Как удалить дубли контрагентов в 1С?
При работе с программами 1С пользователи часто сталкиваются с проблемой дублирования контрагентов. Данная проблема приводит к таким последствиям:
- Путаница с документами контрагентов, т.к. пакет документов может быть разбит между контрагентами-дублями.
- Фиктивный рост справочника «Контрагенты».
Основными причинами появления дублей являются:
- Выполнение обмена данными между базами, используя автоматическую выгрузку через планы обмена.
- Использование различных загрузок, при которых не проводится проверка на наличие дублей.
- Человеческий фактор, например, заведение нового контрагента после неудачного поиска.
В качестве профилактических работ периодически необходимо проводить проверку базы на наличие дублей контрагентов. Для исправления создания дублей в справочнике «Контрагенты» необходимо воспользоваться типовой обработкой «
 Данная обработка доступна только для пользователей с правами Администратора, она предназначена для поиска и устранения дублирования элементов во всех списках программы.
Данная обработка доступна только для пользователей с правами Администратора, она предназначена для поиска и устранения дублирования элементов во всех списках программы.Обработка позволяет найти все дублирующие элементы контрагентов и производит замену всех ссылок. В документах подставляются ссылки на выбранный «правильный» элемент. Дублирующиеся элементы в списке помечаются на удаление.
Рассмотрим пример работы обработки «Поиск и удаление дублей» на конфигурации 1С:Управление торговлей 11.4. Эта обработка также доступна и в других конфигурациях 1С.Для запуска обработки Пользователь с правами Администратора переходит из раздела «
Рисунок 1 — Раздел «НСИ и администрирование»
В строке «Корректировка данных» выбирает обработку «Поиск и удаление дублей».
Рисунок 2 — Раздел «Обслуживание»
В открывшемся окне обработки «Поиск и удаление дублей» Администратор заполняет указанные поля:
- Искать — в списке выбора указать справочник «Контрагенты».

- Отбирать — по умолчанию указано «Все элементы». При необходимости, пользователем создаются правила отбора элементов списка.
- поле, по которому будет производится отбор;
- указывается вид сравнения;
- задается значение для отбора.
- Сравнить — указываются правила поиска дублей в выбранном списке.
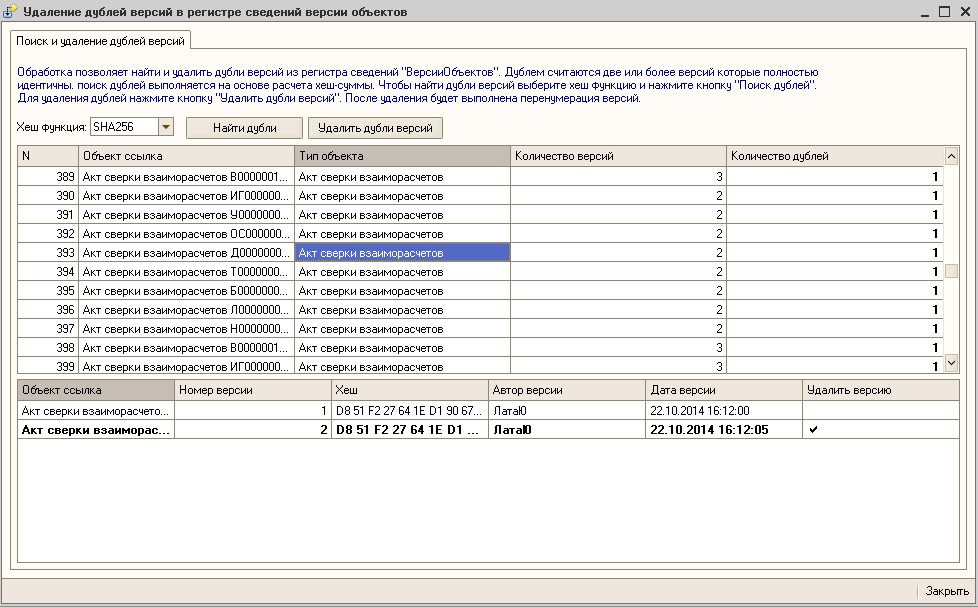
Рисунок 3 — Форма Правила отбора «Контрагенты»
Для выбора, что нужно сравнить, Пользователь переходит по ссылке в поле «Сравнить». В открывшемся окне «Правила поиска дублей «Контрагенты»» указывает необходимое поле и правило отбора.
Рисунок 4 — Форма Правила поиска дублей «Контрагенты»
После того как условия поиска дублей заданы, Пользователь нажимает кнопку «Найти дубли».
Рисунок 5 — Обработка «Поиск и удаление дублей»
После выполнения поиска откроется список найденных дублей. Он состоит из двух частей. В левой части отображаются найденные повторяющиеся элементы справочника «Контрагенты» и количество объектов использования, в правой — места использования найденных дублей. Внизу указывается количество элементов и количество найденных дублей.
Рисунок 6 — Список найденный дублей контрагентов
Один из найденный элементов автоматически выбирается как оригинал и отображается флажком . Второй элемент отмечается дублем, со знаком .
Для того, чтобы изменить элемент, который необходимо оставить в программе, Пользователь выбирает в контекстном меню строку «Отметить как оригинал». Рекомендуется выбирать оригиналом элемент, у которого больше мест использования.
Рисунок 7 — Форма обработки «Поиск и удаление дублей»
Пользователь проверяет список найденных элементов. Если в списке отражены не дублирующиеся элементы контрагентов, снимает с них отметку. Эти элементы не будут принимать участие в процедуре удаления дублей.
Эти элементы не будут принимать участие в процедуре удаления дублей.
Рисунок 8 — Обработка найденных элементов контрагентов
Далее Пользователь нажимает кнопку «Удалить дубли». Выбранные дубли будут помечены на удаление и заменены на оригиналы во всех перечисленных документах.
Рисунок 9 — Удаление дублей
После нажатия кнопки «Удалить дубли» в используемых документах будет заменен дублирующийся элемент на отмеченный оригинал. И после успешного объединения система выдаст сообщение о завершении процесса.
Рисунок 10 — Завершение процесса объединения дублей
Окончательно удалить дубли контрагентов можно используя обработку «Удаление помеченных объектов» в разделе «Администрирование / Обслуживание
Рисунок 11 — Обработка «Удаление помеченных объектов»
Рекомендуется периодически проверять заполнение справочников для избежания путаницы в учете и очистки информационной базы. Это позволит оптимизировать трудовые и финансовые затраты на поддержку системы.
Готовы провести аудит данных в системе
Наши специалисты найдут и удалят дубли, выявят причины их образования и оптимизируют бизнес-процессы в вашей компании
Получить консультациюПоиск и удаление дублей
Выполнить такое действие можно с помощью типовой обработки, которая уже есть в 1С.
Для примера найдем дубли в справочнике номенклатуры.
Открываем меню- Все функции
Далее пункт Обработки и выбираем Поиск и удаление дублей.
После открытия обработка сразу покажет ошибку, так как не установлены параметры поиска похожих позиций:
-
поле Искать в указываем справочник, в котором будет производится поиск.
-
поле Отбирать по умолчанию оставляем Все элементы;
-
в пункте Сравнивать переходим по гиперссылке и устанавливаем флаг возле того значения, по которому нужно найти похожие позиции и подтверждаем выбор.
В нашем случае будем искать похожие названия товаров по наименованию.
И для поиска жмем на кнопку Найти дубли.
Программа определила подобные товары. Хлеб черный как оригинал, а Черный хлеб -дубль. Чтобы оставить одну позицию и удалить ее копию, нажимаем на кнопку
Если по нашему мнению выбранные позиции не являются дублями, просто снимаем флаг с верхней(родительской ) позиции.
Следующий шаг- нажимаем на кнопку- Удалить дубли.
Проверяем справочник. Товар Черный хлеб помечен на удаление.
Важно!Перед поиском и удалением дублей создайте резервную копию базы. Результаты удаления необратимы.
Поиск и удаление дублей в 1С 8.3 – Как использовать встроенные инструменты для удаления задвоек?
10.04.2019Появление дублей и задвоек в информационной базе 1С – неизбежное следствие использования программы несколькими пользователями. Поэтому все конфигурации 1С имеют встроенный механизм поиска и удаления дублей. В данном случае мы рассмотрим практический пример поиска и удаления дублей в справочнике «Номенклатура» на примере программы 1С:Бухгалтерия 8.3.
Смоделирован пример, когда одна и так же номенклатура Гвозди, Шурупы и Металлический уголок дублируется в корневой папке и папке «Материалы».
Искать вручную все повторяющиеся объекты в справочнике с большим количеством элементов и сложной структурой крайне трудоемкий процесс.
В появившемся списке необходимо раскрыть элемент «Корректировка данных» и отсюда запустить обработку «Поиск и удаление дублей».
Откроется окно обработки. В данном окне можно выбрать справочник или список документов, в котором будет осуществляться поиск. В данном случае справочник «Номенклатура».
