как пользоваться и найти удаленный сайт
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
Webarchive — веб-архив всего интернета и сайтов или машина времени на archive.org
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Не так давно я писал про то, что такое народная энциклопедия Википедия, которая безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
Сам факт того, что некоммерческий проект уже не одно десятилетие трудится на благо всего интернет сообщества, заслуживает огромного уважения. Но в сети есть еще подобный масштабный проект, который не получая с этого дохода выполняет очень важную роль — сохраняет архивы сайтов, видео, аудио и печатной продукции.

Я говорю, конечно же, про web.archive.org — глобальный проект с казалось бы невыполнимой миссией — создание архива всех сайтов, когда либо размещенных в интернете. Причем, сайты сохраняются не в виде скриншотов, а в виде полноценно работающих веб-страниц со всеми ссылками, картинками и стилевым оформлением (CSS). Причем, для каждого сайта за время его существования в сети в этом архиве может накопиться и по несколько сотен копий, датированных разными этапами жизни ресурса.
Как можно использовать архив сайтов интернета
Чем же может быть полезен данный webarchive?
- Ну, во-первых, вы можете погрузиться в приятную ностальгию путешествуя по вашему сайту многолетней давности. Проследить историю изменений можно будет для любого другого ресурса интернета (например, я брал скриншоты для статей про уже умерший Апорт именно из это вебархива, да и скриншоты, иллюстрирующие эволюцию главной страницы Яндекса, имеют тоже самое происхождение).
- Но это не все. Если страница добавленного вами в закладки сайта не открывается, то вы, конечно же, можете попробовать вытащить ее из кеша Яндекса или Гугла (читайте подробнее про то, как лучше искать в Google). Но если ресурс недоступен уже очень давно, то такие мертвые ссылки нигде кроме archive.org открыть уже будет не возможно (правда, и там его может не оказаться по описанным чуть ниже причинам).
- Так же, если вы по каким-либо форс-мажорным обстоятельствам не делали бэкап (резервное копирование) вашего сайта, то данный web archive будет единственной возможностью восстановить свой сайт. Имеется возможность очистить все ссылки от привязки к web.archive.org и сделать их прямыми именно для вашего ресурса (читайте об этом ниже).
Ну, и последнее, что приходит в голову — поиск уникального контента. Если вы не способны сами создавать уникальный контента для сайта (писать статьи), то здесь вы сможете ими разжиться, правда, усилия приложить все равно придется. Суть такова, что многие сайты умирают и становятся недоступны вместе с имеющимся на них контентом.
Отыскав такие ресурсы вы сможете вытащить тексты из интернет-архива и разместить их у себя, предварительно проверив их на уникальность. Таким образом вы не занимаетесь плагиатом и не нарушаете авторские права (копирайт), но искать в вебархиве многим может показаться очень уж трудоемкой задачей.
Онлайн сервис Webarchive ведет свою историю аж с 1996 года. Поставленная перед проектом задача казалась невыполнимой даже с учетом того, что сайтов на то время в интернете было значительно меньше, чем сейчас (на несколько порядков). По началу, сайты архивировались не очень часто, но со временем, повышая мощности хранилищ, Веб-архив стал делать все больше и больше слепков сайтов.
Сам себя этот веб архив занес в базу лишь в 1997 году и выглядела его главная страница тогда так:
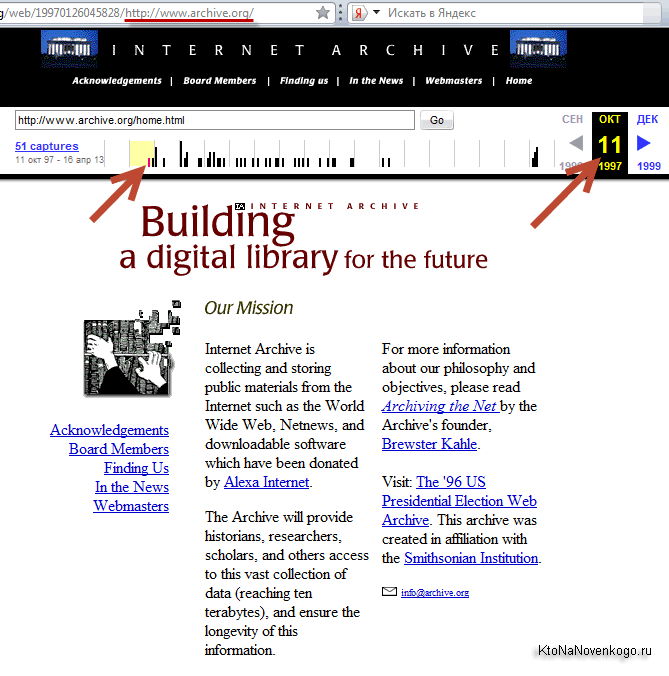
Сейчас на все про все (включая аудио, видео и отсканированные книги) у этой некоммерческой организации задействовано дисковое пространство чудовищных размеров, измеряемое десяткой с пятнадцатью нулями байт. Сайт имеет зеркала в различных дата центрах, а сам проект с недавних пор получил официальный статус библиотеки. Если рассматривать только архив страниц сайтов, то их уже там насчитывается около ста миллиардов (тут учитываются все слепки страниц когда-либо снятые и сохраненные).
На главной странице доступен не только архив страниц интернета Wayback Machine, но и архивы различных кинохроник, телепередач, аудио записей и отсканированных в различных библиотеках книг:
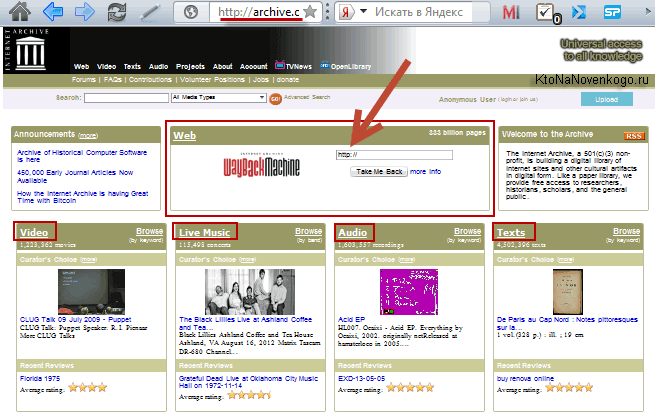
Но нас интересует именно область WEB с логотипом Wayback Machine. В расположенную там форму можно ввести URL или доменное имя интересующего вас сайта (читайте про то, что такое домен и чем он отличается от URL), чтобы попасть на страницу с календарем:
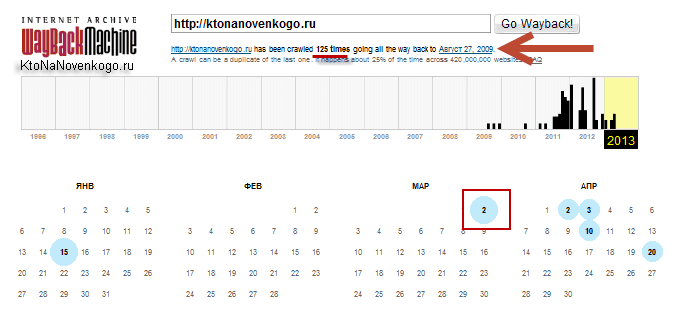
Из приведенного примера видно, что мой блог был впервые архивирован 27 августа 2009 года (через пять дней после регистрации (покупки) домена ktonanovenkogo.ru). За прошедший интервал времени было создано 125 архивных копий сайта, каждую из которым можно будет посмотреть и потрогать руками (осуществляя переходы по внутренним ссылкам).
