Понимание процесса дедупликации данных | Microsoft Docs
- Время чтения: 7 мин
В этой статье
Относится к: Windows Server 2019, Windows Server 2016, Windows Server (Semi-Annual Channel)Applies to: Windows Server 2019, Windows Server 2016, Windows Server (Semi-Annual Channel)
В этом документе описывается, как работает дедупликация данных.This document describes how Data Deduplication works.
Как работает дедупликация данных?How does Data Deduplication work?
Дедупликация данных для Windows Server разрабатывалась на основе двух важнейших принципов.Data Deduplication in Windows Server was created with the following two principles:
Оптимизация не должна получать данные о способе записи на диск
Дедупликация данных оптимизирует данные с помощью модели постобработки.Data Deduplication optimizes data by using a post-processing model. Все данные записываются на диск в неоптимизированном виде, а затем оптимизируются с помощью дедупликации данных.All data is written unoptimized to the disk and then optimized later by Data Deduplication.Оптимизация не должна изменять семантику доступаOptimization should not change access semantics
Пользователи и приложения, обращаясь к данным в оптимизированном томе, не должны даже знать о том, что к этим данным применена дедупликация.Users and applications that access data on an optimized volume are completely unaware that the files they are accessing have been deduplicated.
После включения дедупликации данных для тома она выполняет в фоновом режиме следующие задачи:Once enabled for a volume, Data Deduplication runs in the background to:
- выявляет повторяющиеся фрагменты в файлах тома;Identify repeated patterns across files on that volume.
- автоматически перемещает эти фрагменты (блоки) со специальными указателями, которые называются точками повторного анализа и указывают на уникальную копию блока.Seamlessly move those portions, or chunks, with special pointers called reparse points that point to a unique copy of that chunk.
Этот процесс выполняется в четыре этапа:This occurs in the following four steps:
- Проверка файловой системы на наличие файлов, отвечающих политике оптимизации.Scan the file system for files meeting the optimization policy.
- разбиение файлов на блоки переменного размера;Break files into variable-size chunks.
- выявление уникальных блоков;Identify unique chunks.
- помещение блоков в хранилище блоков со сжатием, если применимо;Place chunks in the chunk store and optionally compress.
- Замена исходного потока данных в оптимизированных файлах на точки повторного анализа, указывающие на хранилище блоков.Replace the original file stream of now optimized files with a reparse point to the chunk store.
При считывании оптимизированных файлов файловая система отправляет файлы с точкой повторного анализа в фильтр дедупликации данных файловой системы (Dedup.sys).When optimized files are read, the file system sends the files with a reparse point to the Data Deduplication file system filter (Dedup.sys). Фильтр перенаправляет операцию чтения к соответствующим блокам, которые образуют поток этого файла в хранилище блоков.The filter redirects the read operation to the appropriate chunks that constitute the stream for that file in the chunk store. Изменения фрагментов дедуплицированного файла записываются на диск в неоптимизированном виде. Их при следующем запуске обрабатывает задание оптимизации.Modifications to ranges of a deduplicated files get written unoptimized to the disk and are optimized by the Optimization job the next time it runs.
Типы использованияUsage Types
Следующие типы использования содержат рациональные настройки дедупликации данных для некоторых распространенных рабочих нагрузок.The following Usage Types provide reasonable Data Deduplication configuration for common workloads:
| Тип использованияUsage Type | Подходящие рабочие нагрузкиIdeal workloads | ОтличияWhat’s different |
|---|---|---|
| ПараметрыDefault | Файловый сервер общего назначения.General purpose file server:
|
|
| Hyper-VHyper-V | Серверы инфраструктуры виртуальных рабочих столов (VDI).Virtualized Desktop Infrastructure (VDI) servers |
|
| КопияBackup | Виртуализированные приложения резервного копирования, например Microsoft Data Protection Manager (DPM)Virtualized backup applications, such as Microsoft Data Protection Manager (DPM) |
|
ВакансииJobs
Функция дедупликации данных использует стратегию постобработки для оптимизации и эффективного использования пространства на томе.Data Deduplication uses a post-processing strategy to optimize and maintain a volume’s space efficiency.
| Имя заданияJob name | Описание заданийJob descriptions | Расписание по умолчаниюDefault schedule |
|---|---|---|
| УлучшениеOptimization | Задание оптимизации выполняет дедупликацию, разбивая на блоки данные, хранящиеся на томе, в соответствии с настройками политики для этого тома, а также (необязательно) сжимая эти блоки и сохраняя их уникальные копии в хранилище блоков.The Optimization job deduplicates by chunking data on a volume per the volume policy settings, (optionally) compressing those chunks, and storing chunks uniquely in the chunk store. Процесс оптимизации, используемый дедупликацией данных, подробно описан в разделе Как работает дедупликация данных?The optimization process that Data Deduplication uses is described in detail in How does Data Deduplication work?. | Каждый часOnce every hour |
| Сборка мусораGarbage Collection | Задание сборки мусора выполняет освобождение места на диске, удаляя ставшие ненужными блоки, на которые не осталось ссылок после изменения или удаления файлов.The Garbage Collection job reclaims disk space by removing unnecessary chunks that are no longer being referenced by files that have been recently modified or deleted. | Каждую субботу в 02:35Every Saturday at 2:35 AM |
| Очистка целостностиIntegrity Scrubbing | Задание проверки целостности обнаруживает повреждения в хранилище блоков, связанные со сбоями диска или поврежденными секторами.The Integrity Scrubbing job identifies corruption in the chunk store due to disk failures or bad sectors. По мере возможности дедупликация данных автоматически применяет доступные для тома функции (например, зеркала или контроль четности для тома дисковых пространств), чтобы восстановить поврежденные данные.When possible, Data Deduplication can automatically use volume features (such as mirror or parity on a Storage Spaces volume) to reconstruct the corrupted data. Кроме того, дедупликация данных сохраняет в отдельной «активной зоне» резервные копии популярных блоков, на которые существует более 100 ссылок.Additionally, Data Deduplication keeps backup copies of popular chunks when they are referenced more than 100 times in an area called the hotspot. | Каждую субботу в 03:35Every Saturday at 3:35 AM |
| Отменяется оптимизацияUnoptimization | Задание отмены оптимизации, особое задание, которое может выполняться только вручную, отменяет всю оптимизацию, выполненную службой дедупликации, и отключает дедупликацию данных для тома.The Unoptimization job, which is a special job that should only be run manually, undoes the optimization done by deduplication and disables Data Deduplication for that volume. | Только по запросуOn-demand only |
Терминология дедупликации данныхData Deduplication terminology
| ТерминTerm | ОпределениеDefinition |
|---|---|
| ФрагментChunk | Блоком называется фрагмент файла, отобранный алгоритмом дедупликации данных, который с высокой долей вероятности будет повторяться в других схожих файлах.A chunk is a section of a file that has been selected by the Data Deduplication chunking algorithm as likely to occur in other, similar files. |
| Хранилище блоковChunk store | Хранилище блоков — это упорядоченный набор файлов в папке «System Volume Information», который дедупликация данных использует исключительно для хранения блоков.The chunk store is an organized series of container files in the System Volume Information folder that Data Deduplication uses to uniquely store chunks. |
| ЧистоDedup | Сокращенная форма англоязычного названия дедупликации данных, которая часто используется в PowerShell, интерфейсах API и компонентах Windows Server, а также в сообществе Windows Server.An abbreviation for Data Deduplication that’s commonly used in PowerShell, Windows Server APIs and components, and the Windows Server community. |
| Метаданные файлаFile metadata | Каждый файл содержит метаданные, которые описывают важные свойства файла, не связанные напрямую с основным содержимым файла.Every file contains metadata that describes interesting properties about the file that are not related to the main content of the file. Например: дата создания файла, дата последнего чтения, создатель файла и т. д.For instance, Date Created, Last Read Date, Author, etc. |
| Файловый потокFile stream | Так называется основное содержимое файла.The file stream is the main content of the file. Именно эту часть файла оптимизирует дедупликация данных.This is the part of the file that Data Deduplication optimizes. |
| Файловая системаFile system | Файловой системой называют специализированное программное обеспечение и структуру хранящихся на диске данных, которые используются операционной системой для хранения файлов на любых носителях.The file system is the software and on-disk data structure that the operating system uses to store files on storage media. Дедупликация данных поддерживается только на томах с файловой системой NTFS.Data Deduplication is supported on NTFS formatted volumes. |
| Фильтр файловой системыFile system filter | Так называется подключаемый модуль, который изменяет стандартное поведение файловой системы.A file system filter is a plugin that modifies the default behavior of the file system. Чтобы сохранить семантику доступа, дедупликация данных использует фильтр файловой системы (Dedup.sys), который перенаправляет запросы на чтение оптимизированного содержимого незаметным для пользователя или приложения образом.To preserve access semantics, Data Deduplication uses a file system filter (Dedup.sys) to redirect reads to optimized content completely transparently to the user or application that makes the read request. |
| УлучшениеOptimization | Файл считается оптимизированным с точки зрения дедупликации данных (дедуплицированным), если он разделен на уникальные блоки, которые перенесены в хранилище блоков.A file is considered optimized (or deduplicated) by Data Deduplication if it has been chunked, and its unique chunks have been stored in the chunk store. |
| Политика оптимизацииOptimization policy | Политика оптимизации определяет, для каких файлов следует применять дедупликацию данных.The optimization policy specifies the files that should be considered for Data Deduplication. Например, политика может исключать из оптимизации недавно созданные или открытые файлы, все файлы в определенном расположении в томе или файлы определенного типа.For example, files may be considered out-of-policy if they are brand new, open, in a certain path on the volume, or a certain file type. |
| Точка повторного анализаReparse point | Точкой повторного анализа называют специальный тег, который уведомляет файловую систему о необходимости перенаправить запрос ввода-вывода на указанный фильтр файловой системы.A reparse point is a special tag that notifies the file system to pass off I/O to a specified file system filter. В тех файлах, для которых выполнена оптимизация, дедупликация данных заменяет файловый поток точкой повторного анализа, что позволяет полностью сохранять семантику доступа к этому файлу.When a file’s file stream has been optimized, Data Deduplication replaces the file stream with a reparse point, which enables Data Deduplication to preserve the access semantics for that file. |
| ТомаVolume | Том — это используемое Windows обозначение для логического диска хранения данных, который может включать несколько физических устройств хранения, расположенных на одном или нескольких серверах.A volume is a Windows construct for a logical storage drive that may span multiple physical storage devices across a one or more servers. Дедупликация включается на уровне отдельного тома.Deduplication is enabled on a volume-by-volume basis. |
| РаспределятьWorkload | Рабочей нагрузкой называется приложение, выполняемое на Windows Server.A workload is an application that runs on Windows Server. Пример рабочей нагрузки — файловый сервер общего назначения, сервер Hyper-V и SQL Server.Example workloads include general purpose file server, Hyper-V, and SQL Server. |
Предупреждение
Не пытайтесь вручную изменять содержимое хранилища блоков, если вы не получали таких указаний от авторизованных представителей службы поддержки корпорации Майкрософт.Unless instructed by authorized Microsoft Support Personnel, do not attempt to manually modify the chunk store. Такие действия могут привести к повреждению или утрате данных.Doing so may result in data corruption or loss.
