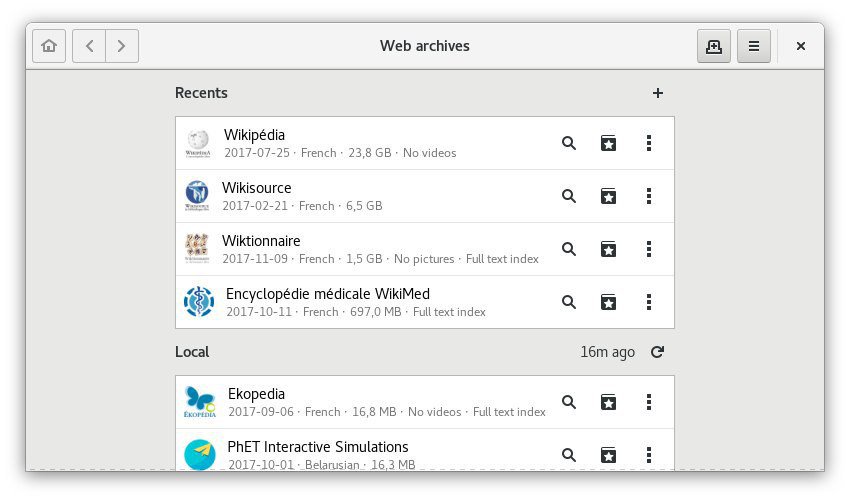
Что такое web.archive.org, для чего он нужен и как ним пользоваться?
Что такое web.archive.org?
это сервис с помощью которого можно изучить историю домена с момента его первого попадания в базу сервиса. Его еще могут искать так цуи фксршму.
С помощью сервиса можно посмотреть скрины сайта, которые сервис делает с некоторой периодичностью.
https://web.archive.org/
Веб архив сайтов:
Не каждый сайт имеет историю в сервисе. Молодой сайт, который ранее никем не регистрировался не будет иметь истории.
История сайтов с 1996 года
Сервис работает с 1996 года.
Если Ваш домен ранее использовался и был активен (размещался контент и присутствовал в поиске), WayBackMachine хранить историю о нем.
Частота сканирования и создания истории
Активные сайты в поиске и большого размера чаще сканируются сервисом.
Можно ли удалить историю домена?
Как написано в документации — можно.
Для этого необходимо отправить запрос по адресу [email protected] с указанием URL-адреса домена и аргументацией, почему необходимо удалить историю. Так-же необходимо подтвердить право владения доменом.
Можно добавить страницы в Wayback Machine?
Да. На https://archive.org/web модно использовать функцию «crawl my site now!» для единоразового сохранения страницы.
Он не сохраняет несколько страниц, каталогов или целых сайтов.
Как пользоваться сервисом Web Archive?
Пример использования Web Archive для просмотра истории сайта.
- показывает историю по годам, выбирайте год в панели сверху
- показывает по датам скриншоты сайта, выбирайте день в который вы хотите посмотреть историю
- переходите по ссылкам в скриншоте, можно переходить по ссылкам, если страница есть в архиве — она откроется
Веб-архив — Викиреальность
(▲)
Веб архив / Каким был интернет в 2000 году? / Гоша ДударьВеб-архив — сайт, предназначенный для сохранения копий страниц других сайтов в зафиксированный момент времени. Может наполняться автоматически или вручную администрацией и его пользователями, в последнем случае является частью Веб 2.0. Различные веб-архивы используют разные методы сохранения страниц.
Близки к веб-архивам сайты-цитатники (например, bash.org), созданные для сохранения интересных или смешных цитат из Интернета, специальные сайты для сохранения страниц имиджборд и сайты для сохранения отдельных страниц закрытых ресурсов.
- web.archive.
 org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра.
org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра. - peeep.us — совмещенный с сокращателем ссылок сайт, позволяющий сохранять страницы самим пользователям. Создаёт зеркало страницы на фиксированный момент времени, который отображается вверху жёлтой полосой, с сокращённым URL-адресом. В отличие от веб-архива, щёлкая по ссылкам, открываются веб-страницы на текущий момент времени, а не в архиве. В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.
- archive.is — сайт, аналогичный peeep.us. Отличается тем, что сохраняет не только основной html-файл страницы, но также и все картинки, стили, фреймы и фонты. Также умеет сохранять страницы с Web2.0-сайтов, например с twitter.com.
 org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра.
org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра. В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.
В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.Также в роли веб-архивов выступают кеши поисковых систем, но в отличие от первых, они ненадёжны, поскольку могут быстро удаляться. Наибольший срок хранения страниц замечен за Яндексом.
[править] В викисреде
Роль веб-архивов могут выполнять отдельные разделы сайтов, которые сами по себе ими не являются:
- Копипаста Луркоморья — сборник заинтересовавших пользователей Луркоморья текстов со страниц Интернета или взятые из книжных источников.
- Архивы Викиреальности — сохраняет заслуживающие внимание страницы и творчество, связанное с викисредой. Для архивов выделено специальное пространство имён.
- Авторские проекты в Традиции (например, творчество АПЭ, Погребного и т. п.) — сборник творчества различных авторов, которое (в большинстве своём) ранее где-то выкладывалось.

Что такое веб-архив Веб-архив… — BAMS — Студия Маркетинга Болоховец Алисы
Что такое веб-архив
Веб-архив (Webarchive) – это бесплатная платформа, где собраны все сайты, созданные когда-либо, и на которые не наложен запрет для их сохранения.
Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг. Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive. org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
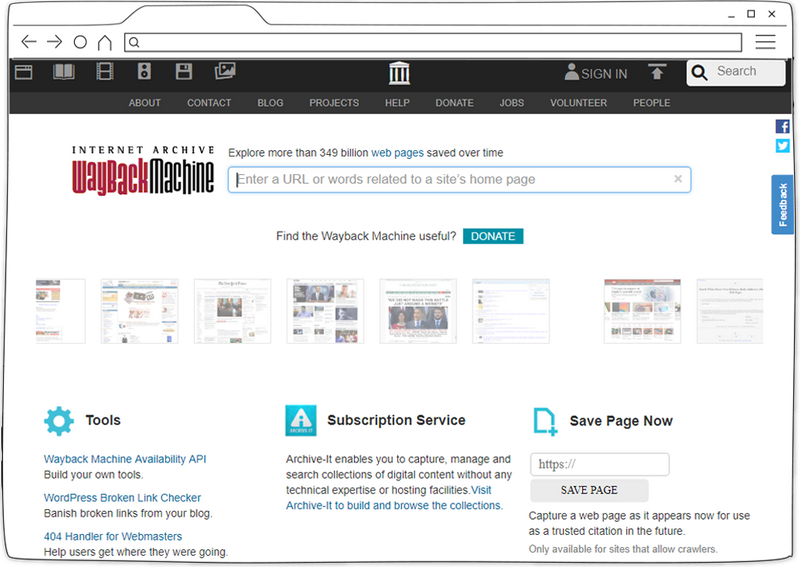
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
правообладатель решил удалить все копии;
веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
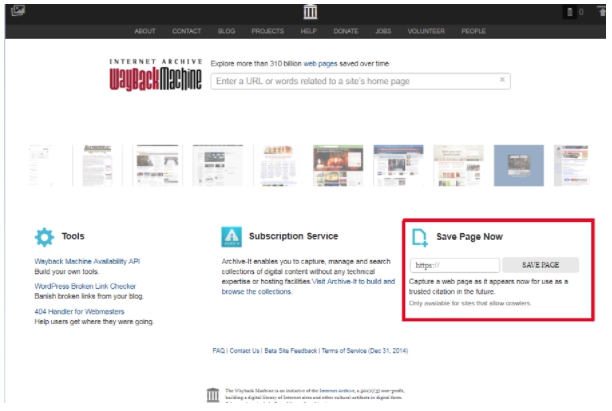
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive.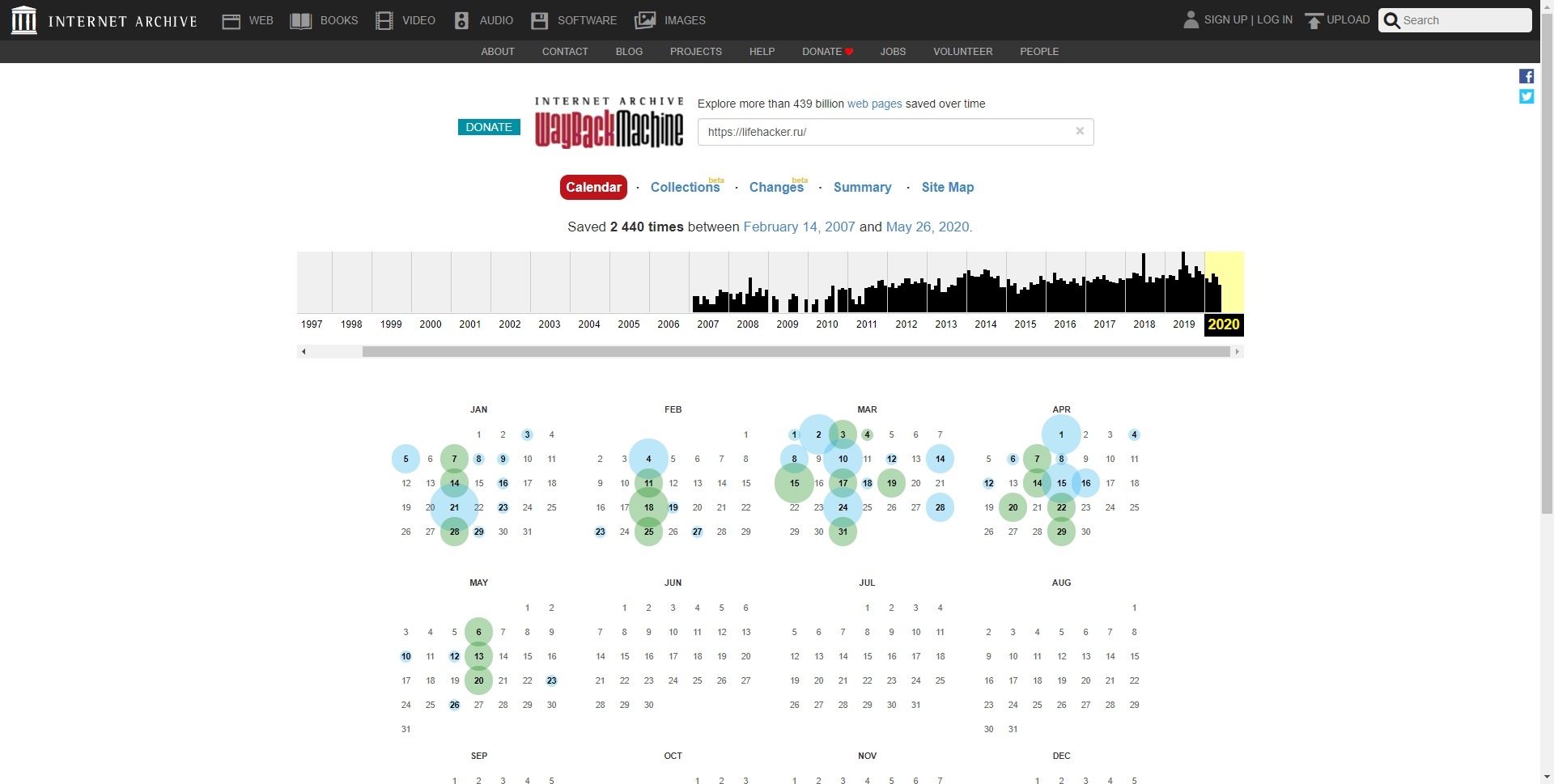 Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
Сохранить копию сайта в веб архив Internet archive Wayback Machine
В интернете существует очень интересный и полезный проект — веб архив, полностью — Internet archive Wayback Machine.
