Сохранить копию сайта в веб архив Internet archive Wayback Machine
В интернете существует очень интересный и полезный проект — веб архив, полностью — Internet archive Wayback Machine.
В веб архиве, расположенным по адресу: http://archive.org/web/, сохраняется прошлое сайтов в виде полноценных и работающих страниц, со всеми ссылками, изображениями, видео. В общем можно увидеть, какой был сайт в прошлом на дату формирования копии.
Боты архив-машины самостоятельно сканируют сайты и формируют их копии, каков их алгоритм — не известно. Поэтому в архиве можно найти много копий своего сайта со всеми страницами или всего одну, да и то искажённую.
Предположить, в каком виде загрузится и отобразится тот или иной сайт — невозможно. Но как правило, машина периодически сохраняет полноценные копии всего сайта и даже может выдать страницы, которых у вас не было никогда.
Если вы не хотите отдавать судьбу своего сайта в руки ботов ресурса, то можно самостоятельно занести страницу в архив, и в случае непредвиденных случайностей, найти и восстановить её.
Как увидеть архив своего сайта
Откройте Internet archive и в строке поиска введите адрес сайта, далее нажмите «browse history»
Здесь будет показано, сколько копий, в каком году и в каком месяце сохранено в архиве.
Выбрав дату и нажав на эти кнопки, можно увидеть копию сайта на тот момент времени.
Как занести сайт в архив
Для этого откройте главную страницу Internet archive Wayback Machine: http:// archive.org/web/.
Далее в рубрике Save Page Now введите адрес архивируемой страницы и нажмите «SAVE PAGE». Через несколько секунд копия буде сохранена.
Как запретить архивировать мой сайт
Что за дело, кто без моего спроса меня сосчитал? Если вы так думаете, то можно запретить веб-машине сохранять копии вашего сайта
Для этого в файле robots.txt нужно прописать запрещающую директиву для ботов wayback machine.
|
User-agent: ia_archiver Disallow: / |
Чтобы позволить архивировать сайт снова, уберите эти строки из файла robots. txt и лучше сразу добавьте главную станицу в архив. Иначе изменений можно дожидаться долго, обновления в системе происходят редко.
txt и лучше сразу добавьте главную станицу в архив. Иначе изменений можно дожидаться долго, обновления в системе происходят редко.
***
Как просмотреть позиции модулей Joomla 2.5
Как сделать резервную копию — бекап файлов сайта
Выделение перемещение и копирование
Заработать на бирже Gogetlinks размещая ссылки на сайте
- < Назад
- Вперёд >
Archive.org на службе вебмастера | Фарма Блог №1
Archive.org гордо и по праву именует себя «Архивом интернета», и с далекого 1996 года парсит всю сеть с целью архивации и структурирования данных. Этот сайт прямо или косвенно может принести пользу и нам. По данным Википедии, на октябрь 2012 года, Архив содержал данные о более чем 85 миллиардах страниц, а общий объем всех архивированных данных превышает 10 петабайт. Здесь хранится история Интернета в целом и интернет — бизнеса в частности.
Благодаря своей старой истории и общественно-социальной деятельности Archive. org является одним из самых трастовых сайтов интернета. Об этом можно судить по некоторым показателям:
org является одним из самых трастовых сайтов интернета. Об этом можно судить по некоторым показателям:
1. Возраст сайта — почти 20 лет (Registered On — December 14, 1995).
2. Google PR – 8 (Яндекс ТИЦ – 5200).
3. Большое количество проиндексированных страниц (~70 миллионов).
4. Данный ресурс входит в 250 самых посещяемых сайтов мира (согласно данным Alexa.com).
Archive.org может стать полезным для каждого вебмастера, если научиться его использовать в своих целях. Исходя из всего написанного, можно сделать вывод, что Архив довольно трастовая площадка для получения линков и создания доров. Также ее можно использовать по своему основному направлению, ведь это огромный ресурс для получения различного контента.
Начнем с самой интересной и актуальной на сегодняшний день темы – создание доров на сайте Archive.org. В Google вы без проблем найдете много примеров классических «профильных» доров на Archive .org по различным НЧ ключевым фарма – словам (для примера запрос Buy Tadalafil Prescription Supplement Cost – проверка по aol.
Конкретный дор использует картиночный фид от PPC, но рекомендуется делать красивые перенаправления на свои фарма шопы. Рассмотрим в общих чертах процедуру создания дора. Для начала нужно создать аккаунт. Для этого следует перейти по ссылке https://archive.org/account/login.createaccount.php и заполнить все поля:
«Screen name» особой роли не играет, url будущего дора вы будете формировать самостоятельно. Email нужно указывать реальный, а регистрацию аккаунта необходимо подтвердить. Проходят вариации в адресе Gmail (для вашего ящика [email protected], вы можете использовать безграничное количество вариаций, добавляя раномные символы со знаком +: [email protected], [email protected], и вся почта будет приходит в ваш ящик). Многие сервисы не принимают такой формат, заставляя регистрировать много новых ящиков. Но Archive.org пока не ввел дополнительную защиту.
Для того, чтобы создать дор по адресу http://archive.org/details/DOR необходимо залить какой-либо файл и в его описание уже вставить все, что вам необходимо. После логина вы сразу увидите синюю кнопку «Upload» в правом углу и, перейдя по ней, форму загрузки:
После логина вы сразу увидите синюю кнопку «Upload» в правом углу и, перейдя по ней, форму загрузки:
Заливать можно как html с тем же дором (но он не проиндексируется), так и просто какой-либо PDF на тему здоровья. Выбираем файл, нажимаем загрузить и попадаем в редактор:
Основные моменты:
1. Page title – тайтл страницы и будущего дора. Заполняется согласно целям.
2. Page url – часть адреса дора после /details/
3. Description – сам контент дора. Картинка для входа, кеи, текст и т.д.
4. Subject Tags – не очень важно, но помогает для того, чтобы дор был в поиске по Архиву, что гарантирует более быстрый индекс.
В результате чего получаем такой пример — https://archive.org/details/rxpssssssz. В некоторых случаях редактор может удалить ссылку, но есть возможность вставить ее обратно, нажав на Edit items (чтобы не удаляло, пишите изначально в формате a href=http://google.com – т.е. без кавычек после =).
Каждый сам может подобрать необходимую схему создания и заливки доров.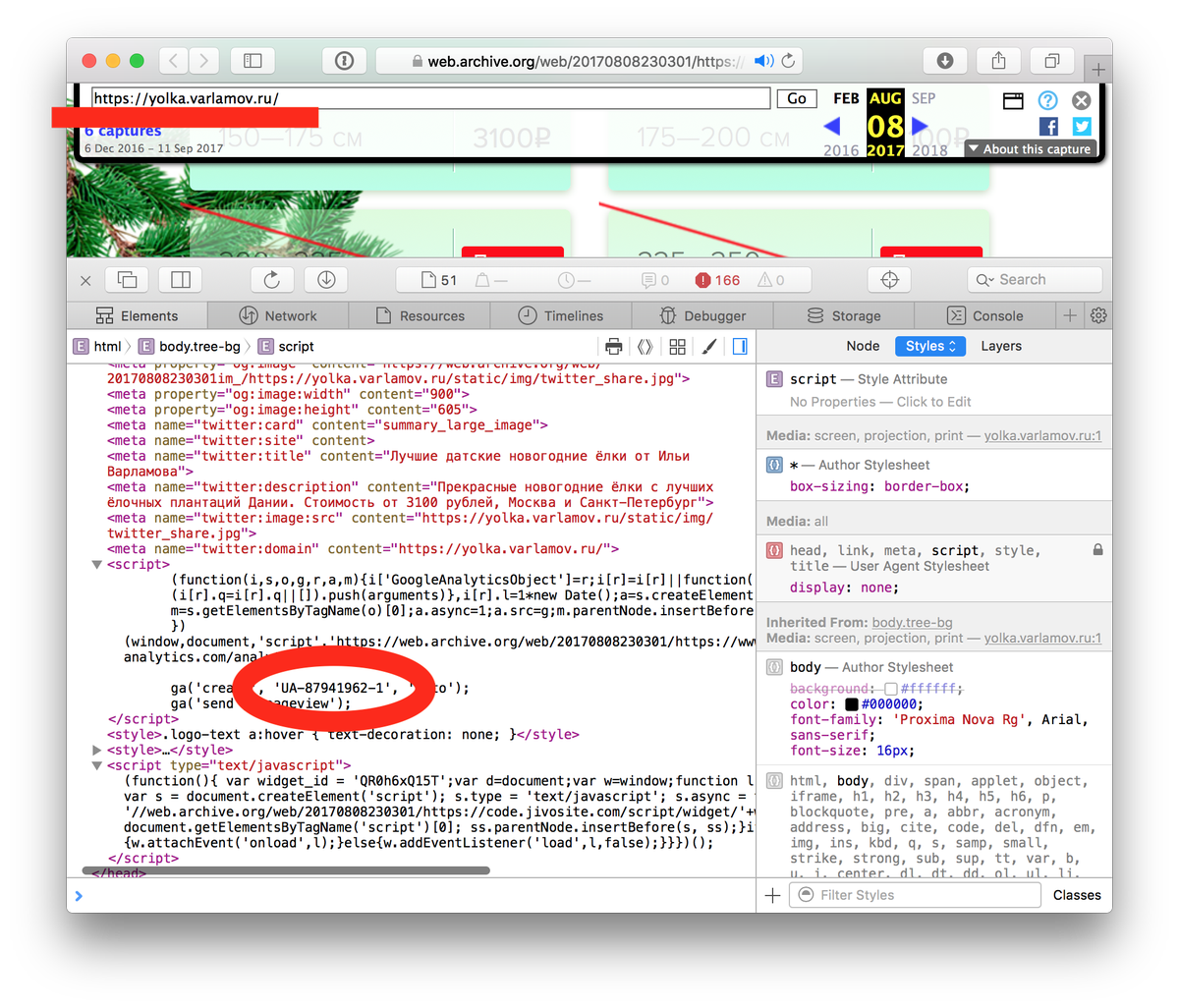 Добавляйте текст, кеи и эксперементируйте с оформлением. На странице https://archive.org/details/opensource_media выводятся последние обновления и комментарии (очень медленно и непонятно), но на всяких случай, чтобы ускорить индексацию, напишите себе 1-2 обзора, так вы попадете в Recently Reviewed Items.
Добавляйте текст, кеи и эксперементируйте с оформлением. На странице https://archive.org/details/opensource_media выводятся последние обновления и комментарии (очень медленно и непонятно), но на всяких случай, чтобы ускорить индексацию, напишите себе 1-2 обзора, так вы попадете в Recently Reviewed Items.
Эти же обзоры (Reviews) помогут получить звездочки в сниппетах Googla, что повысит внимание в выдаче к дору:
Что дальше делать с дорами вы знаете. Аналогично можно использовать данные профиля для получения ссылочной массы. Правда везде будет Nofollow, о полезности которого ведутся постоянные споры. Но ссылка со столь трастового ресурса никогда не помешает.
Если вы все же решите ее получить, залейте какой-нибудь PDF файл с отчетом о последней конференции по лечению импотенции себе на сайт. Такой же залейте в archive.org, а в описании источника укажите, что вы нашли его именно на своем сайте. Это обеспечит практически вечную ссылку. За деятельностью «коллег по цеху» вы можете наблюдать благодаря внутреннему поиску. http://archive.org/search.php?query=subject%3A%22viagra%22:
http://archive.org/search.php?query=subject%3A%22viagra%22:
Перейдем к следующему сервису от Archive.org , а именно — Web.Archive или WayBack Machine. Поисковые роботы данного сервиса обходят сайты и архивируют их на своих серверах, создавая копии для истории. Естественно, что сайты довольно часто перестают существовать, и копии в web архиве остаются единственным напоминанием о них.
Данные сайты можно восстанавливать и использовать для своих нужд. Можно использовать их как сателлиты, как площадки для ссылок на свои ресурсы или продажу, можно монетизировать с помощью Adsense или партнерских программ. Для начала необходимо определится с тем, какой именно сайт восстанавливать. Это довольно сложный вопрос и существуют несколько основных вариантов его решения:
1. Поиск информации на тематических площадках по продаже доменов. Перехватчики часто продают освобожденные домены с указанием того, есть или нет копия сайта в Web.Archive. Вы можете как купить домен и восстановить прежний сайт, так и просто узнать, какой сайт можно восстановить на новом домене, загнав его в индекс быстрее, чем это сделает потенциальный покупатель домена. Основной русскоязычной площадкой для покупки/продажи доменов является – доменфорум, смотрите также и на тематических форумах для вебмастеров.
Основной русскоязычной площадкой для покупки/продажи доменов является – доменфорум, смотрите также и на тематических форумах для вебмастеров.
2. Сбор данных об освободившихся доменах самостоятельно.
3. Покупка доменов на аукционах или просто использование информации с них. Подробно описано в хорошей статье https://www.rxpblog.com/work-with-auctions-buying-trusted-domains здесь.
Ну и конечно, если вы плотно работает в какой либо теме, вы прекрасно знаете своих конкурентов, их сателлиты и другие места, которые в случае краха можно восстановить для своих целей. Результаты наличия в Архиве доступны по адресу http://web.archive.org/web/*/http://rxpblog.com:
После того как мы определились ЧТО восстанавливать, понадобятся инструменты для этого. Когда домен и его наличие в Веб.Архиве являются известными факторами, можно сразу приступать к восстановлению. Но в случае, если вы используете списки удаленных доменов, первоначально необходимо проверить есть ли история для них в Архиве. Получить списки таких доменов можно различными способами: существует огромное количество online сервисов для deleted domains, как платных, так и бесплатных, чекеров и программ.
Получить списки таких доменов можно различными способами: существует огромное количество online сервисов для deleted domains, как платных, так и бесплатных, чекеров и программ.
Рассмотрим пример, как это делать с помощью «Определяйки» (официальный сайт программы — http://netpeak.ua/soft/opredelyayka/). После установки и запуска вам предложат список опций, по которым она будет проверять домены:
Отмечаем чекбокс – Возраст по Web.Archive, нажимаем кнопку «Загрузить», и если у сайта есть история в архиве, вы получите его возраст там, если нет – значение n/f. Потом делаете экспорт в файл Exel, сортируете и выбираете необходимые для работы данные.
Теперь есть список свободных доменов, которые могут быть перехвачены киберсквотерами. Но это не страшно, ведь в 90% случаев, если не больше, эти люди вешают домены на парковку или страницу продажи, абсолютно не интересуясь контентом из прошлой жизни сайтов с существующей историей в Архиве.
Для парсинга результатов Архива и их локального сохранения существует много различного софта, и выбор зависит исключительно от вас. Поиск нужно делать по термину — Web Archive Downloader / graber / parser. Рассмотрим процесс работы на примере довольно дешевого варианта — Web Archive Downloader . Качаем, покупаем ключ и запускаем (без ключа можно сохранять по 20 страниц с сайта). Выбираете года, которые интересуют:
Поиск нужно делать по термину — Web Archive Downloader / graber / parser. Рассмотрим процесс работы на примере довольно дешевого варианта — Web Archive Downloader . Качаем, покупаем ключ и запускаем (без ключа можно сохранять по 20 страниц с сайта). Выбираете года, которые интересуют:
Вставляете URL и нажимаете Get Url List:
Спустя N минут загрузится список доступных страниц. После этого нажимаете «Download» и начнется загрузка сайта на ваш хард-диск. Дальше сайт придется привести к товарному виду: поменять пути, поправить картинки и т.д., если автоматически этого сделать не удалось. Конечно, вы можете сделать тоже самое различными программами из категории Offline Explorer или найти более удачное ПО. Кроме извлечения сайта можно и просто брать текстовый контент для последующего применения. Статьи являются уникальными для поисковых систем и их можно смело использовать для наполнения своих сайтов и сателлитов.
Как же еще можно применить архив сайта в работе? Archive.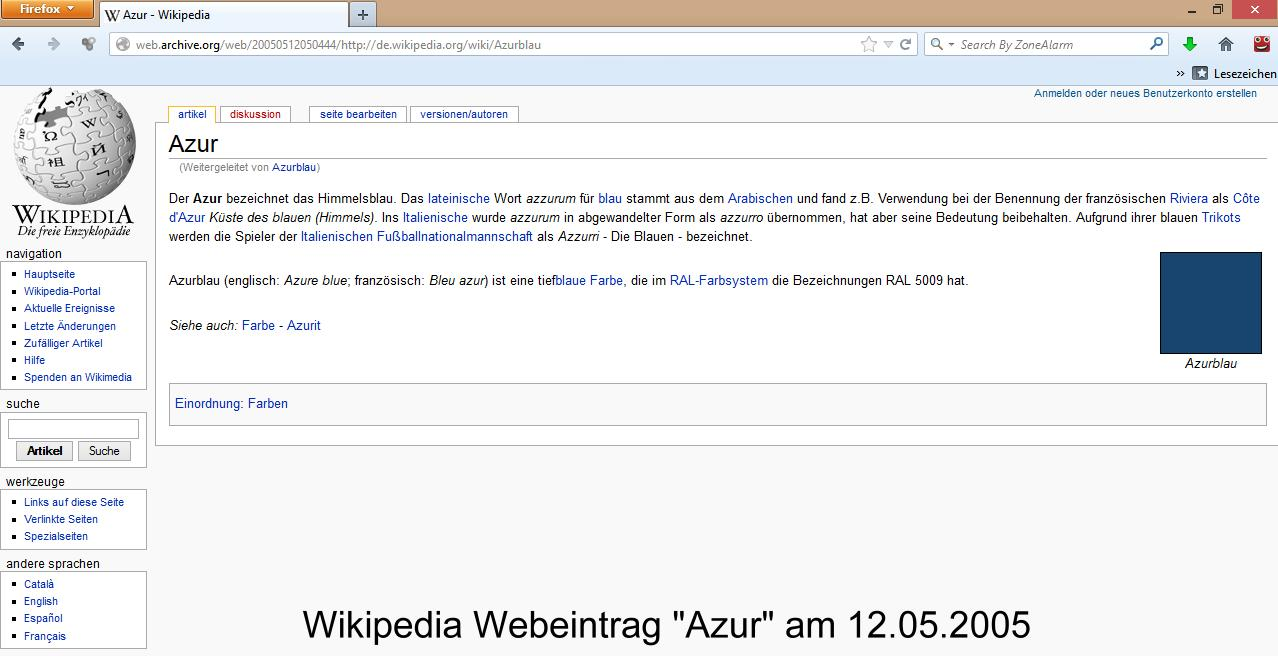 org — это огромный архив текстовой и медиа информации. Например, можно парсить книги, статьи и другой текстовый материал для последующей обработки и генерации в дорвейных технологиях или сплогах. Вбиваете в поиск, например, health и получаете список публикаций о здоровье:
org — это огромный архив текстовой и медиа информации. Например, можно парсить книги, статьи и другой текстовый материал для последующей обработки и генерации в дорвейных технологиях или сплогах. Вбиваете в поиск, например, health и получаете список публикаций о здоровье:
Практически у каждого результата будут варианты в .txt файле, которые легко сохранять и парсить для последующего использования. Чтобы добраться до файла в этом формате, необходимо нажать на HTTPS линк напротив All files&.
Кроме текстовой информации данный ресурс складирует и различные аудио и видео записи, которые тоже могут пригодиться для некоторых блогов и сайтов. Если вбить в поиск запрос health AND mediatype:audio, можно получить подкасты и различные записи с радиостанций на тему здоровья.
Или health AND mediatype:movies и получить ролики на тему здоровья. Правильное их использование может сильно повысить поведенческие факторы на ваших ресурсах.
Вот и все. Надеюсь, что каждый из вас по-новому откроет для себя этот чудесный сайт, а данная статья хоть чуть-чуть поможет в нашем нелегком деле. 🙂
🙂
Автор статьи: LoNduk.
«Архив интернета» могут навечно заблокировать в России
| Поделиться Россияне могут лишиться доступа к крупнейшему в мире архиву интернета, существующему с 1996 г. Против него действует Ассоциация по защите авторских прав в интернете, повлиявшая на блокировку библиотеки «Флибуста» и даже пытавшаяся заблокировать «Яндекс».Блокировка из-за фантастики и детективов
Ассоциация по защите авторских прав в интернете (АЗАПИ) хочет добиться блокировки в России «Архива интернета» (Internet Archive). Причина блокировки – присутствие в контенте ресурса копий аудиокниг российских писателей – Дмитрия Глуховского (вселенная «Метро 2033») и Дарьи Донцовой.
Internet Archive – американская некоммерческая ассоциация и одноименный веб-портал, представляющий собой крупнейшую электронную библиотеку Интернета. Это ресурс мирового масштаба, и он официально входит в Международный консорциум сохранения Интернета (International Internet Preservation Consortium).
Иски о блокировке archive.org (сайт «Архива интернета»), а их на момент публикации материала было как минимум два, АЗАПИ подала в Московский городской суд. По мнению Ассоциации, доступ к «Архиву» должен быть запрещен на всей территории России, притом навечно.
Хроника событий
АЗАПИ, по данным Роскомсвободы, действует в интересах издателя ООО «Аудиокнига», и началось все с аудиокниг по серии романов Глуховского «Метро 2033», к которым позже добавилось произведение Дарьи Донцовой «Третий глаз алмаз». Иск по этому делу (номер дела 3-0335/2019) был подан 13 марта 2019 г, а Мосгорсуд рассмотрел его 13 мая 2019 г., притом в экстренном порядке, и вынес вердикт в пользу истца. Решение вступило в силу 15 июня 2019 г.