Вопросы и ответыFrequently asked questions
Чем дедупликация данных отличается от других продуктов для оптимизации?How does Data Deduplication differ from other optimization products?
Есть несколько важных различий между дедупликацией данных и другими распространенными решениями для оптимизации хранения.There are several important differences between Data Deduplication and other common storage optimization products:
Чем отличается дедупликация данных от хранилища единственных экземпляров?How does Data Deduplication differ from Single Instance Store?
Хранилище единственных копий (SIS) является предшественником технологии дедупликации данных и впервые было представлено в выпуске Windows Storage Server 2008 R2.Single Instance Store, or SIS, is a technology that preceded Data Deduplication and was first introduced in Windows Storage Server 2008 R2. Для оптимизации тома хранилище единственных копий выявляло в нем полностью идентичные файлы и заменяло их логическими ссылками на одну копию такого файла, размещенную в общем хранилище SIS.To optimize a volume, Single Instance Store identified files that were completely identical and replaced them with logical links to a single copy of a file that’s stored in the SIS common store. В отличие от хранилища единственных копий, дедупликация данных способна уменьшить пространство, занимаемое файлами, которые не полностью идентичны, но имеют некоторые одинаковые элементы, а также файлами, в которых встречается много повторяющихся элементов.Unlike Single Instance Store, Data Deduplication can get space savings from files that are not identical but share many common patterns and from files that themselves contain many repeated patterns. Хранилище единственных копий считается устаревшим начиная с выпуска Windows Server 2012 R2, а в Windows Server 2016 его полностью заменила дедупликация данных.Single Instance Store was deprecated in Windows Server 2012 R2 and removed in Windows Server 2016 in favor of Data Deduplication.Чем дедупликация данных отличается от сжатия NTFS?How does Data Deduplication differ from NTFS compression?
Сжатие NTFS используется файловой системой NTFS на уровне тома.NTFS compression is a feature of NTFS that you can optionally enable at the volume level. Эта необязательная функция NTFS оптимизирует каждый файл по отдельности, сжимая его во время записи.With NTFS compression, each file is optimized individually via compression at write-time. В отличие от сжатия NTFS, дедупликация данных использует для экономии места одновременно все файлы на томе.Unlike NTFS compression, Data Deduplication can get spacing savings across all the files on a volume. Это гораздо эффективнее, чем сжатие NTFS, ведь файл может одновременно иметь как внутреннее дублирование данных (которое устраняется сжатием NTFS), так и сходство с другими файлами в томе (которое не устраняется сжатием NTFS).This is better than NTFS compression because files may have both internal duplication (which is addressed by NTFS compression) and have similarities with other files on the volume (which is not addressed by NTFS compression). Кроме того, дедупликация данных использует модель постобработки. Это означает, что новые или измененные файлы записываются на диск в неоптимизированном виде, и лишь затем дедупликация данных оптимизирует их.Additionally, Data Deduplication has a post-processing model, which means that new or modified files will be written to disk unoptimized and will be optimized later by Data Deduplication.Чем дедупликация данных отличается от таких форматов файлов архивов, как ZIP, RAR, 7z, CAB и т. д.?How does Data Deduplication differ from archive file formats like zip, rar, 7z, cab, etc.?
Форматы ZIP, RAR, 7Z, CAB и другие выполняют сжатие для определенного набора файлов.Archive file formats, like zip, rar, 7z, cab, etc., perform compression over a specified set of files. Как и в случае с дедупликацией данных, оптимизируются повторяющиеся фрагменты внутри файлов и в разных файлах.Like Data Deduplication, duplicated patterns within files and duplicated patterns across files are optimized. Однако вам необходимо выбрать файлы, которые должны быть включены в архив.However, you have to choose the files that you want to include in the archive. Семантика доступа также отличается.Access semantics are different, too. Чтобы получить доступ к определенному файлу в архиве, необходимо открыть архив, выбрать файл, а затем распаковать его для использования.To access a specific file within the archive, you have to open the archive, select a specific file, and decompress that file for use. Дедупликация данных работает незаметно для пользователей и администраторов, не требуя никаких ручных операций.Data Deduplication operates transparently to users and administrators and requires no manual kick-off. Кроме того, дедупликация данных сохраняет семантику доступа — оптимизированные файлы выглядят для пользователя точно так же, как и раньше.Additionally, Data Deduplication preserves access semantics: optimized files appear unchanged after optimization.
Можно ли изменить параметры дедупликации данных для выбранного типа использования?Can I change the Data Deduplication settings for my selected Usage Type?
Да.Yes. Хотя дедупликация данных обеспечивает рациональные значения по умолчанию для рекомендуемых рабочих нагрузок, вам может потребоваться настроить параметры для наиболее эффективного использования хранилища.Although Data Deduplication provides reasonable defaults for Recommended workloads, you might still want to tweak Data Deduplication settings to get the most out of your storage. И не забывайте, что в некоторых случаях определенная дополнительная настройка нужна для того, чтобы дедупликация не мешала рабочей нагрузке.Additionally, other workloads will require some tweaking to ensure that Data Deduplication does not interfere with the workload.
Можно ли вручную запустить задание дедупликации данных?Can I manually run a Data Deduplication job?
Да, все задания дедупликации данных можно запускать вручную.Yes, all Data Deduplication jobs may be run manually. Это удобно, если запланированное задание не было выполнено из-за недостатка системных ресурсов или ошибки.This may be desirable if scheduled jobs did not run due to insufficient system resources or because of an error. Кроме того, есть специальное задание отмены оптимизации, которое запускается только вручную.Additionally, the Unoptimization job can only be run manually.
Можно ли отслеживать исторические результаты заданий дедупликации данных?Can I monitor the historical outcomes of Data Deduplication jobs?
Да, все задания дедупликации данных создают записи в журнале событий Windows.Yes, all Data Deduplication jobs make entries in the Windows Event Log.
Можно ли изменить расписания по умолчанию для заданий дедупликации данных в моей системе?Can I change the default schedules for the Data Deduplication jobs on my system?
Да, все расписания можно настраивать вручную.Yes, all schedules are configurable. Важнее всего изменять расписание дедупликации данных в тех случаях, когда нужно обеспечить достаточное время для завершения заданий, чтобы дедупликация данных не претендовала на ресурсы, требуемые для рабочей нагрузки.Modifying the default Data Deduplication schedules is particularly desirable to ensure that the Data Deduplication jobs have time to finish and do not compete for resources with the workload.
docs.microsoft.com
Дедупликация данных — подход NetApp / NetApp corporate blog / Habr

Дедупликация данных — это технология, при помощи которой обнаруживаются и исключаются избыточные данные в дисковом хранилище. В результате это позволяет сократить объёмы физических носителей для хранения тех же объёмов данных.
Дедупликация данных это одна из самых «горячих» тем в области систем хранения данных последних двух-трех лет. Ведь очевидно, что в том гигантском объеме данных, который сейчас приходится хранить современным системам хранения, неизбежно встречаются дубликаты и идентичные данные, за счет устранения которых можно было бы значительно сократить объемы хранения.
Пожалуй наибольшего успеха снискали реализации технологий дедупликации в области систем дискового резервного копирования (например EMC Avamar, Data Domain), однако компания NetApp первой объявила о возможности использования дедупликации для так называемых «primary storage», то есть основного, «боевого» хранилища активных данных, так как смогла предложить технологию дедупликации, практически не снижающую производительность его работы.
Сегодня я бы хотел рассказать как и за счет чего это удалось, и почему пока не получается у других.
Итак, дедупликация — это устранение дублирующихся данных при их хранении на дисках хранилища. Каким образом?
Под общим названием «дедупликация» может скрываться сразу целый ряд различных реализаций. Простейшая из них — реализация дедупликации на «файловом» уровне. Это то, что давно реализовано в «UNIX-like» файловых системах с помощью механизма «линков». Одна и та же физическая цепочка блоков может адресоваться из разных точек файловой системы. Если, к примеру, одна и та же стандартная библиотека используется без изменения множеством разных программ, то, вместо того, чтобы копировать один и тот же файл в десятки мест на диске, мы храним одну копию, а остальные заменяем на линк. Когда OS или приложение обращается к файловой системе за этим файлом, то файловая система прозрачно перенаправляет по линку это обращение к тому самому единственному экземпляру.