Открытие мертвых ссылок и условия попадания сайта в archive.org
В календаре голубыми кружочками отмечены даты, в которые был создан слепок (вебархив) данного сайта. Естественно, что моменты снятия слепка никак не будет коррелироваться с производимыми на вашем ресурсе изменениями, и их время Webarchive определяет строго исходя из своих внутренних алгоритмов и таймеров.
Поэтому использовать архив интернета, как инструмент для открытия временно недоступных сайтов, наверное, не всегда будет резонным. Для этого у Яндекса имеется возможность просмотра архивной копии документа:

Да, и в Google можно всегда посмотреть сохраненную копию веб-страницы:

Данный же онлайн сервис понадобится в особо тяжелых случаях, когда искомая страница уже не существует и вряд ли уже будет существовать в реальном интернете, но зато она по прежнему будет доступна в машине времени.
Правда, тут должно быть соблюдено несколько условий того, чтобы
Он не должен содержать в своем файле robots.txt запрет для его индексации роботом с web.archive.org. Такой запрет, обычно выглядит так:
User-agent: ia_archiver Disallow: /
Когда я писал статью про электронную почту mail.ru, то не смог найти в Архиве Интернета сохраненных копий сайта mail.ru, т.к. его файл robots.txt содержал в себе похожий запрет:

- Некоторые сайты Вебархив по каким-либо причинам банально не нашел. Вероятность попадания ресурса в базу повышается, если он будет добавлен в каталог Dmoz или же если на него будут проставлены ссылки с других популярных ресурсов, которые в Webarchive уже находятся. В общем то, даже простой запрос через форму на главной странице этого сервиса может послужить толчком к привлечению внимания этого архиватора к вашему ресурсу.

Как найти нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
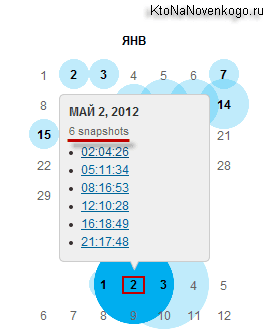
Возможно, что это делается во избежании потери данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру одного из веб-архивов, вы увидите копию своего (в данном примере моего) сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающее на ДжаваСкрипте полностью исчезло:
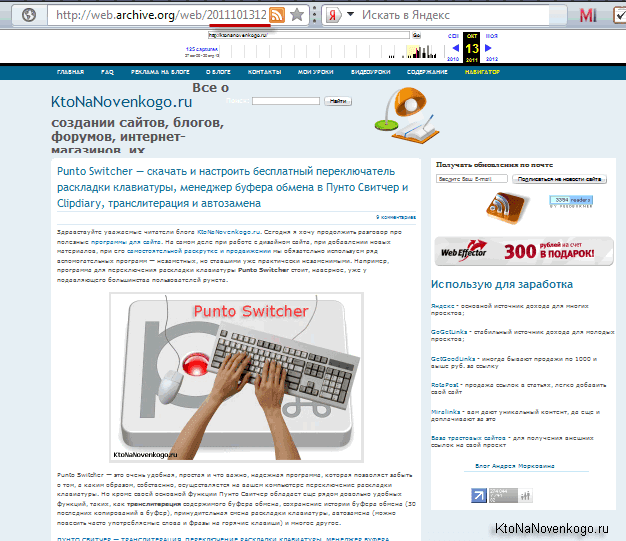
Но это не столь важно, ибо в исходном коде страницы с web.archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится. Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
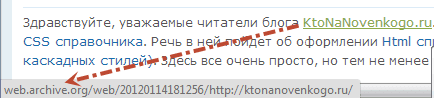
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomu-vnutrennej-optimizaciej.html
Понятно, что можно будет вручную отсечь вступительную часть ссылок (http://web.archive.org/web/20111013120145/), получив таким образом рабочий вариант. Можно этот процесс даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет воспользоваться встроенной в этот сервис возможностью замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки браузера — начинается с http://web.archive.org/). Он будет иметь примерно такой вид:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
И вставляете в него конструкцию «id_» в конце даты (20111013120145), чтобы получилось так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Теперь измененный адрес обратно возвращаете в адресную строку браузера и жмете на Enter. После этого страница c архивом вашего сайта обновится и все внутренние ссылки станут прямыми. Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что восстановление таким образом огромного сайта займет чудовищное количество времени, но когда другого варианта нет, то и такой покажется манной небесной. К тому же, страдают невозвратной потерей контента обычно только начинающие вебмастера, у которых этого самого контента было мало, а более-менее опытные сайтовладельцы, уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые содержатся в недрах этого мастодонта, то вам нужно будет вставить в адресную строку браузера следующий адрес и нажать Enter:
http://wayback.archive.org/web/*/ktonanovenkogo.ru*
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этого форме:
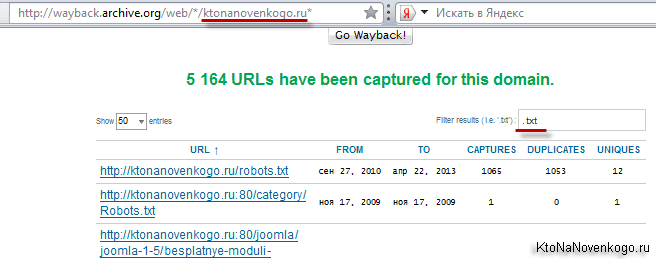
Например, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive. Зачем — не знаю, но захотел.
Как вытянуть из Webarchive уникальный контент для сайта
Описанный ниже способ лично я не использовал, но чисто теоретически все должно работать. Саму идею я почерпнул на этом молодом ресурсе, где и были описаны все шаги. Принцип метода состоит в том, что каждый день умирают и никогда не возрождаются десятки сайтов.
Причин этому может быть много и большинство из почивших в бозе ресурсов никакой особой ценности в плане контента никогда и не представляли. Но из всякого правила бывают исключения и нужно будет всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были бы представлены в Web Archive, хотя бы одной копией.
Т.к. после смерти контент этих сайтов постепенно выпадет из индекса поисковых систем, то взяв его из интернет-архива вы, по идее, станете его законным владельцем и первоисточником для поисковых систем. Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса его нещадно могли откопипастить). Но кроме проблемы уникальности текстов, существует проблема их отыскания.
Во-первых, нам нужен список сайтов, которые скоро умрут или уже померли. Автор метода предлагает скачать с сайта регистратора доменных имен Nic.ru список освобождающихся или уже освободившихся доменов.
Что примечательно, в последней колонке этого списка (его можно открыть в Excel) будет отображаться количество архивов, созданных для каждого сайта в Web Archive (правда, проверить наличие домена в веб-архиве можно и в ряде онлайн сервисов).
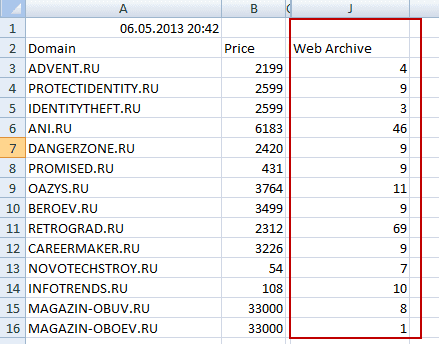
Список буржуйских доменных имен, освобождающихся или уже освободившихся, предлагается скачать по этой ссылке. Ну, а дальше просматриваем содержимое сайтов, которое сохранил Web Archive и пытаемся найти что-то стоящее. Потом проверяем уникальность этих материалов (ссылку приводил чуть выше) и в случае удачи публикуем их на своем ресурсе, либо продаем в какой-нибудь бирже контента.