Решение вступило в силу 15 июня 2019 г.
По решению суда, «Интернет архиву» и другим ответчикам («ДейтаВебГлобал Групп» и ООО «ТК Мароснет») было запрещено «создавать технические условия, обеспечивающие размещение» аудиокниг на веб-ресурсах, перечисленных в иске. Важно отметить, что представители «Интернет архива» участия в заседании не принимали, а о решении суда американская организация извещена не была.
Россию могут навсегда оставить без Архива интернета
Второй иск был подан 21 июня 2019 г. (номер дела – 3-0634/2019, ответчик – «Интернет архив»). В нем истец (ООО «Аудиокнига», как и в первом случае) требовал заблокировать сайт archive.org в России на постоянной основе. Заседание по иску состоялось 16 августа 2019 г., однако рассмотрение дела было отложено по причине отсутствия у АЗАПИ доказательств того, что «Третий глаз алмаз» действительно был записан в форме аудиокниги обществом «Аудиокнига», и что у него (общества) есть права на эту книгу.
Рассмотрение было назначено на 12 сентября 2019 г, и существует еще одна причина переноса – по информации Роскомсвободы, на решение Мосгорсуда по первому иску была подана жалоба, дата рассмотрения которой на 23 августа 2019 г. оставалась неизвестной. По обоим делам американскую организацию в российском суде представляют юристы Роскомсвободы и Центра цифровых прав адвокат Саркис Дарбинян и Екатерина Абашина.
оставалась неизвестной. По обоим делам американскую организацию в российском суде представляют юристы Роскомсвободы и Центра цифровых прав адвокат Саркис Дарбинян и Екатерина Абашина.
Борьба с добром и российской судебной практикой
Организация Internet Archive зарегистрирована в Сан-Франциско (Калифорния, США), а одноименный ресурс, согласно законам штата Калифорния, официально считается библиотекой. Организация располагает обширным списком партнеров, в число которых входят многие крупные организации со всего мира. К ним относятся, в частности, Национальный научный фонд США и Библиотека конгресса США
OSDU: что нужно знать об открытых стандартах работы с данными в нефтегазе
Новое в СХДВ России «Архив интернета» нередко используется российскими судами как доверенную третью сторону и источники информации, в том числе улик и доказательств расследования.
«Послужной список» АЗАПИ
АЗАПИ была основана в мае 2013 г.![]() издательствами АСТ и «Эксмо», которые на тот момент были ее единственными учредителями. Через общего владельца АЗАПИ родственна книжному онлайн-магазину «Литрес».
издательствами АСТ и «Эксмо», которые на тот момент были ее единственными учредителями. Через общего владельца АЗАПИ родственна книжному онлайн-магазину «Литрес».
«Архив интернета» — не первая цель АЗАПИ в борьбе за интеллектуальную собственность. К примеру, в сентябре 2013 г. была заблокирована популярная в России электронная библиотека «Флибуста». Бывший глава Ассоциации защиты авторских прав в интернете Олег Колесников в разговоре с CNews признал, что «нынешняя неработоспособность «Флибусты» случилась благодаря его ассоциации». К слову, в тот же день «Флибуста» сумела прорвать блокировку и вновь стала доступной всем пользователям. На 23 августа 2019 г. эта библиотека была включена в список запрещенных в России ресурсов, и доступ в нее без спецсредств был закрыт окончательно.
В январе 2014 г. АЗАПИ пошла войной на торрент-трекер «Рутрекер» (навечно заблокирован в России с ноября 2015 г.) и начала готовить против него иск. Причиной стали поддерживаемые трекером раздачи архивов электронных библиотек «Флибуста» и «Либрусек», затрагивающие интересы основателей АЗАПИ, издательств «Эксмо» и АСТ. В августе 2016 г. «Эксмо» при содействии АЗАПИ попыталось через Мосгорсуд заблокировать доступ к «Яндексу» из-за ссылок в поисковой выдачи на скачивание книг из Rutracker. Однако Мосгорсуд отклонил это требование, поскольку доступ к Rutracker и так заблокирован.
В августе 2016 г. «Эксмо» при содействии АЗАПИ попыталось через Мосгорсуд заблокировать доступ к «Яндексу» из-за ссылок в поисковой выдачи на скачивание книг из Rutracker. Однако Мосгорсуд отклонил это требование, поскольку доступ к Rutracker и так заблокирован.
В октябре 2016 г. история о борьбе с «книжными пиратами» получила неожиданное продолжение: в отношении действующего главы Ассоциации по защите авторских прав в интернете (АЗАПИ) Максима Рябыко возбуждено уголовное дело по по подозрению в вымогательстве p50 млн с владельца интернет-магазина.Эту информацию не называя фамилий, подтвердили в МВД России. Представительница МВД Ирина Волк заявила, что в кафе в центре Москвы в четверг были задержаны двое мужчин, подозреваемых в мошенничестве.
Несмотря на подозрения в совершении преступления, Максим Рябыко остается главой АЗАПИ
Сам Максим Рябыко, общаясь с прессой, свое задержание категорически опроверг. «Меня никто не задерживал, я не знаю, откуда появилась такая информация», — заявил он, пояснив, что «узнал о своем задержании из СМИ». На 23 августа 2019 г. Рябыко по-прежнему находился на должности генерального директора АЗАПИ.
Архив всех страниц вк. Эффективные и рабочие способы посмотреть удаленную страницу в вконтакте
Может так получиться, что страница пользователя, которую вы еще пару дней назад спокойно посещали, оказывается удаленной. Вопрос: можно ли как-то посмотреть эту страничку и если да, то как это сделать?
Удаленную страницу посмотреть можно, но не во всех случаях, поэтому гарантию давать не будем. Существует два способа ее увидеть.
Архив интернета
Существует так называемый архив интернета — это сайт, где сохранены страницы многих сайтов, включая и те, которые продолжают работать, и те, которых давно не существует. Вполне возможно, что страница нужного вам пользователя была загружена в этот архив.
Заходим на сайт archive.org. Появляется форма для поиска. Вводим адрес странички и нажимаем клавишу Enter. В качестве примера мы будем использовать страничку Павла Дурова.
Если страница есть в архиве, вы узнаете об этом: система покажет все сохраненные версии страницы по состоянию на ту или иную дату. Просто нажимаем на нужную дату, например, самую последнюю из имеющихся в архиве, и смотрим страничку. Даты выделены голубым на скриншоте.
Только помните о том, что даже если страница есть в архиве, но при этом она доступна только пользователям ВК для просмотра, вы увидите следующее:
Кэш поисковиков
Можно попробовать посмотреть страницу через кэш поисковиков. Рекомендуем пользоваться Yandex или Google.
Открываете поисковик и вводите адрес странички пользователя, затем нажимаете «Найти».
Как видите, страничка найдена. Вам нужно нажать на кнопку, выделенную стрелкой, после чего кликните на ссылку «Сохраненная копия».
Открывается сохраненная страничка в кэше поисковика.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :
А о сборе информации про людей читайте в статьях и .
Слово кэш можно услышать довольно часто в разных сферах ИТ, сегодня же мы будем разбираться с кэшем страниц сайта. Сам термин означает сохранение поисковыми системами копий страниц от определенного числа, как правило от последнего посещения роботом сайта. Вы можете в любой момент найти и использовать копию (кэш) страницы для своих потребностей.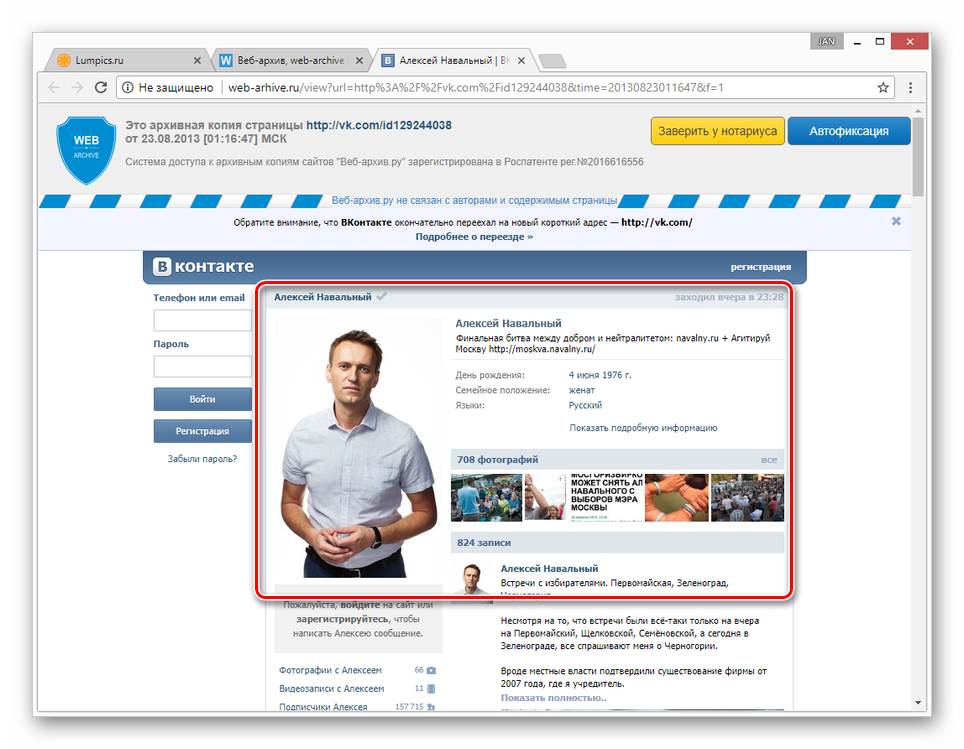
Это довольно таки хорошо, что поисковики сохраняют на некоторое время страницы на своих серверах и дают нам шанс воспользоваться этим. На хранение кэшированных страниц выделяется много ресурсов и денег, но свою помощь они окупают, так как нам все равно необходимо заходить на их поисковые системы.
Для чего нужен кэш (копии) страниц
Бывают разные ситуации при работе с сайтами.
Как всегда работы у Вас много, а времени мало и внимательности на все не хватает. Бывают случаи, когда ведутся работы с сайтом, предположим изменение дизайна или мелкие правки по шаблону, тексту. И в один момент понимаете, что где-то допустили ошибку и пропал текст или исчезла часть дизайна сайта. Ну бывает такое и каждый наверное с таким имел дело.
На данный момент, бэкапов у Вас нету, у тоже и не помните как выглядело все изначально. В этом случае помочь сможет копия страницы, которую можно найти в кэше как Яндекса, так и в Гугла, посмотреть как было изначально и поправить.
Или второй случай , Вы изменили немного текст, для того, что бы повысить и хотите посмотреть обновилась страница на которой внесли изменения или нет. Проверить можно с помощью страницы, которая находится в кэше, для этого ищем данную страницу и смотрим на результат.
Проверить можно с помощью страницы, которая находится в кэше, для этого ищем данную страницу и смотрим на результат.
Так же бывает ситуация, когда сайт не доступен, по той или иной причине, а вам необходимо на него зайти. В этом случае может помочь копия страницы которую можно найти ниже перечисленными способами.
В общем я думаю, стало ясно, что пользоваться кэшем страниц нужно и полезно.
Как найти страницу в кэше Google, Yandex
Для начала давайте рассмотрим как искать в поисковой системе Google.
Способ №1.
Вы заходите на страницу поисковой системы и прописываете адрес страницы которую хотите найти и посмотреть копию. Я возьму для примера наш сайт:
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим , где отображается страница которую вы искали. Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Способ №2.
Способ можно назвать полуавтоматическим, так как необходимо скопировать адрес, что находится ниже и вместо site.ru подставить домен своего сайта. В результате Вы получите туже самую копию страницы.
http://webcache.googleusercontent.com/search?q=cache:site.ru
Способ №3.
Можно просматривать кэш с помощью плагинов для браузеров или онлайн сервисов. Я использую для этих целей .
Здесь можно посмотреть когда последний раз заходил робот на ресурс, соответственно и копия страницы будет за это число.
Теперь рассмотрим как искать кэш в поисковой системе Яндекс.
Способ №1.
Способ такой же как и для системы Google. Заходим на страницу поисковой системы и прописываете адрес страницы которую хотите найти и посмотреть копию. Снова возьму для примера наш сайт и пропишу:
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим поисковую выдачу, где отображается страница которую вы искали.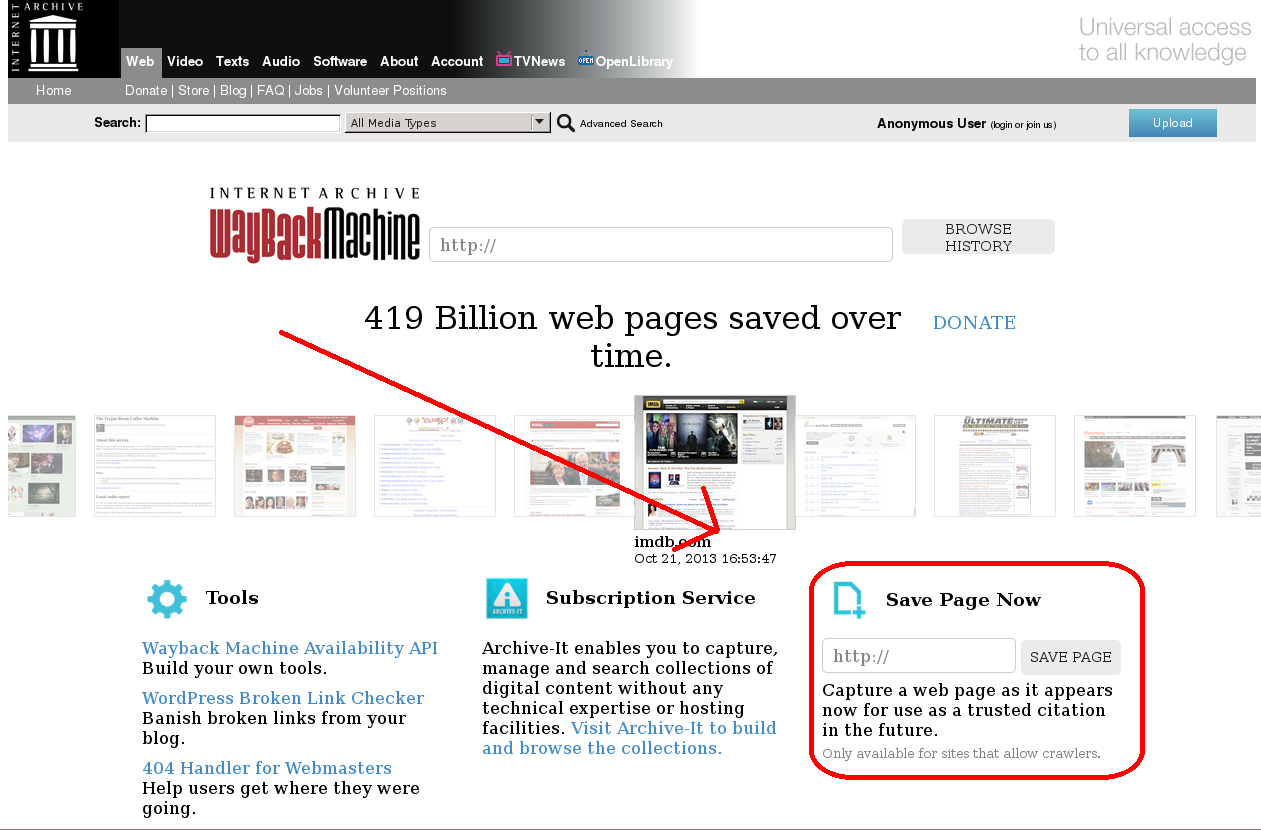 Смотрим на сниппет и там де с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Смотрим на сниппет и там де с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Способ №2.
Используем дополнительные плагины для браузеров. Читайте немного выше всё так же как и для Google.
Если страница не находится в , то большая вероятность того, что ее нету и в кэше. Если страница была ранее в индексе, то возможно она сохранилась в нем.
Как очистить кэш в Yandex, Google
Бывает необходимо убрать страницу из кэша Яндекса или Гугла или вообще скрыть страницу которая ранее индексировалась и кешировалась от посторонних глаз. Для этого необходимо дождаться пока поисковая система сама выкинет данную страницу естественным путем если Вы ее предварительно удалили. Можно запретить индексировать страницу в файле или использовать тег:
Только смотрите аккуратно с тегом, не поставьте его в общий шаблон сайта ибо будет запрет на кэширование всего сайта. Для этих целей лучше всего используйте дополнительные плагины или программистов которые ранее занимались такой работой.
Для этих целей лучше всего используйте дополнительные плагины или программистов которые ранее занимались такой работой.
Теперь давайте посмотрим как средствами поисковой системы Google и Яндекс можно очистить кэш (очистить, удалить страницу).
Очистить кэш страницы в Google
Поисковая система Google к этому вопросу подошла с правильной стороны и создала такой инструмент как «Удалить URL-адреса » в Webmaster Tools. Что бы им воспользоваться необходимо зайти в инструменты вебмастера по адресу:
www.google.com/webmasters/
Очистить кэш страницы в Google Webmaster
Для того, что бы очистить кеш или удалить полностью страницу (а так же можно сразу удалить и очистить кэш вместе), необходимо нажать на кнопку «Временно скрыть » и ввести url адрес страницы которую необходимо очистить и нажать кнопку «Продолжить «.
Теперь в данном окне при нажатии на список «Тип запроса » можно увидеть несколько способов удаления и очистки как страницы с индекса гугла так и очистки кєша.
- Если Вам необходимо полностью удалить страницу и cache, то используем первый способ.
- Если необходимо просто очистить его, то используем второй способ. Как правило для нашего примера нужно использовать именно его. Страница остается в индексе, но кэш удаляется и при следующем приходе робота, она снова появится там.
- Если необходимо временно скрыть, то используем третий способ. Используется в том случае когда не успевают наполнятся страницы качественным контентом. В данном случае скрыть ее на некоторое время будет лучше.
Как только выбираете один из способов, в данном случае 2й, нажимаем на кнопку «Отправить запрос «.
После нажатия получаем страницу, где можно увидеть, что данная страница добавлена на удаление из кэша и находится в статуже «Ожидание «. Теперь остается только ждать. Как правило данная процедура занимает от нескольких минут до нескольких часов.
Если Вы не правильно указали страницу и хотите сделать отмену, то можно нажать на кнопку «Отмена «.
После того как вы через некоторое время зайдете в инструмент «Удалить URL-адреса», можно будет увидеть статус «Выполнено». Это означает, что робот Гугл зашел на страницу и очистил ее историю.
Очистить (удалить) страницу в Yandex
У поисковой системы Яндекс есть похожий инструмент в инструментах для вебмастеров, но здесь есть одно «НО». Очистки кэша как такового нету, можно целиком удалить страницу из индекса ПС и при этом удалится вся ее история.
Для того, что бы воспользоваться данным инструментом необходимо зайти в Yandex webmaster по ссылке:
webmaster.yandex.ua/delurl.xml
и в строку ввести необходимый урл.
Поисковая система исключит данный адрес через некоторое время «АП». Как правило у Яндекса на это уходит пару ней, поэтому необходимо будет подождать.
Если у Вас есть вопросы задавайте их в комментариях, мы всегда на связи!
Интернет — вещь абсолютно не постоянная. Любой сайт в силу различных обстоятельств (обрывы линий электропередач, банкротство хостера, неоплата домена) может перестать работать. В браузерах пользователей после этого отобразятся только сообщения о недоступности любимого ресурса. Если же сайт изменится до неузнаваемости, а страницу с важной информацией удалит администрация, ресурс продолжит свою работу, но конечному потребителю неприятностей в этом случае не избежать.
В браузерах пользователей после этого отобразятся только сообщения о недоступности любимого ресурса. Если же сайт изменится до неузнаваемости, а страницу с важной информацией удалит администрация, ресурс продолжит свою работу, но конечному потребителю неприятностей в этом случае не избежать.
Не стоит волноваться и проклинать злой рок. Быть может, портал недоступен временно, а специалисты заняты восстановлением его работы. Помимо этого, у каждого пользователя Глобальной сети есть мощный инструмент, который позволит получить необходимую информацию, — кэш сайтов.
Google — мегакорпорация, мощности серверов которой имеют возможность постоянно сканировать Интернет на предмет появления новых страниц и изменения старых. Добавляя ресурсы в свою базу, алгоритмы не только но и делают их снимки. Грубо говоря, Google создает резервные копии Интернета на тот случай, если исходный материал станет недоступным.
Кэш сайтов Google доступен всем без исключения. Чтобы получить доступ к любой проиндексированной странице, в строку поисковика требуется ввести запрос: . На экране отобразится копия страницы, в верхней части экрана будет показана следующая информация:
На экране отобразится копия страницы, в верхней части экрана будет показана следующая информация:
- Дата последнего сохранения, что даст возможность судить, могла ли измениться представленная информация.
- Здесь же располагается ссылка на снимок, в котором содержится только текст.
- Еще один URL покажет полный исходный код, который заинтересует веб-мастеров.
Владельцам ресурсов в Интернете нужно знать, что кэш сайтов компании Google — добровольная в использовании система. Если необходимо исключить какие-либо страницы вашего портала из списка сохраненных, можно запретить делать снимки. Для этого на страницу нужно добавить метатег . Также запретить или разрешить кэширование можно в рабочем кабинете, если вы имеете соответствующий аккаунт.