В веб архиве, расположенным по адресу: http://archive.org/web/, сохраняется прошлое сайтов в виде полноценных и работающих страниц, со всеми ссылками, изображениями, видео. В общем можно увидеть, какой был сайт в прошлом на дату формирования копии.
Боты архив-машины самостоятельно сканируют сайты и формируют их копии, каков их алгоритм — не известно. Поэтому в архиве можно найти много копий своего сайта со всеми страницами или всего одну, да и то искажённую.
Предположить, в каком виде загрузится и отобразится тот или иной сайт — невозможно. Но как правило, машина периодически сохраняет полноценные копии всего сайта и даже может выдать страницы, которых у вас не было никогда.
Если вы не хотите отдавать судьбу своего сайта в руки ботов ресурса, то можно самостоятельно занести страницу в архив, и в случае непредвиденных случайностей, найти и восстановить её.
Как увидеть архив своего сайта
Откройте Internet archive и в строке поиска введите адрес сайта, далее нажмите «browse history»
Здесь будет показано, сколько копий, в каком году и в каком месяце сохранено в архиве.
Выбрав дату и нажав на эти кнопки, можно увидеть копию сайта на тот момент времени.
Как занести сайт в архив
Для этого откройте главную страницу Internet archive Wayback Machine: http:// archive.org/web/.
Далее в рубрике Save Page Now введите адрес архивируемой страницы и нажмите «SAVE PAGE». Через несколько секунд копия буде сохранена.
Как запретить архивировать мой сайт
Что за дело, кто без моего спроса меня сосчитал? Если вы так думаете, то можно запретить веб-машине сохранять копии вашего сайта
Для этого в файле robots. txt нужно прописать запрещающую директиву для ботов wayback machine.
txt нужно прописать запрещающую директиву для ботов wayback machine.
|
User-agent: ia_archiver Disallow: / |
Чтобы позволить архивировать сайт снова, уберите эти строки из файла robots.txt и лучше сразу добавьте главную станицу в архив. Иначе изменений можно дожидаться долго, обновления в системе происходят редко.
***
Как просмотреть позиции модулей Joomla 2.5
Как сделать резервную копию — бекап файлов сайта
Выделение перемещение и копирование
Заработать на бирже Gogetlinks размещая ссылки на сайте
- < Назад
- Вперёд >
Крупнейший в мире архив интернета бежит из США из-за Трампа
, Текст: Валерия Шмырова
Американский ресурс Internet Archive решил скопировать себя на территорию Канады, чтобы избежать последствий избрания Дональда Трампа президентом США.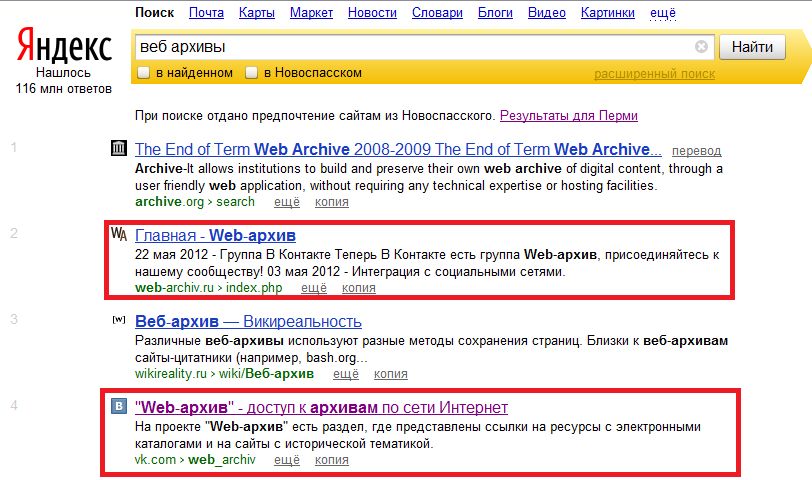 Ресурс содержит материалы, которые могут быть криминализированы, если Трамп изменит законы о цензуре и клевете.
Ресурс содержит материалы, которые могут быть криминализированы, если Трамп изменит законы о цензуре и клевете.
Internet Archive собрался в Канаду
Американская некоммерческая организация Internet Archive собирается создать копию своего архива в Канаде из-за победы Дональда Трампа (Donald Trump) на выборах президента США. Владелец ресурса
Internet Archive – это универсальная электронная библиотека, которая занимается сбором и хранением старых версий различных сайтов. По словам Кейла, в скором будущем наблюдение властей США за свободными источниками информации станет более пристальным, поэтому он не желает, чтобы его ресурс находился в пределах досягаемости правительства.
Сейчас сервера Internet Archive находятся в Сан-Франциско, а зеркала – в Александрии (Египет) и в Амстердаме (Нидерланды). Создание копии в Канаде должно защитить ресурс в том случае, если Трамп решит ужесточить закон о цензуре или закон о клевете, чтобы отплатить американским СМИ за свой подпорченный имидж, пишет ресурс Business Insider.
Создание копии в Канаде должно защитить ресурс в том случае, если Трамп решит ужесточить закон о цензуре или закон о клевете, чтобы отплатить американским СМИ за свой подпорченный имидж, пишет ресурс Business Insider.
Чем опасен для Трампа Internet Archive
Internet Archive наиболее известен благодаря сервису Wayback Machine, созданному в 2001 г. Wayback Machine позволяет увидеть, как в разное время выглядел тот или иной веб-ресурс, даже если он уже удален к моменту просмотра. По словам Кейла, сервис еженедельно сохраняет копии 300 млн веб-страниц.
Сервис Wayback Machine позволяет увидеть, как в разное время выглядел тот или иной веб-ресурс
В ряде случаев Wayback Machine дает возможность просмотреть материалы, доступ к которым уже был ограничен на исходном сайте. Обычно Internet Archive удаляет такие материалы по требованию правообладателей или владельцев ресурса-источника. Однако в октябре 2014 г. ресурс не прислушался к требованию Роскомнадзора удалить ролик экстремистского содержания, за что был заблокирован на территории России.
Также Internet Archive располагает большой библиотекой публикаций и видеозаписей политического характера Political TV Ad Archive. По словам Кейла, эти материалы используются американскими журналистами для «проверки фактов, относящихся к предвыборным обещаниям кандидатов», в том числе Дональда Трампа.
История Internet Archive
Internet Archive был основан Брюстером Кейлом в Сан-Франциско в 1996 г. и до 1999 г. там хранились только копии веб-страниц, однако впоследствии были добавлены графические объекты, видео- и аудиоматериалы, ПО и т. д. До 2001 г. собранные копии не были доступны широкой аудитории, но ситуация изменилась после запуска Wayback Machine.
Материалы хранятся в архиве длительное время, доступ к ним бесплатный. По состоянию на август 2016 г. в Internet Archive насчитывалось 502 млрд копий различных веб-страниц. По словам Кейла, архив входит в топ-250 самых посещаемых веб-сайтов мира и является крупнейшим ресурсом своего профиля. Его поддержкой занимается команда из 150 человек.
Организация гарантирует посетителям сайта приватность и, в частности, не применяет механизмы отслеживания поведения пользователя и не собирает IP-адреса.
«Архив интернета» могут навечно заблокировать в России
, Текст: Эльяс Касми
Россияне могут лишиться доступа к крупнейшему в мире архиву интернета, существующему с 1996 г. Против него действует Ассоциация по защите авторских прав в интернете, повлиявшая на блокировку библиотеки «Флибуста» и даже пытавшаяся заблокировать «Яндекс».Блокировка из-за фантастики и детективов
Ассоциация по защите авторских прав в интернете (АЗАПИ) хочет добиться блокировки в России «Архива интернета» (Internet Archive). Причина блокировки – присутствие в контенте ресурса копий аудиокниг российских писателей – Дмитрия Глуховского (вселенная «Метро 2033») и Дарьи Донцовой.
Internet Archive – американская некоммерческая ассоциация и одноименный веб-портал, представляющий собой крупнейшую электронную библиотеку Интернета. Это ресурс мирового масштаба, и он официально входит в Международный консорциум сохранения Интернета (International Internet Preservation Consortium).
Иски о блокировке archive.org (сайт «Архива интернета»), а их на момент публикации материала было как минимум два, АЗАПИ подала в Московский городской суд. По мнению Ассоциации, доступ к «Архиву» должен быть запрещен на всей территории России, притом навечно.
Хроника событий
АЗАПИ, по данным Роскомсвободы, действует в интересах издателя ООО «Аудиокнига», и началось все с аудиокниг по серии романов Глуховского «Метро 2033», к которым позже добавилось произведение Дарьи Донцовой «Третий глаз алмаз». Иск по этому делу (номер дела 3-0335/2019) был подан 13 марта 2019 г, а Мосгорсуд рассмотрел его 13 мая 2019 г., притом в экстренном порядке, и вынес вердикт в пользу истца. Решение вступило в силу 15 июня 2019 г.
Решение вступило в силу 15 июня 2019 г.
По решению суда, «Интернет архиву» и другим ответчикам («ДейтаВебГлобал Групп» и ООО «ТК Мароснет») было запрещено «создавать технические условия, обеспечивающие размещение» аудиокниг на веб-ресурсах, перечисленных в иске. Важно отметить, что представители «Интернет архива» участия в заседании не принимали, а о решении суда американская организация извещена не была.
Россию могут навсегда оставить без Архива интернета
Второй иск был подан 21 июня 2019 г. (номер дела – 3-0634/2019, ответчик – «Интернет архив»). В нем истец (ООО «Аудиокнига», как и в первом случае) требовал заблокировать сайт archive.org в России на постоянной основе. Заседание по иску состоялось 16 августа 2019 г., однако рассмотрение дела было отложено по причине отсутствия у АЗАПИ доказательств того, что «Третий глаз алмаз» действительно был записан в форме аудиокниги обществом «Аудиокнига», и что у него (общества) есть права на эту книгу.
Рассмотрение было назначено на 12 сентября 2019 г, и существует еще одна причина переноса – по информации Роскомсвободы, на решение Мосгорсуда по первому иску была подана жалоба, дата рассмотрения которой на 23 августа 2019 г. оставалась неизвестной. По обоим делам американскую организацию в российском суде представляют юристы Роскомсвободы и Центра цифровых прав адвокат Саркис Дарбинян и Екатерина Абашина.
оставалась неизвестной. По обоим делам американскую организацию в российском суде представляют юристы Роскомсвободы и Центра цифровых прав адвокат Саркис Дарбинян и Екатерина Абашина.
Борьба с добром и российской судебной практикой
Организация Internet Archive зарегистрирована в Сан-Франциско (Калифорния, США), а одноименный ресурс, согласно законам штата Калифорния, официально считается библиотекой. Организация располагает обширным списком партнеров, в число которых входят многие крупные организации со всего мира. К ним относятся, в частности, Национальный научный фонд США и Библиотека конгресса США
Гибридная рабочая среда вызывает привыкание
БизнесВ России «Архив интернета» нередко используется российскими судами как доверенную третью сторону и источники информации, в том числе улик и доказательств расследования.
«Послужной список» АЗАПИ
АЗАПИ была основана в мае 2013 г. издательствами АСТ и «Эксмо», которые на тот момент были ее единственными учредителями. Через общего владельца АЗАПИ родственна книжному онлайн-магазину «Литрес».
Через общего владельца АЗАПИ родственна книжному онлайн-магазину «Литрес».
«Архив интернета» — не первая цель АЗАПИ в борьбе за интеллектуальную собственность. К примеру, в сентябре 2013 г. была заблокирована популярная в России электронная библиотека «Флибуста». Бывший глава Ассоциации защиты авторских прав в интернете Олег Колесников в разговоре с CNews признал, что «нынешняя неработоспособность «Флибусты» случилась благодаря его ассоциации». К слову, в тот же день «Флибуста» сумела прорвать блокировку и вновь стала доступной всем пользователям. На 23 августа 2019 г. эта библиотека была включена в список запрещенных в России ресурсов, и доступ в нее без спецсредств был закрыт окончательно.