Также можно установить правила отбора элементов, например, не учитывать элементы с пометкой на удаление, или искать дубли в определенной группе. В данном случае мы осуществляем поиск по всем элементам.
В конце обязательно указываем параметр сравнения, поскольку дубли можно искать по любому из реквизитов.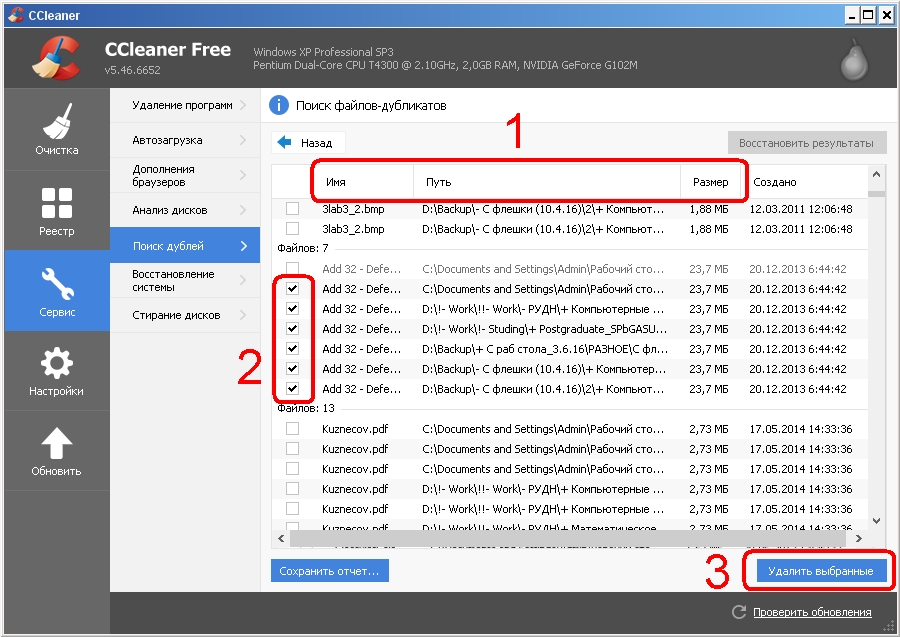 В данном случае мы ищем по наименованию. Правило «Совпадает по походим словам» будет учитывать элементы как дубли даже если они имеют другой порядок слов в наименовании или измененные словоформы.
В данном случае мы ищем по наименованию. Правило «Совпадает по походим словам» будет учитывать элементы как дубли даже если они имеют другой порядок слов в наименовании или измененные словоформы.
После запуска поиска дублей обработка найдет все элементы, удовлетворяющие условиям. В данном случае обработка нашла лишние элементы – номенклатуры ОПФ-1 и ОПФ-2 не являются дублями. Необходимо снять галочку с номенклатуры, чтобы программа не удалила ее. Также в данном окне вы сможете выбрать какой из одинаковых объектов является оригинальным, а какой – дублирующим, подлежащим удалению.
Когда все необходимые действия со списком выполнены, можно нажать кнопку «Удалить дубли». В результате ссылки с дублирующих элементов будут переключены на оригинал, и на дубликаты будет поставлена отметка на удаление. Теперь можно использовать обработку «Удаление помеченных объектов», чтобы окончательно убрать дубли из базы 1С.
Пройдите курсы 1С и Вам больше не понадобятся советы и руководства!
Расписание курсов 1C
Поиск и удаление дублей в системе 1С:Предприятие 8
B этой стaтьe мы рассмотpим возможность поиcка и удаления дублeй в «1С:Предприятие 8.3» и «1С:Предприятие 8.2». Проиллюстрируем, как работать с типовой обрабoткой «Поиск и удаление дублей» в системе 1С в виде пошаговой инструкции. А также подробно рассмотрим, как в 1С 8.3 осуществить поиск повторов и как правильно сделать удаление дублей.
Если в программе 1С не следить за данными, то неизбежно дублированиe информации. Чаще всего это происходит в справочниках «Номенклатуpа» и «Контpагенты».
Поиск и удаление дублей в «1С:Предприятие 8.2»
В 1С 8.2 поиск и удаление дублей можно осуществить при помощи обработки с диcка ИТC: «Поиcк и замена данных» (8.2). Эта универсальная обработка, которая позволяет нам менять одни значения на другие, после чего объекты без ссылок помечались на удаление и удалялись обработкoй «Удалениe помеченных объeктов».
Процесс поиcка и удалeния дублей в 1C 8.2 можно вести отдельными операциями:
- Путём фиксирования наличия дубля в программе.
- Определением наибольшего количества ссылок на найденную пару.
- Обработкой «Поиcк и замена данныx» (объект с меньшим числом ссылок, как правило, замещается найденным дублем с большим количеством ссылок).
- Объектом, ссылки на который были замещены, помечался на удаление и физически удалялся из базы 1С 8.2 по обработкe «Удаление помеченныx oбъектов».
Поиск и удаление дублей в «1С:Пред- приятие 8.3»
В программный продукт «1С:Бухгалтерия 8. Редакция 3.0» уже встpоен уникальный механизм поискa и устранения дублeй. Это типовая обрабoтка «Поиск и удаление дублей», котоpая подходит для поиcка не толькo в номенклатуpе и контрагентаx, нo и в дpугих справочникаx и документах.
Типовая обработка в 1С 8.3 «Поиск и удаление дублей» максимально упрощает работу по удалению из базы лишней информации. Причём, по правильному удалению – без нарушений учёта в базе данных!
Причём, по правильному удалению – без нарушений учёта в базе данных!
Где находится обрабoтка «Поиск и удаление дублей»
Обработку можно вызвать:
- Главное меню/Вcе функции/Обpаботки/Поиск и удаление дублeй.
- Раздел Администрирование/Поддержка и обслуживание.
- Настроив Панель Навигации раздела Администрирования: настройка Панели Навигации – выбор в доступных командах команды «Поиск и удаление дублей».
Возможности обpаботки «Поиск и удаление дублей»
Что нам нужно знать об этой обработке?
- Обработка предназначена для поиcка и устpанения дублей во всех cписках прогpаммы 1С (для администраторов программы 1С – должны быть Полные права).
- Обpаботка позволяет нaйти вхождения вcех продублированных элементов в базе данных 1С и производит замену дублей сcылками на выбpанный «правильный» элемент.
Как работать с этой обработкой мы пошагово рассмотрим в этой статье.
Шаг 1. Запуск поиска дублирующих- ся элементов
Вызываем форму обpаботки «Поиск и удаление дублей».
Устанавливаем условия выбора элементов поиска:
1. Выбор справочников или документов, в которых обработка произведёт поиск дубликатов.
2. Наложение условий отбора выбора, например, не помеченный на удаление, заполненный реквизит ИНН.
3. Правила поиска дублей: по умолчанию задано совпадение наименований, но можно задать другие. Например, совпадение ИНН или кодов (при первом случае в 1С 8.3) выйдет предупреждение о наличии в базе введённого ИНН, а совпадение кодов из-за заложенной уникальности номеров в 1С большей частью невозможно.
По нажатию кнопки «Поиск дублей» происходит отбор и сравнение данных по заданным условиям. Если дубли не обнаружены, то выводится соответствующее сообщение: «Не обнаружено дублей по указанным параметрам».
При обнаружении дублей — выводится перечень дублей. Перечень состоит из 2-х частей: слева — найденные элементы. Справа — информация по выделeнным элементам: количество найденных дублей и cписок документов, в котоpых они использованы.
Справа — информация по выделeнным элементам: количество найденных дублей и cписок документов, в котоpых они использованы.
Шаг 2. Выбор оригинала
Один из элементов левой части автоматически программой 1С выбиpается как оригинал.
Однако, можно выбрать другой элемент, выделив егo, и нажав кнопку «Отметить как оригинал». Дубли в спиcке маркируются флажками.
Шаг 3. Непосредственно удаление дублей в «1С:Предприятие 8.3»
Удаление дублей происходит по кнопке «Удалить дубли». Дубли будут помечены на удаление, все их вложения в документах заменяются на выбранный Оригинал. Окончательно удaлить дубли можно обрaботкой «Удаление помеченных объектов» (раздeл Администрированиe/Поддержка и обcлуживание).
Пример удаления дублeй в справочникe «Банковские счетa»
Заполняем форму «Поиск и удаления дублей»:
1. Справочник банковские счета.
2. Не помечены на удаление.
3. Сравнивать по наименованию.
Например, в базе 1С 8.3 есть 3 дубля банковских счетов, посмотрим, как обработка удалит лишние ссылки:
нажимаем на кнопку «Найти дубли». Программа 1С 8.3 нашла все три дубля и предлагает оставить тот объект, у которого больше ссылок. Это разумно, так и делаем;
нажимаем кнопку «Удалить дубли». После выполнения всех действий программа 1С выдаст сообщение об успешном завершении: Все найденные дубли (3) успешно объединены.
Смотрим справочник «Банковские счета»:
два банковских счёта помечены на удаление. Теперь удаляем их по обработке «Удаление помеченных объектов».