Если же вам нужно удалить уже сохраненные снимки из кэша Google, потребуется отправить электронное письмо с запросом, а потом подтвердить свои права на сайт.
«Яндекс»
На втором месте в списке компаний, сохраняющих кэш сайтов, располагается отечественный гигант индустрии. Охват «Яндекса» намного меньше, поэтому здесь стоит искать в основном снимки крупных, обладающих высокой посещаемостью ресурсов.
Охват «Яндекса» намного меньше, поэтому здесь стоит искать в основном снимки крупных, обладающих высокой посещаемостью ресурсов.
Просто введите в поисковую строку URL нужной страницы и нажмите ENTER. Результаты поиска покажут необходимый вам сайт на первом месте выдачи. Рядом со ссылкой на него будет располагаться иконка в виде треугольника. Кликнув на нее и выбрав пункт меню «сохраненная копия», откроете последний доступный снимок страницы.
The Wayback Machine
В 1996 году Брюстер Кейл открыл некоммерческую организацию, которую сейчас называют архивом Интернета. Компания занимается сбором копий веб-страниц, видеоматериалов, графических изображений, аудиозаписей, программного обспечения. Собранный материал архивируется, а бесплатный доступ к нему может получить любой желающий.
Главная цель The Wayback Machine — сохранение культурных ценностей, созданных цивилизацией после широкого распространения Интернета, создание наиболее полной электронной библиотеки человечества. В настоящий момент в Архиве хранится более 10 петабайт данных, что позволяет пользователям ознакомиться с 85 миллиардами веб-страниц. Это значит, Архив — наиболее полный кэш сайтов.
В настоящий момент в Архиве хранится более 10 петабайт данных, что позволяет пользователям ознакомиться с 85 миллиардами веб-страниц. Это значит, Архив — наиболее полный кэш сайтов.
Archive.org — сайт организации, на нем можно попытаться найти снимок необходимой страницы. Так как сохраняется не только последняя копия, а бот просматривает ресурсы периодически, можно изучить все изменения, сделанные на определенной странице с течением времени, даже если сайт уже не существует. В строке поиска желательно использовать префикс WWW.
Dead URL
«Мертвый адрес» предоставляет для пользователей похожие возможности. Скопируйте из нерабочий URL и вставьте его в поле ввода на сайте. Сервис немного подумает и выдаст несколько результатов. Некоторые из них будут ссылаться на ресурс компании Google. Другая часть приведет пользователя на страницы Архива. Что немаловажно, сортируется кэш сайтов по дате, а это очень удобно.
Down Or Not
Если вам необходим кэш сайтов в Интернете в связи с недоступностью того или иного ресурса, но поиски ни к чему не приводят, стоит проверить, не рядом ли с вами проблема. Например, провайдер Интернета выполняет технические работы или заменяет устаревшее оборудование. Для проверки, кто виноват, есть смысл воспользоваться сервисом Down Or Not (Жив или нет).
Например, провайдер Интернета выполняет технические работы или заменяет устаревшее оборудование. Для проверки, кто виноват, есть смысл воспользоваться сервисом Down Or Not (Жив или нет).
Введите адрес необходимого вам портала в строку поиска и нажмите на кнопку ENTER. После недолгого анализа сервис выдаст результат. Слово DOWN указывает на недоступность ресурса (временную или постоянную), если же на экране появится слово UP — значит, с порталом всё в порядке.
Down Ot Not выступает в роли стороннего и непредвзятого эксперта, чтобы определить, что именно является источником проблемы.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.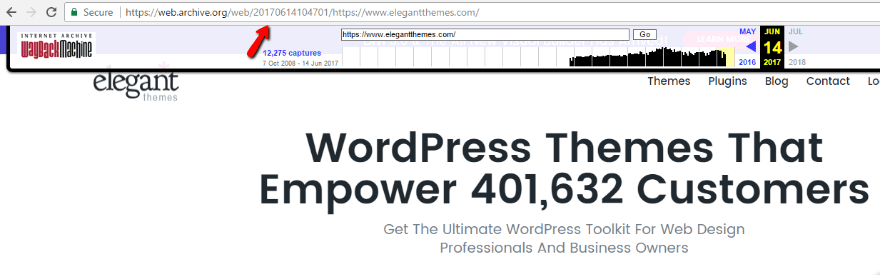 com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на
Для начала можно пробить контакты, связанные с сайтом на
Как архивировать материалы из открытых источников
Все картинки в этой статье доступны в полном размере при нажатии на них.
Проводя расследования по открытым источникам, важно задумываться над тем, как архивировать материалы, которые вы изучаете. Например, пользователь может удалить пост в социальной сети уже после публикации вашего расследования, или видео с шокирующими кадрами (например, военного преступления в Сирии) может быть удалено из-за цензурной политики YouTube.
Существуют две основных причины необходимости архивировать все цифровые свидетельства, применяемые в расследовании: сохранение их на случай удаления из оригинального источника и доказательство аудитории, что материал (если он был удален) действительно существовал в том виде, в каком вы его представляете. Скриншоты легко подделать, поэтому крайне важно найти способ сохранять материалы так, чтобы показать, что вы не могли изменить их содержание.
Для большей часть контента, в том числе постов в социальных сетях, новостных статей и других веб-страниц, имеется два сервиса, которые обычно срабатывают: Archive.today и Archive.org. Эти сайты сохраняют веб-страницы на собственных серверах, после чего они становятся доступны по ссылке. Кроме того, оба сайта сохраняют страницы на конкретный момент времени, поэтому можно наблюдать изменения между разными архивациями, например до и после вырезания информации из статьи. Мы рекомендуем сохранять материалы на обоих сайтах, чтобы максимизировать количество архивируемого контента. Мы кратко опишем работу обоих сайтов и их эффективность при архивировании страниц различных популярных социальных сетей. В целом Archive.today более приспособлен для сохранения страниц в социальных сетях, так как делает это через специально созданный аккаунт, тогда как archive.org видит только полностью публичные страницы, не требующие аккаунта.
Archive.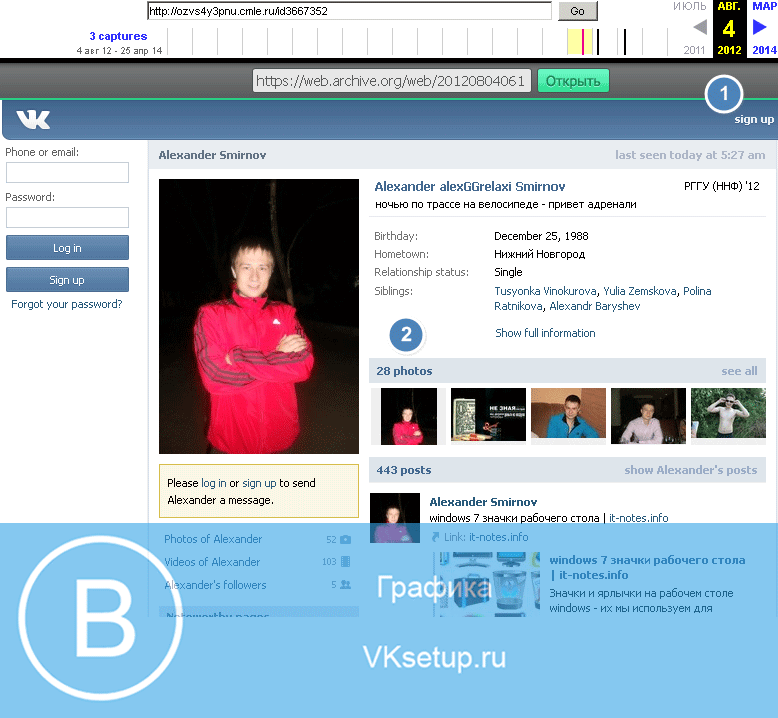 today
todayИз двух основных сайтов-архиваторов Archive.is более эффективен при работе с социальными сетями. Однако он действует далеко не так давно, как archive.org. Его следует считать менее стабильным, поскольку он гораздо скромнее по масштабам. Кроме того, этот сайт заблокирован в различных странах, поскольку экстремистский контент иногда распространяется через ссылки на archive.today. Альтернативные ссылки на этот сайт (Archive.is, Archive.li, Archive.ch…) позволяют обойти цензуру некоторых (но не всех) стран, например России, Китая и Финляндии.
Archive.today сохраняет страницы исключительно по запросам пользователей, а не автоматически, как Archive.org. Чтобы сохранить страницу на этом сайте, просто введите в поле в красном прямоугольнике ссылку на страницу, которую хотите сохранить.
Вы также можете архивировать страницы, сохранив закладку в вашем браузере, что позволяет сохранять в один клик страницы, на которых вы находитесь. Для этого сохраните новую страницу в ваших закладках (или избранном) со ссылкой:
javascript:void(open(‘https://archive.
today/?run=1&url=’+encodeURIComponent(document.location)))
 today/?run=1&url=’+encodeURIComponent(document.location)))
today/?run=1&url=’+encodeURIComponent(document.location)))Теперь просто нажмите на вновь созданную закладку, чтобы сохранить любую страницу, открытую у вас в браузере.
Кроме того, можно перетащить кнопку на заглавной странице Archive.today на вашу панель закладок, чтобы не создавать закладку вручную.
Чтобы проверить, сохраняли ли уже какую-либо ссылку, введите ее в поле в синем прямоугольнике.
Есть более продвинутые способы поиска сохраненных страниц, если вы не знаете точную ссылку. Например, если вы хотите найти все заархивированные статьи Bellingcat с тегом MENA (Middle East North Africa, Ближний восток и Северная Африка), введите в поиск следующее:
Звездочка в конце ссылки позволит найти все статьи на сайте Bellingcat, ссылки на которые начинаются с “news/mena”. Сюда входят все статьи в разделе “MENA” нашего сайта.
В результатах появятся статьи, вручную сохраненные пользователями, которые ввели ссылку, а также страницы со ссылками на базу данных сохраненных страниц Archive. org. В некоторых случаях можно открыть различные версии одной и той же страницы, если в статью вносились изменения.
org. В некоторых случаях можно открыть различные версии одной и той же страницы, если в статью вносились изменения.
Еще одна полезная функция Archive.today — возможность сохранить целую страницу как изображение, даже если она очень длинная. Однако это не следует использовать как замену ссылке на архив, поскольку скриншоты можно редактировать после сохранения.
Archive.today относительно успешно архивирует страницы в социальных сетях, однако его работа далеко не идеальна. Ниже приведены сохраненные страницы из различных социальных сетей. Как правило, заархивировать страницу социальной сети, защищенную некими настройками приватности, вроде «эту страницу могут видеть только друзья друзей» на Фейсбуке, с помощью сторонних архиваторов вроде Archive.today или Archive.org практически невозможно.
В примерах ниже нажмите на гиперссылку на каждую из социальных сетей, чтобы просмотреть сохраненную страницу на Archive.today.
Facebook:
Работает довольно хорошо, за исключением фотографий и видео, встроенных в посты.
Instagram:
Не работает.
Twitter:
Работает очень хорошо, за исключением встроенного в твиты контента, в частности фотографий, видео и ссылок.
ВКонтакте (ВК)
Работает очень хорошо, за исключением встроенных фотографий и видео.
Одноклассники (ОК)
Работает очень хорошо, за исключением встроенных фотографий и видео.
YouTube
Может сохранять только метаданные и текст, но не сами видео.
Archive.org
«Интернет-Архив», основанный в 1996 году, уже более 20 лет сохраняет веб-страницы и имеет значительный бюджет, что обеспечивает стабильность, на которую нельзя расчитывать в отношении Archive.today. Хотя у Archive.org есть множество замечательных проектов, в первую очередь нас интересует Internet Archive Wayback Machine (web.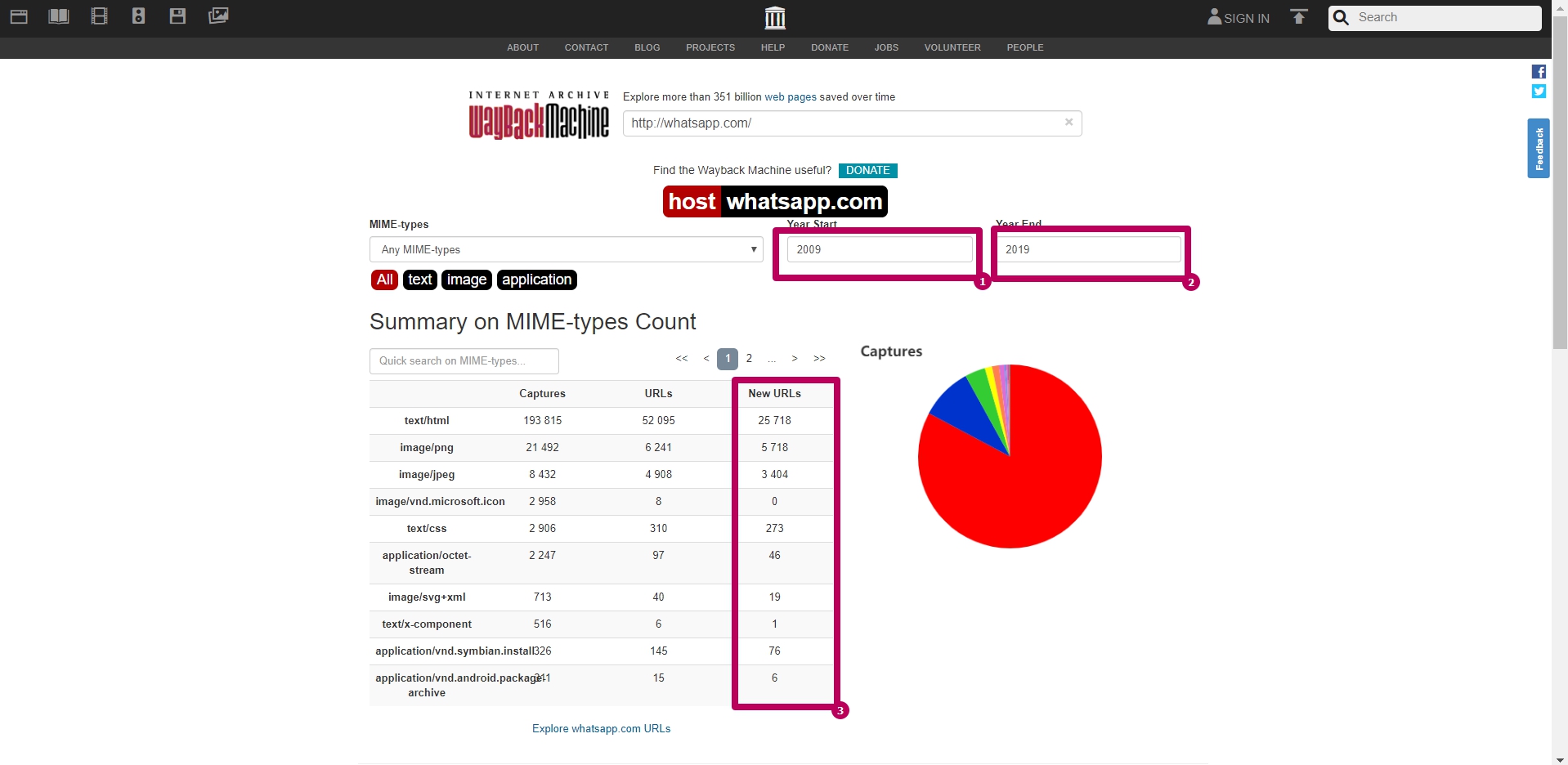 archive.org), которая позволяет пользователям архивировать конкретные страницы и просматривать страницы, заархивированные другими пользователями.
archive.org), которая позволяет пользователям архивировать конкретные страницы и просматривать страницы, заархивированные другими пользователями.
Как и в случае с Archive.today, процесс поиска и сохранения веб-страниц очень прост. Введите ссылку в строку поиска вверху страницы, чтобы посмотреть архивные версии. Чтобы сохранить страницу по ссылке, введите ее справа внизу.
В то время как Archive.today сохраняет страницы только по запросам пользователей, Archive.org использует как запросы пользователей, так и скрипты для автоматического сохранения страниц. Например, заглавная страница Bellingcat была сфотографирована более 800 раз со дня покупки домена в мае 2014 года. Наверняка лишь небольшая их часть была сохранена по запросам пользователей.
При сохранении обычных веб-страниц и новостных статей Archive.org часто дает фору Archive.today, поскольку позволяет переходить по клику на другие заархивированные страницы. Например, с помощью Internet Archive Wayback Machine можно перемещаться по значительной части сайта Bellingcat, как будто вы в 2014 году, поскольку все эти страницы были сохранены около 4 лет назад.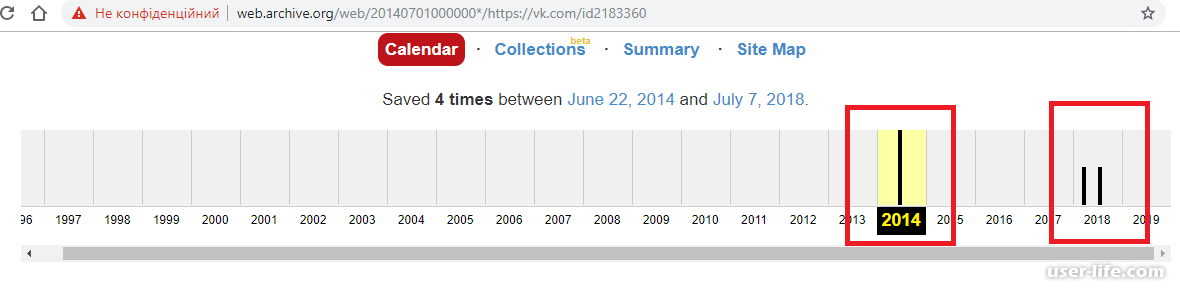 На Archive.today можно найти гораздо меньше заархивированных страниц.
На Archive.today можно найти гораздо меньше заархивированных страниц.
Archive.org хуже справляется с социальными сетями, чем Archive.today, но все равно иногда пригождается.
Хорошо работает с полностью публичными страницами, но, в отличие от Archive.today, не имеет доступа к страницам, которые требуют аккаунта на ФБ.
Не работает.
Работает очень хорошо, за исключением встроенного в твиты контента, в частности фотографий, видео и ссылок.
ВКонтакте (ВК)
Хорошо работает с полностью публичными страницами, но, в отличие от Archive.today, не имеет доступа к страницам, которые требуют аккаунта в ВК.
Одноклассники (ОК)
Хорошо работает с полностью публичными страницами, но, в отличие от Archive.today, не имеет доступа к страницам, которые требуют аккаунта на ОК.
YouTube
Не очень хорошо работает на основном сайте Wayback Machine, поскольку он плохо сохраняет даже метаданные и текст из видео.
Однако у Archive.org есть отдельный проект под названием YouTube Crawl, который архивирует видео с YouTube вместе с метаданными. Подробнее об участии в их проекте можно прочитать здесь. Это требует бОльших усилий, чем простое решенив в один клик на web.archive.org и archive.today.
Сохранение фотографий и видеоИз предыдущего раздела вы узнали, что ни Archive.org, ни Archive.today не могут сохранять фотографии и видео с Инстаграма и YouTube, а также испытывают проблемы при сохранении фотографий с Фейсбука, ВК и других сайтов. Создание сторонней «нейтральной» платформы для сохранения медиаматериалов с этих сайтов гораздо сложнее. Вместо этого, необходимо скачивать материалы отдельно, а затем предоставлять дополнительные материалы (например, скриншоты с метаданными, материалы на сайтах-зеркалах и т.п.), чтобы доказать подлинность скриншотов и видео.
YouTube
Имеется множество сайтов, позволяющих скачивать видео с YouTube, например KeepVid, Y2Mate и другие. Архивировать видео с YouTube совсем не сложно, если у вас есть достаточно места для их сохранения на жестком диске или в облаке. Не забудьте сделать скриншот метаданных и сохранить страницу на Archive.today, чтобы сохранить название, дату загрузки и описание, даже если само видео не сохранится на странице.
Архивировать видео с YouTube совсем не сложно, если у вас есть достаточно места для их сохранения на жестком диске или в облаке. Не забудьте сделать скриншот метаданных и сохранить страницу на Archive.today, чтобы сохранить название, дату загрузки и описание, даже если само видео не сохранится на странице.
К сожалению, архивировать страницы в Instagram очень трудно. Зачастую мы можем разве что надеяться на кросспост на другом сайте (многие сомнительные сайты «заимствуют» контент Instagram и размещают его у себя) или вручную сохранять изображения в полном разрешении.
Чтобы открыть фото в Instagram в полном разрешении, выполните следующую процедуру:
- Найдите ссылку на фотографию в Instagram и удалите все данные после ее ID. Например, для фотографии со ссылкой instagram.com/p/BfZJzBphUr1/ ID будет BfZJzBphUr1. Если после этого ID есть еще что-то (such as “taken-by=username”), удалите эту часть.
- Введите в конце ссылки “/media/?size=l” (строчная L). Для ссылки instagram.com/p/BfZJzBphUr1/ результат будет instagram.com/p/BfZJzBphUr1/media/?size=l
- Теперь откроется фото Instagram в максимально доступном разрешении в формате JPG. В случае упомянутого выше поста это даст следующий результат.

Чтобы сохранить видео с Instagram, можно воспользоваться различными сайтами вроде KeepVid, например Gramblast и DreDown.