В январе 2014 г. АЗАПИ пошла войной на торрент-трекер «Рутрекер» (навечно заблокирован в России с ноября 2015 г.) и начала готовить против него иск. Причиной стали поддерживаемые трекером раздачи архивов электронных библиотек «Флибуста» и «Либрусек», затрагивающие интересы основателей АЗАПИ, издательств «Эксмо» и АСТ.![]() В августе 2016 г. «Эксмо» при содействии АЗАПИ попыталось через Мосгорсуд заблокировать доступ к «Яндексу» из-за ссылок в поисковой выдачи на скачивание книг из Rutracker. Однако Мосгорсуд отклонил это требование, поскольку доступ к Rutracker и так заблокирован.
В августе 2016 г. «Эксмо» при содействии АЗАПИ попыталось через Мосгорсуд заблокировать доступ к «Яндексу» из-за ссылок в поисковой выдачи на скачивание книг из Rutracker. Однако Мосгорсуд отклонил это требование, поскольку доступ к Rutracker и так заблокирован.
В октябре 2016 г. история о борьбе с «книжными пиратами» получила неожиданное продолжение: в отношении действующего главы Ассоциации по защите авторских прав в интернете (АЗАПИ) Максима Рябыко возбуждено уголовное дело по по подозрению в вымогательстве p50 млн с владельца интернет-магазина.Эту информацию не называя фамилий, подтвердили в МВД России. Представительница МВД Ирина Волк заявила, что в кафе в центре Москвы в четверг были задержаны двое мужчин, подозреваемых в мошенничестве.
Несмотря на подозрения в совершении преступления, Максим Рябыко остается главой АЗАПИ
Сам Максим Рябыко, общаясь с прессой, свое задержание категорически опроверг. «Меня никто не задерживал, я не знаю, откуда появилась такая информация», — заявил он, пояснив, что «узнал о своем задержании из СМИ». На 23 августа 2019 г. Рябыко по-прежнему находился на должности генерального директора АЗАПИ.
На 23 августа 2019 г. Рябыко по-прежнему находился на должности генерального директора АЗАПИ.
Веб-Архив — Каталог архивных Интернет-ресурсов
Веб-Архив — Каталог архивных Интернет-ресурсов Новые По рейтингу Сайты архивов-
0 0 0
Пермский государственный архив социально-политической истории
-
0 0 0
Комитет по делам архивов при Правительстве Удмуртской Республики
-
0 0 0
Российский государственный архив научно-технической документации (РГАНТД)
-
0 0 0
Управления по делам архивов Республики Башкортостан
-
0 0 0
Управление государственной архивной службы Самарской области
-
0 0 0
Государственный комитет Республики Татарстан по архивному делу
-
0 0 0
Архивное управление администрации Осинниковского городского округа
-
0 0 0
Государственный архив Пермского края
-
0 0 0
Государственный архив Калининградской области
-
0 0 0
Государственный архив Алтайского края
-
0 0 0
Федеральное архивное агентство (Росархив)
-
0 0 0
Архив города Перми
-
0 0 0
Главное архивное управление города Москвы (Главархив Москвы)
-
0 0 0
Управление государственной архивной службы Новосибирской области
-
0 0 0
Государственный архив социально-политической истории Кировской области
-
0 0 0
Управление по делам архивов Правительства Ярославской области
-
0 0 0
Государственный архив Ханты — Мансийского автономного округа — Югры
-
0 0 0
Архивное агентство Красноярского края
-
0 0 0
Архивный департамент администрации Владимирской области
-
0 0 0
Российский государственный архив кинофотодокументов (РГАКФД)
-
0 0 0
Комитет по управлению архивным делом Ростовской области
-
0 0 0
Архивный отдел администрации Александровского муниципального района
-
0 0 0
Государственный комитет по делам архивов Челябинской области
-
0 0 0
Комитет по делам архивов Нижегородской области
 Самаре»>
Самаре»>
0 0 0
Филиал российского государственного архива научно-технической документации в г. Самаре-
0 0 0
Школьные годы полководцев
-
0 0 0
Я, партизан Великой Отечественной войны…
-
0 0 0
К празднику весны и труда (май 2014)
-
0 0 0
8 марта. История празднования
-
0 0 0
«Женщина – на все руки мастер»
-
1 0 0
Выставка-подборка документов к 80-летию со дня рождения Е. В. Плотниковой
-
1 0 0
«Советско-финляндская война 1939-1940 гг.»
-
0 0 0
Война в Афганистане глазами советских военнослужащих. Повседневность службы в памятных фотографиях
-
0 0 0
К 100-летию создания Красной Армии
-
0 0 0
Выставка к Юбилею Анатолия Геннадьевича Зернина
-
0 0 0
«В нем жил неудержимый дух эпохи»
-
0 0 0
Виртуальная выставка документов К 105-летию Н. И. Кузнецова
-
4 0 0
«Тимуровское движение в Чувашии по фондам госархива» (2018)
-
4 0 0
Электронный фотоальбом «Жизнь и деятельность Ильи Павловича Прокопьева через фотообъектив» (2018)
-
3 0 0
«Тебя пою, мой край родной . ..» (2017)
-
7 0 0
«Воевали, чтобы победить» (2016)
-
6 0 0
Ими гордится земля чувашская
-
20 1 0
К 70-летию Победы в Великой Отечественной войне. Ярославцы на фронте и в тылу.
-
13 0 0
Ростов в годы Великой Отечественной войны
-
8 1 0
Страницы мужества и героизма. Ярославль в Великой Отечественной войне 1941—1945 гг.
-
4 0 0
Ярославский край в Отечественной войне 1812 года
-
15 0 0
Наша «Чайка» (к 50-летию полета в космос первой в мире женщины—космонавта В. В. Терешковой)
-
5 0 0
«Моя комсомольская юность совпала с этим трудным и прекрасным временем…» 105-летию со дня рождения Пермяковой Анфисы Кузьмовны посвящается
-
4 0 0
ЯМАЛЬЦЫ НА ФРОНТАХ ВЕЛИКОЙ ОТЕЧЕСТВЕННОЙ ВОЙНЫ
-
4 0 0
«Страницы истории Ямала в лицах» к 80-летию Государственного архива Ямало-Ненецкого автономного округа
 История празднования
История празднования В. Плотниковой
В. Плотниковой И. Кузнецова
И. Кузнецова ..» (2017)
..» (2017) Ярославцы на фронте и в тылу.
Ярославцы на фронте и в тылу.
-
0 0 0
Электронное издание «Дневник рабочего» -
0 0 0
В. Я. АБОЛТИН. ОСТРОВ СОКРОВИЩ: СЕВЕРНЫЙ САХАЛИН -
12 0 0
В.Я. АБОЛТИН. ОСТРОВ СОКРОВИЩ: СЕВЕРНЫЙ САХАЛИН -
7 0 0
Смоленская область в годы Великой Отечественной войны (1941-1945 гг. ) -
4 0 0
Шагай вперед, комсомольское племя. Сборник материалов -
6 0 0
Возрожденный из руин. Сборник документов и материалов (1943-1962 гг.) -
15 0 0
Партизанская борьба с немецко-фашистскими оккупантами на территории Смоленщины (1941-1943 гг.) -
3 0 0
Женщины рассказывают. Воспоминания, статьи (1918-1959 гг.) -
13 0 0
Раскулачивание на Урале. Тематический перечень Ч.1 -
7 0 0
Раскулачивание на Урале. Тематический перечень Ч.2 -
0 0 0
«Свердловская область.70 лет». Справочное издание -
4 0 0
Трагедия на озере Ильмень -
3 0 0
П. А.Ойунский. Жизнь и деятельность -
7 1 0
Воины-якутяне на Курской Дуге -
1 0 0
Золотые звезды Земли Олонхо -
4 0 0
Трудный путь к Победе -
3 0 0
Святой праведный Иоанн Кронштадтский. Творения. -
1 0 0
Назад Русская Райвола XIX – начала XX века -
1 0 0
Издания Государственного архива Республики Бурятия за 1957-2016 гг. -
1 0 0
«Александровский архивный вестник» -
1 0 0
«Спасибо за Победу» -
4 0 0
«Тебе эти строки пишу я. ..» -
10 0 0
«Человек на войне: сборник интервью с участниками Великой Отечественной войны 1941-1945 гг. » -
1 0 0
«Исполнительная власть Республики Марий Эл 1921-2008 гг. Т. 4: сборник документов» -
0 0 0
«Исполнительная власть Республики Марий Эл 1921-2008 гг. Т. 3: сборник документов»
 Я. АБОЛТИН. ОСТРОВ СОКРОВИЩ: СЕВЕРНЫЙ САХАЛИН
Я. АБОЛТИН. ОСТРОВ СОКРОВИЩ: СЕВЕРНЫЙ САХАЛИН )
) Сборник документов и материалов (1943-1962 гг.)
Сборник документов и материалов (1943-1962 гг.)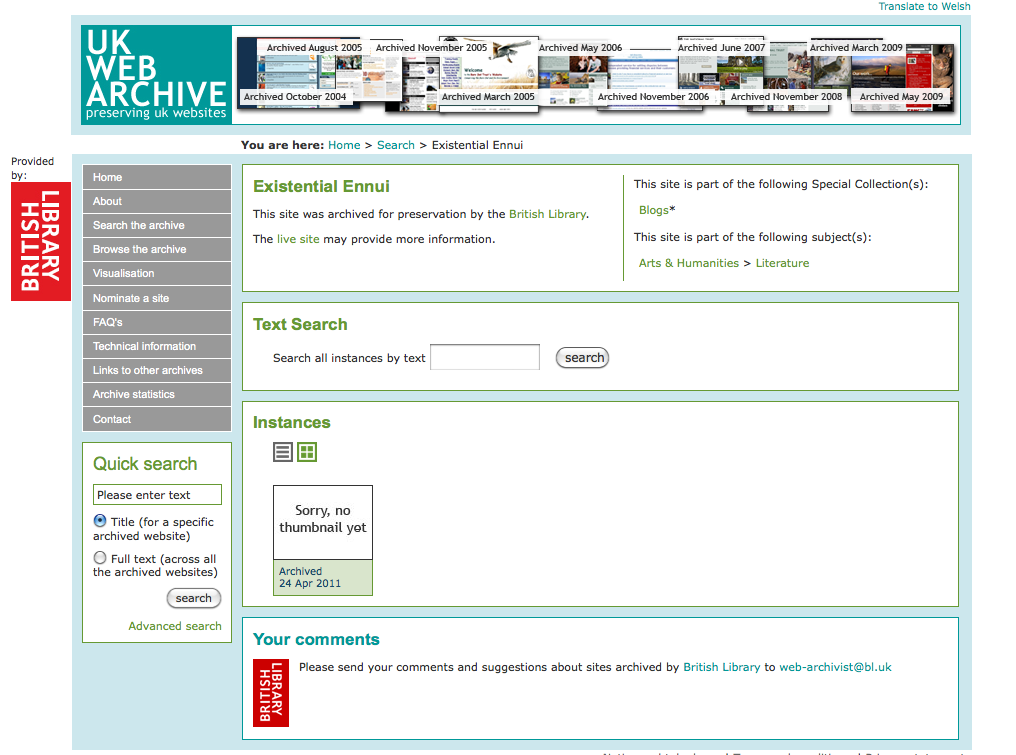 Воспоминания, статьи (1918-1959 гг.)