Но что делать, если вышла новая версия библиотеки, которая хоть и отличается всего на пару сотен байт содержимого, но уже является в целом иным файлом? Такой механизм уже не сработает. Также не работает он для «нефайловых» данных, например в SAN-хранилищах, работающих по FC или iSCSI.Именно поэтому механизмы линков, или «файловая дедупликация», в настоящий момент используется относительно ограниченно. Вот если бы можно было по линку ссылаться на часть содержимого!
Такой механизм стал носить название субфайловой или блочной дедупликации. Он уже не реализуем на уровне стандартной UNIX-like файловой системы, так как линки в ней могут адресоваться только на файлы, причем на файлы в целом.
Если вы вспомните мою статью об основе всех систем хранения NetApp, файловой структуре WAFL, то увидите, почему NetApp так заинтересовалась дедупликацией. Ведь субфайловая, блочная дедупликация абсолютно естественно реализуется в терминах WAFL, где «всё есть линки» на блоки хранения.
Где же может применяться дедупликация?
Я уже упомянул хранилище резервных копий, и в этой области дедупликация применяется относительно давно и успешно (часто в резервные копии попадают одни и те же, мало измененные по содержимому, обширные файлы, пользовательские документы, в том числе в копиях, например в разных папках, разных пользователей,). Но есть и другие перспективные области применения.
Один из них — хранение данных виртуальных машин в среде серверной виртуализации VMware ESX, MS Hyper-V, Xen Server, и так далее.
Однако использовать для дедупликации методы, хорошо работающие с резервными копиями, чаще всего не получится. Никому не захочется заплатить за пространство катастрофическим падением производительности дискового хранилища, как это часто происходит.
То, что годится для бэкапов — не годится для primary storage.
Нужно не просто устранить дубликаты, но и сделать это таким образом, чтобы не пострадала производительность.
За счет чего дедупликация столь эффективна на данных виртуальных инфраструктур?
Приведу какой-нибудь наиболее вопиющий пример. Допустим, вы разворачиваете систему серверной виртуализации в среде VMware, и в датаcторах сервера ESX у вас находится десяток серверов Windows или Linux, каждый выполняющий свою собственную задачу. Все виртуальные машины одного типа, конечно же, развернуты из предварительно подготовленного «темплейта», содержащего эталонную OS, со всеми необходимыми патчами, настройками и сервис-паками.
Для создания нового сервера вы просто копируете этот темплейт, и получаете новую, уже настроенную и обновленную виртуальную машину, состоящую из файла индивидуальных настроек, и большого файла «виртуального диска», содержащего в себе все файлы «гостевой OS» и ее приложений.
Но при этом, на десяток таких виртуальных машин, вы имеете десяток почти полностью идентичных виртуальных дисков, с папками /Windows/System32 (или /usr) внутри, отличающихся всего в нескольких десятках килобайтов индивидуальных настроек в реестре и конфигурационных файлах.
Несмотря на то, что по содержимому они, формально, практически идентичны, каждая виртуальная машина своим «диском C:» займет на системе хранения свой десяток гигабайт. Помноженное на десять виртуальных машин это дает уже вполне весомую цифру.
Еще более вопиющие ситуации возможны в случае VDI (Virtual Desktop Infrasructure), где количество «виртуальных десктопов» может исчисляться сотнями, и все они, как правило, используют одну и ту же OS.
Практика использования дедупликации на данных файлов виртуальных дисков показывает, что результаты экономии пространства часто достигают 75-90% от изначально занятого объема, «без дедупликации».
Это довольно заманчиво, без особого риска и накладных расходов, не жертвуя производительностью, освободить на терабайте хранилища 750-900 гигабайт ранее занятого образами виртуальных машин объема.
За счет того, что дедупликация осуществляется на «суб-файловом», блочном уровне, дедуплицироваться могут и разные, а не только идентичные файлы, если только они имеют внутри себя фрагменты идентичного содержимого, в пределах одного 4KB-блока файловой системы.
Дедупликация может осуществляться непосредственно в момент записи данных на диски, она носит название «онлайн-дедупликация», а может быть реализована «постпроцессом», в оффлайне.
Отказавшись от «онлайн»-дедупликации, той, что происходит непосредственно при поступлении данных, Что-то мы, безусловно, теряем.
Например, если мы записываем сильно дуплицированные данные, допустим 1TB, из которых 900GB — нули, нам придется сперва выделить на запись место, размером 1TB, заполнить его нашими «нулями на 90%», и лишь потом, в ходе процесса дедупликации, 90% этого пространства освободится.
Однако «оффлайновая» дедупликация дает нам и множество очень значимых плюсов.
- Мы можем использовать более эффективные и точные (читай: медленные и «процессороемкие») алгоритмы обнаружения дубликатов данных. Нам не нужно идти на компромиссы, чтобы не перегрузить работой процессор и не снизить производительность работы системы хранения с дедупликацией.
- Мы можем анализировать и обрабатывать значительно большие объемы данных, так как в случае «оффлайна» нам доступно для анализа и использования при дедупликации все пространство хранения, а не только нынешняя, непосредственно записываемая порция данных.
- Наконец, мы можем делать дедупликацию тогда и там, когда и где нам удобно.
Таким образом, ничего удивительного, что системы хранения NetApp выбрали для использования именно «оффлайновый» способ, ведь он позволил делать им дедупликацию с минимальным влиянием на собственно дисковую производительность системы.
Насколько я знаю, на сегодня NetApp единственный производитель систем хранения, использующих дедупликацию, который не опасается официально рекомендовать ее использование для так называемых primary data, то есть основных, рабочих данных, а не только бэкапов и архивов.
Как же «физически» устроен использованный в NetApp механизм дедупликации?
Часто приходится слышать, что жесткие диски FC и SAS систем хранения NetApp используют «нестандартный размер сектора» равный 520, вместо 512 байт. «Нестандартный» в кавычках, потому что, как ни странно это прозвучит, но именно сектор в 520 байт (512b data + 8b CRC) на сегодня следует считать «стандартным», так как именно это значение утверждено «комитетом T10», организацией, занимающимся разработкой и утверждением стандартов в области SCSI. Увы, пока совсем немногие системы хранения последовали этому новому стандарту (кроме NetApp я знаю только EMC Clariion, а также системы highend-класса, такие как EMC Symmetrix и HDS USP), а использование такого формата сектора дает много правильных и полезных бонусов в работе, вводя дополнительную защиту против неотслеживаемых на уровне RAID повреждений содержимого записанного сектора. Вероятность таких ошибок весьма невысока, но все же ненулевая.
Однако, помимо этой защиты, NetApp использует такие дополнительные 8 байт на сектор для организации своего механизма дедупликации данных.
(pic)
Блок данных в WAFL занимает 4096 байт. Блок данных, это то, что в файловых системах иногда называется «дисковым кластером», одна адресуемая порция данных, не путайте с компьютерным кластером «высокой доступности». Этот блок, как вы видите, состоит из 8 секторов по 512 байт.
Как я уже рассказал ранее, каждому из этих 512 байт данных «придано» на системном уровне диска еще 8 байт CRC. Итого, на блок WAFL в 4KB мы имеем 64 байта «контрольной суммы» CRC.
У CRC есть один большой плюс — он очень быстро и просто вычисляется. Однако есть и минус — возможна так называемая «hash-коллизия», ситуация, когда два различных по содержимому блока имеют одинаковый результат хэша. Если мы будем ориентироваться только на результаты сравнения хэшей, то мы вполне можем принять за идентичные (и один из них безвозвратно удалить) два блока разного содержимого. Эта вероятность невелика, но она существует, и я уверен, вы не захотите, чтобы она произошла именно с вашими данными.
Как бороться с хэш-коллизией? Решение «влоб» — удлиннять хэш и усложнять алгоритм расчета. Однако этот вариант очень ресурсоемок, прежде всего в отношении процессора системы хранения. Именно поэтому, системы CAS — Content-Addressable Storage, так сказать «дедупликация первого поколения», например EMC Centera, ОЧЕНЬ медленные на запись, и пригодны только для архивного хранения малоизменяющихся документов.
Но для онлайн-дедупликаци у нас чаще всего просто нет иного варианта.
Однако «выйдя в оффлайн» мы получаем сразу множество новых возможностей, не будучи привязанными к собственно процессу записи данных на диск.
Процесс дедупликации, работающий в фоне, составляет базу хэшей всех блоков дискового тома, и, отсортировав ее, получает список «подозреваемых в совершении дупликации данных». Далее, получив этот список, и резко сократив круг «подозреваемых», и объем дальнейшей работы, процесс дедупликации проходит по диску, и над всеми потенциальными дубликатами проводит тривиальную операцию побайтового сравнения. И только убедившись в полном и безоговорочном совпадении содержимого рассмотренных блоков, один из них освобождает на уровне файловой системы, а на другой переставляет указатель inode, который ранее указывал на теперь высвобожденный блок. Механизм чем-то напоминает механизм линков в UNIX-ных файловых системах, только примененный не к файлам, а непосредственно к блокам данных файловой системы.
«Что же мешает такой механизм применить на обычной файловой системе?» — спросите вы. Если вы читали мой ранее опубликованный пост, про устройство WAFL, вы легко ответите на свой вопрос. Потому что на этих файловых системах блоки данных могут быть впоследствии изменены, перезаписаны. Представим себе, что у нас есть два разных файла, А и Б, каждый состоящий из трех блоков данных (по 4096Kb), так получилось, что средний из этих трех блоков у обоих файлов совпадает (два других — разные). Мы обнаруживаем это, используем такие «линки», и вместо ссылки на средний блок файла Б, устанавливаем ссылку на второй блок у файла А.