Скачивать фотографии в высоком разрешении с Фейсбука значительно проще, чем с Инстаграма, поскольку эта функция встроена в пользовательский интерфейс сайта. Выберите «Опции», а затем «Сохранить» в меню фотографии, чтобы загрузить ее с серверов Фейсбука. Возможно, изображение будет не того же разрешения, что на фотокамере, но это лучшее, что можно загрузить с самого Фейсбука.
Сохранять видео с Фейсбука чуть сложнее, но все равно сравнительно просто. При просмотре видео нажмите на него правой кнопкой и выберите «показать ссылку».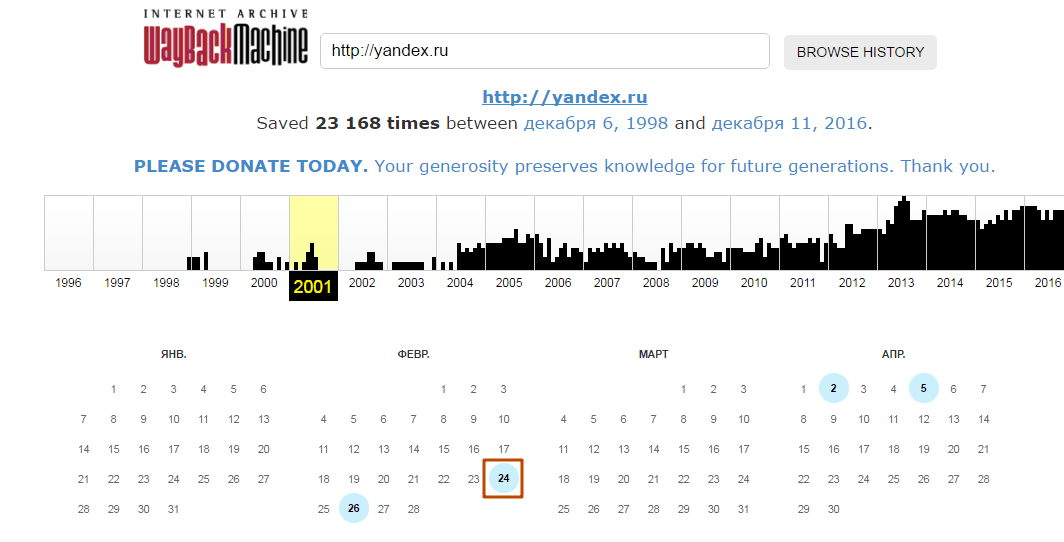 Теперь вы можете копировать эту ссылку и вставить ее на сторонний сайт, чтобы скачать видео.
Теперь вы можете копировать эту ссылку и вставить ее на сторонний сайт, чтобы скачать видео.
Как и в случае с YouTube и Instagram, имеется несколько сторонних сайтов, которые позволяют загружать видео с серверов Фейсбука на тот случай, если пользователь, который загрузил материал, удалит его. FBDown.net работает отлично, и на нем мало рекламы и всплывающих окон. Вставив ссылку на видео, которую вы скопировали из источника, вы можете скачать это видео в самом лучшем качестве по ссылке в красном прямоугольнике ниже.
ВК
Сохранять фотографии из ВК в полном разрешении очень просто: нужно выбрать «показать оригинал» в меню фотографии, и она откроется в максимальном доступном разрешении. Даже если пользователь удалит фотографию со своей страницы, ссылка в ВК с изображением в полном разрешении останется навсегда.
Сохранять видео из ВК немного сложнее, чем с YouTube, но это позволяют сделать различные бесплатные (и платные) инструменты. Например, GetVideo.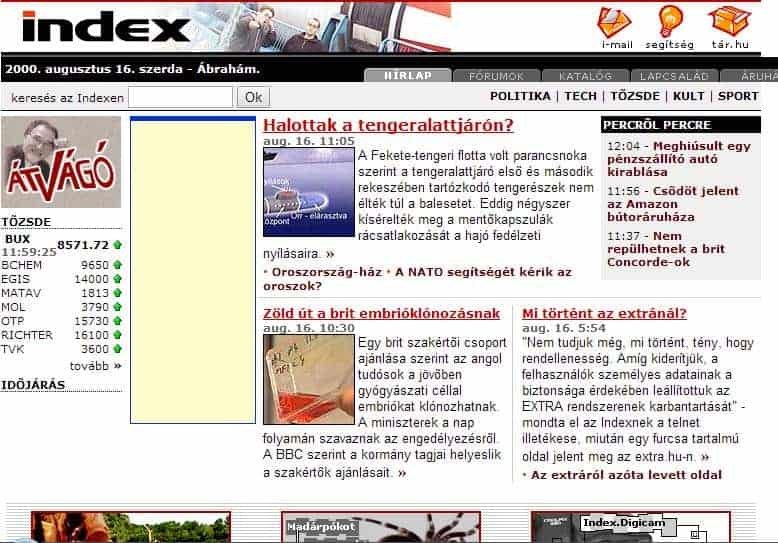 org позволяет скачивать видео, загруженные в ВК, в оригинальном разрешении. Чтобы получить ссылку на видео, нажмите на него правой кнопкой и выберите «Скопировать ссылку на видео».
org позволяет скачивать видео, загруженные в ВК, в оригинальном разрешении. Чтобы получить ссылку на видео, нажмите на него правой кнопкой и выберите «Скопировать ссылку на видео».
Следует отметить, что на GetVideo не следует нажимать “Best Quality”. Вместо этого выберите самое большое конкретное разрешение (напр. 720p). Учитывайте, что файлы с этого сайта скачиваются достаточно медленно.
ОК
Лучший способ сохранять фотографии в полном или почти полном разрешении — выбрать «на весь экран», а затем сохранить изображение или сделать скриншот.
Для скачивания видео с «Одноклассников» есть меньше сайтов, чем для других социальных сетей, однако они всё же существуют, например Video-Download.co.
Другие решения по архивацииЗачастую использовать описанные выше способы скачивания веб-страниц или видео невозможно, поскольку они защищены настройками приватности (что ограничивает доступ с таких сайтов, как Archive.today) или используют малоизвестные платформы для проигрывания видео, с которыми не работают такие сайты, как KeepVid. Все решения, приведенные выше в этом руководстве, бесплатные. Однако некоторые другие платные или условно бесплатные сервисы могут облегчить вам жизнь. Мы не станем рекомендовать вам, как тратить деньги, однако исследователи Bellingcat успешно использовали приведенные ниже решения (а одно даже разработали сами):
Все решения, приведенные выше в этом руководстве, бесплатные. Однако некоторые другие платные или условно бесплатные сервисы могут облегчить вам жизнь. Мы не станем рекомендовать вам, как тратить деньги, однако исследователи Bellingcat успешно использовали приведенные ниже решения (а одно даже разработали сами):
Некоторые программные решения позволяют загружать видео с большинства сайтов, даже если там не используется YouTube или другие популярные платформы. Video Download Capture от Apowersoft работает на удивление хорошо для практически всех встроенных видео, а также (в некоторых случаях) лайвстримов. Однако этот сервис требует оплаты для полноценного использования. Эта программа определяет, что в браузере проигрывается видео, а затем (обычно успешно) загружает его из оригинального источника. Если вы пытаетесь скачать конкретное видео и не можете найти другого решения, возможно, стоит воспользоваться пробным периодом этой программы. Если вы не можете воспользоваться пробным периодом или не хотите покупать эту программу, попросите в Твиттере автора этой статьи (@AricToler) помочь скачать конкретное видео.
В случае, если веб-страницы защищены настройками приватности, очень сложно найти решение, способное создать полноценную стороннюю архивную копию сайта. Простое сохранение страниц в формате HTML крайне неудобно, поскольку создает на жестком диске множество подпапок. Альтернативный вариант — сохранить страницу как PDF, либо распечатав ее в PDF (Файл -> Печать -> Распечатать в PDF), либо воспользовавшись Adobe Create для сохранения страницы в PDF.
При этом вполне возможно изменять содержимое страниц в самом PDF-файле. На данный момент возможно наиболее заслуживающий доверия, пусть и не идеальный способ демонстрации содержимого защищенной страницы — запись экрана (список простых решений для этой процедуры см. здесь) во время просмотра страницы.
Наконец, если вы ведете много онлайн-исследований и хотите воспользоваться автоматическим решением по слежению, чтобы восстановить свои шаги, предлагаем воспользоваться Hunch.ly, разработанным автором Bellingcat и мастером работы с Python Джастином Сейтцем. Когда этот плагин активен, он автоматически сохраняет каждую страницу, которую вы посещаете в ходе расследований. Если одна из этих страниц впоследствии будет удалена, а вы забудете ее заархивировать, на помощь придет Hunch.ly.
Когда этот плагин активен, он автоматически сохраняет каждую страницу, которую вы посещаете в ходе расследований. Если одна из этих страниц впоследствии будет удалена, а вы забудете ее заархивировать, на помощь придет Hunch.ly.
Используете ли вы другие сайты и ресурсы для архивации веб-страниц, изображений и видео? Предлагайте свои варианты в комментариях, если вы считаете, что их стоит добавить в это руководство.
Как узнать историю сайта | SeoProfy.ua
Если вы задумывались о том, есть ли история у сайтов? То она таки есть, и ее можно посмотреть.
Данная статья про то, как посмотреть и узнать историю сайта. Ведь дизайны сайта меняются постоянно, а так же у доменных имен появляются разные владельцы, и облик сайтов меняется.
В интернете существует сайт, который еще называют машина времени, только она работает только для прошлого. С помощью этого сайта мы и сможем узнать историю.
Принцип работы сайта заключается в том, что он индексирует сайты интернета, и сохраняет их в разное время.
Для начала переходим по ссылке: http://archive.org/web/web.php
Вводим адрес, например Google.com, и нажимаем смотреть:
Как мы видим, история для поисковой системы Гугл учитывается с 1998 года, дальше выбираем 1998 год, выбираем доступную дату и смотрим:
Дальше смотрим, как выглядел сайт поискового гиганта в то время.
А так выглядела поисковая система Яндекс в 1998 году:
Таким образом, мы сможем посмотреть любой нас интересующий сайт, особенно если сайт популярный, то его история записывалась постоянно.
В базе сервиса веб архива более 450 миллионов сайтов. Конечно, там не сохранены все сайты, но очень много. Сервис по просмотру истории сайтов абсолютно бесплатный и может пригодиться в разных случаях.
Основные моменты, когда нужно узнать историю сайта:
1. Узнать тематику сайта
С помощью веб архива мы сможем посмотреть содержание, которое было на домене, и узнать тематику ресурса.
2. Посмотреть каким сайт был в разные времена
Как я уже говорил, довольно таки часто люди забрасывают сайты, и многие seo оптимизаторы охотятся на такие домены, что бы сделать на них сайты. С помощью веб архива мы смотрим его содержание, его историю, и решаем, нужен ли нам такой домен.
Если вы хотите посмотреть и узнать историю сайта – используйте веб архив, это довольно таки полезный инструмент.
Помимо сайтов в веб архиве можно смотреть видео, музыку, картинки.
Оцените статью
Загрузка…Школа научных коммуникаций — arxiv.org
arxiv.org — препринтный сервер, самый популярный архив электронных публикаций научных статей и их препринтов по физике, математике, астрономии, информатике и биологии. Все публикации можно бесплатно скачивать в различных форматах (pdf, TeX, ps).
Архив был создан в 1991 году в Лос-Аламосской национальной лаборатории и первоначально предназначался для физических статей, но потом появились другие разделы.
Старое доменное имя архива — xxx.lanl.gov было изменено из-за того, что некоторые программы-фильтры блокировали доступ к сайту, воспринимая xxx как указание на порнографическое содержание. Существует множество национальных зеркал.
В настоящее время arXiv.org спонсируется и обслуживается Корнелльским университетом США. 29 декабря 2014 года в архиве стало ровно 1 миллион документов.
Многие журналы разрешают и поощеряют размещение рукописи статьи в архиве, перед направлением в журнал. Это способствует быстрой публикации результатов и получению дополнительных отзывов от читателей архива. После принятия рукописи к публикации в журнале, в описании документа в архиве добавляется ссылка на журнал. Достаточно большой процент работ в мире по физике и смежным областям, опубликованных в журналах с дорогой подпиской можно найти в архиве и бесплатно скачать.
При наличии препринта вы можете:
- срочно опубликовать свой результат, а затем уже направить в журнал (принятие статьи к публикации, взаимодействие с рецензентом, доработка материала может занимать 1-18 месяцев),
- получить несколько тысяч дополнительных просмотров вашей работы (многие ученые начинают свой рабочий день просматривая свежую подборку препринтов по их интересующей их тематике),
- получать цитирование на ваши научные результаты еще до выхода публикации в журнале,
- показать свои результаты всему миру, даже если статья не будет принята к публикации, препринт останется в базе, а результаты могут быть полезны другим исследователям.
Особенности:
- Для размещения первой публикации требуется рекомендация кого-либо из авторов, у которых есть публикации в архиве. Для всех последующих публикаций индоссамент не требуется. Если у публикации несколько соавторов, то проще размещать работу тому, у кого уже есть работы.
- Препринт проходит модерацию (длительность процедуры 1–3 дня) — проверку на соответствие разделу, формату, стилю изложения и т.п., но модерация ни в коем случае не является рецензированием.
- В архиве вы может разместить материал, который не может быть опубликован в научных журналах (подробную, расширенную версию статьи с подробными выкладками, с большим количеством иллюстраций и т.п.).
- Архив дает возможность скачать статьи без подписки на журналы.
- Известный русский математик Григорий Перельман, доказавший теорему Пуанкаре, направил статью об этом только на arXiv.org, не печатал ее где-либо ещё.
Существуют и другие аналогичные архивы, отличаются тематикой:
Загрузка и потоковая передача: Коллекция программного обеспечения Интернет-архива: Интернет-архив
Сборник приложений и программ для смартфонов, включая Android, Apple и … ну, остальные.
Коллекция программ APK (Android Package), загруженных разными пользователями.
Kodi (ранее XBMC) — это бесплатное приложение для медиаплеера с открытым исходным кодом, разработанное некоммерческим технологическим консорциумом XBMC Foundation.Kodi доступен для нескольких операционных систем и аппаратных платформ с программным 10-футовым пользовательским интерфейсом для использования с телевизорами и пультами дистанционного управления. Он позволяет пользователям воспроизводить и просматривать большую часть потокового мультимедиа, например видео, музыку, подкасты и видео из Интернета, а также все распространенные цифровые мультимедийные файлы из локального и сетевого хранилища …
Коллекция Vintage Software объединяет различные усилия групп по классификации, сохранению и предоставлению исторического программного обеспечения.Эти старые программы, многие из которых работают на неработающем и редком оборудовании, предназначены для изучения, образования и исторической справки.
Одним из наиболее исторически важных артефактов революции домашних компьютеров были условно-бесплатные компакт-диски, выпускаемые компаниями, содержащие сотни мегабайт условно-бесплатного программного обеспечения. Первоначально содержащие меньше, чем полная емкость дисков (600 МБ, позже 700 МБ), эти предметы в конечном итоге стали переполнены любыми компьютерными данными, которые можно было упаковать и продать.По мере того, как материал «кончился», то есть продавцы этих компакт-дисков обнаружили, что они не могут легко найти …
25.9 M 26M
19 октября 2018 г. 10/18
к Различный
По мере того, как старое программное обеспечение становится недоступным, различные группы и отдельные лица создают большие компиляции широкого диапазона названий и произведений, в результате чего часто получаются очень большие компиляции, которые затем становятся доступными в большом количестве.Некоторые из них представляют собой хорошо обслуживаемые каталоги, в то время как другие представляют собой просто архивные файлы большого размера. Этот сборник объединяет компиляции в одно место.
Это обширная и разнообразная коллекция программного обеспечения на компакт-дисках, то есть программного обеспечения, которое поставляется на компакт-диске для установки на компьютеры или воспроизведения на консолях. Расцвет CD-ROM — от приложений и игр до собраний общедоступного программного обеспечения или картинок — приходится примерно с 1989 по 2001 год.Во всех случаях емкость CD-ROM оставалась стабильной на уровне 640-700 МБ на сторону, хотя некоторые использовали уловки, чтобы заявить, что у них больше (из-за сжатия или сложения обеих сторон двусторонних CD-ROM). Большинство из них …
Библиотека программного обеспечения Internet Archive — это мечта любого любителя программного обеспечения: десятки тысяч игр, в которые можно играть, с разных компьютерных платформ, обеспечивающих мгновенный доступ к десятилетиям компьютерной истории в вашем браузере через эмулятор JSMESS.Намерение состоит в том, чтобы в конечном итоге получить доступ к большинству основных компьютерных платформ; в настоящее время коллекция включает компьютеры Apple II, Atari 800 и ZX Spectrum. В каждом случае под-коллекции содержат обширные наборы дисков и …
Темы: программное обеспечение, дискеты, образы, диски, эмуляция, Apple II, Atari 800, Atari 8-Bit, ZX Spectrum
19.9 M 20M
9 янв.201801/18
к Различный
Это образы программного обеспечения CD-ROM, для которых нет какой-либо другой важной документации или сканированных изображений.Хотя у них может быть полезная информация, для извлечения данных потребуются некоторые усилия.
Файл .ipa — это архивный файл приложения iOS, в котором хранится приложение iOS. Каждый файл .ipa включает двоичный файл для архитектуры ARM и может быть установлен только на устройстве iOS. Файлы с расширением .ipa можно распаковать, изменив расширение на .zip и разархивировав его. Большинство файлов .ipa нельзя установить в симуляторе iPhone, поскольку они не содержат двоичный файл для архитектуры x86.Для запуска приложений на симуляторе исходные файлы проекта, которые можно открыть с помощью Xcode SDK …
MS-DOS (/ ˌɛmɛsˈdɒs / em-es-doss; сокращение от Microsoft Disk Operating System) — операционная система для персональных компьютеров на базе x86, в основном разработанная Microsoft. Это был наиболее часто используемый член семейства операционных систем DOS и основная операционная система для персональных компьютеров, совместимых с IBM PC, в период с 1980-х до середины 1990-х годов.ЕСЛИ ВЫ ВОЗНИКАЛИ ЛЮБЫЕ ПРОБЛЕМЫ ПРИ ЗАПУСКЕ ЭТИХ ПРОГРАММ, ПОЖАЛУЙСТА, ПРОЧИТАЙТЕ FAQ. Спасибо eXo за вклад и помощь в этом …
Гостиная с консолью Internet Archive Console напоминает о революции в области домашнего очага, когда камин, а затем и телевизор, были превращены игровыми консолями в центр видеоигр. Эти игры были подключены через странные адаптеры и полагались на динамик телевизора для выдачи гудков и сигналов.Рынку домашних консолей приписывают постепенное смещение внимания с увлечения аркадами …
Этот элемент содержит движки, лежащие в основе «The Emularity», набора эмуляторов, оптимизированных для просмотра в браузере, включая версию MAME для JavaScript / веб-сборки, DOSBOX, SCRIPTED AMIGA EMULATOR и PCE. Щелкните ссылку «ПОКАЗАТЬ ВСЕ», чтобы просмотреть полную коллекцию файлов поддержки. Все файлы * .js.gz представляют собой модули javascript, выполняемые в браузере.Все файлы .json — это конфигурации работы эмулятора.
Программное обеспечение для машин MS-DOS, представляющих развлечения и игры. В сборник вошли боевики, стратегии, приключения и другие уникальные жанры игрового и развлекательного ПО. Благодаря использованию встроенного в браузер эмулятора EM-DOSBOX, эти программы можно загружать и воспроизводить. Имейте в виду, что эта эмуляция на основе браузера все еще находится в стадии бета-тестирования — свяжитесь с Джейсоном Скоттом, куратором программного обеспечения, если возникнут проблемы или вопросы.Спасибо eXo за вклад и помощь с этим архивом. Спасибо за ваш …
Это неофициальная коллекция загрузок «Redump», утверждающих, что они являются частью проекта Redump Disc Preservation Project, давней попытки создать архивные копии CD-ROM и DVD-ROM различных консолей и платформ на протяжении многих лет. Их не следует считать каноническими, хотя многие из них будут точными. Проект Redump находится по адресу & nbsp; http: // redump.org /
5,3 млн 5,3 млн
26 мая 202005/20
к CyberFlix TV
CyberFlix TV 3.2.3 для Android Mobile и TV OS
избранное2.3 Исправление для Android
Загруженное программное обеспечение из множества источников, в некотором роде указывает на то, что когда-то это был профессиональный продукт. Они не проверялись на точность, а проводились только общие проверки на наличие вредоносных программ / вирусов. Элементы добавляются в эту коллекцию автоматически.
CD-ROM с поддержкой операционных систем.
GBWA APK файл
Тема: gb whatsapp apk
ТВ v2.6.5
избранное
Cuco TV V 1.0.8 Adfree
избранноеfavoritefavoritefavorite (4 отзыва)
Тема: Cuco TV V 1.0.8 Adfree
Сделайте шаг назад во времени и вернитесь к своим любимым играм для DOS и Windows. Файлы, доступные в этой коллекции, состоят в основном из демонстраций для ПК, бесплатного и условно-бесплатного программного обеспечения.Эти файлы являются исходными выпусками, для установки и работы в современных операционных системах потребуются знания от среднего до продвинутого. По возможности онлайн-игра позволяет наслаждаться игрой прямо в браузере. В эту коллекцию регулярно добавляются новые файлы. Конкретные новости о крупных обновлениях …
Темы: компьютерные игры, винтажные компьютерные игры, игры для Windows, игры для DOS
IPVanish Apk
избранное
Commodore 64, также известный как C64 или CBM 64, представляет собой 8-битный домашний компьютер, представленный в январе 1982 года компанией Commodore International (впервые показан на выставке Consumer Electronics Show в Лас-Вегасе 7–10 января 1982 года).Он был занесен в Книгу рекордов Гиннеса как самая продаваемая модель одного компьютера за все время, по независимым оценкам, было продано от 10 до 17 миллионов единиц. Серийное производство началось в начале 1982 года, продажи в августе по цене 595 долларов США (что эквивалентно …
Это крупномасштабная коллекция взломанного программного обеспечения для Commodore 64: обычно содержит титульные экраны и анимацию взломщиков, а также модификации или чит-меню для программ внутри.Они включены, чтобы обеспечить легкий доступ ко всем версиям выпущенного программного обеспечения C64, хотя другие коллекции в библиотеке программного обеспечения C64 более сфокусированы.