Воспоминания, статьи (1918-1959 гг.) Тематический перечень Ч.2
Тематический перечень Ч.2 А.Ойунский. Жизнь и деятельность
А.Ойунский. Жизнь и деятельность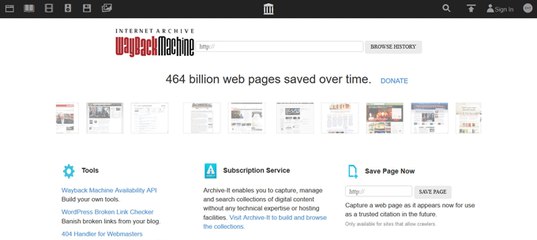 Творения.
Творения.
 ..»
..» Т. 4: сборник документов»
Т. 4: сборник документов»-
0 0 0
Книга памяти. Финляндия. 1939–1940. -
0 0 0
Книга Памяти. Чечня 1994-1996 и 1999-2009 гг. -
0 0 0
Книга Памяти. Афганистан. 1979–1989 -
0 0 0
Книга памяти. Хасан, Халхин-Гол -
0 0 0
Памятники, памятные знаки, исторические здания и места Коми-Пермяцкого округа -
0 0 0
Люди Пармы -
0 0 0
Эвакуированные дети -
0 0 0
Эвакуированные -
11 0 0
Каталог фондов -
8 0 0
Фонды архива Хабаровского края -
1 0 0
Каталог фондов Ульяновской области -
13 0 0
Базы данных Республики Удмуртия -
3 0 0
Краткий справочник по фондам Тверского центра документации новейшей истории -
20 0 0
Поисковые базы данных Свердловской области -
4 0 0
Список фондов по личному составу Сахалинской области -
5 0 0
Фонды по личному составу Ростовской области -
2 0 0
Фонды Ростовской области -
1 0 0
Фонды Ростовской области -
1 0 0
Фонды периода после 1917 года с документами по личному составу Костромской области -
3 0 0
Сгоревшие фонды периода после 1917 года Костромской области -
1 0 0
Фонды периода после 1917 года Костромской области -
1 0 0
Сгоревшие фонды периода до 1917 года Костромской области -
2 0 0
Фонды периода до 1917 года Костромской области -
6 0 0
СПИСОК ФОНДОВ ГУ «РАДЛС» Республиканского архива
 Финляндия. 1939–1940.
Финляндия. 1939–1940.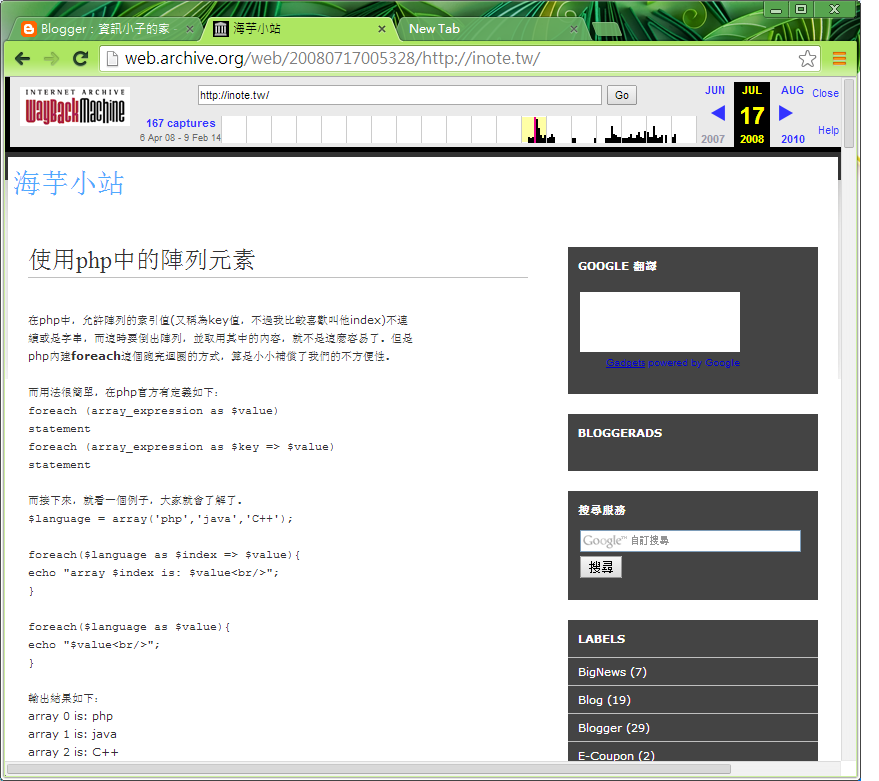 Афганистан. 1979–1989
Афганистан. 1979–1989 Шахты Ростовской области»>
Шахты Ростовской области»>
5 0 0
Фонды г. Шахты Ростовской области-
2 0 0
МУЗЕИ КРЫМА В ГОДЫ ВЕЛИКОЙ ОТЕЧЕСТВЕННОЙ ВОЙНЫ (С. А. АНДРОСОВ) -
1 0 0
ПАМЯТИ ДОКТОРА Ф. К. МИЛЬГАУЗЕНА (К 235-ЛЕТИЮ СО ДНЯ РОЖДЕНИЯ ВРАЧА, УЧЕНОГО БОТАНИКА, МЕТЕОРОЛОГА) (КРАВЦОВА Л.П.) -
1 0 0
АЛУПКИНСКИЙ ДВОРЕЦ: ОТ РОДОВОГО ЗАМКА ВОРОНЦОВЫХ К ГОСУДАРСТВЕННОМУ МУЗЕЮ (С. А. АНДРОСОВ) -
2 0 0
А.Я.ФАБР: ШТРИХИ К ИСТОРИЧЕСКОМУ ПОРТРЕТУ (С.А. АНДРОСОВ) -
1 0 0
«БУДНИ» ГОРОДСКОГО АРХИТЕКТОРА ЯЛТЫ (А. В. КАБАЧКОВА) -
2 0 0
На ладони земли – городок небольшой -
1 0 0
Белая земля контрастов, опорный край державы -
3 0 0
Архивная служба Югры шагает в ногу со временем -
0 0 0
«Письмо из победного дня» -
1 0 0
Мероприятие, посвященное Дню Победы в Великой Отечественной войне, под названием «Нет героев от рожденья, они рождаются в боях». -
2 0 0
«Времен связующая нить…» связала историю Ханты-Мансийска воедино -
1 0 0
Алексей Путин: «В ближайшие годы медицина у нас достигнет уровня Германии, США, Израиля» -
0 0 0
К 95-летию историка и краеведа Александра Александровича Александрова -
1 0 0
О новом поступлении документов личного фонда А. А. Александрова -
0 0 0
Листая страницы истории БУЗ УР «Глазовская межрайонная больница» -
1 0 0
«180 лет селу Шаркан» -
1 0 0
О новом поступлении документов в личный фонд А. А. Ельцова -
2 0 0
О создании личного фонда Ю.И. Копысова — комсомольского, партийного работника, кандидата исторических наук, Почетного архивиста в ГКУ «ЦДНИ УР» -
0 0 0
«Общеобразовательные процессы Удмуртии начала XX века на примере Ижевской женской гимназии по документам ГКУ «ЦГА УР» -
0 0 0
Г. Е. Верещагин – писатель, ученый, просветитель… -
1 0 0
Старейшему на Северном Кавказе театру исполняется 170 лет -
2 0 0
Архивные документы рассказывают, как ставропольцы помогали фронту -
2 0 0
Государственному архиву Ставропольского края исполняется 95 лет -
5 1 0
«Озверелый фашизм напал на нашу Родину, и с ним сражаются лучшие сыны. ..» -
1 0 0
О благотворительности в Ставрополе в XIX веке
 А. АНДРОСОВ)
А. АНДРОСОВ) А. АНДРОСОВ)
А. АНДРОСОВ) В. КАБАЧКОВА)
В. КАБАЧКОВА)
 А. Александрова
А. Александрова А. Ельцова
А. Ельцова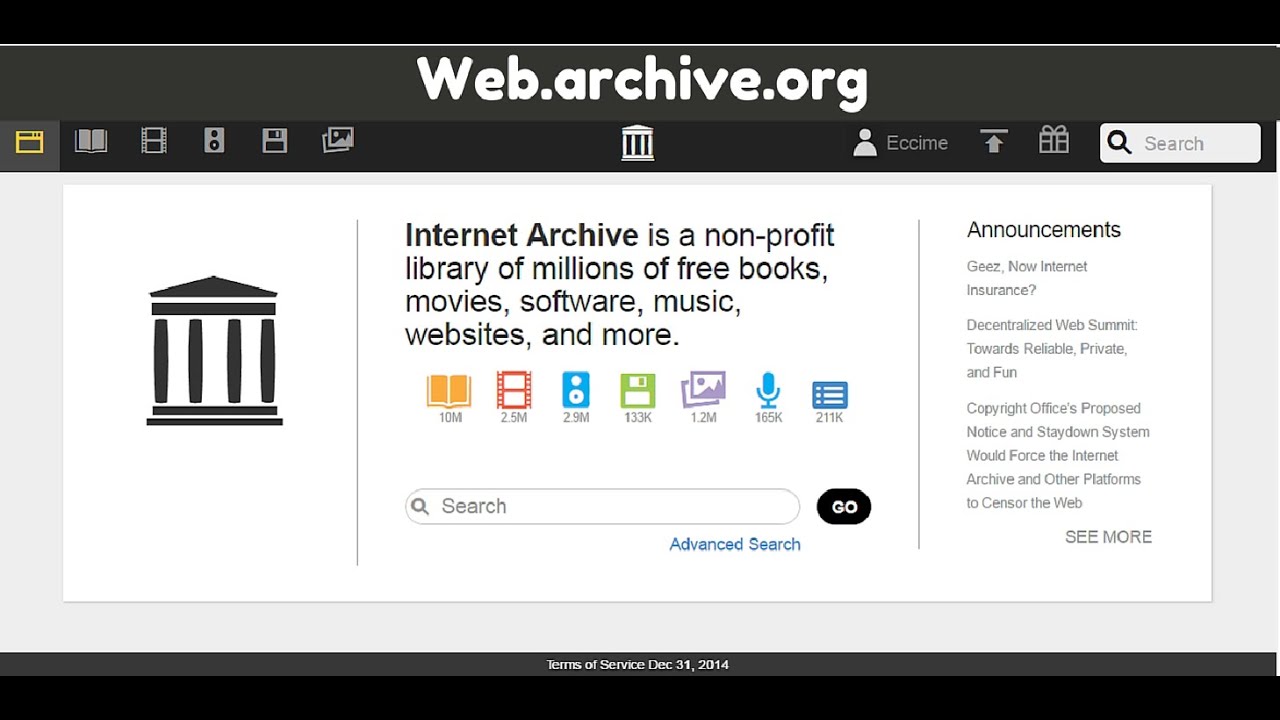 ..»
..»Исследователям
Мы в соц. сетях
Об этой программе | Веб-архивирование | Программы | Библиотека Конгресса
Веб-архив Библиотеки Конгресса США управляет, сохраняет и предоставляет доступ к заархивированному веб-контенту, выбранному предметными экспертами со всей Библиотеки, так что он будет доступен исследователям сегодня и в будущем. Веб-сайты эфемерны и часто считаются цифровым контентом, подверженным риску. Постоянно создаются новые веб-сайты, меняются URL-адреса, изменяется контент, а иногда и веб-сайты полностью исчезают.Веб-сайты документируют текущие события, организации, реакцию общественности, правительственную информацию, а также культурную и научную информацию по широкому кругу тем. Материалы, которые раньше печатались, все чаще публикуются в Интернете.
Веб-сайты эфемерны и часто считаются цифровым контентом, подверженным риску. Постоянно создаются новые веб-сайты, меняются URL-адреса, изменяется контент, а иногда и веб-сайты полностью исчезают.Веб-сайты документируют текущие события, организации, реакцию общественности, правительственную информацию, а также культурную и научную информацию по широкому кругу тем. Материалы, которые раньше печатались, все чаще публикуются в Интернете.
