а новые объекты Run можно добавлять только в конец объекта Paragraph . .
Метод save () можно вызвать снова, чтобы сохранить внесенные вами дополнительные изменения.
Рисунок 13-9. В документ с несколькими объектами Paragraph и Run добавлено
И add_paragraph (), , и add_run () принимают необязательный второй аргумент, который является строкой стиля объекта Paragraph или Run .Например:
>>> doc.add_paragraph ('Hello world!', 'Title') Эта строка добавляет абзац с текстом Hello world! в стиле Заголовок.
Вызов add_heading () добавляет абзац с одним из стилей заголовка. Введите в интерактивную оболочку следующее:
>>> doc = docx.Document ()
>>> doc.add_heading ('Заголовок 0', 0)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> док.add_heading ('Заголовок 1', 1)
<объект docx.text.Paragraph в 0x00000000036CB630>
>>> doc.add_heading ('Заголовок 2', 2)
>>> doc.add_heading ('Заголовок 3', 3)
<объект docx.text.Paragraph в 0x00000000036CB2E8>
>>> doc.add_heading ('Заголовок 4', 4)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> doc.save ('заголовки.docx ') Аргументы для add_heading () — это строка текста заголовка и целое число от 0 до 4 . Целое число 0 делает заголовок стилем заголовка, который используется для верхней части документа. Целые числа от 1 до 4 относятся к разным уровням заголовков, причем 1 является основным заголовком, а 4 — самым низким подзаголовком. Функция add_heading () возвращает объект Paragraph , чтобы сэкономить вам этап извлечения его из объекта Document в качестве отдельного шага.
Результирующий файл headings.docx будет выглядеть, как показано на Рисунке 13-10.
Рисунок 13-10. Документ headings.docx с заголовками от 0 до 4
Добавление строк и разрывов страниц
Чтобы добавить разрыв строки (а не начинать новый абзац), вы можете вызвать метод add_break () для объекта Run , после которого должен отображаться разрыв. Если вместо этого вы хотите добавить разрыв страницы, вам нужно передать значение docx.text.WD_BREAK.PAGE как единственный аргумент для add_break () , как это сделано в середине следующего примера:
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Это на первой странице!')
<объект docx.text.Paragraph по адресу 0x0000000003785518>
❶ >>> doc.paragraphs [0] .runs [0] .add_break (docx.text.WD_BREAK.PAGE)
>>> doc.add_paragraph ('Это на второй странице!')
>>> doc.save ('twoPage.docx') Это создает двухстраничный документ Word с Это на первой странице! на первой странице и это на второй странице! на втором. Несмотря на то, что на первой странице после текста все еще было достаточно места. Это на первой странице! , мы заставили следующий абзац начинаться на новой странице, вставив разрыв страницы после первого прогона первого абзаца ❶.
Объекты документа имеют метод add_picture () , который позволяет добавлять изображение в конец документа. Допустим, у вас есть файл zophie.png в текущем рабочем каталоге. Вы можете добавить zophie.png в конец документа с шириной 1 дюйм и высотой 4 сантиметра (Word может использовать как британские, так и метрические единицы измерения), введя следующее:
>>> doc.add_picture ('zophie.png', width = docx.shared.Дюймы (1),
высота = docx.shared.Cm (4))
<объект docx.shape.InlineShape по адресу 0x00000000036C7D30> Первый аргумент — это строка имени файла изображения. Необязательные аргументы ключевого слова width и height задают ширину и высоту изображения в документе. Если не указано иное, ширина и высота по умолчанию будут равны нормальному размеру изображения.
Вы, вероятно, предпочтете указывать высоту и ширину изображения в знакомых единицах измерения, таких как дюймы и сантиметры, поэтому вы можете использовать docx.shared.Inches () и docx.shared.Cm () , если вы указываете аргументы ключевого слова width и height .
Извлечение текста из PDF-файла Python + полезные примеры
В этом руководстве Python объясняется, что извлекает текст из PDF-файла Python . Мы увидим, как извлекать текст из файлов PDF в Python с помощью Python Tkinter. Я также покажу конвертер pdf в word , который мы разработали с использованием Python.
Также проверим:
- Копировать текст из файла PDF в Python
- Как извлечь текст из файла PDF с помощью Python Tkinter
- Удалить текст из файла PDF в Python
- Как скопировать текст из изображений из файла PDF в Python
- Невозможно скопировать текст из pdf
- Как скопировать текст из PDF в Word в Python
- Скопировать текст из PDF в Интернете
- Удалить текст из PDF в Интернете
- Как выбрать текст из PDF в Python
Перед тем, как выполнять приведенные ниже примеры, ознакомьтесь с приведенными ниже три статьи:
Python скопировать текст из файла pdf
- В этом разделе мы узнаем, как копировать текст из файлов PDF с помощью Python .Также мы будем демонстрировать все, используя Python Tkinter. Мы предполагаем, что вы уже установили модуль PyPDF2 и Tkinter в своей системе.