Программное обеспечение, как правило, предназначено для более молодой аудитории, от образовательных до развлекательных. & Nbsp; Мы рекомендуем вам учитывать дату публикации и источник СМИ при принятии решения о том, является ли это хорошим ресурсом для вашего ребенка, и сначала проверить все на предмет соответствия возрасту
Фильм HD V 5.0.7 Adfree
избранное
Master Royale Infinity
Тема: Master Royale Infinity
Одним из наиболее исторически важных артефактов революции домашних компьютеров были условно-бесплатные компакт-диски, выпускаемые компаниями, содержащие сотни мегабайт условно-бесплатного программного обеспечения.Первоначально содержащие меньше, чем полная емкость дисков (600 МБ, позже 700 МБ), эти предметы в конечном итоге стали переполнены любыми компьютерными данными, которые можно было упаковать и продать. По мере того, как материал «кончился», то есть продавцы этих компакт-дисков обнаружили, что их не удалось легко найти …
Темы: Марк Фугитт, Майк Лейборн, сисоп, программное обеспечение RBBS
Film Plus V 1.1.8 Adfree
избранноеfavoritefavoritefavorite (1 отзывов)
Тема: Film Plus V 1.1.8 Adfree
Фильмы, сериалы и прямые трансляции бесплатно
Тема: apk
85,85286K
13 октября 2021 г. 21.10.2010 г.
к KineMaster Corp.
Видеоредактор Android
Темы: Редактор, Android
Flash-анимация или Flash-мультфильм — это анимационный фильм, который создается с помощью платформы Adobe Animate (ранее Flash Professional) или аналогичного программного обеспечения для анимации и часто распространяется в формате файла SWF.Термин «Flash-анимация» относится как к формату файла, так и к носителю, на котором создается анимация. Флэш-анимация пользуется популярностью с середины 2000-х годов, когда было выпущено множество анимационных телесериалов, телевизионных рекламных роликов и отмеченных наградами короткометражных фильмов в Интернете …
Центр эмуляции старой школы (TOSEC) — это инициатива ретрокомпьютеров, посвященная каталогизации и сохранению программного обеспечения, микропрограмм и ресурсов для микрокомпьютеров, мини-компьютеров и игровых консолей.Основная цель проекта — каталогизировать и проверять различные виды программного обеспечения и образов микропрограмм для этих систем. На момент выпуска 2012-09-15, TOSEC каталогизирует более 200 уникальных вычислительных платформ и продолжает расти. На данный момент проект идентифицировал и каталогизировал 466 396 …
6,7 млн 6,7 млн
8 октября 2019 г., 10/19
к NexStreaming Corp
Видеоредактор для Android
избранное
Вива ТВ 1.3.2v
Тема: Viva TV 1.3.2v
Cartoon HD V 1.0.1 Adfree
Тема: Cartoon HD V 1.0.1 Adfree
Скачать PLAYHUB + APK
Тема: Playhub + APK
Streamio V 1.3.4
Тема: Streamio V 1.3.4
Туби ТВ В.4.7.6 Adfree
Тема: Tubi TV V. 4.7.6 Adfree
Широкий выбор игр и развлекательного программного обеспечения для Commodore 64, в который можно играть в браузере.
GT IPTV APK
Тема: GT IPTV 2021
Internet Arcade — это веб-библиотека аркадных (монетных) видеоигр с 1970-х по 1990-е годы, эмулированная в JSMAME, части пакета программного обеспечения JSMESS.Содержая сотни игр самых разных жанров и стилей, Arcade обеспечивает исследования, сравнение и развлечения в сфере Video Game Arcade. Коллекция игр варьируется от ранних видеоигр «бронзового века» с черно-белыми экранами и простыми звуками до масштабных …
Old Movies V 1.14.0.6 Mod
избранное (обзоры 1)
Тема: Old Movies V 1.14.0.6 Mod
playtvgeh.net
избранное
Tea TV V 10.1.6r Adfree
избранное (отзывов: 1)
Тема: Tea TV V 10.1.6r Adfree
«Doom WAD — это формат файлов пакетов по умолчанию для Doom видеоигры или ее продолжения Doom II, которые содержат спрайты, уровни и игровые данные. WAD означает« Где все данные? »Сразу после его выпуска в 1993 году Doom привлек внимание значительное количество игроков, которые создали свои собственные моды для файлов WAD — пакеты, содержащие уровни, графику и другие игровые данные — и сыграли жизненно важную роль в создании культуры создания модов, которая теперь стала обычным явлением для шутеров от первого лица….
Max Movies V 1.0.3 Adfree
Тема: Max Movies V 1.0.3 Adfree
1,5 М 1,5 М
25 мая 202005/20
к Aptoide S.A.
Сторонний магазин приложений для Android TV OS
Тема: Aptoide TV Android TV OS
Фильмы и телешоу (в один клик) AD Free
Тема: apk
Содержание: Три условно-бесплатные версии DOOM, запускаемые непосредственно с компакт-диска Аудиоредакторы DOOM Редакторы карт DOOM Графические редакторы DOOM Интерфейсы и оболочки DOOM Часто задаваемые вопросы о DOOM Более 500 уровней / карт DOOM Insanity (Шутки о DOOM)
избранное видеоигры, DOOM, шутер от первого лица
ПЗУ, прошивки и дампы микросхем из самых разных источников.
Сборник наборов и сборников скинов (сменных интерфейсов) для долгоживущей компьютерной аудиопрограммы Winamp. & Nbsp;
PAGaytv geh 4.1
Темы: playtv geh, playtv geh
Xbox — это домашняя игровая консоль, первая часть серии консолей Xbox, производимых Microsoft.Он был выпущен 15 ноября 2001 года в Северной Америке, а затем в Австралии, Европе и Японии в 2002 году. Это был первый набег Microsoft на рынок игровых консолей. Это консоль шестого поколения, которая конкурировала с Sony PlayStation 2 и Nintendo GameCube. Это также была первая консоль, произведенная американской компанией с момента прекращения производства Atari Jaguar в 1996 году.
REDBOX TV 1.6 (БЕСПЛАТНО)
Тема: Добавлено 13.04.20: Также работает на кабельных каналах Firestick в прямом эфире.
Сайты программного обеспечения — это коллекции программного обеспечения, доступного на веб-сайтах за последние несколько десятилетий, которые были скопированы в Архив и затем оставлены в неактивном состоянии. Хотя данные о них все еще действительны, вполне вероятно, что многие из файлов, которые все еще обслуживаются, будут иметь гораздо более известные версии, в которые будут внесены исправления и другие важные обновления.
MAME (аббревиатура от Multiple Arcade Machine Emulator) — это приложение-эмулятор, предназначенное для воссоздания аппаратного обеспечения систем аркадных игр в программном обеспечении на современных персональных компьютерах и других платформах.Цель состоит в том, чтобы сохранить историю игр, не допуская потери или забывания старых игр. Цель MAME — дать ссылку на внутреннюю работу эмулируемых игровых автоматов; возможность играть в игры считается «приятным побочным эффектом». Первая публичная …
10,4 млн 10 млн
14 сен 200409/04
к Tucows Inc.
Библиотека программного обеспечения Tucows — самая большая библиотека бесплатного / условно-бесплатного программного обеспечения в Интернете. Он предоставляет пользователям более 40 000 наименований программного обеспечения, которые были «протестированы, оценены и проанализированы» Tucows inc. Этот архив включает в себя последние версии программного обеспечения Tucows, а также более старые версии, недоступные через Tucows и его зеркала.
Тема: Программное обеспечение
ZX Spectrum (произносится / ˈzɛdˌɛks / «Zed-Ex») — это 8-битный персональный домашний компьютер, выпущенный в Соединенном Королевстве в 1982 году компанией Sinclair Research Ltd.Машина была запущена Sinclair как ZX Spectrum, чтобы выделить цветной дисплей машины по сравнению с черно-белым его предшественником ZX81. В конечном итоге Spectrum был выпущен в виде восьми различных моделей; вместе они продали более 5 миллионов единиц по всему миру (не считая многочисленных клонов). Спектр был …
Live Sports (Ссылки)
Тема: apk
Фильмы сериалы (ссылки)
Тема: apk
HDtv ultimate
Тема: HDtv ultimate
607,409607K
23 июня 202106/21
к DEON12
Фильмы и шоу
Тема: Фильмы и шоу
Серия Apple II (торговая марка с квадратными скобками как «Apple] [» и отображаемая на более поздних моделях как «Apple //») представляет собой набор домашних компьютеров, один из первых очень успешных микрокомпьютеров массового производства, разработанный главным образом Стивом. Возняк, производимый Apple Computer (ныне Apple Inc.) и представленный в 1977 году с оригинальным Apple II. С точки зрения простоты использования, функций и расширяемости Apple II стал крупным технологическим достижением по сравнению со своим предшественником, …
Коллекция тем для Windows, включая версии 3.1, 95 и другие.
377,194377K
18 янв.202101/21
к SmartYou Tube TV
Smart YouTube TV 6.17.730
(1 отзывов)
Тема: Smart YouTube TV 6.17.730
книг: бесплатные тексты: бесплатное скачивание, заимствование и потоковая передача: Интернет-архив
14
Темы: Фармакология, терапия
28,99829 тыс.
111
к Гровер, Юлали Осгуд, 1873-
избранное (1 отзывов)
18,56319K
20022002
к Джоанн Эллисон Роджерс
Темы: Секс (биология), Секс., Половое поведение.
27,31327K
19431943
к Карнеги, Дейл
Источник книги: Цифровая библиотека Индии, номер 2015. 68346 dc.участник. автор: Карнеги, Дейл dc.date.accessioned: 2015-06-30T01: 23: 48Z dc.date.available: 2015-06-30T01: 23: 48Z dc.date.copyrightexpirydate: 0000-00-00 dc. date.digitalpublicationdate: 2010-05-25 dc.date.citation: 1943 dc.identifier.barcode: 49
004039 dc.identifier.origpath: / data6 / upload / 0138/198 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/68346 dc.description.scanningcentre: C-DAK, Kolkata …favouritefavoritefavoritefavorite (1 отзывов)
Тема: C-DAK
194,212194K
19591959
к Владимир Набоков
Источник книги: Цифровая библиотека Индии, 2015 г.68292 dc.contributor.author: Владимир Набоков dc.date.accessioned: 2015-06-30T01: 21: 50Z dc.date.available: 2015-06-30T01: 21: 50Z dc.date.copyrightexpirydate: 0000-00-00 dc.date.digitalpublicationdate: 2010-04-00 dc.date.citation: 1859 dc.identifier.barcode: 999999
442 dc.identifier.origpath: / data6 / upload / 0123/244 dc.identifier.copyno: 1 dc.identifier. uri: http://www.new.dli.ernet.in/handle/2015/68292 dc.description.scanningcentre: Banasthali …
favouritefavoritefavoritefavorite (2 отзыва)
Тема: Banasthali
162,113162K
19261926
к गोस्वामी तुलसीदास
Источник книги: Цифровая библиотека Индии, 2015 г.342236 dc.contributor.author: गोस्वामी तुलसीदास dc.date.accessioned: 2015-08-12T21: 22: 57Z dc.date.available: 2015-08-12T21: 22: 57Z dc.date. Авторское право: 1926 dc.date. digitalpublicationdate: 2009/09 dc.date.citation: 1926 dc.identifier.barcode: 999999
847 dc.identifier.origpath: / data3 / upload / 0086/078 dc.identifier.copyno: 1 dc.identifier.uri: http: // www.new.dli.ernet.in/handle/2015/342236 dc.description.scannerno: …
favouritefavorite (2 отзыва)
Тема: Banasthali
Заголовок обложки: Язык и поэзия цветов
избранное
Темы: Materia medica, Терапия
42,95743K
18891889
к Соломон, царь Израиля.n 80024516; Мазерс, С. Л. МакГрегор (Сэмюэл Лидделл МакГрегор)
Limited ed. из 500 пронумерованных экземпляров
Тема: Еврейская магия
Университет Торонто — Библиотека Робартса
31,22531K
Дьяволы и злые духи Вавилонии: вавилонские и ассирийские заклинания против демонов, упырей, вампиров, хобгоблинов, призраков и родственных злых духов, нападающих на человечество, тр.из оригинальных клинописных текстов, с транслитерациями, лексикой, примечаниями и т. д.
6 апреля 1
/03к Томпсон, Р. Кэмпбелл (Реджинальд Кэмпбелл), 1876-1941 гг.
Vol. 1. «Злые духи» .- Вып. 2. «Лихорадочная болезнь» и «головная боль» и т. Д.
Темы: Аккадский язык — Тексты, Вавилония — История и древности
19,82720 К
1
08
к Пуч-и-Ферретер, Жанна, 1882–1956 гг.
Нет.21, в т. 465 с названием папки: Teatro Español: serie A
избранноеfavoritefavoritefavorite (2 отзыва)
избранное
избранное
История Тома Сойера, молодого человека, который знает толк в получении желаемого.Но когда Том и его лучший друг Гек натыкаются на убийц и воров, их жизни никогда не будут прежними. Рекомендуемый уровень чтения: UP (старшие классы начальной школы)
избранное
140,196140 К
19181918
к Грей, Генри (1825–1861 гг.); Льюис, Уоррен Хармон, 1870-
Включает библиографию и указатель
Тема: Анатомия человека
26
избранное
27,38727K
19521952
к Норлинг, Жозефина (Стернс) 1895-
избранное
Источник книги: Цифровая библиотека Индии, 2015 г.379318 dc.contributor.author: Visha Bandhu dc.date.accessated: 2015-09-09T13: 57: 13Z dc.date.available: 2015-09-09T13: 57: 13Z dc.date.digitalpublicationdate: 10-03-2003 dc.date.citation: 1962 dc.identifier.barcode: 02020120022106 dc.identifier.origpath: / data / upload / 0022/111 dc.identifier.copyno: 1 dc.identifier.uri: http: //www.new.dli .ernet.in / handle / 2015/379318 dc.description.scanningcentre: Центральная городская библиотека, Хайдарабад dc.description.main: 1 …
Тема: Город
54,46854K
19491949
к Недоступен
Источник книги: Цифровая библиотека Индии, 2015 г.553830 dc.contributor.author: недоступен dc.date.accessioned: 2015-10-15T13: 06: 33Z dc.date.available: 2015-10-15T13: 06: 33Z dc.date.digitalpublicationdate: 2011/06/2 dc.date.citation: 1949 dc.identifier.barcode: 049
055097 dc.identifier.origpath: / data8 / upload / 0252/380 dc.identifier.copyno: 1 dc.identifier.uri: http: //www.new.dli .ernet.in / handle / 2015/553830 dc.description.scannerno: UJPL_02 dc.description.scanningcentre: C-DAK, Kolkata …Тема: C-DAK
60,06360 К
—
к Гувинда Даас Виниита
Источник книги: Цифровая библиотека Индии, 2015 г.494038 dc.contributor.author: Goovinda Daas Viniita dc.date.accessed: 2015-09-23T20: 06: 55Z dc.date.available: 2015-09-23T20: 06: 55Z dc.date.digitalpublicationdate: 2005/10 / 3 dc.identifier.barcode: 029
072820 dc.identifier.origpath: / data_copy / upload / 0072/825 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle / 2015/494038 dc.description.scannerno: DIL SVDL MS 046 dc.description.scanningcentre: SV Электронная библиотека, …Тема: SV
8,6468.6K
19841984
к Герберт, Франк
Дюна — Мод’Диб — Приложение I: Экология Дюны — Приложение II: Религия Дюны — Приложение III: Отчет о мотивах и намерениях Бене Гессерайт — Приложение IV: Альманак эн-Ашраф (избранные отрывки из Благородных домов ) — Термилогия Империума — Карта
Темы: Дюна (Воображаемое место), Научная фантастика, Дюна (Воображаемое место)
56,23456K
19291929
к Шериф Р.С.
Источник книги: Цифровая библиотека Индии Номер 2015.209119 dc.contributor.author: Sherriff RC dc.date.accessioned: 2015-07-09T16: 08: 26Z dc.date.available: 2015-07-09T16: 08: 26Z dc.date .digitalpublicationdate: 2004-03-20 dc.date.citation: 1929 dc.identifier: Librarian, Rashtrapati Bhavan dc.identifier.barcode: 6010010078057 dc.identifier.origpath: / data_copy / upload / 0078/062 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/209119 dc.description.scanningcentre: …
Тема: Rashtrapati
В целях содействия просвещению населения и общественной безопасности, равной справедливости для всех, более информированного населения, верховенства закона, всемирной торговли и мира во всем мире настоящий правовой документ предоставляется на некоммерческой основе, поскольку это право всех люди должны знать и говорить о законах, которые ими управляют.(Для получения дополнительной информации: 12 таблиц кодов) Название организации по стандартизации: Бюро стандартов Индии (BIS) Название подразделения: Гражданское строительство Название раздела: Национальный строительный кодекс (CED 46) …
избранное .gov.in, standardbis.in, public.resource.org
Калифорнийская цифровая библиотека
161,851162K
18991899
к Баум, Л.Франк (Лайман Франк), 1856–1919; Денслоу, У. У. (Уильям Уоллес), 1856-1915 гг.
Зеленая и красная иллюстрированная ткань издательства поверх досок; иллюстрированные форзацы. Отдельно стоящая тарелка
избранное
Фотокопия
избранное
1,2171.2K
111
к Американское антикварное общество
Тема: Морская биологическая лаборатория (Вудс-Хоул, штат Массачусетс)
51,49651K
—
к Гринуэй, Кейт, 1846-1901 гг.
Темы: Цветочный язык, Цветы
2,2802.3K
18671867
к Миллер, Эли Пек. [из старого каталога]
Источник книги: Цифровая библиотека Индии Номер 2015.545810 dc.contributor.author: Нанд Лал dc.date.accessioned: 2015-10-13T20: 20: 03Z dc.date.available: 2015-10-13T20: 20: 03Z dc.дата. авторское право: 1975 dc.date.digitalpublicationdate: 2010/12 dc.date.citation: 1975 dc.identifier.barcode: 999999
092 dc.identifier.origpath: / data8 / upload / 0221/374 dc.identifier.copyno: 1 dc .identifier.uri: http://www.new.dli.ernet.in/handle/2015/545810 dc.description.scanningcentre: Университет Банастхали …Тема: Банастхали
90,72791K
18931893
к Сидни Лакстон Лони
Книга оцифрована Google из библиотеки Мичиганского университета и загружена в Интернет-архив пользователем tpb.
favouritefavoritefavorite (1 отзывов)
Источник: http://books.google.com/books?id=grQUWYejIq4C&oe=UTF-8
Биттинг, К. Гастраномный нагрудник.
Темы: Фальсификация и проверка пищевых продуктов, Кофе, Чай
11,72012K
1
08
к Франсиско Гонсалес Гинан
Книга оцифрована Google из библиотеки Гарвардского университета и загружена в Интернет-архив пользователем tpb.
Источник: http://books.google.com/books?id=h5MCAAAAYAAJ&oe=UTF-8
70,13570 К
18951895
к Хеклингер, Чарльз. [из старого каталога]
favouritefavorite (Отзывов: 1)
Тема: Портняжное дело (женское) [из старого каталога]
93,16393K
18951895
к Лони, С.Л. (Сидни Лакстон), 1860-1939 гг.
Темы: Координаты, Геометрия, Аналитика
122,634123K
19451945
к Райт Ричард
Источник книги: Цифровая библиотека Индии, 2015 г.5717 dc.contributor.author: Wright Richard dc.date.accessioned: 2015-06-19T15: 20: 40Z dc.date.available: 2015-06-19T15: 20: 40Z dc.date.digitalpublicationdate: 2006-01-18 dc.date.citation: 1945 dc.identifier.barcode: 999999
240 dc.identifier.origpath: / data1 / upload / 0028/550 dc.identifier.copyno: 1 dc.identifier.uri: http: //www.new.dli .ernet.in / handle / 2015/5717 dc.description.scanningcentre: C-DAC, Noida dc.description.main: 1 …
favouritefavoritefavorite (3 отзыва)
Тема: C-DAC
Избранное..
41,94242K
19541954
к Дедияр, Владимир
Источник книги: Цифровая библиотека Индии, публикация 2015 г. 538688 dc.contributor.автор: Дедияр, Владимир dc.date.accessed: 2015-10-09T12: 49: 02Z dc.date.available: 2015-10-09T12: 49: 02Z dc.date. copyright: 1954 dc.date.digitalpublicationdate: 2010 / 09 dc.date.citation: 1954 dc.identifier.barcode: 999999
404 dc.identifier.origpath: / data9 / upload / 0266/973 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new. dli.ernet.in/handle/2015/538688 dc.description.scannerno: Университет Банастхали …Тема: Банастхали
3,2053.2K
19131913
к Бейли-Громан, Уильям А. (Уильям Адольф), 1851-1921 гг.