На этом сайте представлена общая информация о деятельности программы, информация для исследователей, которые заинтересованы в использовании веб-архивов, а также информация для владельцев сайтов, которые могут быть включены в архивы.
Для исследователей
Интернет-архивы Библиотеки Конгресса организованы в виде тематических коллекций и коллекций, основанных на событиях, и содержат веб-сайты, документирующие различные U.С. и международные организации, представляющие широкий круг предметов и тематических областей. Примеры включают избранные правительственные сайты США из органов законодательной, судебной и исполнительной власти; выбрать зарубежные правительственные сайты; веб-сайты кампаний и политических партий, документирующие выборы в США и отдельных странах; некоммерческие организации; журналистика и новости; творческие сайты, например, документирующие комиксы, музыку, авторов и искусство; юридические сайты; и международные организации. Хотя большинство веб-архивов собирается как часть одного или нескольких тематических архивов или архивов событий, Библиотека также сохраняет другие сайты в своих общих веб-архивах.
Хотя большинство веб-архивов собирается как часть одного или нескольких тематических архивов или архивов событий, Библиотека также сохраняет другие сайты в своих общих веб-архивах.
Для исследователей
Для владельцев сайтов
Библиотека уведомляет каждого владельца сайта о том, что мы хотели бы включить их контент в архив (за исключением государственных веб-сайтов) перед архивированием. В некоторых случаях в электронном письме запрашивается разрешение на архивирование или предоставление доступа исследователям извне.
Для владельцев сайтов
Веб-архивы
Просмотр веб-архивов по тематике коллекции.Дополнительные веб-архивы можно найти, посетив Search Web Archives.
Интернет-архивы
В сети: The Wayback Machine: Архив Интернета
Сейчас что Интернет создан в публичном информационном пространстве, стать новым средством публикации.
 Интернет, в частности, оказался невероятным
хранилище всех видов информационного контента. Но это также доказало
быть очень изменчивой средой, заметно лишенной постоянства.Особенно
за последние пару лет, поскольку количество сбоев новых интернет-компаний
выросла, ранее существующие веб-сайты прекратили работу, а их
информационный контент ушел в прошлое Интернета.
Интернет, в частности, оказался невероятным
хранилище всех видов информационного контента. Но это также доказало
быть очень изменчивой средой, заметно лишенной постоянства.Особенно
за последние пару лет, поскольку количество сбоев новых интернет-компаний
выросла, ранее существующие веб-сайты прекратили работу, а их
информационный контент ушел в прошлое Интернета.С печатными публикациями, библиотеки и архивы мира приложили немало усилий, чтобы собрать и сохраните элементы печати. Но появление Интернета было настолько внезапным и созданным совершенно новый набор задач для каталогизации, хранения и поиска, что несколько библиотек активно собирают копии веб-страниц.Пока библиотека профессия усердно работала над поиском решений доступной стороны проблемы, веб-страницы были созданы, изменены и умерли без записи этих страниц сохраняются.
К счастью, Брюстер
Alexa Internet компании Kahle и ее дочерняя компания Internet Archive
проделана огромная коллекторская работа. Начиная с 1996 г., Интернет
Архив хранит веб-страницы, включая графические файлы, из общедоступных
доступные веб-сайты, просканированные Alexa.С запуском в октябре 2001 г.
Wayback Machine, этот огромный архив теперь находится в свободном доступе для
Интернет-публикация.
Начиная с 1996 г., Интернет
Архив хранит веб-страницы, включая графические файлы, из общедоступных
доступные веб-сайты, просканированные Alexa.С запуском в октябре 2001 г.
Wayback Machine, этот огромный архив теперь находится в свободном доступе для
Интернет-публикация.
НАЗАД ДЕЛАЕТ
Машина обратного пути — это интерфейс к коллекции общедоступных веб-страниц Интернет-архива. Включает в себя более 100 терабайт данных — огромная коллекция с огромными требования к хранению. Wayback Machine открывает доступ к этому богатству данных по URL.Это не поиск по тексту, пользователь должен знать точную URL-адрес конкретной веб-страницы или, по крайней мере, веб-сайта, чтобы иметь возможность войти архив.
При входе в
Адрес в Интернете, Wayback Machine представляет список дат с указанием
когда эта конкретная страница была заархивирована. Проверка на домашней странице для
Библиотека Конгресса находит заархивированные страницы с 9 ноября 1996 г. вчерашний день. В 1996, 1997, 1998 и 1999 годах страниц намного меньше.
архивы.В 2001 году был экземпляр почти через день.
вчерашний день. В 1996, 1997, 1998 и 1999 годах страниц намного меньше.
архивы.В 2001 году был экземпляр почти через день.
Щелкните по одному из отображаемые даты, чтобы увидеть заархивированную страницу. Звездочка после некоторых из даты используются для обозначения того, когда Интернет-архив обнаружил изменение на странице. Так что, по-видимому, все эти объявления без звездочки должны быть точно таким же, как первая перед ними страница, отмеченная звездочкой.
Обратите внимание, что URL для заархивированной страницы начинается с web.archive.орг. В отличие от кешированных файлов в Google Wayback Machine также включает в себя большинство файлов изображений в архиве. Таким образом, изображения берутся не с текущего сервера, а с Интернет-архив. Это означает, что на заархивированной странице будет отображаться гораздо точнее, как страница появилась в этот конкретный день.
Кроме того, все
ссылки на заархивированной странице указывают не на исходное место ссылки,
но на другие страницы Интернет-архива. Итак, пока Wayback Machine
недоступен для поиска, его можно просматривать. Найдите заархивированную страницу 1997 года,
щелкните любую ссылку на этой странице, и Wayback Machine примет
вы перейдете к ближайшему (по дате) архиву доступной страницы. В
таким образом, пользователь может просматривать веб-сайт в том виде, в каком он появился в определенном
временной период.
Итак, пока Wayback Machine
недоступен для поиска, его можно просматривать. Найдите заархивированную страницу 1997 года,
щелкните любую ссылку на этой странице, и Wayback Machine примет
вы перейдете к ближайшему (по дате) архиву доступной страницы. В
таким образом, пользователь может просматривать веб-сайт в том виде, в каком он появился в определенном
временной период.
Расположение
сам Wayback Machine переместился между несколькими URL-адресами во время
первые несколько месяцев. Оба http: // web.archive.com и http://archive.alexa.com работали раньше, но на данный момент все они перенаправляют на www.archive.org ,
дом самого Интернет-архива.
ПОЧЕМУ НАЗАД
Есть много
использует для невероятного архива от Wayback Machine. На очень простом
уровне, это отличный источник для поиска информации на страницах, когда страница
или сам хост недоступен.Когда вы сталкиваетесь с ошибкой «404 не найден» или
аналогичное сообщение в Интернете, просто проверьте на Wayback Machine, чтобы найти
копия страницы в том виде, в котором она выглядела раньше. Кеш Google был единственным
вариант для этой функции, но кешированные страницы ограничены отсутствием
любой записи о дате, когда они были кэшированы. Машина Wayback делает
это намного проще, если четко указать дату, когда страница была заархивирована.
Кеш Google был единственным
вариант для этой функции, но кешированные страницы ограничены отсутствием
любой записи о дате, когда они были кэшированы. Машина Wayback делает
это намного проще, если четко указать дату, когда страница была заархивирована.
Исторический Последствия использования Wayback Machine огромны.Исторические исследователи теперь могут просматривать значительные части Интернета, существовавшие в разное время с 1996 г. по настоящее время. Исторические преимущества выходят далеко за рамки чисто историческое исследование. Специалисты по поиску патентов могут проверить уровень техники. Бизнес эксперты могут найти бизнес-планы несостоявшихся компаний. Работодатели могут расследовать студенческие веб-страницы соискателей вакансий. Источники потеряны из-за сложного URL переключение можно найти по их старому URL-адресу на Wayback Machine.
Возможность
просматривать диапазон версий конкретной страницы и просматривать заархивированные
сам сайт предлагает множество вариантов использования. Новый веб-дизайнер может посмотреть предыдущие
воплощения сайта, даже если сама организация никогда не архивировала
различные версии. Новый бизнес может взглянуть на своих конкурентов раньше
конструкции и избежать тех же ошибок. И исследователь, который пытается
отследить онлайн-ресурсы из библиографии четырехлетнего ребенка
бумага может найти их в архиве, даже если они иным образом исчезли
из текущего Интернета.
Новый веб-дизайнер может посмотреть предыдущие
воплощения сайта, даже если сама организация никогда не архивировала
различные версии. Новый бизнес может взглянуть на своих конкурентов раньше
конструкции и избежать тех же ошибок. И исследователь, который пытается
отследить онлайн-ресурсы из библиографии четырехлетнего ребенка
бумага может найти их в архиве, даже если они иным образом исчезли
из текущего Интернета.
Для учреждений,
Интернет-архив приветствует совместные усилия по созданию специальных тематических
коллекции.Уже доступны три коллекции: The September
11, сборник 2001 г., Web Pioneers и Election 2000. Как другие специальные сборники
созданы, они могут быть особенно полезны для более глубокого исследования
по этим темам.
РАСШИРЕННАЯ ФОРМА
Базовый доступ к
архив находится по одному URL-адресу, но Wayback Machine также имеет расширенный
форма поиска. На него нет ссылок на главной странице, но он доступен как
ссылку мелким шрифтом в верхней части формы поиска, которая появляется с
результаты после ввода поиска. Посмотрите вправо от «Take
Me Back »на страницах из архива Библиотеки Конгресса США.
также напрямую доступен (http://web.archive.org/collections/web/advanced.html) .
Посмотрите вправо от «Take
Me Back »на страницах из архива Библиотеки Конгресса США.
также напрямую доступен (http://web.archive.org/collections/web/advanced.html) .
Пока есть все еще нет возможности текстового поиска в форме расширенного поиска, предлагает ряд вариантов помимо простого поля на домашней странице. Например, расширенная форма позволяет использовать два типа URL Matching «Получить страницу, наиболее точно соответствует критериям поиска »и« Перечислить все страницы, соответствующие поиску. критерии.»Последний вариант используется по умолчанию в простой форме и вызывает список совпадений дат. Первый вариант ведет пользователя непосредственно к наиболее последняя копия заархивированной страницы.
Расширенный поиск
форма также дает возможность ограничить результаты определенным диапазоном дат.
У отдельных заархивированных страниц есть URL-адреса, на которые можно напрямую ссылаться.
На странице расширенного поиска также объясняется синтаксис. Например, URL
web.archive.org/20011230221317/http:// www.site.net будет www. site.net
страничный архив 30 декабря 2001 г., 22:13. и 17 секунд. В другом
слова, длинный список чисел после части archive.org представляет
год, месяц, день, час, минута и секунда, когда страница была заархивирована в
форма ГГГГММДДччммсс.
Например, URL
web.archive.org/20011230221317/http:// www.site.net будет www. site.net
страничный архив 30 декабря 2001 г., 22:13. и 17 секунд. В другом
слова, длинный список чисел после части archive.org представляет
год, месяц, день, час, минута и секунда, когда страница была заархивирована в
форма ГГГГММДДччммсс.
В дополнение к
скриптовые ограничения даты, доступные в расширенной форме, звездочка может
также использоваться как символ усечения в URL-адресе. Итак, http: //web.archive.org / 200112 * / http: //www.site.net получит список всех заархивированных страниц с декабря 2001 года.
со звездочки, и Wayback Machine автоматически найдет
страница, ближайшая к середине месяца. Символ усечения также может
использоваться для поиска всех страниц сайта за определенную дату. В другом
слов, web.archive.org/1997*/http://www.site.net* находит все
URL сайтов (страниц и изображений) в архиве с 1997 года.