- Процесс копирования текста в Python Tkinter разделен на две части:
- В первой части мы будем извлекать текст из PDF с помощью модуля PyPDF2 в Python.
- На втором этапе мы будем копировать текст с помощью функции
clipboard (), доступной в Python Tkinter.
Вот код для чтения и извлечения данных из PDF с помощью модуля PyPDF2 в Python.
reader = PdfFileReader (имя файла)
pageObj = reader.getNumPages ()
для page_count в диапазоне (pageObj):
page = reader.getPage (page_count)
page_data = page.extractText ()
- В первой строке мы создали переменную «reader», которая содержит путь к файлу PDF. Здесь имя файла относится к имени файла с путем.
- Во второй строке мы получили общее количество страниц, имеющихся в файле PDF.
- В третьей строке запускается цикл, и он будет перебирать общее количество страниц в файле PDF.
- Каждый раз при запуске цикла отображается текстовая информация, имеющаяся в файле PDF.
- Таким образом, мы можем извлечь текст из PDF с помощью модуля PyPDF2 в Python.
Вот код для копирования текста с помощью Python Tkinter.
ws.withdraw ()
ws.clipboard_clear ()
ws.clipboard_append (содержимое)
ws.update ()
ws.destroy () - Здесь ws — главное окно.
- Первая строка кода используется для удаления окна с экрана без его разрушения.
- Во второй строке кода мы удалили весь текст, если он уже скопирован.
- третья строка кода — это действие по копированию содержимого. Здесь контент можно заменить текстом, который вы хотите скопировать.
- Важно, чтобы текст оставался скопированным даже после закрытия окна. Для этого мы используем функцию обновления.
- В последней строке кода мы просто уничтожили окно. Вы можете удалить этот код, если не хотите, чтобы окно закрывалось.
Фрагмент кода:
Вот код небольшого проекта, который включает в себя все, что мы узнали до сих пор. Этот проект представляет собой программу на основе графического интерфейса, созданную с использованием Python Tkinter для копирования текста из PDF.
из PyPDF2 импортировать PdfFileReader
из tkinter import *
from tkinter import filedialog
ws = Tk ()
ws.title ('PythonGuides')
ws.geometry ('400x300')
ws.config (bg = '# D9653B')
def choose_pdf ():
filename = filedialog.askopenfilename (
initialdir = "/", # для пользователей Linux и Mac
# initialdir = "C: /", для пользователей Windows
title = "Выберите файл",
filetypes = (("PDF-файлы", "*.pdf * "), (" все файлы "," *. * ")))
если имя файла:
вернуть имя файла
def read_pdf ():
имя файла = выбрать_pdf ()
reader = PdfFileReader (имя файла)
pageObj = reader.getNumPages ()
для page_count в диапазоне (pageObj):
page = reader.getPage (page_count)
page_data = page.extractText ()
textbox.insert (КОНЕЦ, данные_страницы)
def copy_pdf_text ():
content = textbox.get (1.0, "конец-1c")
ws.withdraw ()
ws.clipboard_clear ()
ws.clipboard_append (содержимое)
ws.update ()
ws.разрушать()
текстовое поле = Текст (
WS,
высота = 13,
ширина = 40,
wrap = 'слово',
bg = '# D9BDAD'
)
textbox.pack (expand = True)
Кнопка(
WS,
text = 'Выбрать файл PDF',
padx = 20,
пады = 10,
bg = '# 262626',
fg = 'белый',
команда = read_pdf
) .pack (expand = True, side = LEFT, pady = 10)
Кнопка(
WS,
text = "Копировать текст",
padx = 20,
пады = 10,
bg = '# 262626',
fg = 'белый',
command = copy_pdf_text
) .pack (expand = True, side = LEFT, pady = 10)
ws.mainloop ()
Выход:
В этом выводе мы использовали текстовое поле Python Tkinter для отображения текста файла PDF.Пользователь нажимает кнопку Выбрать файл PDF . Используя диалоговое окно файла в Python Tkinter, он / она может перемещаться и выбирать файл PDF на компьютере.
Текст будет отображаться в текстовом поле немедленно. Отсюда пользователь может скопировать текст, просто нажав кнопку Копировать текст . Текст будет скопирован, и его можно будет вставить куда угодно, как обычно.
Python скопировать текст из файла pdfВот как скопировать текст из файла PDF в Python .