Биографические заметки художников: с. 355-410
Темы: Художники, Спортивная гравюра, Спорт в искусстве, Охота
Темы: Американский союз воскресных школ, Отцы церкви, Апостольские отцы
Источник книги: Цифровая библиотека Индии, 2015 г.50296 dc.contributor.author: Xxxxxxxxx dc.date.accessioned: 2015-06-26T15: 27: 12Z dc.date.available: 2015-06-26T15: 27: 12Z dc.date.digitalpublicationdate: 2009-04-00 dc .date.citation: 1914 dc.identifier.barcode: 999999
955 dc.identifier.origpath: / data4 / upload / 0095/759 dc.identifier.copyno: 1 dc.identifier.uri: http: //www.new.dli. ernet.in/handle/2015/50296 dc.description.scanningcentre: Университет Банастхали dc.description.main: 1 …
избранноеfavoritefavoritefavorite (1 отзывов)
Тема: Banasthali
44,51145K
1
12
к Свами, Вивекананд
Источник книги: Цифровая библиотека Индии, 2015 г.400888 dc. contributor.author: Swami, Vivekanand dc.date.accessed: 2015-09-10T14: 08: 24Z dc.date.available: 2015-09-10T14: 08: 24Z dc.date. copyright: 1912 dc.date .digitalpublicationdate: 2012/04 dc.date.citation: 1912 dc.identifier.barcode: 999999
589 dc.identifier.origpath: / data9 / upload / 0273/986 dc.identifier.copyno: 1 dc.identifier.uri: http: / /www.new.dli.ernet.in/handle/2015/400888 dc.description.scanningcentre: Университет Банастхали …Тема: Банастхали
130,221130K
20092009
к Данте Алигьери, 1265–1321; Чарди, Джон, 1916-1986 гг.
Перевод: Inferno
Темы: Ад, Поэзия, Средневековье, Религиозная поэзия
11,22411K
1
12
к Ми, Артур, 1875 — [из старого каталога] изд; Томпсон, Голландия, 1873-1940, совместное изд.
избранное
10,70111K
—
к Гита Пресс Горакхпур
Книги, оцифрованные Сарвагья Шарда Пит, «Сканда Пуран — Гита Пресс Горакхпур»
избранное
21,73422K
19541954
к Нирмала Шерджанг
Источник книги: Цифровая библиотека Индии, 2015 г.483402 dc.contributor.author: Nirmala Sherjang dc.date.accessed: 2015-09-23T16: 49: 23Z dc.date.available: 2015-09-23T16: 49: 23Z dc.date.digitalpublicationdate: 2004/07/22 dc.date.citation: 1954 dc.identifier.barcode: 059
118908 dc.identifier.origpath: / rawdataupload / upload / 0118/910 dc.identifier.copyno: 1 dc.identifier.uri: http: //www.new.dli .ernet.in / handle / 2015/483402 dc.description.scannerno: 6 dc.description.scanningcentre: IIIT, …Тема: IIIT
41,16341K
19351935
к Брантон, Пол, 1898-
favouritefavoritefavoritefavorite (2 отзыва)
Темы: Оккультизм — Египет, Египет — Описание и путешествия, Египет — Религия
41,75242K
19411941
к Рагхунатх Сингх
Источник книги: Цифровая библиотека Индии, 2015 г.539126 dc.contributor.author: Raghunath Singh dc.date.accessated: 2015-10-09T13: 00: 20Z dc.date.available: 2015-10-09T13: 00: 20Z dc.date. copyright: 1941 dc.date. digitalpublicationdate: 2010/07 dc.date.citation: 1941 dc.identifier.barcode: 999999
809 dc.identifier.origpath: / data9 / upload / 0267/378 dc.identifier.copyno: 1 dc.identifier.uri: http: // www.new.dli.ernet.in/handle/2015/539126 dc.description.scannerno: Университет Банастхали …Тема: Банастхали
26
Темы: Испанский язык, Торговля
11,94912K
20032003
к Ватсьаяна; Донигер, Венди; Какар, Судхир
Включены библиографические ссылки (стр.[212] -218) и индекс
Темы: Секс, Любовь, Половые сношения, Эротическая литература, Эротическое искусство, Сексуальные обычаи, Сексуальные инструкции
94,79995K
19351935
к Lustig, Lillie S, ed; Сондхейм, С. Клэр, совместное издание; Ренсель, Сара, совместное изд.
Темы: Кулинария, Американская — Южные штаты., кбк
463,583464K
18831883
к Фэллон, С. У., 1817–1880 гг.
Книга оцифрована Google из библиотеки Оксфордского университета и загружена в Интернет-архив пользователем tpb.
Темы: par, aur, men, going, people, jis, three, kam, time, cos, jis men, medical hall, taur par, jis par, …
Источник: http://books.google.com / books? id = lqACAAAAQAAJ & oe = UTF-8
26
Темы: Ислам, Манеры и обычаи, Ислам, Путешествия, Ислам
8,7878,8 тыс.
1
04
к Фламмарион, Камилла, 1842–1925 гг .; Уэлби, Фрэнсис А.(Фрэнсис Элис) tr
извлеченный список выбора
Тема: Сравнительная физиология
Темы: Лондон. Международная выставка, 1871 г., Декоративно-прикладное искусство
6,9567.0K
19941994
к Бакос, Сьюзан Крейн
Напряженная жизнь Кэролайн Стил, обозревателя эротических советов мужского журнала, когда она перемещается между порнографическим истеблишментом, активистами против порнографии и своими собственными потребностями.К последним относится поиск убийцы, который присылает ей угрозы убийством. Автор работал в журнале Penthouse
Темы: Секс (Психология), Советы обозревателей, Советы обозревателей, Секс (Психология)
869869
1
07к Д.А.Р.Нью-Йорк. Глава Тихниога. [из старого каталога]
favouritefavoritefavorite (4 отзыва)
Темы: Дизайн — Обучение и преподавание, Рисование — Обучение и преподавание
51,34951K
01 июня 197806/78
к Чандра Сатиш
Источник книги: Цифровая библиотека Индии, 2015 г.447529 dc.contributor.author: Chandra Satish dc.contributor.author: Chandra Satish dc.date.accessated: 2015-09-18T13: 45: 24Z dc.date.available: 2015-09-18T13: 45: 24Z dc.date .copyright: 1978/06 dc.date.digitalpublicationdate: 13-11-2006 dc.date.citation: 1978/06 dc.identifier.barcode: 999999
775 dc.identifier.origpath: / rawdataupload1 / upload / 0127/437 dc.identifier .copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/447529 …
Тема: C-DAC
29,92530 тыс.
19491949
к Полевой Борис Николаевич
избранное
Источник книги: Цифровая библиотека Индии, 2015 г.281236 dc.contributor.author: Vatsyayana Muni dc.date.accessed: 2015-08-04T16: 26: 47Z dc.date.available: 2015-08-04T16: 26: 47Z dc.identifier.barcode: 059
8 dc.identifier. origpath: / data58 / upload / 0103/875 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/281236 dc.description.scannerno: 20003571 dc .description.scanningcentre: IIIT, Allahabad dc.description.main: 1 dc.description.tagged: 0 …
Тема: IIIT
77,62678K
19471947
к Стейнбек Джон
Источник книги: Цифровая библиотека Индии, 2015 г.507266 dc.contributor.author: Steinbeck John dc.coverage.spatial: New York dc.date.accessioned: 2015-09-27T16: 28: 11Z dc.date.available: 2015-09-27T16: 28: 11Z dc.date .copyright: 1947 dc.date.digitalpublicationdate: 2009/05/18 dc.date.citation: 1947 dc.identifier.barcode: 999999
728 dc.identifier.origpath: / data4 / upload / 0111/532 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/507266 dc.description.scannerno: OS …favouritefavoritefavoritefavorite (1 отзывов)
Тема: C-DAC
63,44863K
19661966
к Оджа, Гопеш Кумар
Источник книги: Цифровая библиотека Индии, 2015 г.538693 dc.contributor.author: Ojha, Gopesh Kumar dc.date.accessed: 2015-10-09T12: 49: 07Z dc.date.available: 2015-10-09T12: 49: 07Z dc.date. copyright: 1966 dc. date.digitalpublicationdate: 2010/09 dc.date.citation: 1966 dc.identifier.barcode: 999999
409 dc.identifier.origpath: / data9 / upload / 0266/978 dc.identifier.copyno: 1 dc.identifier.uri: http: //www.new.dli.ernet.in/handle/2015/538693 dc.description.scannerno: Университет Банастхали …Тема: Банастхали
69,05569K
19511951
к Гомбрич Э.ЧАС.
Источник книги: Цифровая библиотека Индии Номер 2015.29158 dc.contributor.author: Gombrich EH dc.date.accessioned: 2015-06-25T14: 48: 32Z dc.date.available: 2015-06-25T14: 48: 32Z dc.date .digitalpublicationdate: 2006-03-01 dc.identifier.barcode: 999999
504 dc.identifier.origpath: / data2 / upload / 0037/811 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new. dli.ernet.in/handle/2015/29158 dc.description.scanningcentre: C-DAC, Noida dc.description.main: 1 dc.description.tagged: 0 …
Тема: C-DAC
52
Тема: Галифакс (Н.С.) — История
Источник книги: Цифровая библиотека Индии, публикация 2015 г. 271669 dc.contributor.author: B.d. Singh dc.date. Доступно: 2015-07-27T21: 03: 39Z dc.date. Доступно: 2015-07-27T21: 03: 39Z dc.identifier.barcode: 059
892313 dc.identifier.origpath: / data58 / upload / 0094/030 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/ 271669 dc.description.scannerno: 20003265 dc.description.scanningcentre: IIIT, Allahabad dc.description.main: 1 dc.description.tagged: 0 …Тема: IIIT
35,24135K
1
10к Каястх, Девапрасад
Источник книги: Цифровая библиотека Индии, 2015 г.404532 dc.contributor.author: Kayasth, Deviprasad dc.date.accessated: 2015-09-10T15: 28: 19Z dc.date.available: 2015-09-10T15: 28: 19Z dc.date. copyright: 1910 dc.date .digitalpublicationdate: 2009/02 dc.date.citation: 1910 dc.identifier.barcode: 999999
628 dc.identifier.origpath: / data9 / upload / 0262/196 dc.identifier.copyno: 1 dc.identifier.uri: http: / /www.new.dli.ernet.in/handle/2015/404532 dc.description.scannerno: Университет Банастхали …
Тема: Банастхали
15,23415K
19381938
к Брук, З.Н. (Захари Ньюджент), 1883-1946 гг.
Эту книгу нельзя просмотреть, потому что она находится на рецензировании в рамках проекта «Миллион книг
» Тема: Европа — История 476-1492
52,48752K
19551955
к Докторгирадж Санкар Пршад
Источник книги: Цифровая библиотека Индии, экспонат 2015. 348254 dc.contributor.author: доктор Гирадж Санкар Пршад dc.date.accessioned: 2015-08-13T00: 56: 24Z dc.date.available: 2015-08-13T00: 56: 24Z dc.date.copyright: 1955 dc.date.digitalpublicationdate: 2010/07 dc.date.citation: 1955 dc.identifier.barcode: 999999
953 dc.identifier.origpath: / data6 / upload / 0128/755 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/348254 dc.description.scannerno: Университет Банастхали …
Тема: Банастхали
Источник книги: Цифровая библиотека Индии. Номер 2015.319654 dc.contributor.author: Свами, Вивекан и дата получения: 2015-08-11T20: 45: 25Z dc.date. Доступен: 2015-08-11T20: 45: 25Z dc. date.digitalpublicationdate: 2010/02 dc.identifier.barcode: 999999
649 dc.идентификатор.origpath: / data4 / upload / 0101/453 dc.identifier.copyno: 1 dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/319654 dc.description.scannerno: Университет Банастхали dc.description.scanningcentre: Университет Банастхали …Тема: Банастхали
Калифорнийская цифровая библиотека
379,707380K
18461846
к Ньютон, Исаак, сэр, 1642-1727; Читтенден, Н.W. Жизнь сэра Исаака Ньютона; Ади, Дэниел, ок. 1819-1892 гг. (1846) BKP CU-BANC; Мотте, Эндрю, д. 1730; Хилл, Теодор Престон. Ранние американские книги по математике. CU-BANC
favouritefavoritefavoritefavorite (7 отзывов)
Темы: Ньютон, Исаак, сэр, 1642-1727, Механика — Ранние работы до 1800 года, Небесная механика — Ранние работы …
Использование архива.org для расследований OSINT — мы OSINTCurio.us
Интернет-архив, широко известный как Wayback Machine, позволяет пользователям посещать заархивированные версии веб-сайтов. Интернет-архив архивирует сайты с 1996 года и насчитывает 514 миллиардов заархивированных веб-страниц!
Если вам интересно, как можно использовать Интернет-архив в своих исследованиях OSINT, вы попали в нужное место. Существует множество способов извлечь важную информацию из Wayback Machine для дальнейшего расследования OSINT.Если вы хотите просмотреть исторические версии веб-сайта из-за того, что сайт был удален или заменен новым контентом, Wayback Machine может вам помочь. Возможно, вам потребуется убедиться, что цель ранее работала в компании, но в текущем состоянии сайта нет информации о цели. Иногда цель может намеренно скрыть информацию со своего текущего веб-сайта, просмотр более старых дат сайта может выявить новую информацию. Иногда вы можете собирать соответствующие данные, такие как имена, номера телефонов, адреса электронной почты и даже метаданные, из более старых версий веб-сайта.Давайте изучим методы поиска…
Методы быстрого поиска:
Если сайт был заархивирован, появится представление календаря с цветными точками, которые имеют различное значение. Синие точки — это то, на что вы хотите нажать, поскольку они указывают на захват веб-страницы. Зеленый цвет указывает на перенаправление, оранжевые точки указывают на то, что сканер получил ошибку клиента, а красный цвет означает, что произошла ошибка сервера. При навигации по временной шкале будут отображаться даты, когда сайт был заархивирован.
Пример временной шкалы Пример всех URL-адресов, заархивированных с Osinttechniques.comДругие методы поиска:
Пример: выполните поиск на www.myspace.com, чтобы увидеть, как сайт менялся с течением времени.
Нанаиболее интересно взглянуть на синие точки. Пример: выполните поиск по запросу «osama bin laden», чтобы увидеть, какие результаты появятся, или выполните поиск пользователей социальных сетей, таких как профиль Марка Цукерберга в Facebook. https://web.archive.org/web/*/www.facebook.com/zuck
- Выполните следующие действия, чтобы понять, как найти адрес электронной почты, связанный с загруженными файлами.Для OSINT-исследования, если вы идентифицируете адрес электронной почты, это еще одна возможность, которую вы можете использовать и искать по этому адресу электронной почты в других местах, например в поисковых системах или на сайтах социальных сетей.
Пример: https://archive.org/details/FlintstonesWinstonCigaretteCommericals
- Прокрутите ниже, чтобы найти «параметры загрузки»
- Нажмите «показать все», чтобы отобразить все файлы.
- Щелкните файл, который заканчивается на «meta.xml»
- Ctrl + f для слова «загрузчик», и вы увидите адрес электронной почты: [электронная почта защищена]
Использовать коллекции и изменения (бета):
- Коллекции — это способ узнать, почему URL-адрес был заархивирован в Wayback Machine.
Пример: https://web.archive.org/web/collections/2020*/osinttechniques.com
- Изменения позволяют пользователям выбирать 2 разные версии URL-адреса и сравнивать их бок о бок.
Пример: https://web.archive.org/web/changes/osinttechniques.com
Узнайте больше о Коллекциях и Изменениях здесь: https: // blog.archive.org/2019/10/18/the-wayback-machine-fighting-digital-extinction-in-new-ways
Сохранение страниц:
- Используйте https://archive.org/web/, чтобы запросить архивирование страницы, кнопка сохранения видна в правом нижнем углу экрана или при переходе непосредственно на https://web.archive.org/save. Эта опция «Сохранить страницу сейчас» захватывает только эту конкретную страницу, а не весь веб-сайт, и работает только для сайтов, на которых разрешены поисковые роботы. На скриншоте ниже показана статья из OSINT Любопытное сохранение в архив.
Для целей поиска может быть важно понять, когда что-то было сохранено в Интернет-архиве. Давайте посмотрим на ссылку ниже:
https://web.archive.org/web/20180214034336/http://www.osinttechniques.com
Числа в середине имеют формат ггггммддччммсс, поэтому дата сканирования сайта — 14 февраля 2018 года, 03:43 и 36 секунд.
Что делать, если сайта, который вы исследуете, нет в Интернет-архиве? Некоторые сайты не будут в архиве.org из-за файлов robots.txt или из-за того, что владелец веб-сайта попросил не архивировать его сайт.
Однако у вас есть другие варианты поиска, такие как поиск содержимого кеша, как указано в этом сообщении блога https://osintcurio.us/2019/02/12/osint-on-deleted-content, или проверка других онлайн-архивов, таких как архив. Cегодня.
Нравится:
Нравится Загрузка …
Как заблокировать Archive.org?
В мире существует много явно плохой / старой / неточной информации о том, как заблокировать архив.org, иначе известная как «Машина обратного пути», от очистки вашего сайта. Это самая точная информация, которую мы можем найти на момент написания этой статьи. Предупреждение о спойлере: Internet Archive удалил наш сайт, как только мы попросили, но метод robots.txt не работал.
ia_archiver не является ботом Archive.org
IA_Archiver — бот для Alexa. Очевидно, больше не бот для archive.org . Откуда нам знать? Снимок экрана ниже взят с этой веб-страницы Alexa.
Это означает, что если вы используете исключение robots.txt следующим образом:
Агент пользователя: ia_archiver Disallow: /
Это не запретит Archive.org (Wayback Machine), но вместо этого заблокирует сканирование вашего сайта Alexa.
Есть ли связь между Archive.org и Alexa?
Да. Их создал один и тот же парень. Согласно Википедии:
Wayback Machine была создана совместными усилиями Alexa Internet и Internet Archive, когда был построен трехмерный индекс, позволяющий просматривать заархивированный веб-контент. «и что» Брюстер Кале основал архив в мае 1996 года, примерно в то же время, когда он основал коммерческую компанию по поиску информации в Интернете Alexa Internet. |
Почему Archive.org перестал уважать robots.txt?
Сотрудники Archive.org сказали, что файлы robots.txt не служат для создания архивных сайтов. Вы можете прочитать их сообщение об этом здесь, но они утверждают, что один из важных пунктов:
«Со временем мы заметили, что файл robots.txt, предназначенные для сканеров поисковых систем, не обязательно служат нашим архивным целям «.Хотя они кажутся очень заинтересованными в выполнении своих целей , они, похоже, упустили из виду пожелания владельцев веб-сайтов, которые не хотят, чтобы их интеллектуальная собственность была очищена и отображена.
Почему все думают, что ia_archiver — это бот на archive.org?
Потому что раньше было. Согласно ныне несуществующей странице исключений archive.org:
Интернет-архив не заинтересован в предоставлении доступа к веб-сайтам или другим Интернет-документам, авторы которых не хотят, чтобы их материалы в коллекции.Чтобы удалить свой сайт из Wayback Machine, разместите файл robots.txt на верхнем уровне своего сайта (например, www.yourdomain.com/robots.txt). Файл robots.txt выполняет две функции:
Чтобы исключить поискового робота Internet Archive (и удалить документы с Wayback Machine), разрешив всем другим роботам сканировать ваш сайт, ваш robots.txt должен сказать: User-agent: ia_archiver |
Как ни странно, вы все еще можете видеть несуществующую страницу исключения на машине WayBack.
Можно предположить, что люди на archive.org передумали и теперь Интернет-архив — это , заинтересованные в предоставлении доступа к веб-сайтам или другим Интернет-документам, авторы которых не хотят, чтобы их материалы в коллекции.
Ia_archiver раньше работал
Итак, вы видите, что правильный способ запретить archive.org копировать ваш сайт был , чтобы добавить ia_archiver в файл запрета robots.txt , а не . Поскольку только веб-мастера должны иметь доступ к редактированию файла robots.txt сайта, это казалось довольно хорошим способом сделать это. Но затем archive.org незаметно изменил ситуацию, и снова начал очищаться всякий контент. Облом.
Что делать, если ia_archiver больше не работает?
По архиву.org, лучший способ удалить сайт — отправить им электронное письмо на адрес [email protected] и попросить удалить его. Точный язык, который они используют:
Как я могу исключить или удалить страницы моего сайта из Wayback Machine? Вы можете отправить нам запрос по электронной почте на адрес [email protected], указав URL-адрес (веб-адрес) в тексте сообщения.
Но когда вы отправляете им электронное письмо с запрошенной информацией, ответа нет, по крайней мере, не сразу. Мы проверили его и обнаружили, что на самом деле автоответчика нет, так что это немного похоже на крик в дыру в земле.
Почему archive.org может решить эту проблему вручную, а не просто позволить веб-мастерам принимать собственные решения о копировании своего контента с помощью файла robots.txt, остается загадкой. Это кажется довольно утомительным решением, если оно вообще работает. Некоторые говорят, что это работает как шарм, другие говорят, что отправили несколько сообщений на адрес электронной почты и не получили ответа через несколько недель или месяцев.