Да, способ муторный и мною лично не проверенный. Но, думаю, что при некоторой степени автоматизации и обмозговывания он может давать неплохой выхлоп. Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Рубрика: Лучшие онлайн-сервисыЧто такое веб-архив и как им пользоваться
Веб-архив — это проект web.archive.org, на котором хранятся разные версии всех сайтов с момента их создания при условии, что нет запрета на сохранение ресурса. Благодаря наличию сохраненных копий в веб-архиве, доступно восстановление сайта даже при отсутствии резервной копии.
Что такое веб-архив сайта
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив был основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Как использовать архив веб-сайтов
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
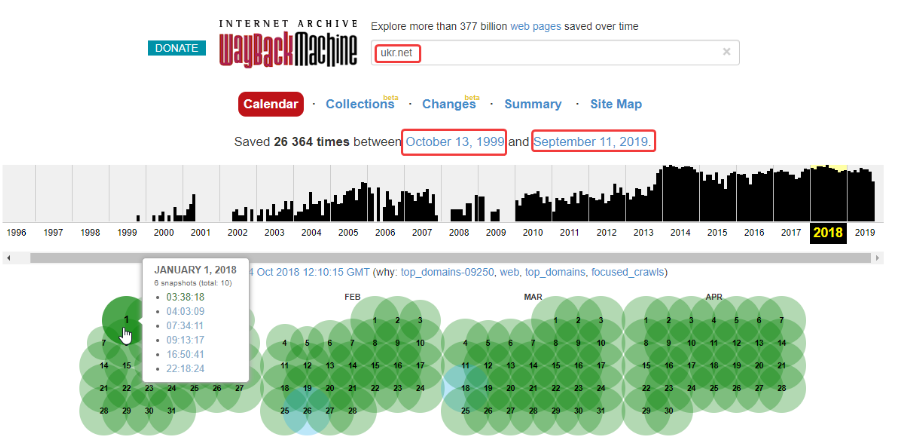
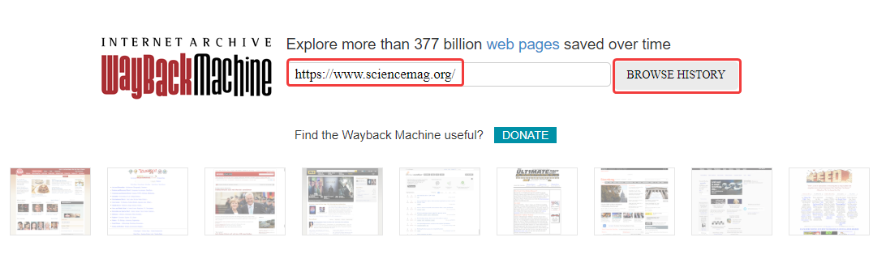
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент времени. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
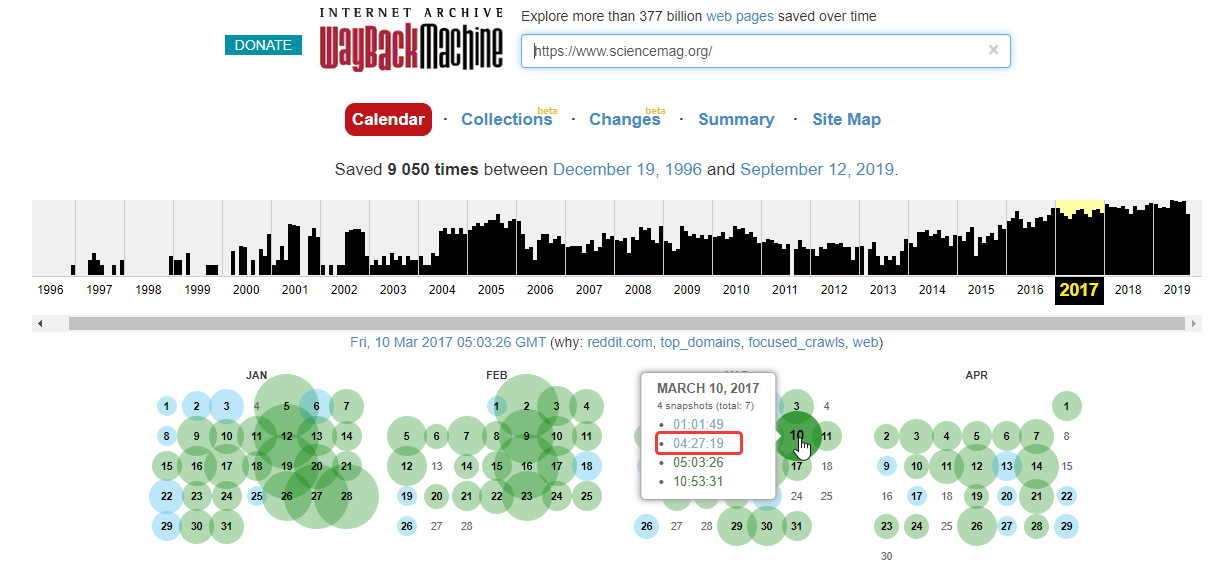
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Как добавить текущую версию сайта в веб-архив
Для уверенности в том, что все нужные версии собственного проекта будут сохранены в веб-архиве желательно самостоятельно инициировать сканирование сайта. Для этого введем в разделе «Save Page Now» домен сайта и нажмем «Save page»:
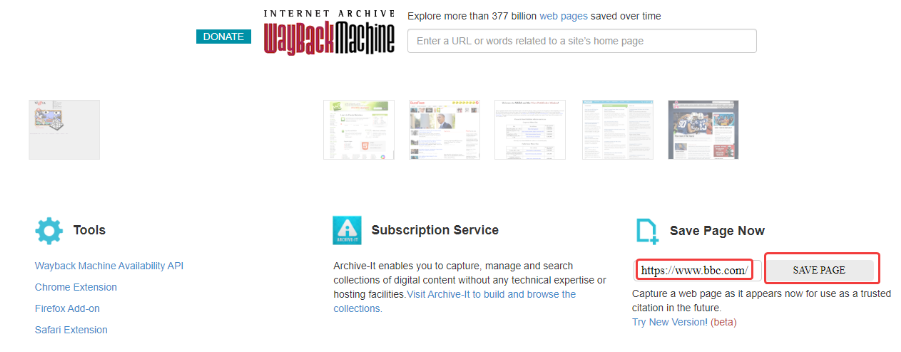
После этого в архив будет добавлена текущая версия сайта. На всякий случай целесообразно повторять подобную процедуру перед всеми существенными изменениями сайта и после их осуществления.