- В этом разделе мы узнаем , как извлекать текст из PDF с помощью Python Tkinter . Модуль PyPDF2 в Python предлагает метод extractText () , с помощью которого мы можем извлекать текст из PDF в Python.
- В предыдущем разделе, где мы продемонстрировали , как копировать текст в Python Tkinter . Здесь мы использовали метод extractText () для отображения текста на экране.
- Вот код из предыдущего раздела для извлечения текста из PDF с помощью модуля PyPDF в Python Tkinter.
reader = PdfFileReader (имя файла)
pageObj = reader.getNumPages ()
для page_count в диапазоне (pageObj):
page = reader.getPage (page_count)
page_data = page.extractText ()
- В этой первой строке кода мы создали объект PdfFileReader. Здесь имя файла — это имя файла PDF с полным путем.
- Во второй строке кода мы собрали общее количество страниц, доступных в файле PDF. Эта информация будет в дальнейшем использоваться в цикле.
- В третьей строке кода мы запустили цикл для , цикл , который будет суммировать количество страниц, представленных в файле PDF. например, если PDF-файл содержит 10 страниц, цикл будет выполняться 10 раз.
- Каждый раз при запуске цикла он добавляет информацию о каждой странице в переменную page. Это означает, что переменная Page содержит информацию о каждой странице PDF-файла.
- Теперь, применив метод extractText () к переменной «page», мы можем извлечь и отобразить весь текст PDF в удобочитаемом формате.
- Весь отображаемый здесь текст использует метод extractText () модуля PyPDF2 в Python. Исходный код см. В предыдущем разделе.
Вот как извлечь текст из pdf python .
Чтение: загрузка файла в Python Tkinter
Удалить текст из файла PDF в Python
Ниже приведен полный код для удаления текста из файла PDF в Python .
из PyPDF2 импортировать PdfFileReader
из tkinter import *
from tkinter import filedialog
ws = Tk ()
ws.название ('PythonGuides')
ws.geometry ('400x300')
ws.config (bg = '# D9653B')
путь = []
def save_pdf ():
content = textbox.get (1.0, "конец-1c")
content.output (путь [0])
def saveas_pdf ():
проходить
def choose_pdf ():
глобальный путь
filename = filedialog.askopenfilename (
initialdir = "/", # для пользователей Linux и Mac
# initialdir = "C: /", для пользователей Windows
title = "Выберите файл",
filetypes = (("PDF-файлы", "*. pdf *"), ("все файлы", "*. *")))
если имя файла:
дорожка.добавить (имя файла)
вернуть имя файла
def read_pdf ():
имя файла = выбрать_pdf ()
reader = PdfFileReader (имя файла)
pageObj = reader.getNumPages ()
для page_count в диапазоне (pageObj):
page = reader.getPage (page_count)
page_data = page.extractText ()
textbox.insert (КОНЕЦ, данные_страницы)
def copy_pdf_text ():
content = textbox.get (1.0, "конец-1c")
ws.withdraw ()
ws.clipboard_clear ()
ws.clipboard_append (содержимое)
ws.update ()
ws.destroy ()
fmenu = Меню (
мастер = WS,
bg = '# D9653B',
рельеф = ПАЗ
)
ws.config (меню = fmenu)
file_menu = Меню (
fmenu,
tearoff = Ложь
)
fmenu.add_cascade (
label = "Файл", menu = file_menu
)
file_menu.add_command (
label = "Открыть",
команда = read_pdf
)
file_menu.add_command (
label = "Сохранить",
команда = save_pdf
)
file_menu.add_command (
label = "Сохранить как",
command = None # ToDo
)
file_menu.add_separator ()
file_menu.add_command (
label = "Выход",
команда = ws.destroy
)
текстовое поле = Текст (
WS,
высота = 13,
ширина = 40,
wrap = 'слово',
bg = '# D9BDAD'
)
текстовое окно.pack (expand = True)
Кнопка(
WS,
text = 'Выбрать файл PDF',
padx = 20,
пады = 10,
bg = '# 262626',
fg = 'белый',
команда = read_pdf
) .pack (expand = True, side = LEFT, pady = 10)
Кнопка(
WS,
text = "Копировать текст",
padx = 20,
пады = 10,
bg = '# 262626',
fg = 'белый',
command = copy_pdf_text
) .pack (expand = True, side = LEFT, pady = 10)
ws.mainloop ()
Чтение: генератор QR-кода Python с использованием pyqrcode в Tkinter
- Чтение или копирование текста с изображения — сложный процесс, требующий алгоритма машинного обучения.