ФОРМАТЫ ФАЙЛОВ И НИКНЕЙМЫ
Расширенный поиск
форма также указывает на то, что Wayback Machine обеспечивает доступ к более чем
просто веб-страницы. Ограничение типов файлов включает шесть форматов: изображения, аудио,
Видео, двоичный, текстовый и PDF. Выбрав один из этих типов файлов, а затем
вводя только корневой URL (с полным именем хоста), результаты будут
включить все типы файлов этого формата с этого хоста в архив.
Каждая запись отдельного типа файла имеет уникальный URL-адрес, но если поисковик
не знает полный URL, это ограничение помогает их идентифицировать. Кроме того,
его можно использовать как инструмент для подсчета количества файлов определенного типа на
конкретный сервер.
Ограничение типов файлов включает шесть форматов: изображения, аудио,
Видео, двоичный, текстовый и PDF. Выбрав один из этих типов файлов, а затем
вводя только корневой URL (с полным именем хоста), результаты будут
включить все типы файлов этого формата с этого хоста в архив.
Каждая запись отдельного типа файла имеет уникальный URL-адрес, но если поисковик
не знает полный URL, это ограничение помогает их идентифицировать. Кроме того,
его можно использовать как инструмент для подсчета количества файлов определенного типа на
конкретный сервер.
Псевдонимы
еще одна приятная функция по расширенному поиску. Многие веб-сайты имеют несколько
способы написания URL-адреса, который приведет к одной и той же странице, особенно
на главной странице. Раздел «Псевдонимы» расширенного поиска дает три
опции. По умолчанию все псевдонимы имен хостов группируются вместе, для большей части
всесторонний поиск. Однако есть второй вариант «Показать псевдонимы отдельно»
даст точные совпадения только для URL, введенного со списком
другие псевдонимы, в то время как «Не показывать псевдонимы» будут давать только точные совпадения.
ОГРАНИЧЕНИЯ
Признавая значительным достижением Wayback Machine, у него есть ограничения. Даже со 100 терабайтами данных многого не хватает. Интернет-архив включает лишь небольшое количество материалов за 1996 год, и Интернет определенно предшествует этому. Кроме того, более старый контент суслика и другие файлы, не относящиеся к Интернету, недоступны.
Более значительные являются организованными исключениями.Кто угодно может исключить свои страницы с помощью использование роботов. txt на своем сервере. Если Интернет-архив включает ваши веб-страницы, и вы хотите, чтобы они были исключены, просто добавьте файл robots.txt в исключить их поискового робота. При следующем сканировании страницы все старые страницы в архиве также будут исключены. См. Www.archive.org/internet/remove. html для более подробной информации.
К сожалению,
слишком много сайтов имеют файл robots.txt, исключая сканирование или архивирование. По крайней мере, когда пользователь запрашивает страницу, которая была исключена из-за файла robots.txt.
файла, Wayback Machine объясняет, почему страница была
исключено и ссылается на архивную копию файла robots.txt сайта.
По крайней мере, когда пользователь запрашивает страницу, которая была исключена из-за файла robots.txt.
файла, Wayback Machine объясняет, почему страница была
исключено и ссылается на архивную копию файла robots.txt сайта.
Процесс архивирования есть некоторые проблемы. Большинство изображений заархивированы, но некоторые по-прежнему указывают на исходный источник и, таким образом, могут оказаться мертвыми ссылками или измененным изображением файлы. Другие изображения или объекты на веб-странице, особенно при высокой посещаемости сайты, могут быть связаны с версией сетевого кэширования с URL-адресом на Akamai хост, например.Таким образом, некоторые изображения на некоторых страницах будут отсутствовать.
И обратный путь не будет
Машина всегда будет в наличии. После первого запуска часто появлялось сообщение
заявляя, что из-за «большего, чем ожидалось, количества запросов» Wayback
Машина вышла из строя. В других случаях вы можете встретить «Этот Интернет-архив
сайт в настоящее время закрыт на техническое обслуживание ».
Учитывая огромную размер архива, еще одна проблема — долгосрочная финансовая жизнеспособность машины Wayback.Кроме кнопки Amazon для пожертвований, есть на сайте нет рекламы, и Alexa не поддерживает это финансово. Согласно Брюстеру Кале, частному сбору средств, фондам и грантам в настоящее время поддержите это. Кале говорит, что у них «достаточно, чтобы поддерживать Wayback Machine, но этот рост будет зависеть от финансовой поддержки через совместные проекты ».
Кале должна быть хвалили за попытки поддержать Wayback Machine, больше похожую на традиционную библиотека или архив, в отличие от типичного коммерческого веб-проекта.В на главной странице перечислены несколько доноров, включая AT&T Research, Compaq, Prelinger Архивы, QuantumDLT и Xerox PARC. В конце концов, Кале надеется, что Интернет Архив может «обеспечить всеобщий доступ к человеческим знаниям. Это наша цель в жизни.»
Замечательный
и достойная цель. И хотя Wayback Machine имеет много ограничений и
исключает огромное количество как онлайн, так и печатных знаний, это, безусловно,
важный шаг вперед в обеспечении доступа к большой части этих знаний
который находится во всемирной паутине.
Грег Р. Нотесс ( [email protected] ; www.notess.com/ ) является справочным библиотекарем в Государственном университете Монтаны и основателем SearchEngineShowdown.com .
Комментарии? Электронное письмо редактор: [email protected] .
Веб-архивирование | Стэнфордские библиотеки
Интернет стал исключительно важным средством коммуникации для обучения, социальной истории и культурного наследия.Однако уникальная и ценная информация находится под угрозой, поскольку контент в Интернете постоянно обновляется, заменяется или теряется.
Примеры таких материалов, подверженных риску, включают: веб-сайты предвыборных кампаний политических кандидатов, которые действуют только на время сезона выборов; веб-сайты проектов, финансируемых за счет грантов, ценность которых для стипендий сохраняется и после периода финансирования; диссидентские политические выступления, подлежащие государственной цензуре; онлайн-новости, связанные с быстрыми событиями, которые быстро исправляются и скрываются; присутствие в сети осиротевших важных, умерших персонажей; и больше. Обеспечение постоянной возможности доступа к веб-контенту, который исчез или был перезаписан, необходимо для таких разнообразных целей, как исследования, обучение, создание библиотечных фондов, институциональное наследие, соблюдение правовых норм и управление правительственной информацией.
Обеспечение постоянной возможности доступа к веб-контенту, который исчез или был перезаписан, необходимо для таких разнообразных целей, как исследования, обучение, создание библиотечных фондов, институциональное наследие, соблюдение правовых норм и управление правительственной информацией.
Осознавая эти потребности, мы создаем службу веб-архивирования для поддержки сбора, сохранения и предоставления доступа к уязвимому веб-контенту. Эти усилия основаны на нашем опыте текущих проектов веб-архивирования и основаны на внутреннем обзоре примеров использования 2011 года, откликах заинтересованных сторон Стэнфордского университета и на развивающихся передовых методах национальных и международных сообществ веб-архивирования, и они основаны на стандартных форматах данных и технологии с открытым исходным кодом.
Мы будем определять ценный веб-контент в сотрудничестве с библиотекарями, преподавателями, исследователями и другими сотрудниками Стэнфордского университета. Мы будем хранить веб-архивы в Стэнфордском цифровом репозитории, обеспечивать обнаружение через SearchWorks и разрешать просмотр через локальный экземпляр платформы воспроизведения веб-архивов Wayback. Мы рассмотрим дополнительные услуги и стратегии доступа к собранному контенту, уделяя особое внимание использованию в исследованиях.
Мы рассмотрим дополнительные услуги и стратегии доступа к собранному контенту, уделяя особое внимание использованию в исследованиях.
Пожалуйста, свяжитесь с нами с отзывами, вопросами или рекомендациями, касающимися разработки услуг, пробного сканирования или консультативной поддержки для проектов веб-архивирования.
iipc / awesome-web-archiving: отличный список для начала работы с веб-архивированием
GitHub — iipc / awesome-web-archiving: отличный список для начала работы с веб-архивированиемОтличный список для начала работы с веб-архивированием
Файлы
Постоянная ссылка Не удалось загрузить последнюю информацию о фиксации.Тип
Имя
Последнее сообщение фиксации
Время фиксации
Архивирование Web — это процесс сбора частей Всемирной паутины для обеспечения сохранения информации в архиве для будущих исследователей, историков и общественности. Веб-архивисты обычно используют веб-сканеры для автоматического захвата из-за огромного масштаба Интернета.Постоянно развивающиеся веб-стандарты требуют непрерывной эволюции инструментов архивирования, чтобы идти в ногу с изменениями в веб-технологиях, чтобы гарантировать надежный и значимый захват и воспроизведение заархивированных веб-страниц.
Веб-архивисты обычно используют веб-сканеры для автоматического захвата из-за огромного масштаба Интернета.Постоянно развивающиеся веб-стандарты требуют непрерывной эволюции инструментов архивирования, чтобы идти в ногу с изменениями в веб-технологиях, чтобы гарантировать надежный и значимый захват и воспроизведение заархивированных веб-страниц.
Содержание
Обучение / документация
- Введение в концепции веб-архивирования:
- Стандарт WARC:
- Для исследователей, использующих веб-архивы:
Ресурсы для веб-издателей
Эти ресурсы могут помочь при работе с отдельными лицами или организациями, которые публикуют в Интернете и хотят быть уверены, что их сайт можно заархивировать.
Инструменты и программное обеспечение
Этот список инструментов и программного обеспечения предназначен для краткого описания некоторых из наиболее важных и широко используемых инструментов, связанных с веб-архивированием. Для получения дополнительной информации мы рекомендуем вам обратиться (и внести свой вклад!) В эти отличные ресурсы от других групп:
Для получения дополнительной информации мы рекомендуем вам обратиться (и внести свой вклад!) В эти отличные ресурсы от других групп:
Приобретение
- 22120 — Инструмент, не основанный на WARC, который подключается к браузеру Chrome и архивирует все, что вы просматриваете, делая его доступным для автономного воспроизведения. (в разработке)
- ArchiveBox — инструмент, который поддерживает дополнительный архив из RSS-каналов, закладок и ссылок с помощью wget, chrome headless и других методов (ранее
Bookmark Archiver). (в разработке) - archivenow — библиотека Python для передачи веб-ресурсов в веб-архивы по запросу. (стабильный)
- Brozzler — распределенный веб-сканер (爬虫), который использует настоящий браузер (хром или хром) для получения страниц и встроенных URL-адресов и для извлечения ссылок. (стабильный)
- Cairn — Пакет npm и инструмент командной строки для сохранения веб-страниц. (стабильный)
- Chronicler — Веб-браузер с функцией записи и воспроизведения. (в разработке)
- Crawl — простой поисковый робот на Golang. (стабильный)
- crocoite — сканирование веб-сайтов с использованием безголового Google Chrome / Chromium и сохранение ресурсов, статических снимков DOM и скриншотов страниц в файлы WARC. (в разработке)
- F (b) arc — Инструмент командной строки и библиотека Python для архивирования данных из Facebook с использованием Graph API. (стабильный)
- freeze-dry — библиотека JavaScript для преобразования страницы в статический автономный HTML-документ; полезно для расширений браузера. (в разработке)
- grab-site — поисковый робот архивариуса: вывод WARC, информационная панель для всех обходов, шаблоны динамического игнорирования. (стабильный)
- Heritrix — Расширяемый веб-сканер с открытым исходным кодом и качеством архивирования. (стабильный)
- html2warc — простой скрипт для преобразования автономных данных в один файл WARC. (стабильный)
- HTTrack — Утилита для копирования веб-сайтов с открытым исходным кодом. (стабильный)
- monolith — инструмент командной строки для сохранения веб-страницы в виде единого файла HTML. (стабильный)
- Obelisk — пакет Go и инструмент командной строки для сохранения веб-страницы в виде одного файла HTML. (стабильный)
- SingleFile — расширение браузера для Firefox / Chrome и инструмент командной строки для сохранения точной копии полной страницы в виде единого файла HTML. (стабильный)
- SiteStory — архив транзакций, который выборочно фиксирует и сохраняет транзакции, происходящие между веб-клиентом (браузером) и веб-сервером. (стабильный)
- Social Feed Manager — программное обеспечение с открытым исходным кодом, которое позволяет пользователям создавать коллекции социальных сетей с помощью общедоступных API-интерфейсов Twitter, Tumblr, Flickr и Sina Weibo. (стабильный)
- Squidwarc — поисковый робот с открытым исходным кодом, высококачественный, взаимодействующий со страницами, который напрямую использует Chrome или Chrome Headless. (в разработке)
- StormCrawler — набор ресурсов для создания масштабируемых веб-сканеров с малой задержкой на Apache Storm. (стабильный)
- twarc — инструмент командной строки и библиотека Python для архивирования данных Twitter JSON. (стабильный)
- WARCreate — расширение Google Chrome для архивирования отдельной веб-страницы или веб-сайта в файл WARC. (стабильный)
- Warcworker — Открытый исходный код, dockerized, очередной, высококачественный веб-архиватор на основе Squidwarc с простым веб-интерфейсом. (стабильный)
- WAIL — графический пользовательский интерфейс (GUI) поверх нескольких инструментов веб-архивирования, предназначенный для использования в качестве простого способа для всех сохранять и воспроизводить веб-страницы; Python, электрон. (стабильный)
- Web2Warc — простой в использовании и настраиваемый поисковый робот, который позволяет любому создавать свои собственные небольшие веб-архивы (WARC / CDX). (стабильный)
- WebMemex — расширение браузера для Firefox и Chrome, которое позволяет архивировать посещаемые веб-страницы. (в разработке)
- Webrecorder — Создавайте высококачественные интерактивные записи любого веб-сайта, который вы просматриваете. (стабильный)
- Wget — Утилита для поиска файлов с открытым исходным кодом, версия 1.14 поддерживает запись варков. (стабильный)
- Wget-lua — Wget с расширением Lua. (стабильный)
- Wpull — Wget-совместимый (или переделанный / клонированный / заменяющий / альтернативный) веб-загрузчик и поисковый робот. (стабильный)
 (стабильный)
(стабильный)  (стабильный)
(стабильный)  (стабильный)
(стабильный)  (стабильный)
(стабильный) Повтор
- Межпланетный путь назад (ipwb) — индексирование и воспроизведение веб-архива (WARC) с использованием IPFS.