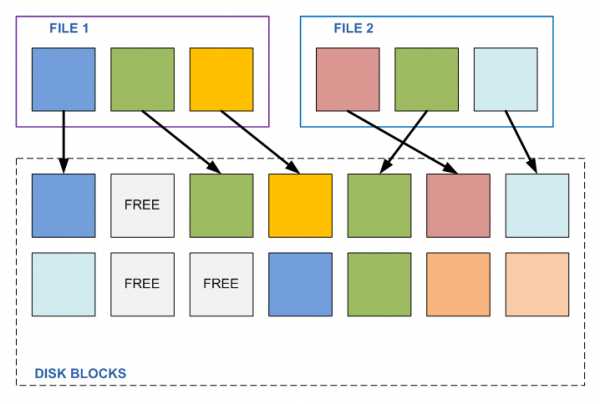

Все хорошо, пока какой-либо программе не понадобится изменить этот второй блок у любого из этих файлов. Изменив содержимое одного файла мы, тем самым, автоматически изменяем содержимое и второго файла. Который, вообще говоря, изменять не планировали, у него свое собственное содержимое, и принадлежит он совсем другой задаче. Просто так вышло, что в середине у него оказался такой же кусок, как у другого файла (например, тривиально, последовательность нулей), пока этот файл не был изменен.
И что же будет, если блок окажется измененным? Ничего хорошего. Окажется, что программа, сама того не зная, изменила содержимое совсем постороннего файла. А теперь представим, что этих файлов в разных места сотня, а если часть из них при этом считывается?

Это могло бы сработать для резервных копий, которые обычно записываются только раз, и более не изменяются, но абсолютно не подходит для активных «primary data», которые могут изменяться произвольно.
Как вы помните из статьи про устройство WAFL, она устроена таким образом, что однажды записанный блок в дальнейшем уже не перезаписывается и не изменяется, пока существует файл, и пока на данный блок есть хоть одна ссылка из активной файловой системы или любого из снэпшотов. А при необходимости записать изменение в данные файла, из пула свободных блоков выделяется место, куда производится запись, затем на этот блок переставляется указатель активной файловой системы (а указатели снэпшотов остаются на прежние блоки, поэтому мы имеем доступ одновременно и к новому содержимому файла, в «активной файловой системе», и к его старому содержимому, в снэпшоте, если он делался).
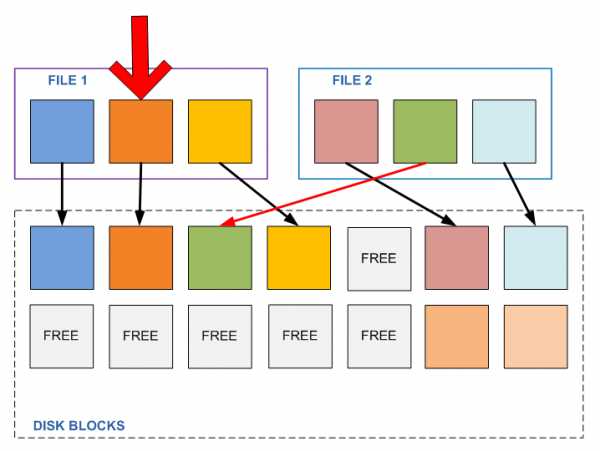
Такая схема устройства хранения данных есть гарантия того, что ситуации нежелательного изменения содержимого внутри файла не произойдет.
Единожды записанные блоки уже гарантированно не изменятся, и мы можем проделывать над ними любые нужные нам операции, будучи уверенными в их дальнейшей неизменности, например заменять блоки с дублирующимся содержимым на ссылку на блок с единственным экземпляром этого «контента».
Наверное наиболее часто встречающимся вопросом про дедупликацию будет: Как дедупликация влияет на производительность использующей ее системы хранения?
Во-первых, надо принять во внимание, что, как указывалось выше, дедупликация, как процесс, происходит «оффлайново», поиск, нахождение и устранение дубликатов блоков данных это процесс с фоновым, наиболее низким приоритетом, ниже, чем у процессов рабочей нагрузки. Тем самым, даже при работающей дедупликации(которую можно назначить на часы наименьшей загрузки) ресурсы процессора контроллера в ущерб рабочей нагрузке не занимаются.
Во-вторых, хотя дедуплицированные объемы данных и имеют несколько большие объемы связанных с ними метаданных, что теоретически может увеличить нагрузку на систему при больших объемах ввода-вывода, большинство пользователей не отмечают эффекта снижения производительности дедуплицированных данных вовсе. А в ряде случаев, за счет уменьшения объемов чтения и лучшей загрузке в кэш (а кэш NetApp знает и умеет правильно использовать дедуплицированные данные), может наблюдаться даже увеличение производительности, например в моменты так называемого ‘boot storm’, одновременной загрузки нескольких десятков и даже сотен виртуальных машин, когда подавляющее количество считываемых с дисков данных — одни и те же загружаемые в память файлы OS для множества разных машин.
Однако, тем не менее, NetApp дает в документации «консервативную» рекомендацию ожидать снижения производительности в пределах 5-10% в наихудшем сочетании характера нагрузки хранимых данных, проводить сайзинг и тестировать дедупликацию перед принятием решения о «выводе в продакшн». Для админов приятно будет узнать, что в случае обнаружения каких-то нежелательных эффектов данные в любой момент могут быть безболезненно «де-дедуплицированы» и «откачены» в исходное состояние.
Тем не менее, повторюсь, многочисленные отзывы о практических инсталляциях говорят об отсутствии сколь-нибудь заметного негативного эффекта на производительность вовсе.
Экономия же пространства на задачах хорошо поддающихся дедупликации, например на содержимом дисков виртуальных машин, показывает экономию пространства от 50% (половина ранее занятого на дисках объема освобождается) до 75% (три четверти ранее занятого объема освобождается).
Кстати сказать, именно дедупликация, наряду с другими технологиями NetApp, такими как RAID-DP, уже описанным Thin Provisioning, и снэпшотами, о которых вкратце было в статье о WAFL, позволила NetApp объявить два года назад беспрецедентную для индустрии акцию «50% space saving guarantee», по которой NetApp гарантирует, что тот же объем данных виртуальных машин, хранимый на любой системе хранения другого производителя, на NetApp уместится в два раза меньшем объеме дисков. А при невыполнении этого обещания — поставить бесплатно недостающие диски. Впрочем, как я знаю, за дисками так никто и не обращался.
И напоследок стоит сказать, что функция дедупликации данных доступна на любой системе хранения NetApp бесплатно, и обычно лицензия на ее активация поставляется по умолчанию с любой системой хранения, а если вам вдруг была продана система без нее, то вы можете получить ее бесплатно у вашего продавца.
habr.com
Дедупликация данных — это… Что такое Дедупликация данных?
Дедупликация данных — это технология, при помощи которой обнаруживаются и исключаются избыточные данные в дисковом хранилище. Например, путем замены повторных копий данных ссылками на первую копию. Это позволяет сократить объёмы физических носителей для хранения тех же объёмов данных.
Простой пример: при использовании централизованной корпоративной почтовой системы когда сотрудник отправляет письмо с вложенным файлом размером 1 МБ двум своим коллегам, это письмо сохраняется 1) в папке «Исходящие» отправителя, 2) в папке «Входящие» двух получателей, 3) все это дублируется в резервной копии базы данных (как минимум в одной). Итого 6 копий — 6 МБ. После дедупликации остаётся 1 МБ. Это пример дедупликации на уровне базы данных почтового сервера, в системах хранения эта технология реализована более сложным образом.
Использование дедупликации данных активно развивается в области хранения данных резервного копирования, как среди аппаратных устройств (NetApp VTL и Nearstore, EMC Data Domain), так и для программных решений (Symantec Backup Exec 2010, и др.), так как, зачастую, в результате сохранения резервных копий, на устройствах хранения оказываются практически идентичные по содержимому файлы с минимальными изменениями в них. Использование дедупликации позволяет не только экономить пространство хранения, но и увеличивать скорость сохранения и восстановления данных, за счет меньшего объема считывания-записи данных резервных копий.
Другим активно развивающимся направлением, получающим большие выгоды от использования дедупликации, являются системы серверной виртуализации, так как содержимое множества образов виртуальных машин зачастую идентично на 80-90 и более процентов (одна и та же версия OS, с идентичным набором системных файлов, service packs и patch level). На сегодня пока только системы хранения компании NetApp, использующие внутреннюю файловую систему WAFL имеют возможность реализовать дедупликацию на оперативных, primary хранилищах данных, без значительного негативного эффекта на их производительность. Использование дедупликации NetApp для хранилищ данных и образов виртуальных машин зачастую позволяет снизить хранимые объемы на 80-90 %, без заметного снижения производительности, а, в ряде случаев, и повышает ее, так как дедуплицированный набор данных занимает меньше пространства в кэш-памяти системы хранения, и позволяет поместить в кэш значительно большие, чем без дедупликации, объемы данных.
Ссылки
dic.academic.ru
8 мифов о дедупликации / Hewlett Packard Enterprise corporate blog / Habr
Пришло время рассмотреть все мифы и узнать где правда в вопросах дедупликации для массивов данных.
Несмотря на то, что технология дедупликации известна уже достаточно давно, но только сейчас технологии, применяемые в современных массивах данных, позволили ей пережить второе рождение. Во всех современных массивах данных на текущий момент используется дедупликация, но наличие этой функции в массиве еще не значит, что это даст весомые преимущества именно под ваши данные.
К сожалению, большое количество администраторов принимают «на веру» и считают, что дедупликация обладает безграничными возможностями.
Не важно, являетесь ли вы администратором системы хранения уровня tier-1, архивного хранилища или all-flash гибридных систем хранения, вам будет интересно пройтись по мифам и легендам дедупликации, чтобы избежать досадных ошибок при проектировании или работе с вашими системами хранения.
Коэффициент сокращения данных: чудес не бывает
В то время как дедупликация стала доступна как для массивов, хранящих ваши продуктивные данные, так и для массивов, хранящих резервные копии данных, коэффициент дедупликации на этих массивах может быть совершенно разным. Архитекторы очень часто полагают, что коэффициент, достигнутый на архивном массиве, можно применить и к продуктивному хранилищу.