- Каждый язык имеет разную схему написания алфавитов. Поэтому для этого требуется набор данных из алфавитов и слов с разной каллиграфией на определенном языке, который написан на изображении.
- Когда этот набор данных передается в алгоритм машинного обучения, он начинает идентифицировать текст на изображении путем сопоставления с шаблоном алфавитов.
- OCR (Оптическое распознавание символов) — это библиотека Python, которая запускает алгоритм машинного обучения для идентификации символов на изображениях.
- Python извлекает текст из изображения . Тема будет рассмотрена в разделе «Машинное обучение».
Не удается скопировать текст из PDF в Python
В этом разделе мы расскажем об общих проблемах, возникающих при чтении PDF с использованием Python Tkinter. Итак, если вы не можете скопировать текст из pdf в Python, проверьте следующие моменты.
- Если PDF-файл используется другим процессом, вы не можете скопировать текст из PDF.
- Дважды проверьте файл PDF, если вы видите сообщение о невозможности скопировать текст из PDF.
Это общие наблюдения, при которых пользователи не могут копировать текст из PDF.Если вы столкнулись с какой-либо другой проблемой, оставьте ее в комментарии ниже.
Чтение перетаскивания Python Tkinter
Как скопировать текст из PDF в Word в Python
- Чтобы скопировать текст из PDF в файл Word с помощью Python, мы используем модуль pdf2docs в Python.
- pdf2docx позволяет конвертировать любой документ PDF в файл Word с помощью Python. Этот файл Word можно в дальнейшем открыть с помощью сторонних приложений, таких как Microsoft Word, Libre Office и WPS.
- Первым шагом в этом процессе является установка модуля pdf2docs .Используя pip , вы можете установить модуль на свое устройство в любой операционной системе.
pip install pdf2docx Фрагмент кода:
Этот код показывает, как PDF можно преобразовать в файл Word с помощью Python Tkinter.
из tkinter import *
from tkinter import filedialog
импортировать pdf2docx
путь = []
def convert_toword ():
глобальный путь
данные = []
файл = filedialog.asksaveasfile (
defaultextension = данные,
filetypes = (("Файлы WORD", "*.docx * "), (" все файлы "," *. * ")),
)
pdf2docx.parse (
pdf_file = путь [0],
docx_file = имя_файла,
start = 0,
конец = Нет,
)
def choose_file ():
глобальный путь
path.clear ()
filename = filedialog.askopenfilename (
initialdir = "/", # для пользователей Linux и Mac
# initialdir = "C: /", для пользователей Windows
title = "Выберите файл",
filetypes = (("PDF-файлы", "*. pdf *"), ("все файлы", "*. *")))
path.append (имя файла)
ws = Tk ()
ws.название ('PythonGuides')
ws.geometry ('400x300')
ws.config (bg = '# F2E750')
choose_btn = Кнопка (
WS,
text = 'Выбрать файл',
padx = 20,
пады = 10,
bg = '# 344973',
fg = 'белый',
команда = выбрать_файл
)
choose_btn.pack (expand = True, side = LEFT)
convert_btn = Кнопка (
WS,
text = 'Преобразовать в Word',
padx = 20,
пады = 10,
bg = '# 344973',
fg = 'белый',
команда = convert_toword
)
convert_btn.pack (expand = True, side = LEFT)
ws.mainloop () Выход:
Это вывод главного экрана приложения.Пользователь может выбрать файл PDF, нажав кнопку Выбрать файл . И после выбора он может щелкнуть преобразовать в Word PDF. Файл Word будет создан в том же каталоге, из которого был выбран файл PDF.
рис 1: главный экран приложениярис. 2 показывает внешний вид диалогового окна файла, когда пользователь нажимает кнопку «Выбрать файл». Итак, пользователь выбрал Grades.pdf
рис 2: выбор PDFНа рис. 3 показан внешний вид диалогового окна сохранения файла.Пользователь сохраняет файл с расширением .docx .
Рис. 3: преобразование в словоНа рис. 4 показано преобразование PDF в файл Word. В этом случае вы можете увидеть, что документ Word создан с именем updatedGrades.docx . Это имя предоставлено пользователем на рис. 3.
рис 4: файл преобразован в текстовый документЭто , как скопировать текст из PDF в Word в Python .
Прочтите: создание игры с использованием Python Pygame
Как выделить текст из файла PDF в Python
- В этом разделе мы узнаем, как выбрать текст из PDF с помощью Python .Также мы будем демонстрировать все, используя Python Tkinter. Мы предполагаем, что вы уже установили модуль PyPDF2 и Tkinter в своей системе.
- Процесс выбора текста в Python Tkinter разделен на две части:
- В первой части мы будем извлекать текст из PDF с помощью модуля PyPDF2 в Python.