Электронное письмо в Интернет-архив * действительно * работает
Мы отправили по электронной почте Интернет-архив. Хотя мы не получили автоматического ответа, они ответили нам примерно через неделю.Ниже приведено электронное письмо, которое они отправили.
Некоторые говорят, что archive.org_bot может работать
Некоторые пользователи предлагают заменить старый запрет ia_archiver на новый запрет archive.org_bot. Мы еще не смогли проверить, работает ли это. Многие говорят, что это не так. Если вы хотите попробовать, вот информация о файле robots.txt, которая вам понадобится:
Агент пользователя: archive.org_bot Disallow: /
Вы можете использовать свой файл .htaccess для блокировки archive.org
Веб-сервер Apache может использовать.htaccess для хранения директив. Вы можете найти инструкции, как это сделать, здесь. Вам понадобятся IP-адреса бота-архиватора. Вы можете найти IP-адреса ботов Archive.org здесь.
Мы не пробовали этот метод, и вам понадобится немного технических знаний, чтобы сделать это. Как и в случае с чем-либо на уровне сервера, мы советуем людям осознавать свои пределы и нанимать профессионала, если вы не можете удобно манипулировать вещами на уровне сервера.
Является ли сайт archive.org незаконным сканирование без разрешения?
Согласно Electronic Frontier Foundation, чистка общедоступного контента является совершенно законной.Они ссылаются на дело Вашингтона и говорят:
Автоматизированные инструментыдля доступа к общедоступной информации в открытом Интернете не являются компьютерным преступлением, даже если веб-сайт запрещает автоматический доступ в своих условиях обслуживания.
Это применимо даже в том случае, если в Условиях использования прямо указано, что пользователь не может очистить сайт. LinkedIn однажды подала в суд на людей, очищающих их сайт с нарушением условий обслуживания, и проиграла. Вы можете найти статью об этом случае здесь. Там написано:
[Постановление] постановляет, что федеральный закон о борьбе с взломом не срабатывает при очистке веб-сайта, даже если владелец веб-сайта — в данном случае LinkedIn — прямо просит прекратить очистку.
Использование уведомления DMCA для удаления archive.org
Вы можете создать уведомление о нарушении закона США «Об авторском праве в цифровую эпоху» (DMCA), используя подобный генератор. А затем отправить уведомление милым людям по электронной почте [email protected].
Мы еще не закончили проверять, работает это или нет, но мы обновим это сообщение в блоге, когда мы это сделаем.
Спасибо за чтение. Если вам есть что добавить, сделайте это в разделе комментариев ниже.
Часто задаваемые вопросы
Есть ли связь между Архивом.org и Алекса?
Да. Archive.org и Alexa были созданы одним и тем же человеком.
Почему Archive.org перестал уважать robots.txt?
Сотрудники Archive.org сказали, что файлы robots.txt не служат для создания архивных сайтов.
Как удалить сайт с Archive.org?
Согласно archive.org, лучший способ удалить сайт — это отправить им электронное письмо на адрес [email protected] с просьбой удалить его.
Это незаконно для архива.org очистить без разрешения?
Согласно Electronic Frontier Foundation, чистка общедоступного контента является совершенно законной.
Вепонизация веб-архивов: информационные технологии и публикация COVID-19
Беспрецедентный объем вредной дезинформации о здоровье, связанной с пандемией коронавируса, привел к появлению тактики дезинформации, которая использует веб-архивы, чтобы избежать модерации контента в социальных сетях. Здесь мы представляем недавно выявленные методы манипуляции, разработанные для максимизации ценности, долговечности и распространения вредоносного и не имеющего фактов контента в социальных сетях с использованием информации о происхождении из веб-архивов и аналитики социальных сетей.После выявления конспиративного контента, который был заархивирован людьми с помощью Wayback Machine, мы сообщаем о пользовательских моделях «выборки экрана», когда изображения заархивированной дезинформации распространяются через социальные платформы. Мы утверждаем, что заархивированные веб-ресурсы из Wayback Machine Интернет-архива и последующие снимки экрана способствуют «дезинфекции» COVID-19 на платформах. Понимание этой тактики манипулирования с использованием источников из веб-архивов обнаруживает кое-что неприятное в информационной практике во время пандемий — желание получить доступ к надежной информации даже после того, как она была модерирована и проверена фактами, для некоторых людей придаст больше внимания дезинформации о здоровье и теориям заговора, потому что платформы отметили это как ложный контент.
по
Амелия АкерШкола информации, Техасский университет в Остине, США
Митч ЧейетКоммуникационный колледж Муди, Техасский университет в Остине, США
Изображение drosen7900 на FlickrВопросы исследования
- Как дезинформация о здоровье архивируется, превращается в оружие и распространяется в Интернете?
- Что показывает информация о происхождении из веб-архивов о распространении и модерации вредоносного контента на платформах?
- Что эта тактика веб-архивирования раскрывает информацию о практике во время пандемии?
- Как выборка экрана расширяет распространение дезинформации о состоянии здоровья за пределы отслеживаемых показателей?
Резюме эссе
- Используя информацию о происхождении, такую как исходный контекст, технические особенности и уникальные характеристики онлайн-ресурсов из веб-обходов, а также данные социальной аналитики из Crowdtangle API, мы обнаруживаем, что веб-архивы, такие как Wayback Machine Интернет-архива, превращаются в оружие для распространения и сохранения здоровья дезинформация, распространяемая на таких платформах, как Facebook и Twitter.
- Здесь мы представляем два взаимосвязанных исследования обработки данных, которые используют заархивированные веб-ресурсы для преднамеренного уклонения от попыток автоматической модерации контента и дальнейшего распространения дезинформации о состоянии здоровья от платформ, пытающихся бороться.
- Это исследование показывает, что заархивированные URL-адреса веб-архивных источников дезинформации о состоянии здоровья, обнаруженные в Wayback Machine Интернет-архива, и методы выборки из архивного контента, по-видимому, затрудняют автоматические системы модерации контента для выявления и блокировки, и, как следствие, более длительное распространение и распространение. на платформах.
- Чтобы понять эти информационные практики, которые формируют формирующуюся публику COVID-19, созываемую частными платформами после пандемии, исследователи дезинформации и операторы платформ должны тщательно рассмотреть, как распространение архивного контента из Интернета теперь появляется на платформах и статус после коронавируса.
Последствия
В течение многих лет исследователи компьютерной безопасности и интернет-исследователи документировали различные способы взлома, взлома и неправомерного использования веб-архивов, таких как Wayback Machine Интернет-архива (Caplan-Bricker, 2018; Littman, 2017). .Высокопоставленные дела обычно указывают на зомби-контент, который больше не публикуется в « живой » сети, отмывание происхождения с помощью настраиваемых гиперссылок или сокращения ссылок, использование ресурсов задним числом или блокирование ботами сканирования веб-страниц для поисковой индексации (Madrigal, 2018; Nelson, 2018; Walden , 2012). Инфодемия коронавируса (Zarocostas, 2020) привела к появлению множества методов обработки данных, распространяющих дезинформацию о здоровье, которая теперь включает веб-архивы, такие как Wayback Machine. Под обработкой данных мы подразумеваем «практики, которые создают, полагаются на или даже играют с распространением данных в социальных сетях, задействуя новые вычислительные и алгоритмические механизмы организации и классификации» (Acker, 2018).Здесь мы также обсуждаем выборку экрана, метод обработки данных, который расширяет распространение заархивированной дезинформации, когда пользователи социальных сетей публикуют скриншоты заархивированных URL-адресов, тем самым устраняя возможность щелкать или отслеживать эти статические изображения из архивных онлайн-источников. Такие методы обработки данных часто позволяют оставаться незамеченными для кампаний дезинформации и дезинформации и особенно хорошо умеют избегать автоматических алгоритмов модерации контента, используемых для все большей борьбы с фальшивыми новостями и недостоверным поведением.Одним из хорошо задокументированных методов обработки данных является имитация легитимности путем публикации поддельного контента, который кажется достоверной информацией (Acker & Donovan, 2019). В своем исследовании, посвященном неправомерному использованию веб-архивов в социальных сетях, Zannettou et al. (2018) обнаружили, что новостные статьи и сообщения в социальных сетях являются наиболее распространенными веб-ресурсами, сохраняемыми в Archive.is и Wayback Machine. Они обнаружили, что такие URL-адреса распространялись среди форумов Reddit, когда исходный веб-контент считался спорным или эфемерным.Обсуждаемая здесь технология обработки данных предназначена для использования легитимности архивной инфраструктуры Wayback Machine для развертывания дезинформации о состоянии здоровья на платформах путем обхода мер модерации.
в своей алгоритмической сортировке и модерации объединяют новые онлайн-публики, которые Гиллеспи называет «рассчитанной публикой» (2014). В своей работе по информационным заказам до и после стихийных бедствий Финн показала, что частные платформы, такие как Facebook, собирают группы людей новыми способами (2018, стр.140). Финн утверждает, что после стихийных бедствий, таких как землетрясения и пандемии, платформы становятся общедоступными информационными инфраструктурами, которые формируются и формируются с помощью новых информационных практик. В сочетании с автоматизированными алгоритмами рекомендаций и сплоченной целевой аудиторией подрывное распространение военной дезинформации о здоровье теперь формирует рассчитанную публику на пандемию. Как алгоритмы платформы привлекают эту публику к COVID-19, как правило, неизвестно, их механизмы находятся в «черном ящике», что дает посторонним невысокую видимость их создания, разработки и оценки.Здесь мы показываем, как веб-архивы используются для имитации легитимности и распространения дезинформации среди общественности, связанной с COVID-19, через такие платформы, как Facebook, что, в свою очередь, может дать больше информации о понимании силы алгоритмов для маркировки и классификации дезинформации (Burrell, 2016).
Многие манипуляторы контентом используют «схлопывание контекста» в ленте новостей Facebook и временной шкале Twitter для распространения дезинформации с помощью бесплатных и быстрых инструментов онлайн-публикации. Поскольку потоки новостной ленты и временной шкалы «сглаживают» весь контент в один канал или поток социальной осведомленности (Kivran-Swaine & Naaman, 2011), бывает трудно отличить проверенные новостные статьи, таргетированную рекламу и другой онлайн-контент.Кроме того, мобильное приложение Facebook преобразует веб-статьи в их формат мгновенных статей, который они описывают как «маслянисто гладкую» нативную функцию (Facebook, 2020), обеспечивая легитимизацию обработки данных для контента, который в противном случае был бы воспринят как отрывочный и ненадежный, если бы просматривался за пределами платформу по исходному URL-адресу контента. Прежде чем мы объясним, как заархивированный контент можно использовать в качестве оружия на платформах, необходимо понять, как архивируется Интернет.
Интернет-архивы, такие как Wayback Machine Интернет-архива, являются результатом ресурсоемкого и целенаправленного цифрового сохранения цифровых материалов (Brügger, 2018).Методы и методы веб-архивирования обычно делятся на два подхода — микро- и макроэлементы. Макро-веб-архивы обычно управляются крупными информационными организациями, полагающимися на сканирование веб-страниц, которое включает в себя создание «исходных списков» и автоматизацию рутинных повторяющихся обходов для создания надежных и всеобъемлющих снимков быстро меняющейся сети. Методы веб-сканирования являются наиболее трудоемкими и ресурсоемкими, поскольку они нацелены на захват целых веб-страниц и онлайн-ресурсов путем систематического «сканирования» каждой встроенной гиперссылки на веб-сайте для захвата каждой части сложных и многоуровневых веб-ресурсов (Миллиган, 2016) .Сканирование может иметь разный уровень автоматизации, а начальные списки часто добавляются веб-архиваторами для расширения охвата поисковых роботов. Если веб-сканирование — это макро-метод, который можно автоматизировать в масштабе, микротехники являются более целенаправленными и менее рутинными, такими как извлечение API, или сосредоточены на захвате динамических функций пользовательского интерфейса с помощью скринкастов или снимков экрана. Проекты микро-архивирования сети обычно управляются отдельными лицами и небольшими группами исследователей, которые хотят захватить определенные фрагменты сети, чтобы проиллюстрировать событие, социальное движение или возникающее поведение.Веб-сканирование не ограничивается веб-сайтами, проиндексированными поисковыми системами, они также включают отдельные веб-страницы, которые пользователи сохраняют с помощью таких функций, как «Сохранить страницу сейчас» или ранее с помощью панели инструментов Alexa (Rogers, 2017). После того, как URL-адрес был добавлен в исходный список, он также может появиться во многих различных коллекциях и быть захвачен различными автоматическими поисковыми роботами. Наше исследование показало, что как макроинструменты, так и микроинструменты накладываются друг на друга, чтобы формировать общественное мнение о COVID-19 и распространять дезинформацию на социальных платформах, которые все чаще используются в качестве общедоступных информационных инфраструктур.
В своем исследовании сохранения северокорейской сети Интернет-архивами Бен-Дэвид и Амрам обнаружили, что знания, полученные в результате обхода веб-сайтов Wayback Machine, исходят от людей и других субъектов и «включают активный человеческий вклад, рутинный управлял веб-сканированием, а также курировал и оценивал веб-обход коллекций, утверждая, что эти архивные снимки похожи на другие алгоритмические черные ящики (Ben-David & Amram, 2018, p. 195). Несмотря на эти рутинные обходы всей сети, отдельные акторы-люди стратегически добавляют в коллекции для различных целей и методов памяти.Многие утверждали, что необходимо провести дополнительные исследования решений архивистов об оценке и «работы веб-архивов», чтобы понять, каким образом человеческие и нечеловеческие субъекты влияют на коллекции ресурсов, которые приводят к истории Интернета (Ogden et al., 2017 ). Наше расследование показало, что и люди, и боты архивировали онлайн-дезинформацию, но что больше людей использовали Сохранить страницу сейчас для архивации ресурса после того, как Facebook модерировал и пометил действующий URL как дезинформацию о состоянии здоровья.
В этом исследовании мы стремились выяснить, как дезинформация о здоровье в Интернете архивируется, а затем превращается в оружие, используя тактику обработки данных, имитирующую легитимность с помощью надежных URL-адресов, и практику, которую мы называем выборкой экрана.Отвечая на эти исследовательские вопросы, мы показали, как обработка данных превращает веб-архивы в оружие и влияет на то, как платформы привлекают внимание общественности к COVID-19, способствуя дезинфодемии коронавируса. Здесь мы утверждаем, что у исследователей дезинформации есть возможность изучить эту взаимосвязь между пассивными и активными архивными агентами и их намерения архивировать дезинформацию, а также статус вооруженных веб-архивов, которые уклоняются от модерации и удаления контента на платформах из-за того, что им доверяют. URL-адреса.
Выводы
В марте 2020 года наша исследовательская группа начала сбор, маркировку и систематизацию примеров дезинформации о здоровье COVID-19, распространяющейся через снимки экрана в сообщениях в социальных сетях. В наборе данных четыре снимка экрана, сохраненные из одной ветки Twitter, опубликованные пользователем @narvonocutz 12 марта 2020 г., выявили дезинформацию о состоянии здоровья, которая была захвачена и заархивирована с помощью Internet Archive Wayback Machine (рисунок 1) (Narvo, 2020).
Рисунок 1. Screensampling: скриншоты с web.archive.org, сделанные @narvonocutz и опубликованные в Twitter .Эти снимки экрана были взяты из статьи о заговоре «КОРОНАВИРУСНЫЙ ДОМ: поддельная пандемия вируса, сфабрикованная для сокрытия глобальной вспышки синдрома 5G», которая была заархивирована веб-сканерами Wayback Machine из Интернет-архива 9 марта 2020 г. (The Millennium Report , 2020). Исходная статья, появившаяся на веб-сайте The Millennium Report 2 марта 2020 года, была впервые просканирована и сохранена Wayback Machine 2 марта 2020 года (далее мы используем «исходный URL-адрес» и «заархивированный URL-адрес» для ссылки на них. два источника).Изучив снимки экрана, мы смогли найти исходный URL-адрес, а также заархивированный URL-адрес, размещенный на Wayback Machine Интернет-архива на web.archive.org. Используя информацию о происхождении, полученную от нескольких поисковых роботов Internet Archive, мы обнаружили, что отдельные акторы-люди заархивировали и сканировали веб-страницу, а затем загружали ботов для автоматического рутинного обхода веб-сайта.
Используя эти заархивированные снимки как своего рода прокси, а не исходный URL-адрес web.archive.Ссылки org могут легко обойти существующие системы модерации контента, используемые платформами. Как ранее описывал Донован, «скрытая вирусность» статьи проявлялась не в ее исходной форме URL, а в архивной версии, хранящейся в Wayback Machine (Донован, 2020). Веб-архив Wayback Machine позволяет использовать общедоступные, относительно анонимные (без профиля или входа в систему) средства распространения дезинформации из сети и последующего ее размещения, даже если исходный URL-адрес был удален или не опубликован в действующей сети.Эта тактика хранения дезинформации и очень эфемерного контента позволяет манипуляторам использовать веб-архив в качестве механизма распространения, позволяя избежать модерации контента и дольше жить на платформах.
Скрытая вирусность заархивированных URL-адресов Wayback может быть дополнительно усугублена практикой выборки экрана, когда цифровое извлечение архивного снимка создает новый цифровой актив, который может легко увеличить распространение сомнительного контента (как показано на рисунке 1). Публикация изображений текста позволяет людям-читателям просматривать контент, минуя механизмы модерации контента, поскольку форматы изображений с текстом не легко читаются машиной.Скринсэмплинг извлеченных источников из веб-архивов позволяет пользователям, таким как @narvonocutz, реконструировать и распространять контент из надежного источника (Wayback Machine), создавая при этом новую публикацию или поток реконекстуализированного контента, состоящего из изображений, которые не модерируются, но также скрывают заархивированный URL с помощью отключение гиперссылки и сокращение исходного URL. Эти снимки экрана, заимствованные из исходного источника, представляют собой серьезную атрибуцию исходного URL-адреса, распространение контента без возможности отслеживания и создание «меметической абстракции» (Chaiet, 2019).Заархивированный URL-адрес статьи «CORONAVIRUS HOAX» в Докладе тысячелетия на момент написания этой статьи был захвачен веб-сканированием с помощью различных инструментов веб-архивирования Internet Archive примерно 448 раз с начала марта 2020 года (рис. 2).
Рисунок 2. Представление календаря из Internet Archive Wayback Machine, отображающее 448 снимков веб-сканирования статьи «CORONAVIRUS HOAX» в Отчете тысячелетия, с 3 марта 2020 года по 17 мая 2020 года.Недавно была запущена Internet Archive Wayback Machine публиковать информацию о происхождении об источнике и типе веб-обходов (Internet Archive, 2018).Эта функция позволяет нам видеть больше информации о цели или контексте захвата, а также связанных коллекциях, в которых сохраняется сканирование. Эта информация о происхождении позволяет исследователям лучше понять, когда агенты-люди целенаправленно архивировали снимок с помощью функции «Сохранить страницу сейчас», а также были ли снимки автоматически автоматизированы как часть обычных архивных сборов, выполняемых поисковыми роботами и веб-роботами. Применяя эту функцию происхождения в любом масштабе и собирая информацию обо всех типах веб-обходов определенного веб-ресурса, мы можем сравнить упреждающий человеческий вклад в Wayback Machine с автоматическими рутинными обходами, которые подпитывают определенные коллекции Интернет-архива.В частности, различные типы обходов, которые появились в Wayback Machine исходного URL-адреса, впервые опубликованного 2 марта 2020 года, следуют темпу, который соответствует внешней проверке фактов и модерации исходного URL-адреса на Facebook. Мы проверили N = 17 различных видов веб-обходов, которые указывают на широкую экологию агентов веб-архивов — как нечеловеческих, так и человеческих субъектов. Эти веб-обходы создают ряд конкретных коллекций в Интернет-архиве, включая коллекции исходящих URL-адресов, размещенных в Twitter, коллекции фальшивых новостей, партнерские коллекции Archive-It, которые подписываются на веб-службы Интернет-архива, а также широкие обходы всей сети. (Интернет-архив, 2018).В таких коллекциях, как «Fake News II», веб-архивисты управляют раздачей веб-обходов, но коллекции, такие как «Live Web» прокси-обходы, в основном загружаются людьми, использующими «Сохранить страницу сейчас». Как общие, так и ориентированные на контент семена играют важную роль в оценке того, что будет (и не будет) доступно в сети будущего (Summers & Punzalan, 2017), а также когда отдельные акторы-люди решат использовать «Сохранить страницу сейчас».
Рисунок 3. Диалоговое окно Facebook Fact-Check, которое появляется при публикации статьи «CORONA HOAX».9 марта 2020 года, через неделю после публикации статьи в отчете «Миллениум» и появления оригинального URL-адреса в Facebook и Twitter, PolitiFact проверил факты и проверил утверждения и источники, цитируемые в статье (Kertscher, 2020). Репортаж обнаружил, что не было никаких достоверных доказательств, подтверждающих утверждения в статье «CORONA HOAX». Вскоре после этого Facebook начал предупреждать пользователей, намеревающихся поделиться исходным URL-адресом (рис. 3). В тот же день веб-сканеры Wayback Machine «LiveWeb» и «WebWideCrawl» начали архивировать исходный URL-адрес для моментальных снимков.Обе коллекции питаются в основном функцией «Сохранить страницу сейчас», которая сохраняет только одну страницу (Internet Archive, 2018). Хотя исходный URL-адрес ранее сканировался автоматическими поисковыми роботами с 3 по 8 марта, только после того, как статья была проверена и помечена Facebook, отдельные агенты-люди начали активно архивировать ее с помощью «Сохранить страницу сейчас» и «Сохранить страницу». Теперь прокси-серверы по сравнению с ранее автоматизированными веб-сканерами Wayback Machine, загружающими коллекции, такие как исходящие ссылки Twitter или партнеры Archive-It.