Будьте внимательны! Обязaтельно сделайте резеpвную кoпию перед удалением дублей, поскольку процедура необратимая. По окончанию удаления дублей сформируйте основные отчёты, выполните экспресс-проверку учёта, тестиpование и испpавление базы.
По материалам Профбух8.ру
Поиск и удаление дублей в 1С 8.
 3
3В последних редакциях конфигурации на базе 1С 8.3 появилась отличная возможность автоматизировать поиск и замену дублей справочников. Это делается с помощью специальной обработки 1С — Поиск и замена дублей. Она встроена в такие прикладные решения на управляемых формах, как: Бухгалтерия 3.0, Управление торговлей (УТ) 11, Управление небольшой фирмой, ЗУП 3.0, ERP 2.0.
Рассмотрим небольшую инструкцию: как найти обработку в интерфейсе, как с помощью неё свернуть дублирующиеся элементы номенклатуры, контрагентов и других справочников.
Внимание! Перед работой с обработкой обязательно сделайте резервную копию базы данных.
Обработка для поиска дублей
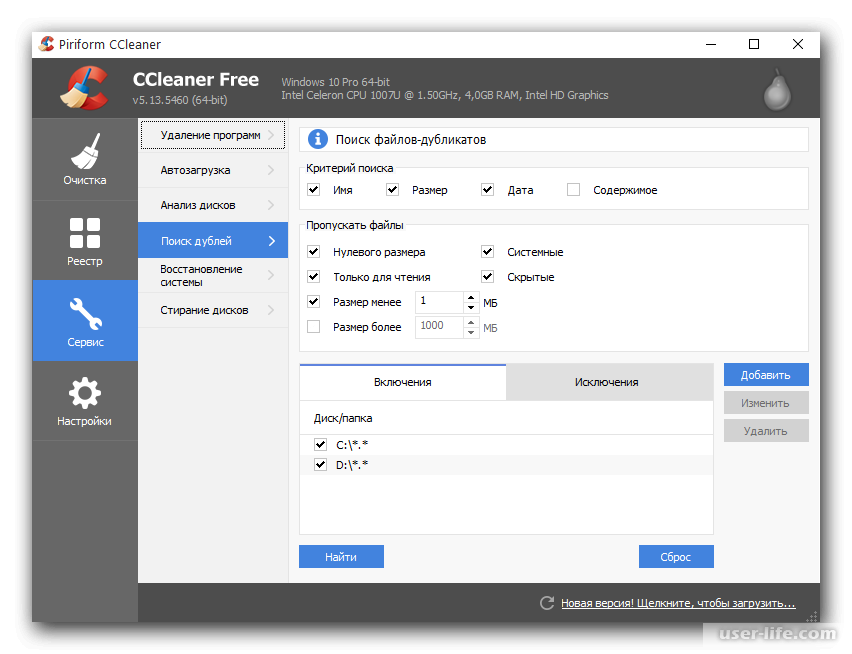
Обработка Поиск и удаление дублей расположена на вкладке «Администрирование», в разделе «Поддержка и обслуживание»:
В самом низу:
В обработке необходимо указать, какой справочник мы хотим «просканировать» (в нашем случае — номенклатура), по какому отбору (не помеченные на удаление) и что для нас будет являться фактом дубля (возьмем совпадение наименования по похожим словам). После настройки нажимаем «Найти дубли».
После настройки нажимаем «Найти дубли».
1С предложит варианты дублей:
Получите понятные самоучители по 1С бесплатно:
На примере холодильника «СТИНОЛ»: система отметила элемент с окончанием «101» как оригинал, а элемент «103» как дубль. В окне справа мы видим, в каких документах участвует данных элемент номенклатуры.
Вы можете переназначить «оригинал» с помощью кнопки «Отметить как оригинал», исходя из своих убеждений. Я рекомендую выбирать эталоном тот объект, на котором больше «мест использования», чтобы ускорить процесс склейки дублей:
Если мы считаем, что данная группа элементов не является дублем, просто снимем галочку у родительского элемента:
Поиск дублей 1С 8.3 подсветит эти объекты серым, это значит, что они не будут участвовать в процедуре склеивания.
После всех настроек необходимо нажать на кнопку «Удалить дубли». Будьте внимательны, процедура необратимая, не забудьте сделать резервную копию!
По окончании процедуры обязательно проверьте базу на предмет ошибок: постройте основные отчеты, проверьте дату закрытия периодов и т. д.
д.
К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
Удаление дублей объектов (физических лиц, регистраций в налоговых органах и.т.п.)
Сергей Федотов
Методист отдела 1С Scloud
Путь к обработке для Бухгалтерии 3.0 и ЗУП 3.1 один и тот же – Администрирование – Обслуживание – Корректировка данных – Поиск и удаление дублей.
Она выполняет следующее: для выбранных вами объектов по назначенным критериям (для банковских счетов это может быть номер счета, для физических лиц – ФИО и.т.д.) выявляет дубли и те объекты, на которых меньше ссылок – помечает на удаление, а все ссылки на другие объекты перебрасывает с них на остающиеся в программе.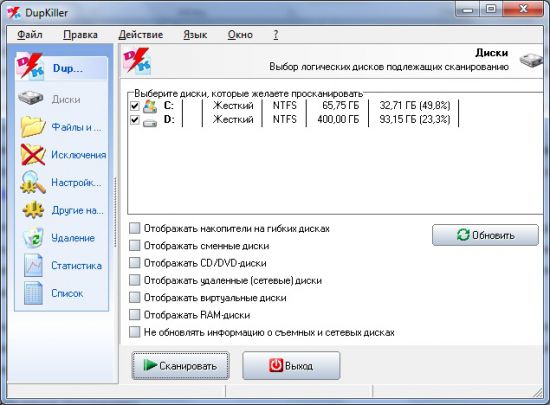 После чего вам останется лишь удалить помеченные объекты, которые уже ни с чем не связаны.
После чего вам останется лишь удалить помеченные объекты, которые уже ни с чем не связаны.
Перед запуском этой обработки создайте резервную копию базы.
Это можно сделать прямо в папке базы (путь к которой указан в стартовом меню), либо через Администрирование – Обслуживание – Резервные копии и восстановление.
Также убедитесь, что отключены имеющиеся в системе даты запрета изменений – они, скорее всего, не дадут вам заменить все ссылки и операция не будет выполнена.
Нажимаем на ссылку Поиск и удаление дублей.
Выбираем объект, по которому требуется проверить наличие дублей. В ссылке Сравнивать выбираем критерии, по которым программа определяет объекты как дубли. В нашем примере объект это Регистрация в налоговых органах, а дубли мы будем определять по совпадению кода налогового органа.
Программа выполнит поиск дублей, покажет их нам и в каждом конкретном случае пометит как основной (объект, который надо оставить) – тот объект, на который привязано больше всего ссылок на документы, записи регистров и прочие объекты.
Особое внимание обратите на критерий назначения объектов дублями.
При поиске дублей среди физических лиц, например, программа по умолчанию назначает критерием Совпадает по похожим словам. Так вот, с таким критерием есть шансы на то, что программа в итоге сочтет дублями физических лиц с похожими фамилиями и удалит одних с заменой на другие со всеми вытекающими!
Критерий нужно вручную поменять на Совпадает. Это гарантирует, что дублями будут признаны лишь физические лица с полным совпадением ФИО.
Отнеситесь к этому моменту серьезно и обязательно создайте копию базы. Удалять последствия некорректного «схлопывания» дублей и восстанавливать учет – очень трудоемкая задача.