- На втором этапе мы будем выбирать текст из извлеченного текста.
Вот код для чтения и извлечения данных из PDF с помощью модуля PyPDF2 в Python
reader = PdfFileReader (имя файла)
pageObj = читатель.getNumPages ()
для page_count в диапазоне (pageObj):
page = reader.getPage (page_count)
page_data = page.extractText ()
- В первой строке мы создали переменную «reader», которая содержит путь к файлу PDF. Здесь имя файла относится к имени файла с путем.
- Во второй строке мы получили общее количество страниц, имеющихся в файле PDF.
- В третьей строке запускается цикл, и он будет перебирать общее количество страниц в файле PDF.
- при каждом запуске цикла отображается текстовая информация, имеющаяся в файле PDF.
- Таким образом, мы можем извлечь текст из PDF с помощью модуля PyPDF2 в Python.
- После того, как вы извлекли текст, теперь вы можете просто выбрать текст, щелкнув правой кнопкой мыши и перетащив мышь
Фрагмент кода:
Вот код небольшого проекта, который показывает извлечение текста из PDF. Этот проект представляет собой программу на основе графического интерфейса, созданную с использованием Python Tkinter для реализации выделения текста из PDF.
из PyPDF2 импортировать PdfFileReader
из tkinter import *
from tkinter import filedialog
ws = Tk ()
ws.title ('PythonGuides')
ws.geometry ('400x300')
ws.config (bg = '# D9653B')
def choose_pdf ():
filename = filedialog.askopenfilename (
initialdir = "/", # для пользователей Linux и Mac
# initialdir = "C: /", для пользователей Windows
title = "Выберите файл",
filetypes = (("PDF-файлы", "*. pdf *"), ("все файлы", "*. *")))
если имя файла:
вернуть имя файла
def read_pdf ():
имя файла = выбрать_pdf ()
reader = PdfFileReader (имя файла)
pageObj = читатель.getNumPages ()
для page_count в диапазоне (pageObj):
page = reader.getPage (page_count)
page_data = page.extractText ()
textbox.insert (КОНЕЦ, данные_страницы)
def copy_pdf_text ():
content = textbox.get (1.0, "конец-1c")
ws.withdraw ()
ws.clipboard_clear ()
ws.clipboard_append (содержимое)
ws.update ()
ws.destroy ()
текстовое поле = Текст (
WS,
высота = 13,
ширина = 40,
wrap = 'слово',
bg = '# D9BDAD'
)
textbox.pack (expand = True)
Кнопка(
WS,
text = 'Выбрать файл PDF',
padx = 20,
пады = 10,
bg = '# 262626',
fg = 'белый',
команда = read_pdf
).pack (раскрыть = True, сторона = LEFT, pady = 10)
Кнопка(
WS,
text = "Копировать текст",
padx = 20,
пады = 10,
bg = '# 262626',
fg = 'белый',
command = copy_pdf_text
) .pack (expand = True, side = LEFT, pady = 10)
ws.mainloop ()
Выход:
В этом выводе мы использовали текстовое поле Python Tkinter для отображения текста файла PDF. Пользователь нажимает кнопку Выбрать файл PDF . Используя диалоговое окно файла в Python Tkinter, он / она может перемещаться и выбирать файл PDF на компьютере.
Текст будет отображаться в текстовом поле немедленно. Отсюда пользователь может скопировать текст, просто нажав кнопку Копировать текст . Текст будет скопирован, и его можно будет вставить куда угодно, как обычно. Теперь пользователь может выделить любую часть текста и использовать ее для решения своей задачи.
Выберите текст из файла PDF в PythonКак преобразовать PDF в Word Python pypdf2
Теперь пришло время разработать инструмент pdf to word converter с использованием Python.
В этом разделе мы создали программное обеспечение для преобразования PDF в Word python pypdf2 . Это законченное программное обеспечение, которое можно использовать в качестве второстепенного проекта с использованием Python Tkinter.