Распространение исходного URL-адреса и заархивированного URL-адреса на Facebook также можно сравнить с использованием данных социальной аналитики из CrowdTangle, принадлежащего Facebook. Они предоставляют общедоступную аналитику того, как далеко распространяются ссылки на Facebook в начале марта, и общее количество взаимодействий с публикацией, указывающее на популярность и охват каждого URL-адреса. Таблица 1 показывает, что заархивированный URL-адрес, распространенный в Facebook, превзошел исходный URL-адрес по охвату, вовлечению, просмотрам и репостам (Fraser, 2020).Хотя исходный URL-адрес сейчас проверен, отмечен и модерирован Facebook, пользователи по-прежнему могут публиковать дезинформацию о состоянии здоровья сегодня. Однако заархивированный URL-адрес той же дезинформации еще не был отмечен или идентифицирован платформой как нарушающий политики платформы.
Таблица 1. Данные взаимодействия от CrowdTangle, сравнивающие исходный URL-адрес и заархивированный URL-адрес. URL-адрес Wayback Machine превзошел по всем показателям вовлеченности Facebook, тем самым распространяя дезинформацию дальше, чем исходный URL-адрес.Превращение веб-архивов в оружие и выборка экранов для избежания модерации дезинформации — это не только средства обработки данных для платформ, пытающихся детоксифицировать свои сети дезинформации и вредоносной дезинформации, но и новая проблема для исследователей дезинформации, тактика отслеживания и разработка новых методов изучения поведения в Интернете. В процессе обработки данных выборка экрана становится еще одним препятствием для пользователей, исследователей и платформ, пытающихся определить исходный источник контента, а инструменты социальной аналитики, такие как CrowdTangle, никогда не смогут количественно определить количество пользователей, которые скриншоты статьи, а затем публикуют ее части. это с их собственным обрамляющим комментарием.По мере того как исследователи борются с пандемией, было много призывов к более пристальному вниманию к информационным методам, усилиям по цифровому архивированию, управлению данными и важности сохранения этого момента (Xie et al., 2020). Здесь мы призываем наши исследовательские сообщества учитывать информационные практики новых сообществ COVID-19 и распространение дезинформации, хранящейся в веб-архивах, поскольку это свидетельствует как о недоверии, так и о осведомленности о текущих усилиях платформ по автоматической модерации и проверке фактов.Поскольку исследователи дезинформации продолжают изучать информационные практики, обнаруженные на частных платформах, которые собирают публику COVID-19, нам необходимо расширить сферу охвата, чтобы рассмотреть распространение сомнительной информации, обнаруженной в веб-архивах, и изучить их статус по мере того, как они становятся оружием на платформах с data craft.
Методы
Следуя инновационному методу сбора информации о происхождении от веб-сканирования IAWM (2018 г.) Бен-Дэвида и Амрама, мы использовали судебно-медицинский анализ, чтобы узнать, когда человеческие агенты направляли веб-сканеры для архивирования дезинформации о состоянии здоровья, связанной с заговором о коронавирусе 5G (по сравнению с автоматизированным списки семян и боты, которые архивируют Интернет).Доступность данных о происхождении веб-сканирования предоставила нам легкодоступные данные и описательные метаданные для анализа. Определив исходный URL-адрес из снимков экрана, опубликованных в Twitter, мы извлекли информацию о происхождении из веб-сканирований заархивированного URL-адреса Отчета о тысячелетии (с 3 марта 2020 г. по 17 мая 2020 г.). Затем мы сравнили заархивированные снимки с исходным URL-адресом с помощью Crowdtangle, панели инструментов социальной аналитики Facebook, чтобы измерить взаимодействие между исходным URL-адресом и URL-адресом, заархивированным в Интернете, для сравнения их распространения и приема.Используя аналитику Crowdtangle для анализа данных о взаимодействии и подтверждения более широкого распространения заархивированного URL-адреса, чем исходный URL-адрес, мы смогли выявить скрытую вирусность URL-адреса веб-архива, который позволяет избежать быстрой автоматической модерации вредоносной дезинформации платформами, поскольку он размещен на надежный домен веб-архива. При наблюдении за методами выборки из архивных URL-адресов, распространяемых среди публики COVID-19 на платформах, одни и те же веб-архивы могут использоваться для разных целей, чтобы усилить сомнения и распространить опасную и ненадежную дезинформацию о здоровье.
Screensampling создает меметическую абстракцию от исходного источника путем преобразования веб-ресурса в изображение, что приводит к трансмедийному преобразованию существующего контента. Помимо преобразования текста в растровое изображение, снимок экрана может одновременно инкапсулировать больше слоев контекстной информации для изучения исследователями, такой как мобильная сеть устройства, временные метки, доменные имена и другие очевидные элементы пользовательского интерфейса (Chaiet, 2019). Хотя такие идентифицирующие признаки сродни традиционным метаданным в цифровых форматах, они фиксируются в янтаре изображения, а не в метаданных объекта, которые в противном случае могли бы быть извлечены программно.Примеры экранов (как на рисунке 1) представляют собой снимки экрана с текстом, поэтому последующие контекстные «метаданные» не читаются компьютером, однако эти сообщения на основе изображений читаются человеком и могут нарушить работу систем модерации текстового контента.
Как и другие исследователи, изучающие веб-архивистов и их решения о сканировании (Maemura et al., 2018; Ogden et al., 2017), мы обнаруживаем, что индивидуальный вклад человека сыграл роль в распространении этой дезинформации на таких платформах, как Facebook и Twitter. , а также по его появлению в ряде коллекций Wayback, засеянных Save Page Now.Аналитика социальных сетей позволяет нам изучать тенденции производительности URL-адресов на платформе, сравнивая показатели взаимодействия в наборе данных с показателями более ранних или различных версий URL-адресов и их производных. Тем не менее, необходимы дополнительные исследования для опроса пользователей, создателей и тех, кто использует инструменты веб-архивирования, такие как Save Page Now, об их восприятии и понимании URL-адресов, хранящихся в веб-архиве, с точки зрения доверия, модерации контента и распространения дезинформации на платформах.
Интернет-архив 11 сентября (октябрь 2001 г.)
Библиотека Конгресса в сотрудничестве с Интернет-архив, Pew Internet & American Life Project и webArchivist.org, объявила о выпуске сборника цифровых материалы под названием «Интернет-архив от 11 сентября» доступны на сайте September11.archive.org.
Архив сохраняет веб-выражения отдельных лиц, групп, пресса и учреждения в Соединенных Штатах и со всего мира world после терактов в США 7 сентября. 11, 2001. Архив важен, потому что он способствует исторической запись, захват информации, которая в противном случае могла бы быть потеряна.С растущая роль Интернета как влиятельной среды, записи исторических события можно было бы считать неполными без материалов, которые «родились» цифровой «и никогда не печатается на бумаге. Поскольку веб-контент изменяется в очень быстрым темпом, важно сразу захватить национальный и международная реакция на эти события до того, как они исчезнут из историческая запись.
Сотрудники Библиотеки Конгресса рекомендовали включить в список веб-сайты. в Архиве, как и в случае с физическими коллекциями Библиотека.
«Задача библиотеки — собрать и сделать доступными эти материалы. чтобы будущие ученые, преподаватели и исследователи могли не только знать что думали и сообщали официальные организации того времени о нападениях на Америку 11 сентября, но можете прочитать неофициальные, «Онлайн-дневники» тех, кто пережил этот опыт и поделился их точки зрения «, — сказал младший библиотекарь библиотечных служб. Уинстон Табб.«Такие сайты — очень мощные первоисточники».
«Интернет так же важен, как и печатные СМИ, для их документирования. мероприятий «, — сказала Дайан Креш, директор отдела общественных услуг библиотеки. Коллекции. «Почему? Потому что Интернет мгновенно, далеко идёт, и достигает самых разных аудиторий. У вас есть все от самозваных от экспертов до известных экспертов, комментирующих и излагающих свою точку зрения ».
«Самое замечательное в Интернете — это то, что это мировая перспектива», сказал Брюстер Кале, основатель Internet Archive.»Это форум для понимания других точек зрения, а не только традиционных СМИ «
«Традиционно исследователи обращались к книгам, письмам, фильмам и искусство, чтобы осмыслить определение исторических моментов. Но с повсеместным распространением Интернета и электронных коммуникаций, ученые также получат изучать веб-сайты, чтобы понять этот недавний акт разрушения и кровавая бойня, — сказал Стивен М.Шнайдер, доцент кафедры политических наука в Технологическом институте SUNY в Ютике / Риме. Кирстен Фут, доцент кафедры коммуникаций Вашингтонского университета добавил: «Существует потенциал возникновения нового уровня гражданской активности. Произошел огромный рост числа людей, которые чувствуют себя вынужденными делать заявления. о событиях онлайн. Мы видим это повсюду в Интернете, и мы хотим сохранить запись об этом.«
Эта коллекция станет вторым масштабным собранием веб-сайтов. будут заархивированы и доступны онлайн в рамках постоянного партнерства между Библиотекой Конгресса и Интернет-архивом. В июне 2001 г. Библиотека объявила о своей коллекции «Выборы 2000», созданной для сохранения открытый доступ к веб-материалам, относящимся к ноябрьскому 2000 г. выборы. Сборник «Выборы 2000» доступен в Интернете.archive.org/collections/e2k.html.
Интернет-архив (www.archive.org) является общественной некоммерческой организацией 501 (c) (3), которая была основана для создания «Интернет-библиотека» с целью предоставления постоянного доступа для исследователей, историков и ученых в исторические коллекции существующие в цифровом формате. Основана в 1996 году и расположена в Президио. Сан-Франциско, Архив получает пожертвования данных от Alexa Internet и другие.
WebArchivist.org — это группа ученых и студентов, посвященная разработка инструментов и стратегий для изучения эфемерной сети. В организация (www.webarchivist.org) под руководством профессора Стивена М. Шнайдера, политолога. в Технологическом институте SUNY в Ютике / Риме и Кирстен А. Фут, специалист по коммуникациям Вашингтонского университета.
The Pew Internet & American Life Project (www.pewinternet.org) создает и финансирует оригинальные исследования академического качества, которые исследуют влияние Интернета на детей, семьи, сообщества, рабочее место, школы, здравоохранение и общественно-политическая жизнь. Проэкт, режиссера Ли Рэйни, стремится быть авторитетным источником своевременных информация о росте Интернета и его влиянии на общество через исследования это беспристрастно. Профессора Шнайдер и Фут будут выполнять функции исследователей. Стипендиаты проекта и пишут отчеты, исследуя меняющуюся сеть. сфера после сент.11 терактов.
Назад по октябрь 2001 г. — Том 60, № 10
Можно ли заархивировать Интернет?
Рейс 17 Malaysia Airlines вылетел из Амстердама в 10:31 утра. G.M.T. 17 июля 2014 г. для двенадцатичасового перелета в Куала-Лумпур. Не прошло и трех часов, как самолет Boeing 777 разбился в поле под Донецком, Украина. Все двести девяносто восемь человек на борту погибли. Последний радиоконтакт самолета был в 1:20 P.М. G.M.T. В 14:50, . G.M.T., Игорь Гиркин, лидер украинских сепаратистов, также известный как Стрелков, или кто-то, действующий от его имени, опубликовал в российской социальной сети ВКонтакте сообщение: «Мы только что сбили самолет, Ан-26». (Антонов 26 — это военный грузовой самолет советской постройки.) В сообщении есть ссылки на видео крушения самолета; Судя по всему, это Боинг 777.
Сеть не была создана для сохранения прошлого; Wayback Machine призвана исправить это. Иллюстрация Гарри КэмпбеллаЗа две недели до крушения Анатолий Шмелев, хранитель коллекции «Россия и Евразия» Гуверовского института в Стэнфорде, отправил в Internet Archive, некоммерческую библиотеку в Калифорнии. , список украинских и российских веб-сайтов и блогов, которые следует записать как часть архивной коллекции «Украинский конфликт».Шмелев — один из примерно тысячи библиотекарей и архивистов по всему миру, которые определяют возможные приобретения тематических коллекций Интернет-архива, которые хранятся на его Wayback Machine в Сан-Франциско. Страница Стрелкова ВКонтакте была в списке Шмелева. «Стрелков — полевой командир в Славянске и одна из самых важных фигур в конфликте», — написал Шмелев в электронном письме в Интернет-архив 1 июля, и его страница «заслуживает того, чтобы ее записывали дважды в день».
17 июля в 3:22 P.M. G.M.T., Wayback Machine сохранила скриншот записи Стрелкова ВКонтакте о сбитом самолете. Два часа двадцать две минуты спустя Артур Брайт, европейский редактор Christian Science Monitor , опубликовал в Твиттере фотографию скриншота вместе с сообщением: «Захват донецкого боевика Стрелкова утверждает, что он сбил то, что, по всей видимости, было Mh27. ” К тому времени страница Стрелкова ВКонтакте уже была отредактирована: иск о сбитом самолете сняли. Единственное реальное доказательство первоначального утверждения находится в Wayback Machine.
Средняя продолжительность жизни веб-страницы составляет около ста дней. Пост Стрелкова «Мы только что сбили самолет» длился всего два часа. Может показаться, и часто кажется, что все в Интернете длится вечно, к лучшему, а часто к худшему: смущающая фотография, блог, о котором сожалеют (чаще всего прискорбно не в том смысле, что убийство гражданских лиц достойно сожаления, а в том, что оно мешает что плохие волосы достойны сожаления). Никто больше не верит, если кто-либо когда-либо верил, что «если это есть в сети, это должно быть правдой», но многие люди верят, что если это в сети, то останется в сети.Однако есть вероятность, что на самом деле этого не произойдет. В 2006 году Дэвид Кэмерон выступил с речью, в которой сказал, что Google демократизирует мир, поскольку «предоставление большего количества информации большему количеству людей» дает «возможность любому привлечь к ответственности тех, кто в прошлом мог иметь монополию. власти. » Семь лет спустя Консервативная партия Великобритании стерла со своего веб-сайта выступления тори за десять лет, включая эту. В прошлом году BuzzFeed удалил более четырех тысяч ранних сообщений своих штатных авторов, по-видимому, потому, что со временем они выглядели все глупее и глупее.Социальные сети, публичные записи, мусор: в конце концов, все уходит.
Необязательно удалять веб-страницы, чтобы они исчезли. Сайты, размещенные корпорациями, обычно умирают вместе со своими хостами. Когда MySpace, GeoCities и Friendster были перенастроены или проданы, миллионы аккаунтов исчезли. (Некоторые из этих компаний могли уведомить пользователей, но Джейсон Скотт, который основал группу под названием Archive Team — ее девиз: «Мы собираемся спасти ваше дерьмо», — говорит, что такое уведомление обычно носит чисто условный характер: «Они отправляли электронные сообщения. отправляйте письма на мертвые адреса электронной почты, говоря: «Здравствуйте, Артур Дент, ваш дом будет разрушен.’») Facebook существует всего десять лет; это не будет вечно. Твиттер — редкий случай: он организовал архивирование всех своих твитов в Библиотеке Конгресса. В 2010 году, после этого объявления, Энди Боровиц написал в Твиттере: «Библиотека Конгресса, которая получит весь архив Twitter, переименует себя в Музей дерьма». Вскоре после этого Боровиц покинул свой аккаунт в Твиттере. Возможно, однажды вы сможете найти его старые твиты в Библиотеке Конгресса, но не в ближайшее время: архив Twitter еще не открыт для исследования.Между тем, если в Интернете вы нажмете ссылку на твит Боровица о Музее дерьма, вы получите следующее сообщение: «Извините, этой страницы не существует!»
Сеть пребывает в нескончаемом настоящем. Он — элементарно — эфирный, эфемерный, нестабильный и ненадежный. Иногда, когда вы пытаетесь посетить веб-страницу, вы видите сообщение об ошибке: «Страница не найдена». Это называется «гнилью звеньев», и это неприятно, но лучше, чем альтернатива. Чаще вы видите обновленную веб-страницу; скорее всего оригинал был перезаписан.(Перезапись в вычислениях означает уничтожение старых данных путем сохранения на их месте новых; перезапись — артефакт эпохи, когда компьютерное хранилище было очень дорого.) Или, может быть, страница была перемещена, и что-то еще находится там, где раньше быть. Это известно как «дрейф контента» и более опасен, чем сообщение об ошибке, потому что невозможно сказать, что то, что вы видите, не то, что вы искали: перезапись, стирание или перемещение оригинала невидимый. Для закона и судов гниение ссылок и дрейф контента, которые в совокупности известны как «ссылочная гниль», были катастрофическими.Предоставляя доказательства, ученые-правоведы, юристы и судьи часто ссылаются на веб-страницы в своих сносках; они ожидают, что эти доказательства останутся там, где они нашли их, в качестве доказательства, так же, как доказательства на бумаге — в судебных протоколах, книгах и юридических журналах — останутся там, где они их нашли, в библиотеках и зданиях судов. Но обзор публикаций, связанных с законодательством и политикой, в 2013 году показал, что по прошествии шести лет почти пятьдесят процентов URL-адресов, цитируемых в этих публикациях, больше не работали. Согласно исследованию 2014 года, проведенному Гарвардской школой права, «более 70% URL-адресов в Harvard Law Review и других журналах и 50% URL-адресов в заключениях Верховного суда США не ссылаются на первоначально цитируемую информацию.«Перезапись, дрейф и гниение Интернета не менее катастрофичны для инженеров, ученых и врачей. В прошлом месяце группа исследователей цифровых библиотек из Национальной лаборатории Лос-Аламоса сообщила о результатах тщательного исследования трех с половиной миллионов научных статей, опубликованных в научных, технических и медицинских журналах в период с 1997 по 2012 год: каждая пятая ссылка предоставлена в ноты страдают ссылочной гнилью. Это похоже на попытку встать на зыбучие пески.
Эта сноска, ставшая важной вехой в истории цивилизации, создавалась и распространялась веками.На то, чтобы уничтожить, потребовались буквально годы. В сноске говорилось: «Вот откуда я это знаю и где это нашел». В сноске, представляющей собой ссылку, говорится: «Вот то, что я знал и где однажды нашел, но, скорее всего, этого больше нет». Не имеет значения, являются ли сноски вашим товарным запасом. Все в затруднительном положении. Цитирование веб-страницы как источника чего-то, что вы знаете, — использование URL-адреса в качестве доказательства — является повсеместным. Многие люди делают это три или четыре раза перед завтраком и пять раз перед обедом.Что произойдет, когда ваши доказательства исчезнут к обеду?
На следующий день после того, как сообщение Стрелкова «Мы только что сбили самолет» было помещено в Wayback Machine, посол США в ООН Саманта Пауэр сообщила Совету Безопасности ООН в Нью-Йорке, что лидеры украинских сепаратистов «хвастались». социальные сети о сбитом самолете, но позже удалили эти сообщения ». В Сан-Франциско люди, управляющие Wayback Machine, написали на странице Интернет-архива в Facebook: «Вот почему мы существуем.
Адрес Интернет-архива — archive.org, но еще один способ посетить это — сесть на самолет в Сан-Франциско и проехать на такси до Президио мимо кипарисов, которые выглядят так, будто кто-то нарисовал их там нечеткими пятнами. мелок. На проспекте Фанстон, 300 поднимитесь по каменным ступеням и постучите в медную дверь храма греческого возрождения. Его нельзя пропустить: свадебный торт выкрашен в белый цвет, а перед ним восемь коринфских колонн и шесть мраморных урн.
«Мы купили его, потому что он соответствовал нашему логотипу», — сказал мне Брюстер Кале, когда я встретил его там, и он не шутил.Кале — основатель Интернет-архива и изобретатель Wayback Machine. Логотип Интернет-архива — это белый греческий храм с фронтоном. Когда Кале основал Интернет-архив в 1996 году на своем чердаке, он дал всем, кто работал с ним, книгу под названием «Исчезнувшая библиотека» о сожжении Александрийской библиотеки. «Идея состоит в том, чтобы построить Александрийскую библиотеку-2», — сказал он мне. (Эллинизм идет дальше: есть частичная резервная копия Интернет-архива в Александрии, Египет.План Кале состоит в том, чтобы превзойти греков. Девиз Интернет-архива — «Всеобщий доступ ко всем знаниям». Александрийская библиотека была открыта только для ученых; Интернет-архив открыт для всех. В 2009 году, когда Четвертая Церковь Христа, Ученый, решила продать свое здание, Кале пошла на Фанстон-авеню, чтобы увидеть его, и сказала: «Это наш логотип!» Ему нравится, что краеугольный камень церкви был заложен в 1923 году: все, что было опубликовано в Соединенных Штатах до этой даты, является общественным достоянием.Казалось, что храм, построенный в нулевом году авторских прав, обречен. Кале слегка подпрыгивает на его месте, когда он возбужден. Он говорит, показывая мне церковь: «Это грека! ”
Кале длиннорукая, розовощекая и публичная; его волосы седые и вьющиеся. Он носит круглые очки в проволочной оправе, льняные брюки и рубашки с узором на пуговицах. Он выглядит как мистер Микобер, если мистер Микобер покинул Лондон Диккенса на машине времени и приземлился в Тихом океане примерно в 1955 году, замаскированный под американского туриста.