Как запретить добавление сайта в веб-архив
Чтобы сайт не был доступен в веб-архиве, пропишите запрет в файле robots.txt. Для этого нужно зайти в корневой каталог сайта на панели управления хостинг-провайдера и выбрать редактирование данного файла:
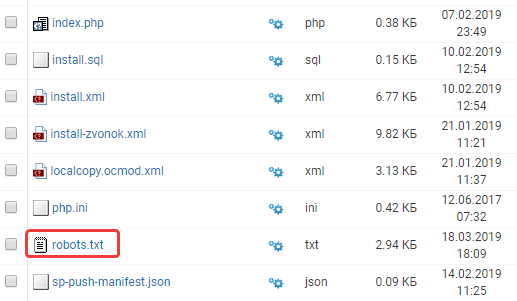
Запрет устанавливается с помощью такого кода:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /После этого удалятся существующие версии проекта, а также не будет осуществляться копирование сайта в архив пока домен функционирует и в файле robots.txt присутствуют данные настройки. Когда закончится регистрация доменного имени старые версии сайта вновь станут доступны в веб-архиве.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как использовать парсер веб-архива Robotools
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в демо-версии, после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
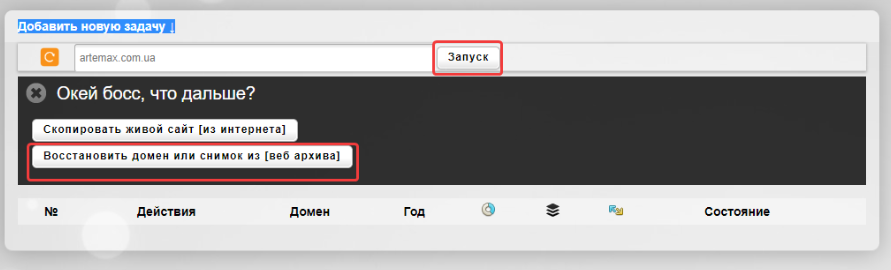
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
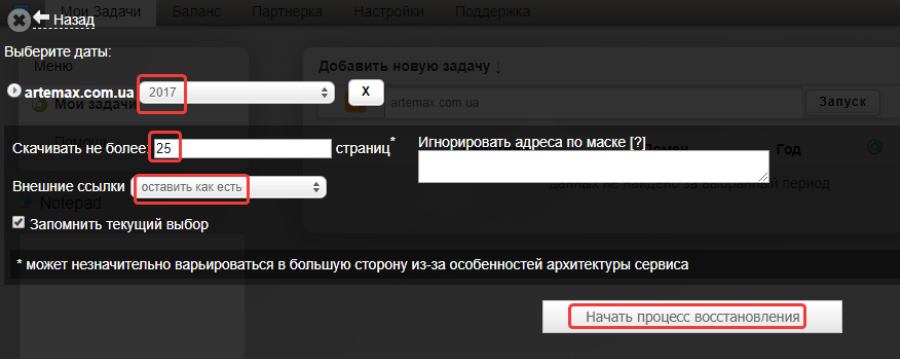
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
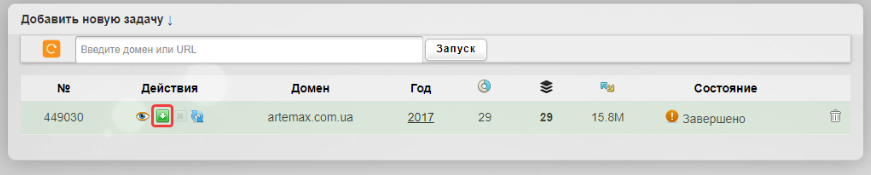
Затем нажимаем «Все ОК, собрать ZIP-архив»:
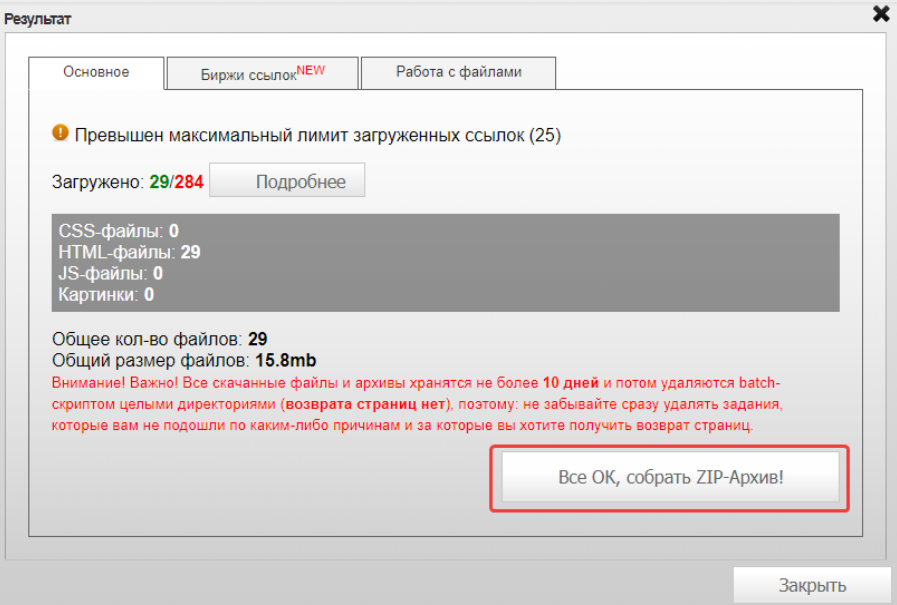
После этого нажимаем «Скачать архив»:
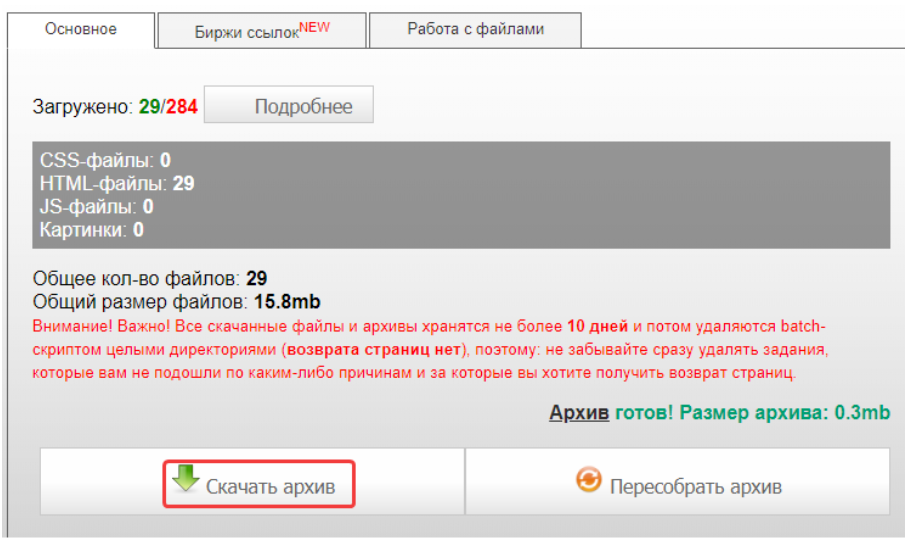
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
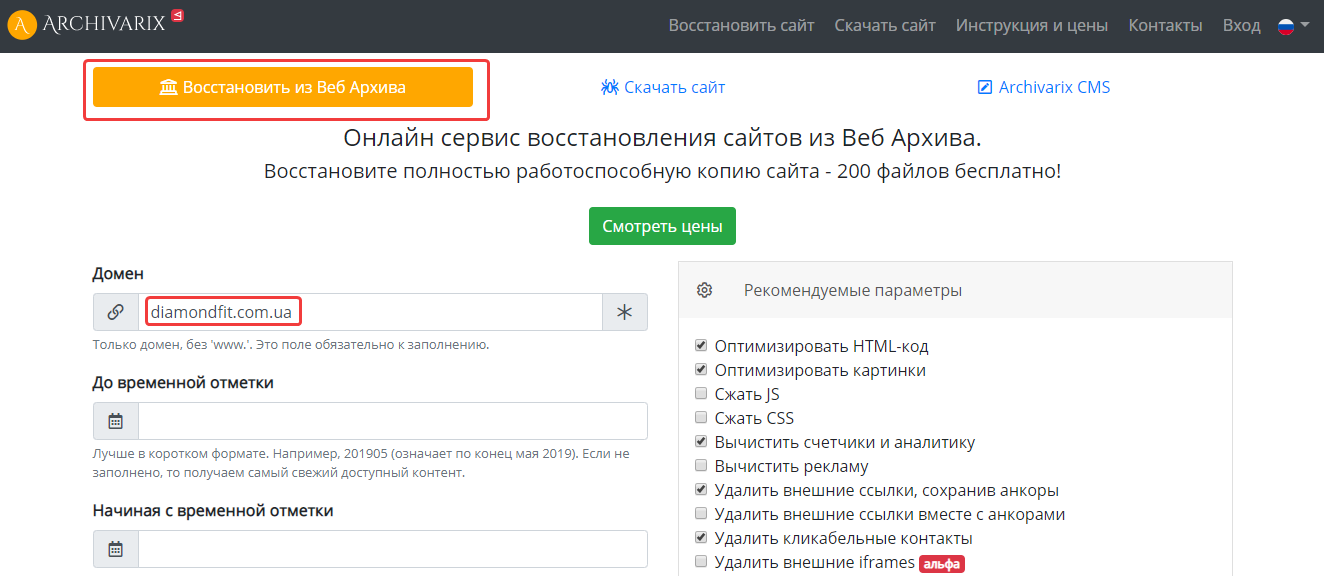
Как скачать сайт из веб-архива с помощью Archivarix
Данный сервис также предназначен для восстановления старых версий сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из Веб Архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
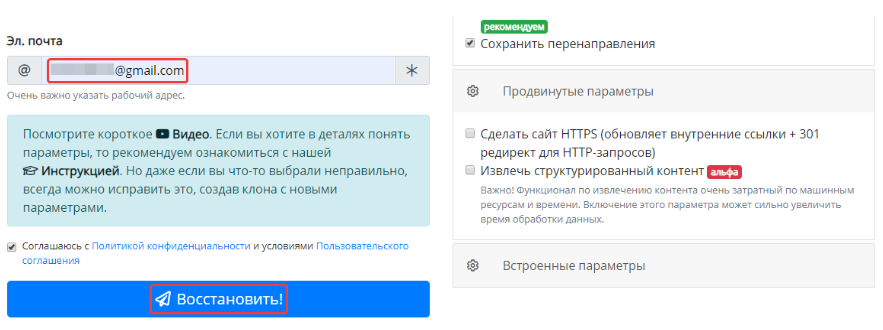
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
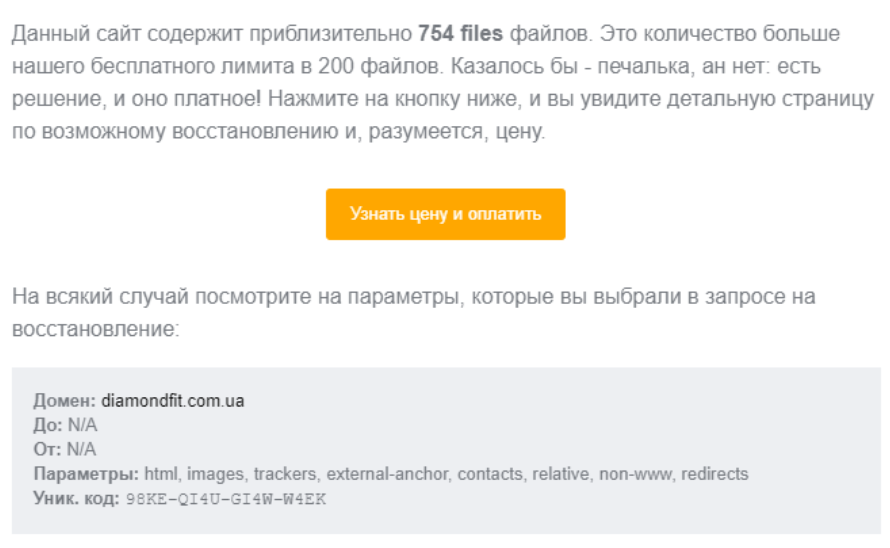
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Запомнить
- Веб-архив — масштабный бесплатный проект, созданный для сохранения всего контента, представленного в интернете, даже после его удаления на исходном сайте.
- Веб-архив полезен для анализа сайтов клиентов и конкурентов, отслеживания изменений на собственном проекте, проверки доменов перед покупкой.
- Используя данные веб-архива, полученные с помощью онлайн-сервисов, доступно восстановление сайта без бэкапа.
- В веб-архиве много текстового контента, среди которого есть уникальные статьи на любую тематику, подходящие для публикаций на собственном информационном проекте.
{«0»:{«lid»:»1573230077755″,»ls»:»10″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»1″:{«lid»:»1596820612019″,»ls»:»20″,»loff»:»»,»li_type»:»hd»,»li_name»:»country_code»,»li_nm»:»country_code»}}
Истории бизнеса и полезные фишки
История домена, история сайта
У Вас в браузере заблокирован JavaScript. Разрешите JavaScript для работы сайта!
В моей экспертно-судебной практике стали встречаться запросы, связанные с историей использования домена. Данный материал поможет пользователям и другим экспертам в получении информации об истории сайта.
Основные источники информации:
- Анализ сайта — сводная информация о сайте и готовые прямые ссылки на другие сервисы с передачей домена.
- web.archive.org — История сайта, если сайту более 6 месяцев
Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»
Чтобы увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/yoursite.com/*, например, http://web.archive.org/*/htmlweb.ru/
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE». - archive.md, он же archive.ph и archive.today
Получить все снимки указанного URL: http://archive.is/http://htmlweb.ru/
Все сохранённые страницы домена: http://archive.is/htmlweb.ru
Все сохранённые страницы всех субдоменов: http://archive.is/*.htmlweb.ru - web-arhive.ru
- whoishistory.ru — история изменения Whois только для зон ru, рф, su
Пример прямого запроса:whoishistory.ru/simplesearch?sbmt=start&domainsimple=htmlweb.ru - Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:cache:https://htmlweb.ru/ - История Whois на reg.ru — регистратор reg.ru платно предоставляет информацию об изменениях whois домена
- История Whois на domaintools.com
- Поиск по Whois в зонах RU и SU
- Поиск соседних доменов (расположенных по тому же IP адресу что и Ваш домен)
Пример прямого запроса:http://1stat.ru/neighbours?show=neighbours&search_name=htmlweb.ru - Косвенно по ссылкам на домен: linkpad
Пример прямого запроса:https://www.linkpad.ru/?search=htmlweb.ru - История Alexa Rank за 90 дней
Пример прямого запроса:https://www.alexa.com/siteinfo/htmlweb.ru
Аналоги web.archive.org. Как найти удаленные сайты?
Первое июньское обновление Archivarix CMS с новыми, удобными фичами.
— Исправлено: Раздел История не работал при отсутствии включённого php расширения zip.
— Вкладка История с деталями изменений при редактировании текстовых файлов.
— Инструмент редактирования .htaccess.
— Возможность подчистить бэкапы до нужной точки отката.
— Блок «Отсутствующие урлы» убран из Инструментов, т.к. он доступен с главной панели
— В главную панель добавлена проверка и показ свободного места на диске.
— Улучшена проверка необходимых PHP расширений при запуске и начальной установке.
— Мелкие косметические правки.
— Все внешние инструменты обновлены на последние версии.
Обновление, которое оценят веб-студии и те, кто использует аутсорс.
— Отдельный пароль для безопасного режима.
— Расширен безопасный режим. Теперь можно создавать кастомные правила и файлы, но без исполняемого кода.
— Переустановка сайта из CMS без необходимости что-либо вручную удалять с сервера.
— Возможность сортировать кастомные правила.
— Улучшены Поиск & Замена для очень больших сайтов.
— Дополнительные настройки у инструмента «Метатег viewport».
— Поддержка IDN доменов на хостингах со старой версией ICU.
— В начальной установке с паролем добавлена возможность разлогиниться.
— Если при интеграции с WP обнаружен .htaccess, то правила Archivarix допишутся в его начало.
— При скачивании сайтов по серийному номер используется CDN для повышения скорости.
— Другие мелкие улучшения и фиксы.
— Новый дэшборд для просмотра статистики, настроек сервера и обновления системы.
— Возможность создавать шаблоны и удобным образом добавлять новые страницы на сайт.
— Интеграция с WordPress и Joomla в один клик.
— Теперь в Поиске-Замене дополнительная фильтрация сделана в виде конструктора, где можно добавить любое количество правил.