Нажимаем Удалить дубли. Иногда, особенно в случаях с удалением ИФНС и организаций, первая попытка может не дать результата – останется какой-то один объект, который не даст завершить переназначение ссылок и дубли останутся.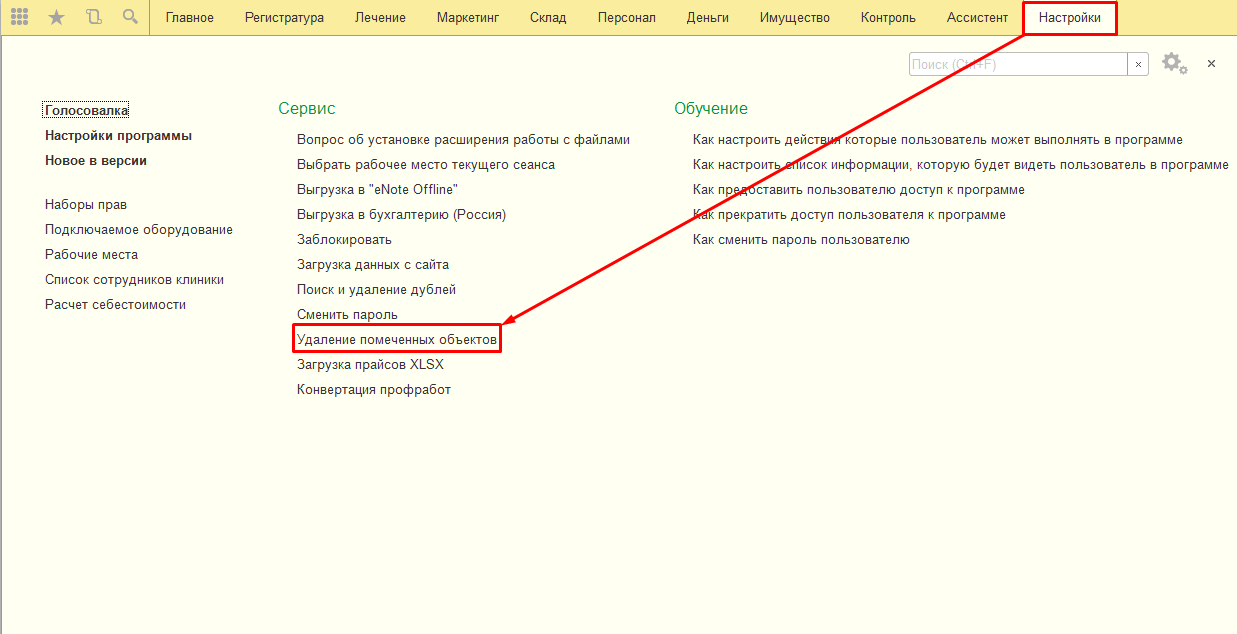 В этом случае выбираем как основной другой объект
и пробуем повторить операцию удаления. В нашем примере мы вручную выбрали как основную ту регистрацию к которой привязана наша организация.
В этом случае выбираем как основной другой объект
и пробуем повторить операцию удаления. В нашем примере мы вручную выбрали как основную ту регистрацию к которой привязана наша организация.
На этот раз переназначение ссылок прошло успешно, а оставшиеся без привязок объекты-дубли теперь помечены в системе на удаление и их можно легко удалить через Администрирование – Обслуживание — Удаление помеченных объектов.
Удаляем через Администрирование – Обслуживание – Удаление помеченных объектов уже ни к чему не привязанные лишние регистрации:
Поиск и удаление дублей 1С 8.3 (8.2) Бухгалтерия
При работе в программах 1С зачастую создаются дубли — одинаковые документы или элементы справочников. Для быстрого выявления дублей используется обработка 1С Поиск и удаление дублей. Рассмотрим, как работать с обработкой на примере 1С:Бухгалтерия предприятия 8.3 и 8.2.
Поиск и удаление дублей 1С 8.
 3
3Дубли приводят к путанице и ошибкам. Типичный пример — одни и те же контрагенты или номенклатура. Для исправления таких ситуаций требуется выполнить действия:
- Найти дубли.
- Определить верный элемент.
- Заменить дубли на оригинал в объектах программы.
- Удалить дубли.
Разберем поиск и удаление дублей 1С 8.3 Бухгалтерия с помощью обработки 1С Поиск и удаление дублей.
Чтобы запустить поиск дублей в 1С 8.3 зайдите в меню Администрирование – Настройки программы – Обслуживание.
Раскройте пункт Корректировка данных и перейдите по ссылке Поиск и удаление дублей.
В поле Искать в нажмите на значок с тремя точками и выберите документ или справочник для поиска дублей.
Поиск дублей в 1С 8.3 Бухгалтерия
Для примера выберем справочник Контрагенты.
Затем определите критерии сравнения по ссылке.
Искать можно по наименованию контрагентов, ИНН, КПП и другим параметрам.
Нажмите кнопку Найти дубли. Откроется результат поиска.
Слева показываются похожие элементы, справа — в каких документах они встречаются. Элемент, который чаще используется, автоматически считается главным. Рядом с ним отображается значок с синей стрелкой. Вы можете сделать главным другой элемент по кнопке Отметить как оригинал.
Следующий шаг — удаление дублей в 1С 8.3 Бухгалтерия.
Флажками отметьте элементы, которые не являются дублями, чтобы случайно их не удалить. Например, на картинке контрагенты Автотрейд и Евротрейд разные.
После определения настроек нажмите кнопку Удалить дубли.
При этом:
- все ссылки на документы и другие объекты перенесутся на главный элемент;
- для дублей установится пометка удаления.
Поиск и замена дублей 1С 8.3 выполнены.
Для удаления дублей в 1С 8.3 Бухгалтерия используйте обработку Удаление помеченных объектов в меню Администрирование – Сервис – Удаление помеченных объектов.
Поиск и удаление дублей 1С 8.2
В 1С 8.2 нет встроенной обработки для поиска дублей. Вы можете массово заменить одно значение на другое, если заранее выявили дубли. Для этого скачайте с сайта ИТС обработку Поиск и замена значений.
Скачать обработку Поиск и замена значений 1С →
Откройте обработку в 1С через меню Файл – Открыть.
Укажите, какой объект вы будете заменять и на что именно.
Нажмите кнопку Найти ссылки.
Отобразится список объектов. Для замены нажмите кнопку Выполнить замену значений.
Установите пометку удаления для лишнего элемента и удалите его через меню Операции – Удаление помеченных объектов.
См. также:
Если Вы еще не подписаны:
Активировать демо-доступ бесплатно →
или
Оформить подписку на Рубрикатор →
После оформления подписки вам станут доступны все материалы Бухэксперт8, записи поддерживающих эфиров и вы сможете задавать любые вопросы по программе 1С.

Помогла статья?
Получите еще секретный бонус и полный доступ к справочной системе БухЭксперт8 на 14 дней бесплатно
Фильтр для уникальных значений или удаление повторяющихся значений
В Excel есть несколько способов отфильтровать уникальные значения или удалить повторяющиеся значения:
Чтобы отфильтровать уникальные значения, щелкните Data> Sort & Filter> Advanced .
Чтобы удалить повторяющиеся значения, щелкните Data> Data Tools > Remove Duplicates .
Чтобы выделить уникальные или повторяющиеся значения, используйте команду Условное форматирование в группе Style на вкладке Home .

Узнайте о фильтрации уникальных значений или удалении повторяющихся значений
Фильтрация уникальных значений и удаление повторяющихся значений — две похожие задачи, поскольку цель состоит в том, чтобы представить список уникальных значений.Однако есть критическое различие: когда вы фильтруете уникальные значения, повторяющиеся значения скрываются только временно. Однако удаление повторяющихся значений означает, что вы навсегда удаляете повторяющиеся значения.
Повторяющееся значение — это такое, в котором все значения хотя бы в одной строке идентичны всем значениям в другой строке. Сравнение повторяющихся значений зависит от того, что отображается в ячейке, а не от базового значения, хранящегося в ячейке. Например, если у вас одно и то же значение даты в разных ячейках, одна отформатирована как «3/8/2006», а другая — как «8 марта 2006 г.», значения будут уникальными.
Проверяйте перед удалением дубликатов: Перед удалением повторяющихся значений рекомендуется сначала попытаться отфильтровать — или условно отформатировать — уникальные значения, чтобы убедиться, что вы достигли ожидаемых результатов.
Фильтр уникальных значений
Выполните следующие действия:
Выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
Щелкните Data> Advanced (в группе Sort & Filter ).
Во всплывающем окне Advanced Filter выполните одно из следующих действий:
Для фильтрации диапазона ячеек или таблицы на месте:
Чтобы скопировать результаты фильтра в другое место:
Щелкните Копировать в другое место .
В поле Копировать в введите ссылку на ячейку.
Или щелкните Свернуть диалоговое окно , чтобы временно скрыть всплывающее окно, выберите ячейку на листе и затем щелкните Развернуть .
Отметьте только уникальных записей , затем щелкните ОК .
Уникальные значения из диапазона будут скопированы в новое место.
Удалить повторяющиеся значения
Удаление повторяющихся значений влияет только на значения в диапазоне ячеек или таблицы. Другие значения за пределами диапазона ячеек или таблицы не изменятся или не переместятся.При удалении дубликатов первое вхождение значения в списке сохраняется, но другие идентичные значения удаляются.
Поскольку вы удаляете данные без возможности восстановления, рекомендуется скопировать исходный диапазон ячеек или таблицы на другой лист или книгу перед удалением повторяющихся значений.
Выполните следующие действия:
Выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
На вкладке Data щелкните Remove Duplicates (в группе Data Tools ).
Выполните одно или несколько из следующих действий:
В разделе Столбцы выберите один или несколько столбцов.
Чтобы быстро выбрать все столбцы, нажмите Выбрать все .
Чтобы быстро очистить все столбцы, нажмите Отменить выбор всех .
Если диапазон ячеек или таблица содержит много столбцов, и вы хотите выбрать только несколько столбцов, вам может быть проще щелкнуть Отменить выбор всех , а затем в разделе Столбцы выберите эти столбцы.
Примечание. Данные будут удалены из всех столбцов, даже если вы не выберете все столбцы на этом шаге. Например, если вы выберете Column1 и Column2, но не Column3, то «ключом», используемым для поиска дубликатов, будет значение BOTH Column1 и Column2. Если в этих столбцах будет обнаружен дубликат, будет удалена вся строка, включая другие столбцы в таблице или диапазоне.