Дедупликация — это автоматический процесс, существующий на многих массивах известных производителей, но потенциальный коэффициент, который вы можете получить, отличается у массивов разного типа. В результате, например, если вам будет нужен массив на 100ТБ, а вы будете считать коэффициент 10:1, то и приобретете хранилище под 10ТБ, или, скажем, если вы будете оценивать коэффициент как 2:1, следовательно, приобретете хранилище на 50ТБ – в итоге, эти совершенно разные подходы, приводят к совершенно разной стоимости покупки! Вы должны на практике понять какой коэффициент вы можете получить на ваших продуктивных данных, прежде чем сделать выбор в пользу определенной модели с определенным объемом.
Строя конфигурации массивов данных под различные задачи оперативного хранения и резервного хранения, часто приходится сталкиваться со сложностями в правильном определении коэффициента дедупликации. Если вам интересны тонкости архитектурного дизайна массивов под дедупликацию, эта дискуссия для вас.
Как минимум, понимание на базовом уровне 8 мифов, приведенных далее, позволит вам осознанно понять дедупликацию и оценить ее коэффициент для ваших данных.
Миф1. Больший коэффициент дедупликации дает больше преимуществ для хранения данных
Верно ли утверждение, что если один вендор предлагает коэффициент дедупликации 50:1 это в пять раз лучше альтернативного предложения 10:1? Нужно проверять и сравнивать совокупную стоимость влдения! Дедупликация позволяет сократить требования к ресурсам, но какова потенциальная экономия объема? 10:1 позволяет уменьшить размер хранимых данных (reduction ratio) на 90%, в то время как коэффициент в 50:1 увеличивает этот показатель на 8% и дает 98% reduction ratio (см. график ниже). Но это только 8% разницы…
В целом, чем выше коэффициент дедупликации, тем меньше преимуществ по уменьшению объема данных, согласно закону убывающей доходности. Объяснение смысла закона убывающей доходности может быть таким: дополнительно применяемые затраты одного фактора (например, коэффициента дедупликации) сочетаются с неизменным количеством другого фактора (например, объема данных). Следовательно, новые дополнительные затраты на текущем объеме дают всё меньшую экономию ресурсов.
К примеру, у вас есть офис, в котором работают клерки. Со временем, если увеличивать количество клерков, не увеличивая размер помещения, они будут мешаться под ногами друг у друга и возможно затраты будут превышать доходы.
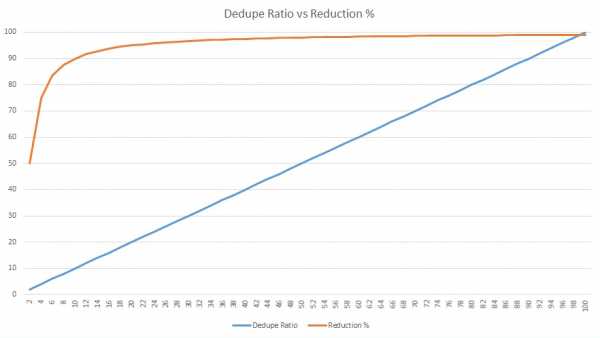
Рис. 1 Рост коэффициента дедупликации и сокращение объемов хранения
Миф2. Есть четкое определение термина «дедупликация»
Дедупликация позволяет сократить объем хранимых данных, удаляя повторяющиеся последовательности данных из пула. Дедупликация может быть на файловом уровне, блочном уровне или на уровне приложения или контента. Большая часть продуктов сочетают дедупликацию с компрессией, чтобы еще сильнее сократить объем хранимых данных. В то время, как некоторые производители не разделяют эти термины, некоторые разделяют их и вводят такие термины, как «уплотнение» (compaction), что, по сути, является просто другим названием «дедупликации плюс сжатие». К сожалению, не существует единственного определения дедупликации. В обывательском уровне вам будет важно, как вы сможете сэкономить на дисковых ресурсах вашей системы хранения и резервного копирования, применяя дедупликацию. Ниже мы раскроем эту тему.
Говоря про линейку систем хранения и резервного копирования HPE важно отметить, что и системы хранения, и системы резервного копирования обладают интересным функционалом, позволяющим заказчикам экономить на дисковых ресурсах.
Для систем хранения оперативных данных в массиве 3PAR разработан целый комплекс утилит и механизмов, позволяющий сократить объем данных на продуктивном массиве.
Этот комплекс носит название HPE 3PAR Thin Technologies и состоит из нескольких механизмов:
- Thin Provisioning – наиболее эффективно реализованная в системах хранения 3PAR, т.к. применяется виртуализация дискового пространства и массив используют свою внутреннюю карту хранимых блоков, при высвобождении ресурсов массиву не нужно проводить ревизию (garbage collection), высвободившиеся блоки сразу готовы к дальнейшему использованию… Позволяет выделять логическому тому ровно столько объема, сколько он требует, но на массиве занять всего лишь столько, сколько на этот том физически записано.
- Thin Conversion — технология, позволяющая переводить в реальном времени тома со старых массивов данных HPE (3PAR, EVA), EMC, Hitachi и других производителей в «тонкие тома» (которые используют Thin Provisioning) на массиве 3PAR с сокращением объема тома на целевом устройстве.
- Thin Persistence и Thin Copy Reclamation — технология, позволяющая массиву 3PAR на очень низком гранулярном уровне понимать работу всех популярных файловых систем и гипервизоров и в случае удаления файлов (освобождения физического объема) переводить соответствующие блоки в пул свободных ресурсов.
- Thin Deduplication — технология позволяющая использовать дедупликацию на продуктивном массиве в реальном времени, без существенной просадки производительности.
Все три технологии доступны бесплатно и без ограничений по времени или объему для любой системы хранения 3PAR, в том числе, установленных у наших заказчиков, подробнее об этих технологиях.

Рис. 2 Технологии Thin в массивах 3PAR
Миф3. Коэффициенты дедупликации на основном массиве такие же, как и на массиве с резервными копиями.
Разработчики систем хранения данных используют различные алгоритмы дедупликации. Некоторые из них требуют больших ресурсов CPU и сложнее, чем остальные, следовательно, не должен удивлять тот факт, что коэффициент дедупликации варьируется достаточно сильно.
Однако, самый большой фактор, влияющий на то, какой коэффициент дедупликации вы получите — как много у вас повторяющихся данных. По этой причине системы резервного копирования, содержащие несколько копий одних и тех же данных (дневные, недельные, месячные, квартальные, годичные) имеют такой высокий коэффициент дедупликации. В то время как оперативные системы хранения имеют практически уникальный набор данных, что практически всегда дает невысокий коэффициент дедупликации. В случае, если вы храните несколько копий оперативных данных на продуктивном массиве (например, в виде клонов) — это увеличивает коэффициент дедупликации, т.к. применяются механизмы сокращения места хранения.
Поэтому для оперативных массивов хранения данных иметь коэффициент 5:1 также замечательно, как иметь коэффициент 30:1 или 40:1 для систем резервного копирования, поскольку коэффициент этот зависит от того, сколько копий продуктивных данных хранится на таких массивах.
Если рассматривать продукты компании HPE, то в массивах для оперативного хранения HPE 3PAR поиск повторяющихся последовательностей (например, при инициализации виртуальных машин или создании снэпшотов) проходит «на лету» на специальной микросхеме ASIC, установленной в каждом контроллере массива. Этот подход позволяет разгрузить центральные процессоры массива для других, более важных, задач и дает возможность включить дедупликацию для всех типов данных, не боясь, что массив «просядет» под нагрузкой. Подробнее про дедупликацию на массиве 3PAR можно прочитать.

Рис.3 Дедупликация в массивах 3PAR выполняется на выделенной микросхеме ASIC
В портфеле HPE также есть аппаратные комплексы для резервного копирования данных с онлайн дедупликацией на уровне блоков переменной длины — HPE StoreOnce. Варианты систем охватывают полный спектр заказчиков от начального до корпоративного уровня:
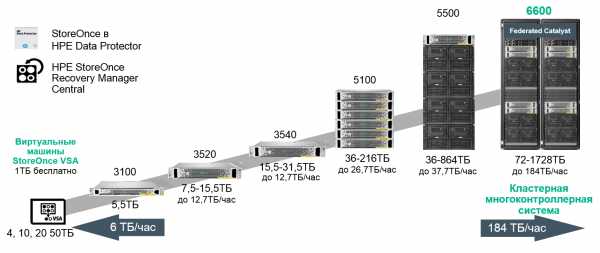
Рис. 4 Портфель систем резервного копирования HPE StoreOnce
Про преимущества систем резервного копирования StoreOnce можно почитать в других статьях.
Для заказчиков может быть интересно, что связка HPE 3PAR и StoreOnce позволяет упростить и ускорить процесс переноса данных с продуктивного массива на систему резервного копирования без использования ПО резервного копирования или выделенного сервера бэкапа. Такая связка получила название HPE StoreOnce RMC и подробнее о ней также можно почитать в нашей статье.
Миф4. Все данные одинаковы
Здесь не должно быть никаких сомнений- все данные разные. Даже данные одного и того же приложения в различных условиях будут иметь разные коэффициенты дедупликации на одном и том же массиве. Коэффициент дедупликации для конкретных данных зависит от разных факторов:
- Тип данных — данные, прошедшие программное сжатие, метаданные, медиа-потоки и зашифрованные данные всегда имеют очень невысокий коэффициент дедупликации или не сжимаются вовсе.
- Степень изменяемости данных — чем выше объем дневных изменений данных на блочном или файловом уровне, тем ниже коэффициент дедупликации. Это особенно актуально для систем резервного копирования.
- Срок хранения — чем больше копий данных вы имеете, тем выше коэффициент дедупликации.