— Фильтровать результаты теперь можно и по домену/поддоменам, дате-времени, размеру файлов.
— Новый инструмент сброса кэша в Cloudlfare или включения/отключения Dev Mode.
— Новый инструмент удаления версионности у урлов, к примеру, «?ver=1.2.3» у css или js. Позволяет чинить даже те страницы, которые криво выглядели в ВебАрхиве из-за отсутствия стилей с разными версиями.
— У инструмента robots.txt добавлена возможность сразу включать и добавлять Sitemap карту.
— Автоматическое и ручное создание точек откатов у изменений.
— Импорт умеет импортировать шаблоны.
— Сохранение/Импорт настроек лоадера содержит в себе созданные кастомные файлы.
— У всех действий, которые могут длиться больше таймаута, отображается прогресс-бар.
— Инструмент добавления метатега viewport во все страницы сайта.
— У инструментов удаления битых ссылок и изображений возможность учитывать файлы на сервере.
— Новый инструмент исправления неправильных urlencode ссылок в html коде. Редко, но может пригодиться.
— Улучшен инструмент отсутствующих урлов. Вместе с новым лоадером, теперь ведётся подсчёт обращений к несуществующим урлам.
— Подсказки по регулярным выражениями в Поиске & Замене.
— Улучшена проверка недостающих расширений php.
— Обновлены все используемые js инструменты на последние версии.
Это и много других косметических улучший и оптимизации по скорости.
Новая пятница, новые обновления!
Много нового и полезного было сделано в Archivarix CMS:
— В Поиске и Замене теперь можно фильтровать по дате урла.
— Теперь внешние ссылки со всех страниц сайта можно удалять нажатием одной кнопки. Анкоры сохраняются.
— Новый параметр ACMS_SAFE_MODE, который запрещает менять настройки Лоадера/CMS и загружать кастомные файлы, у импортов тоже запрещается импортировать настройки и кастомные файлы.
— JSON-файлы настроек Лоадера и CMS теперь можно скачать себе на компьютер и загрузить в CMS из файла на компьютере. Таким образом перенос настроек на другие сайты стал ещё проще.
— Создание кастомных правил стало удобнее, есть часто используемые шаблоны, которые можно выбрать.
— Новые кастомные файлы можно создать в файл менеджере без необходимости загружать файл.
— Дерево урлов для основного домена всегда идёт первым.
— Если вы скрываете дерево урлов для домена/поддомена, то эта настройка сохраняется во время работы с CMS.
— Вместо двух кнопок раскрыть/свернуть дерево урлов, теперь одна, которая умеет и то и другое.
— Создание нового урла упростилось и при создании можно сразу указать файл с компьютера.
— В мобильной вёрстке основная рабочая часть идёт первой.
— После каждой манипуляции с файлом, в базе обновляется его размер.
— Исправлена работа кнопок выборочных откатов истории.
— Исправлено создание новых урлов для поддоменов, которые содержат цифры в названии домена.
В исходном-коде файлов теперь ничего менять не нужно.
— Загружать сайты на сервер теперь можно загрузив на сервер лишь один скрипт с нашей Archivarix CMS.
— Для того чтобы что-то поменять в настройках CMS больше не нужно открывать её исходный код. Поставить пароль или понизить лимиты можно напрямую из раздела Настроек.
— Для подключения своих счётчиков, трекеров, кастомных скриптов теперь используется отдельная папка «includes» внутри папки .content.xxxxxx. Загружать кастомные файлы можно тоже напрямую через новый файловый менеджер в CMS. Добавление счётчиков и аналитики на все страницы сайта тоже стало удобным и понятным.
— Импорты поддерживают новую структуру файлов с настройками и папкой «includes».
— Добавлены комбинации клавиш для работы в редакторе кода.
Эти и многие другие улучшения в новой версии. Лоадер тоже обновился и работает с настройками, которые создаёт CMS.
Как получить сотни уникальных статей из Веб Архива.
С помощью веб архива очень легко можно абсолютно бесплатно получить сотни статей на различные темы, при этом затратив совсем немного времени.
Вебархив, хранит множество копий сайтов и статей, которые располагались на них с 1996 года. Как вы понимаете, много доменов уже сейчас не работают, либо на них присутствует контент совершенно другой направленности. Все эти сайты можно разделить на четыре вида:
- Работающие сайты без изменения тематики – они нам не подходят
- Работающие сайты, но по другой тематике – такие нам подходят
- Полностью неработающие сайты – такие нам тоже подходят
- Припаркованные сайты (домены) – тоже подходят
Для получения уникальных статей подходят все типы кроме первого. Чтобы не затягивать время давайте перейдем к практической части.
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.

Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50

Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.
На наш взгляд последний вариант предпочтительней всего, тем более что он практически бесплатный. Поэтому переходим на сайт eTXT.RU и скачиваем приложение в разделе «Сервисы->Проверка уникальности» ( нужно немного промотать страницу вниз чтобы скачать приложение).

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».
Программа использует для проверки уникальности статей поисковик Яндекс, Google, Rambler и другие. Эти поисковые системы не любят частые запросы к себе и блокируют их путем запроса разгадывания каптчи. Чтобы обойти этот момент нужно зарегистрироваться на сервисе anti-captcha.com и пополнить его на 1 доллар. Данной суммы вам хватит на разгадывание 1000 каптчей, а если по времени, то примерно на пол года. Скопируйте персональный Key и введите его в настройках программы, как показано на рисунке.

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
- 5. Etxt.ru – сервис позволяющий проверить статью на уникальность. Есть возможность скачать приложение для компьютера.
- 6. Аnti-captcha.com — сервис распознавания каптчи, используются при пакетных проверках статей.
Web.archive.org.ru — восстанови сайт из веб архива интернета
WebArchive Downloader 6.0 – профессиональное программное обеспечение для скачивания сайта и страниц из интернет архива web.archive.org.
Основные преимущества программы:
- Сохраняет все файлы — стили CSS, скрипты, изображения, страницы
- Создает внутреннюю перелинковку страниц сайта
- Возможны два вида внутренних ссылок: файловые и доменные
- Удаляет из текста страниц всю служебную информацию
- Восстанавливать сайт из вебархива на конкретную дату
- Поддерживает три вида кодировки страниц
- Автоматический процесс закачки контента сайта
- Сохраняет полную навигацию по сайту
Применяя WebArchive Downloader 6.0 вы выбираете:
Экономию
денегНе нужно платить каждый раз за скачивание сайта из web архива. Достаточно один раз просто купить программу.
Автоматизацию
процессаWebArchive Downloader 6.0 автоматизирует процесс сохранения страниц сайта, изображений и прочего контента.
Больше
времениРучной метод сохранения страниц из вебархива очень нудный и занимает много времени. WebArchive Downloader делает это пока вы отдыхаете.
Готовый
сайтСкачанный сайт, при нормальном его качестве, практически сразу можно размещать на хостинг.
Уникальный
контентНайдите брошенный домен и получите уникальные статьи и материал для своего сайта.
Что такое web.archive.org ?
Сайт web.archive.org принадлежит мировому архиву Интернета. Веб архив интернета — это некоммерческая организация занимающаяся сбором копий веб-страниц, изображений и даже видео-, аудио- материалов и предоставляющая доступ к нему на бесплатной основе. Веб архив сайтов создан в 1996 году и на сегодняшний день содержит более 520 млрд копий веб страниц, более 200 тысяч фильмов и 400 тысяч аудио записей и книг. Конечно веб архив не содержит всех копий сайтов, но шанс найти то что вам нужно достаточно высок. Более подробно про работу с веб архивом вы можете прочитать в этом обзоре.