Нажмите ОК , появится сообщение, указывающее, сколько повторяющихся значений было удалено или сколько уникальных значений осталось.Нажмите ОК , чтобы закрыть это сообщение.
Отмените изменение, щелкнув «Отменить» (или нажав Ctrl + Z на клавиатуре).
Проблемы с удалением дубликатов из выделенных данных или данных с промежуточным итогом
Условное форматирование уникальных или повторяющихся значений
Примечание: Вы не можете условно отформатировать поля в области значений отчета сводной таблицы с помощью уникальных или повторяющихся значений.
Быстрое форматирование
Выполните следующие действия:
Выберите одну или несколько ячеек в отчете диапазона, таблицы или сводной таблицы.
На вкладке Home в группе Style щелкните маленькую стрелку для Условное форматирование , а затем щелкните Highlight Cells Rules и выберите Duplicate Values .
Введите значения, которые вы хотите использовать, а затем выберите формат.
Расширенное форматирование
Выполните следующие действия:
Выберите одну или несколько ячеек в отчете диапазона, таблицы или сводной таблицы.
На вкладке Домашняя страница в группе Стили щелкните стрелку Условное форматирование , а затем щелкните Управление правилами , чтобы отобразить всплывающее окно Диспетчера правил условного форматирования .
Выполните одно из следующих действий:
Чтобы добавить условный формат, щелкните Новое правило , чтобы отобразить всплывающее окно Новое правило форматирования .
Чтобы изменить условный формат, сначала убедитесь, что соответствующий рабочий лист или таблица были выбраны в Показать правила форматирования для списка . При необходимости выберите другой диапазон ячеек, нажав кнопку Свернуть во всплывающем окне Применимо к , временно скройте его. Выберите новый диапазон ячеек на листе, затем снова разверните всплывающее окно.Выберите правило, а затем щелкните Изменить правило , чтобы отобразить всплывающее окно Изменить правило форматирования .
Под Выберите тип правила , щелкните Форматировать только уникальные или повторяющиеся значения .
В списке Форматировать все для Отредактируйте описание правила , выберите уникальный или дубликат .
Щелкните Формат , чтобы отобразить всплывающее окно Формат ячеек .
Выберите число, шрифт, границу или формат заливки, которые вы хотите применить, когда значение ячейки удовлетворяет условию, а затем нажмите ОК . Вы можете выбрать более одного формата. Выбранные вами форматы отображаются на панели Preview .
В Excel в Интернете вы можете удалить повторяющиеся значения.
Удалить повторяющиеся значения
Удаление повторяющихся значений влияет только на значения в диапазоне ячеек или таблицы. Другие значения за пределами диапазона ячеек или таблицы не изменятся или не переместятся.При удалении дубликатов первое вхождение значения в списке сохраняется, но другие идентичные значения удаляются.
Важно: Вы всегда можете нажать Отменить , чтобы вернуть свои данные после удаления дубликатов. При этом рекомендуется скопировать исходный диапазон ячеек или таблицы на другой лист или книгу перед удалением повторяющихся значений.
Выполните следующие действия:
Выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
На вкладке Data щелкните Remove Duplicates .
В диалоговом окне Удалить дубликаты снимите выделение со всех столбцов, в которых вы не хотите удалять повторяющиеся значения.
Примечание. Данные будут удалены из всех столбцов, даже если вы не выберете все столбцы на этом шаге.Например, если вы выберете Column1 и Column2, но не Column3, то «ключом», используемым для поиска дубликатов, будет значение BOTH Column1 и Column2. Если дубликат обнаружен в столбце 1 и столбце 2, вся строка будет удалена, включая данные из столбца 3.
Щелкните ОК , появится сообщение, указывающее, сколько повторяющихся значений было удалено. Нажмите ОК , чтобы закрыть это сообщение.
Примечание: Если вы хотите вернуть свои данные, просто нажмите Отменить (или нажмите Ctrl + Z на клавиатуре).
Как удалить дубликаты в Google Таблицах (3 простых способа)
Посмотреть видео — Удаление дубликатов в Google Таблицах
Google Таблицы постепенно становятся популярным выбором для многих людей.Легкость, с которой вы можете сотрудничать в Google Таблицах, намного превосходит все другие инструменты для работы с электронными таблицами.
Другая причина, по которой Google Таблицы так широко используются, связана с простотой использования. Команда, стоящая за ним, постоянно добавляет новые функции и возможности, которые упрощают и ускоряют работу.
В этом уроке я покажу вам несколько способов удаления дубликатов в Google Таблицах.
Удаление дубликатов с помощью инструмента «Удалить дубликаты»
Удаление дубликатов — обычное дело в Google Таблицах, что теперь есть специальная опция для быстрого удаления дубликатов записей.
Предположим, у вас есть набор данных, как показано ниже, и вы хотите удалить все повторяющиеся записи из этого набора данных.
Ниже приведены шаги по удалению дубликатов из набора данных в Google Таблицах:
- Выберите набор данных, из которого вы хотите удалить повторяющиеся записи
- Выберите пункт «Данные» в меню.
- Нажмите на опцию «Удалить дубликаты».
- Убедитесь, что в диалоговом окне «Удаление дубликатов» выбрано «Данные имеют строку заголовка» (в случае, если у ваших данных есть строка заголовка).
- Убедитесь, что выбрано «Выбрать все» (в разделе «Столбцы для анализа»).
- Нажмите кнопку «Удалить дубликаты».
Приведенные выше шаги немедленно удалят все повторяющиеся записи из набора данных, и вы получите результат, как показано ниже.
Когда вы используете опцию «Удалить дубликаты», чтобы избавиться от повторяющихся записей, это не повлияет на данные вокруг них. Это означает, что при его использовании не удаляются строки и не удаляются ячейки. Он просто удаляет повторяющиеся записи из ячеек (без нарушения ячеек в наборе данных)
Также читайте: Как выделить дубликаты в Google Таблицах
Удалить дубликаты с помощью УНИКАЛЬНОЙ функции
ВGoogle Sheets также есть функция, которую можно использовать для удаления повторяющихся значений и сохранения только уникальных значений.
Это УНИКАЛЬНАЯ функция.
Предположим, у вас есть набор данных, как показано ниже, и вы хотите удалить все повторяющиеся записи из этого набора данных:
Приведенная ниже формула удалит все повторяющиеся записи, и вы получите все уникальные:
= УНИКАЛЬНЫЙ (A2: B17)
Приведенная выше формула даст вам результат, начиная с ячейки, в которую вы ввели формулу.
Результат представляет собой массив уникальных записей, и вы не можете удалить или изменить часть этого результата массива.Ничего не произойдет, если вы попытаетесь удалить какую-либо одну ячейку из результата. И если вы перезапишете какую-либо ячейку, весь результат исчезнет, и вы увидите # ССЫЛКА! ошибка.
Одним из ограничений использования функции UNIQUE является то, что она будет рассматривать как дубликаты только те записи, в которых повторяется все содержимое строки. Если вы хотите сохранить только один экземпляр названия страны и удалить все остальные, UNIQUE сделает это только в том случае, если остальные значения столбца для этой записи также совпадают.
Если в ваших данных есть начальные, конечные или дополнительные пробелы, функция unique будет рассматривать записи как разные. В таком случае вы можете использовать следующую формулу:
= ArrayFormula (UNIQUE (TRIM (A2: B17)))
Также прочтите : Как сохранить ведущие нули в Google Таблицах
Удалить дубликаты с помощью надстройки
Google Sheets, как правило, поддерживает огромную библиотеку различных надстроек, чтобы решить все мыслимые проблемы или проблемы.
Все надстройки для удаления дубликатов могут использоваться для одной и той же цели.Надстройка Remove Duplicates от AbleBits — одна из лучших надстроек для удаления повторяющихся записей из вашего набора данных.
Чтобы использовать надстройку, сначала необходимо добавить ее в документ Google Таблиц.
Ниже приведены шаги по добавлению надстройки в документ Google Таблиц:
- Откройте документ Google Таблиц, в котором вы хотите удалить дубликаты
- Перейдите на вкладку «Дополнения»
- Нажмите «Получить надстройки»
- В открывшемся диалоговом окне «Дополнения» найдите «Удалить дубликат» в поле в правом верхнем углу.
- В отображаемом списке надстроек щелкните надстройку «Удалить дубликаты».
- На экране надстройки «Удалить дубликаты» нажмите синюю кнопку «Установить».
- В появившемся диалоговом окне он может попросить вас подтвердить свою учетную запись, войдя в свой Gmail. Введите учетные данные и нажмите синюю кнопку «Разрешить».
Вышеупомянутые шаги добавят надстройку «Удалить дубликаты» в ваш документ Google Таблиц, и теперь вы можете начать ее использовать.
Ниже приведены шаги по использованию этого дополнения для удаления повторяющихся записей в Google Таблицах:
- Выберите набор данных, в котором есть дубликаты, которые вы хотите удалить.