из PyPDF2 импортировать PdfFileReader
из tkinter import *
from tkinter import filedialog
импортировать pdf2docx
f = ("Times", "15", "жирный")
def export_toword ():
pdf2docx.convert = browseFiles.filename
def browseFiles ():
filename = filedialog.askopenfilename (
initialdir = "/",
title = "Выберите файл",
filetypes = (("PDF-файлы", "*.pdf * "), (" все файлы "," *. * ")))
fname = filename.split ('/')
upload_confirmation_lbl.configure (text = fname [-1])
процесс (имя файла)
вернуть имя файла
def process (имя файла):
с open (filename, 'rb') как f:
pdf = PdfFileReader (f)
информация = pdf.getDocumentInfo ()
number_of_pages = pdf.getNumPages ()
fname = filename.split ('/')
right2.config (text = f '{information.author}')
right3.config (text = f '{information.producer}')
right1.config (text = f '{fname [-1]}:')
правильно4.config (text = f '{information.subject}')
right5.config (text = f '{information.title}')
right6.config (текст = f '{number_of_pages}')
ws = Tk ()
ws.title ('PythonGuides')
ws.geometry ('800x800')
upload_frame = Кадр (
WS,
padx = 5,
pady = 5
)
upload_frame.pack (pady = 10)
upload_btn = Кнопка (
upload_frame,
text = 'ЗАГРУЗИТЬ ФАЙЛ PDF',
padx = 20,
пады = 20,
bg = '# f74231',
fg = 'белый',
команда = browseFiles
)
upload_btn.pack (expand = True)
upload_confirmation_lbl = Ярлык (
upload_frame,
пады = 10,
fg = 'зеленый'
)
upload_confirmation_lbl.пакет()
description_frame = Рамка (
WS,
padx = 10,
пады = 10
)
description_frame.pack ()
right1 = Метка (
description_frame,
)
right2 = Метка (
description_frame,
)
right3 = Метка (
description_frame,
)
right4 = Метка (
description_frame,
)
right5 = Метка (
description_frame,
)
right6 = Метка (
description_frame
)
left1 = Метка (
description_frame,
text = 'Автор:',
padx = 5,
пады = 5,
font = f
)
left2 = Метка (
description_frame,
text = 'Производитель:',
padx = 5,
пады = 5,
font = f
)
left3 = Метка (
description_frame,
text = 'Информация о:',
padx = 5,
пады = 5,
font = f
)
left4 = Метка (
description_frame,
text = 'Тема:',
padx = 5,
пады = 5,
font = f
)
left5 = Метка (
description_frame,
text = 'Название:',
padx = 5,
пады = 5,
font = f
)
left6 = Метка (
description_frame,
text = 'Количество страниц:',
padx = 5,
пады = 5,
font = f
)
left1.сетка (строка = 1, столбец = 0, липкий = W)
left2.grid (строка = 2, столбец = 0, липкий = W)
left3.grid (строка = 3, столбец = 0, липкий = W)
left4.grid (строка = 4, столбец = 0, липкий = W)
left5.grid (строка = 5, столбец = 0, липкий = W)
left6.grid (строка = 6, столбец = 0, липкий = W)
right1.grid (строка = 1, столбец = 1)
right2.grid (строка = 2, столбец = 1)
right3.grid (строка = 3, столбец = 1)
right4.grid (строка = 4, столбец = 1)
right5.grid (строка = 5, столбец = 1)
right6.grid (строка = 6, столбец = 1)
export_frame = LabelFrame (
WS,
text = "Экспортировать файл как",
padx = 10,
пады = 10,
font = f
)
export_frame.pack (expand = True, fill = X)
to_text_btn = Кнопка (
export_frame,
text = "ТЕКСТОВЫЙ ФАЙЛ",
команда = Нет,
пады = 20,
font = f,
bg = '# 00ad8b',
fg = 'белый'
)
to_text_btn.pack (side = LEFT, expand = True, fill = BOTH)
to_word_btn = Кнопка (
export_frame,
text = "СЛОВО ФАЙЛ",
command = export_toword,
пады = 20,
font = f,
bg = '# 00609f',
fg = 'белый'
)
to_word_btn.pack (side = LEFT, expand = True, fill = BOTH)
ws.mainloop ()
Выход:
Это созданное многоцелевое программное обеспечение.Он может преобразовать файл PDF в текстовый файл и файл Word. Также он отображает краткую информацию о выбранном PDF-файле.
преобразовать PDF в слово python pypdf2Это конвертер PDF в Word, разработанный с использованием Python.
Приведенный выше код поможет решить следующие проблемы:
- pypdf2 преобразовать PDF в Word
- pypdf2 преобразовать PDF в DOCX
- Преобразовать PDF в DOCX в Python
- Преобразовать PDF в DOCX с помощью Python
- Преобразовать PDF в текстовый файл с помощью Python
- Как преобразовать PDF в Word в Python
- Как преобразовать PDF в Word файл в Python
Это Как преобразовать PDF в Word в Python с помощью pypdf2 .