- OpenWayback — проект с открытым исходным кодом, направленный на разработку Wayback Machine, ключевого программного обеспечения, используемого веб-архивами по всему миру для воспроизведения заархивированных веб-сайтов в браузере пользователя. (стабильный)
- PyWb — Python (2 и 3) реализация инструментов воспроизведения веб-архивов, иногда также известных как «Wayback Machine». (стабильный)
- Reconstructive — Reconstructive — это модуль ServiceWorker для реконструкции составных сувениров на стороне клиента путем перенаправления запросов ресурсов на соответствующие архивные копии (JavaScript).
- ReplayWeb.Page — основанный на браузере, полностью клиентский механизм воспроизведения для локальных и удаленных файлов WARC.

Поиск и обнаружение
- Mink — Расширение Google Chrome для запросов к агрегаторам Memento при просмотре и интеграции веб-навигации в реальном времени с архивом. (стабильный)
- SecurityTrails — Интернет-архив для записей WHOIS и DNS. REST API доступен бесплатно.
- Tempas v1 — Временный поиск в веб-архиве на основе тегов Delicious. (стабильный)
- Tempas v2 — поиск по временному веб-архиву на основе ссылок и якорных текстов, извлеченных из немецкой сети с 1996 по 2013 год (результаты не ограничиваются немецкими страницами, например, Obama @ 2005-2009 в Tempas). (стабильный)
- webarchive-discovery — инструменты полнотекстового индексирования и обнаружения WARC и ARC с рядом связанных инструментов, способных использовать показанный ниже индекс. (стабильный)
- Shine — прототип пользовательского интерфейса для исследования веб-архивов, разработанный совместно с исследователями в рамках проекта Big UK Domain Data for the Arts and Humanities. (стабильный)
- SolrWayback — прототип пользовательского интерфейса для исследования веб-архивов со встроенной функцией воспроизведения файлов WARC. (в разработке)
- Warclight — движок Rails на основе Project Blacklight, который поддерживает обнаружение веб-архивов, хранящихся в форматах WARC и ARC. (в разработке)
- Wasp — Полнофункциональный прототип личного веб-архива и поисковой системы. (в разработке)
- Другие возможные варианты создания внешнего интерфейса перечислены в вики
webarchive-discovery, здесь.
 REST API доступен бесплатно.
REST API доступен бесплатно. (в разработке)
(в разработке) Коммунальные услуги
- ArchiveTools — Набор инструментов для извлечения файлов WARC и взаимодействия с ними (Python).
- har2warc — Преобразование HTTP-архива (HAR) в формат веб-архива (WARC) (Python).
- httpreserve.info — Сервис для возврата статуса веб-страницы или сохранения его в Интернет-архиве. Возвращает JSON через браузер или командную строку через CURL, используя GET (пакет Golang). (стабильный)
- HTTPreserve Workbench — Инструмент и API для описания состояния веб-страницы, закодированного в виде простого вывода JSON, описывающего текущий статус, а также самые ранние и последние ссылки на обратном пути.орг. Сохраните веб-страницу в Интернет-архиве. Просмотрите списки URI и выведите CSV с данными, описанными выше (Golang). (в разработке)
- MementoMap — инструмент для обобщения данных веб-архивов (Python). (в разработке)
- MemGator — интерфейс и сервер агрегатора Memento (Golang). (стабильный)
- node-cdxj — парсер файлов CDXJ (Node.js). (стабильный)
- OutbackCDX — сервер индекса захвата (CDX) на основе RocksDB, поддерживающий инкрементные обновления и сжатие.Может использоваться как бэкэнд для OpenWayback, PyWb и Heritrix. (стабильный)
- py-wasapi-client — Приложение командной строки для загрузки обходов из WASAPI (Python). (стабильный)
- Обозреватель архивов. Обозреватель архивов — это программа, которая позволяет просматривать содержимое архивов, а также извлекать их. Это позволит вам открывать файлы из архивов и просматривать их с помощью Quick Look. Поддерживается WARC (только для macOS, проприетарное приложение).
- The Unarchiver — Программа для извлечения содержимого многих архивных форматов, включая WARC, в файловую систему.Бесплатная версия Archive Browser (только для macOS, проприетарное приложение).
- tikalinkextract — Извлекает гиперссылки в качестве начального числа для веб-архивирования из папок типов документов, которые могут быть проанализированы Apache Tika (Golang, Apache Tika Server). (в разработке)
- wasapi-downloader — приложение командной строки Java для загрузки обходов из WASAPI. (стабильный)
- WarcPartitioner — Разделение (W) файлов ARC по типу MIME и году. (стабильный)
- webarchive-indexing — Инструменты для массового индексирования файлов WARC / ARC в Hadoop, EMR или локальной файловой системе.
- wikiteam — Инструменты для загрузки и сохранения вики. (стабильный)
 Просмотрите списки URI и выведите CSV с данными, описанными выше (Golang). (в разработке)
Просмотрите списки URI и выведите CSV с данными, описанными выше (Golang). (в разработке) 
Библиотеки ввода-вывода WARC
- HadoopConcatGz — разделяемый формат ввода Hadoop для составных файлов GZIP (и
* .). (стабильный) warc.gz - jwarc — чтение и запись файлов WARC с помощью API безопасного типа (Java).
- Jwat — Библиотеки и инструменты для чтения / записи / проверки файлов WARC / ARC / GZIP (Java). (стабильный)
- node-warc — анализируйте файлы WARC или создавайте файлы WARC с помощью Electron или chrome-remote-interface (Node.js). (стабильный)
- Warcat — Инструмент и библиотека для работы с файлами Web ARChive (WARC) (Python). (стабильный)
- warcio — Потоковая библиотека WARC / ARC для быстрого ввода-вывода веб-архива (Python).
- warctools — Библиотека для работы с файлами ARC и WARC (Python).
- webarchive — программы чтения Golang для форматов веб-архивов ARC и WARC (Golang).
 warc.gz
warc.gz Анализ
- ArchiveSpark — фреймворк Apache Spark (не только) для веб-архивов, который позволяет легко обрабатывать, извлекать и извлекать данные. (стабильный)
- Archives Unleashed Cloud — Archives Unleashed Cloud (AUK) — это веб-интерфейс для анализа веб-архивов. В настоящее время он может синхронизироваться с коллекциями Archive-It и извлекать сети гиперссылок, полный текст и другую информацию из ваших коллекций. (стабильный)
- Archives Unleashed Notebooks — Блокноты для работы с веб-архивами с помощью Archives Unleashed Toolkit и производных, созданных Archives Unleashed Toolkit. (стабильный)
- Archives Unleashed Toolkit — Archives Unleashed Toolkit (AUT) — это платформа с открытым исходным кодом для анализа веб-архивов с помощью Apache Spark. (стабильный)
- Tweet Archvies Unleashed Toolkit — набор инструментов с открытым исходным кодом для анализа строчно-ориентированных архивов JSON Twitter с помощью Apache Spark. (в разработке)
 В настоящее время он может синхронизироваться с коллекциями Archive-It и извлекать сети гиперссылок, полный текст и другую информацию из ваших коллекций. (стабильный)
В настоящее время он может синхронизироваться с коллекциями Archive-It и извлекать сети гиперссылок, полный текст и другую информацию из ваших коллекций. (стабильный) Гарантия качества
Ресурсы сообщества
Другие замечательные списки
Блоги и стипендии
Списки рассылки
Слабина
Твиттер
Около
Отличный список для начала работы с веб-архивированием
Темы
ресурса
Лицензия
Вы не можете выполнить это действие в настоящее время. Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.
Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.euwebarchive — Веб-инструменты — Бюро публикаций ЕС
Все больше и больше информации о ЕС публикуется только в Интернете. Однако веб-контент часто имеет короткую продолжительность жизни, и веб-технологии быстро развиваются. Таким образом, эта информация может быть потеряна, например когда веб-сайты существенно изменены или отключены.Веб-архивирование — это процесс сбора веб-сайтов для обеспечения сохранения информации в архиве для будущих исследователей, историков и общественности.
Бюро публикаций Европейского Союза выполняет веб-архивирование для сохранения веб-сайтов учреждений, агентств и органов ЕС . Архивные материалы хранятся в веб-архиве ЕС, открыты и доступны в Интернете, к которому могут получить доступ представители общественности онлайн
Этот архив отражает содержание и дизайн веб-сайтов, какими они были в данный момент времени. Благодаря этому информационные учреждения, представленные на их сайтах, остаются доступными, даже если исходный сайт или страница полностью или частично исчезли
Благодаря этому информационные учреждения, представленные на их сайтах, остаются доступными, даже если исходный сайт или страница полностью или частично исчезли
Веб-архивирование в Европейском Союзе началось в 2013 году. С тех пор мы архивируем веб-сайты ЕС и постоянно добавляем новые веб-сайты в коллекцию.
Мы регулярно архивируем веб-сайты учреждений ЕС, большинство из которых размещены в домене и субдоменах europa.eu и архивируются на регулярной основе.
Исключительно мы создаем коллекции архивов веб-сайтов, связанных с деятельностью Европейского Союза (e.грамм. сайты председателей Совета ЕС, публикации ЕС и др.).
Специальное сканирование веб-сайтов, которые будут отключены или существенно изменятся, может выполняться по запросу соответствующего учреждения ЕС. Например, мы можем архивировать страницы, созданные для определенных событий.
Из архива исключено следующее содержимое:
- Внешние сайты.