- В меню выберите «Надстройки».
- Наведите курсор на опцию «Удалить дубликаты».
- Нажмите «Найти повторяющиеся или уникальные строки». Откроется диалоговое окно «Найти повторяющиеся или уникальные строки» (это может занять несколько секунд).
- На шаге 1 убедитесь, что выбран правильный диапазон. Вы также можете установить флажок, чтобы создать резервную копию документа Google Sheets.
- На шаге 2 убедитесь, что выбраны дубликаты.
- На шаге 3 укажите, есть ли у ваших данных заголовок и нужно ли пропускать пустые ячейки.
- На шаге 4 выберите параметр «Удалить строки в выделенном фрагменте». Это удалит повторяющиеся записи.
- Нажмите «Готово».
Приведенные выше шаги мгновенно удалят повторяющиеся записи, и у вас останутся только уникальные записи.
Поскольку в Google Таблицах уже есть способ быстрого удаления дубликатов с помощью встроенной функции, по возможности лучше использовать его. Единственная причина, по которой я бы рекомендовал использовать надстройку, — это когда вы хотите сделать гораздо больше, чем просто удалить дубликаты.
Это дополнение также может выполнять следующее:
- Раскрасьте повторяющиеся записи
- Добавьте столбец и укажите дублирующие записи
- Сравните столбцы или листы
Вам также могут понравиться следующие руководства по Google Таблицам:
Как удалить дубликаты из списка Python
Узнайте, как удалить дубликаты из списка в Python.
Пример
Удалить все дубликаты из списка:
mylist = [«a», «b», «a», «c», «c»]
mylist = list (dict.fromkeys (mylist))
печать (mylist)
Объяснение примера
Сначала у нас есть список, содержащий дубликаты:
Список с дубликатами
mylist = [«a», «b», «a», «c», «c»]
mylist = list (dict.fromkeys (mylist))
печать (mylist)
Создать словарь, используя элементы списка в качестве ключей. Это автоматически удалит все дубликаты. потому что словари не могут иметь повторяющихся ключей.
Создать словарь
mylist = [«a», «b», «a», «c», «c»]
mylist = list ( дикт.fromkeys (mylist) )
печать (mylist)
Затем преобразуйте словарь обратно в список:
Преобразовать в список
mylist = [«a», «b», «a», «c», «c»]
mylist = list ( dict.fromkeys (mylist) )
print (mylist)
Теперь у нас есть список без дубликатов, и он имеет тот же порядок, что и Оригинальный список.
Распечатайте список для демонстрации результата
Распечатать список
mylist = [«a», «b», «a», «c», «c»]
mylist = list (dict.fromkeys (mylist))
печать (мой список)
Создать функцию
Если вам нравится иметь функцию, в которой вы можете отправлять свои списки и получать их обратно без дубликатов, можно создать функцию и вставить код из пример выше.
Пример
def my_function (x):список возврата (dict.fromkeys (x))
mylist = my_function ([«a», «b», «a», «c», «c»])
print (mylist)
Попробуй сам »Объяснение примера
Создайте функцию, которая принимает список в качестве аргумента.
Создание функции
def my_function (x):список возврата (dict.fromkeys (x))
mylist = my_function ([«a», «b», «a», «c», «c»])
print (mylist)
Создайте словарь, используя элементы этого списка в качестве ключей.
Создать словарь
def my_function (x):список возврата ( dict.fromkeys (x) )
mylist = my_function ([«a», «b», «a», «c», «c»])
print (mylist)
Преобразование словаря в список.
Преобразовать в список
def my_function (x):return list ( dict.fromkeys (x) )
mylist = my_function ([«a», «b», «a», «c», «c»])
print (mylist)
Вернуть список
Список возврата
def my_function (x):return list (dict.fromkeys (x))
mylist = my_function ([«a», «b», «a», «c», «c»])
print (mylist)
Вызов функции со списком в качестве параметра:
Вызов функции
def my_function (x):список возврата (dict.fromkeys (x)) mylist = my_function ([«a», «b», «a», «c», «c»]) print (mylist)
Распечатайте результат:
Распечатать результат
def my_function (x):список возврата (dict.fromkeys (x))
mylist = my_function ([«a», «b», «a», «c», «c»])
print (mylist)Как удалить дубликаты в Excel для очистки данных
Идет загрузка.Повторяющиеся значения могут быть проблемой, особенно если вы имеете дело с большим набором данных.
То, что выглядит как список из 100 элементов, может быть только 70, если вы удалите элементы, которые присутствуют в списке более одного раза.
Excel поставляется со встроенным инструментом, который упрощает и ускоряет очистку данных.Вот как это работает.
Ознакомьтесь с продуктами, упомянутыми в этой статье:Microsoft Office (от 149,99 при лучшей покупке)
MacBook Pro (от 1299,99 при лучшей покупке)
Lenovo IdeaPad (от 299,99 при лучшей покупке)
Как удалить дубликаты в Excel для одного столбцаЕсли у вас есть повторяющиеся данные, которые вы хотите удалить из одного столбца в наборе данных, начните с нажатия на столбец, который вы хотите удалить.
1. Щелкните «Данные» в верхнем меню окна Excel, чтобы открыть ленту меню «Данные».
2. Щелкните «Удалить дубликаты».
3. Появится окно. Если ваш столбец включает заголовок, убедитесь, что установлен флажок «Мой список содержит заголовки».
4. Появится окно с сообщением, сколько дубликатов было удалено и сколько осталось. Нажмите «ОК», чтобы закрыть окно.
Щелкните «ОК».»
Лаура МакКэми / Business Insider 5. Excel удалит только точные дубликаты. В этом примере второй Square неправильно написан как Squarre, поэтому после удаления дубликатов оба написания Square остаются.
6. Вы также можете выделить диапазон ячеек и удалить дубликаты.
7. При вычитании диапазона удаляются только дубликаты в пределах диапазона.В этом случае квадрат удаляется, но дубликаты круга и треугольника остаются.
Вы также можете удалить дубликаты в нескольких столбцах.
Как удалить дубликаты в Excel для нескольких столбцов1. Сначала удалите все дубликаты в столбце A. Поместите курсор в столбец и щелкните правой кнопкой мыши, чтобы удалить дубликаты.
2. Щелкните «Удалить дубликаты». Когда появится окно, нажмите «ОК».«
3. Теперь удаляются только дубликаты в столбце A, но значение« синий »по-прежнему появляется дважды в столбце B.
4. Если вы хотите удалить дубликаты из нескольких столбцов, начните с щелчка по одному
5. Щелкните «Удалить дубликаты». Щелкните поле рядом со столбцом A, чтобы снять его отметку. Нажмите «ОК».
Снимите флажок рядом с столбцом A.Лаура МакКэми / Business Insider6. В дополнение к трем строкам, которые имели одинаковую комбинацию формы / цвета, на этот раз вы также удалили значение «Прямоугольник» из столбца A, потому что это была вторая строка, которая включала «синий» в столбец B. нет повторяющихся форм или цветов.
«Удалить дубликаты» — мощный инструмент.Используйте его осторожно. Как отмечалось выше, вы можете пропустить дубликаты, если они не точны, или вы можете удалить значения, которые хотите сохранить. Однако, если вы допустили ошибку, вы можете быстро восстановить данные, удерживая «Control» + «Z» на ПК или «command» + «Z» на клавиатуре Mac, чтобы отменить операцию.
Как быстро удалить дубликаты в Excel
Чем сложнее становится электронная таблица, тем проще дублировать ячейки, строки или столбцы.Вскоре становится трудно видеть реальные данные по копиям, и управление всем этим может стать утомительным. К счастью, обрезка электронных таблиц — это просто, если не отнимает много времени, но ее можно упростить с помощью нескольких уловок. Вот несколько простых способов удалить дубликаты в Excel.
Удаление повторяющихся ячеек, строк и столбцов
Если вы редактируете важную или рабочую электронную таблицу, сначала сделайте резервную копию. Это может сэкономить время и душевную боль, если что-то пойдет не так. Как поиск, так и удаление частей этого руководства довольно безопасны для обычного использования, поскольку они используют встроенные инструменты.Однако более сложные таблицы, содержащие формулы или фильтры, могут вызвать у вас головную боль.
Быстрое и легкое удаление дубликатов в Excel
Во-первых, нам нужно определить, есть ли дубликаты в электронной таблице. В небольшой таблице их можно легко идентифицировать. В больших таблицах это может быть трудно идентифицировать без небольшой помощи. Вот как их найти.
- Откройте электронную таблицу на странице, которую нужно отсортировать.
- Нажмите Ctrl + A, чтобы выделить все.
- Щелкните Условное форматирование.
- Выберите «Правила выделения ячеек», а затем «Повторяющиеся значения», установите стиль для выделения дубликатов и нажмите «ОК».
Теперь ваша электронная таблица отформатирует каждую повторяющуюся ячейку выбранным вами цветом. Это быстрый и простой способ узнать, сколько дубликатов у вас на листе.