- Политика резервного копирования — политика создания дневных полных копий, в противовес политике с инкрементными или дифференциальными бэкапами, даст больший коэффициент дедупликации (см. исследование ниже).
Таблица ниже дает поверхностную оценку коэффициента дедупликации, в зависимости от типа данных. Необходимо помнить, что коэффициент дедупликации на основном массиве данных будет всегда ниже коэффициента дедупликации на резервном массиве.
Рис. 5 Оценка коэффициента дедупликации в зависимости от типов данных и политики резервного копирования
Миф5. Группировка несвязных типов данных повышает уровень дедупликации
В теории, вы можете смешивать совершенно разные типы данных в общем пуле хранения для дедупликации. Может возникнуть ощущение, что вы имеете очень большой набор уникальных данных и, следовательно, вероятность нахождения в этом пуле уже записанных ранее блоков или объектов будет велика. На практике же этот подход не работает между несвязанными типами данных, например, между БД и Exchange, поскольку форматы данных разные, даже если хранится один и тот же набор данных. Такой, все время растущий пул, становится более сложным и требует больше времени для поиска повторяющихся последовательностей. Лучшей практикой является разделение пулов по типу данных.
Например, если выполнить дедупликацию одной виртуальной машины, вы получите некоторый коэффициент, если создать несколько копий этой виртуальной машины и выполнить дедупликацию на этом пуле, ваш коэффициент дедупликации вырастет, а если сгруппировать несколько виртуальных машин по типу приложения и создать несколько копий этих виртуальных машин — коэффициент увеличится еще больше.
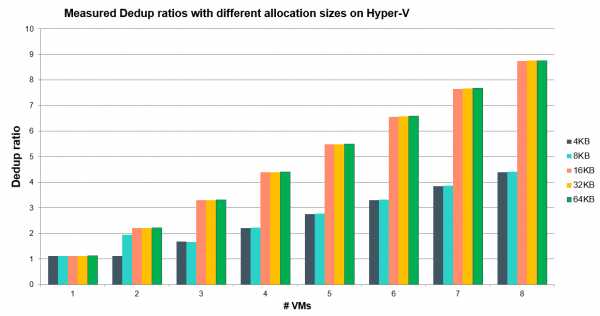
Рис.6 Зависимость коэффициента дедупликации от количества виртуальных машин в пуле и размеров блока данных.
Миф6. Ваше первое резервное копирование покажет вам ожидаемый коэффициент дедупликации.
Это ошибочное мнение появляется при сравнении коэффициентов на основном массиве и системе резервного копирования. Если вы храните только одну копию данных – возможно, вы увидите некоторый коэффициент дедупликации, больший единицы. Этот коэффициент сможет вырасти в том случае, если вы увеличите количество копий очень похожих данных, таких как резервные копии текущей БД.
График ниже показывает очень типичную кривую коэффициента дедупликации. Приложение, в этом графике — БД SAP HANA, но большинство приложений показывает схожую кривую. Ваше первое резервное копирование показывает определенную дедупликацию, но большая экономия достигается благодаря сжатию данных. Как только вы начинаете держать в пуле больше копий данных — коэффициент дедупликации пула начинает расти (голубая линия). Коэффициент индивидуального бэкапа взмывает вверх уже после создания второй копии (орнжевая линия), т.к. на блочном уровне первый и второй бэкап очень похожи.
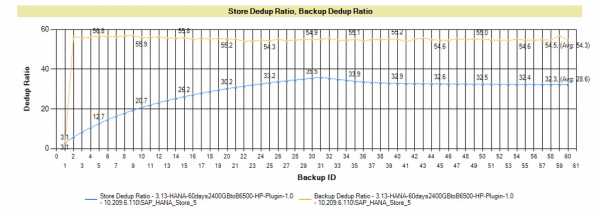
Рис. 7 График роста коэффициента дедупликации при увеличении количества резервных копий (подробнее в документе).
Миф7. Вы не можете увеличить уровень дедупликации
Наивно рассуждать, что нет возможности искусственно увеличить уровень дедупликации. Другой вопрос — зачем? Если показать маркетинговые цифры — это одно, если необходимо создать эффективную схему резервного копирования — это другое. Если цель — иметь синтетический наивысший коэффициент дедупликации, то необходимо просто хранить больше как можно больше копий одних и тех же данных. Конечно, это увеличит объем хранимых данных, но ваш коэффициент дедупликации взмоет до небес.
Изменение политики резервного копирования, определенно также влияет на коэффициент дедупликации, как можно увидеть в примере ниже для реального типа данных, где сравниваются политики создания полных копий и комбинации полных копий с инкрементальными и дифферентальными бэкапами. В примере ниже лучший коэффициент получается при использовании только дневных полных бэкапов. Тем не менее, на одних и тех же данных объем хранения является довольно разным для всех трех подходов. Поэтому необходимо понимать, что изменение в вашем подходе к резервному копированию может довольно сильно повлиять на коэффициент дедупликации и на физический объем хранимых данных.
Миф8. Нет возможности заранее спрогнозировать коэффициент дедупликации
Всякая окружающая среда уникальна и очень сложно аккуратно спрогнозировать реальный коэффициент дедупликации. Но тем не менее, производители систем резервного копирования выпускают наборы небольших утилит для основных систем хранения и систем резервного копирования, позволяющие получить представление о типе данных, политике резервного копирования, сроке хранения. Эти утилиты позволяют в какой-то мере получить представление об ожидаемом коэффициенте дедупликации.
Также производители имеют представление о коэффициентах, получаемых у других заказчиках на примерно похожей среде и отраслевом сегменте и могут использовать эту информацию для построения прогноза. В то время как это не дает гарантии, что на ваших данных вы получите схожий коэффициент, к этим цифрам, как минимум, стоит присмотреться.
Но наиболее точный прогноз по коэффициенту дедупликации получается в ходе проведения испытаний на реальных данных.
Рис. 8 Изменение коэффициента дедупликации и объема занимаемых данных в зависимости от политики резервного копирования на данных конкретного заказчика
У компании HPE есть набор утилит и сайзеров, позволяющий спрогнозировать (с неким допущением) тот объем систем хранения, который необходим заказчикам.
- Для оперативного хранилища данных есть бесплатная программа оценки текущей утилизации массива и оценки экономии места, в случае перехода на 3PAR.
- Для оценки утилизации ресурсов на оперативном массиве и построения прогноза по росту объема данных на уже установленных системах, при условии разрешения отправки массивом информации о его состоянии в службу технической поддержки HPE: www.storefrontremote.com
- Аналогичная программа по оценке утилизации систем резервного копирования.
Также есть возможность оценить предполагаемый объем, который мы получим после включения на системе 3PAR дедупликации в режиме симулятора, для этого необходимо на 3PAR запустить команду оценки, выполняемую в онлайн режиме, прозрачно для хоста:
checkvv -dedup_dryrun {Имена виртуальных томов}И получить предварительную оценку:
Итак, нет никакой магии за понятием дедупликации, а развенчивание мифов, приведенное выше, позволит вам лучше понять, на что способны ваши данные и позволит вам спрогнозировать утилизацию ваших массивов.
Следует отметить, что современный рост объемов SSD и снижения стоимости хранения на 1ГБ на flash накопителях (а стоимость уже соответствует $1.5 за ГБ) отодвигают вопросы, связанные с эффективностью дедупликации на второй план для оперативного хранилища, но становятся все более актуальными для систем резервного копирования.
К слову, есть альтернативное видение будущего (без дедупликации): Викибон считает, что устранение копий одних и тех же данных эффективнее, чем рост коэффициенотв дедупликации и компрессии (см. по ссылке в середине отчета), но такой подход требует кардинального внедрения целого комплекса технических мер, изменения всей инфраструктуры, правил одновременной работы приложений (процессинг, аналитика) с данными так, чтобы они не снижали производительность (при внедрении хороших средств работы с SLA) и надежность.
И, самое главное, если все это внедрить во всей экосистеме — и разработчикам ПО, и вендорам, и CIO, то через несколько лет экономия от этого будет больше, чем от дедупликации.
Какая школа мысли победит – покажет время.
Использованы материалы
habr.com
Подводные камни резервного копирования и восстановления дедуплицированных данных в сценарии disaster recovery

Развивая тему бэкапа и восстановления на СХД с новой архитектурой, рассмотрим нюансы работы с дедуплицированными данными в сценарии disaster recovery, где защищаются СХД с собственной дедупликацией, а именно, как эта технология эффективного хранения может помочь или помешать восстанавливать данные.
Предыдущая статья находится здесь: Подводные камни резервного копирования в гибридных системах хранения.
Введение
Раз дедуплицированные данные занимают меньше места на дисках, то логично предположить, что резервное копирование и восстановление должны занимать меньше времени. Действительно, почему бы не бэкапить/восстанавливать дедуплицированные данные сразу же в компактном дедуплицированном виде? Ведь в этом случае:
- В бэкап помещаются только уникальные данные.
- Не надо редуплицировать (регидрировать) данные на продуктивной системе.
- Не надо обратно дедуплицировать данные на СРК.
- И наоборот, восстановить можно лишь те уникальные данные, которые необходимы для реконструкции. Ничего лишнего.
Но если рассмотреть ситуацию внимательнее, то оказывается, что не всё так просто, прямой путь не всегда более эффективен. Хотя бы потому, что в СХД общего назначения и СХД резервного копирования используется разная дедупликация.
Дедупликация в СХД общего назначения
Дедупликация, как метод исключения избыточных данных и повышения эффективности хранения, была и остаётся одним из ключевых направлений развития в индустрии СХД.
Принцип дедупликации.
В случае с продуктивными данными, дедупликация предназначена не только и не столько для уменьшения места на дисках, сколько для повышения скорости доступа к данным за счёт их более плотного размещения на быстрых носителях. Кроме того, дедуплицированные данные удобны для кэширования.