Отличия версий
| Скачать Купить | Демо версия | Полная версия |
|---|---|---|
| Все виды данных | ||
| Все временые метки | ||
| Перелинковка файлов | ||
| Доступные кодировки | ||
| Кол-во запросов в день | 50 | ∞ |
| Сохраняет файлов | 10 | ∞ |
Кому полезна программа
-
Копирайтерам
Вебмастерам
SEO-специалистам
«Историкам»
Почему стоит выбрать WebArchive Downloader 6
- Скачивайте любое количество копий сайтов из веб архива без ограничений
- Получайте уникальные статьи, контент или дизайн бесплатно. Узнай как ?
- Сохраните утерянные копии страниц сайта на определенную дату
- Получайте готовые сайты при помощи нажатия нескольких кнопок
- Не тратте время на поиск и выбор страниц из web архива
Если вы приобрели полную версию программы
Приобретая WebArchive Downloader 6.0, Вы гарантированно получаете:
- Лицензию для одного устройства на неограниченны срок использования программы
- Все выпускаемые обновления абсолютно бесплатно
- Возможность участвовать в развитии проекта и предлагать идеи для реализации
Интернет-архив: Wayback Machine
Другие параметры расширенного поиска
Советы и подсказки для расширенного локатора URL
Есть ряд простых URL-запросов для расширенного поиска на документах в Wayback Machine. Для проведения этих расширенных Поиск, просто введите следующие URL-адреса в адрес вашего браузера или адресной строке.
Получение последней архивированной копии определенного URL-адреса
https: // web.archive.org/web/http://www.cnet.com
, где «http://www.cnet.com» целевой URL. Этот запрос возвращает последний заархивированный версия этого целевого URL в архиве.
Получение заархивированная копия определенного URL с заданной даты
https://web.archive.org/web/20011007203917/http://www.cnet.com
Это возвращается конкретный документ, URL-адрес которого совпадает с целевым URL-адресом и чей дата архивации наиболее точно соответствует дате, указанной в формат ГГГГММДДччммсс.В приведенном выше примере это возвращает www.cnet.com заархивировано 7 октября 2001 г. в 20:39 17 секунд.
Дата не нужно указывать до второго. Использование усеченной даты вернет заархивированную страницу, которая наиболее точно соответствует среднему значение указанной даты.
Пример усечения до года
https://web.archive.org/web/2000/http://www.cnet.comЭто возвращается документ, URL-адрес которого точно соответствует http: // www.cnet.com и дата архивирования которого наиболее точно совпадает с 1 июля 2000 г. (июль 1 — середина года или «среднее значение» 2000 года).
Пример усечения до года и месяца
https://web.archive.org/web/200010/http://www.cnet.comЭто возвращается документ, URL-адрес которого точно соответствует http://www.cnet.com и дата архивации наиболее точно совпадает с 15 октября 2000 г. ( 15-е — середина октября или «среднее значение» октября 2000 г.).
Поиск для всех копий определенного URL, заархивированных за определенный период времени
https://web.archive.org/web/200109*/http://www.cnet.com
Это возвращается все копии определенного целевого URL (например, http://www.cnet.com) которые были заархивированы начиная с даты, указанной в формат ГГГГММДДччммсс. В приведенном выше примере это возвращает список всех архивных версий www.cnet.com в архиве Сентябрь 2001 г.
Поиск для всех URL-адресов сайта, заархивированных за определенный период времени
.APIhttps://web.archive.org/web/200109*/http://www.cnet.com*
Это возвращается все URL-адреса, начинающиеся с http://www.cnet.com, которые были заархивированы в сентябре 2001г.
Wayback Machine | Интернет-архив
The Internet Archive Wayback Machine поддерживает ряд различных API, чтобы разработчикам проще получать информацию о данных захвата Wayback.
Ниже приводится список поддерживаемых в настоящее время API. Эта страница часто меняется, пожалуйста, проверяйте последнюю информацию.
Обновлено 24 сентября 2013 г.Доступность обратного пути JSON API
Этот простой API для Wayback — тест, чтобы увидеть, заархивирован ли данный URL и в настоящее время доступны в Wayback Machine.Этот API полезен для предоставления 404 или другого обработчика ошибок, который проверяет Wayback. чтобы увидеть, есть ли готовая к отображению архивная копия. API можно использовать следующим образом:
http://archive.org/wayback/available?url=example.com , который может вернуться:
{
"archived_snapshots": {
"ближайший": {
"доступно": правда,
"url": "http://web.archive.org/web/20130919044612/http://example.com/",
"отметка времени": "20130919044612",
"status": "200"
}
}
}
, если URL доступен.Если доступно, url — это ссылка на архивный снимок в Wayback Machine. В это время archived_snapshots просто возвращает единственный ближайший снимок , но в будущем могут быть добавлены дополнительные снимки.
Если URL-адрес недоступен (не заархивирован или в настоящее время недоступен), ответ будет следующим:
{"archived_snapshots": {}}
Другие опции
Можно указать дополнительные параметры: метка времени и обратный вызов -
отметка времени— отметка времени для поиска в Wayback.Если не указан, возвращается самый последний доступный захват в Wayback. Формат метки времени составляет 1–14 цифр (ГГГГММДДччммсс), например:
http://archive.org/wayback/available?url=example.com×tamp=20060101
может привести к следующему ответу (обратите внимание, что метка времени моментального снимка теперь близка к 20060101):
{
"archived_snapshots": {
"ближайший": {
"доступно": правда,
"url": "http: // web.archive.org/web/20060101064348/http://www.example.com:80/ ",
"отметка времени": "20060101064348",
"status": "200"
}
}
}
обратный вызов — дополнительный обратный вызов, который может быть указан для создания ответа JSONP.
Memento API
Интернет-архиватор Wayback Machine также полностью совместим с Мементо Протокол Memento API предоставляет дополнительные интерфейсы для запроса снимков (например, «Mementos») в Wayback Machine.API доступности частично основан на API Memento.
Вот некоторые конкретные примеры поддержки Memento в Wayback Machine
API сервера Wayback CDX
CDX Server — это еще один API, который позволяет выполнять сложные запросы, фильтрация и анализ данных захвата Wayback. Если вы ищете более подробную информацию о машинных данных Wayback, пожалуйста, взгляните на API сервера CDX.
Последнюю документацию по серверу CDX можно найти по адресу: Сервер Wayback CDX @ GitHub
.Интернет-архив: контакт
Парковка:
На Фанстоне и прилегающих улицах есть бесплатные парковочные места на 2 часа, а также парковка со счетчиками на Клементе. Для карты дневных платных участков в районе: Карта парковок
Списки
Архивисты
Список объявлений (новости интернет-библиотек)
читать в Интернете
архив
Архивисты
Список обсуждения (обсуждение интернет-библиотек)
читать в Интернете
архив
Список обсуждения киноархива (новости онлайн
архив фильмов)
читать в Интернете
архив
Путь к Интернет-архиву
Масса
Транзит в пределах Сан-Франциско
На машине от Северной бухты
На машине от Восточного залива
На машине от Южного залива
через 280
На машине от Южного залива
через 101
Масса Транзит в Сан-Франциско
Наши район обслуживается Сан-Франциско MUNI автобусные маршруты.Следующие ссылки, перечисленные ниже, приведут вас к различным маршрутам MUNI; выберите наиболее удобный маршрут, нажмите, чтобы увидеть расписание и карту. 511 Trip Planner — тоже полезный ресурс
1 — Калифорния: в сторону центра города. Выезд в сторону Ричмонда. Доска на Дэвис-стрит и Пайн-стрит. Попросите водителя отпустить вас на углу Калифорнийской улицы и бульвара Парк Президио. Поверните налево на бульвар Парк Президио. в сторону Geary Blvd.Поверните налево на Clement St., поверните направо на Funston Ave. Пункт назначения будет слева.