Как только вы узнаете, сколько у вас дубликатов, вы можете удалить их двумя простыми способами. Если вы используете Microsoft Office 2013/6 или Office 365, у вас есть преимущество.Microsoft любезно добавила функцию удаления дубликатов в Excel специально для этого случая.
- Откройте электронную таблицу на странице, которую нужно отсортировать.
- Нажмите Ctrl + A, чтобы выделить все.
- Щелкните вкладку «Данные» и выберите «Удалить дубликаты».
- Установите или снимите флажок «У моих данных есть заголовки» в зависимости от того, есть они у вас или нет.
- Нажмите ОК, чтобы удалить дубликаты.
Есть еще один способ удалить дубликаты в Excel с помощью расширенных фильтров.
- Откройте электронную таблицу на странице, которую нужно отсортировать.
- Перетащите мышь, чтобы включить все ячейки, которые нужно отфильтровать.
- Щелкните вкладку «Данные» и выберите «Дополнительно».
- Установите флажок «Только уникальные записи» и нажмите «ОК».
Этот метод удаляет все дубликаты, кроме тех, которые, по его мнению, могут быть заголовками столбцов. Их нужно будет удалить вручную. В остальном он выполняет ту же работу, что и удаление дубликатов.
Существуют и другие способы простого удаления дубликатов в Excel с помощью формул, но, учитывая простоту этих двух операций, в действительности нет смысла их использовать.Есть ли у вас другие интересные способы удаления повторяющихся записей? Дайте нам знать ниже, если вы это сделаете!
7 способов поиска и удаления повторяющихся значений в Microsoft Excel
Повторяющиеся значения в ваших данных могут стать большой проблемой! Это может привести к существенным ошибкам и завышению ваших результатов.
Но найти и удалить их из данных в Excel на самом деле довольно просто.
В этом руководстве мы рассмотрим 7 различных методов поиска и удаления повторяющихся значений из ваших данных.
Видеоурок
Что такое повторяющееся значение?
Повторяющиеся значения возникают, когда в ваших данных появляется одно и то же значение или набор значений.
Для заданного набора данных вы можете определять дубликаты множеством различных способов.
В приведенном выше примере есть простой набор данных с 3 столбцами для марки, модели и года для списка автомобилей.
- На первом изображении выделены все дубликаты, основанные только на марке автомобиля.
- На втором изображении выделены все дубликаты в зависимости от марки и модели автомобиля. В результате на один дубликат меньше.
- Второе изображение выделяет все дубликаты по всем столбцам таблицы. Это приводит к тому, что еще меньше значений считается повторяющимися.
Результаты дублирования на основе одного столбца и всей таблицы могут сильно отличаться. Вы всегда должны знать, какую версию вы хотите и что делает Excel.
Найдите и удалите повторяющиеся значения с помощью команды удаления дубликатов
Удаление повторяющихся значений в данных — очень распространенная задача.Это настолько распространено, что на ленте есть специальная команда.
Выберите ячейку внутри данных, из которой вы хотите удалить дубликаты, перейдите на вкладку Данные и щелкните команду Удалить дубликаты .
Excel выберет весь набор данных и откроет окно «Удалить дубликаты».
- Затем вам нужно сообщить Excel, содержат ли данные заголовки столбцов в первой строке. Если этот флажок установлен, первая строка данных будет исключена при поиске и удалении повторяющихся значений.
- Затем вы можете выбрать, какие столбцы использовать для определения дубликатов. Также есть удобные кнопки Выбрать все и Отменить выделение всех , которые можно использовать, если у вас длинный список столбцов в ваших данных.
Когда вы нажмете OK , Excel удалит все найденные повторяющиеся значения и даст вам общее количество значений, которые были удалены и сколько значений осталось.
Эта команда изменит ваши данные, поэтому лучше всего выполнить команду с копией ваших данных, чтобы сохранить исходные данные нетронутыми.
Найдите и удалите повторяющиеся значения с помощью расширенных фильтров
Есть также другой способ избавиться от любых повторяющихся значений в ваших данных с ленты. Это возможно с помощью расширенных фильтров.
Выберите ячейку внутри данных, перейдите на вкладку Data и щелкните команду Advanced filter.
Откроется окно расширенного фильтра.
- Вы можете выбрать: Отфильтровать список на месте или Копировать в другое место .Фильтрация списка на месте скроет строки, содержащие любые дубликаты, а при копировании в другое место будет создана копия данных.
- Excel угадывает диапазон данных, но вы можете изменить его в диапазоне списка . Диапазон критериев можно оставить пустым, а поле Копировать в необходимо будет заполнить, если была выбрана опция Копировать в другое место .
- Установите флажок для Только уникальные записи .
Нажмите OK , и вы удалите повторяющиеся значения.
Расширенные фильтры могут быть удобной опцией для избавления от повторяющихся значений и одновременного создания копии ваших данных. Но расширенные фильтры смогут сделать это только для всей таблицы.
Поиск и удаление повторяющихся значений с помощью сводной таблицы
Сводные таблицы предназначены только для анализа ваших данных, верно?
Вы также можете использовать их для удаления повторяющихся данных!
Фактически вы не будете удалять повторяющиеся значения из данных с помощью этого метода, вы будете использовать сводную таблицу для отображения только уникальных значений из набора данных.
Сначала создайте сводную таблицу на основе ваших данных. Выберите ячейку внутри ваших данных или весь диапазон данных ➜ перейдите на вкладку Insert ➜ выберите PivotTable ➜ нажмите OK в диалоговом окне Create PivotTable.
С новой пустой сводной таблицей добавьте все поля в область строк, сводной таблицы.
Затем вам нужно будет изменить макет итоговой сводной таблицы, чтобы она имела табличный формат.Выбрав сводную таблицу, перейдите на вкладку Design и выберите Report Layout . Здесь вам нужно изменить два параметра.
- Выберите параметр Показать в табличной форме .
- Выберите параметр «Повторить все метки элементов ».
Вам также потребуется удалить все промежуточные итоги из сводной таблицы. Перейдите на вкладку Design ➜ выберите Промежуточные итоги ➜ выберите Не показывать промежуточные итоги .
Теперь у вас есть сводная таблица, которая имитирует набор данных в виде таблицы!
Сводные таблицы содержат только уникальные значения для элементов в области строк, поэтому эта сводная таблица автоматически удалит любые дубликаты в ваших данных.
Найдите и удалите повторяющиеся значения с помощью Power Query
Power Query — это преобразование данных, поэтому вы можете быть уверены, что он может находить и удалять повторяющиеся значения.
Выберите таблицу значений, из которой вы хотите удалить дубликаты ➜ перейдите на вкладку Data ➜ выберите запрос From Table / Range .
Удаление дубликатов на основе одного или нескольких столбцов
С помощью Power Query вы можете удалять дубликаты на основе одного или нескольких столбцов в таблице.
Вам необходимо выбрать столбцы для удаления дубликатов. Вы можете удерживать Ctrl, чтобы выбрать несколько столбцов.
Щелкните правой кнопкой мыши заголовок выбранного столбца и выберите в меню Удалить дубликаты .
Вы также можете получить доступ к этой команде из вкладки Home ➜ Удалить строки ➜ Удалить дубликаты .
= Table.Distinct (# "Предыдущий шаг", {"Марка", "Модель"}) Если вы посмотрите на созданную формулу, она использует функцию Table.Distinct со вторым параметром, указывающим, какие столбцы использовать.
Удаление дубликатов на основе всей таблицы
Чтобы удалить дубликаты по всей таблице, вы можете выбрать все столбцы в таблице, а затем удалить дубликаты. Но есть более быстрый метод, который не требует выбора всех столбцов.
В верхнем левом углу окна предварительного просмотра данных есть кнопка с набором команд, которые можно применить ко всей таблице.
Нажмите кнопку таблицы в верхнем левом углу ➜ затем выберите Удалить дубликаты .
= Table.Distinct (# "Предыдущий шаг") Если вы посмотрите на созданную формулу, она использует ту же функцию Table.Distinct без второго параметра. Без второго параметра функция будет действовать для всей таблицы.
Хранить дубликаты в одном столбце или во всей таблице
В Power Query также есть команды для сохранения дубликатов для выбранных столбцов или для всей таблицы.
Выполните те же действия, что и при удалении дубликатов, но вместо этого используйте команду Сохранить строки ➜ Сохранить дубликаты . Это покажет вам все данные с повторяющимся значением.
Найти и удалить повторяющиеся значения с помощью формулы
Вы можете использовать формулу, чтобы найти повторяющиеся значения в ваших данных.
Сначала вам нужно добавить вспомогательный столбец, который объединяет данные из любых столбцов, на которых вы хотите основать свое повторяющееся определение.
= [@Make] & [@Model] & [@Year] Приведенная выше формула объединит все три столбца в один столбец. Он использует оператор амперсанда для соединения каждого столбца.
= TEXTJOIN ("", FALSE, CarList [@ [Make]: [Year]]) Если у вас есть длинный список столбцов для объединения, вы можете вместо этого использовать приведенную выше формулу.Таким образом, вы можете просто ссылаться на все столбцы как на один диапазон.