Один дедуплицированный блок в кэш-памяти, на верхнем уровне многоуровневого хранения, или просто размещённый на флэше, может соответствовать десяткам или даже сотням идентичных пользовательских блоков данных, которые раньше занимали место на физических дисках и имели совершенно разные адреса, а потому не могли быть эффективно кэшированы.
Сегодня дедупликация на СХД общего назначения бывает очень эффективна и выгодна. Например:
- На флэш-системы (All-Flash Array) можно положить существенно больше логических данных, чем обычно позволяет их «сырая» ёмкость.
- При использовании гибридных систем дедупликация помогает выделить «горячие» блоки данных, поскольку при этом сохраняются лишь уникальные данные. И чем выше дедупликация, тем больше обращений к одним и тем же блокам, а значит — выше эффективность многоуровневого хранения.
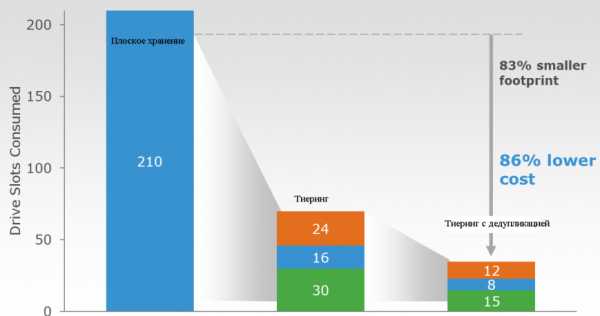
Эффективность решения задачи хранения при помощи сочетания дедупликации и тиеринга. В каждом варианте достигается равная производительность и ёмкость.
Дедупликация в СХД резервного копирования
Изначально дедупликация получила широкое распространение именно в этих системах. Благодаря тому, что однотипные блоки данных копируются на СРК десятки, а то и сотни раз, то за счёт исключения избыточности можно достичь существенной экономии места. В своё время это стало причиной «наступления» на ленточные системы дисковых библиотек для резервного копирования с дедупликацией. Диск сильно потеснил ленты, потому что стоимость хранения резервных копий на дисках стала очень конкурентоспособной.

Преимущество дедуплицированного бэкапа на диски.
В итоге, даже такие приверженцы лент, как Quantum, стали развивать у себя дисковые библиотеки с дедупликацией.
Какая дедупликация лучше?
Таким образом, в мире хранения в настоящий момент есть, два разных способа дедупликации – в резервном копировании и в системах общего назначения. Технологии в них используются разные — с переменным и фиксированным блоком соответственно.
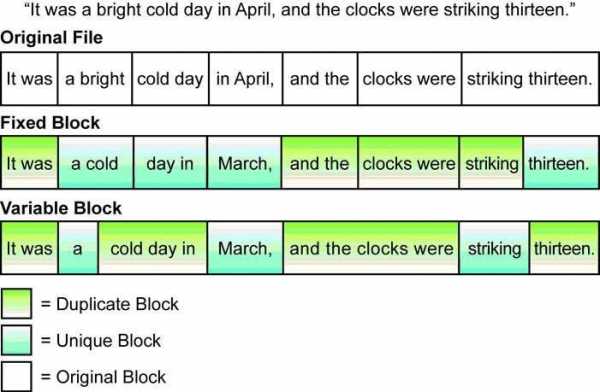
Различие двух методов дедупликации.
Дедупликация с фиксированным блоком проще в реализации. Она хорошо подходит для данных, к которым нужен регулярный доступ, поэтому чаще используется в СХД общего назначения. Её главным минусом является меньшая способность к распознаванию одинаковых последовательностей данных в общем потоке. То есть два одинаковых потока с небольшим смещением будут восприняты как совершенно разные, и не будут дедуплицированы.
Дедупликация с переменным блоком может лучше распознавать повторы в потоке данных, но для этого ей требуется больше ресурсов процессора. К тому же, она малопригодна для предоставления блочного или многопоточного доступа к данным. Это связано со структурой хранения дедуплицированной информации: если говорить упрощённо, то она тоже хранится переменными блоками.
Со своими задачами оба метода помогают отлично справляться, но с несвойственными задачами всё обстоит куда хуже.
Давайте рассмотрим ситуацию, возникающую на стыке взаимодействия этих двух технологий.
Проблемы резервного копирования дедуплицированных данных
Разница между обоими подходами в отсутствие их координированного взаимодействия приводит к тому, что если с системы хранения, которая хранит уже дедуплицированные данные, осуществлять резервное копирование с дедупликацией, то данные каждый раз «редуплицируются», а потом дедуплицируются обратно в процессе сохранения их на систему резервного копирования.
Например, физически хранится 10 Тб продуктивных дедуплицированных данных с суммарным коэффициентом 5:1. Тогда в процессе резервного копирования происходит следующее:
- Копируется не 10, а полностью 50 Тб.
- Продуктивной системе, в которой хранятся исходные данные, придется выполнить работу по регидрации («редупликации») данных в обратную сторону. В то же время она должна обеспечивать работу продуктивных приложений и поток данных резервного копирования. То есть три одновременных тяжёлых процесса, нагружающих системные шины ввода-вывода, кэш-память и процессорные ядра обеих систем хранения.
- Целевой системе резервного копирования придётся обратно дедуплицировать данные.
С точки зрения использования процессорных ресурсов — это можно сравнить с одновременным нажатием на газ и тормоз. Возникает вопрос — можно ли это как-то оптимизировать?
Проблема восстановления дедуплицированных данных
При восстановлении данных на тома с включённой дедупликацией придётся весь процесс повторить в обратную сторону. Далеко не во всех системах хранения данный процесс работает «на лету», а во многих решениях используется принцип «post process». То есть данные сначала записываются на физические диски (пусть даже на флэш) как есть, потом анализируются, сравниваются блоки данных, выявляются дубликаты, и только потом производится очистка.
Сравнение In-line и Post-Process Dedupe.
Это значит, что в системе хранения при первом проходе может потенциально не хватить места для полного восстановления всех недедуплицированных данных. И тогда придётся делать восстановление в несколько проходов, на каждый из которых может уйти немало времени, складывающегося из времени восстановления и времени дедупликации с освобождением места на СХД общего назначения.
Этот возможный сценарий относится не столько к восстановлению данных из бэкапа (Data recovery), минимизирующего риски класса Data loss, сколько к восстановлению после катастрофически большой потери данных (которая классифицируется как катастрофа, т.е. Disaster). Однако такой Disaster Recovery мягко говоря не оптимален.
Кроме того, при катастрофическом сбое совсем не обязательно восстанавливать все данные сразу. Достаточно начать лишь с самых необходимых.
В итоге, бэкап, который призван быть средством последней надежды, к которому обращаются, когда уже ничто другое не сработало, работает не оптимально в случае с дедуплицирующими СХД общего назначения.
Зачем тогда вообще нужен бэкап, из которого в случае катастрофы можно восстановиться лишь с огромным трудом, и почти наверняка не полностью? Ведь существуют встроенные в продуктивную систему хранения средства репликации (зеркалирование, снэпшоты), которые не оказывают существенного влияния на производительность (например, VNX Snapshots, XtremIO Snapshots). Ответ на этот вопрос будет всё тот же. Однако, любой нормальный инженер попытался бы эту ситуацию как-то оптимизировать и улучшить.
Как совместить два мира?
Старая организация работы с данными при бэкапе и восстановлении выглядит, по меньшей мере, странно. Поэтому предпринималось немало попыток оптимизации бэкапа и восстановления дедуплицированных данных, и ряд проблем удалось решить.
Вот лишь несколько примеров:
Но это всего лишь «заплатки» на уровне операционных систем и отдельных изолированных серверов. Они не решают задач на общем аппаратном уровне в СХД, где это действительно сложно сделать.
Дело в том, что в СХД общего назначения и в системах резервного копирования используются разные, специально разработанные алгоритмы дедупликации — с фиксированным и переменным блоками.
С другой стороны, далеко не всегда требуется делать полное резервное копирование, и значительно реже — полное восстановление. Совсем не обязательно подвергать дедупликации и сжатию все продуктивные данные. Тем не менее, нужно помнить о нюансах. Потому, что катастрофические потери данных никто не отменял. И для их предотвращения разработаны стандартные промышленные решения, которые должны быть предусмотрены по регламенту. Так что если восстановить данные из бэкапа за нормальное время не удаётся, то ответственным людям это может стоить карьеры.

Давайте рассмотрим, как наилучшим образом подготовиться к подобной ситуации и избежать неприятных сюрпризов.
Резервное копирование
- Используйте по возможности инкрементальный бэкап и синтетические полные (synthetic full) копии. В Networker, например, эта возможность есть, начиная с версии 8.
- Закладывайте больше времени на полный бэкап, учитывая необходимость регидрации данных. Выбирайте время минимальной утилизации процессоров системы. В ходе бэкапов лучше понаблюдать за утилизацией процессоров продуктивной СХД. Лучше, чтобы она не превышала 70% хотя бы в среднем за период бэкапа.
- Осмысленно применяйте дедупликацию. Если данные не дедуплицируются и не жмутся, то зачем тратить процессорную мощность в ходе бэкапа? Если же система дедуплицирует всегда, то она должна быть достаточно мощной, чтобы справиться со всей работой.
- Принимайте во внимание процессорную мощность, выделенную для дедупликации в СХД. Эта функция встречается даже в системах начального уровня, которые не всегда справляются с одновременным выполнением всех задач.
Полное восстановление данных, Disaster Recovery
- Подготовьте вменяемый Disaster Recovery или Business Continuity Plan, учитывающий поведение систем хранения с дедупликацией. Многие вендоры, включая EMC, а так же системные интеграторы, предлагают услуги подобного планирования, потому что в каждой организации есть своя уникальная комбинация факторов, влияющих на процесс восстановления работы приложений
- Если СХД общего назначения использует механизм дедупликации post-process, то я бы рекомендовал предусмотреть в ней буфер свободной ёмкости, на случай восстановления из бэкапа. Например, размер буфера можно принять как 20% от логической ёмкости дедуплицированных данных. Старайтесь хотя бы в среднем поддерживать этот параметр.