Вам могут понравиться следующие статьи о Python:
В этом руководстве мы узнали , как извлекать текст из PDF в Python . Также мы рассмотрели следующие темы:
- Python скопировать текст из файла PDF
- Извлечь текст из файла PDF Python
- Удалить текст из файла PDF в Python
- Python извлечь текст из изображения
- Невозможно скопировать текст из PDF в Python
- Как скопировать текст из PDF в слово в Python
- Как выделить текст из файла PDF в Python
- Как преобразовать PDF в слово Python pypdf2
python — Как извлечь текст из файла PDF?
Я добавляю код для этого: У меня работает нормально:
# Это работает в python 3
# требуемых пакетов Python
# tabula-py == 1.0,0
# PyPDF2 == 1.26.0
# Подушка == 4.0.0
# pdfminer.six == 20170720
импорт ОС
импортный шутил
предупреждения об импорте
из io import StringIO
запросы на импорт
импортная таблица
из PIL импорта изображения
из PyPDF2 импортировать PdfFileWriter, PdfFileReader
из pdfminer.converter импортировать TextConverter
из pdfminer.layout импортировать LAParams
из pdfminer.pdfinterp импорт PDFResourceManager, PDFPageInterpreter
из pdfminer.pdfpage импортировать PDFPage
warnings.filterwarnings ("игнорировать")
def download_file (url):
local_filename = url.split ('/') [- 1]
local_filename = local_filename.replace ("% 20", "_")
r = requests.get (url, stream = True)
печать (r)
с open (local_filename, 'wb') как f:
shutil.copyfileobj (r.raw, f)
вернуть local_filename
класс PDFExtractor ():
def __init __ (self, url):
self.url = url
# Загрузка файла на локальный
def break_pdf (self, filename, start_page = -1, end_page = -1):
pdf_reader = PdfFileReader (открыть (имя файла, «rb»))
# Чтение каждого pdf по одному
total_pages = pdf_reader.numPages
если start_page == -1:
start_page = 0
elif start_page <1 или start_page> total_pages:
return "Неправильный выбор стартовой страницы"
еще:
start_page = start_page - 1
если end_page == -1:
end_page = total_pages
elif end_page <1 или end_page> total_pages - 1:
return "Неправильный выбор конечной страницы"
еще:
end_page = end_page
для i в диапазоне (start_page, end_page):
output = PdfFileWriter ()
выход.addPage (pdf_reader.getPage (i))
с open (str (i + 1) + "_" + filename, "wb") как outputStream:
output.write (outputStream)
def extract_text_algo_1 (сам, файл):
pdf_reader = PdfFileReader (открыть (файл, 'rb'))
# создание объекта страницы
pageObj = pdf_reader.getPage (0)
# извлечение extract_text со страницы
текст = pageObj.extractText ()
text = text.replace ("\ n", "") .replace ("\ t", "")
текст возврата
def extract_text_algo_2 (сам, файл):
pdfResourceManager = PDFResourceManager ()
retstr = StringIO ()
la_params = LAParams ()
устройство = TextConverter (pdfResourceManager, retstr, codec = 'utf-8', laparams = la_params)
fp = open (файл, 'rb')
интерпретатор = PDFPageInterpreter (pdfResourceManager, устройство)
пароль = ""
max_pages = 0
caching = True
page_num = набор ()
для страницы в PDFPage.get_pages (fp, page_num, maxpages = max_pages, password = password, caching = caching,
check_extractable = True):
интерпретатор.process_page (страница)
текст = retstr.getvalue ()
text = text.replace ("\ t", "") .replace ("\ n", "")
fp.close ()
device.close ()
retstr.close ()
текст возврата
def extract_text (сам, файл):
text1 = self.extract_text_algo_1 (файл)
text2 = self.extract_text_algo_2 (файл)
если len (text2)> len (str (text1)):
return text2
еще:
return text1
def extarct_table (сам, файл):
# Читать PDF в DataFrame
пытаться:
df = tabula.read_pdf (файл, output_format = "csv")
Кроме:
print ("Таблица ошибок чтения")
возвращение
print ("\ nПечать содержимого таблицы: \ n", df)
print ("\ nDone Printing Table Content \ n")
def tiff_header_for_CCITT (self, width, height, img_size, CCITT_group = 4):
tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h'
вернуть struct.pack (tiff_header_struct,
b'II ', # Индикация порядка байтов: Маленький индеец
42, # Номер версии (всегда 42)
8, # Смещение к первому IFD
8, # Количество тегов в IFD
256, 4, 1, ширина, # ImageWidth, LONG, 1, ширина