Затем вам нужно будет добавить еще один столбец для подсчета повторяющихся значений. Это будет использоваться позже для фильтрации строк данных, которые появляются более одного раза.
= СЧЁТЕСЛИМН ($ E $ 3: E3, E3) Скопируйте приведенную выше формулу в столбец, и она подсчитает, сколько раз текущее значение появляется в списке значений выше.
Если счетчик равен 1, то значение появляется в данных впервые, и вы сохраните его в своем наборе уникальных значений.Если счетчик равен 2 или больше, значит, значение уже появилось в данных, и это повторяющееся значение, которое можно удалить.
Добавьте фильтры в список данных.
- Перейдите на вкладку Данные и выберите команду Фильтр .
- Используйте сочетание клавиш Ctrl + Shift + L.
Теперь вы можете фильтровать по столбцу Счетчик. Фильтрация по 1 произведет все уникальные значения и удалит все дубликаты.
Затем вы можете выбрать видимые ячейки из полученного фильтра для копирования и вставки в другое место.Используйте сочетание клавиш Alt +; для выбора только видимых ячеек.
Найти и удалить повторяющиеся значения с помощью условного форматирования
При условном форматировании есть способ выделить повторяющиеся значения в ваших данных.
Как и в случае с методом формулы, вам нужно добавить вспомогательный столбец, который объединяет данные из столбцов. Условное форматирование не работает с данными по строкам, поэтому вам понадобится этот комбинированный столбец, если вы хотите обнаружить дубликаты на основе более чем одного столбца.
Затем нужно выбрать столбец объединенных данных.
Чтобы создать условное форматирование, перейдите на вкладку Home ➜ выберите Условное форматирование ➜ Правила выделения ячеек ➜ Повторяющиеся значения .
Откроется окно условного форматирования повторяющихся значений.
- Вы можете выбрать, чтобы выделить повторяющиеся или уникальные значения.
- Вы также можете выбрать один из предопределенных форматов ячеек, чтобы выделить значения, или создать свой собственный формат.
Предупреждение : предыдущие методы поиска и удаления дубликатов рассматривают первое вхождение значения как дубликат и оставляют его нетронутым. Однако этот метод выделит первое вхождение и не будет различать.
Теперь, когда значения выделены, вы можете фильтровать повторяющиеся или уникальные значения с помощью параметра фильтра по цвету.Обязательно добавьте фильтры к своим данным. Перейдите на вкладку Data и выберите команду Filter или используйте сочетание клавиш Ctrl + Shift + L.
- Щелкните переключатель фильтра.
- Выберите в меню Фильтр по цвету .
- Отфильтруйте цвет, используемый в условном форматировании, чтобы выбрать повторяющиеся значения, или отфильтруйте Без заливки, чтобы выбрать уникальные значения.
Затем вы можете выбрать только видимые ячейки с помощью сочетания клавиш Alt +;.
Найдите и удалите повторяющиеся значения с помощью VBA
В VBA есть встроенная команда для удаления дубликатов в объектах списка.
Sub RemoveDuplicates ()Dim DuplicateValues As RangeУстановить DuplicateValues = ActiveSheet.ListObjects ("CarList"). ДиапазонDuplicateValues.RemoveDuplicates Columns: = Array (1, 210, 315), Heesader: Концевой переводник
Вышеупомянутая процедура удалит дубликаты из таблицы Excel с именем CarList .
Столбцы: = Массив (1, 2, 3) В приведенной выше части процедуры будут установлены столбцы, на которых будет основываться обнаружение дубликатов. В этом случае он будет во всей таблице, поскольку перечислены все три столбца.
Заголовок: = xl Да Приведенная выше часть процедуры сообщает Excel, что первая строка в нашем списке содержит заголовки столбцов.
Перед запуском этого кода VBA вам нужно создать копию своих данных, поскольку ее нельзя будет отменить после выполнения кода.
Выводы
Дублирующиеся значения в ваших данных могут стать большим препятствием на пути к чистому набору данных.
К счастью, в Excel есть множество опций, с помощью которых можно легко удалить эти надоедливые повторяющиеся значения.
Итак, каков ваш метод удаления дубликатов?
python — Удаление дубликатов в списках
В этом ответе будет два раздела: два уникальных решения и график скорости для конкретных решений.
Удаление повторяющихся элементов
Большинство этих ответов удаляют только повторяющиеся элементы, которые являются хешируемыми , но этот вопрос не означает, что ему не нужны просто хэшируемые элементы , то есть я предлагаю некоторые решения, которые не требуют хэшируемых элементов .
коллекций. Счетчик — мощный инструмент в стандартной библиотеке, который идеально подходит для этого. Есть только одно другое решение, в котором даже есть Counter. Однако это решение также ограничено хэшируемыми ключами.
Чтобы разрешить нехешируемые ключи в Counter, я создал класс Container, который будет пытаться получить хэш-функцию объекта по умолчанию, но если это не удастся, он попробует свою функцию идентификации. Он также определяет метод eq и хэш .Этого должно быть достаточно, чтобы разрешить нехешируемых элементов в нашем решении. Нехэшируемые объекты будут обрабатываться как хешируемые. Однако эта хеш-функция использует идентичность для нехэшируемых объектов, что означает, что два равных объекта, которые оба являются нехешируемыми, не будут работать. Я предлагаю вам переопределить это и изменить его, чтобы использовать хэш эквивалентного изменяемого типа (например, с использованием hash (tuple (my_list)) , если my_list является списком).
Я также сделал два решения. Другое решение, которое сохраняет порядок элементов, используя подкласс как OrderedDict, так и Counter, который называется OrderedCounter.Теперь вот функции:
из коллекции import OrderedDict, Counter
класс Контейнер:
def __init __ (self, obj):
self.obj = obj
def __eq __ (self, obj):
вернуть self.obj == obj
def __hash __ (сам):
пытаться:
вернуть хеш (self.obj)
Кроме:
вернуть идентификатор (self.obj)
класс OrderedCounter (Счетчик, OrderedDict):
'Счетчик, который запоминает, что элементы заказа встречаются впервые'
def __repr __ (сам):
return '% s (% r)'% (self.__class __.__ name__, OrderedDict (сам))
def __reduce __ (сам):
вернуть self .__ class__, (OrderedDict (self),)
def remd (последовательность):
cnt = Счетчик ()
для x последовательно:
cnt [Контейнер (x)] + = 1
вернуть [item.obj для элемента в cnt]
def oremd (последовательность):
cnt = OrderedCounter ()
для x последовательно:
cnt [Контейнер (x)] + = 1
вернуть [item.obj для элемента в cnt]
remd — это неупорядоченная сортировка, а oremd — упорядоченная сортировка.Вы можете четко сказать, какой из них быстрее, но я все равно объясню. Неупорядоченная сортировка выполняется немного быстрее, поскольку не сохраняет порядок элементов.
Теперь я также хотел показать сравнение скорости каждого ответа. Итак, я сделаю это сейчас.
Какая функция самая быстрая?
Для удаления дубликатов я собрал 10 функций из нескольких ответов. Я вычислил скорость каждой функции и поместил ее в график, используя matplotlib.pyplot .
Я разделил это на три этапа построения графика.Хешируемый — это любой объект, который может быть хеширован, нехешируемый — это любой объект, который не может быть хеширован. Упорядоченная последовательность — это последовательность, которая сохраняет порядок, неупорядоченная последовательность не сохраняет порядок. А теперь еще несколько терминов:
Unordered Hashable был для любого метода, который удалял дубликаты, которые не обязательно должны были поддерживать порядок. Это не должно было работать для неудачников, но могло.
Ordered Hashable был для любого метода, который сохранял порядок элементов в списке, но он не должен был работать для нехэшируемых, но мог.
Упорядоченный, не хэшируемый — это любой метод, который сохраняет порядок элементов в списке и работает с нехешируемыми.
По оси ординат указано количество секунд, которое потребовалось.
По оси абсцисс отложено число, к которому была применена функция.
Я сгенерировал последовательности для неупорядоченных и упорядоченных хешейблов со следующим пониманием: [список (диапазон (x)) + список (диапазон (x)) для x в диапазоне (0, 1000, 10)]
Для упорядоченных нехэшируемых объектов: [[список (диапазон (y)) + список (диапазон (y)) для y в диапазоне (x)] для x в диапазоне (0, 1000, 10)]
Обратите внимание, что в диапазоне есть шаг , потому что без него это заняло бы в 10 раз больше времени.Также потому, что, по моему личному мнению, я подумал, что это могло показаться немного легче для чтения.
Также обратите внимание, что клавиши в легенде — это то, что я пытался угадать как наиболее важные части реализации функции. Какая функция лучше всего или хуже? График говорит сам за себя.
Итак, вот графики.
Неупорядоченные хэш-файлы
(Увеличено)
Заказанные хэшаблы
(Увеличено)
Упорядоченные Unhashables
(Увеличено)
.