- Ищите возможности архивировать старые данные, чтобы они не мешали быстрому восстановлению. Даже если дедупликация хороша и эффективна, не дожидайтесь сбоя, после которого придётся восстанавливать из бэкапа и полностью дедуплицировать тома во много десятков Тб. Все неоперативные/исторические данные лучше перенести в онлайновый архив (например, на основе Infoarchive).
- Дедупликация данных «на лету» в СХД общего назначения имеет преимущество перед post-process с точки зрения скорости. Она может сыграть особое значение при восстановлении после катастрофической потери.
Таковы мои некоторые соображения относительно резервного копирования и восстановления дедуплицированных данных. Буду рад услышать здесь ваши отзывы и мнения по этому вопросу.
И, надо сказать, что здесь ещё не затронут один интересный частный случай, требующий отдельного рассмотрения. Так что продолжение следует.
Денис Серов
habr.com
Обзор и настройка средств дедупликации в Windows Server 2012 / Microsoft corporate blog / Habr
Всем доброго времени суток!Сегодня хотелось бы провести обзор такой интересной новой фичи в Windows Server 2012 как дедупликация данных (data deduplication). Фича крайне интересная, но все же сначала нужно разобраться насколько она нужна…
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей вселенной и на нашей планете, то практически все в этом мире имеет свойство подчиняться 3-му закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространства постоянно растут и тем самым нивелируют увеличение объем и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.
И вот тут как раз вопрос о дедупликации данных очень сильно становится актуальным. Ведь данные, которые мы используем бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент, фича серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд так оно будет нагляднее.
1) Файловая дедупликация — как и любой механизм дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, где вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и кажется будет продолжать это делать. Как нетрудно догадаться — файловый уровень самый высокий (если вспомнить устройство систем хранения данных в общем) — а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном применяется данный тип дедупликации к архивным данным.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но на уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскроют свои таланты.
Очень интересным в этом плане выглядит доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
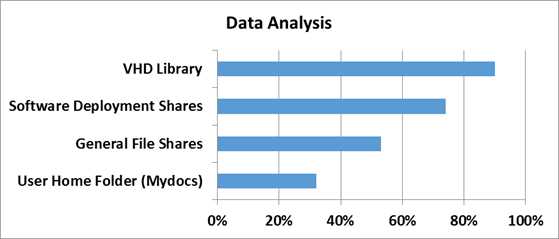
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:
1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно изменение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.
А теперь самое интересное — ниже приведен скриншот с томами в Windows Server 2012, на которых размещаются все эти данные.

Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
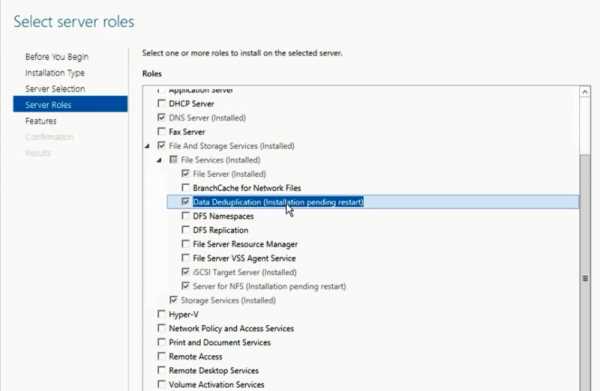
1) Прозрачность и легкость в использовании — настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрывайте роль File and Storage Services, далее File and iSCSI Services — а у же там включаете опцию Data Deduplication.
После этого в Server Manager вы выбираете Fike and Storage Services, клик правой кнопкой мыши — и там вы выбираете пункт «Enable Volume Deduplication». Спешл линк для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы — то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома защищенные с помощью EFS (Encrypted Fike System). Также под дедупликацию не попадают фалы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).
2) Оптимизация под основные данные — стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен 5 дням, но никто не мешает вам изменить этот параметр — но будьте разумны в своих экспериментах!
3) Планирование процессов оптимизации — механизм который каждый час проверяет файлы на соответствия параметрам дедупликации и добавляет их в расписание.
4) Механизмы исключения объектов из области дедупликации — данный механизм позволяет исключит файлы из области дедупликации по их типу (JPG, MOV, AVI — как пример, это потоковые данны — то, что меньше всего поддается дедупликации — если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
5) Мобильность — дедуплицированный том — это целостный объект — его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Все что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
6) Оптимизация ресурсоемкости — данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом применять дедупликацию можно даже к очень массивным наборам данных.
Также алгоритм всегда проверяет достаточно ли ресурсов памяти для проведения процесса дедупликации — если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.
7) Интеграция с BranchCache — механизмы индексация для дедупликация являются общими также и для BranchCache — поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
1) Резервное копирование — Windows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома, с точки зрения процессов резервного копирования. Также доступно специальное API, которое позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
После установки дедупликации вы можете найти инструмент под названием DDPEval.exe, который находится в \Windows\System32\ — данная утиль может быть портирована на сменный носитель или другой том. Поддерживаются ОС Windows 7 и выше. Так что вы можете проанализировать ваши данный и понять стоимость овечье шкурки. (смайл).
На этом мой обзор завершен. Надеюсь вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях — ВКонтакте, Facebook — по имени и фамилии — и я постараюсь вам помочь.
Для тех, кто хочет узнать про новые возможности в Windows Server 2012, а также System Center 2012 SP1 — я всех приглашаю посетить IT Camp — 26 ноября, накануне TechEd Russia 2012 состоится данное мероприятие — проводить его будем я, Георгий Гаджиев и Саймон Перриман, который специально прилетает к нам из США.
До встречи на IT Camp и на TechEd!
С уважением,
человек-огонь
Георгий А. Гаджиев
Microsoft Corporation
habr.com
Дедупликация данных – Weril
Skip to contentWeril
Weril
Menu and widgets- Nets
- Instruments
- Topology
- Wireshark
- Emulation
- Network
- VRF
- Data Link
- Ethernet
- LAN
- ERPS
- Wireless
- Transport
- Socket
- Upper Layers
- DNS
- DHCP
- ISP
- Beeline
- Services
- IP transit
- Network Arch
- Devices
- Huawei
- L3VPN
- BGP
- WLC
- Cisco
- ASR9k
- Extreme
- SNMP
- Bugs
- Static speed
- ZTE
- cpu-guard
- FW Update
- SNMP
- D-Link
- Bugs
- DES-3200c1
- Unicast low speed & IPTV
- DGS-3620
- STP + IPOE
- DES-3200c1
- DDM
- Bugs
- RRL
- MINI-LINK 6352
- CPE
- MikroTik
- Hardware
- Interfaces
- Zyxel Keenetic
- VPN
- Functions
- TR-069
- Huawei
- Instruments
- Coding
- Python
- Ruby
- http
- Gem installation
- File and Dir
- string
- mysql2
- oci8
- spreadsheet
- mechanize
- PHP
- Oracle
- File Upload
- PHPExcel
- Classes
- Debug
- If-else-elseif
- Authentication
- php-wget/curl
- urlencode
- PHP cookie/session
- Google Authenticator
- Install
- MySQL
- Bash
- port list from range
- mW to Dbm
- HTML, HTTP, CSS
- GET and POST
- CSS
- JavaScript
- phantomjs
- Testing
- Progs
- bot
- Linux
- Characters
- General
- screen
- xargs
- join
- sort
- cron
- editors
- vim
- cat/zcat
- arch & compress
- compressing tools
- sed
- tr
- pwd
- ls
- cd
- wc
- Admin tasks
- Distributives
- Application Installation
- OS
- Date/time
- Update (apps/OS)
- Info
- Hostname
- Log
- last(log)(b)
- Users (add, del, pass)
- Myself
- Groups
- Network
- ftp
- iperf
- tcpreplay
- vrf
- proxy
- tftpd
- tcpdump
- nmap
- SNMP
- Install
- Trap & Inform
- iptables
- nc
- wget/curl
- rsync
- ssh
- ssh tunnel
- Mail
- mutt
- ssmtp
- attach
- Misc
- Dict
- Utilities
- HD tune
- WinSCP
- Terminal Emulator
- SecureCRT
- TV
- Picture
- 4K
- Satellite
- Picture
- Storage
- Big Data
- NAS
- SAN
- IP
- Fibre Channel
- Devices
- Storage systems
- VTL
- SCSI
- RAID
- Web Servers
- Apache
- nginx
- Based on Ruby
- Web Services
- Uptimerobot
- Auth0
- WordPress
- Google Authenticator
- Messengers
- IT monsters
- Windows
- MS Office
- Excel
- ВПР
- Excel
- MS Office
- Monitoring
- SPAN/RSPAN/MIRROR
- Probe
- Wireshark
- Virtualization
- Basic
- VPS&VDS
- OpenStack
- FusionSphere
- FusionAccess
- VMWare
- VirtualBox
- Hyper-V
- XEN
- KVM
- Devices
- notebook
- Servers
- Computer and Components
- IPMI
- Arch
- RAID
- HDD
- SSD
- Storage interfaces
- CPU
- Bus
- BIOS
- Watch
- Mobile Phones/Tablets
- DB
- MySQL
- Users
- Install
- View
- Oracle
- script
- PostgreSQL
- MySQL
- Security
- Antivirus
- Kaspersky
- Devices
- DPI
- Antivirus
- NewTech
- Bots
- Носимые устройства
- IoT
- Life
- Art
- History
- Books
- Достоевский
- Films
- Travel
- Philosophy
- About
weril.me