1AX — Калифорнийский экспресс A: прибывает в сторону финансового района в утренний час пик. Отправление в сторону Внешнего Ричмонда на послеобеденный час пик. Выйдите на углу улицы California St. & Park Presidio Blvd. Поверните налево на бульвар Парк Президио. в сторону Geary Blvd. Поверните налево на Clement St., поверните направо на Funston Ave. Пункт назначения будет слева.
1BX — Калифорнийский экспресс B: прибывающее в сторону финансового района в утренний час пик.Отправление в сторону Внешнего Ричмонда на послеобеденный час пик. Выйдите на углу улицы California St. & Park Presidio Blvd. Поверните налево на бульвар Парк Президио. в сторону Geary Blvd. Поверните налево на Clement St., поверните направо на Funston Ave. Пункт назначения будет слева.
38R — Geary Rapid : (те же направления, что и маршрут 38, но этот маршрут имеет ограниченные автобусные остановки , и он быстрее). Попросите водителя отпустить вас на углу Geary Blvd. & Park Presidio Blvd.Направляйтесь на восток по Гири (в сторону центра) и поверните налево на Funston Ave. Пункт назначения будет в конце блока справа.
38 — Geary: попросите водителя отпустить вас на углу Geary Blvd. & Park Presidio Blvd. Направляйтесь на восток по Гири (в сторону центра) и поверните налево на Funston Ave. Пункт назначения будет в конце блока справа.
28 — 19-я авеню: попросите водителя отпустить вас на углу бульвара Гири. & Park Presidio Blvd.Направляйтесь на восток по Гири (в сторону центра) и поверните налево на Funston Ave. Пункт назначения будет в конце блока справа.
От южный залив на CalTrain: Сядьте на автобус № 30 на Таунсенд-стрит и 4-ю улицу. Отойдите на 3-ю улицу и Маркет-стрит. Затем сядьте на автобус № 38 или № 38R на Гири-Бульвар и Кирни-Стрит. Попросите водителя отпустить вас на углу Geary Blvd и Park Presidio Blvd. Направляйтесь на восток по Гири (в сторону центра) и поверните налево на Funston Ave.Пункт назначения будет в конце блока справа.
От БАРТ, выйти на Монтгомери Улица станции и следуйте по 38 Geary (см. Выше)
На машине из Северный залив
Двигайтесь по шоссе US-101 South через мост Золотые Ворота (платные).
Продолжайте движение по US-101 на юг, пройдите 0,3 мили.
Сверните с съезда с 19-й авеню / Golden Gate Park на CA-1 South, пройдите 1.3 миль
Поверните направо на озеро Св.
Поверните налево на 14-ю авеню, пройдите 0,5 мили
Поверните налево на Clement St, пройдите 0,1 мили
Поверните направо на Funston Ave.
Прибытие на проспект Фанстон 300, Сан-Франциско, слева.
Есть парковка со счетчиками на Клементе и 2-часовая парковка на Фанстон и параллельных проспектах (обратите внимание на время уборки улиц).
На машине из Восточный залив
Take Автомагистраль между штатами 80 на запад через мост через залив.
Сверните с моста Golden Gate Bridge на US-101 North, пройдите 1,1 мили
Продолжайте движение по Octavia Blvd, пройдите 0,30 мили
Поверните налево на Fell St, пройдите 0,6 мили
Поверните направо на Scott Ave, пройдите 0,1 мили
Поверните Налево на Hayes St, проехать 0,1 мили
Повернуть направо на Divisadero Ave, проехать 0.6 миль
Поверните налево на бульвар Гири, пройдите 1,8 мили
Поверните направо на Funston Ave, пройдите 0,1 мили
Прибытие на 300 Funston Ave. Сан-Франциско, справа
Есть парковка со счетчиками на Клементе и 2-часовая парковка на Фанстон и параллельных проспектах (обратите внимание на время уборки улиц).
Из Южный залив по шоссе 280
Take Межгосударственный 280 к северу до Сан-Франциско
Когда Автомагистраль между штатами 280 разделяется на маршруты 1 и 280, поверните налево, на шоссе 1 (19 авеню).
Подписаться Шоссе 1 (19-я авеню) на север через Сан-Франциско и через парк Золотые Ворота.
Поверните направо на ул. Клемент
Поверните направо на Funston Ave.
Прибытие на проспект Фанстон, 300, Сан-Франциско, слева.
Есть парковка со счетчиками на Клементе и 2-часовая парковка на Фанстон и параллельных проспектах (обратите внимание на время уборки улиц).
Из Южный залив по шоссе 101
Когда Шоссе 101 разделяется на шоссе 80 / мост через залив. и подходы к шоссе 101 / мосту Золотые Ворота, повернуть налево, на шоссе 101.
Подписаться поворот на 101 север / мост Золотые Ворота
Продолжайте движение по Octavia Blvd, проехать 0,3 мили.
Поверните налево на Fell St, пройдите 0.6 миль
Поверните направо на Скотт-авеню, пройдите 0,1 мили
Поверните налево на Hayes St, пройдите 0,1 мили
Поверните направо на Divisadero Ave, проехать 0,6 мили
Поверните налево на бульвар Гири, пройдите 2,8 мили
Поверните направо на Funston Ave, проехать 0,1 мили
Прибытие на проспект 300 Funston, Сан-Франциско, справа.
Есть парковка со счетчиками на Клементе и 2-часовая парковка на Фанстон и параллельных проспектах (обратите внимание на время уборки улиц).
Адрес:
Физический архив
2512 Флорида Авеню
Ричмонд, Калифорния 94804
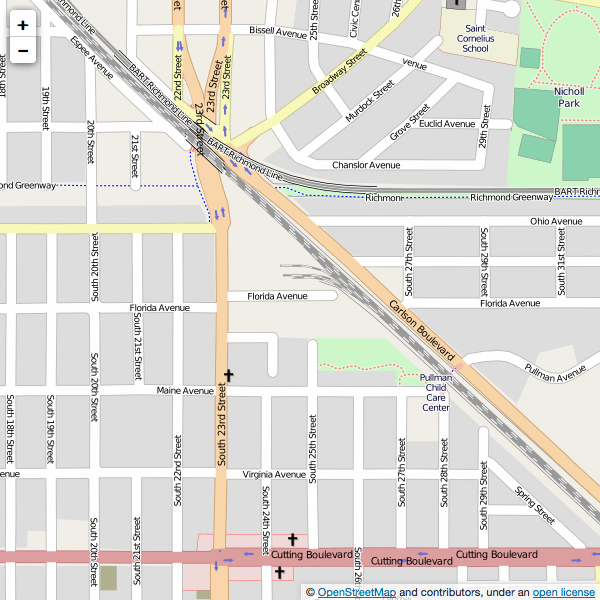
Направления к физическому архиву
На машине от Северной бухты
На машине от Восточного залива
На машине от Северного залива
Возьмите межштатную автомагистраль 80 на запад через мост через залив.
Выезжайте на I-580 W в сторону Сан-Франциско.
Сверните на выезд MARINA BAY PKWY / S 23RD ST, ВЫХОД 10A.
Поверните направо на S 23RD ST.
Поверните направо на Флорида-авеню.
Если вы дойдете до Огайо-авеню, вы зашли слишком далеко.
На машине от Восточного залива
I-880 N в сторону OAKLAND.
Двигайтесь по I-980 E в сторону CA-24 / WALNUT CREEK.
Выезжайте на I-580 W в сторону Сан-Франциско.
Сверните на выезд MARINA BAY PKWY / S 23RD ST, ВЫХОД 10A.
Поверните направо на S 23RD ST.
Поверните направо на Флорида-авеню.
Если вы дойдете до Огайо-авеню, вы зашли слишком далеко.
.