257, 4, 1, высота, # ImageLength, LONG, 1, длина
258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1
259, 3, 1, CCITT_group, # Сжатие, SHORT, 1, 4 = CCITT Group 4 кодирование факса
262, 3, 1, 0, # Порог, КОРОТКИЙ, 1, 0 = WhiteIsZero
273, 4, 1, строение.calcsize (tiff_header_struct), # StripOffsets, LONG, 1, len заголовка
278, 4, 1, высота, # RowsPerStrip, LONG, 1, длина
279, 4, 1, img_size, # StripByteCounts, LONG, 1, размер extract_image
0 # последний IFD
)
def extract_image (self, имя файла):
число = 1
pdf_reader = PdfFileReader (открыть (имя файла, 'rb'))
для i в диапазоне (0, pdf_reader.numPages):
страница = pdf_reader.getPage (я)
пытаться:
xObject = page ['/ Resources'] ['/ XObject']. getObject ()
Кроме:
print («XObject не найден»)
возвращение
для obj в xObject:
пытаться:
если xObject [obj] ['/ Subtype'] == '/ Image':
size = (xObject [obj] ['/ Width'], xObject [obj] ['/ Height'])
data = xObject [объект] ._ данные
если xObject [obj] ['/ ColorSpace'] == '/ DeviceRGB':
mode = "RGB"
еще:
mode = "P"
image_name = имя файла.split (".") [0] + str (число)
print (xObject [объект] ['/ Фильтр'])
если xObject [obj] ['/ Filter'] == '/ FlateDecode':
data = xObject [объект] .getData ()
img = Image.frombytes (режим, размер, данные)
img.save (image_name + "_Flate.png")
# save_to_s3 (imagename + "_Flate.png")
print ("Сохраненное изображение")
число + = 1
elif xObject [obj] ['/ Filter'] == '/ DCTDecode':
img = open (image_name + "_DCT.jpg "," wb ")
img.write (данные)
# save_to_s3 (imagename + "_DCT.jpg")
img.close ()
число + = 1
elif xObject [obj] ['/ Filter'] == '/ JPXDecode':
img = open (image_name + "_JPX.jp2", "wb")
img.write (данные)
# save_to_s3 (imagename + "_JPX.jp2")
img.close ()
число + = 1
elif xObject [obj] ['/ Filter'] == '/ CCITTFaxDecode':
если xObject [obj] ['/ DecodeParms'] ['/ K'] == -1:
CCITT_group = 4
еще:
CCITT_group = 3
width = xObject [объект] ['/ Ширина']
height = xObject [объект] ['/ Высота']
данные = xObject [объект]._data # извините, getData () не работает для CCITTFaxDecode
img_size = len (данные)
tiff_header = self.tiff_header_for_CCITT (ширина, высота, img_size, CCITT_group)
img_name = image_name + '_CCITT.tiff'
с open (img_name, 'wb') как img_file:
img_file.write (tiff_header + данные)
# save_to_s3 (img_name)
число + = 1
Кроме:
Продолжить
номер возврата
def read_pages (self, start_page = -1, end_page = -1):
# Загрузка файла локально
загруженный_файл = файл_загрузки (сам.URL)
печать (загруженный_файл)
# разбиение PDF на количество страниц в файлах diff pdf
self.break_pdf (загруженный_файл, начальная_страница, конечная_страница)
# создание объекта чтения pdf
pdf_reader = PdfFileReader (открыть (загруженный_файл, 'rb'))
# Чтение каждого pdf по одному
total_pages = pdf_reader.numPages
если start_page == -1:
start_page = 0
elif start_page <1 или start_page> total_pages:
return "Неправильный выбор стартовой страницы"
еще:
start_page = start_page - 1
если end_page == -1:
end_page = total_pages
elif end_page <1 или end_page> total_pages - 1:
return "Неправильный выбор конечной страницы"
еще:
end_page = end_page
для i в диапазоне (start_page, end_page):
# создание имени файла на основе страницы
file = str (i + 1) + "_" + загруженный_файл
print ("\ nНачало чтения страницы:", i + 1, "\ n ----------- === -------------")
file_text = self.extract_text (файл)
печать (текст_файла)
self.extract_image (файл)
self.extarct_table (файл)
os.remove (файл)
print ("Страница остановлена для чтения:", i + 1, "\ n ----------- === -------------")
os.remove (загруженный_файл)
# Я протестировал эти 3 файла PDF
# url = "http://s3.amazonaws.com/NLP_Project/Original_Documents/Healthcare-January-2017.pdf"
url = "http://s3.amazonaws.com/NLP_Project/Original_Documents/Sample_Test.pdf"
# url = "http: // s3.amazonaws.com/NLP_Project/Original_Documents/Sazerac_FS_2017_06_30%20Annual.pdf "
# создание экземпляра класса
pdf_extractor = PDFExtractor (URL)
# Получение желаемых данных
pdf_extractor.read_pages (15, 23)
.