- Базы данных.
- Динамический контент.
- Социальные сети.
- Сайты, защищенные паролем.
- Потоковое и загружаемое мультимедиа.
Мы фиксируем только веб-контент, который находится в свободном доступе в открытом доступе.
Чтобы оптимизировать качество архивных версий вашего веб-сайта, важно создавать сохраняемые веб-сайты. Более подробную информацию вы найдете в этих правилах .
Для получения дополнительной информации о веб-сайтах Европейской комиссии см. Europa Web Guide .
Вы должны удалить контент, который не должен сохраняться (и быть доступным) в долгосрочной перспективе.Это может быть связано с такими причинами, как права интеллектуальной собственности (например, авторское право), конфиденциальность, конфиденциальность, защита данных и т. Д. Если это содержимое не может быть удалено перед архивированием, воспрепятствуйте его сканированию с помощью файлов robot.txt.
Существуют законные обстоятельства, когда может потребоваться скрыть страницы в веб-архиве от публичного просмотра.
Любой желающий может отправить мотивированный запрос на удаление. Воспользуйтесь этой ссылкой электронной почты, чтобы инициировать его: op-web-preservation @ публикации.europa.eu.
Удалениебудет рассматриваться только в одном из следующих случаев:
- , если страница содержит один из следующих типов содержимого:
- личная или конфиденциальная личная информация, как определено Регламентом (ЕС) 2018/1725 о защите физических лиц в отношении обработки личных данных учреждениями, органами, офисами и агентствами Союза;
- материалов, защищенных авторским правом, на которые не закреплены необходимые права;
- клеветнических или непристойных материалов или сообщений;
- , если содержание страницы может вызвать серьезные и реальные административные трудности у владельца сайта;
- , если страница была опубликована добросовестно, но обстоятельства для этого изменились, и ее удаление теперь считается целесообразным;
- , если страница была опубликована по ошибке и ее удаление необходимо для исправления этой ошибки.
Авторские права
© Европейский Союз, 2019
Отдел публикаций осуществляет веб-архивирование для сохранения веб-сайтов Европейского Союза. Большая часть заархивированного контента веб-сайтов, доступного в веб-архиве ЕС (EUWA), находится под авторским правом ЕС (или учреждений, агентств или органов ЕС). Право собственности и авторские права на веб-сайты в EUWA остаются ответственностью владельцев веб-сайтов.
Если не указано иное, материалы, полученные от EUWA, могут свободно воспроизводиться.Этот общий принцип может регулироваться условиями, которые могут быть указаны в отдельных уведомлениях об авторских правах. Это не распространяется на фотографии, видео, музыкальные произведения или другие материалы, на которые распространяются права интеллектуальной собственности третьих лиц (не входящих в ЕС). В таких случаях разрешение на использование материала следует запрашивать непосредственно у правообладателей. Офис публикаций не гарантирует, что весь сторонний контент соответствующим образом помечен.
Все логотипы и торговые марки исключены из вышеупомянутого разрешения.
Любые вопросы относительно вышеизложенного следует направлять по следующему адресу электронной почты [email protected]
Заявление о конфиденциальности
Свяжитесь с командой веб-архивирования: [email protected]
веб-архивов FAQ | Библиотеки GW
Как выбираются веб-сайты?
Специалисты-предметники и кураторы веб-коллекций в библиотеках Университета Джорджа Вашингтона выбирают веб-сайты для архивирования. Критерии отбора включают соответствие веб-сайта инициативам по развитию библиотечной коллекции, текущим исследованиям и обучению, предполагаемому риску исчезновения веб-сайта и вероятности того, что веб-сайт не будет заархивирован или сохранен другими способами.Веб-сайты, связанные с Университетом Джорджа Вашингтона и организациями, чьи бумажные архивы хранятся в GW, будут дополнительными приоритетами для веб-архивирования.
GW и партнеры могут запрашивать снимки институциональных веб-сайтов GW и аффилированных через форму запроса на архивирование веб-сайта, связанного с GW
Какова ваша политика в отношении авторских прав в отношении архивирования веб-сайтов?
Мы следуем принципам и методам безопасного сбора урожая. Мы уважаем права других лиц на интеллектуальную собственность.Некоторые веб-сайты могут содержать материалы, созданные другими сторонами, которые могут претендовать на авторские права на такие материалы. GW оставляет за собой право удалить любой материал, который, по нашему разумному мнению, может нарушать авторские права или другие права интеллектуальной собственности. Владельцы авторских прав, включая сторонних правообладателей, которые считают, что их права были нарушены в результате включения их контента в наш архив, могут связаться с нами по адресу [email protected].
Как вы собираете и храните веб-сайты?
Мы используем веб-сканер с открытым исходным кодом Heritrix для создания архивных копий веб-сайтов. В настоящее время мы управляем Heritrix через службу Archive-It Интернет-архива. Все данные, созданные с помощью службы Archive-It, размещаются и хранятся в Интернет-архиве. Наш веб-архив доступен по адресу https://archive-it.org/organizations/825. В будущем мы также можем хранить данные в цифровом репозитории библиотек GW.
В настоящее время мы управляем Heritrix через службу Archive-It Интернет-архива. Все данные, созданные с помощью службы Archive-It, размещаются и хранятся в Интернет-архиве. Наш веб-архив доступен по адресу https://archive-it.org/organizations/825. В будущем мы также можем хранить данные в цифровом репозитории библиотек GW.
Должны ли владельцы веб-сайтов изменять или изменять веб-сайты, чтобы их можно было включить в сканирование?
Нет, владельцам веб-сайтов не нужно изменять контент, структуру или внешний вид своих веб-сайтов, чтобы их можно было включить в сканирование.
Будет ли ваше сканирование мешать доступу к нашему сайту?
Мы сканируем веб-сайты со скоростью, которая не мешает доступу к вашему веб-сайту. Сканирование активно обновляемых веб-сайтов обычно выполняется ежеквартально или раз в полгода и продолжается несколько дней. После завершения сканирования сканер больше не взаимодействует с вашим сервером. Если у вас возникнут проблемы или возникнут дополнительные вопросы, свяжитесь с нами по адресу webarchive@gwu. edu.
edu.
Умеете ли вы записывать медиа, аудио и видео файлы?
Да, загружаемые медиафайлы, аудио- и видеофайлы обычно можно захватывать, хотя видео на YouTube — это сложная задача.Наш сканер переходит по ссылкам, чтобы обнаруживать и захватывать контент, поэтому ссылки на контент должны существовать на веб-сайте, чтобы этот контент был включен в архив. Мы не можем захватывать файлы, которые не связаны и которые должны быть получены из базы данных по запросу пользователя. (Например, база данных публикаций, которая требует, чтобы один выполнял поиск для доступа к публикациям.) Потоковое аудио и видео вообще не может быть захвачено веб-сканерами текущего поколения.
Как я могу просмотреть веб-сайты, которые были заархивированы? Всегда ли доступ будет бесплатным?
Архивные веб-сайты останутся в свободном доступе для общественности.Веб-сайты можно просматривать по дате захвата через наш веб-архив, размещенный в Интернет-архиве. Персонал может изучить дополнительные способы просмотра заархивированных веб-сайтов.
Почему заархивированные версии некоторых веб-сайтов кажутся неполными?
Есть несколько причин, по которым заархивированный веб-сайт может показаться неполным. Некоторые типы контента сложно или невозможно захватить и / или воспроизвести, включая навигационные меню на основе JavaScript, потоковое аудио и видео, а также контент, управляемый динамической формой и базой данных.Мы не можем захватывать файлы, которые не связаны и которые должны быть получены из базы данных по запросу пользователя. (Например, база данных публикаций, которая требует выполнения поиска для доступа к публикациям.) Кроме того, части веб-сайта могут быть ограничены или защищены паролем. Мы будем собирать только общедоступный контент, поэтому материалы, защищенные паролем, не будут сканироваться, пока нам не будет предоставлен доступ.
Я хочу, чтобы веб-сайт моей организации был удален из веб-архива библиотек GW.С кем мне связаться?
Мы будем воздерживаться от сбора веб-сайтов, владельцы которых не желают участвовать в этом проекте, и мы будем выполнять запросы на удаление архивного содержимого. Свяжитесь с нами по адресу [email protected].
Свяжитесь с нами по адресу [email protected].
Как я могу узнать больше о вашем проекте?
Свяжитесь с нами по адресу [email protected] для получения дополнительной информации.
Источники :
Библиотеки Колумбийского университета https://library.columbia.edu/bts/web_resources_collection/faq.html
Веб-стандарт: Архив | Веб-руководство: Политики и процедуры
Определение
Архив состоит из веб-контента:
- Больше не обслуживается
- Выделено из активного собрания
- Доступно в открытом доступе для исторических или справочных целей
- Отличается баннером (страница HTML) или водяным знаком (PDF)
- Находится и доступен для поиска только в архиве.epa.gov
Требования к содержанию
- Содержимое архива идентифицируется владельцем содержимого.
- НЕ ссылайтесь напрямую на архивные материалы. Ссылка только на домашнюю страницу архива со страниц содержимого WebCMS.
- При добавлении ссылки на архивы EPA с веб-страниц активных коллекций в WebCMS используйте «Поиск в архиве EPA» (кнопка в редакторе WYSIWYG). Кнопка, добавленная на страницу, создаст ссылку на домашнюю страницу (https: // archive.epa.gov).

Содержание, которое может быть заархивировано
N или- Содержание NEPIS / NSCEP
- Контент Superfund, который входит в систему управления предприятием Superfund (SDMS / SEMS) или принадлежит к ней
- Контент, принадлежащий другим агентствам, включая GPO (Федеральный регистр) или rules.gov
- Контент, который следует исключить и удалить из коллекции активного контента, поскольку он устарел и не отражает текущую политику, решения и т. Д. EPA.Используйте избыточный, устаревший, простой (ROT) просмотр, чтобы решить, следует ли архивировать или удалять контент.
Об архивировании
- Контент для основной аудитории отсутствует в архиве. Он принадлежит к активной коллекции.
- Можно заархивировать файлы многих типов: HTML, PDF, WMV, CSV и другие. При архивировании страницы прикрепленные файлы также будут заархивированы. Ссылки непосредственно на файлы могут разорваться при архивировании.
- Ссылки на контент, который был перемещен в архив, будут повреждены.
- Процедура EPA: типы веб-контента и проверка требует, чтобы владельцы контента просматривали контент, который они заархивировали, каждые три года.
- Контент может стать ROT и быть удален по запросу в OMS (WCSD Web Team).
- Контент можно преобразовать в активный веб-контент One EPA.
- Повторяющееся содержимое должно быть удалено из архива при публикации нового содержимого EPA в активной коллекции.
- Контент может быть определен как полезный и оставаться в коллекции архива.
- Многие ссылки в архивном содержимом не работают. Уведомление в верхней части содержимого архива уведомляет клиентов о том, что содержимое не поддерживается.
- Владельцы контента могут организовать услуги через Фонд оборотных средств (WCF) TZ для ремонта неработающих ссылок или любого другого обслуживания.
 Он принадлежит к активной коллекции.
Он принадлежит к активной коллекции.
Как люди будут искать архивный контент
- Результаты архива отображаются в верхней части результатов поиска.
- При добавлении ссылки на главную страницу архива с активной домашней страницы коллекции вы можете предоставить подсказки и / или ключевые слова, которые помогут пользователям найти контент.
Об этом стандарте
Весь общедоступный веб-контент EPA должен соответствовать веб-стандартам EPA, руководящим принципам системы веб-дизайна США и Закону об интегрированном цифровом опыте 21-го века.
Первоначальная дата вступления в силу: 11.02.2015
Дата последнего утверждения: 08.04.2020
Web Council на рассмотрение: 08.04.2023 (или ранее, если Web Council сочтет это необходимым)
